
1. はじめに
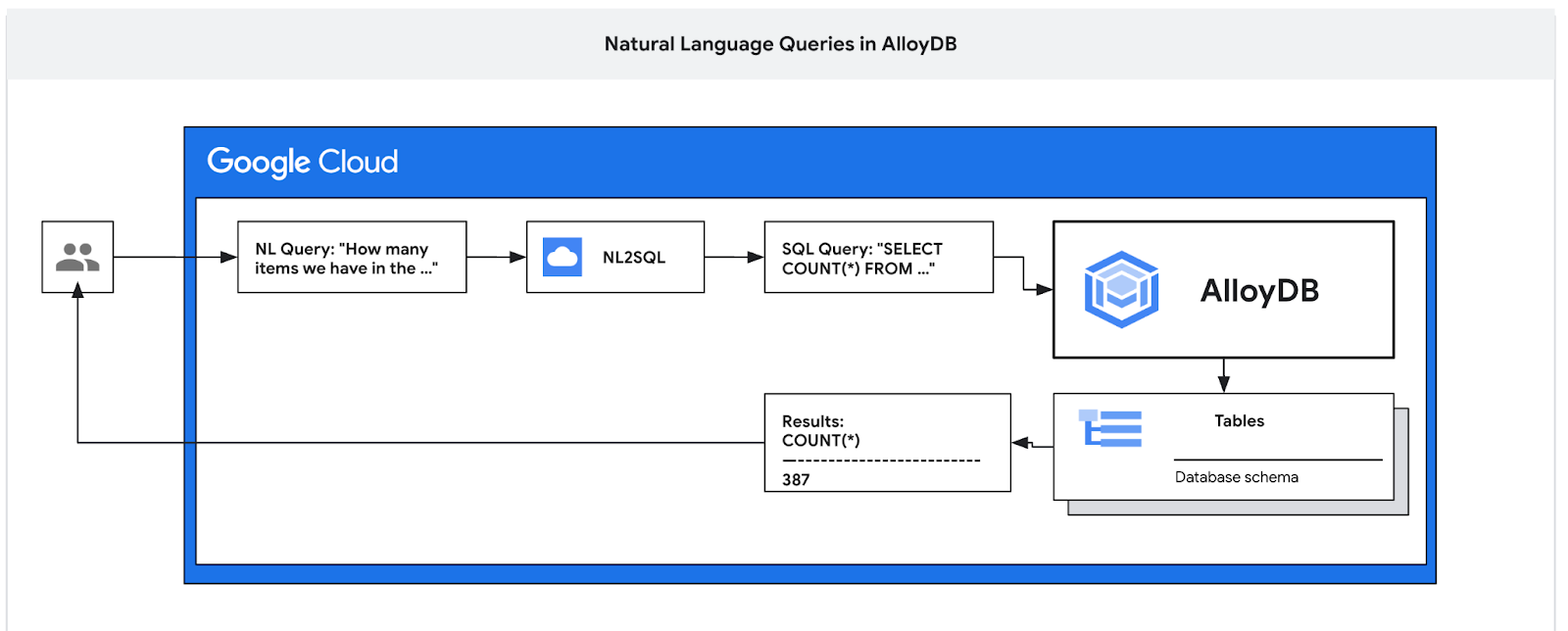
この Codelab では、AlloyDB をデプロイし、AI 自然言語を使用してデータをクエリし、予測可能で効率的なクエリの構成を調整する方法を学習します。このラボは、AlloyDB AI 機能専用のラボ コレクションの一部です。詳細については、ドキュメントの AlloyDB AI ページをご覧ください。
前提条件
- Google Cloud とコンソールの基本的な知識
- コマンドライン インターフェースと Cloud Shell の基本的なスキル
学習内容
- AlloyDB for Postgres をデプロイする方法
- AlloyDB AI 自然言語を有効にする方法
- AI 自然言語の構成を作成して調整する方法
- 自然言語を使用して SQL クエリを生成し、結果を取得する方法
必要なもの
- Google Cloud アカウントと Google Cloud プロジェクト
- Google Cloud コンソールと Cloud Shell をサポートするウェブブラウザ(Chrome など)
2. 設定と要件
セルフペース型の環境設定
- Google Cloud Console にログインして、プロジェクトを新規作成するか、既存のプロジェクトを再利用します。Gmail アカウントも Google Workspace アカウントもまだお持ちでない場合は、アカウントを作成してください。

- プロジェクト名は、このプロジェクトの参加者に表示される名称です。Google API では使用されない文字列です。いつでも更新できます。
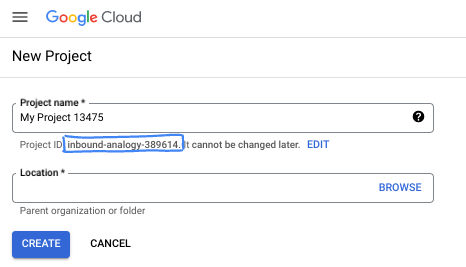
- プロジェクト ID は、すべての Google Cloud プロジェクトにおいて一意でなければならず、不変です(設定後は変更できません)。Cloud コンソールでは一意の文字列が自動生成されます。通常は、この内容を意識する必要はありません。ほとんどの Codelab では、プロジェクト ID(通常は
PROJECT_IDと識別されます)を参照する必要があります。生成された ID が好みではない場合は、ランダムに別の ID を生成できます。または、ご自身で試して、利用可能かどうかを確認することもできます。このステップ以降は変更できず、プロジェクトを通して同じ ID になります。 - なお、3 つ目の値として、一部の API が使用するプロジェクト番号があります。これら 3 つの値について詳しくは、こちらのドキュメントをご覧ください。
- 次に、Cloud のリソースや API を使用するために、Cloud コンソールで課金を有効にする必要があります。この Codelab の操作をすべて行って、費用が生じたとしても、少額です。このチュートリアルの終了後に請求が発生しないようにリソースをシャットダウンするには、作成したリソースを削除するか、プロジェクトを削除します。Google Cloud の新規ユーザーは、300 米ドル分の無料トライアル プログラムをご利用いただけます。
Cloud Shell を起動する
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud Console で、右上のツールバーにある Cloud Shell アイコンをクリックします。
プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
3. はじめに
API を有効にする
Cloud Shell で、プロジェクト ID が設定されていることを確認します。
gcloud config set project [YOUR-PROJECT-ID]
環境変数 PROJECT_ID を設定します。
PROJECT_ID=$(gcloud config get-value project)
必要なサービスをすべて有効にします。
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
想定される出力
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB をデプロイする
AlloyDB クラスタとプライマリ インスタンスを作成します。次の手順では、Google Cloud SDK を使用して AlloyDB クラスタとインスタンスを作成する方法について説明します。コンソールを使用する場合は、こちらのドキュメントをご覧ください。
AlloyDB クラスタを作成する前に、将来の AlloyDB インスタンスで使用する VPC で使用可能なプライベート IP 範囲が必要です。ない場合は、作成して内部の Google サービスで使用されるように割り当てる必要があります。その後、クラスタとインスタンスを作成できます。
プライベート IP 範囲を作成する
AlloyDB の VPC でプライベート サービス アクセスを構成する必要があります。ここでは、プロジェクトに「デフォルト」の VPC ネットワークがあり、すべてのアクションで使用されることを前提としています。
プライベート IP 範囲を作成します。
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
割り振られた IP 範囲を使用してプライベート接続を作成します。
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
想定されるコンソール出力:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
AlloyDB クラスタを作成する
このセクションでは、us-central1 リージョンに AlloyDB クラスタを作成します。
postgres ユーザーのパスワードを定義します。独自のパスワードを定義することも、ランダム関数を使用してパスワードを生成することもできます。
export PGPASSWORD=`openssl rand -hex 12`
想定されるコンソール出力:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
後で使用できるように PostgreSQL のパスワードをメモしておきます。
echo $PGPASSWORD
このパスワードは、後で postgres ユーザーとしてインスタンスに接続するために必要になります。後で使用できるように、書き留めておくか、どこかにコピーしておくことをおすすめします。
想定されるコンソール出力:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
無料トライアル クラスタを作成する
AlloyDB を使用したことがない場合は、無料のトライアル クラスタを作成できます。
リージョンと AlloyDB クラスタ名を定義します。ここでは、us-central1 リージョンと alloydb-aip-01 をクラスタ名として使用します。
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
コマンドを実行してクラスタを作成します。
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
想定されるコンソール出力:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
同じ Cloud Shell セッションで、クラスタの AlloyDB プライマリ インスタンスを作成します。切断された場合は、リージョンとクラスタ名の環境変数を再度定義する必要があります。
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
想定されるコンソール出力:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
AlloyDB Standard クラスタを作成する
プロジェクトで最初の AlloyDB クラスタでない場合は、標準クラスタの作成に進みます。
リージョンと AlloyDB クラスタ名を定義します。ここでは、us-central1 リージョンと alloydb-aip-01 をクラスタ名として使用します。
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
コマンドを実行してクラスタを作成します。
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
想定されるコンソール出力:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
同じ Cloud Shell セッションで、クラスタの AlloyDB プライマリ インスタンスを作成します。切断された場合は、リージョンとクラスタ名の環境変数を再度定義する必要があります。
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
想定されるコンソール出力:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. データベースを準備する
データベースを作成し、Vertex AI インテグレーションを有効にして、データベース オブジェクトを作成し、データをインポートする必要があります。
AlloyDB に必要な権限を付与する
AlloyDB サービス エージェントに Vertex AI 権限を追加します。
上部の「+」記号を選択して、別の Cloud Shell タブを開きます。
新しい Cloud Shell タブで、次のコマンドを実行します。
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
タブに実行コマンド「exit」を入力して、タブを閉じます。
exit
AlloyDB Studio に接続する
以降の章では、データベースへの接続を必要とするすべての SQL コマンドを AlloyDB Studio で実行することもできます。コマンドを実行するには、プライマリ インスタンスをクリックして AlloyDB クラスタのウェブ コンソール インターフェースを開く必要があります。
次に、左側の [AlloyDB Studio] をクリックします。
postgres データベースとユーザー postgres を選択し、クラスタの作成時にメモしたパスワードを入力します。[認証] ボタンをクリックします。
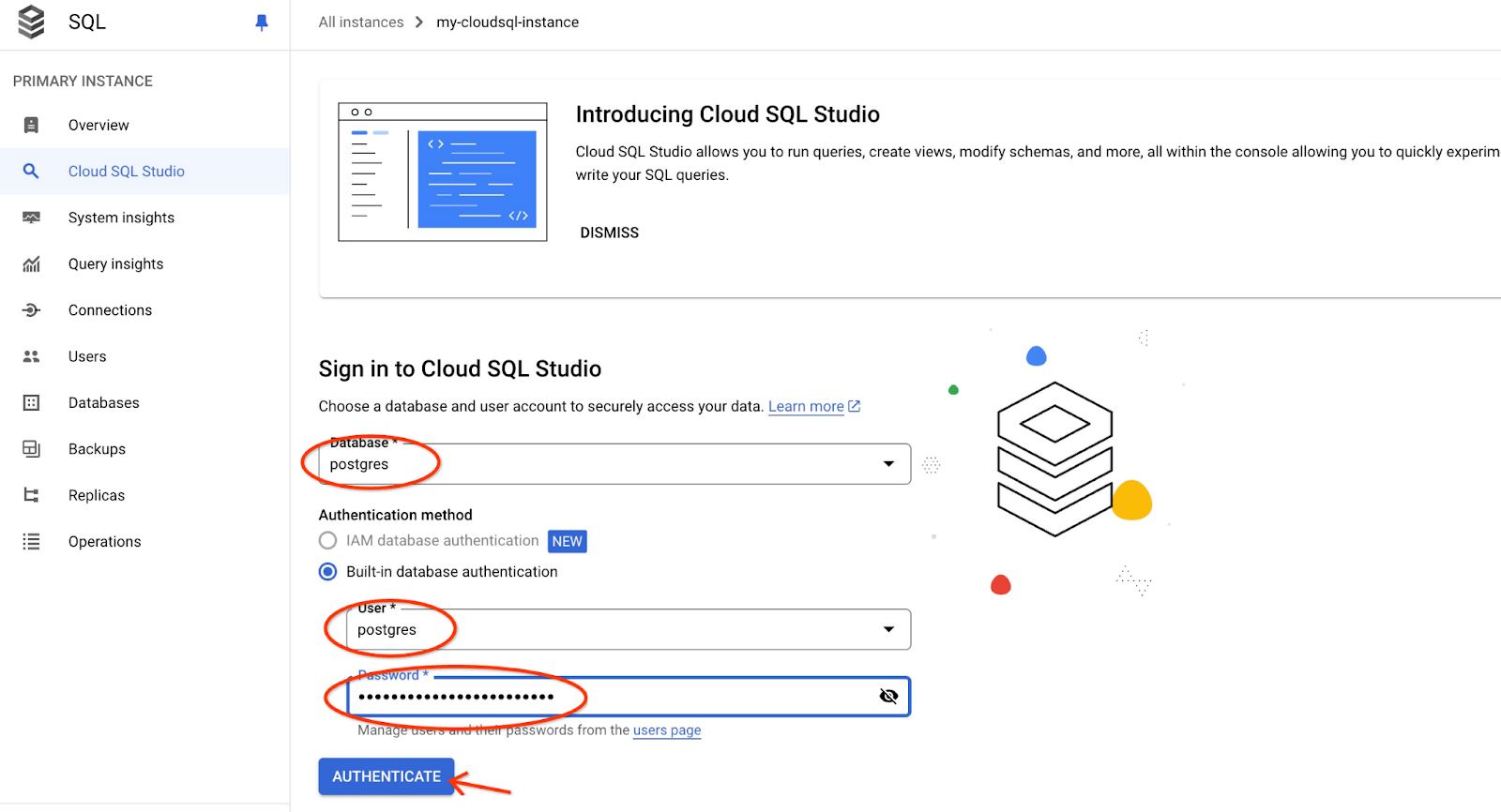
AlloyDB Studio インターフェースが開きます。データベースでコマンドを実行するには、右側の [エディタ 1] タブをクリックします。
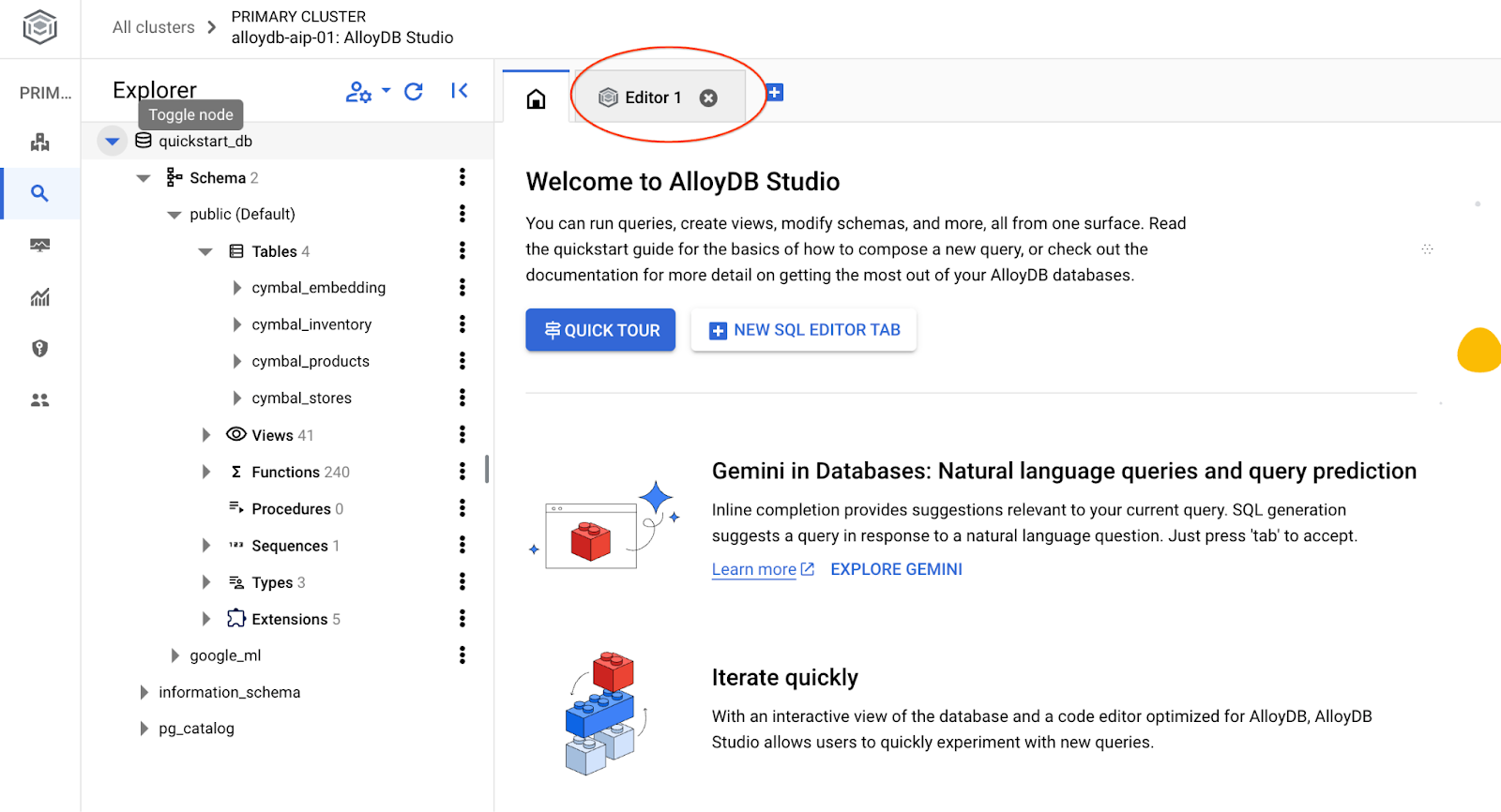
SQL コマンドを実行できるインターフェースが開きます。
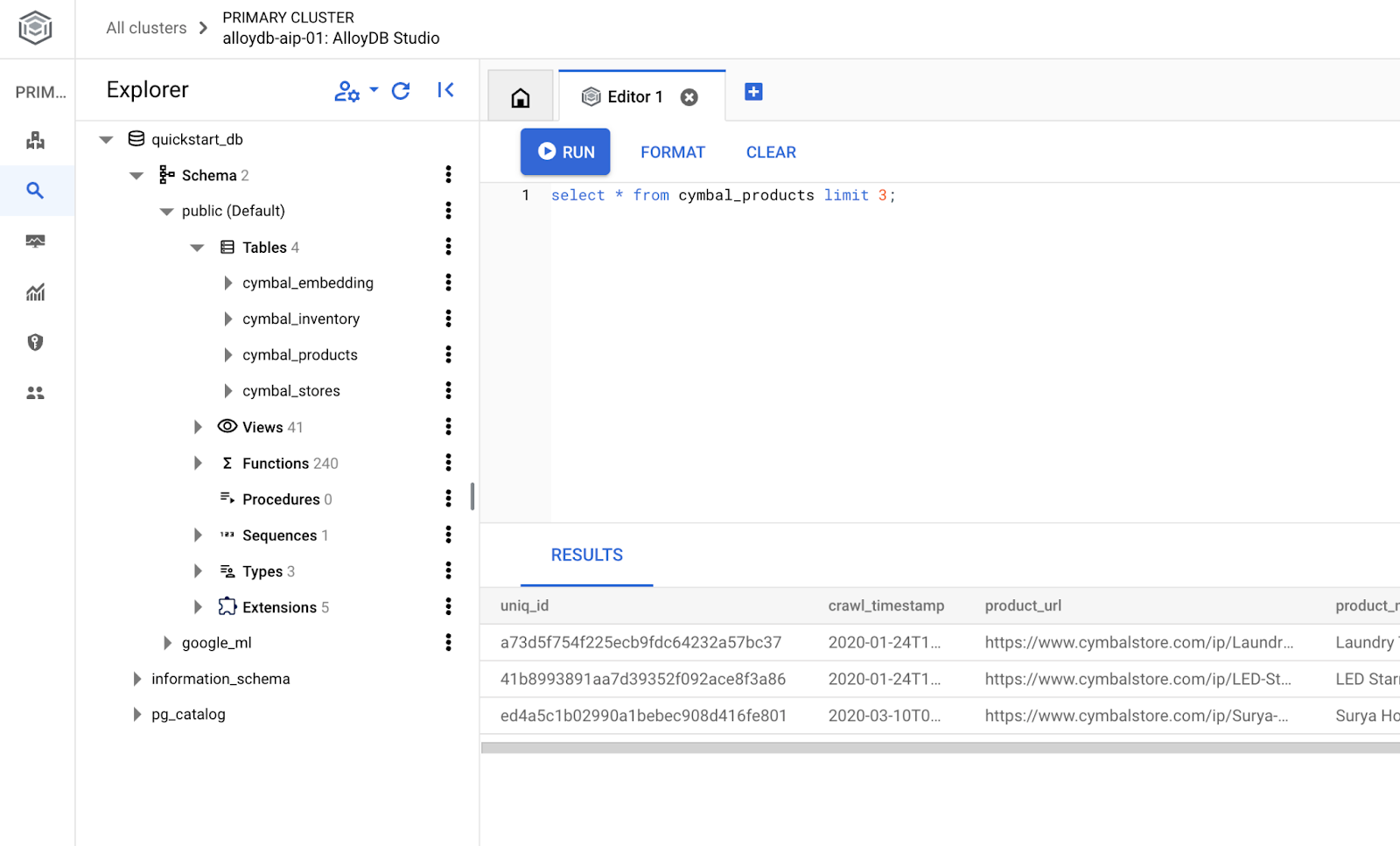
データベースを作成する
データベース作成のクイックスタート。
AlloyDB Studio エディタで、次のコマンドを実行します。
データベースを作成します。
CREATE DATABASE quickstart_db
予想される出力:
Statement executed successfully
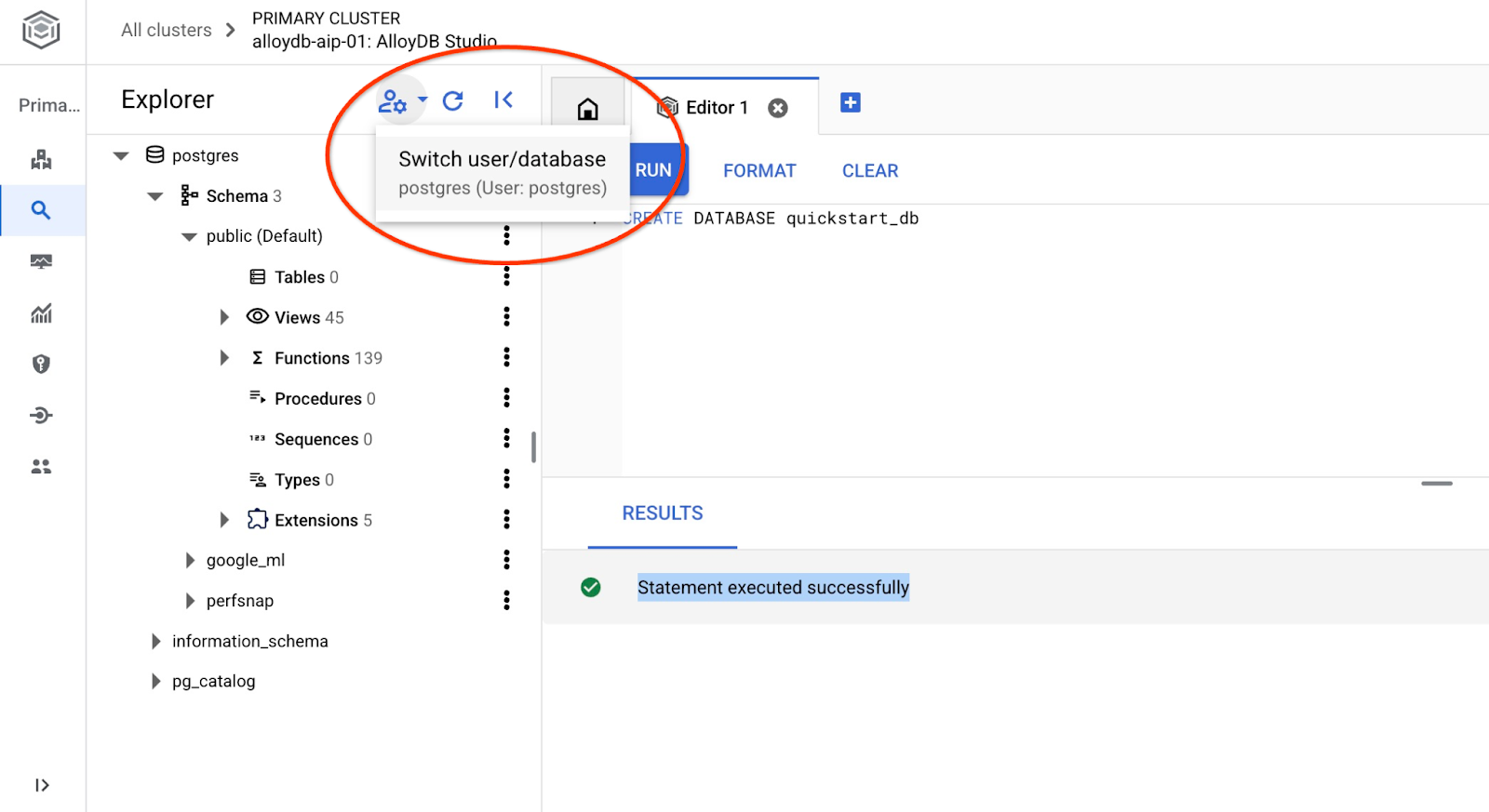
quickstart_db に接続する
ユーザー/データベースを切り替えるボタンを使用して、スタジオに再接続します。
プルダウン リストから新しい quickstart_db データベースを選択し、以前と同じユーザーとパスワードを使用します。
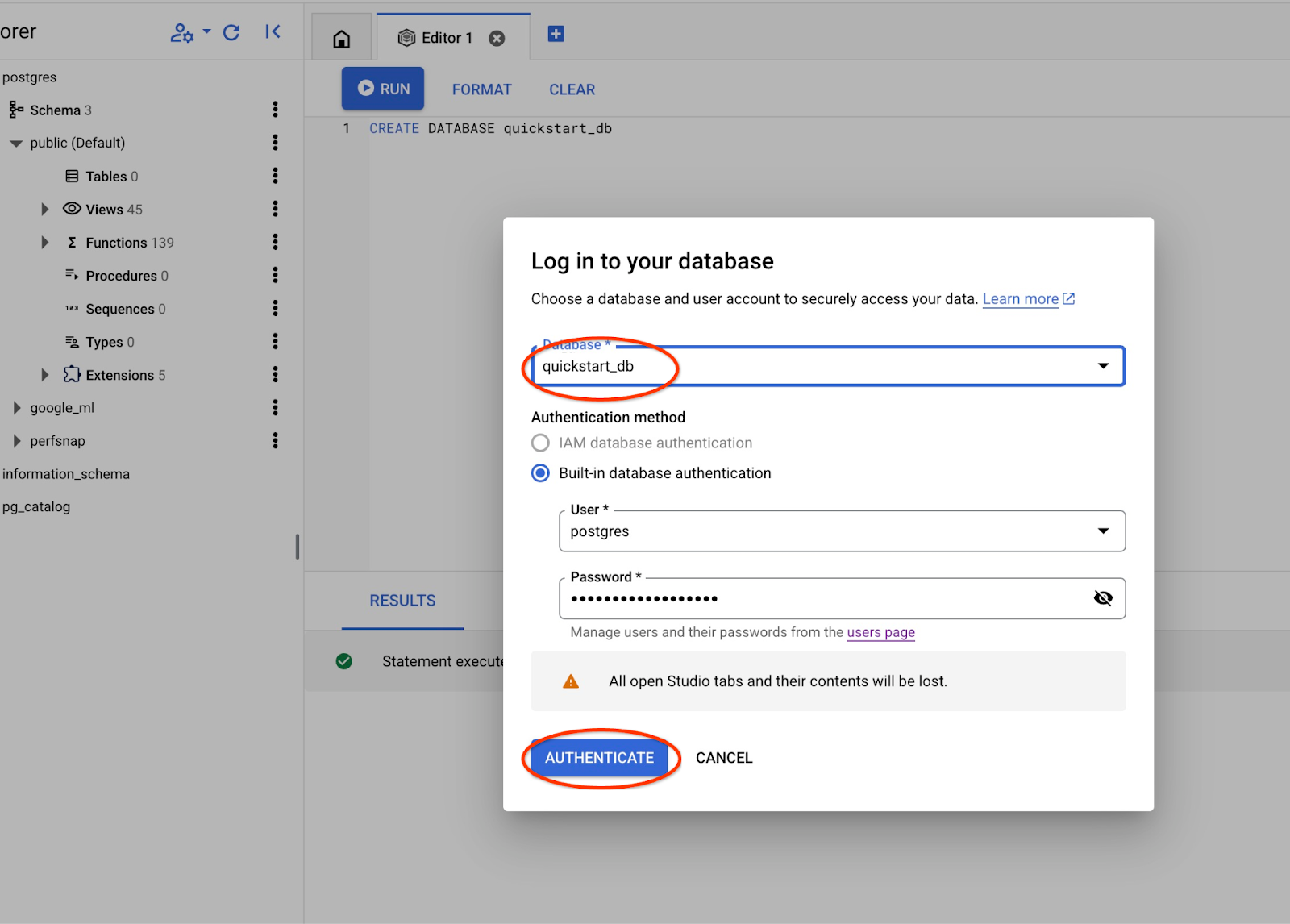
新しい接続が開き、quickstart_db データベースのオブジェクトを操作できます。
6. サンプルデータ
次に、データベースにオブジェクトを作成してデータを読み込む必要があります。ここでは、架空の「Cymbal ecomm」ストアと、オンライン ストア用のテーブルのセットを使用します。リレーショナル データベース スキーマに似たキーで接続された複数のテーブルが含まれています。
データセットは、インポート インターフェースを使用してデータベースに読み込むことができる SQL ファイルとして準備され、配置されます。Cloud Shell で、次のコマンドを実行します。
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic.sql' --user=postgres --sql
このコマンドは AlloyDB SDK を使用して ecomm スキーマを作成し、必要なオブジェクトをすべて作成してデータを挿入しながら、サンプルデータを GCS バケットからデータベースに直接インポートします。
インポート後、AlloyDB Studio でテーブルを確認できます。
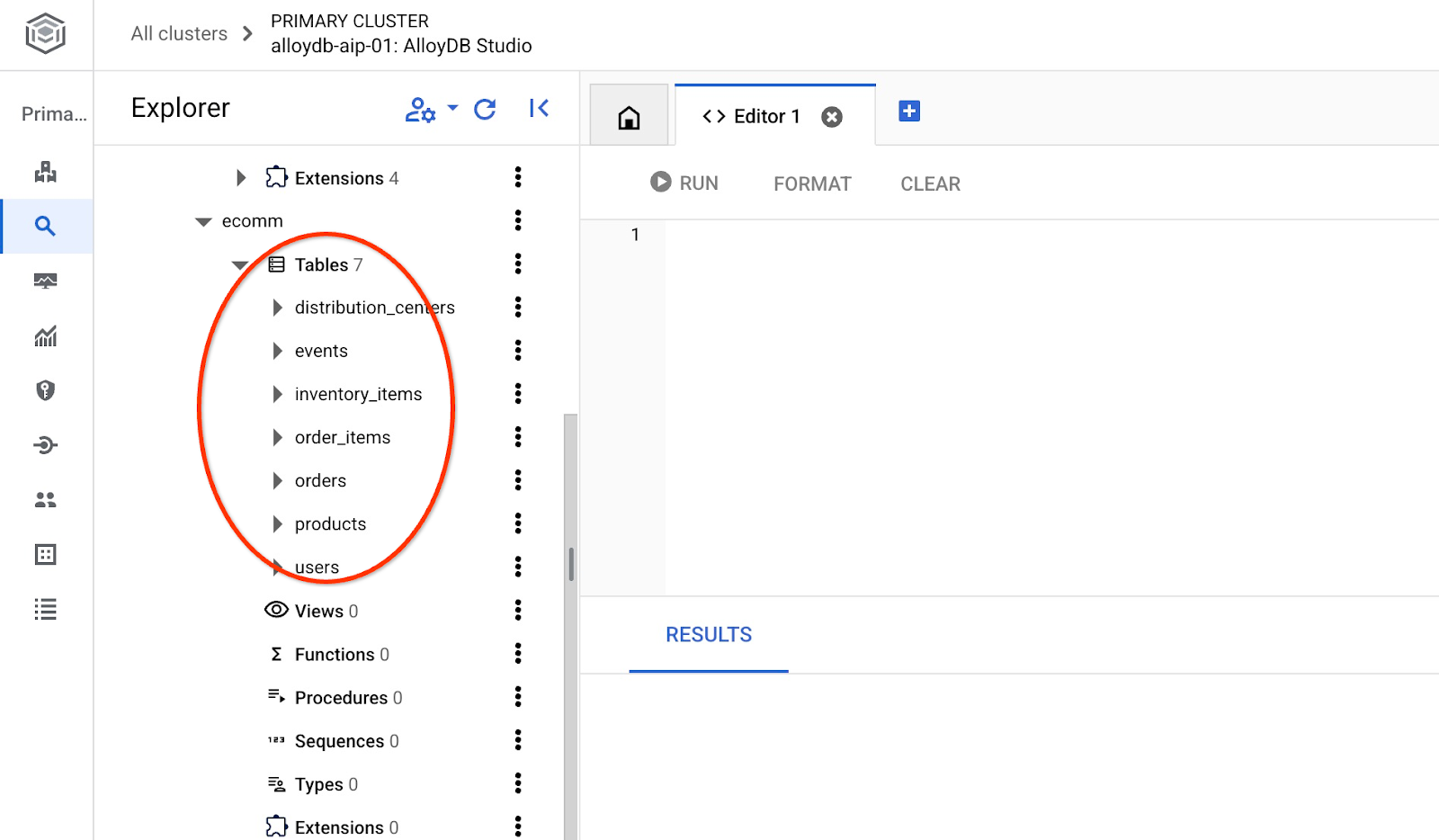
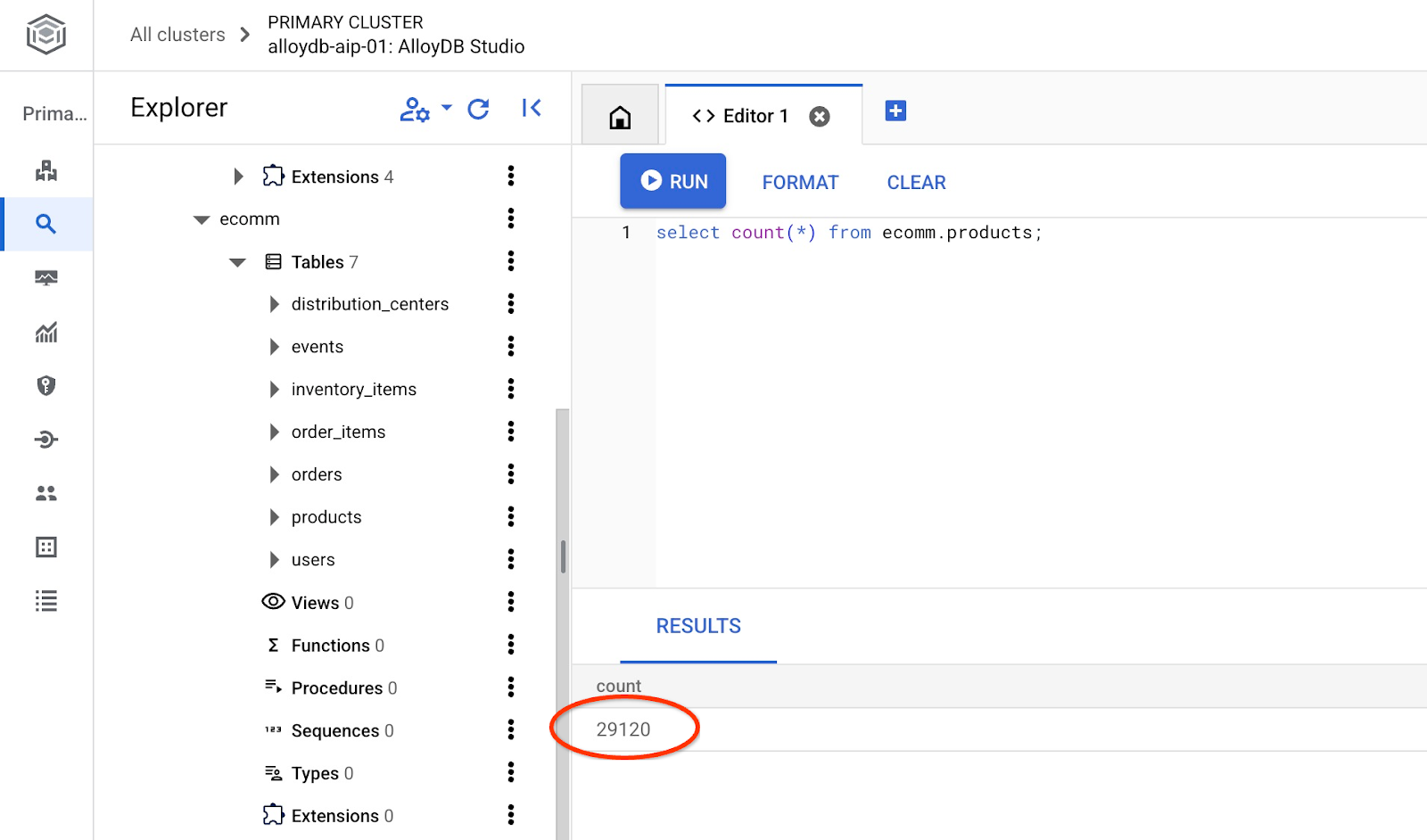
テーブルの行数を確認します。
7. NL SQL を構成する
この章では、サンプル スキーマで NL が動作するように構成します。
alloydb_nl_ai 拡張機能をインストールする
データベースに alloydb_ai_nl 拡張機能をインストールする必要があります。これを行う前に、データベース フラグ alloydb_ai_nl.enabled をオンに設定する必要があります。
Cloud Shell セッションで、次のコマンドを実行します。
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb instances update $ADBCLUSTER-pr \
--cluster=$ADBCLUSTER \
--region=$REGION \
--database-flags=alloydb_ai_nl.enabled=on
これにより、インスタンスの更新が開始されます。更新中のインスタンスのステータスは、ウェブ コンソールで確認できます。
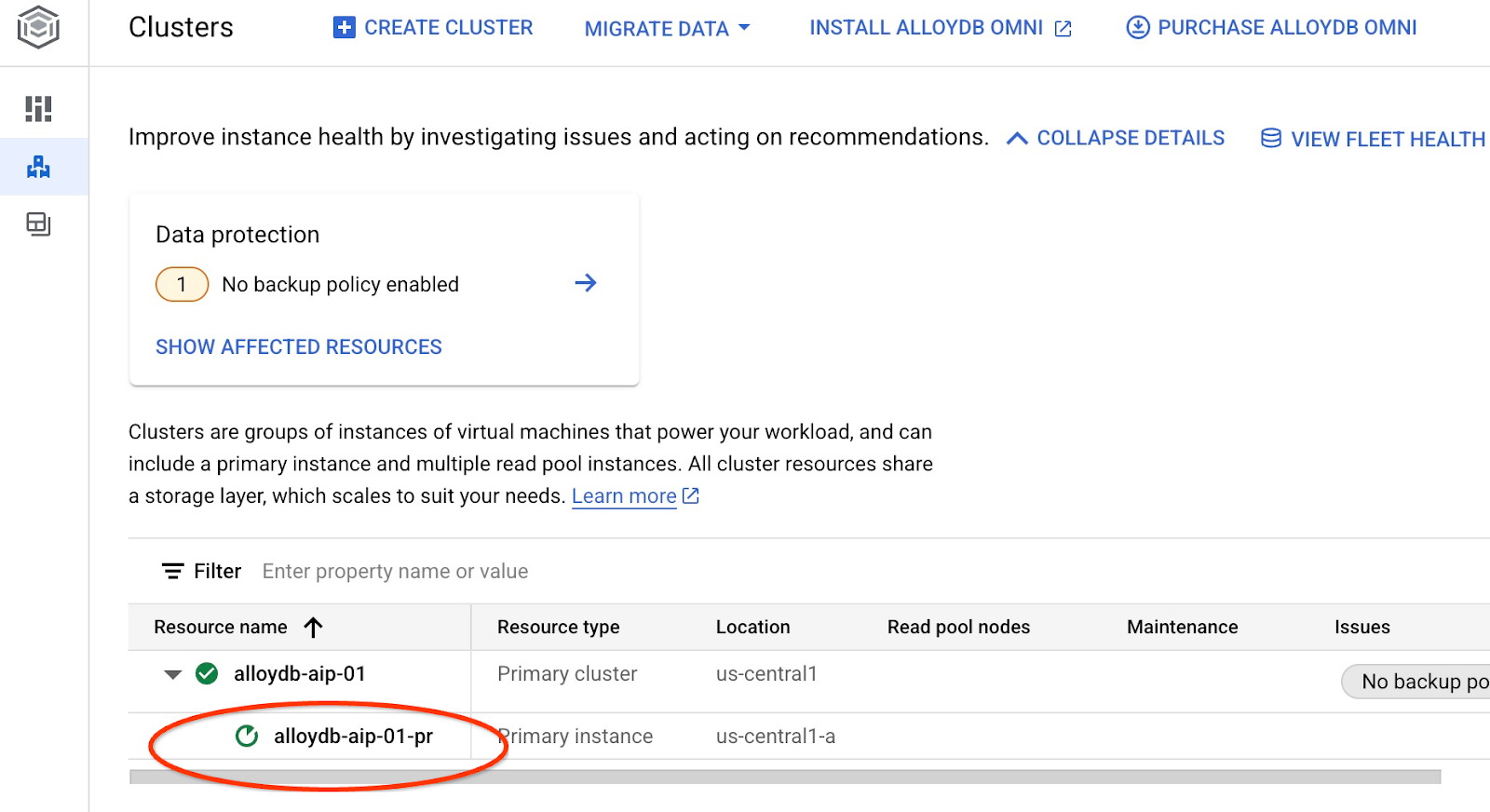
インスタンスが更新されると(インスタンスのステータスが緑色)、alloydb_ai_nl 拡張機能を有効にできます。
AlloyDB Studio で実行します。
CREATE EXTENSION IF NOT EXISTS google_ml_integration;
CREATE EXTENSION alloydb_ai_nl cascade;
自然言語の構成を作成する
拡張機能を使用するには、構成を作成する必要があります。この構成は、特定のスキーマ、クエリ テンプレート、モデル エンドポイントにアプリケーションを関連付けるために必要です。ID が cymbal_ecomm_config の構成を作成しましょう。
AlloyDB Studio で実行します。
SELECT
alloydb_ai_nl.g_create_configuration(
configuration_id => 'cymbal_ecomm_config'
);
これで、構成に e コマース スキーマを登録できます。データを ecomm スキーマにインポートしたので、そのスキーマを NL 構成に追加します。
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'register_schema',
configuration_id_in => 'cymbal_ecomm_config',
schema_names_in => '{ecomm}'
);
8. NL SQL にコンテキストを追加する
一般的なコンテキストを追加する
登録済みのスキーマにコンテキストを追加できます。コンテキストは、ユーザーのリクエストに対してより適切な結果を生成するために使用されます。たとえば、明示的に定義されていない場合、あるブランドがユーザーの優先ブランドであると判断できます。Clades(架空のブランド)をデフォルトのブランドに設定しましょう。
AlloyDB Studio で、次のコマンドを実行します。
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'add_general_context',
configuration_id_in => 'cymbal_ecomm_config',
general_context_in => '{"If the user doesn''t clearly define preferred brand then use Clades."}'
);
一般的なコンテキストがどのように機能するかを確認しましょう。
AlloyDB Studio で、次のコマンドを実行します。
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
);
生成されたクエリは、一般的なコンテキストで事前に定義されたデフォルトのブランドを使用しています。
{"sql": "SELECT count(*) FROM \"ecomm\".\"products\" WHERE \"brand\" = 'Clades'", "method": "default", "prompt": "", "retries": 0, "time(ms)": {"llm": 505.628000, "magic": 424.019000}, "error_msg": "", "nl_question": "How many products do we have of our preferred brand?", "toolbox_used": false}
これをクリーンアップして、SQL ステートメントのみを出力として生成できます。
次に例を示します。
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
クリアされた出力:
SELECT count(*) FROM "ecomm"."products" WHERE "brand" = 'Clades'
このクエリでは、products ではなく inventory_items テーブルが自動的に選択され、クエリの作成に使用されています。これは一部のケースでは機能するかもしれませんが、このスキーマでは機能しません。この例では、inventory_items テーブルは販売を追跡するために使用されます。内部情報がない場合、このテーブルは誤解を招く可能性があります。クエリの精度を高める方法については、後で確認します。
スキーマ コンテキスト
スキーマ コンテキストは、テーブル、ビュー、個々の列などのスキーマ オブジェクトを記述します。スキーマ オブジェクトのコメントとして情報を保存します。
次のクエリを使用すると、定義された構成内のすべてのスキーマ オブジェクトに対して自動的に作成できます。
SELECT
alloydb_ai_nl.generate_schema_context(
nl_config_id => 'cymbal_ecomm_config',
overwrite_if_exist => TRUE
);
「TRUE」パラメータは、コンテキストを再生成して上書きするように指示します。実行には、データモデルに応じて時間がかかります。関係と接続が多いほど、時間がかかる可能性があります。
コンテキストを作成したら、次のクエリを使用して、インベントリ アイテム テーブルに作成された内容を確認できます。
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.inventory_items';
クリアされた出力:
The `ecomm.inventory_items` table stores information about individual inventory items in an e-commerce system. Each item is uniquely identified by an `id` (primary key). The table tracks the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn't been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men's and women's apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.
商品説明に、inventory_items テーブルに反映される商品の移動に関する重要な部分が欠けているようです。このキー情報を ecomm.inventory_items 関係のコンテキストに追加することで、更新できます。
SELECT alloydb_ai_nl.update_generated_relation_context(
relation_name => 'ecomm.inventory_items',
relation_context => 'The `ecomm.inventory_items` table stores information about moving and sales of inventory items in an e-commerce system. Each movement is uniquely identified by an `id` (primary key) and used in order_items table as `inventory_item_id`. The table tracks sales and movements for the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the movement for the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn''t been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men''s and women''s apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.'
);
また、商品テーブルの説明の正確性を確認することもできます。
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.products';
products テーブルの自動生成されたコンテキストは非常に正確で、変更は必要ありませんでした。
両方のテーブルの各列に関する情報も確認しましたが、こちらも正しいことがわかりました。
生成された ecomm.inventory_items と ecomm.products のコンテキストを構成に適用しましょう。
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.inventory_items',
overwrite_if_exist => TRUE
);
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.products',
overwrite_if_exist => TRUE
);
「お気に入りのブランドの商品はいくつありますか?」という質問に対する SQL を生成するクエリを覚えていますか?を構築したいとお考えですか?これを繰り返して、出力が変更されるかどうかを確認します。
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
新しい出力は次のとおりです。
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
現在は ecomm.products をチェックしているため、より正確になり、在庫アイテムの 5,000 件のオペレーションではなく、約 300 件の商品が返されます。
9. 価値指標の操作
値のリンクでは、値のフレーズを事前登録されたコンセプト型と列名に関連付けることで、自然言語クエリを拡充します。これにより、結果の予測可能性を高めることができます。
値インデックスを構成する
商品テーブルのブランド列を使用してクエリを作成し、コンセプト タイプを定義して ecomm.products.brand 列に関連付けることで、より安定したブランドの商品を検索できます。
コンセプトを作成して列に関連付けましょう。
SELECT alloydb_ai_nl.add_concept_type(
concept_type_in => 'brand_name',
match_function_in => 'alloydb_ai_nl.get_concept_and_value_generic_entity_name',
additional_info_in => '{
"description": "Concept type for brand name.",
"examples": "SELECT alloydb_ai_nl.get_concept_and_value_generic_entity_name(''Auto Forge'')" }'::jsonb
);
SELECT alloydb_ai_nl.associate_concept_type(
column_names_in => 'ecomm.products.brand',
concept_type_in => 'brand_name',
nl_config_id_in => 'cymbal_ecomm_config'
);
コンセプトを検証するには、alloydb_ai_nl.list_concept_types() をクエリします。
SELECT alloydb_ai_nl.list_concept_types();
次に、作成済みおよび事前構築済みのすべての関連付けの構成でインデックスを作成できます。
SELECT alloydb_ai_nl.create_value_index(
nl_config_id_in => 'cymbal_ecomm_config'
);
価値インデックスを使用する
ブランド名を使用して SQL を作成するクエリを実行する際に、それがブランド名であることを定義しないと、エンティティと列を適切に識別できます。クエリは次のとおりです。
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many Clades do we have?'
) ->> 'sql';
出力には、単語「Clades」がブランド名として正しく識別されていることが示されています。
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
10. クエリ テンプレートの操作
クエリ テンプレートは、ビジネス クリティカルなアプリケーションの安定したクエリを定義し、不確実性を軽減して精度を向上させるのに役立ちます。
クエリ テンプレートを作成する
複数のテーブルを結合して、昨年「Republic Outpost」製品を購入した顧客に関する情報を取得するクエリ テンプレートを作成してみましょう。クエリでは、ecomm.products テーブルと ecomm.inventory_items テーブルのどちらも使用できます。どちらのテーブルにもブランドに関する情報が含まれているためです。ただし、テーブル products の行数は 15 分の 1 で、結合用の主キーにインデックスがあります。products テーブルを使用する方が効率的な場合があります。クエリのテンプレートを作成します。
SELECT alloydb_ai_nl.add_template(
nl_config_id => 'cymbal_ecomm_config',
intent => 'List the last names and the country of all customers who bought products of `Republic Outpost` in the last year.',
sql => 'SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = ''Republic Outpost'' AND oi.created_at >= DATE_TRUNC(''year'', CURRENT_DATE - INTERVAL ''1 year'') AND oi.created_at < DATE_TRUNC(''year'', CURRENT_DATE)',
sql_explanation => 'To answer this question, JOIN `ecomm.users` with `ecom.order_items` on having the same `users.id` and `order_items.user_id`, and JOIN the result with ecom.products on having the same `order_items.product_id` and `products.id`. Then filter rows with products.brand = ''Republic Outpost'' and by `order_items.created_at` for the last year. Return the `last_name` and the `country` of the users with matching records.',
check_intent => TRUE
);
これで、クエリの作成をリクエストできるようになりました。
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
) ->> 'sql';
そして、望ましい出力を生成します。
SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = 'Republic Outpost' AND oi.created_at >= DATE_TRUNC('year', CURRENT_DATE - INTERVAL '1 year') AND oi.created_at < DATE_TRUNC('year', CURRENT_DATE)
または、次のクエリを使用してクエリを直接実行することもできます。
SELECT
alloydb_ai_nl.execute_nl_query(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
);
解析可能な JSON 形式で結果が返されます。
execute_nl_query
--------------------------------------------------------
{"last_name":"Adams","country":"China"}
{"last_name":"Adams","country":"Germany"}
{"last_name":"Aguilar","country":"China"}
{"last_name":"Allen","country":"China"}
11. 環境をクリーンアップする
ラボの終了時に AlloyDB インスタンスとクラスタを破棄します。
AlloyDB クラスタとすべてのインスタンスを削除する
AlloyDB の試用版を使用したことがある場合。トライアル クラスタを使用して他のラボやリソースをテストする予定がある場合は、トライアル クラスタを削除しないでください。同じプロジェクトに別のトライアル クラスタを作成することはできません。
クラスタは force オプションで破棄され、クラスタに属するすべてのインスタンスも削除されます。
接続が切断され、以前の設定がすべて失われた場合は、Cloud Shell でプロジェクトと環境変数を定義します。
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
クラスタを削除します。
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB バックアップを削除する
クラスタの AlloyDB バックアップをすべて削除します。
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
想定されるコンソール出力:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. 完了
以上で、この Codelab は完了です。AlloyDB の NL2SQL 機能を使用して、独自のソリューションを実装できるようになりました。AlloyDB と AlloyDB AI に関連する他の Codelab を試すことをおすすめします。AlloyDB でのマルチモーダル エンベディングの仕組みについては、この Codelab をご覧ください。
学習した内容
- AlloyDB for Postgres をデプロイする方法
- AlloyDB AI 自然言語を有効にする方法
- AI 自然言語の構成を作成して調整する方法
- 自然言語を使用して SQL クエリを生成し、結果を取得する方法
13. アンケート
出力: