
1. Introdução
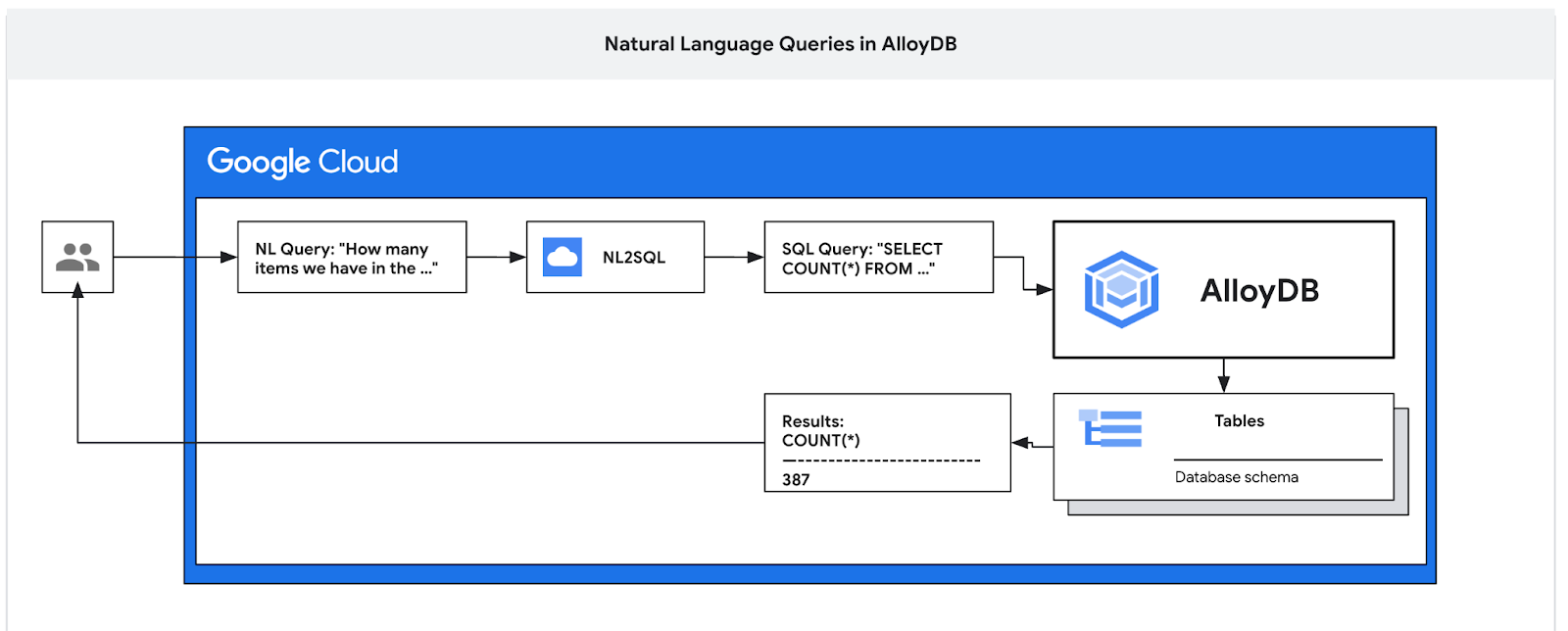
Neste codelab, você vai aprender a implantar o AlloyDB e usar a linguagem natural da IA para consultar dados e ajustar a configuração para consultas previsíveis e eficientes. Este laboratório faz parte de uma coleção dedicada aos recursos de IA do AlloyDB. Leia mais na página da IA do AlloyDB na documentação.
Pré-requisitos
- Conhecimentos básicos sobre o Google Cloud e o console
- Habilidades básicas na interface de linha de comando e no Cloud Shell
O que você vai aprender
- Como implantar o AlloyDB para Postgres
- Como ativar a linguagem natural da IA do AlloyDB
- Como criar e ajustar a configuração para linguagem natural de IA
- Como gerar consultas SQL e receber resultados usando linguagem natural
O que é necessário
- Uma conta e um projeto do Google Cloud
- Um navegador da Web, como o Chrome, que seja compatível com o console do Google Cloud e o Cloud Shell
2. Configuração e requisitos
Configuração de ambiente autoguiada
- Faça login no Console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.

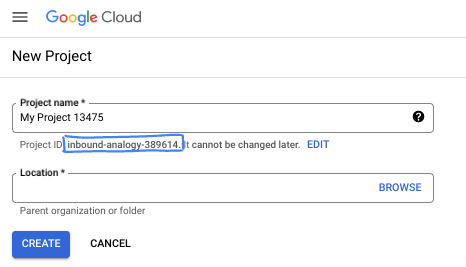
- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
3. Antes de começar
Ativar API
No Cloud Shell, verifique se o ID do projeto está configurado:
gcloud config set project [YOUR-PROJECT-ID]
Defina a variável de ambiente PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Ative todos os serviços necessários:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Resultado esperado
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Implantar o AlloyDB
Crie um cluster do AlloyDB e uma instância principal. O procedimento a seguir descreve como criar um cluster e uma instância do AlloyDB usando o SDK do Google Cloud. Se preferir a abordagem do console, siga a documentação aqui.
Antes de criar um cluster do AlloyDB, é necessário ter um intervalo de IP privado disponível na VPC para ser usado pela instância futura do AlloyDB. Se não tivermos, precisamos criar e atribuir para uso por serviços internos do Google. Depois disso, será possível criar o cluster e a instância.
Criar um intervalo de IP privado
É preciso configurar o Acesso a serviços particulares na VPC para o AlloyDB. Vamos supor que o projeto tem uma rede VPC "padrão" a ser usada para todas as ações.
Crie o intervalo de IP privado:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Crie uma conexão privada com o intervalo de IP alocado:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Criar cluster do AlloyDB
Nesta seção, vamos criar um cluster do AlloyDB na região us-central1.
Defina a senha do usuário postgres. Você pode definir sua própria senha ou usar uma função aleatória para gerar uma.
export PGPASSWORD=`openssl rand -hex 12`
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Anote a senha do PostgreSQL para uso futuro.
echo $PGPASSWORD
Você vai precisar dessa senha no futuro para se conectar à instância como o usuário postgres. Recomendamos que você anote ou copie em algum lugar para usar depois.
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Criar um cluster de teste sem custo financeiro
Se você nunca usou o AlloyDB, crie um cluster de teste sem custo financeiro:
Defina a região e o nome do cluster do AlloyDB. Vamos usar a região us-central1 e alloydb-aip-01 como nome do cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Execute o comando para criar o cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Saída esperada do console:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crie uma instância principal do AlloyDB para o cluster na mesma sessão do Cloud Shell. Se você se desconectar, será necessário definir as variáveis de ambiente de região e nome do cluster novamente.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Criar cluster padrão do AlloyDB
Se não for seu primeiro cluster do AlloyDB no projeto, crie um cluster padrão.
Defina a região e o nome do cluster do AlloyDB. Vamos usar a região us-central1 e alloydb-aip-01 como nome do cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Execute o comando para criar o cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Saída esperada do console:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crie uma instância principal do AlloyDB para o cluster na mesma sessão do Cloud Shell. Se você se desconectar, será necessário definir as variáveis de ambiente de região e nome do cluster novamente.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Preparar banco de dados
Precisamos criar um banco de dados, ativar a integração da Vertex AI, criar objetos de banco de dados e importar os dados.
Conceder as permissões necessárias ao AlloyDB
Adicione permissões da Vertex AI ao agente de serviço do AlloyDB.
Abra outra guia do Cloud Shell pelo sinal "+" na parte superior.
Na nova guia do Cloud Shell, execute:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Feche a guia pelo comando de execução "sair" na guia:
exit
Conectar-se ao AlloyDB Studio
Nos capítulos a seguir, todos os comandos SQL que exigem conexão com o banco de dados podem ser executados alternativamente no AlloyDB Studio. Para executar o comando, clique na instância principal para abrir a interface do console da Web do cluster do AlloyDB.
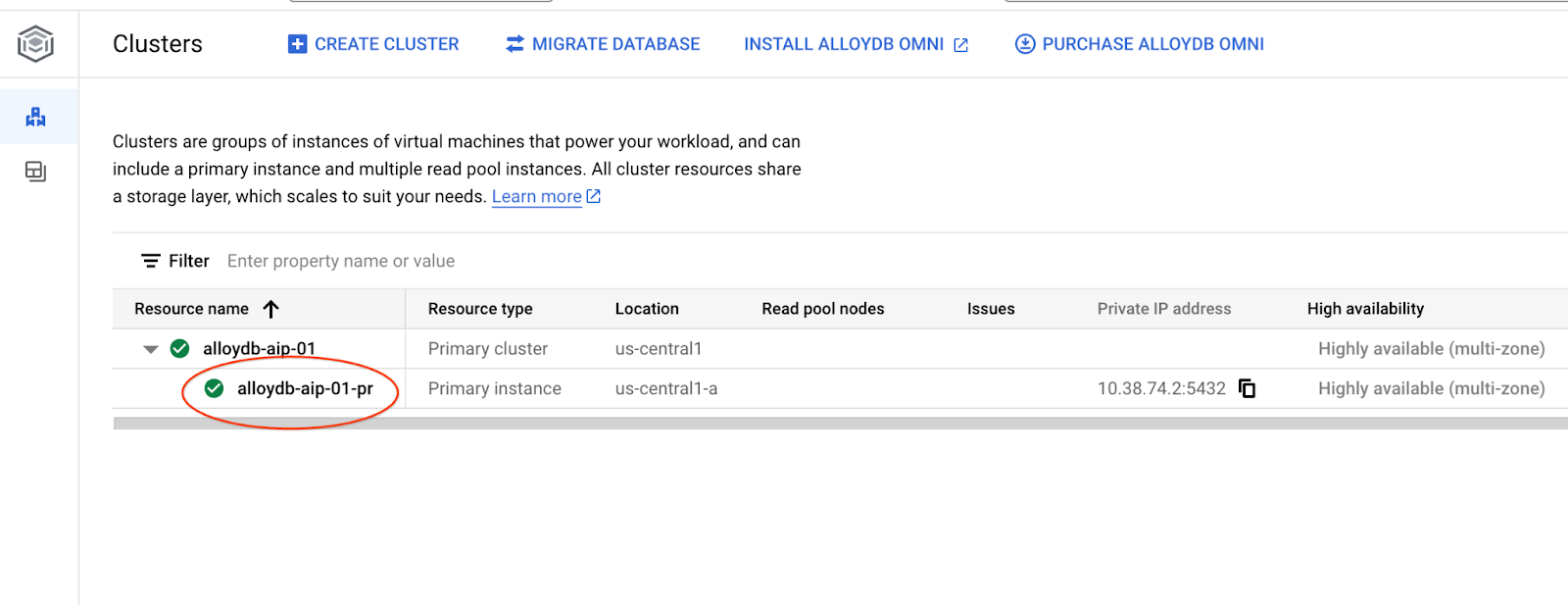
Em seguida, clique em "AlloyDB Studio" à esquerda:
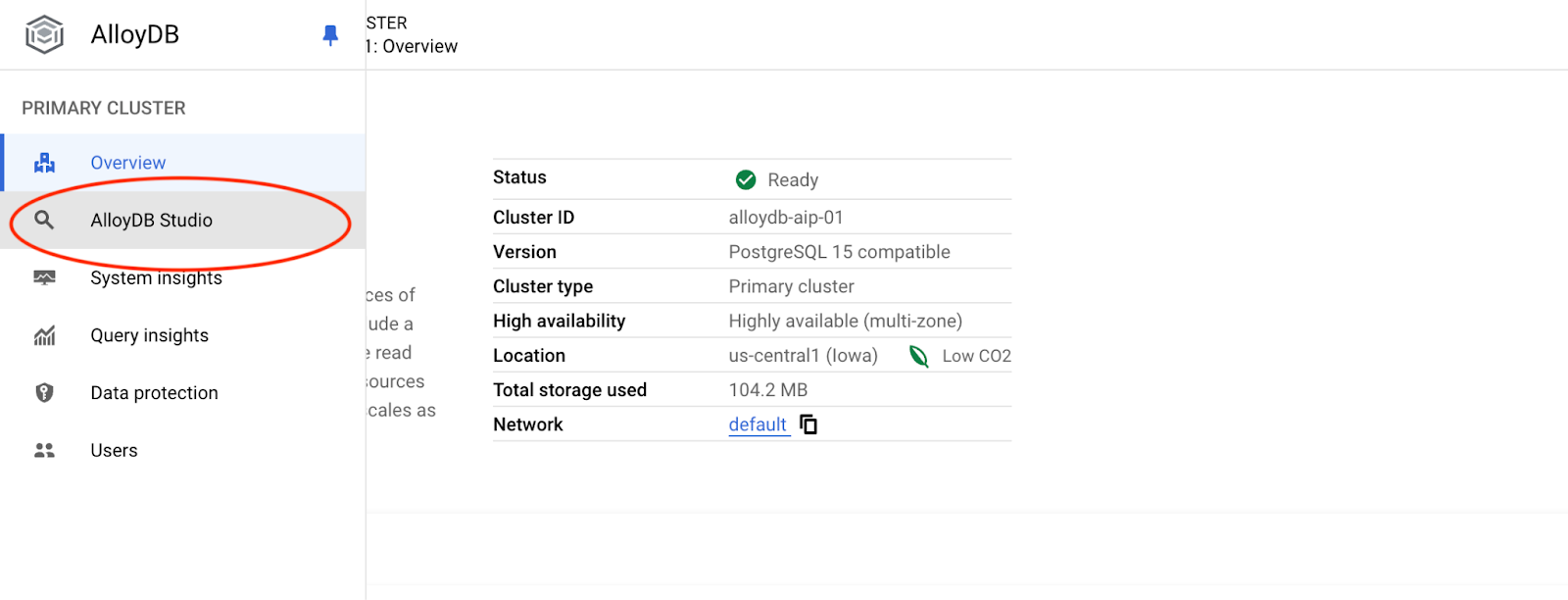
Escolha o banco de dados postgres, o usuário postgres e forneça a senha anotada quando criamos o cluster. Em seguida, clique no botão "Autenticar".
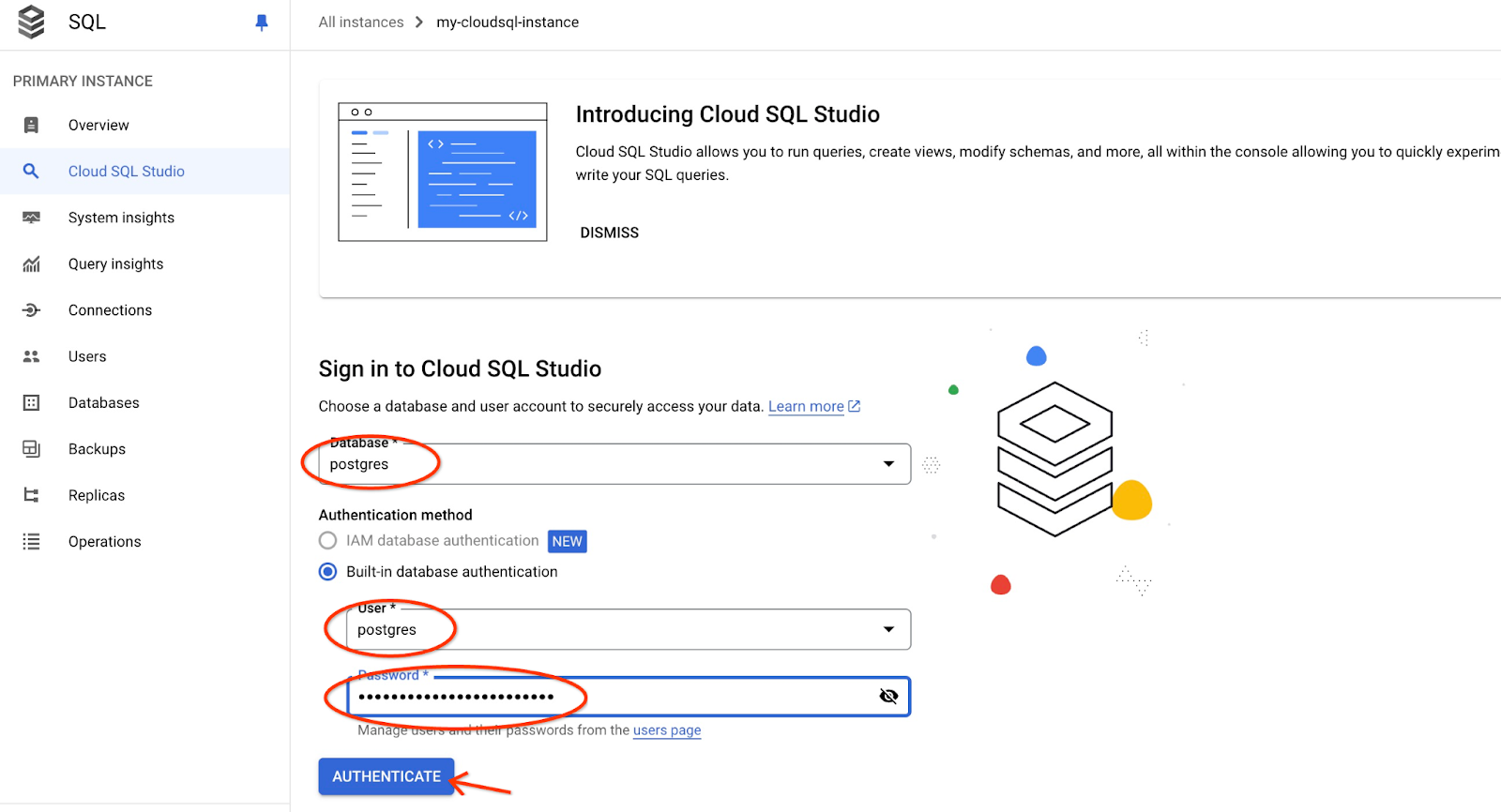
A interface do AlloyDB Studio será aberta. Para executar os comandos no banco de dados, clique na guia "Editor 1" à direita.
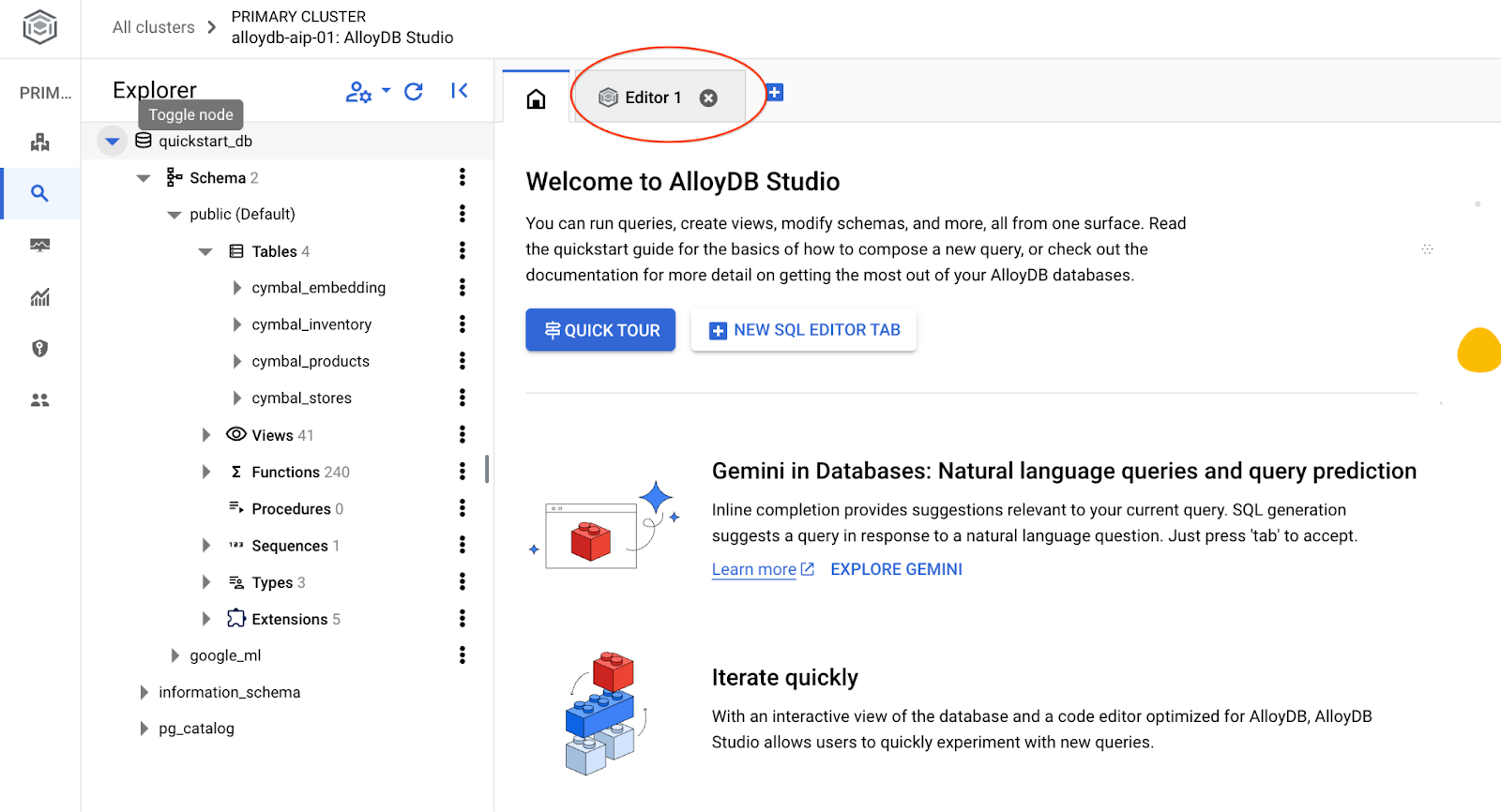
Ela abre uma interface em que é possível executar comandos SQL.
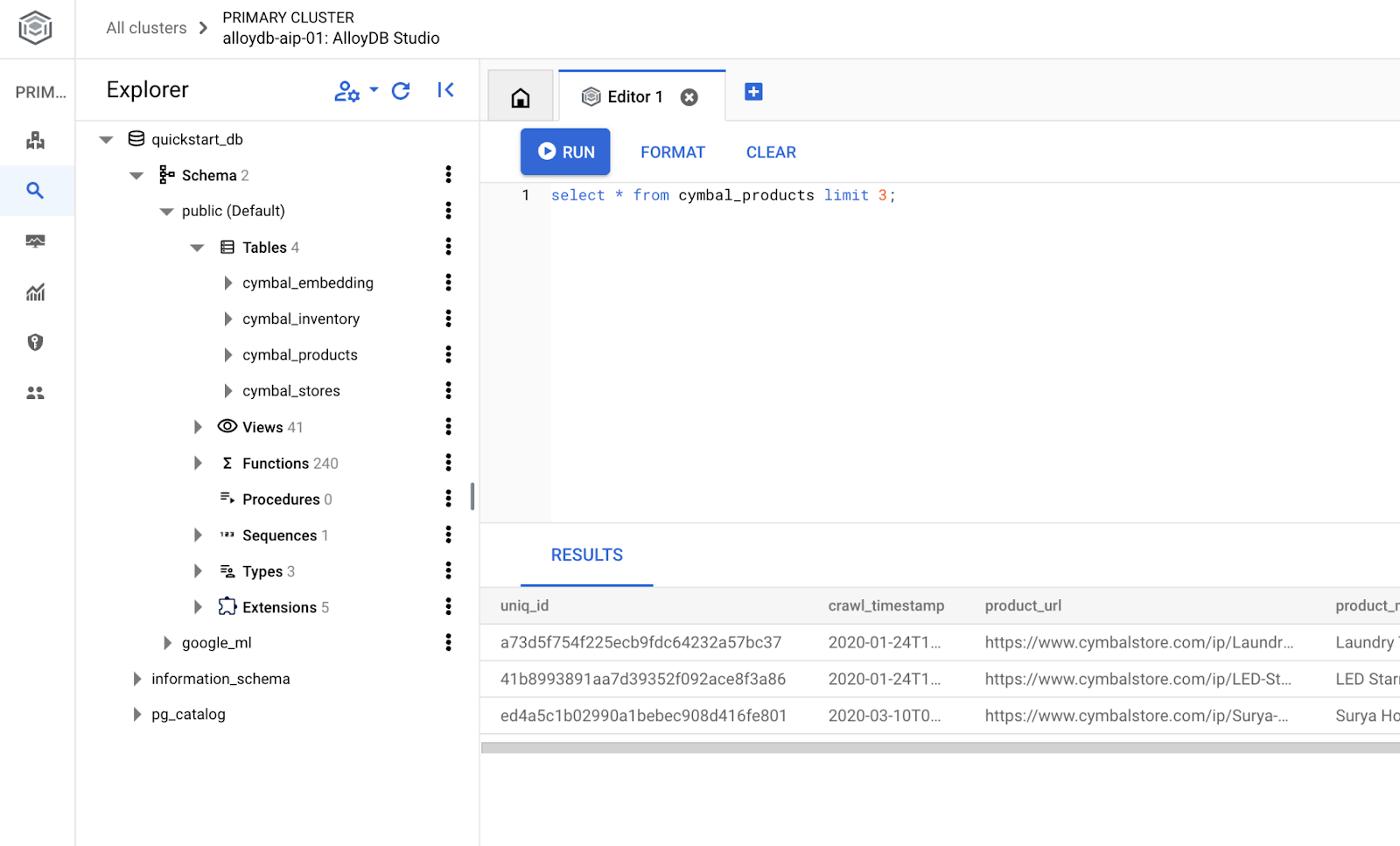
Criar banco de dados
Guia de início rápido para criar um banco de dados.
No editor do AlloyDB Studio, execute o comando a seguir.
Crie o banco de dados:
CREATE DATABASE quickstart_db
Saída esperada:
Statement executed successfully
Conectar-se a quickstart_db
Reconecte-se ao estúdio usando o botão para mudar de usuário/banco de dados.
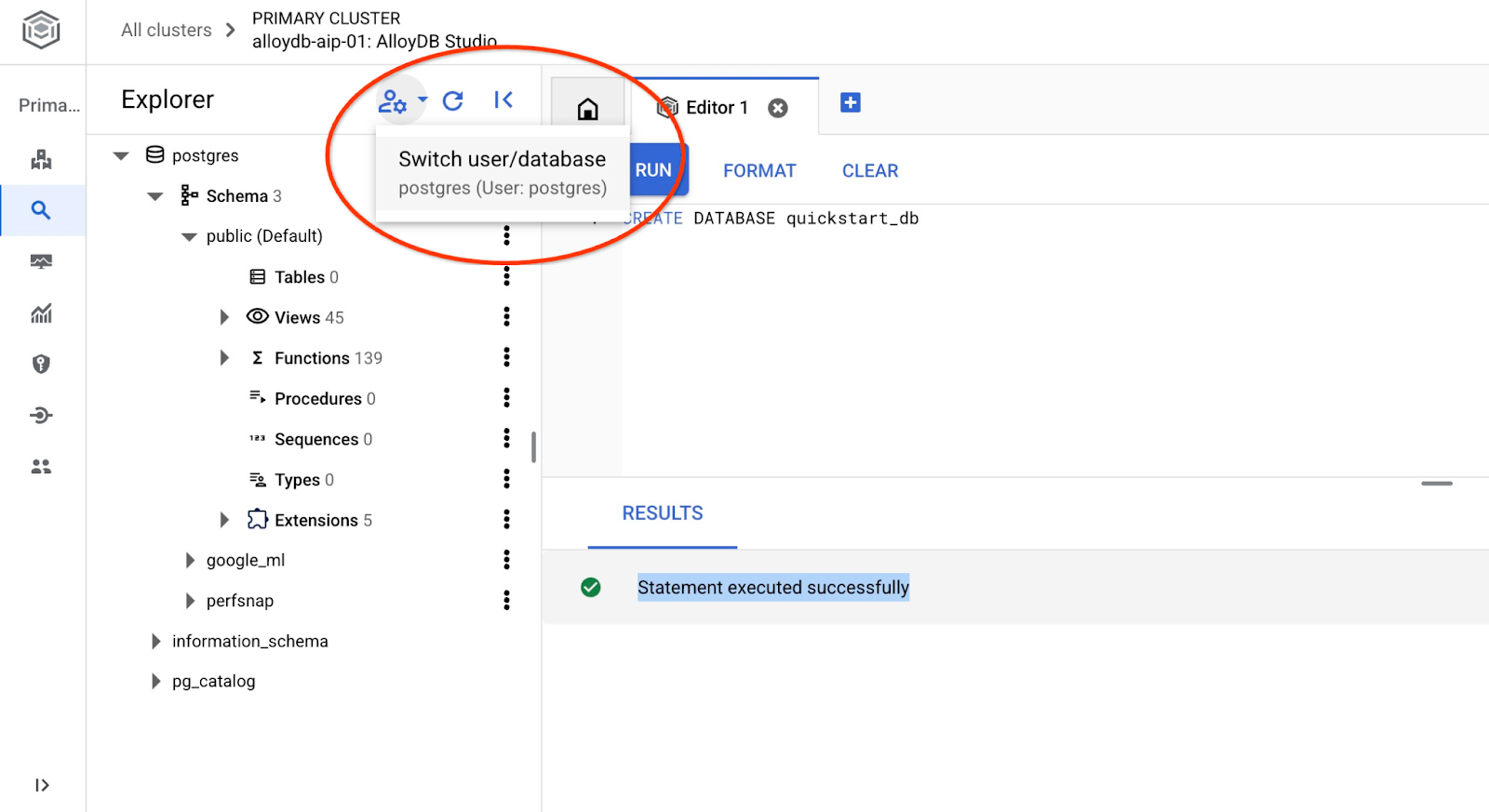
Escolha na lista suspensa o novo banco de dados quickstart_db e use o mesmo usuário e senha de antes.
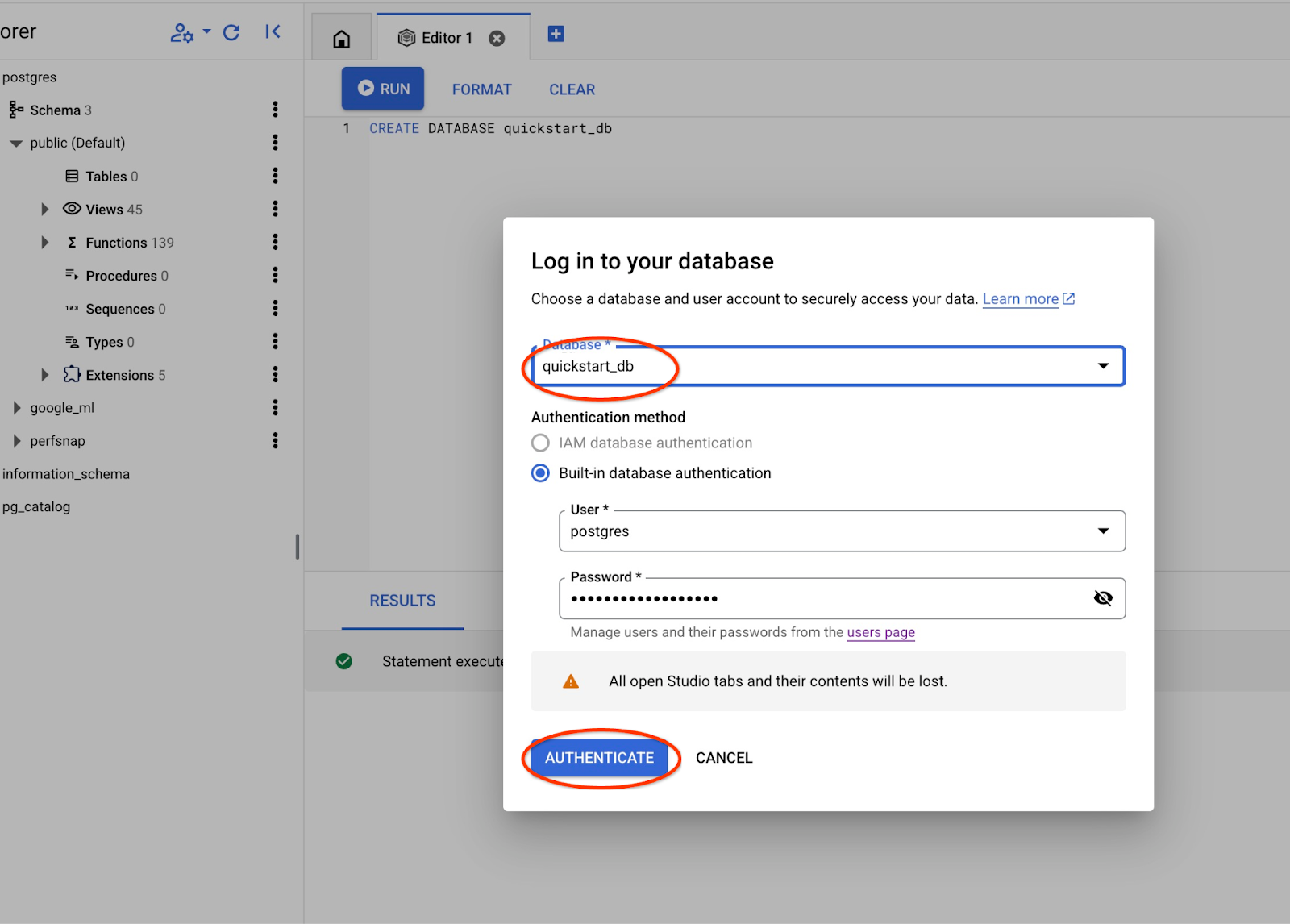
Isso vai abrir uma nova conexão em que você pode trabalhar com objetos do banco de dados quickstart_db.
6. Dados de amostra
Agora precisamos criar objetos no banco de dados e carregar dados. Vamos usar uma loja fictícia "Cymbal ecomm" com um conjunto de tabelas para lojas on-line. Ele contém várias tabelas conectadas por chaves, semelhantes a um esquema de banco de dados relacional.
O conjunto de dados é preparado e colocado como um arquivo SQL que pode ser carregado no banco de dados usando a interface de importação. No Cloud Shell, execute os seguintes comandos:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic.sql' --user=postgres --sql
O comando usa o SDK do AlloyDB e cria um esquema de e-commerce. Em seguida, importa dados de amostra diretamente do bucket do GCS para o banco de dados, criando todos os objetos necessários e inserindo dados.
Depois da importação, podemos verificar as tabelas no AlloyDB Studio.
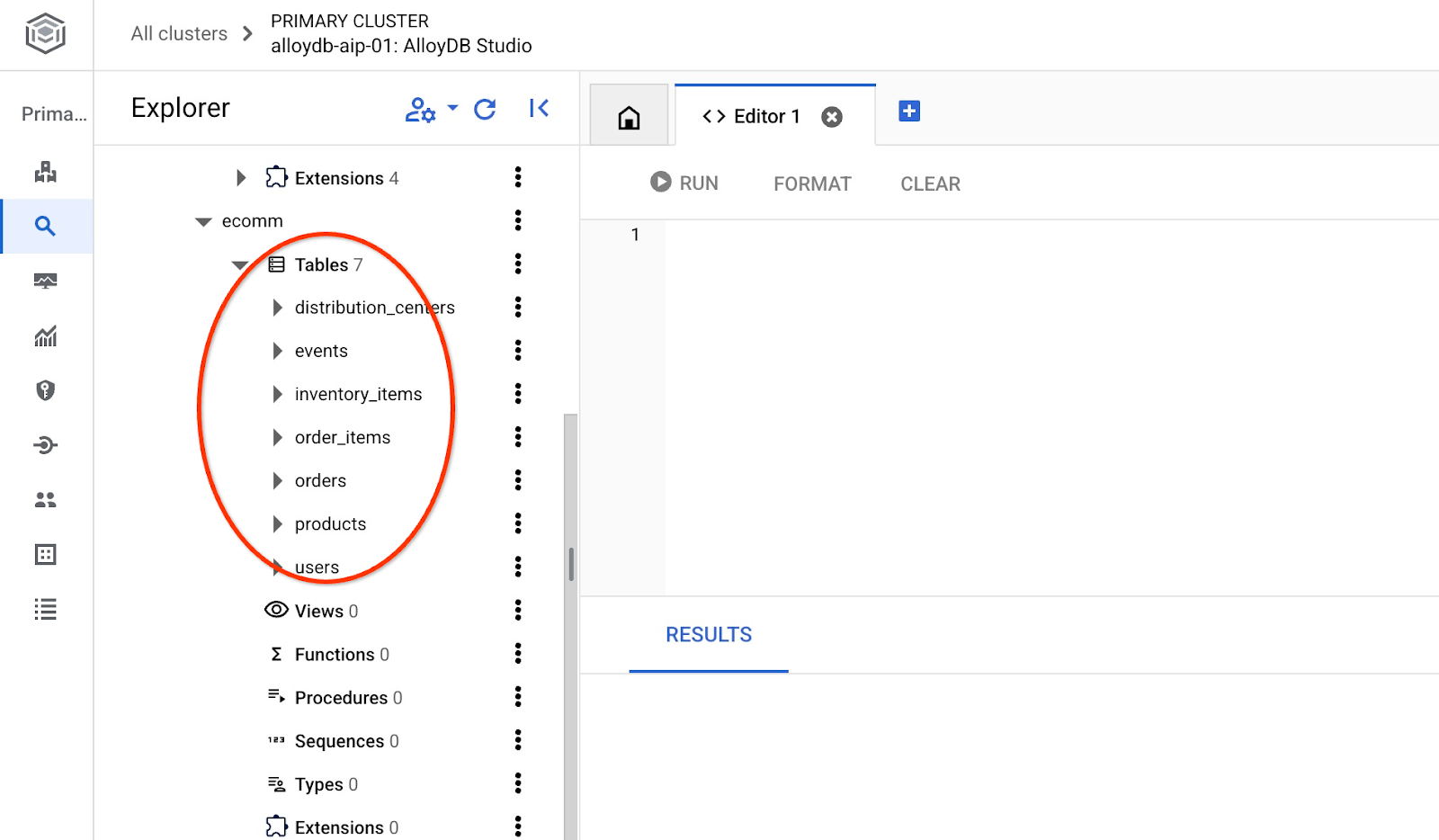
e verifique o número de linhas na tabela.
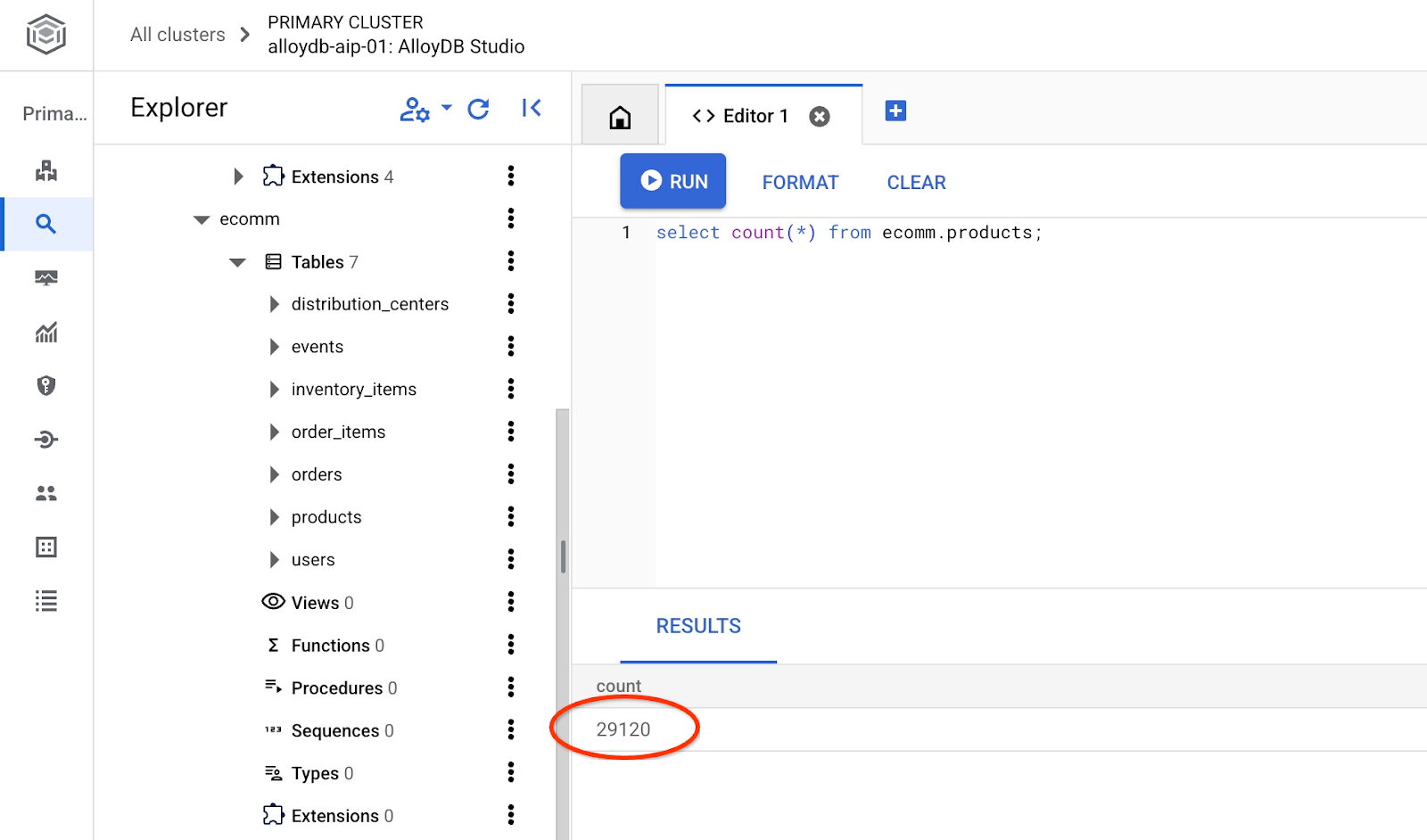
7. Configurar o NL SQL
Neste capítulo, vamos configurar a NL para trabalhar com seu esquema de amostra.
Instalar a extensão alloydb_nl_ai
Precisamos instalar a extensão alloydb_ai_nl no nosso banco de dados. Antes de fazer isso, precisamos definir a flag do banco de dados alloydb_ai_nl.enabled como "on".
Na sessão do Cloud Shell, execute
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb instances update $ADBCLUSTER-pr \
--cluster=$ADBCLUSTER \
--region=$REGION \
--database-flags=alloydb_ai_nl.enabled=on
Isso vai iniciar a atualização da instância. É possível conferir o status da instância em atualização no console da Web:
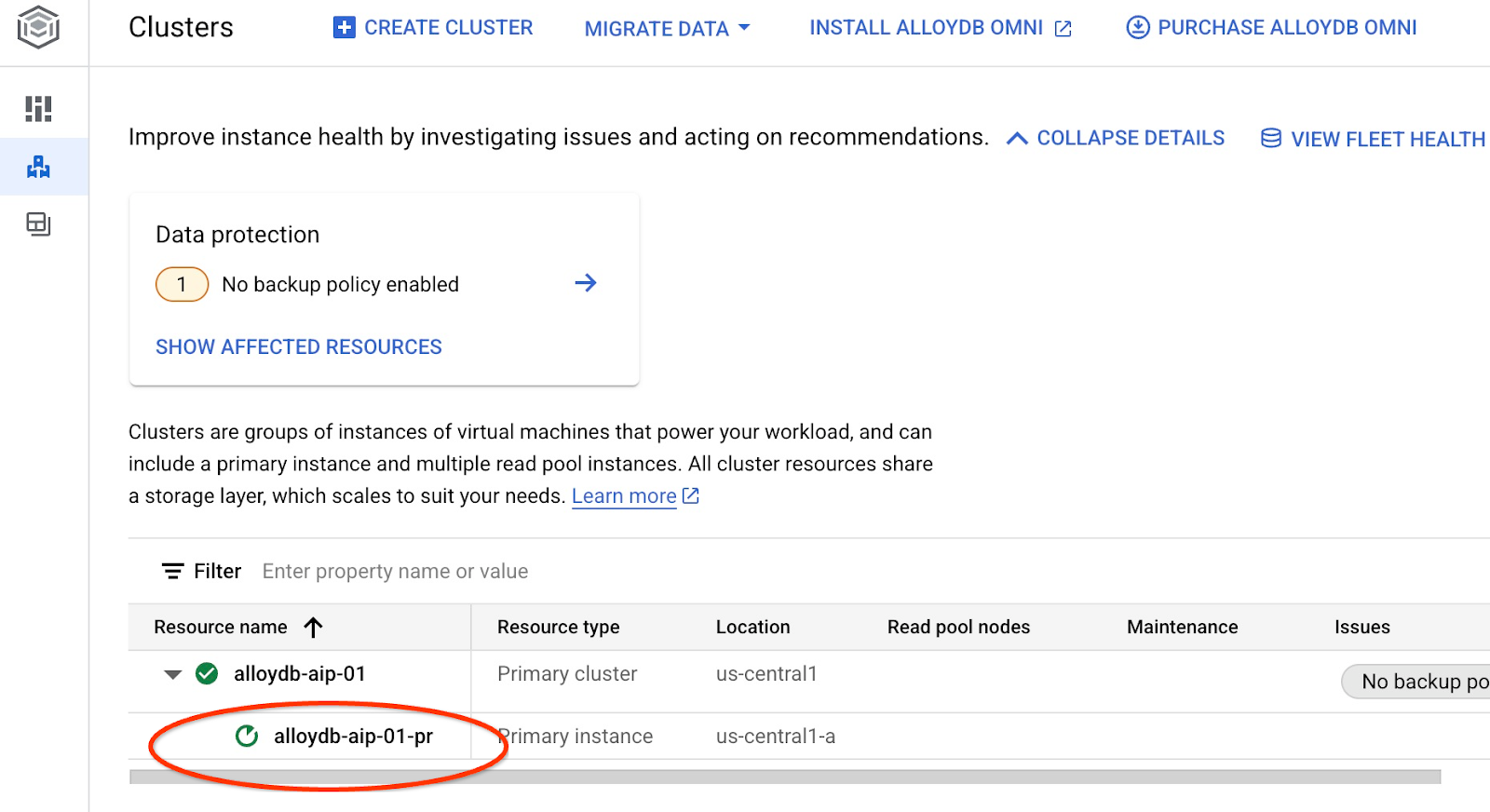
Quando a instância for atualizada (o status dela estiver verde), você poderá ativar a extensão alloydb_ai_nl.
No AlloyDB Studio, execute
CREATE EXTENSION IF NOT EXISTS google_ml_integration;
CREATE EXTENSION alloydb_ai_nl cascade;
Criar uma configuração de linguagem natural
Para usar extensões, precisamos criar uma configuração. A configuração é necessária para associar aplicativos a determinados esquemas, modelos de consulta e endpoints de modelo. Vamos criar uma configuração com o ID cymbal_ecomm_config.
No AlloyDB Studio, execute
SELECT
alloydb_ai_nl.g_create_configuration(
configuration_id => 'cymbal_ecomm_config'
);
Agora podemos registrar nosso esquema de e-commerce na configuração. Importamos dados para o esquema ecomm, então vamos adicionar esse esquema à nossa configuração de NL.
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'register_schema',
configuration_id_in => 'cymbal_ecomm_config',
schema_names_in => '{ecomm}'
);
8. Adicionar contexto ao NL SQL
Adicionar contexto geral
Podemos adicionar algum contexto ao nosso esquema registrado. O contexto ajuda a gerar resultados melhores em resposta às solicitações dos usuários. Por exemplo, podemos dizer que uma marca é a preferida de um usuário quando ela não está definida explicitamente. Vamos definir Clades (marca fictícia) como nossa marca padrão.
No AlloyDB Studio, execute:
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'add_general_context',
configuration_id_in => 'cymbal_ecomm_config',
general_context_in => '{"If the user doesn''t clearly define preferred brand then use Clades."}'
);
Vamos verificar como o contexto geral funciona para nós.
No AlloyDB Studio, execute:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
);
A consulta gerada está usando nossa marca padrão definida anteriormente no contexto geral:
{"sql": "SELECT count(*) FROM \"ecomm\".\"products\" WHERE \"brand\" = 'Clades'", "method": "default", "prompt": "", "retries": 0, "time(ms)": {"llm": 505.628000, "magic": 424.019000}, "error_msg": "", "nl_question": "How many products do we have of our preferred brand?", "toolbox_used": false}
Podemos limpar e produzir apenas a instrução SQL como saída.
Exemplo:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Saída limpa:
SELECT count(*) FROM "ecomm"."products" WHERE "brand" = 'Clades'
Você percebeu que ele escolheu automaticamente a tabela "inventory_items" em vez de "products" e a usou para criar a consulta. Isso pode funcionar para alguns casos, mas não para nosso esquema. No nosso caso, a tabela "inventory_items" serve para rastrear vendas, o que pode ser enganoso se você não tiver informações privilegiadas. Vamos verificar mais tarde como tornar nossas consultas mais precisas.
Contexto do esquema
O contexto do esquema descreve objetos de esquema, como tabelas, visualizações e colunas individuais que armazenam informações como comentários nos objetos de esquema.
Podemos criar automaticamente para todos os objetos de esquema na configuração definida usando a seguinte consulta:
SELECT
alloydb_ai_nl.generate_schema_context(
nl_config_id => 'cymbal_ecomm_config',
overwrite_if_exist => TRUE
);
O parâmetro "TRUE" nos direciona a regenerar e substituir o contexto. A execução vai levar algum tempo, dependendo do modelo de dados. Quanto mais relações e conexões você tiver, mais tempo pode levar.
Depois de criar o contexto, podemos verificar o que ele criou para a tabela de itens de inventário usando a consulta:
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.inventory_items';
Saída limpa:
The `ecomm.inventory_items` table stores information about individual inventory items in an e-commerce system. Each item is uniquely identified by an `id` (primary key). The table tracks the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn't been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men's and women's apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.
Parece que a descrição está faltando algumas partes importantes que a tabela "inventory_items" reflete o movimento dos itens. Podemos atualizar adicionando essas informações importantes ao contexto da relação ecomm.inventory_items.
SELECT alloydb_ai_nl.update_generated_relation_context(
relation_name => 'ecomm.inventory_items',
relation_context => 'The `ecomm.inventory_items` table stores information about moving and sales of inventory items in an e-commerce system. Each movement is uniquely identified by an `id` (primary key) and used in order_items table as `inventory_item_id`. The table tracks sales and movements for the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the movement for the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn''t been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men''s and women''s apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.'
);
Também podemos verificar a precisão da descrição na tabela de produtos.
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.products';
Achei o contexto gerado automaticamente para a tabela de produtos bastante preciso e sem necessidade de mudanças.
Também verifiquei as informações sobre cada coluna nas duas tabelas e elas também estavam corretas.
Vamos aplicar o contexto gerado para ecomm.inventory_items e ecomm.products à nossa configuração.
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.inventory_items',
overwrite_if_exist => TRUE
);
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.products',
overwrite_if_exist => TRUE
);
Você se lembra da nossa consulta para gerar SQL para a pergunta "Quantos produtos temos da nossa marca preferida?" ? Agora podemos repetir e ver se a saída muda.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Esta é a nova saída.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
Agora, ele está verificando o ecomm.products, que é mais preciso e retorna cerca de 300 produtos em vez de 5.000 operações com itens de inventário.
9. Como trabalhar com o índice de valor
A vinculação de valores enriquece as consultas em linguagem natural ao conectar frases de valor a tipos de conceitos e nomes de colunas pré-registrados. Isso pode ajudar a tornar os resultados mais previsíveis.
Configurar o índice de valor
Podemos fazer consultas usando a coluna "marca" na tabela de produtos e pesquisar itens com marcas mais estáveis definindo o tipo de conceito e associando-o à coluna "ecomm.products.brand".
Vamos criar o conceito e associá-lo à coluna:
SELECT alloydb_ai_nl.add_concept_type(
concept_type_in => 'brand_name',
match_function_in => 'alloydb_ai_nl.get_concept_and_value_generic_entity_name',
additional_info_in => '{
"description": "Concept type for brand name.",
"examples": "SELECT alloydb_ai_nl.get_concept_and_value_generic_entity_name(''Auto Forge'')" }'::jsonb
);
SELECT alloydb_ai_nl.associate_concept_type(
column_names_in => 'ecomm.products.brand',
concept_type_in => 'brand_name',
nl_config_id_in => 'cymbal_ecomm_config'
);
Para verificar o conceito, consulte alloydb_ai_nl.list_concept_types().
SELECT alloydb_ai_nl.list_concept_types();
Em seguida, podemos criar o índice na nossa configuração para todas as associações criadas e pré-criadas:
SELECT alloydb_ai_nl.create_value_index(
nl_config_id_in => 'cymbal_ecomm_config'
);
Usar o índice de valor
Se você executar uma consulta para criar um SQL usando nomes de marcas, mas sem definir que é um nome de marca, isso ajuda a identificar corretamente a entidade e a coluna. Esta é a consulta:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many Clades do we have?'
) ->> 'sql';
e a saída mostra a identificação correta da palavra "Clades" como um nome de marca.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
10. Como trabalhar com modelos de consulta
Os modelos de consulta ajudam a definir consultas estáveis para aplicativos essenciais aos negócios, reduzindo a incerteza e melhorando a acurácia.
Criar um modelo de consulta
Vamos criar um modelo de consulta que une várias tabelas para receber informações sobre clientes que compraram produtos da "Republic Outpost" no ano passado. Sabemos que a consulta pode usar a tabela ecomm.products ou ecomm.inventory_items, já que ambas têm informações sobre as marcas. Mas a tabela products tem 15 vezes menos linhas e um índice na chave primária para a junção. Talvez seja mais eficiente usar a tabela de produtos. Então, estamos criando um modelo para a consulta.
SELECT alloydb_ai_nl.add_template(
nl_config_id => 'cymbal_ecomm_config',
intent => 'List the last names and the country of all customers who bought products of `Republic Outpost` in the last year.',
sql => 'SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = ''Republic Outpost'' AND oi.created_at >= DATE_TRUNC(''year'', CURRENT_DATE - INTERVAL ''1 year'') AND oi.created_at < DATE_TRUNC(''year'', CURRENT_DATE)',
sql_explanation => 'To answer this question, JOIN `ecomm.users` with `ecom.order_items` on having the same `users.id` and `order_items.user_id`, and JOIN the result with ecom.products on having the same `order_items.product_id` and `products.id`. Then filter rows with products.brand = ''Republic Outpost'' and by `order_items.created_at` for the last year. Return the `last_name` and the `country` of the users with matching records.',
check_intent => TRUE
);
Agora podemos pedir para criar uma consulta.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
) ->> 'sql';
e gera a saída desejada.
SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = 'Republic Outpost' AND oi.created_at >= DATE_TRUNC('year', CURRENT_DATE - INTERVAL '1 year') AND oi.created_at < DATE_TRUNC('year', CURRENT_DATE)
Ou execute a consulta diretamente usando o seguinte comando:
SELECT
alloydb_ai_nl.execute_nl_query(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
);
Ele vai retornar resultados no formato JSON, que podem ser analisados.
execute_nl_query
--------------------------------------------------------
{"last_name":"Adams","country":"China"}
{"last_name":"Adams","country":"Germany"}
{"last_name":"Aguilar","country":"China"}
{"last_name":"Allen","country":"China"}
11. Limpar o ambiente
Destrua as instâncias e o cluster do AlloyDB quando terminar o laboratório.
Excluir o cluster do AlloyDB e todas as instâncias
Se você usou a versão de teste do AlloyDB. Não exclua o cluster de teste se você planeja testar outros laboratórios e recursos usando esse cluster. Não será possível criar outro cluster de teste no mesmo projeto.
O cluster é destruído com a opção "force" que também exclui todas as instâncias pertencentes.
No Cloud Shell, defina o projeto e as variáveis de ambiente se tiver ocorrido uma desconexão e todas as configurações anteriores forem perdidas:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Exclua o cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Excluir backups do AlloyDB
Exclua todos os backups do AlloyDB do cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Parabéns
Parabéns por concluir o codelab. Agora você pode tentar implementar suas próprias soluções usando os recursos NL2SQL do AlloyDB. Recomendamos que você teste outros codelabs relacionados ao AlloyDB e à IA do AlloyDB. Confira como os embeddings multimodais funcionam no AlloyDB neste codelab.
O que vimos
- Como implantar o AlloyDB para Postgres
- Como ativar a linguagem natural da IA do AlloyDB
- Como criar e ajustar a configuração para linguagem natural de IA
- Como gerar consultas SQL e receber resultados usando linguagem natural
13. Pesquisa
Saída: