
1. Wprowadzenie
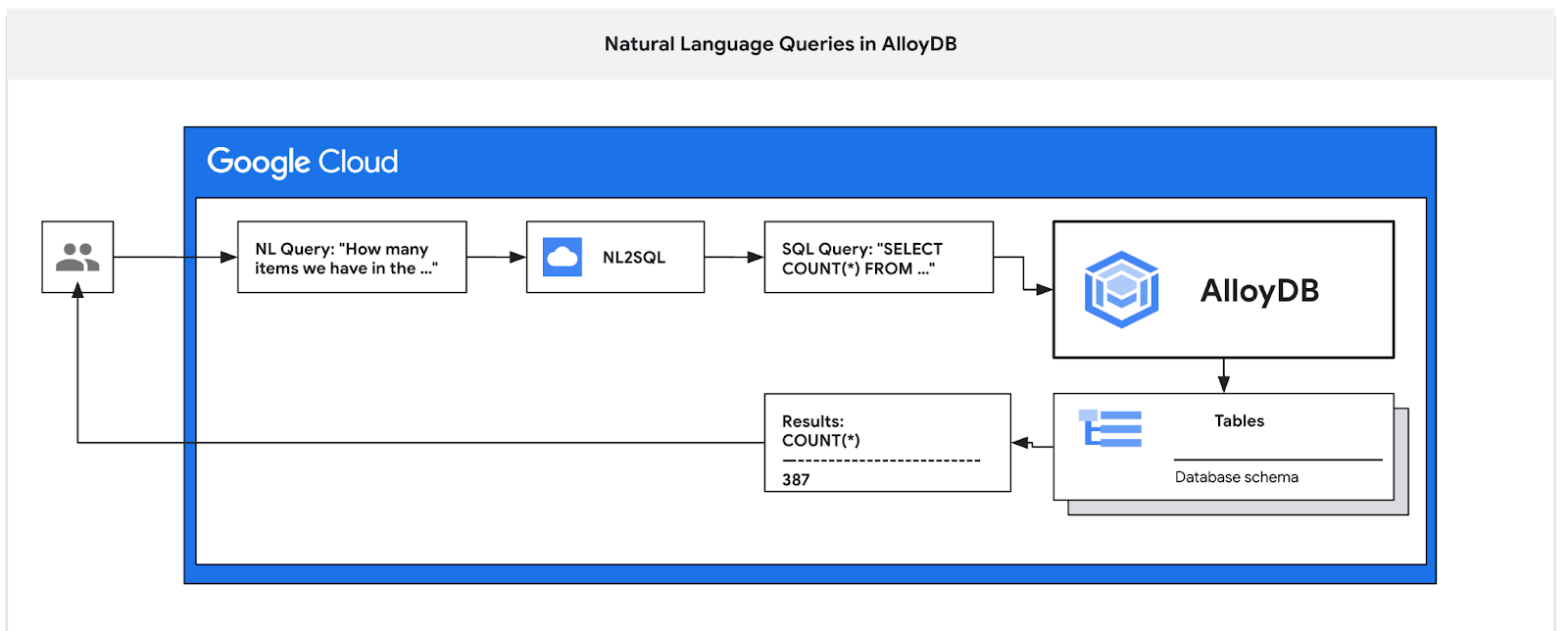
Z tego ćwiczenia w Codelabs dowiesz się, jak wdrożyć AlloyDB i używać AI w języku naturalnym do wykonywania zapytań o dane oraz dostosowywać konfigurację pod kątem przewidywalnych i wydajnych zapytań. Ten moduł należy do kolekcji modułów poświęconych funkcjom AlloyDB AI. Więcej informacji znajdziesz na stronie AlloyDB AI w dokumentacji.
Wymagania wstępne
- Podstawowa wiedza o Google Cloud i konsoli
- Podstawowe umiejętności w zakresie interfejsu wiersza poleceń i Cloud Shell
Czego się nauczysz
- Wdrażanie AlloyDB for Postgres
- Włączanie języka naturalnego w AlloyDB AI
- Jak tworzyć i dostosowywać konfigurację AI w języku naturalnym
- Jak generować zapytania SQL i uzyskiwać wyniki za pomocą języka naturalnego
Czego potrzebujesz
- Konto Google Cloud i projekt Google Cloud
- przeglądarka internetowa, np. Chrome, obsługująca konsolę Google Cloud i Cloud Shell;
2. Konfiguracja i wymagania
Samodzielne konfigurowanie środowiska
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.

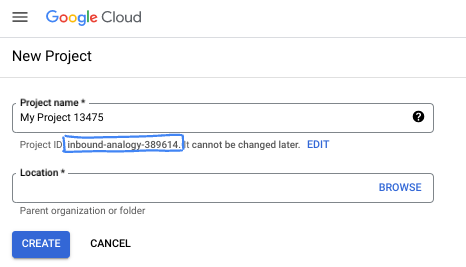
- Nazwa projektu to wyświetlana nazwa uczestników tego projektu. Jest to ciąg znaków, który nie jest używany przez interfejsy API Google. Zawsze możesz ją zaktualizować.
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Cloud automatycznie generuje unikalny ciąg znaków. Zwykle nie musisz się tym przejmować. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu (zwykle oznaczanego jako
PROJECT_ID). Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować inny losowy identyfikator. Możesz też spróbować własnej nazwy i sprawdzić, czy jest dostępna. Po tym kroku nie można go zmienić i pozostaje on taki przez cały czas trwania projektu. - Warto wiedzieć, że istnieje też trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
- Następnie musisz włączyć płatności w konsoli Cloud, aby korzystać z zasobów i interfejsów API Google Cloud. Wykonanie tego laboratorium nie będzie kosztować dużo, a może nawet nic. Aby wyłączyć zasoby i uniknąć naliczania opłat po zakończeniu tego samouczka, możesz usunąć utworzone zasoby lub projekt. Nowi użytkownicy Google Cloud mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym module praktycznym będziesz używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Zanim zaczniesz
Włącz API
W Cloud Shell sprawdź, czy identyfikator projektu jest skonfigurowany:
gcloud config set project [YOUR-PROJECT-ID]
Ustaw zmienną środowiskową PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Włącz wszystkie niezbędne usługi:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Oczekiwane dane wyjściowe
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Wdrażanie AlloyDB
Utwórz klaster AlloyDB i instancję główną. Poniższa procedura opisuje, jak utworzyć klaster i instancję AlloyDB za pomocą pakietu SDK Google Cloud. Jeśli wolisz korzystać z konsoli, zapoznaj się z dokumentacją tutaj.
Przed utworzeniem klastra AlloyDB musimy mieć dostępny zakres prywatnych adresów IP w naszej sieci VPC, który będzie używany przez przyszłą instancję AlloyDB. Jeśli go nie mamy, musimy go utworzyć i przypisać do użytku przez wewnętrzne usługi Google. Dopiero wtedy będziemy mogli utworzyć klaster i instancję.
Tworzenie prywatnego zakresu adresów IP
Musimy skonfigurować prywatny dostęp do usług w naszej sieci VPC dla AlloyDB. Zakładamy, że w projekcie mamy sieć VPC „default”, która będzie używana do wszystkich działań.
Utwórz zakres prywatnych adresów IP:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Utwórz połączenie prywatne, używając przydzielonego zakresu adresów IP:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Tworzenie klastra AlloyDB
W tej sekcji utworzymy klaster AlloyDB w regionie us-central1.
Określ hasło użytkownika postgres. Możesz zdefiniować własne hasło lub użyć funkcji losowej, aby je wygenerować.
export PGPASSWORD=`openssl rand -hex 12`
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Zapisz hasło do PostgreSQL, aby użyć go w przyszłości.
echo $PGPASSWORD
To hasło będzie Ci potrzebne w przyszłości do połączenia z instancją jako użytkownik postgres. Proponuję zapisać go lub skopiować w inne miejsce, aby móc go później użyć.
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Tworzenie bezpłatnego klastra próbnego
Jeśli nie używasz jeszcze AlloyDB, możesz utworzyć bezpłatny klaster próbny:
Określ region i nazwę klastra AlloyDB. Użyjemy regionu us-central1 i nazwy klastra alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Uruchom polecenie, aby utworzyć klaster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Oczekiwane dane wyjściowe konsoli:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Utwórz instancję główną AlloyDB dla klastra w tej samej sesji Cloud Shell. Jeśli połączenie zostanie przerwane, musisz ponownie zdefiniować zmienne środowiskowe regionu i nazwy klastra.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Tworzenie klastra AlloyDB Standard
Jeśli nie jest to Twój pierwszy klaster AlloyDB w projekcie, utwórz klaster standardowy.
Określ region i nazwę klastra AlloyDB. Użyjemy regionu us-central1 i nazwy klastra alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Uruchom polecenie, aby utworzyć klaster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Oczekiwane dane wyjściowe konsoli:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Utwórz instancję główną AlloyDB dla klastra w tej samej sesji Cloud Shell. Jeśli połączenie zostanie przerwane, musisz ponownie zdefiniować zmienne środowiskowe regionu i nazwy klastra.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Przygotowywanie bazy danych
Musimy utworzyć bazę danych, włączyć integrację z Vertex AI, utworzyć obiekty bazy danych i zaimportować dane.
Przyznawanie AlloyDB niezbędnych uprawnień
Dodaj uprawnienia Vertex AI do agenta usługi AlloyDB.
Otwórz kolejną kartę Cloud Shell, klikając znak „+” u góry.
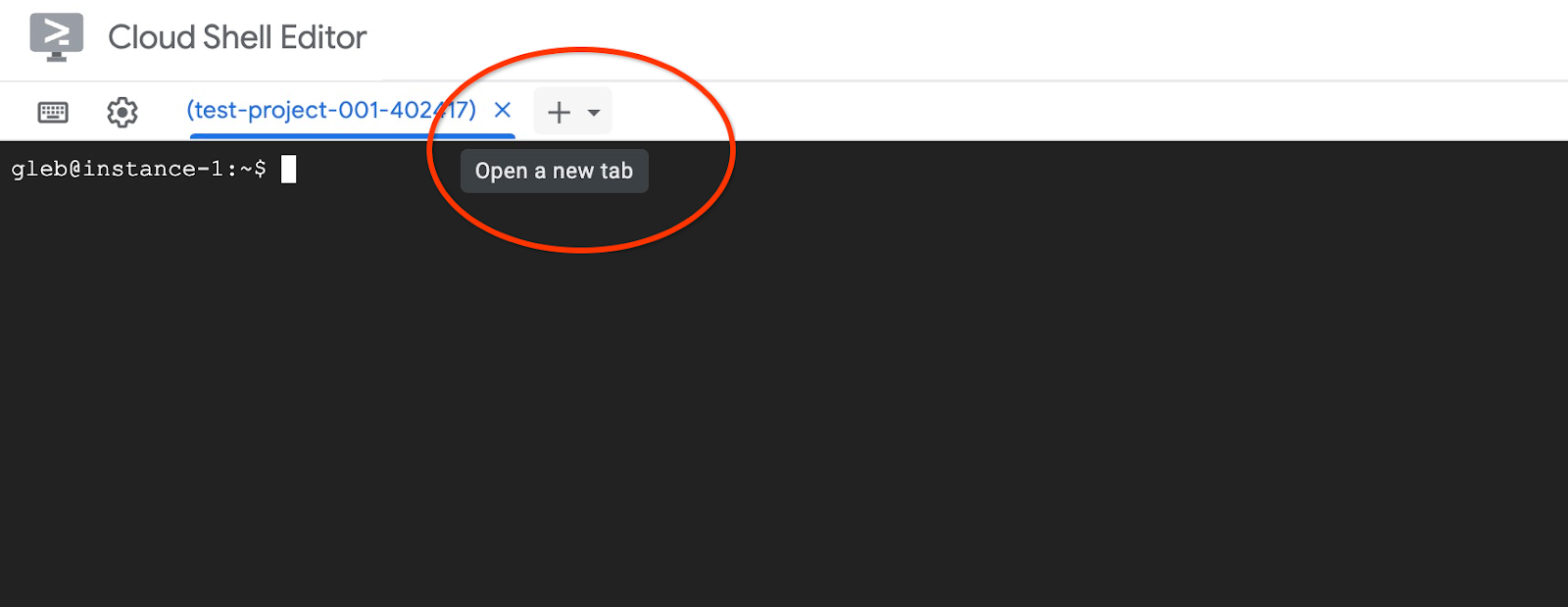
Na nowej karcie Cloud Shell wykonaj to polecenie:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Zamknij kartę, wpisując na niej polecenie „exit”:
exit
Łączenie się z AlloyDB Studio
W kolejnych rozdziałach wszystkie polecenia SQL wymagające połączenia z bazą danych można alternatywnie wykonywać w AlloyDB Studio. Aby uruchomić to polecenie, musisz otworzyć interfejs konsoli internetowej klastra AlloyDB, klikając instancję główną.
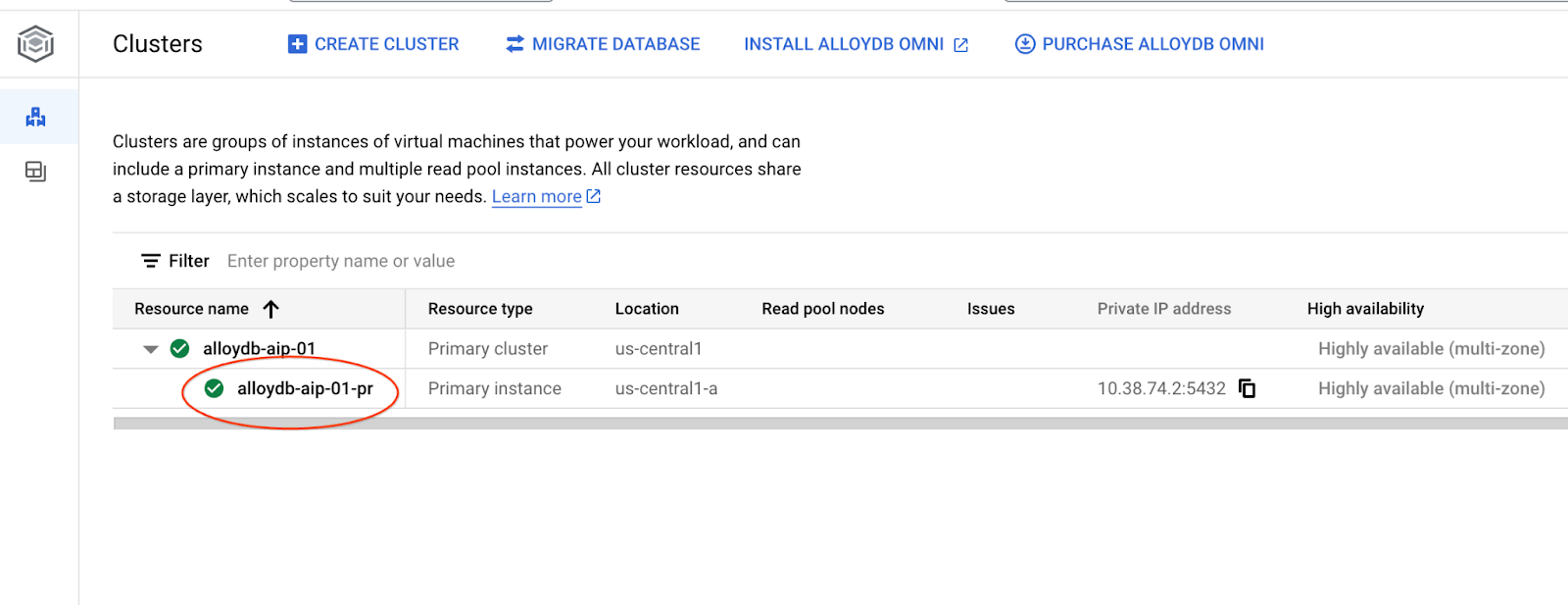
Następnie po lewej stronie kliknij AlloyDB Studio:
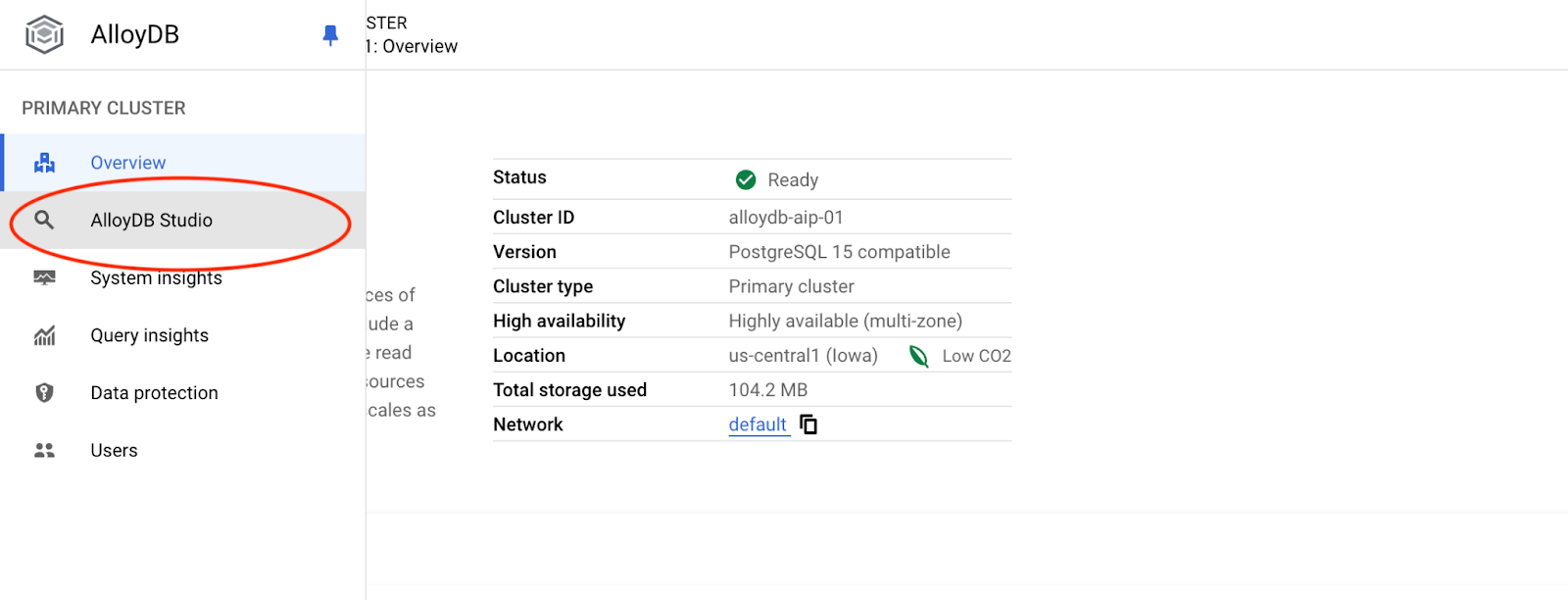
Wybierz bazę danych postgres, użytkownika postgres i podaj hasło zanotowane podczas tworzenia klastra. Następnie kliknij przycisk „Uwierzytelnij”.
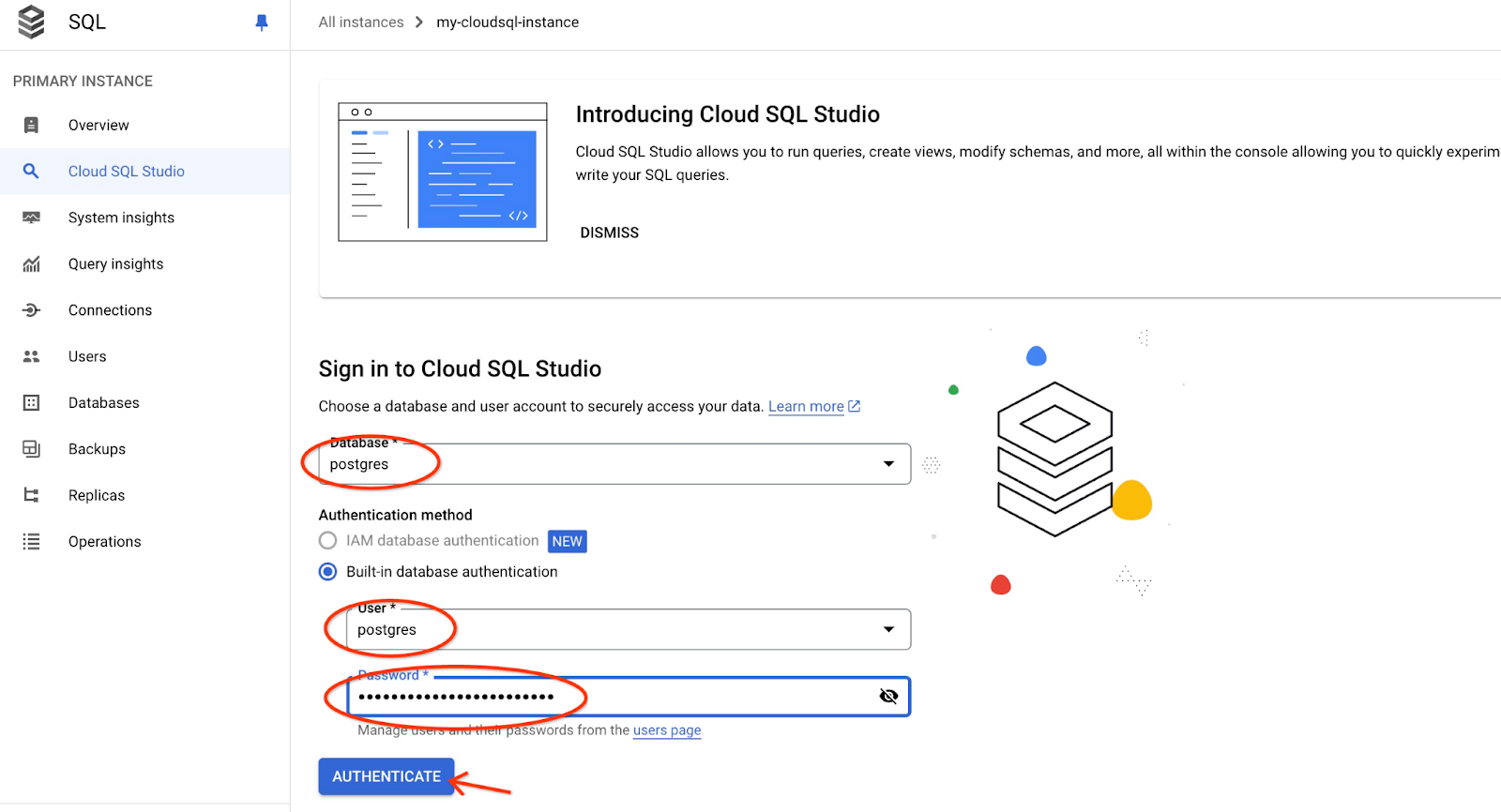
Otworzy się interfejs AlloyDB Studio. Aby uruchomić polecenia w bazie danych, kliknij kartę „Edytor 1” po prawej stronie.
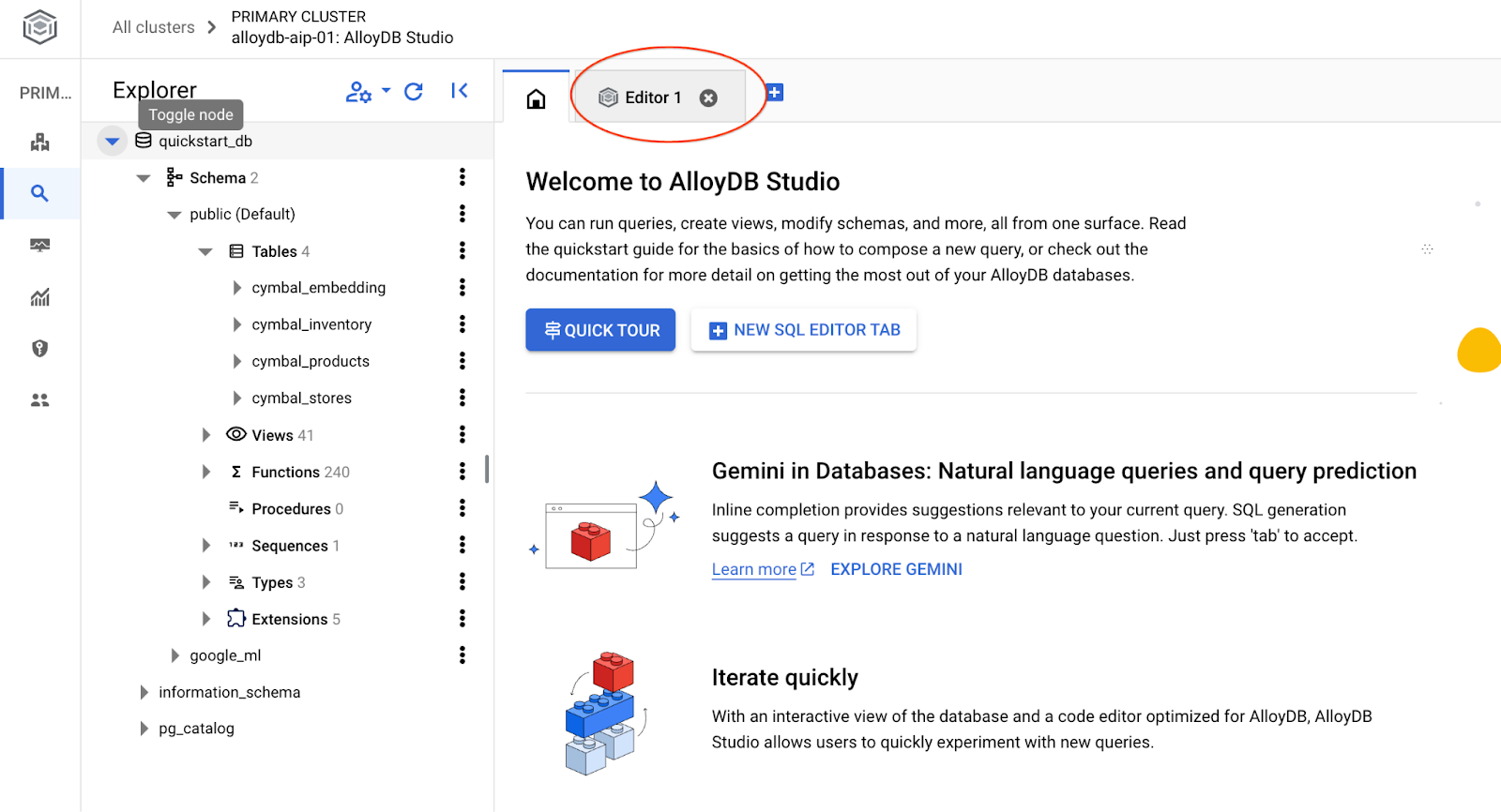
Otworzy się interfejs, w którym możesz uruchamiać polecenia SQL.
Utwórz bazę danych
Krótkie wprowadzenie do tworzenia bazy danych.
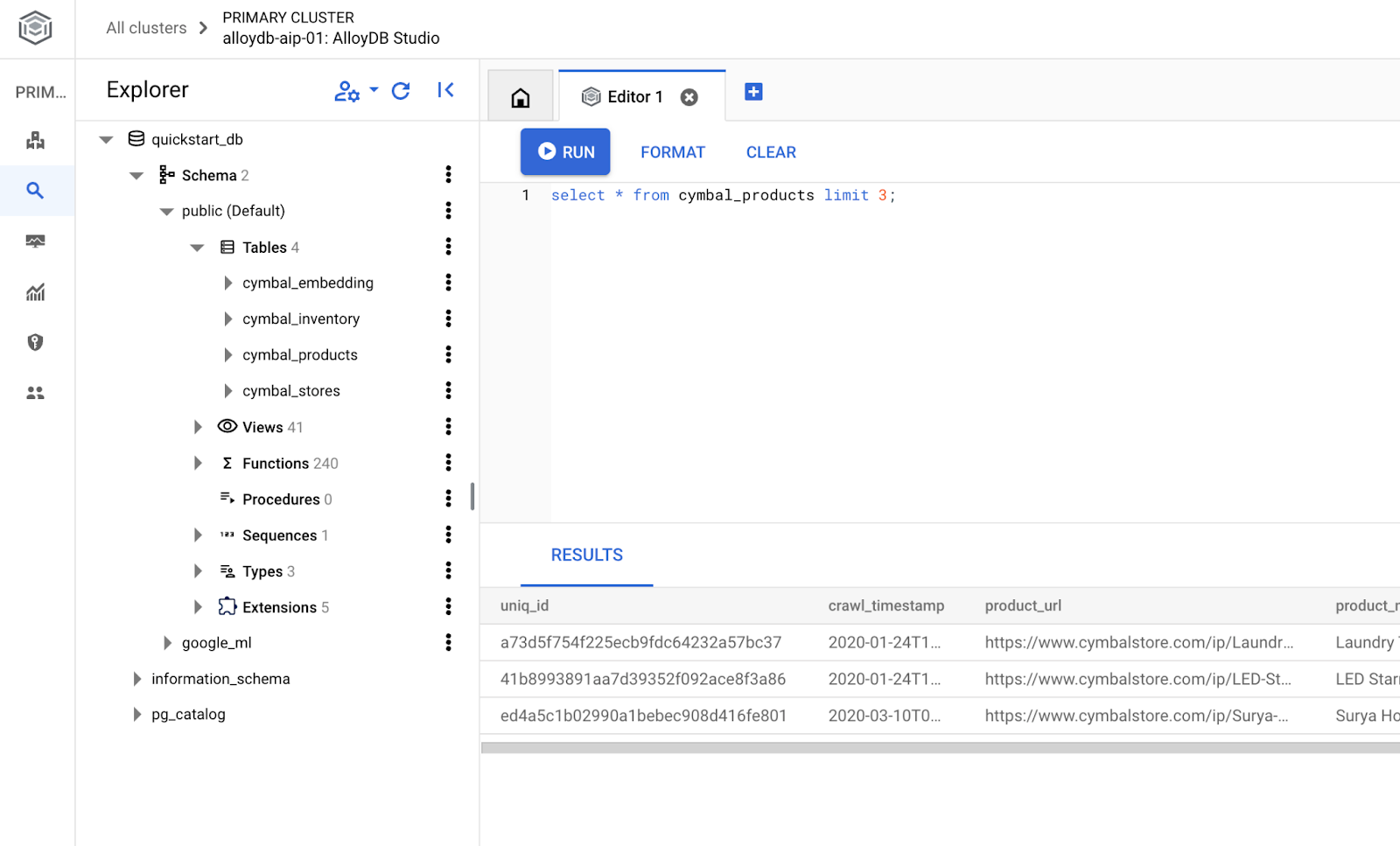
W edytorze AlloyDB Studio wykonaj to polecenie.
Utwórz bazę danych:
CREATE DATABASE quickstart_db
Oczekiwane dane wyjściowe:
Statement executed successfully
Połącz się z bazą danych quickstart_db
Połącz się ponownie ze studiem, używając przycisku przełączania użytkownika lub bazy danych.
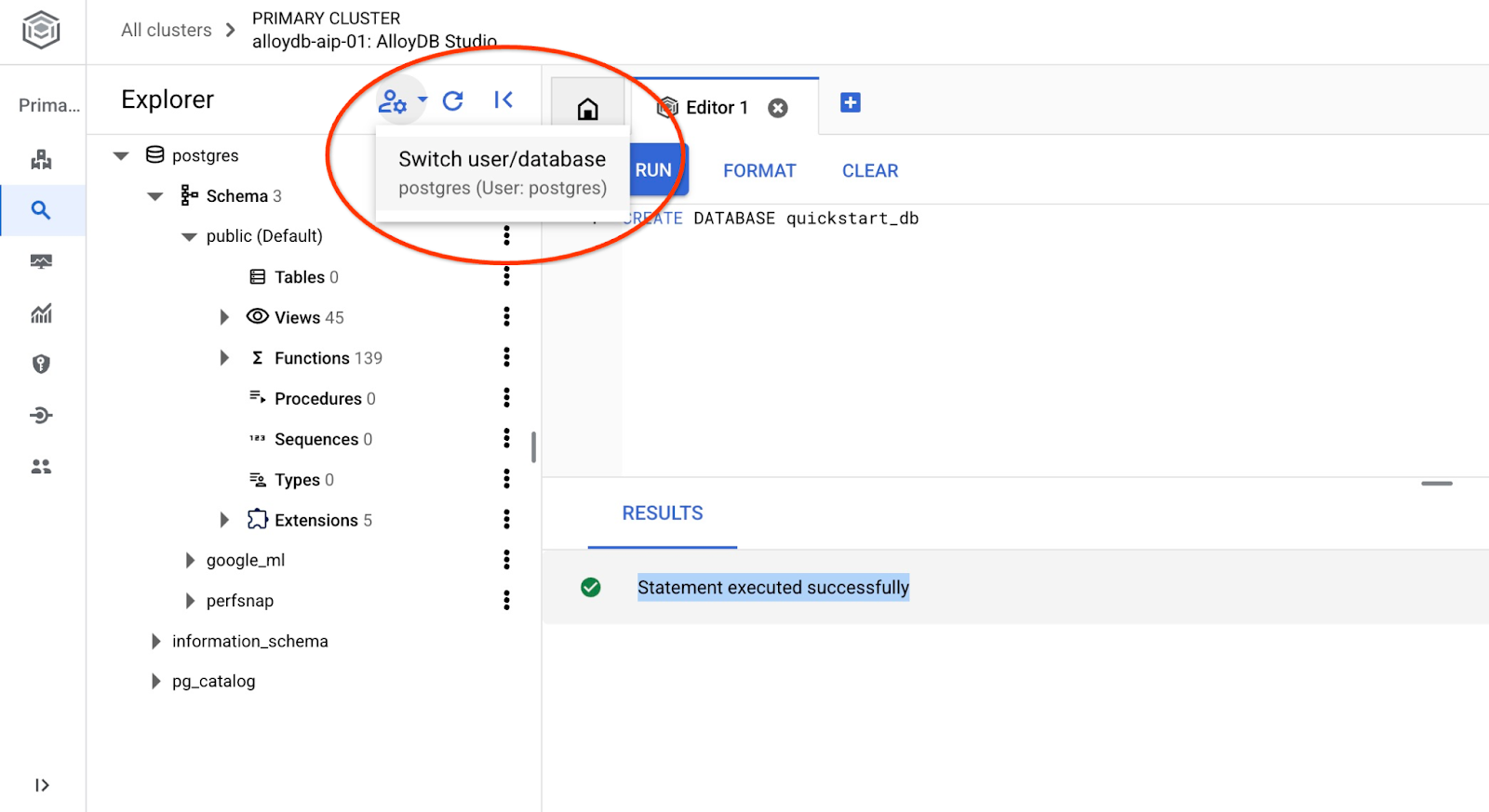
Na liście rozwijanej wybierz nową bazę danych quickstart_db i użyj tych samych danych logowania co wcześniej.
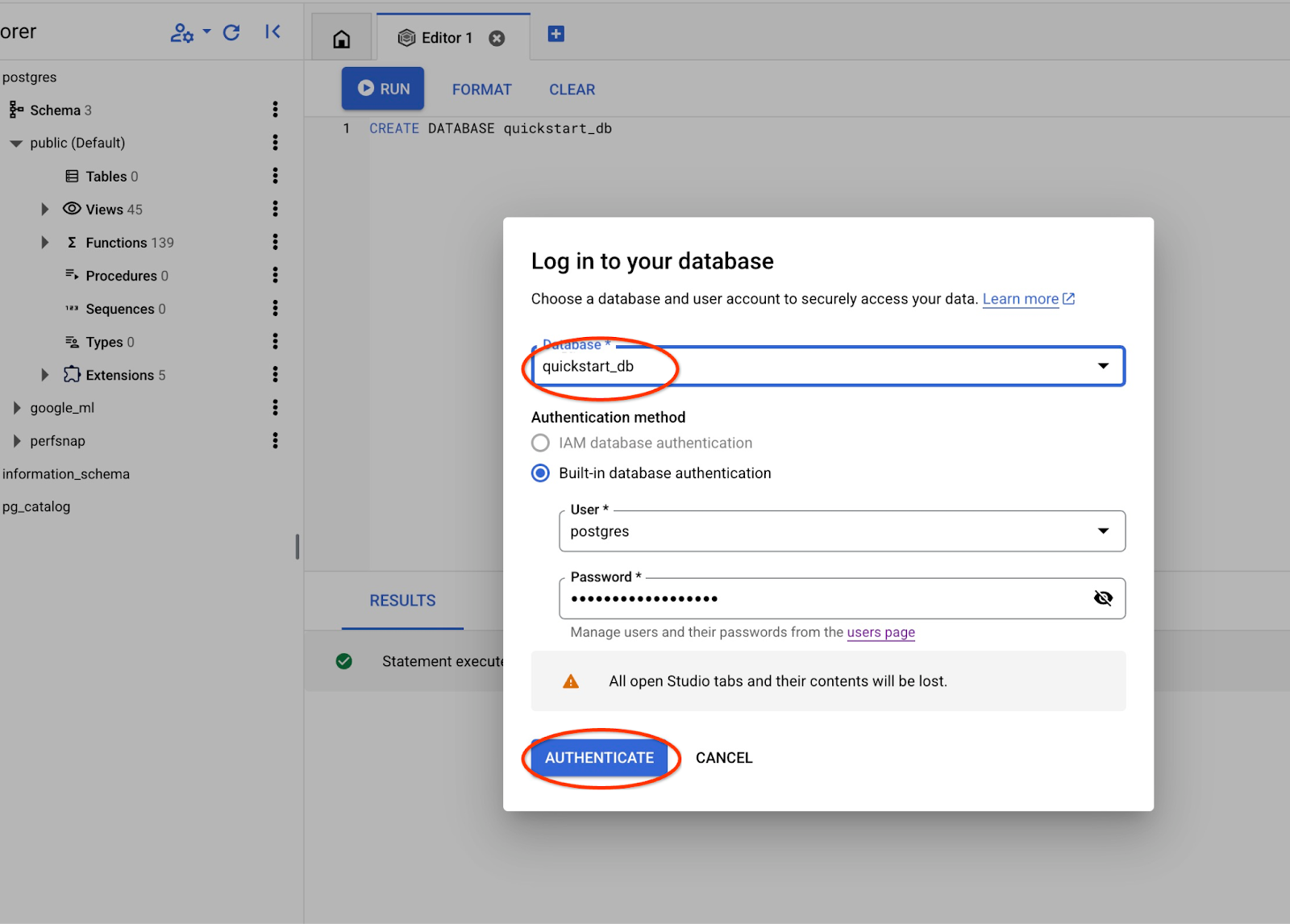
Otworzy się nowe połączenie, w którym możesz pracować z obiektami z bazy danych quickstart_db.
6. Przykładowe dane
Teraz musimy utworzyć obiekty w bazie danych i załadować dane. Użyjemy fikcyjnego sklepu „Cymbal ecomm” z zestawem tabel dla sklepów internetowych. Zawiera kilka tabel połączonych kluczami, które przypominają schemat relacyjnej bazy danych.
Zbiór danych jest przygotowywany i umieszczany jako plik SQL, który można wczytać do bazy danych za pomocą interfejsu importu. W Cloud Shell wykonaj te polecenia:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic.sql' --user=postgres --sql
Polecenie korzysta z pakietu AlloyDB SDK, tworzy schemat ecomm, a następnie importuje przykładowe dane bezpośrednio z zasobnika GCS do bazy danych, tworząc wszystkie niezbędne obiekty i wstawiając dane.
Po zaimportowaniu możemy sprawdzić tabele w AlloyDB Studio.
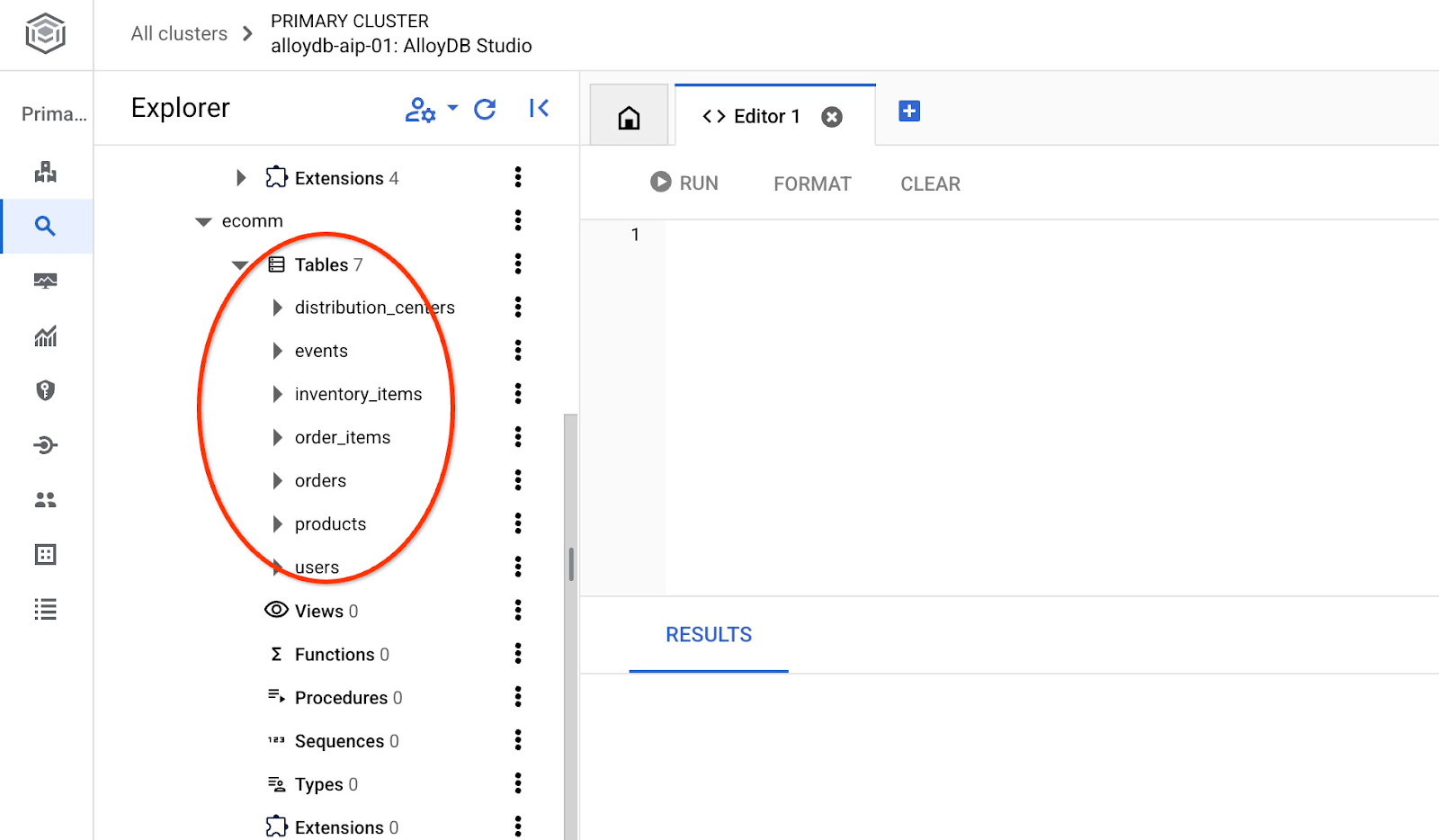
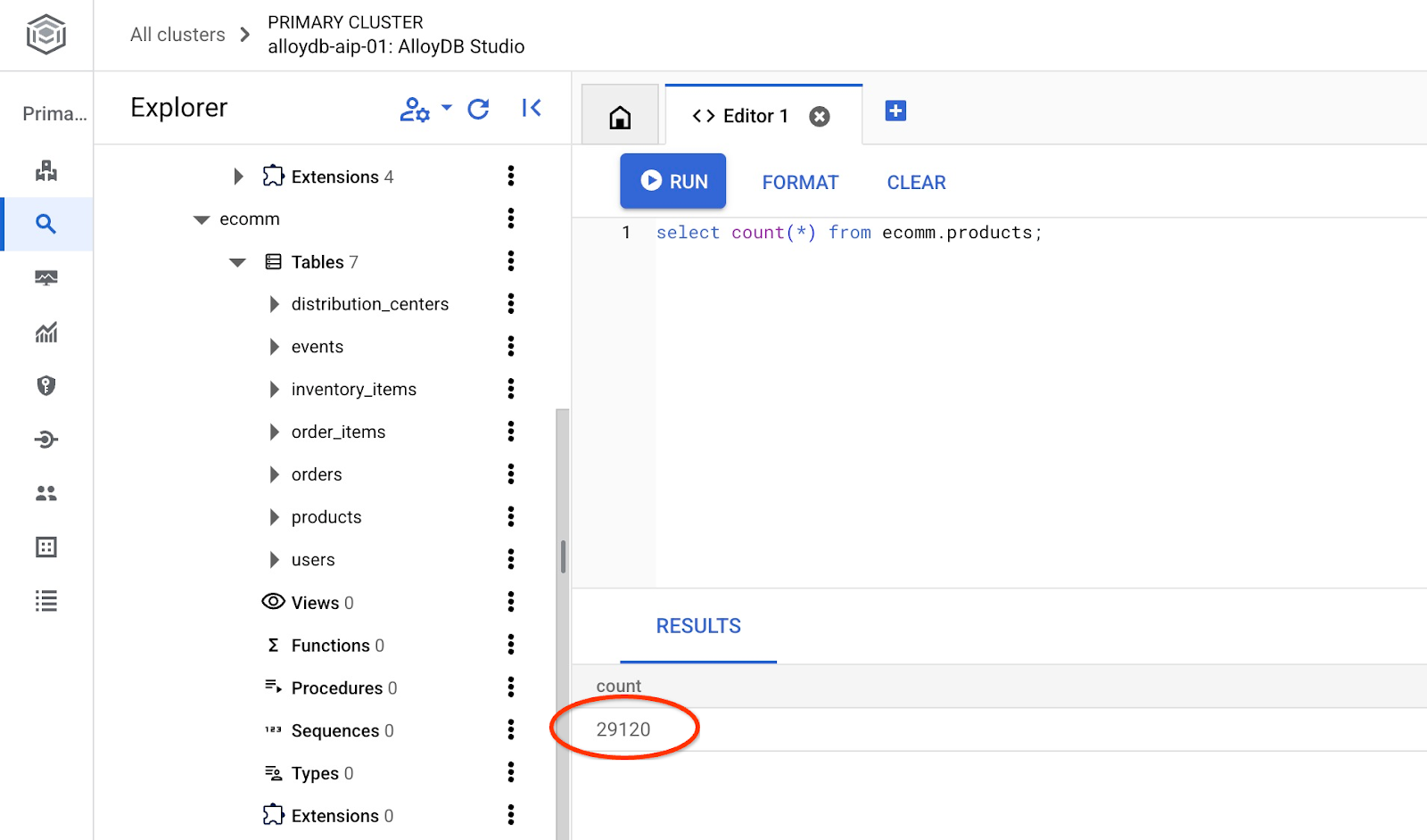
Sprawdź liczbę wierszy w tabeli.
7. Konfigurowanie NL SQL
W tym rozdziale skonfigurujemy NL do współpracy z przykładowym schematem
Instalowanie rozszerzenia alloydb_nl_ai
Musimy zainstalować w bazie danych rozszerzenie alloydb_ai_nl. Zanim to zrobimy, musimy ustawić flagę bazy danych alloydb_ai_nl.enabled na wartość on.
W sesji Cloud Shell wykonaj
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb instances update $ADBCLUSTER-pr \
--cluster=$ADBCLUSTER \
--region=$REGION \
--database-flags=alloydb_ai_nl.enabled=on
Spowoduje to rozpoczęcie aktualizacji instancji. Stan aktualizacji instancji możesz sprawdzić w konsoli internetowej:
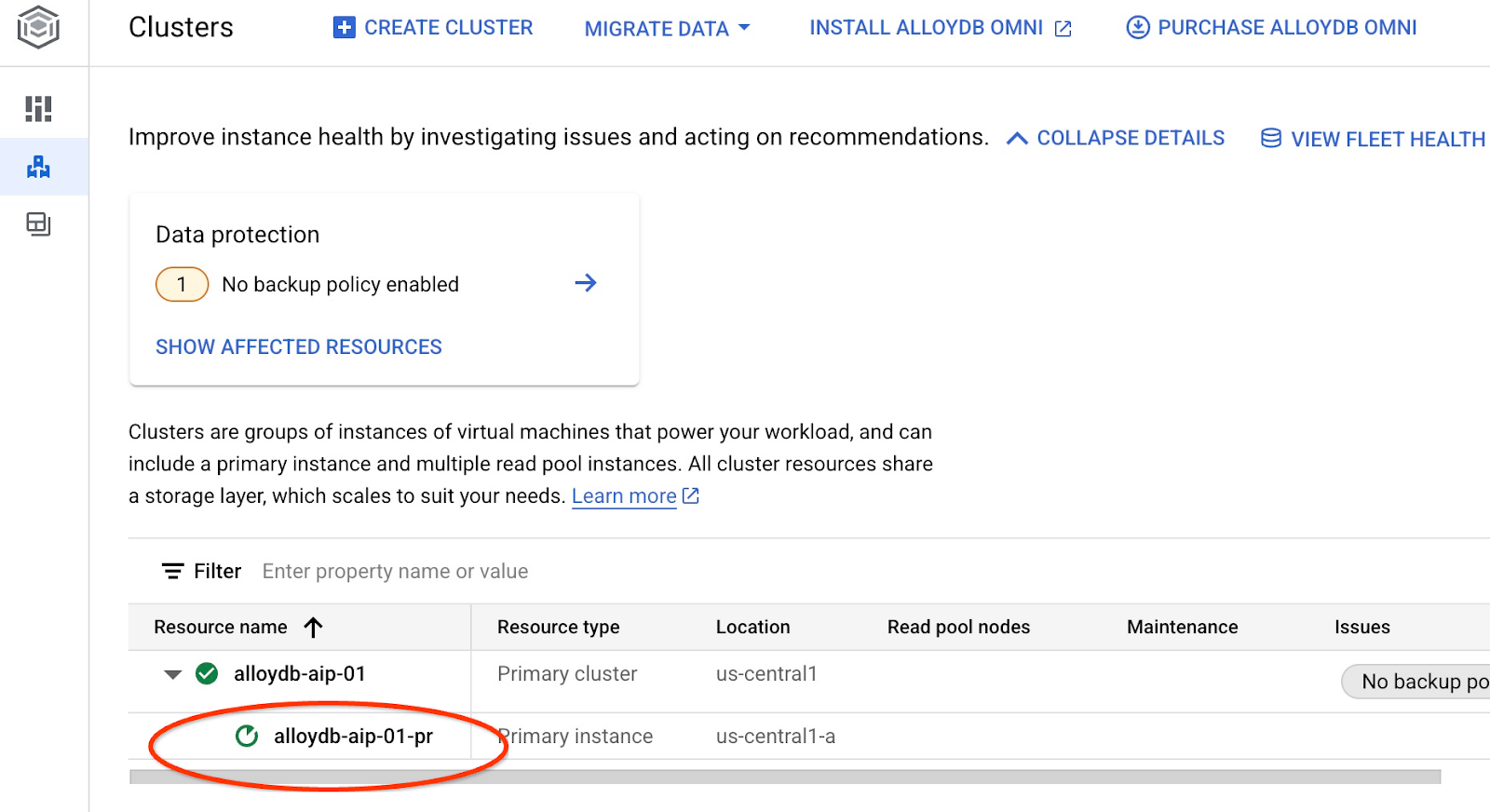
Gdy instancja zostanie zaktualizowana (jej stan będzie oznaczony kolorem zielonym), możesz włączyć rozszerzenie alloydb_ai_nl.
W AlloyDB Studio wykonaj
CREATE EXTENSION IF NOT EXISTS google_ml_integration;
CREATE EXTENSION alloydb_ai_nl cascade;
Tworzenie konfiguracji w języku naturalnym
Aby korzystać z rozszerzeń, musimy utworzyć konfigurację. Konfiguracja jest niezbędna do powiązania aplikacji z określonymi schematami, szablonami zapytań i punktami końcowymi modelu. Utwórzmy konfigurację o identyfikatorze cymbal_ecomm_config.
W AlloyDB Studio wykonaj
SELECT
alloydb_ai_nl.g_create_configuration(
configuration_id => 'cymbal_ecomm_config'
);
Teraz możemy zarejestrować schemat e-commerce w konfiguracji. Zaimportowaliśmy dane do schematu ecomm, więc dodamy ten schemat do naszej konfiguracji NL.
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'register_schema',
configuration_id_in => 'cymbal_ecomm_config',
schema_names_in => '{ecomm}'
);
8. Dodawanie kontekstu do zapytań SQL w języku naturalnym
Dodawanie ogólnego kontekstu
Możemy dodać kontekst do zarejestrowanego schematu. Kontekst ma pomagać w generowaniu lepszych wyników w odpowiedzi na prośby użytkowników. Możemy na przykład stwierdzić, że dana marka jest preferowaną marką użytkownika, nawet jeśli nie jest to wyraźnie określone. Ustawmy Clades (fikcyjną markę) jako domyślną.
W AlloyDB Studio wykonaj te czynności:
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'add_general_context',
configuration_id_in => 'cymbal_ecomm_config',
general_context_in => '{"If the user doesn''t clearly define preferred brand then use Clades."}'
);
Sprawdźmy, jak działa kontekst ogólny.
W AlloyDB Studio wykonaj te czynności:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
);
Wygenerowane zapytanie używa naszej domyślnej marki zdefiniowanej wcześniej w kontekście ogólnym:
{"sql": "SELECT count(*) FROM \"ecomm\".\"products\" WHERE \"brand\" = 'Clades'", "method": "default", "prompt": "", "retries": 0, "time(ms)": {"llm": 505.628000, "magic": 424.019000}, "error_msg": "", "nl_question": "How many products do we have of our preferred brand?", "toolbox_used": false}
Możemy go oczyścić i wygenerować tylko instrukcję SQL.
Na przykład:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Wyczyszczone dane wyjściowe:
SELECT count(*) FROM "ecomm"."products" WHERE "brand" = 'Clades'
Zauważysz, że automatycznie wybrał tabelę inventory_items zamiast tabeli products i użył jej do utworzenia zapytania. W niektórych przypadkach może to działać, ale nie w naszym schemacie. W naszym przypadku tabela inventory_items służy do śledzenia sprzedaży, co może być mylące, jeśli nie masz informacji wewnętrznych. Później sprawdzimy, jak zwiększyć dokładność zapytań.
Kontekst schematu
Kontekst schematu opisuje obiekty schematu, takie jak tabele, widoki i poszczególne kolumny, które przechowują informacje w postaci komentarzy w obiektach schematu.
Możemy utworzyć go automatycznie dla wszystkich obiektów schematu w zdefiniowanej konfiguracji za pomocą tego zapytania:
SELECT
alloydb_ai_nl.generate_schema_context(
nl_config_id => 'cymbal_ecomm_config',
overwrite_if_exist => TRUE
);
Parametr „TRUE” nakazuje nam ponowne wygenerowanie kontekstu i zastąpienie nim poprzedniego. Wykonanie zajmie trochę czasu w zależności od modelu danych. Im więcej masz relacji i połączeń, tym dłużej może to potrwać.
Po utworzeniu kontekstu możemy sprawdzić, co zostało utworzone w tabeli elementów asortymentu, za pomocą zapytania:
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.inventory_items';
Wyczyszczone dane wyjściowe:
The `ecomm.inventory_items` table stores information about individual inventory items in an e-commerce system. Each item is uniquely identified by an `id` (primary key). The table tracks the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn't been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men's and women's apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.
W opisie brakuje kluczowych informacji, które odzwierciedlają ruch produktów w tabeli inventory_items. Możemy to zrobić, dodając te kluczowe informacje do kontekstu relacji ecomm.inventory_items.
SELECT alloydb_ai_nl.update_generated_relation_context(
relation_name => 'ecomm.inventory_items',
relation_context => 'The `ecomm.inventory_items` table stores information about moving and sales of inventory items in an e-commerce system. Each movement is uniquely identified by an `id` (primary key) and used in order_items table as `inventory_item_id`. The table tracks sales and movements for the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the movement for the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn''t been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men''s and women''s apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.'
);
Możemy też sprawdzić poprawność opisu w tabeli produktów.
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.products';
Automatycznie wygenerowany kontekst tabeli produktów okazał się dość dokładny i nie wymagał żadnych zmian.
Sprawdziłem też informacje o każdej kolumnie w obu tabelach i uznałem, że są prawidłowe.
Zastosujmy wygenerowany kontekst dla parametrów ecomm.inventory_items i ecomm.products w naszej konfiguracji.
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.inventory_items',
overwrite_if_exist => TRUE
);
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.products',
overwrite_if_exist => TRUE
);
Pamiętasz nasze zapytanie do wygenerowania kodu SQL dla pytania „Ile produktów naszej ulubionej marki mamy w ofercie?” ? Teraz możemy powtórzyć tę czynność i sprawdzić, czy wynik się zmienił.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Oto nowe dane wyjściowe.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
Teraz sprawdza ecomm.products, co jest dokładniejsze i zwraca około 300 produktów zamiast 5000 operacji z elementami asortymentu.
9. Praca z indeksem wartości
Łączenie wartości wzbogaca zapytania w języku naturalnym, łącząc wyrażenia wartości z wcześniej zarejestrowanymi typami pojęć i nazwami kolumn. Może to pomóc w uzyskiwaniu bardziej przewidywalnych wyników.
Konfigurowanie indeksu wartości
Zapytania możemy tworzyć za pomocą kolumny „Marka” w tabeli produktów i wyszukiwać produkty z bardziej stabilnymi markami, definiując typ pojęcia i łącząc go z kolumną ecomm.products.brand.
Utwórzmy pojęcie i powiążmy je z kolumną:
SELECT alloydb_ai_nl.add_concept_type(
concept_type_in => 'brand_name',
match_function_in => 'alloydb_ai_nl.get_concept_and_value_generic_entity_name',
additional_info_in => '{
"description": "Concept type for brand name.",
"examples": "SELECT alloydb_ai_nl.get_concept_and_value_generic_entity_name(''Auto Forge'')" }'::jsonb
);
SELECT alloydb_ai_nl.associate_concept_type(
column_names_in => 'ecomm.products.brand',
concept_type_in => 'brand_name',
nl_config_id_in => 'cymbal_ecomm_config'
);
Możesz sprawdzić tę koncepcję, wysyłając zapytanie do funkcji alloydb_ai_nl.list_concept_types().
SELECT alloydb_ai_nl.list_concept_types();
Następnie możemy utworzyć indeks w naszej konfiguracji dla wszystkich utworzonych i gotowych powiązań:
SELECT alloydb_ai_nl.create_value_index(
nl_config_id_in => 'cymbal_ecomm_config'
);
Korzystanie z indeksu wartości
Jeśli uruchomisz zapytanie, aby utworzyć SQL przy użyciu nazw marek, ale nie określisz, że jest to nazwa marki, pomoże to prawidłowo zidentyfikować encję i kolumnę. Oto zapytanie:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many Clades do we have?'
) ->> 'sql';
Wynik pokazuje prawidłową identyfikację słowa „Clades” jako nazwy marki.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
10. Korzystanie z szablonów zapytań
Szablony zapytań pomagają definiować stabilne zapytania dotyczące aplikacji o kluczowym znaczeniu dla firmy, co zmniejsza niepewność i zwiększa dokładność.
Tworzenie szablonu zapytania
Utwórzmy szablon zapytania, który łączy kilka tabel, aby uzyskać informacje o klientach, którzy w zeszłym roku kupili produkty „Republic Outpost”. Wiemy, że zapytanie może korzystać z tabeli ecomm.products lub ecomm.inventory_items, ponieważ obie zawierają informacje o markach. Tabela products ma jednak 15 razy mniej wierszy i indeks klucza podstawowego do łączenia. Bardziej efektywne może być użycie tabeli produktów. Tworzymy więc szablon zapytania.
SELECT alloydb_ai_nl.add_template(
nl_config_id => 'cymbal_ecomm_config',
intent => 'List the last names and the country of all customers who bought products of `Republic Outpost` in the last year.',
sql => 'SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = ''Republic Outpost'' AND oi.created_at >= DATE_TRUNC(''year'', CURRENT_DATE - INTERVAL ''1 year'') AND oi.created_at < DATE_TRUNC(''year'', CURRENT_DATE)',
sql_explanation => 'To answer this question, JOIN `ecomm.users` with `ecom.order_items` on having the same `users.id` and `order_items.user_id`, and JOIN the result with ecom.products on having the same `order_items.product_id` and `products.id`. Then filter rows with products.brand = ''Republic Outpost'' and by `order_items.created_at` for the last year. Return the `last_name` and the `country` of the users with matching records.',
check_intent => TRUE
);
Możemy teraz poprosić o utworzenie zapytania.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
) ->> 'sql';
i generuje pożądane dane wyjściowe.
SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = 'Republic Outpost' AND oi.created_at >= DATE_TRUNC('year', CURRENT_DATE - INTERVAL '1 year') AND oi.created_at < DATE_TRUNC('year', CURRENT_DATE)
Możesz też wykonać zapytanie bezpośrednio, używając tego zapytania:
SELECT
alloydb_ai_nl.execute_nl_query(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
);
Zwróci wyniki w formacie JSON, które można przeanalizować.
execute_nl_query
--------------------------------------------------------
{"last_name":"Adams","country":"China"}
{"last_name":"Adams","country":"Germany"}
{"last_name":"Aguilar","country":"China"}
{"last_name":"Allen","country":"China"}
11. Zwalnianie miejsca w środowisku
Po zakończeniu modułu zniszcz instancje i klaster AlloyDB.
Usuwanie klastra AlloyDB i wszystkich instancji
Jeśli korzystasz z wersji próbnej AlloyDB. Nie usuwaj klastra próbnego, jeśli planujesz testować inne laboratoria i zasoby przy użyciu tego klastra. Nie będzie można utworzyć kolejnego klastra próbnego w tym samym projekcie.
Klaster zostanie zniszczony z opcją force, która powoduje też usunięcie wszystkich instancji należących do klastra.
W Cloud Shell zdefiniuj projekt i zmienne środowiskowe, jeśli połączenie zostało przerwane i wszystkie poprzednie ustawienia zostały utracone:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Usuń klaster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Usuwanie kopii zapasowych AlloyDB
Usuń wszystkie kopie zapasowe AlloyDB dla klastra:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Gratulacje
Gratulujemy ukończenia ćwiczenia. Możesz teraz spróbować wdrożyć własne rozwiązania przy użyciu funkcji NL2SQL w AlloyDB. Zachęcamy do wypróbowania innych ćwiczeń z programowania związanych z AlloyDB i AlloyDB AI. Możesz sprawdzić, jak działają wielomodalne wektory dystrybucyjne w AlloyDB, w tych ćwiczeniach.
Omówione zagadnienia
- Wdrażanie AlloyDB for Postgres
- Włączanie języka naturalnego w AlloyDB AI
- Jak tworzyć i dostosowywać konfigurację AI w języku naturalnym
- Jak generować zapytania SQL i uzyskiwać wyniki za pomocą języka naturalnego
13. Ankieta
Dane wyjściowe: