
1. Introduzione
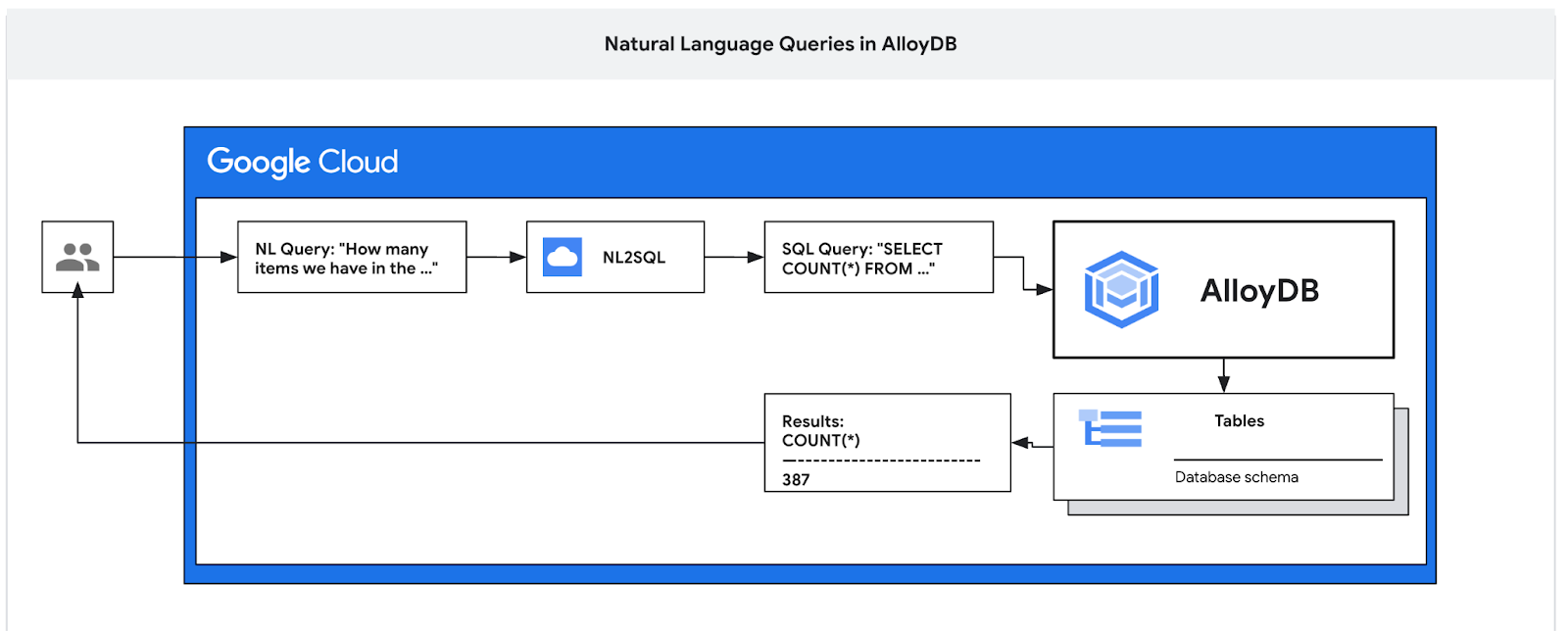
In questo codelab imparerai a eseguire il deployment di AlloyDB e a utilizzare il linguaggio naturale dell'AI per eseguire query sui dati e ottimizzare la configurazione per query prevedibili ed efficienti. Questo lab fa parte di una raccolta dedicata alle funzionalità di AI di AlloyDB. Per saperne di più, consulta la pagina di AlloyDB AI nella documentazione.
Prerequisiti
- Una conoscenza di base di Google Cloud e della console
- Competenze di base nell'interfaccia a riga di comando e in Cloud Shell
Cosa imparerai a fare
- Come eseguire il deployment di AlloyDB per PostgreSQL
- Come attivare il linguaggio naturale di AlloyDB AI
- Come creare e ottimizzare la configurazione per l'AI in linguaggio naturale
- Come generare query SQL e ottenere risultati utilizzando il linguaggio naturale
Che cosa ti serve
- Un account Google Cloud e un progetto Google Cloud
- Un browser web come Chrome che supporta la console Google Cloud e Cloud Shell
2. Configurazione e requisiti
Configurazione dell'ambiente autonomo
- Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.

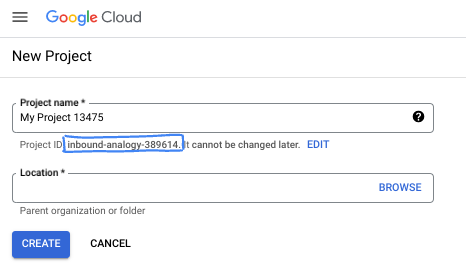
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi sempre aggiornarlo.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Cloud genera automaticamente una stringa univoca, di solito non ti interessa di cosa si tratta. Nella maggior parte dei codelab, dovrai fare riferimento all'ID progetto (in genere identificato come
PROJECT_ID). Se l'ID generato non ti piace, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e vedere se è disponibile. Non può essere modificato dopo questo passaggio e rimane per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
- Successivamente, devi abilitare la fatturazione in Cloud Console per utilizzare le risorse/API Cloud. Completare questo codelab non costa molto, se non nulla. Per arrestare le risorse ed evitare addebiti oltre a quelli previsti in questo tutorial, puoi eliminare le risorse che hai creato o il progetto. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Prima di iniziare
Abilita l'API
In Cloud Shell, assicurati che l'ID progetto sia configurato:
gcloud config set project [YOUR-PROJECT-ID]
Imposta la variabile di ambiente PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Attiva tutti i servizi necessari:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Output previsto:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Esegui il deployment di AlloyDB
Crea il cluster AlloyDB e l'istanza principale. La seguente procedura descrive come creare un cluster e un'istanza AlloyDB utilizzando Google Cloud SDK. Se preferisci l'approccio della console, puoi seguire la documentazione qui.
Prima di creare un cluster AlloyDB, abbiamo bisogno di un intervallo di IP privati disponibile nella nostra VPC da utilizzare per la futura istanza AlloyDB. Se non lo abbiamo, dobbiamo crearlo, assegnarlo per l'utilizzo da parte dei servizi Google interni e solo dopo potremo creare il cluster e l'istanza.
Crea intervallo IP privato
Dobbiamo configurare l'accesso privato ai servizi nel nostro VPC per AlloyDB. Il presupposto è che nel progetto sia presente la rete VPC "default" e che verrà utilizzata per tutte le azioni.
Crea l'intervallo IP privato:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Crea una connessione privata utilizzando l'intervallo IP allocato:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Output console previsto:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Crea cluster AlloyDB
In questa sezione creiamo un cluster AlloyDB nella regione us-central1.
Definisci la password per l'utente postgres. Puoi definire una password personalizzata o utilizzare una funzione casuale per generarla.
export PGPASSWORD=`openssl rand -hex 12`
Output console previsto:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Prendi nota della password PostgreSQL per utilizzarla in futuro.
echo $PGPASSWORD
Avrai bisogno di questa password in futuro per connetterti all'istanza come utente postgres. Ti consiglio di annotarlo o copiarlo da qualche parte per poterlo utilizzare in un secondo momento.
Output console previsto:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Creare un cluster di prova senza costi
Se non hai mai utilizzato AlloyDB, puoi creare un cluster di prova senza costi:
Definisci la regione e il nome del cluster AlloyDB. Utilizzeremo la regione us-central1 e alloydb-aip-01 come nome del cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Esegui il comando per creare il cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Output console previsto:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crea un'istanza principale AlloyDB per il nostro cluster nella stessa sessione della shell Cloud. Se la connessione viene interrotta, dovrai definire nuovamente le variabili di ambiente del nome della regione e del cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Output console previsto:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Crea un cluster AlloyDB Standard
Se non è il tuo primo cluster AlloyDB nel progetto, procedi con la creazione di un cluster standard.
Definisci la regione e il nome del cluster AlloyDB. Utilizzeremo la regione us-central1 e alloydb-aip-01 come nome del cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Esegui il comando per creare il cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Output console previsto:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crea un'istanza principale AlloyDB per il nostro cluster nella stessa sessione della shell Cloud. Se la connessione viene interrotta, dovrai definire nuovamente le variabili di ambiente del nome della regione e del cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Output console previsto:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Prepara il database
Dobbiamo creare un database, abilitare l'integrazione di Vertex AI, creare oggetti di database e importare i dati.
Concedere le autorizzazioni necessarie ad AlloyDB
Aggiungi le autorizzazioni Vertex AI al service agent AlloyDB.
Apri un'altra scheda di Cloud Shell utilizzando il segno "+" in alto.
Nella nuova scheda di Cloud Shell, esegui:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Chiudi la scheda con il comando di esecuzione "exit":
exit
Connettersi ad AlloyDB Studio
Nei capitoli seguenti, tutti i comandi SQL che richiedono la connessione al database possono essere eseguiti in alternativa in AlloyDB Studio. Per eseguire il comando, devi aprire l'interfaccia della console web per il cluster AlloyDB facendo clic sull'istanza principale.
Quindi, fai clic su AlloyDB Studio a sinistra:
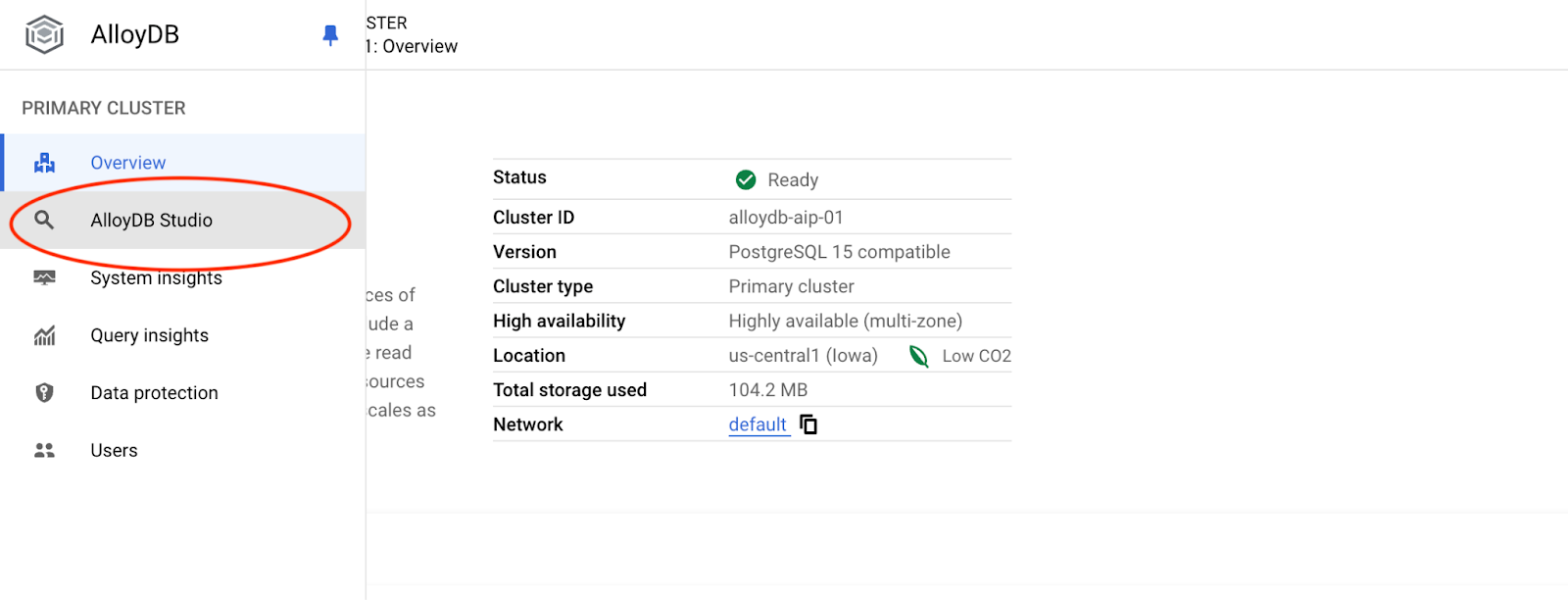
Scegli il database Postgres, l'utente Postgres e fornisci la password annotata quando abbiamo creato il cluster. A questo punto, fai clic sul pulsante "Autentica".
Si aprirà l'interfaccia di AlloyDB Studio. Per eseguire i comandi nel database, fai clic sulla scheda "Editor 1" a destra.
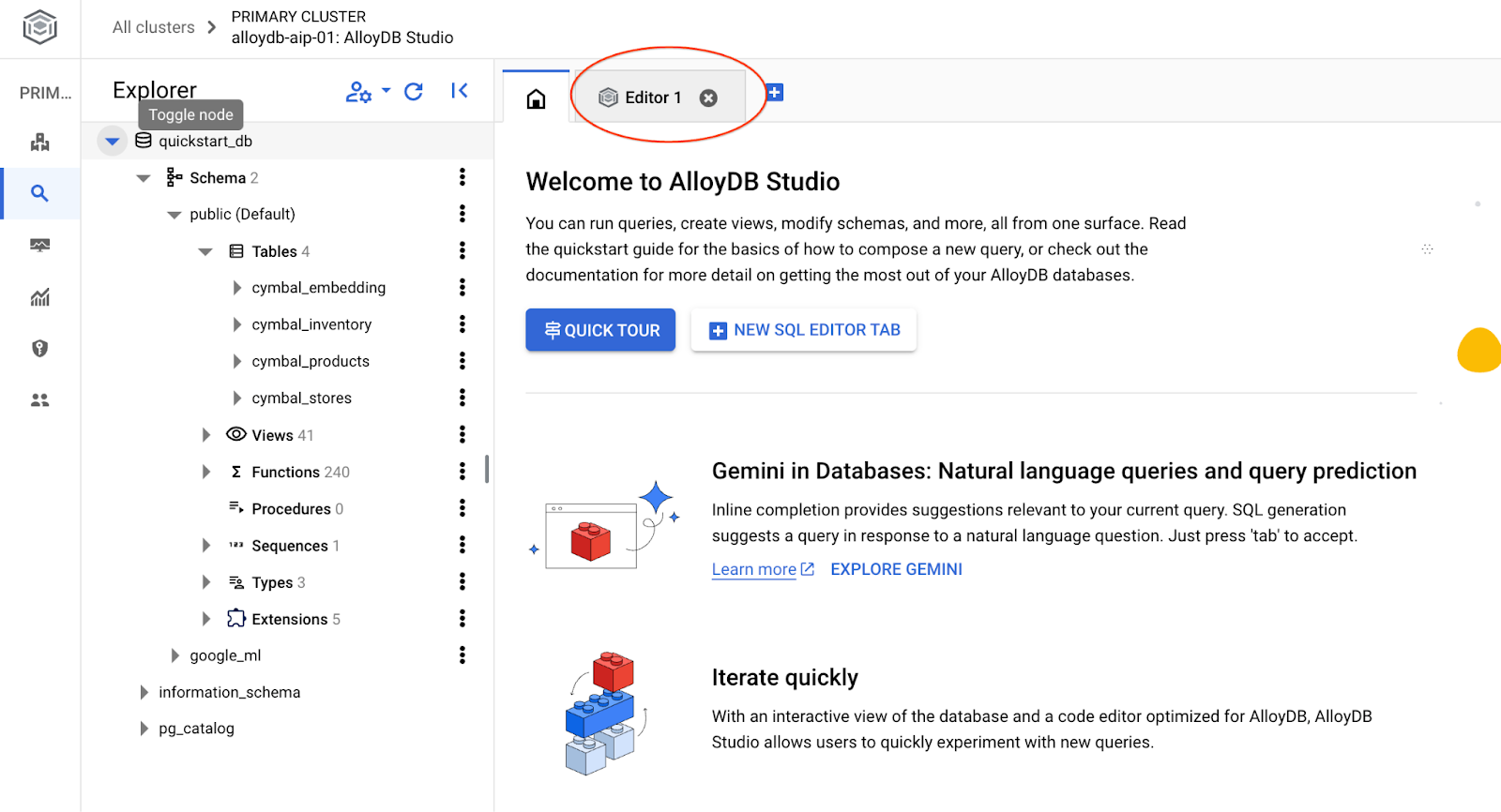
Si apre l'interfaccia in cui puoi eseguire i comandi SQL
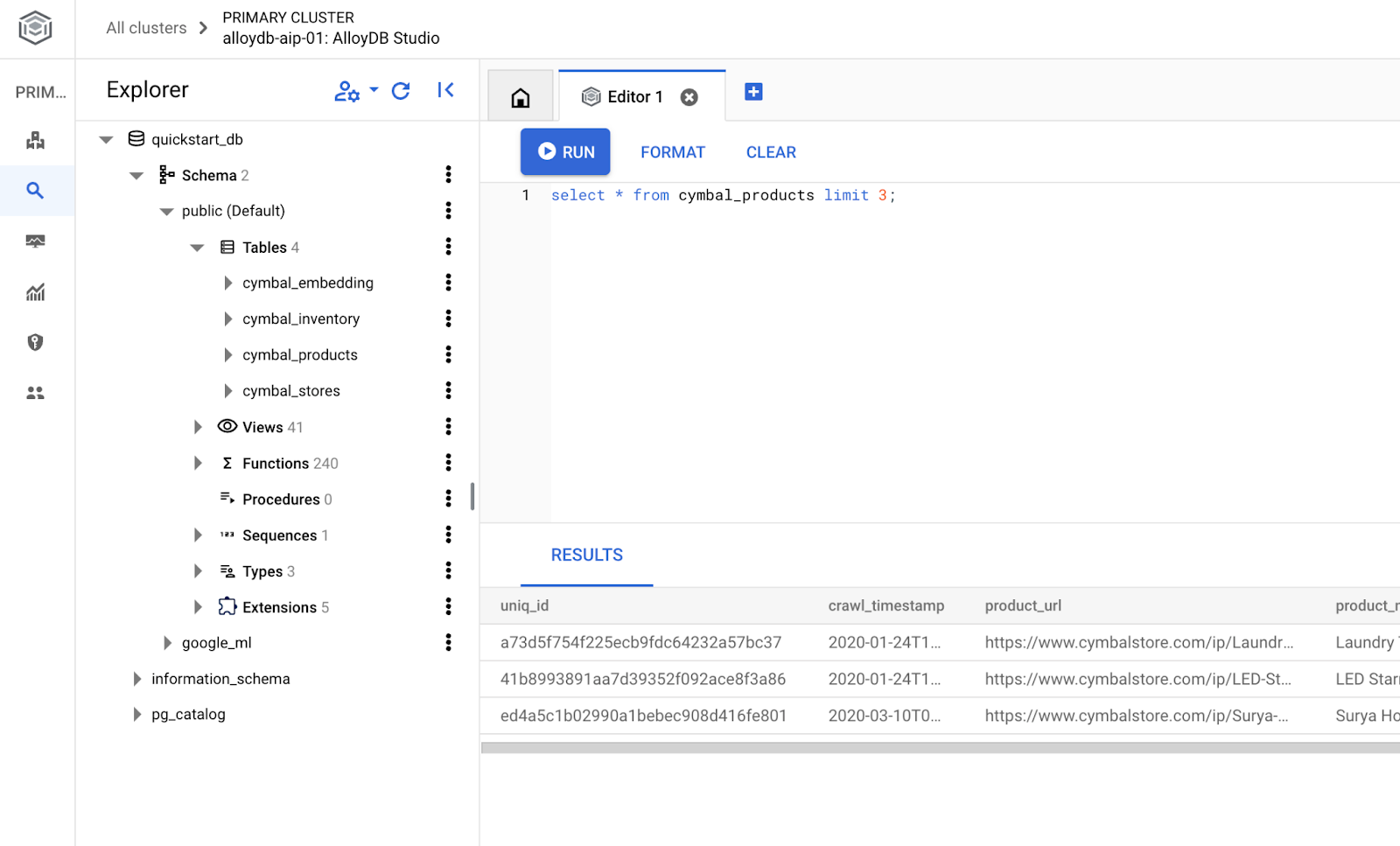
Crea database
Guida rapida alla creazione di un database.
Nell'editor di AlloyDB Studio, esegui questo comando.
Crea database:
CREATE DATABASE quickstart_db
Output previsto:
Statement executed successfully
Connettiti a quickstart_db
Riconnettiti allo studio utilizzando il pulsante per cambiare utente/database.
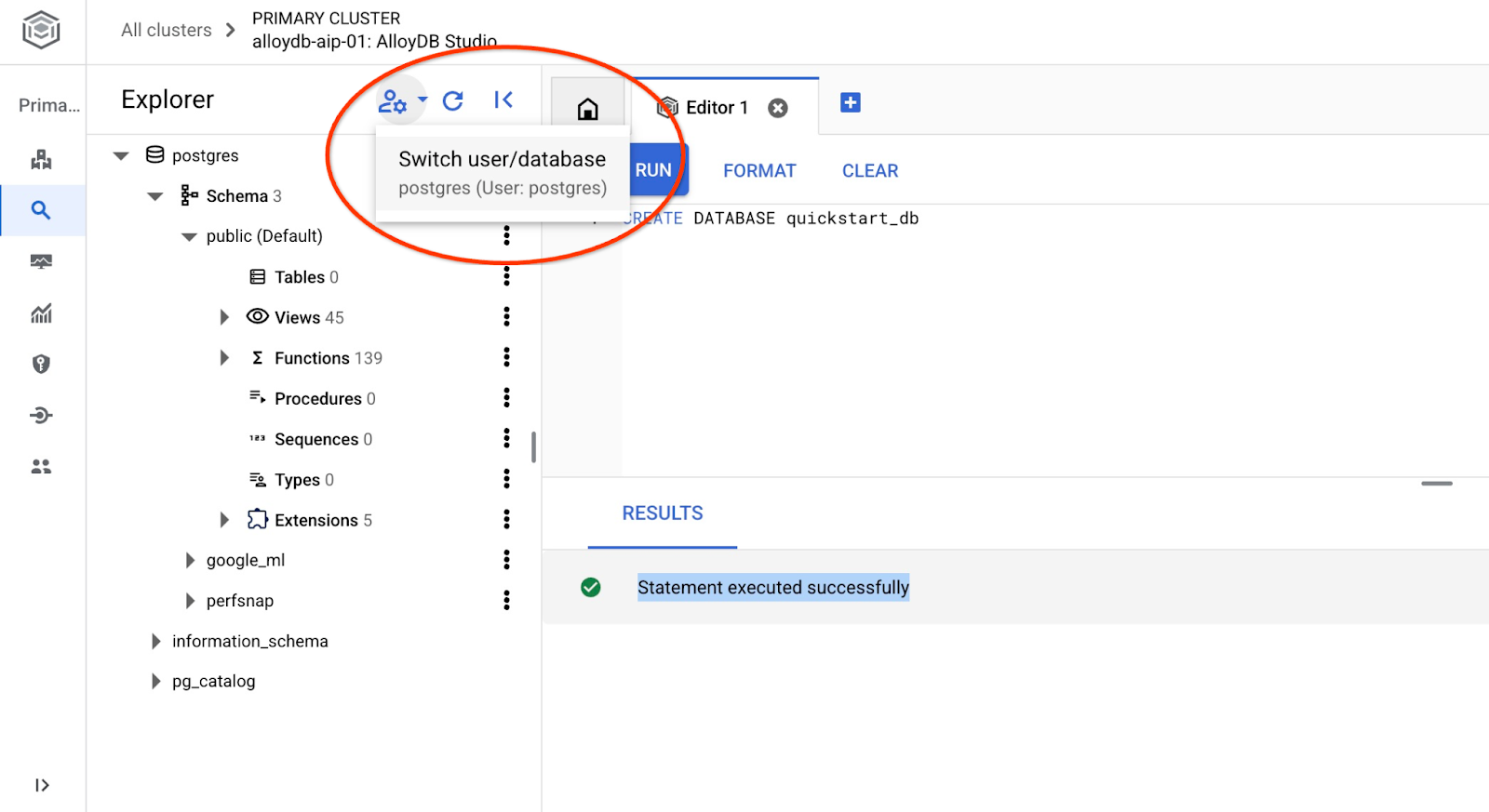
Seleziona il nuovo database quickstart_db dall'elenco a discesa e utilizza lo stesso utente e la stessa password di prima.
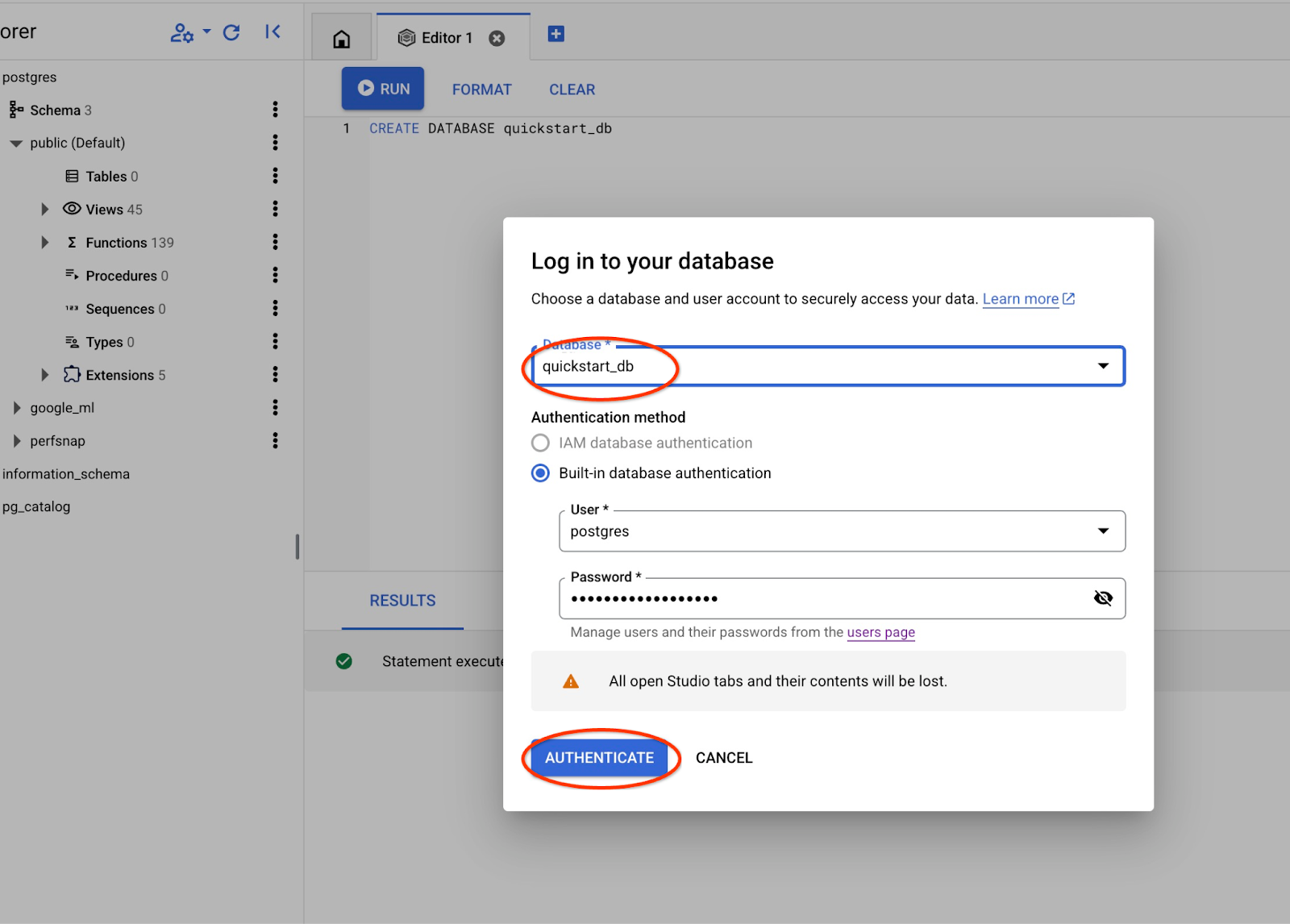
Si aprirà una nuova connessione in cui potrai lavorare con gli oggetti del database quickstart_db.
6. Dati di esempio
Ora dobbiamo creare oggetti nel database e caricare i dati. Utilizzeremo un negozio fittizio "Cymbal ecomm" con un insieme di tabelle per i negozi online. Contiene diverse tabelle collegate dalle chiavi che assomigliano a uno schema di database relazionale.
Il set di dati viene preparato e inserito come file SQL che può essere caricato nel database utilizzando l'interfaccia di importazione. In Cloud Shell, esegui questi comandi:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic.sql' --user=postgres --sql
Il comando utilizza l'SDK AlloyDB e crea uno schema ecomm, quindi importa i dati di esempio direttamente dal bucket GCS al database creando tutti gli oggetti necessari e inserendo i dati.
Dopo l'importazione, possiamo controllare le tabelle in AlloyDB Studio
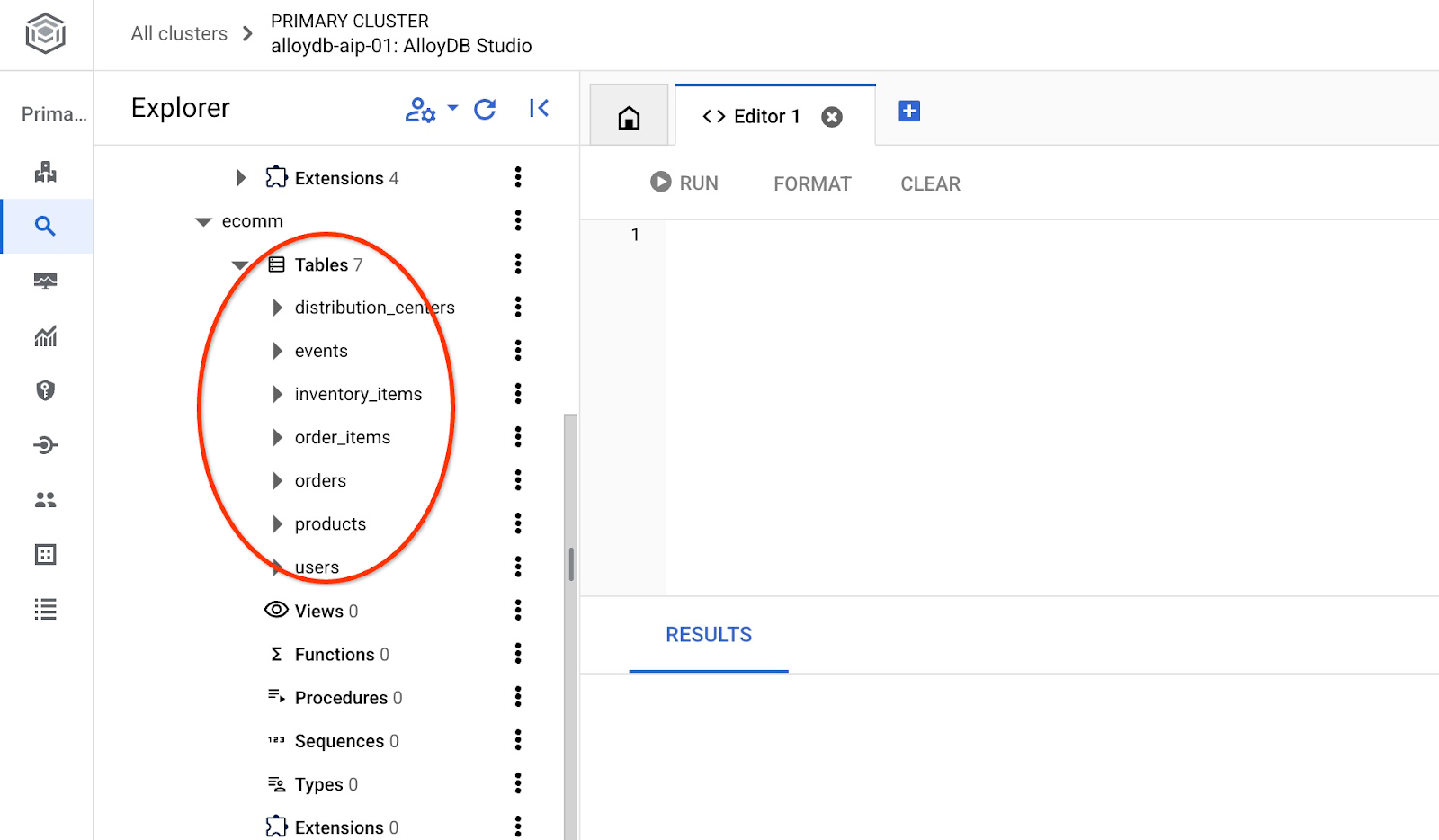
e verifica il numero di righe nella tabella.
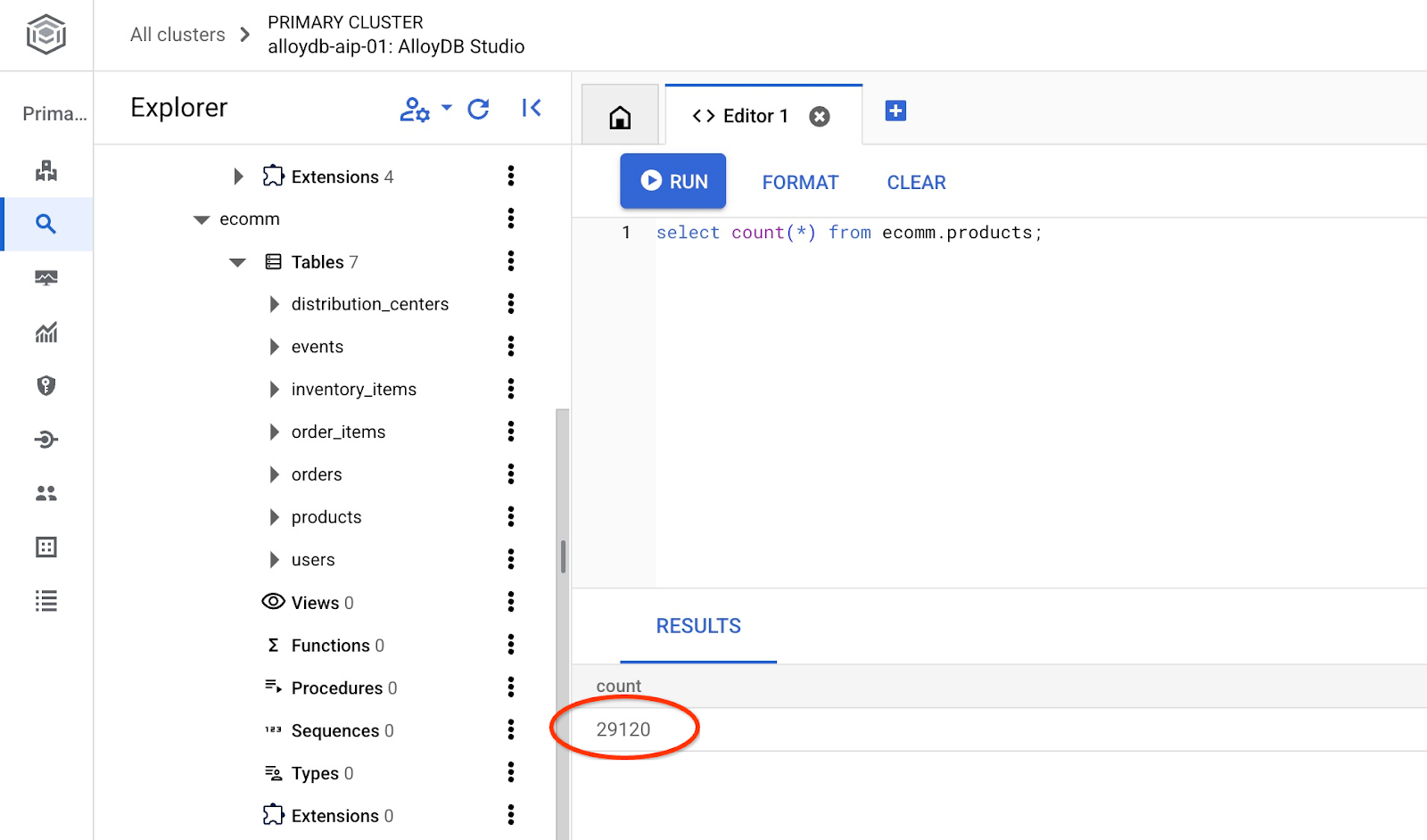
7. Configurare NL SQL
In questo capitolo configureremo NL in modo che funzioni con lo schema di esempio
Installare l'estensione alloydb_nl_ai
Dobbiamo installare l'estensione alloydb_ai_nl nel nostro database. Prima di farlo, dobbiamo impostare il flag di database alloydb_ai_nl.enabled su on.
Nella sessione di Cloud Shell esegui
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb instances update $ADBCLUSTER-pr \
--cluster=$ADBCLUSTER \
--region=$REGION \
--database-flags=alloydb_ai_nl.enabled=on
Verrà avviato l'aggiornamento dell'istanza. Puoi visualizzare lo stato dell'istanza di aggiornamento nella console web:
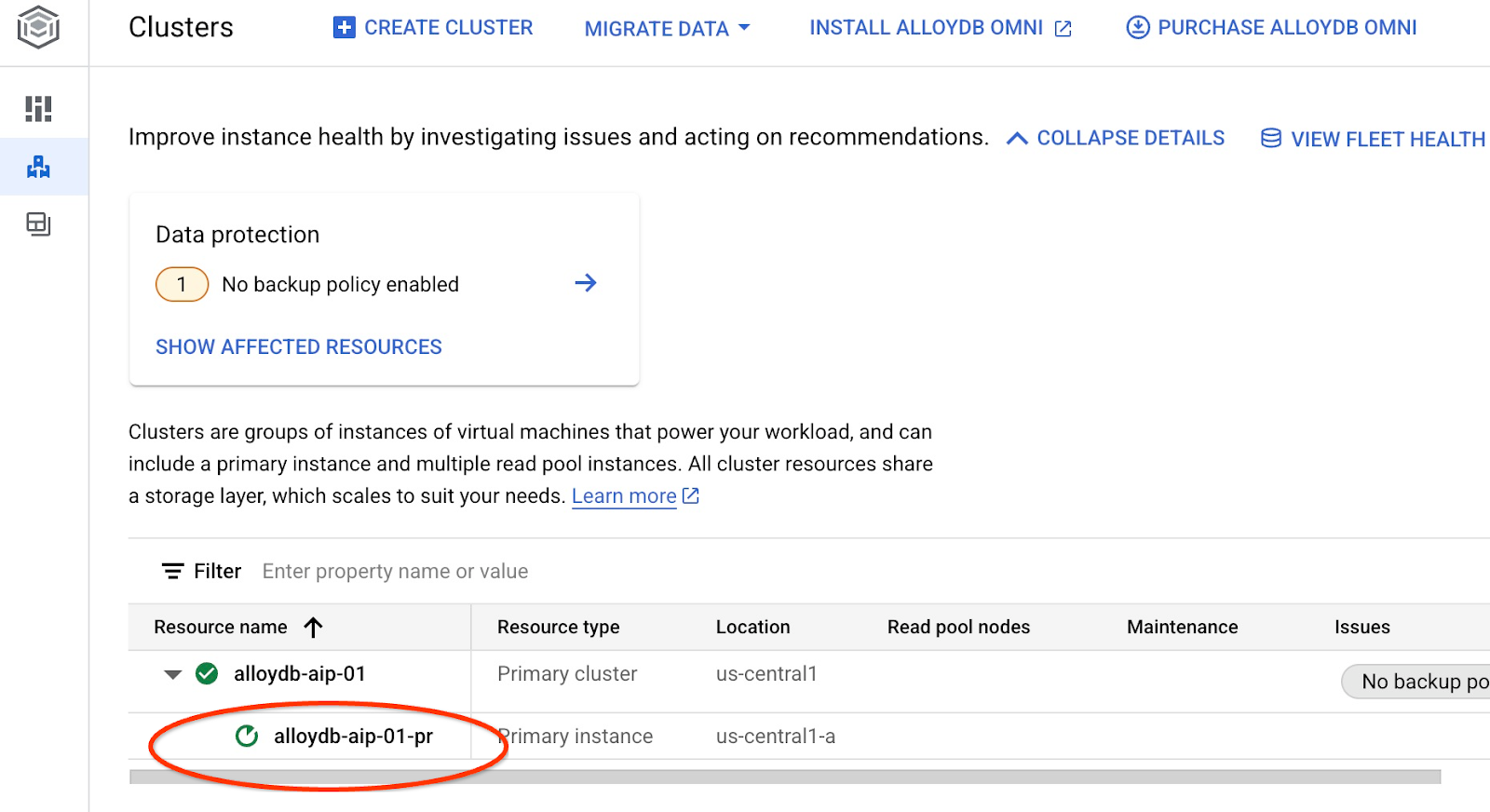
Quando l'istanza viene aggiornata (lo stato dell'istanza è verde), puoi attivare l'estensione alloydb_ai_nl.
In AlloyDB Studio esegui
CREATE EXTENSION IF NOT EXISTS google_ml_integration;
CREATE EXTENSION alloydb_ai_nl cascade;
Creare una configurazione in linguaggio naturale
Per utilizzare le estensioni, dobbiamo creare una configurazione. La configurazione è necessaria per associare le applicazioni a determinati schemi, modelli di query ed endpoint del modello. Creiamo una configurazione con ID cymbal_ecomm_config.
In AlloyDB Studio esegui
SELECT
alloydb_ai_nl.g_create_configuration(
configuration_id => 'cymbal_ecomm_config'
);
Ora possiamo registrare il nostro schema ecomm nella configurazione. Abbiamo importato i dati nello schema ecomm, quindi aggiungeremo questo schema alla nostra configurazione NL.
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'register_schema',
configuration_id_in => 'cymbal_ecomm_config',
schema_names_in => '{ecomm}'
);
8. Aggiungere contesto a NL SQL
Aggiungere un contesto generale
Possiamo aggiungere un po' di contesto per il nostro schema registrato. Il contesto dovrebbe contribuire a generare risultati migliori in risposta alle richieste degli utenti. Ad esempio, possiamo affermare che un brand è il brand preferito di un utente quando non è definito in modo esplicito. Impostiamo Clades (brand fittizio) come brand predefinito.
In AlloyDB Studio esegui:
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'add_general_context',
configuration_id_in => 'cymbal_ecomm_config',
general_context_in => '{"If the user doesn''t clearly define preferred brand then use Clades."}'
);
Verifichiamo come funziona il contesto generale.
In AlloyDB Studio esegui:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
);
La query generata utilizza il nostro brand predefinito definito in precedenza nel contesto generale:
{"sql": "SELECT count(*) FROM \"ecomm\".\"products\" WHERE \"brand\" = 'Clades'", "method": "default", "prompt": "", "retries": 0, "time(ms)": {"llm": 505.628000, "magic": 424.019000}, "error_msg": "", "nl_question": "How many products do we have of our preferred brand?", "toolbox_used": false}
Possiamo ripulirlo e produrre solo l'istruzione SQL come output.
Ad esempio:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Output cancellato:
SELECT count(*) FROM "ecomm"."products" WHERE "brand" = 'Clades'
Hai notato che ha scelto automaticamente la tabella inventory_items anziché products e l'ha utilizzata per creare la query. Potrebbe funzionare per alcuni casi, ma non per il nostro schema. Nel nostro caso, la tabella inventory_items serve a monitorare le vendite, il che può essere fuorviante se non disponi di informazioni privilegiate. Vedremo più avanti come rendere più precise le nostre query.
Contesto dello schema
Il contesto dello schema descrive gli oggetti dello schema come tabelle, viste e singole colonne che memorizzano le informazioni come commenti negli oggetti dello schema.
Possiamo crearlo automaticamente per tutti gli oggetti schema nella nostra configurazione definita utilizzando la seguente query:
SELECT
alloydb_ai_nl.generate_schema_context(
nl_config_id => 'cymbal_ecomm_config',
overwrite_if_exist => TRUE
);
Il parametro "TRUE" ci indica di rigenerare il contesto e sovrascriverlo. L'esecuzione richiederà del tempo a seconda del modello di dati. Più relazioni e connessioni hai, più tempo potrebbe essere necessario.
Dopo aver creato il contesto, possiamo controllare cosa è stato creato per la tabella degli articoli di inventario utilizzando la query:
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.inventory_items';
Output cancellato:
The `ecomm.inventory_items` table stores information about individual inventory items in an e-commerce system. Each item is uniquely identified by an `id` (primary key). The table tracks the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn't been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men's and women's apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.
Sembra che nella descrizione manchino alcune parti chiave che la tabella inventory_items riflette il movimento degli articoli. Possiamo aggiornarlo aggiungendo queste informazioni chiave al contesto della relazione ecomm.inventory_items.
SELECT alloydb_ai_nl.update_generated_relation_context(
relation_name => 'ecomm.inventory_items',
relation_context => 'The `ecomm.inventory_items` table stores information about moving and sales of inventory items in an e-commerce system. Each movement is uniquely identified by an `id` (primary key) and used in order_items table as `inventory_item_id`. The table tracks sales and movements for the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the movement for the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn''t been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men''s and women''s apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.'
);
Inoltre, possiamo verificare l'accuratezza della descrizione per la nostra tabella dei prodotti.
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.products';
Ho trovato il contesto generato automaticamente per la tabella dei prodotti piuttosto preciso e non ho dovuto apportare modifiche.
Ho controllato anche le informazioni su ogni colonna di entrambe le tabelle e ho riscontrato che sono corrette.
Applichiamo il contesto generato per ecomm.inventory_items ed ecomm.products alla nostra configurazione.
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.inventory_items',
overwrite_if_exist => TRUE
);
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.products',
overwrite_if_exist => TRUE
);
Ricordi la nostra query per generare SQL per la domanda "Quanti prodotti abbiamo del nostro brand preferito?" ? Ora possiamo ripetere l'operazione e vedere se l'output è cambiato.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Ecco il nuovo output.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
Ora controlla ecomm.products, che è più preciso e restituisce circa 300 prodotti anziché 5000 operazioni con articoli di inventario.
9. Utilizzo dell'indice di valore
Il collegamento dei valori arricchisce le query in linguaggio naturale collegando le frasi di valore a tipi di concetti e nomi di colonne preregistrati. Può contribuire a rendere i risultati più prevedibili.
Configurare l'indice dei valori
Possiamo creare le nostre query utilizzando la colonna del brand nella tabella dei prodotti e cercare prodotti con brand più stabili definendo il tipo di concetto e associandolo alla colonna ecomm.products.brand.
Creiamo il concetto e associamolo alla colonna:
SELECT alloydb_ai_nl.add_concept_type(
concept_type_in => 'brand_name',
match_function_in => 'alloydb_ai_nl.get_concept_and_value_generic_entity_name',
additional_info_in => '{
"description": "Concept type for brand name.",
"examples": "SELECT alloydb_ai_nl.get_concept_and_value_generic_entity_name(''Auto Forge'')" }'::jsonb
);
SELECT alloydb_ai_nl.associate_concept_type(
column_names_in => 'ecomm.products.brand',
concept_type_in => 'brand_name',
nl_config_id_in => 'cymbal_ecomm_config'
);
Puoi verificare il concetto eseguendo una query su alloydb_ai_nl.list_concept_types()
SELECT alloydb_ai_nl.list_concept_types();
Poi possiamo creare l'indice nella nostra configurazione per tutte le associazioni create e predefinite:
SELECT alloydb_ai_nl.create_value_index(
nl_config_id_in => 'cymbal_ecomm_config'
);
Utilizzare l'indice di valore
Se esegui una query per creare un SQL utilizzando i nomi dei brand, ma non definisci che si tratta di un nome di brand, è più facile identificare correttamente l'entità e la colonna. Ecco la query:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many Clades do we have?'
) ->> 'sql';
e l'output mostra l'identificazione corretta della parola "Clades" come nome del brand.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
10. Utilizzo dei modelli di query
I modelli di query aiutano a definire query stabili per le applicazioni business critical, riducendo l'incertezza e migliorando l'accuratezza.
Creare un modello di query
Creiamo un modello di query che unisce diverse tabelle per ottenere informazioni sui clienti che hanno acquistato prodotti "Republic Outpost " l'anno scorso. Sappiamo che la query può utilizzare la tabella ecomm.products o la tabella ecomm.inventory_items, poiché entrambe contengono informazioni sui brand. Tuttavia, la tabella products ha 15 volte meno righe e un indice sulla chiave primaria per il join. Potrebbe essere più efficiente utilizzare la tabella dei prodotti. Quindi, stiamo creando un modello per la query.
SELECT alloydb_ai_nl.add_template(
nl_config_id => 'cymbal_ecomm_config',
intent => 'List the last names and the country of all customers who bought products of `Republic Outpost` in the last year.',
sql => 'SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = ''Republic Outpost'' AND oi.created_at >= DATE_TRUNC(''year'', CURRENT_DATE - INTERVAL ''1 year'') AND oi.created_at < DATE_TRUNC(''year'', CURRENT_DATE)',
sql_explanation => 'To answer this question, JOIN `ecomm.users` with `ecom.order_items` on having the same `users.id` and `order_items.user_id`, and JOIN the result with ecom.products on having the same `order_items.product_id` and `products.id`. Then filter rows with products.brand = ''Republic Outpost'' and by `order_items.created_at` for the last year. Return the `last_name` and the `country` of the users with matching records.',
check_intent => TRUE
);
Ora possiamo richiedere la creazione di una query.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
) ->> 'sql';
e produce l'output desiderato.
SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = 'Republic Outpost' AND oi.created_at >= DATE_TRUNC('year', CURRENT_DATE - INTERVAL '1 year') AND oi.created_at < DATE_TRUNC('year', CURRENT_DATE)
In alternativa, puoi eseguire la query direttamente utilizzando la seguente query:
SELECT
alloydb_ai_nl.execute_nl_query(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
);
Restituirà i risultati in formato JSON, che possono essere analizzati.
execute_nl_query
--------------------------------------------------------
{"last_name":"Adams","country":"China"}
{"last_name":"Adams","country":"Germany"}
{"last_name":"Aguilar","country":"China"}
{"last_name":"Allen","country":"China"}
11. Pulizia dell'ambiente
Elimina le istanze e il cluster AlloyDB al termine del lab.
Elimina il cluster AlloyDB e tutte le istanze
Se hai utilizzato la versione di prova di AlloyDB. Non eliminare il cluster di prova se prevedi di testare altri lab e risorse utilizzando il cluster di prova. Non potrai creare un altro cluster di prova nello stesso progetto.
Il cluster viene eliminato con l'opzione force, che elimina anche tutte le istanze appartenenti al cluster.
In Cloud Shell definisci le variabili di progetto e di ambiente se la connessione è stata interrotta e tutte le impostazioni precedenti sono andate perse:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Elimina il cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Elimina i backup di AlloyDB
Elimina tutti i backup AlloyDB per il cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Complimenti
Congratulazioni per aver completato il codelab. Ora puoi provare a implementare le tue soluzioni utilizzando le funzionalità NL2SQL di AlloyDB. Ti consigliamo di provare altri codelab correlati ad AlloyDB e AlloyDB AI. Puoi verificare come funzionano gli embedding multimodali in AlloyDB in questo codelab.
Argomenti trattati
- Come eseguire il deployment di AlloyDB per PostgreSQL
- Come attivare il linguaggio naturale di AlloyDB AI
- Come creare e ottimizzare la configurazione per l'AI in linguaggio naturale
- Come generare query SQL e ottenere risultati utilizzando il linguaggio naturale
13. Sondaggio
Output: