
1. परिचय
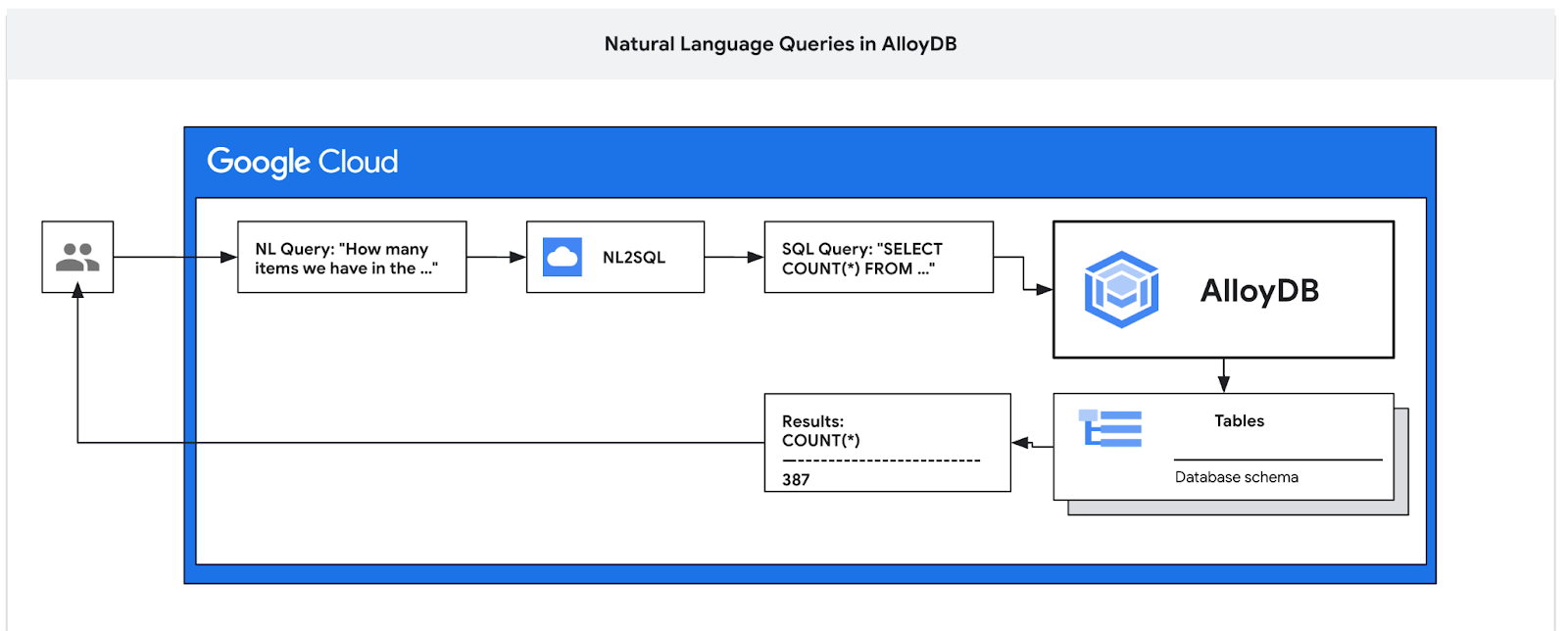
इस कोडलैब में, आपको AlloyDB को डिप्लॉय करने का तरीका बताया जाएगा. साथ ही, इसमें एआई की नैचुरल लैंग्वेज का इस्तेमाल करके डेटा से जुड़ी क्वेरी करने और अनुमानित और असरदार क्वेरी के लिए कॉन्फ़िगरेशन को ट्यून करने का तरीका भी बताया जाएगा. यह लैब, AlloyDB AI की सुविधाओं के लिए बनाए गए लैब कलेक्शन का हिस्सा है. दस्तावेज़ में AlloyDB AI पेज पर जाकर, इस बारे में ज़्यादा पढ़ें.
ज़रूरी शर्तें
- Google Cloud और Console की बुनियादी जानकारी
- कमांड लाइन इंटरफ़ेस और Cloud Shell में बुनियादी कौशल
आपको क्या सीखने को मिलेगा
- AlloyDB for Postgres को डिप्लॉय करने का तरीका
- AlloyDB AI की सामान्य भाषा वाली सुविधा को चालू करने का तरीका
- एआई की नैचुरल लैंग्वेज के लिए कॉन्फ़िगरेशन बनाने और उसे ट्यून करने का तरीका
- आम भाषा का इस्तेमाल करके एसक्यूएल क्वेरी जनरेट करने और नतीजे पाने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- Google Cloud Console और Cloud Shell के साथ काम करने वाला वेब ब्राउज़र, जैसे कि Chrome
2. सेटअप और ज़रूरी शर्तें
अपने हिसाब से एनवायरमेंट सेट अप करना
- Google Cloud Console में साइन इन करें और नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.

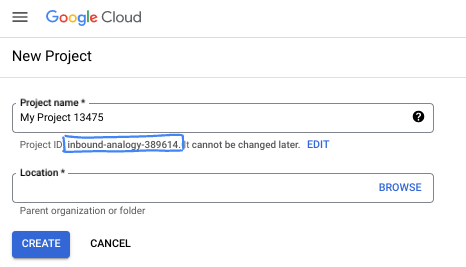
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. यह एक वर्ण स्ट्रिंग है, जिसका इस्तेमाल Google API नहीं करते. इसे कभी भी अपडेट किया जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Cloud Console, यूनीक स्ट्रिंग को अपने-आप जनरेट करता है. आम तौर पर, आपको इससे कोई फ़र्क़ नहीं पड़ता कि यह क्या है. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी (आम तौर पर
PROJECT_IDके तौर पर पहचाना जाता है) का रेफ़रंस देना होगा. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा रैंडम आईडी जनरेट किया जा सकता है. इसके अलावा, आपके पास अपना नाम आज़माने का विकल्प भी है. इससे आपको पता चलेगा कि वह नाम उपलब्ध है या नहीं. इस चरण के बाद, इसे बदला नहीं जा सकता. यह प्रोजेक्ट की अवधि तक बना रहता है. - आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
- इसके बाद, आपको Cloud Console में बिलिंग चालू करनी होगी, ताकि Cloud संसाधनों/एपीआई का इस्तेमाल किया जा सके. इस कोडलैब को पूरा करने में ज़्यादा समय नहीं लगेगा. इस ट्यूटोरियल के बाद बिलिंग से बचने के लिए, संसाधनों को बंद किया जा सकता है. इसके लिए, बनाए गए संसाधनों को मिटाएं या प्रोजेक्ट को मिटाएं. Google Cloud के नए उपयोगकर्ताओं को, 300 डॉलर का क्रेडिट मिलेगा. वे इसे मुफ़्त में आज़मा सकते हैं.
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:
इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, यह Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
3. शुरू करने से पहले
एपीआई चालू करना
Cloud Shell में, पक्का करें कि आपका प्रोजेक्ट आईडी सेट अप हो:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID एनवायरमेंट वैरिएबल सेट करें:
PROJECT_ID=$(gcloud config get-value project)
सभी ज़रूरी सेवाएं चालू करें:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
अनुमानित आउटपुट
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB डिप्लॉय करना
AlloyDB क्लस्टर और प्राइमरी इंस्टेंस बनाएं. Google Cloud SDK का इस्तेमाल करके, AlloyDB क्लस्टर और इंस्टेंस बनाने का तरीका यहां बताया गया है. अगर आपको कंसोल का इस्तेमाल करना है, तो यहां दिया गया दस्तावेज़ पढ़ें.
AlloyDB क्लस्टर बनाने से पहले, हमें अपने वीपीसी में उपलब्ध निजी आईपी पते की एक रेंज की ज़रूरत होती है. इसका इस्तेमाल आने वाले समय में AlloyDB इंस्टेंस के लिए किया जाएगा. अगर हमारे पास यह नहीं है, तो हमें इसे बनाना होगा. साथ ही, इसे Google की आंतरिक सेवाओं के लिए इस्तेमाल करने की अनुमति देनी होगी. इसके बाद, हम क्लस्टर और इंस्टेंस बना पाएंगे.
निजी आईपी रेंज बनाना
हमें AlloyDB के लिए, अपने वीपीसी में Private Service Access कॉन्फ़िगरेशन को कॉन्फ़िगर करना होगा. यहां यह मान लिया गया है कि प्रोजेक्ट में "डिफ़ॉल्ट" वीपीसी नेटवर्क है और इसका इस्तेमाल सभी कार्रवाइयों के लिए किया जाएगा.
निजी आईपी रेंज बनाएं:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
अलॉट की गई आईपी रेंज का इस्तेमाल करके, निजी कनेक्शन बनाएं:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
AlloyDB क्लस्टर बनाएं
इस सेक्शन में, हम us-central1 क्षेत्र में एक AlloyDB क्लस्टर बना रहे हैं.
postgres उपयोगकर्ता के लिए पासवर्ड तय करें. आपके पास अपना पासवर्ड तय करने या पासवर्ड जनरेट करने के लिए, रैंडम फ़ंक्शन का इस्तेमाल करने का विकल्प होता है
export PGPASSWORD=`openssl rand -hex 12`
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
PostgreSQL का पासवर्ड नोट करें, ताकि इसे बाद में इस्तेमाल किया जा सके.
echo $PGPASSWORD
postgres उपयोगकर्ता के तौर पर इंस्टेंस से कनेक्ट करने के लिए, आपको आने वाले समय में इस पासवर्ड की ज़रूरत होगी. हमारा सुझाव है कि आप इसे लिख लें या कहीं कॉपी कर लें, ताकि बाद में इसका इस्तेमाल किया जा सके.
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
मुफ़्त में आज़माने के लिए क्लस्टर बनाना
अगर आपने पहले कभी AlloyDB का इस्तेमाल नहीं किया है, तो बिना किसी शुल्क के आज़माने के लिए क्लस्टर बनाया जा सकता है:
रीजन और AlloyDB क्लस्टर का नाम तय करें. हम us-central1 क्षेत्र और alloydb-aip-01 को क्लस्टर के नाम के तौर पर इस्तेमाल करने जा रहे हैं:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
क्लस्टर बनाने के लिए, यह कमांड चलाएं:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
कंसोल का अनुमानित आउटपुट:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
उसी Cloud Shell सेशन में, हमारे क्लस्टर के लिए AlloyDB प्राइमरी इंस्टेंस बनाएं. अगर आपका कनेक्शन बंद हो जाता है, तो आपको क्षेत्र और क्लस्टर के नाम वाले एनवायरमेंट वैरिएबल फिर से तय करने होंगे.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
AlloyDB Standard क्लस्टर बनाना
अगर यह प्रोजेक्ट में आपका पहला AlloyDB क्लस्टर नहीं है, तो स्टैंडर्ड क्लस्टर बनाएं.
रीजन और AlloyDB क्लस्टर का नाम तय करें. हम us-central1 क्षेत्र और alloydb-aip-01 को क्लस्टर के नाम के तौर पर इस्तेमाल करने जा रहे हैं:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
क्लस्टर बनाने के लिए, यह कमांड चलाएं:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
कंसोल का अनुमानित आउटपुट:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
उसी Cloud Shell सेशन में, हमारे क्लस्टर के लिए AlloyDB प्राइमरी इंस्टेंस बनाएं. अगर आपका कनेक्शन बंद हो जाता है, तो आपको क्षेत्र और क्लस्टर के नाम वाले एनवायरमेंट वैरिएबल फिर से तय करने होंगे.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. डेटाबेस तैयार करना
हमें एक डेटाबेस बनाना होगा, Vertex AI इंटिग्रेशन चालू करना होगा, डेटाबेस ऑब्जेक्ट बनाने होंगे, और डेटा इंपोर्ट करना होगा.
AlloyDB को ज़रूरी अनुमतियां देना
AlloyDB के सेवा एजेंट को Vertex AI की अनुमतियां दें.
सबसे ऊपर मौजूद "+" साइन का इस्तेमाल करके, Cloud Shell का कोई दूसरा टैब खोलें.
नए क्लाउड शेल टैब में यह कमांड चलाएं:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
टैब में "exit" कमांड डालकर टैब बंद करें:
exit
AlloyDB Studio से कनेक्ट करना
यहां दिए गए अध्यायों में, डेटाबेस से कनेक्ट करने के लिए ज़रूरी सभी SQL कमांड को AlloyDB Studio में भी इस्तेमाल किया जा सकता है. कमांड चलाने के लिए, आपको प्राइमरी इंस्टेंस पर क्लिक करके, अपने AlloyDB क्लस्टर के लिए वेब कंसोल इंटरफ़ेस खोलना होगा.
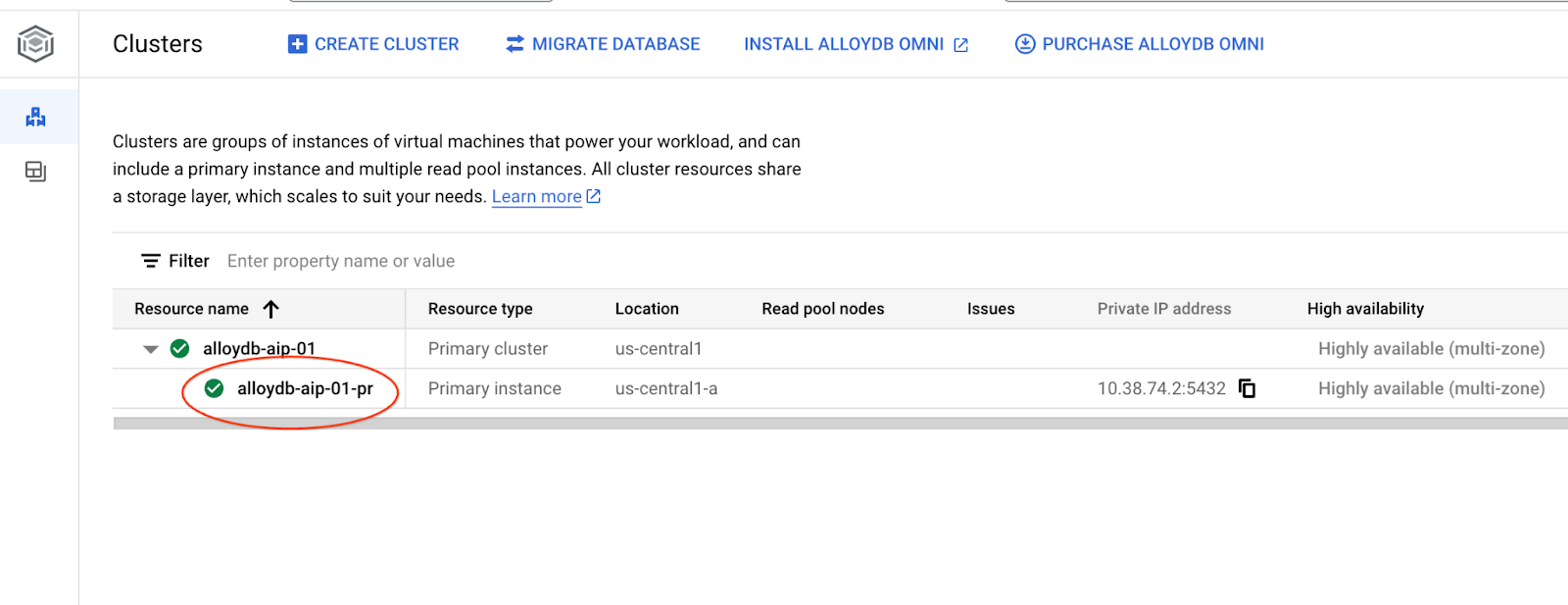
इसके बाद, बाईं ओर मौजूद AlloyDB Studio पर क्लिक करें:
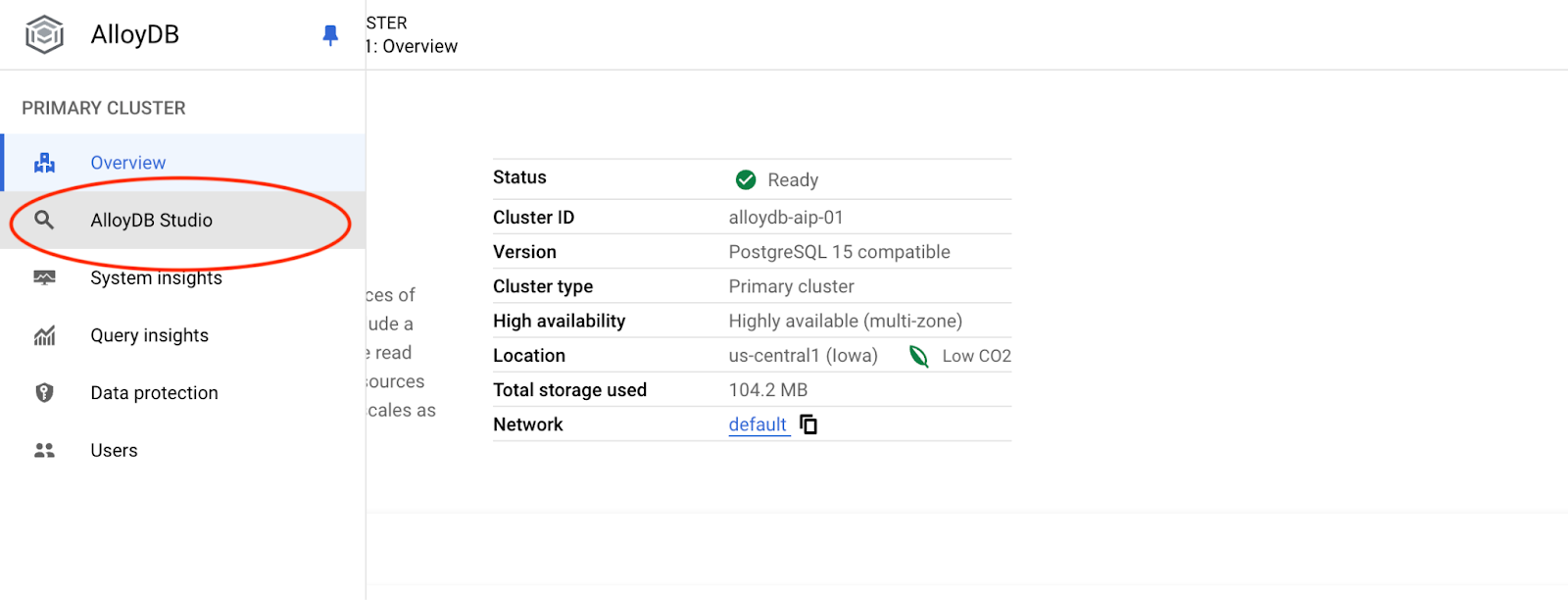
postgres डेटाबेस और postgres उपयोगकर्ता चुनें. साथ ही, क्लस्टर बनाते समय नोट किया गया पासवर्ड डालें. इसके बाद, "Authenticate" बटन पर क्लिक करें.
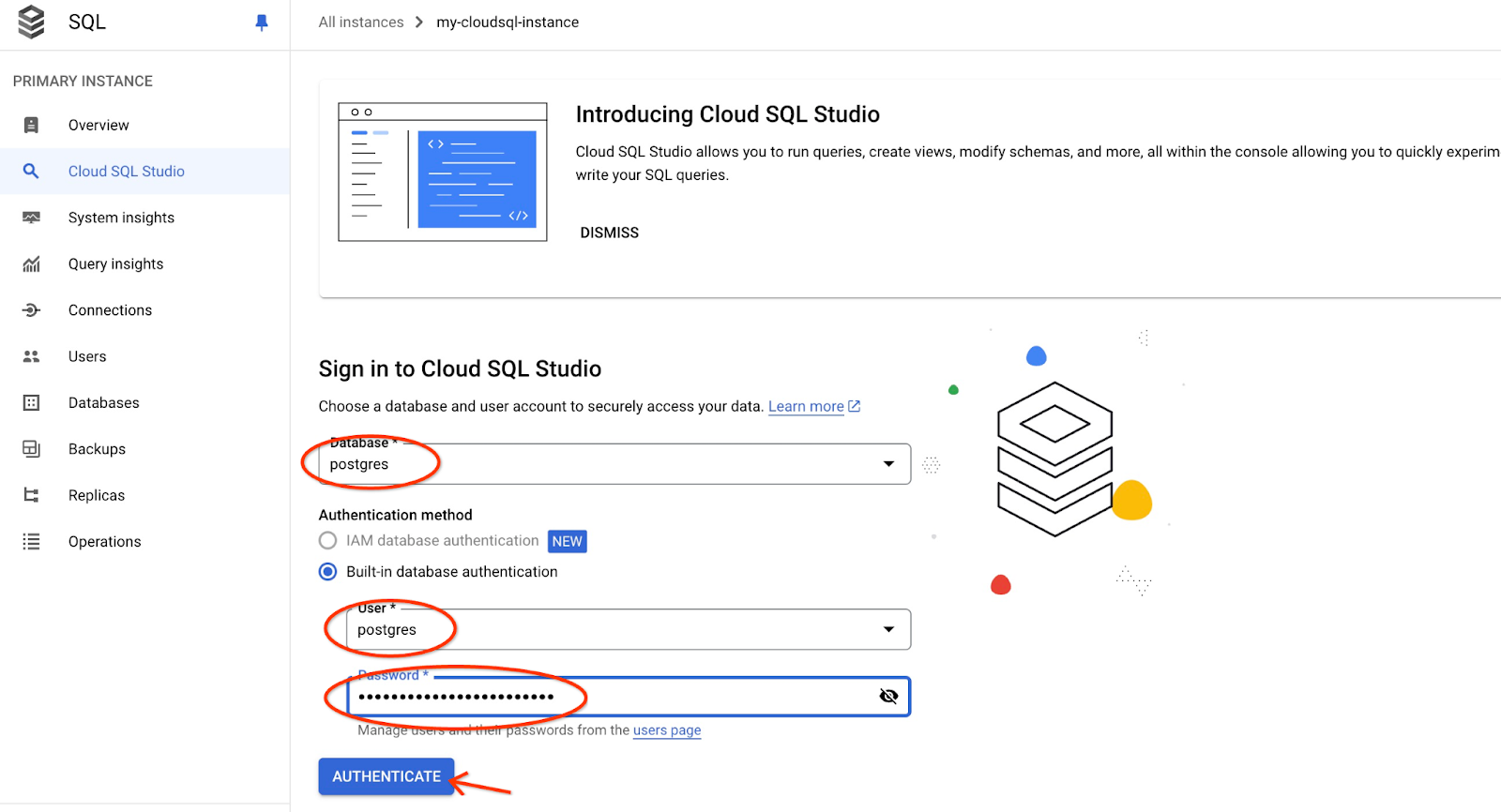
इससे AlloyDB Studio का इंटरफ़ेस खुल जाएगा. डेटाबेस में कमांड चलाने के लिए, दाईं ओर मौजूद "Editor 1" टैब पर क्लिक करें.
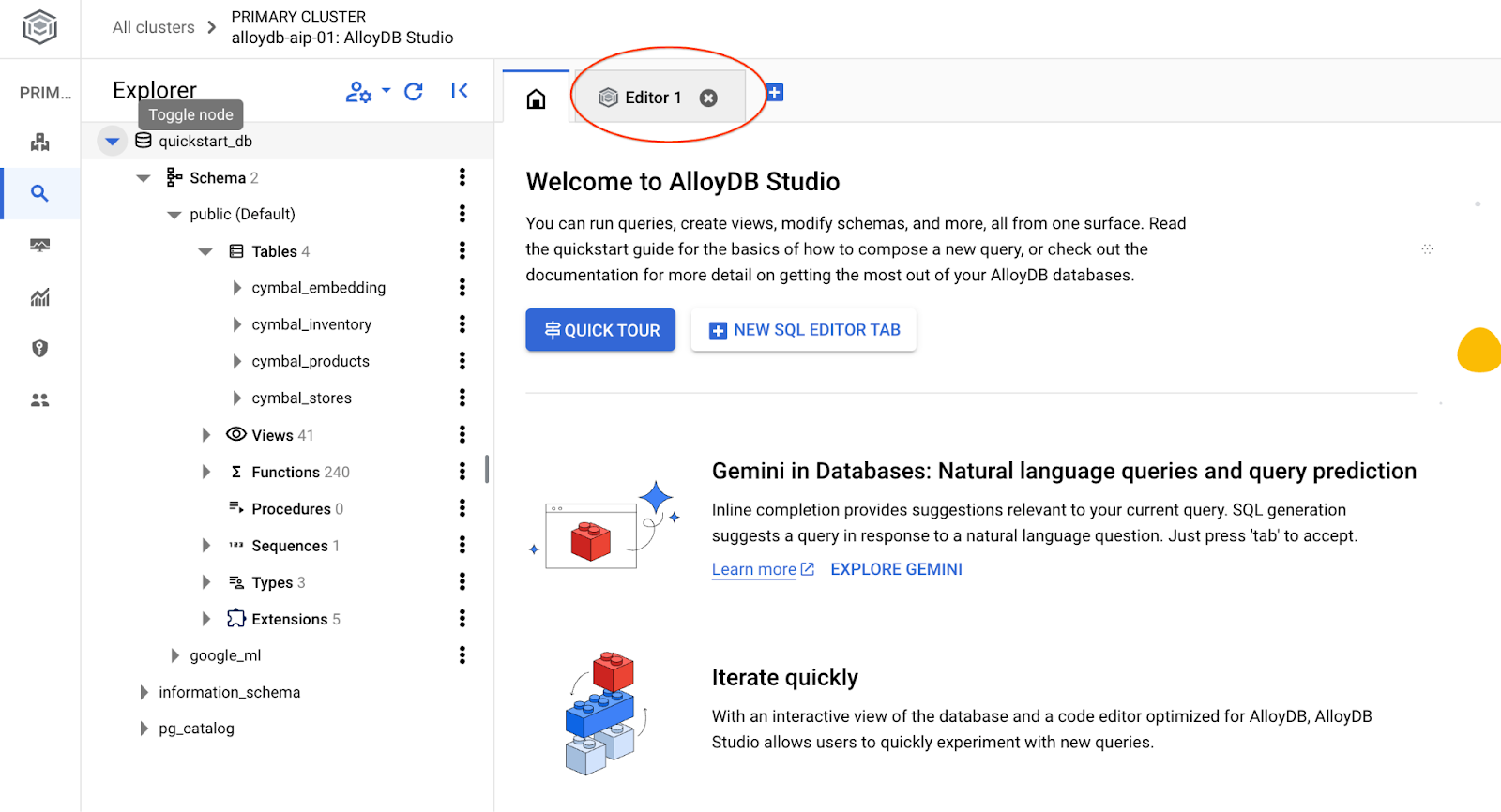
इससे एक इंटरफ़ेस खुलता है, जहां एसक्यूएल कमांड चलाई जा सकती हैं
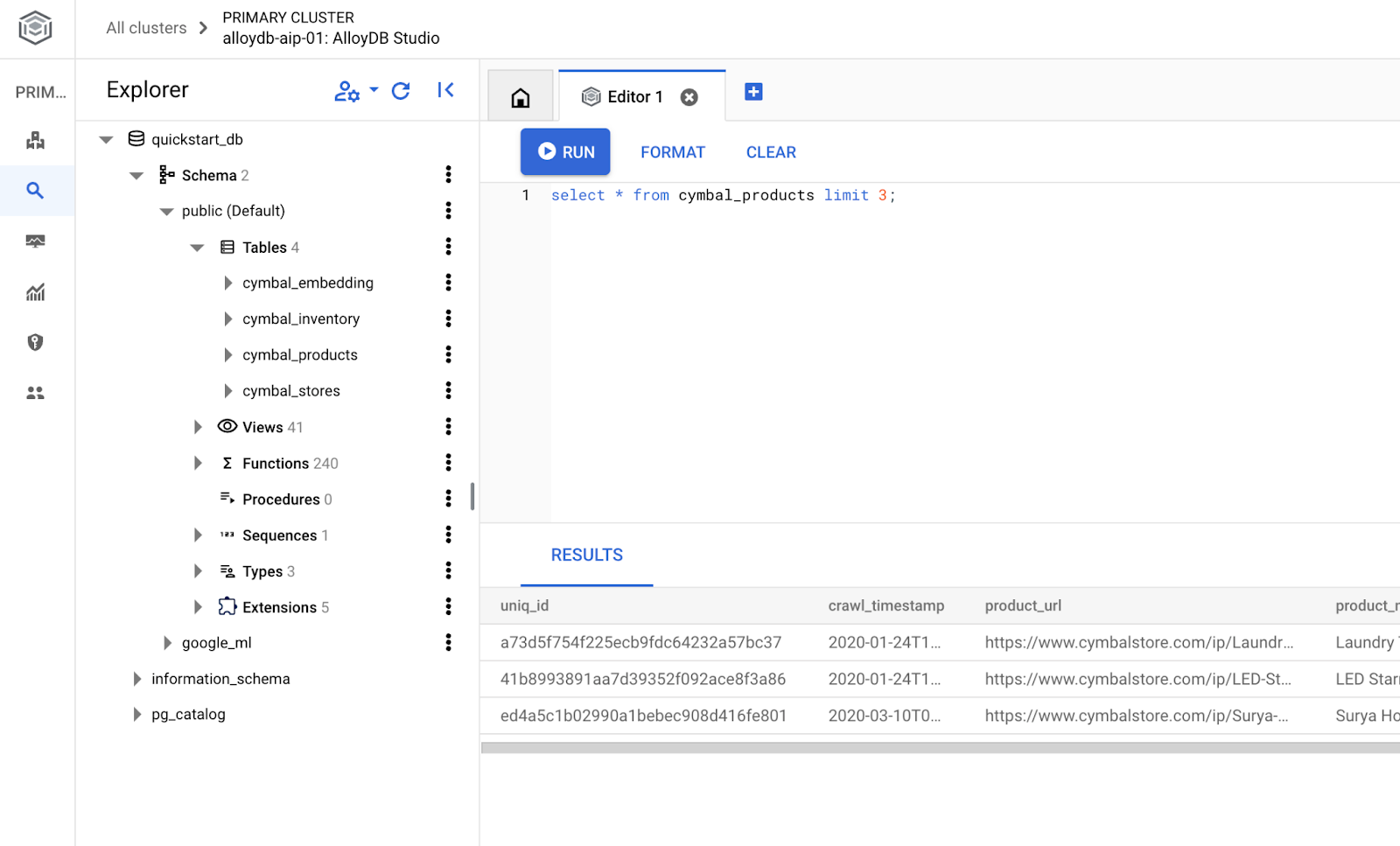
डेटाबेस बनाएं
डेटाबेस बनाने के बारे में क्विकस्टार्ट गाइड.
AlloyDB Studio Editor में, यह कमांड चलाएं.
डेटाबेस बनाएं:
CREATE DATABASE quickstart_db
अनुमानित आउटपुट:
Statement executed successfully
quickstart_db से कनेक्ट करें
उपयोगकर्ता/डेटाबेस बदलने के बटन का इस्तेमाल करके, स्टूडियो से फिर से कनेक्ट करें.
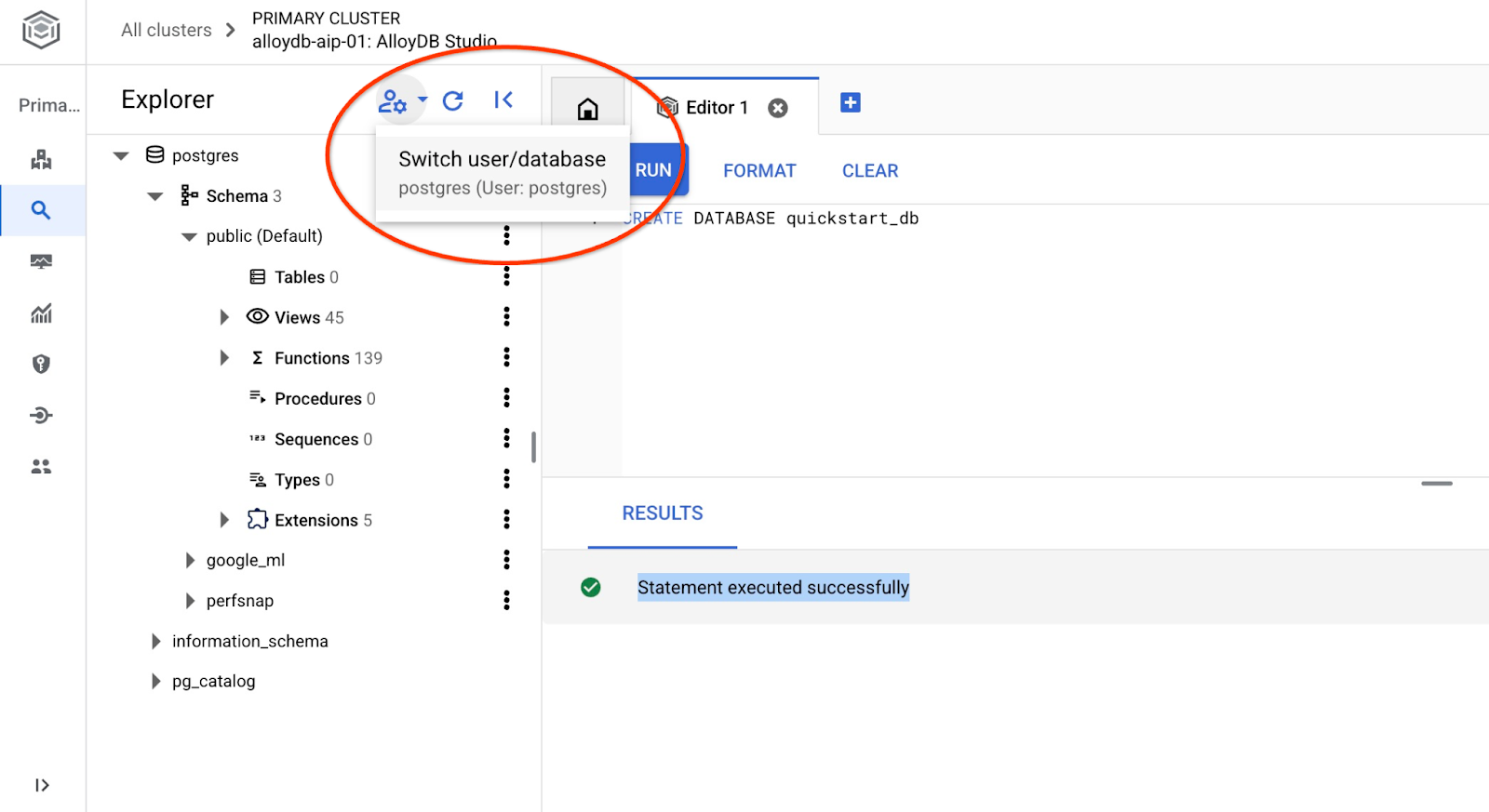
ड्रॉपडाउन सूची से नई quickstart_db डेटाबेस चुनें. साथ ही, पहले की तरह ही उपयोगकर्ता नाम और पासवर्ड का इस्तेमाल करें.
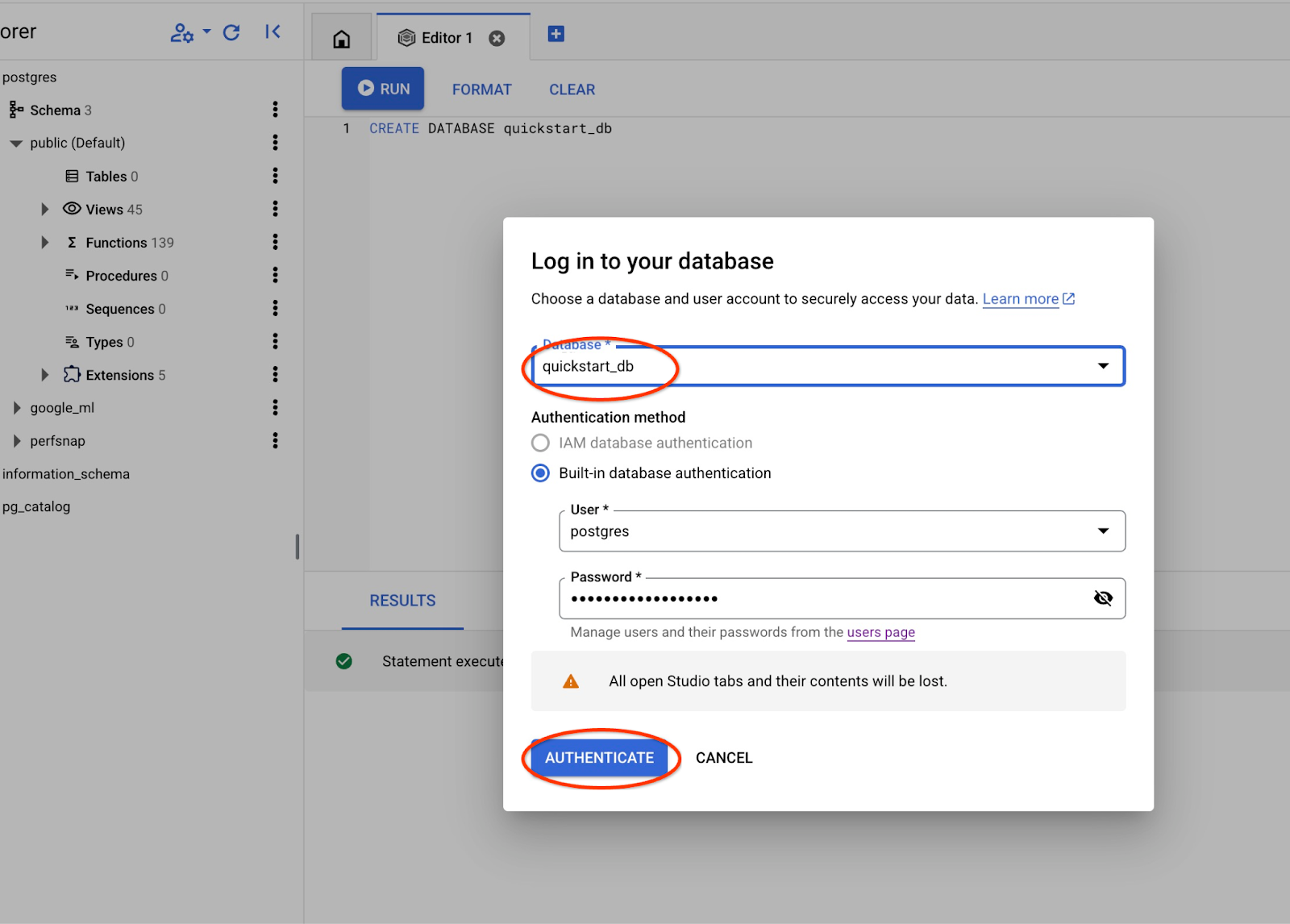
इससे एक नया कनेक्शन खुलेगा. यहां quickstart_db डेटाबेस के ऑब्जेक्ट के साथ काम किया जा सकता है.
6. सैंपल डेटा
अब हमें डेटाबेस में ऑब्जेक्ट बनाने और डेटा लोड करने की ज़रूरत है. हम "Cymbal ecomm" नाम के काल्पनिक स्टोर का इस्तेमाल करेंगे. इसमें ऑनलाइन स्टोर के लिए टेबल का एक सेट होगा. इसमें कई टेबल होती हैं, जो रिलेशनल डेटाबेस स्कीमा की तरह अपनी कुंजियों से जुड़ी होती हैं.
डेटासेट को एसक्यूएल फ़ाइल के तौर पर तैयार किया जाता है और इसे इंपोर्ट इंटरफ़ेस का इस्तेमाल करके डेटाबेस में लोड किया जा सकता है. Cloud Shell में ये कमांड चलाएं:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic.sql' --user=postgres --sql
यह कमांड, AlloyDB SDK का इस्तेमाल करती है. इससे एक ई-कॉमर्स स्कीमा बनता है. इसके बाद, यह GCS बकेट से सीधे डेटाबेस में सैंपल डेटा इंपोर्ट करती है. इससे सभी ज़रूरी ऑब्जेक्ट बनते हैं और डेटा डाला जाता है.
इंपोर्ट करने के बाद, हम AlloyDB Studio में टेबल देख सकते हैं
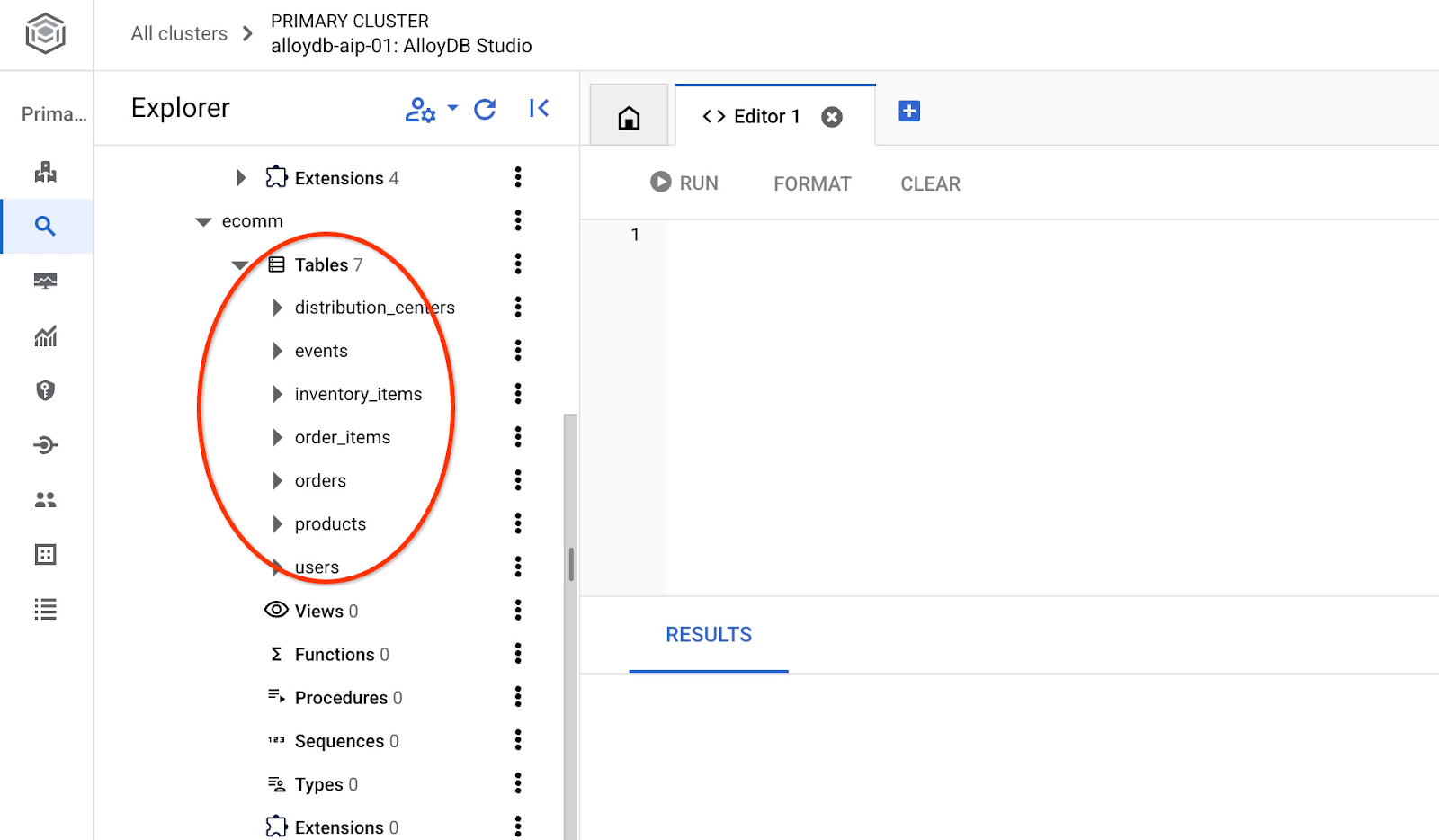
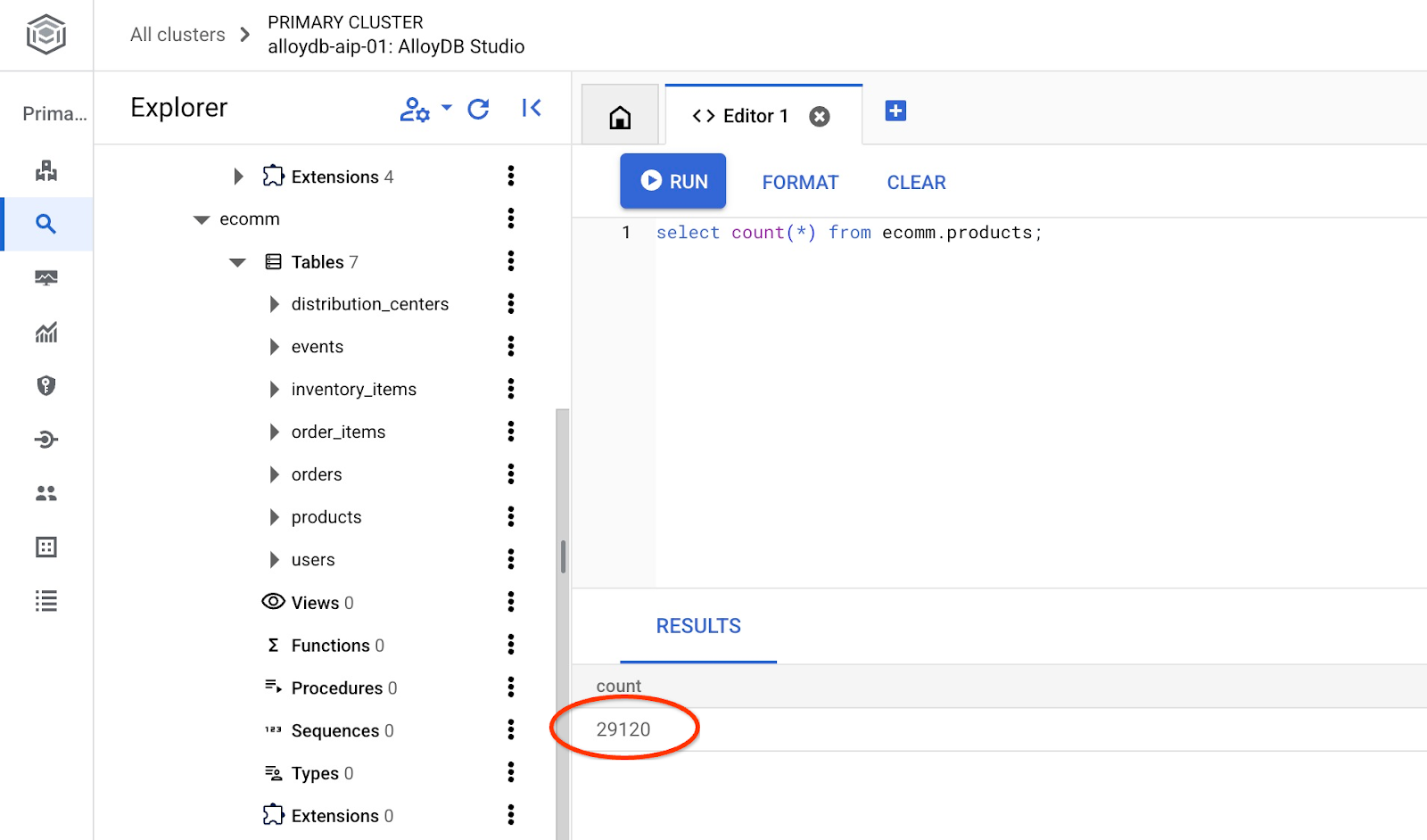
साथ ही, टेबल में मौजूद लाइनों की संख्या की पुष्टि करें.
7. नैचुरल लैंग्वेज में एसक्यूएल क्वेरी लिखने की सुविधा कॉन्फ़िगर करना
इस चैप्टर में, हम एनएल को आपके सैंपल स्कीमा के साथ काम करने के लिए कॉन्फ़िगर करेंगे
alloydb_nl_ai एक्सटेंशन इंस्टॉल करना
हमें अपने डेटाबेस में alloydb_ai_nl एक्सटेंशन इंस्टॉल करना होगा. ऐसा करने से पहले, हमें डेटाबेस फ़्लैग alloydb_ai_nl.enabled को चालू पर सेट करना होगा.
Cloud Shell सेशन में यह कमांड चलाएं
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb instances update $ADBCLUSTER-pr \
--cluster=$ADBCLUSTER \
--region=$REGION \
--database-flags=alloydb_ai_nl.enabled=on
इससे इंस्टेंस अपडेट करने की प्रोसेस शुरू हो जाएगी. वेब कंसोल में, अपडेट किए जा रहे इंस्टेंस का स्टेटस देखा जा सकता है:
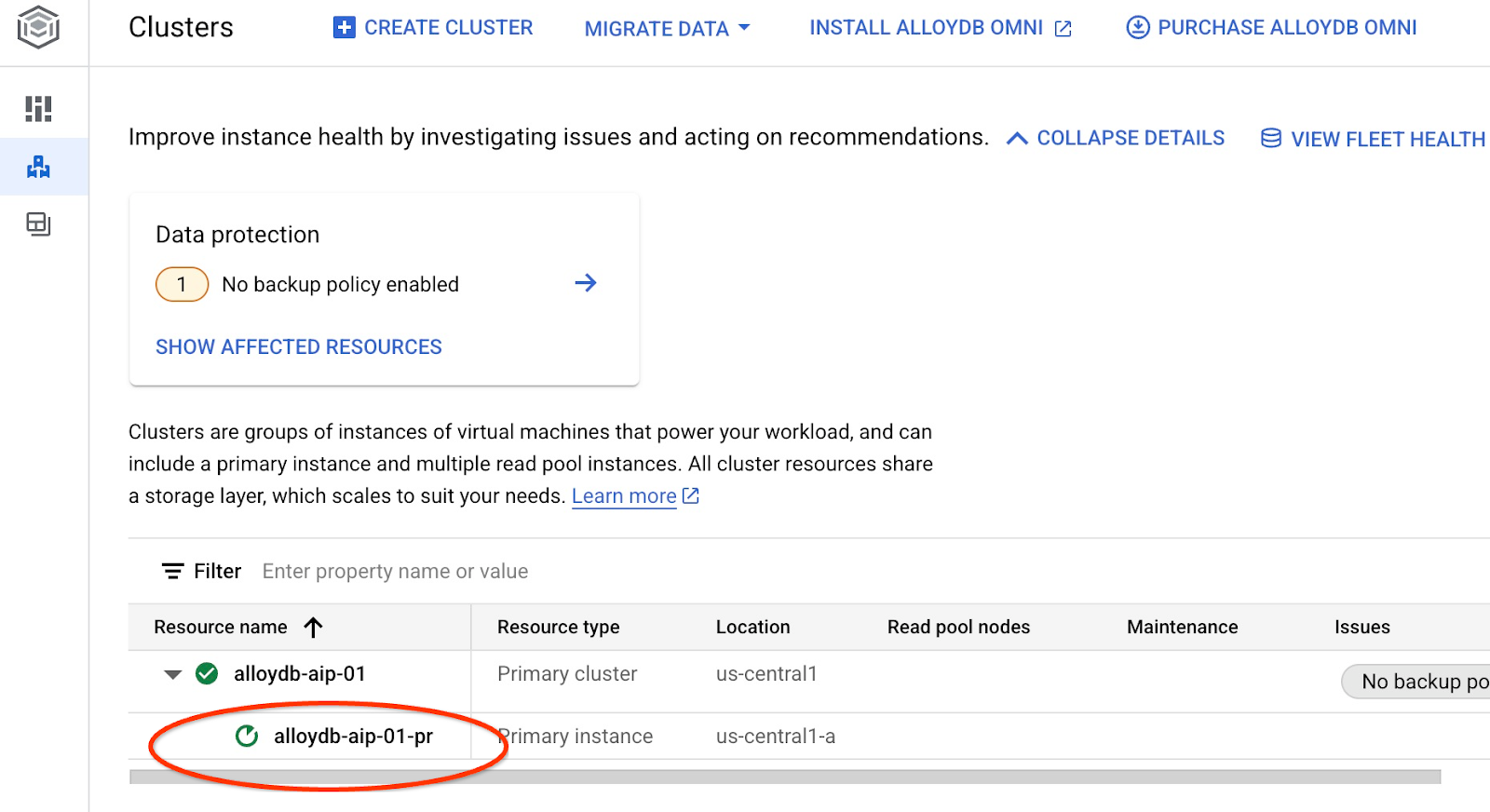
जब इंस्टेंस अपडेट हो जाए (इंस्टेंस का स्टेटस हरा हो), तब alloydb_ai_nl एक्सटेंशन चालू किया जा सकता है.
AlloyDB Studio में यह कमांड चलाएं
CREATE EXTENSION IF NOT EXISTS google_ml_integration;
CREATE EXTENSION alloydb_ai_nl cascade;
आसान भाषा में कॉन्फ़िगरेशन बनाना
एक्सटेंशन का इस्तेमाल करने के लिए, हमें कॉन्फ़िगरेशन बनाना होगा. ऐप्लिकेशन को कुछ स्कीमा, क्वेरी टेंप्लेट, और मॉडल एंडपॉइंट से जोड़ने के लिए, कॉन्फ़िगरेशन ज़रूरी है. चलिए, cymbal_ecomm_config आईडी वाला कॉन्फ़िगरेशन बनाते हैं.
AlloyDB Studio में यह कमांड चलाएं
SELECT
alloydb_ai_nl.g_create_configuration(
configuration_id => 'cymbal_ecomm_config'
);
अब हम कॉन्फ़िगरेशन में अपने ई-कॉमर्स स्कीमा को रजिस्टर कर सकते हैं. हमने ई-कॉमर्स स्कीमा में डेटा इंपोर्ट किया है. इसलिए, हम उस स्कीमा को अपने एनएल कॉन्फ़िगरेशन में जोड़ेंगे.
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'register_schema',
configuration_id_in => 'cymbal_ecomm_config',
schema_names_in => '{ecomm}'
);
8. एनएल एसक्यूएल में कॉन्टेक्स्ट जोड़ना
सामान्य जानकारी जोड़ना
हम रजिस्टर किए गए स्कीमा के लिए कुछ कॉन्टेक्स्ट जोड़ सकते हैं. कॉन्टेक्स्ट से, उपयोगकर्ताओं के अनुरोधों के जवाब में बेहतर नतीजे जनरेट करने में मदद मिलती है. उदाहरण के लिए, हम यह कह सकते हैं कि कोई ब्रैंड किसी उपयोगकर्ता का पसंदीदा ब्रैंड है, जबकि यह साफ़ तौर पर तय नहीं किया गया है. चलिए, Clades (काल्पनिक ब्रैंड) को अपना डिफ़ॉल्ट ब्रैंड बनाते हैं.
AlloyDB Studio में यह कमांड चलाएं:
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'add_general_context',
configuration_id_in => 'cymbal_ecomm_config',
general_context_in => '{"If the user doesn''t clearly define preferred brand then use Clades."}'
);
आइए, पुष्टि करें कि सामान्य कॉन्टेक्स्ट हमारे लिए कैसे काम करता है.
AlloyDB Studio में यह कमांड चलाएं:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
);
जनरेट की गई क्वेरी में, सामान्य कॉन्टेक्स्ट में पहले से तय किए गए हमारे डिफ़ॉल्ट ब्रैंड का इस्तेमाल किया जा रहा है:
{"sql": "SELECT count(*) FROM \"ecomm\".\"products\" WHERE \"brand\" = 'Clades'", "method": "default", "prompt": "", "retries": 0, "time(ms)": {"llm": 505.628000, "magic": 424.019000}, "error_msg": "", "nl_question": "How many products do we have of our preferred brand?", "toolbox_used": false}
हम इसे साफ़ कर सकते हैं और सिर्फ़ एसक्यूएल स्टेटमेंट को आउटपुट के तौर पर दिखा सकते हैं.
उदाहरण के लिए:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
आउटपुट मिटाया गया:
SELECT count(*) FROM "ecomm"."products" WHERE "brand" = 'Clades'
आपने देखा कि यह प्रॉडक्ट के बजाय inventory_items टेबल को अपने-आप चुन लेता है और इसका इस्तेमाल क्वेरी बनाने के लिए करता है. यह तरीका कुछ मामलों में काम कर सकता है, लेकिन हमारे स्कीमा के लिए नहीं. हमारे मामले में, inventory_items टेबल का इस्तेमाल बिक्री को ट्रैक करने के लिए किया जाता है. अगर आपके पास अंदरूनी जानकारी नहीं है, तो यह गुमराह करने वाली हो सकती है. हम बाद में देखेंगे कि अपनी क्वेरी को ज़्यादा सटीक कैसे बनाया जाए.
स्कीमा कॉन्टेक्स्ट
स्कीमा कॉन्टेक्स्ट, स्कीमा ऑब्जेक्ट के बारे में बताता है. जैसे, टेबल, व्यू, और अलग-अलग कॉलम. ये स्कीमा ऑब्जेक्ट में टिप्पणियों के तौर पर जानकारी सेव करते हैं.
हम इस क्वेरी का इस्तेमाल करके, कॉन्फ़िगरेशन में मौजूद सभी स्कीमा ऑब्जेक्ट के लिए इसे अपने-आप बना सकते हैं:
SELECT
alloydb_ai_nl.generate_schema_context(
nl_config_id => 'cymbal_ecomm_config',
overwrite_if_exist => TRUE
);
"TRUE" पैरामीटर, हमें कॉन्टेक्स्ट को फिर से जनरेट करने और उसे बदलने का निर्देश देता है. डेटा मॉडल के हिसाब से, क्वेरी को पूरा होने में कुछ समय लगेगा. आपके जितने ज़्यादा रिश्ते और कनेक्शन होंगे, उतना ही ज़्यादा समय लग सकता है.
संदर्भ बनाने के बाद, हम यह देख सकते हैं कि इसने इन्वेंट्री आइटम टेबल के लिए क्या बनाया है. इसके लिए, इस क्वेरी का इस्तेमाल करें:
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.inventory_items';
आउटपुट मिटाया गया:
The `ecomm.inventory_items` table stores information about individual inventory items in an e-commerce system. Each item is uniquely identified by an `id` (primary key). The table tracks the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn't been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men's and women's apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.
ऐसा लगता है कि ब्यौरे में कुछ अहम जानकारी मौजूद नहीं है. इन्वेंट्री आइटम टेबल में, आइटम की गतिविधि दिखती है. हम इस जानकारी को अपडेट कर सकते हैं. इसके लिए, हमें ecomm.inventory_items रिलेशन के कॉन्टेक्स्ट में यह अहम जानकारी जोड़नी होगी.
SELECT alloydb_ai_nl.update_generated_relation_context(
relation_name => 'ecomm.inventory_items',
relation_context => 'The `ecomm.inventory_items` table stores information about moving and sales of inventory items in an e-commerce system. Each movement is uniquely identified by an `id` (primary key) and used in order_items table as `inventory_item_id`. The table tracks sales and movements for the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the movement for the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn''t been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men''s and women''s apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.'
);
साथ ही, हम प्रॉडक्ट टेबल में मौजूद जानकारी के सटीक होने की पुष्टि कर सकते हैं.
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.products';
मुझे प्रॉडक्ट टेबल के लिए अपने-आप जनरेट हुआ कॉन्टेक्स्ट काफ़ी सटीक लगा. इसमें किसी भी तरह के बदलाव की ज़रूरत नहीं है.
मैंने दोनों टेबल में मौजूद हर कॉलम की जानकारी भी देखी है. यह भी सही है.
आइए, ecomm.inventory_items और ecomm.products के लिए जनरेट किए गए कॉन्टेक्स्ट को अपने कॉन्फ़िगरेशन पर लागू करें.
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.inventory_items',
overwrite_if_exist => TRUE
);
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.products',
overwrite_if_exist => TRUE
);
क्या आपको याद है कि हमने ‘हमारे पसंदीदा ब्रैंड के कितने प्रॉडक्ट उपलब्ध हैं?' सवाल के लिए एसक्यूएल जनरेट करने की क्वेरी की थी ? अब हम इसे दोहरा सकते हैं और देख सकते हैं कि क्या आउटपुट में बदलाव हुआ है.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
यहां नया आउटपुट दिया गया है.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
अब यह ecomm.products की जांच कर रहा है, जो ज़्यादा सटीक है. साथ ही, इन्वेंट्री आइटम के साथ 5,000 ऑपरेशन के बजाय, करीब 300 प्रॉडक्ट दिखाता है.
9. वैल्यू इंडेक्स के साथ काम करना
वैल्यू लिंकिंग की मदद से, नैचुरल लैंग्वेज क्वेरी को बेहतर बनाया जा सकता है. इसके लिए, वैल्यू फ़्रेज़ को पहले से रजिस्टर किए गए कॉन्सेप्ट टाइप और कॉलम के नामों से कनेक्ट किया जाता है. इससे नतीजों का अनुमान लगाना आसान हो जाता है.
वैल्यू इंडेक्स कॉन्फ़िगर करना
हम प्रॉडक्ट टेबल में ब्रैंड कॉलम का इस्तेमाल करके अपनी क्वेरी बना सकते हैं. साथ ही, कॉन्सेप्ट टाइप तय करके और उसे ecomm.products.brand कॉलम से जोड़कर, ज़्यादा स्टेबल ब्रैंड वाले प्रॉडक्ट खोज सकते हैं.
आइए, कॉन्सेप्ट बनाएं और उसे कॉलम से जोड़ें:
SELECT alloydb_ai_nl.add_concept_type(
concept_type_in => 'brand_name',
match_function_in => 'alloydb_ai_nl.get_concept_and_value_generic_entity_name',
additional_info_in => '{
"description": "Concept type for brand name.",
"examples": "SELECT alloydb_ai_nl.get_concept_and_value_generic_entity_name(''Auto Forge'')" }'::jsonb
);
SELECT alloydb_ai_nl.associate_concept_type(
column_names_in => 'ecomm.products.brand',
concept_type_in => 'brand_name',
nl_config_id_in => 'cymbal_ecomm_config'
);
alloydb_ai_nl.list_concept_types() को क्वेरी करके, इस कॉन्सेप्ट की पुष्टि की जा सकती है
SELECT alloydb_ai_nl.list_concept_types();
इसके बाद, हम बनाए गए और पहले से मौजूद सभी असोसिएशन के लिए, अपने कॉन्फ़िगरेशन में इंडेक्स बना सकते हैं:
SELECT alloydb_ai_nl.create_value_index(
nl_config_id_in => 'cymbal_ecomm_config'
);
वैल्यू इंडेक्स का इस्तेमाल करना
अगर ब्रैंड के नामों का इस्तेमाल करके एसक्यूएल बनाने के लिए कोई क्वेरी चलाई जाती है, लेकिन यह तय नहीं किया जाता कि यह ब्रैंड का नाम है, तो इससे इकाई और कॉलम की सही पहचान करने में मदद मिलती है. क्वेरी यहां दी गई है:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many Clades do we have?'
) ->> 'sql';
साथ ही, आउटपुट में ‘Clades' शब्द की पहचान ब्रैंड के नाम के तौर पर सही तरीके से की गई है
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
10. क्वेरी टेंप्लेट का इस्तेमाल करना
क्वेरी टेंप्लेट, कारोबार के लिए ज़रूरी ऐप्लिकेशन के लिए स्टेबल क्वेरी तय करने में मदद करते हैं. इससे अनिश्चितता कम होती है और सटीक नतीजे मिलते हैं.
क्वेरी टेंप्लेट बनाना
आइए, एक क्वेरी टेंप्लेट बनाते हैं. इसमें कई टेबल शामिल होंगी, ताकि हमें उन ग्राहकों के बारे में जानकारी मिल सके जिन्होंने पिछले साल "Republic Outpost" के प्रॉडक्ट खरीदे थे. हमें पता है कि क्वेरी में ecomm.products टेबल या ecomm.inventory_items टेबल का इस्तेमाल किया जा सकता है, क्योंकि दोनों में ब्रैंड के बारे में जानकारी होती है. हालांकि, products टेबल में 15 गुना कम लाइनें हैं और जॉइन के लिए प्राइमरी कुंजी पर इंडेक्स है. प्रॉडक्ट की टेबल का इस्तेमाल करना ज़्यादा फ़ायदेमंद हो सकता है. इसलिए, हम क्वेरी के लिए एक टेंप्लेट बना रहे हैं.
SELECT alloydb_ai_nl.add_template(
nl_config_id => 'cymbal_ecomm_config',
intent => 'List the last names and the country of all customers who bought products of `Republic Outpost` in the last year.',
sql => 'SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = ''Republic Outpost'' AND oi.created_at >= DATE_TRUNC(''year'', CURRENT_DATE - INTERVAL ''1 year'') AND oi.created_at < DATE_TRUNC(''year'', CURRENT_DATE)',
sql_explanation => 'To answer this question, JOIN `ecomm.users` with `ecom.order_items` on having the same `users.id` and `order_items.user_id`, and JOIN the result with ecom.products on having the same `order_items.product_id` and `products.id`. Then filter rows with products.brand = ''Republic Outpost'' and by `order_items.created_at` for the last year. Return the `last_name` and the `country` of the users with matching records.',
check_intent => TRUE
);
अब हम क्वेरी बनाने का अनुरोध कर सकते हैं.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
) ->> 'sql';
साथ ही, इससे मनमुताबिक आउटपुट मिलता है.
SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = 'Republic Outpost' AND oi.created_at >= DATE_TRUNC('year', CURRENT_DATE - INTERVAL '1 year') AND oi.created_at < DATE_TRUNC('year', CURRENT_DATE)
इसके अलावा, इस क्वेरी का इस्तेमाल करके सीधे क्वेरी को लागू किया जा सकता है:
SELECT
alloydb_ai_nl.execute_nl_query(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
);
यह JSON फ़ॉर्मैट में नतीजे देगा, जिन्हें पार्स किया जा सकता है.
execute_nl_query
--------------------------------------------------------
{"last_name":"Adams","country":"China"}
{"last_name":"Adams","country":"Germany"}
{"last_name":"Aguilar","country":"China"}
{"last_name":"Allen","country":"China"}
11. एनवायरमेंट को साफ़ करना
लैब का काम पूरा हो जाने के बाद, AlloyDB इंस्टेंस और क्लस्टर को मिटा दें.
AlloyDB क्लस्टर और सभी इंस्टेंस मिटाना
अगर आपने AlloyDB का मुफ़्त में आज़माने की सुविधा वाला वर्शन इस्तेमाल किया है. अगर आपको ट्रायल क्लस्टर का इस्तेमाल करके अन्य लैब और संसाधनों की जांच करनी है, तो ट्रायल क्लस्टर को न मिटाएं. आपके पास एक ही प्रोजेक्ट में दूसरा ट्रायल क्लस्टर बनाने का विकल्प नहीं होगा.
फ़ोर्स विकल्प के साथ क्लस्टर को डिस्ट्रॉय किया जाता है. इससे क्लस्टर से जुड़े सभी इंस्टेंस भी मिट जाते हैं.
अगर आपका कनेक्शन बंद हो गया है और पिछली सभी सेटिंग मिट गई हैं, तो क्लाउड शेल में प्रोजेक्ट और एनवायरमेंट वैरिएबल तय करें:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
क्लस्टर मिटाने के लिए:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB के बैकअप मिटाना
क्लस्टर के सभी AlloyDB बैकअप मिटाने के लिए:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
कंसोल का अनुमानित आउटपुट:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. बधाई हो
कोडलैब पूरा करने के लिए बधाई. अब AlloyDB की NL2SQL सुविधाओं का इस्तेमाल करके, अपने समाधान लागू किए जा सकते हैं. हमारा सुझाव है कि आप AlloyDB और AlloyDB AI से जुड़े अन्य कोडलैब आज़माएं. इस कोडलैब में जाकर, यह देखा जा सकता है कि AlloyDB में मल्टीमॉडल एम्बेडिंग कैसे काम करती हैं.
हमने क्या-क्या बताया
- AlloyDB for Postgres को डिप्लॉय करने का तरीका
- AlloyDB AI की सामान्य भाषा वाली सुविधा को चालू करने का तरीका
- एआई की नैचुरल लैंग्वेज के लिए कॉन्फ़िगरेशन बनाने और उसे ट्यून करने का तरीका
- आम भाषा का इस्तेमाल करके एसक्यूएल क्वेरी जनरेट करने और नतीजे पाने का तरीका
13. सर्वे
आउटपुट: