
1. Введение
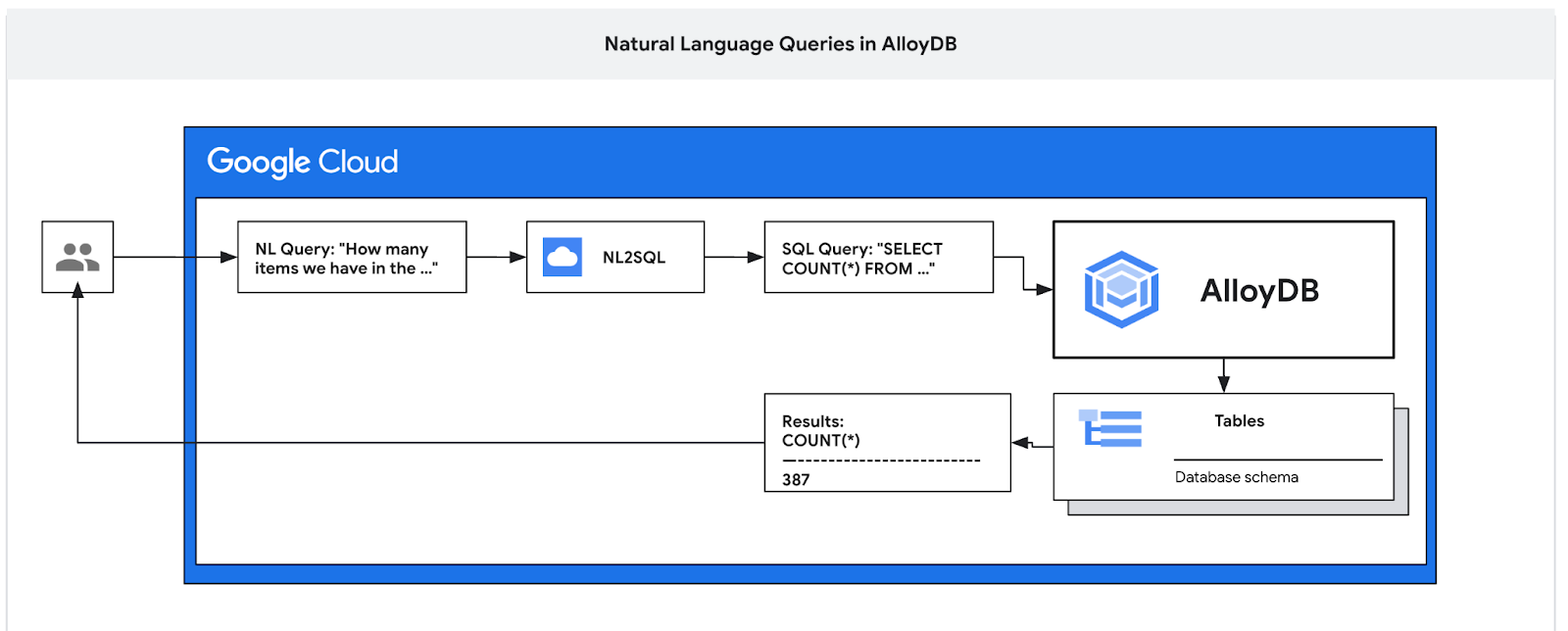
В этом практическом занятии вы узнаете, как развернуть AlloyDB и использовать искусственный интеллект для обработки естественного языка при запросах к данным, а также настраивать конфигурацию для выполнения предсказуемых и эффективных запросов. Это практическое занятие является частью серии практических занятий, посвященных возможностям искусственного интеллекта в AlloyDB. Подробнее можно узнать на странице AlloyDB AI в документации.
Предварительные требования
- Базовое понимание Google Cloud и консоли.
- Базовые навыки работы с командной строкой и Cloud Shell.
Что вы узнаете
- Как развернуть AlloyDB для PostgreSQL
- Как включить обработку естественного языка с помощью AlloyDB AI
- Как создать и настроить конфигурацию для обработки естественного языка с помощью ИИ.
- Как генерировать SQL-запросы и получать результаты, используя естественный язык.
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, такой как Chrome , поддерживающий консоль Google Cloud и Cloud Shell.
2. Настройка и требования
Настройка среды для самостоятельного обучения
- Войдите в консоль Google Cloud и создайте новый проект или используйте существующий. Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .

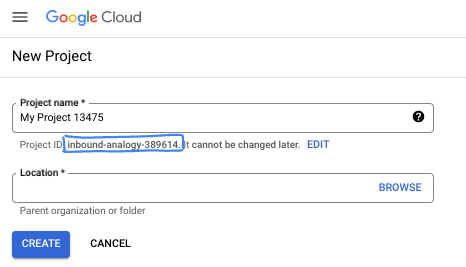
- Название проекта — это отображаемое имя участников данного проекта. Это строка символов, не используемая API Google. Вы всегда можете его изменить.
- Идентификатор проекта уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Cloud автоматически генерирует уникальную строку; обычно вам неважно, какая она. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта (обычно обозначается как
PROJECT_ID). Если сгенерированный идентификатор вас не устраивает, вы можете сгенерировать другой случайный идентификатор. В качестве альтернативы вы можете попробовать свой собственный и посмотреть, доступен ли он. После этого шага его нельзя изменить, и он сохраняется на протяжении всего проекта. - К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
- Далее вам потребуется включить оплату в консоли Cloud для использования ресурсов/API Cloud. Выполнение этого практического задания не потребует больших затрат, если вообще потребует. Чтобы отключить ресурсы и избежать дополнительных расходов после завершения этого урока, вы можете удалить созданные ресурсы или удалить проект. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
3. Прежде чем начать
Включить API
Внутри Cloud Shell убедитесь, что идентификатор вашего проекта указан правильно:
gcloud config set project [YOUR-PROJECT-ID]
Установите переменную среды PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Включите все необходимые службы:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Ожидаемый результат
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Развертывание AlloyDB
Создание кластера AlloyDB и основного экземпляра. Следующая процедура описывает, как создать кластер и экземпляр AlloyDB с помощью Google Cloud SDK. Если вы предпочитаете использовать консольный подход, вы можете следовать документации здесь .
Перед созданием кластера AlloyDB нам необходим доступный диапазон частных IP-адресов в нашей VPC, который будет использоваться будущим экземпляром AlloyDB. Если его нет, нам нужно его создать, назначить для использования внутренними сервисами Google, после чего мы сможем создать кластер и экземпляр.
Создать частный диапазон IP-адресов
Нам необходимо настроить параметры доступа к частным сервисам (Private Service Access, VPC) в нашей VPC для AlloyDB. Предполагается, что в проекте используется «стандартная» сеть VPC, и она будет применяться для всех действий.
Создайте диапазон частных IP-адресов:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Создайте частное соединение, используя выделенный диапазон IP-адресов:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Создание кластера AlloyDB
В этом разделе мы создаём кластер AlloyDB в регионе us-central1.
Задайте пароль для пользователя postgres. Вы можете задать собственный пароль или использовать функцию генерации случайных чисел.
export PGPASSWORD=`openssl rand -hex 12`
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Запишите пароль от PostgreSQL для дальнейшего использования.
echo $PGPASSWORD
Этот пароль понадобится вам в будущем для подключения к экземпляру под учетной записью postgres. Я рекомендую записать его или скопировать куда-нибудь, чтобы иметь возможность использовать позже.
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Создайте кластер для бесплатной пробной версии
Если вы раньше не использовали AlloyDB, вы можете создать бесплатный пробный кластер:
Определите регион и имя кластера AlloyDB. Мы будем использовать регион us-central1 и имя кластера alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Выполните команду для создания кластера:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Ожидаемый вывод в консоль:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Создайте основной экземпляр AlloyDB для нашего кластера в той же сессии Cloud Shell. Если вы отключены, вам потребуется заново определить переменные среды для региона и имени кластера.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Создание кластера AlloyDB Standard
Если это не первый ваш кластер AlloyDB в проекте, перейдите к созданию стандартного кластера.
Определите регион и имя кластера AlloyDB. Мы будем использовать регион us-central1 и имя кластера alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Выполните команду для создания кластера:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Ожидаемый вывод в консоль:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Создайте основной экземпляр AlloyDB для нашего кластера в той же сессии Cloud Shell. Если вы отключены, вам потребуется заново определить переменные среды для региона и имени кластера.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Подготовка базы данных
Нам необходимо создать базу данных, включить интеграцию с Vertex AI, создать объекты базы данных и импортировать данные.
Предоставьте необходимые разрешения AlloyDB
Добавьте разрешения Vertex AI для агента службы AlloyDB.
Откройте еще одну вкладку Cloud Shell, используя знак "+" вверху.
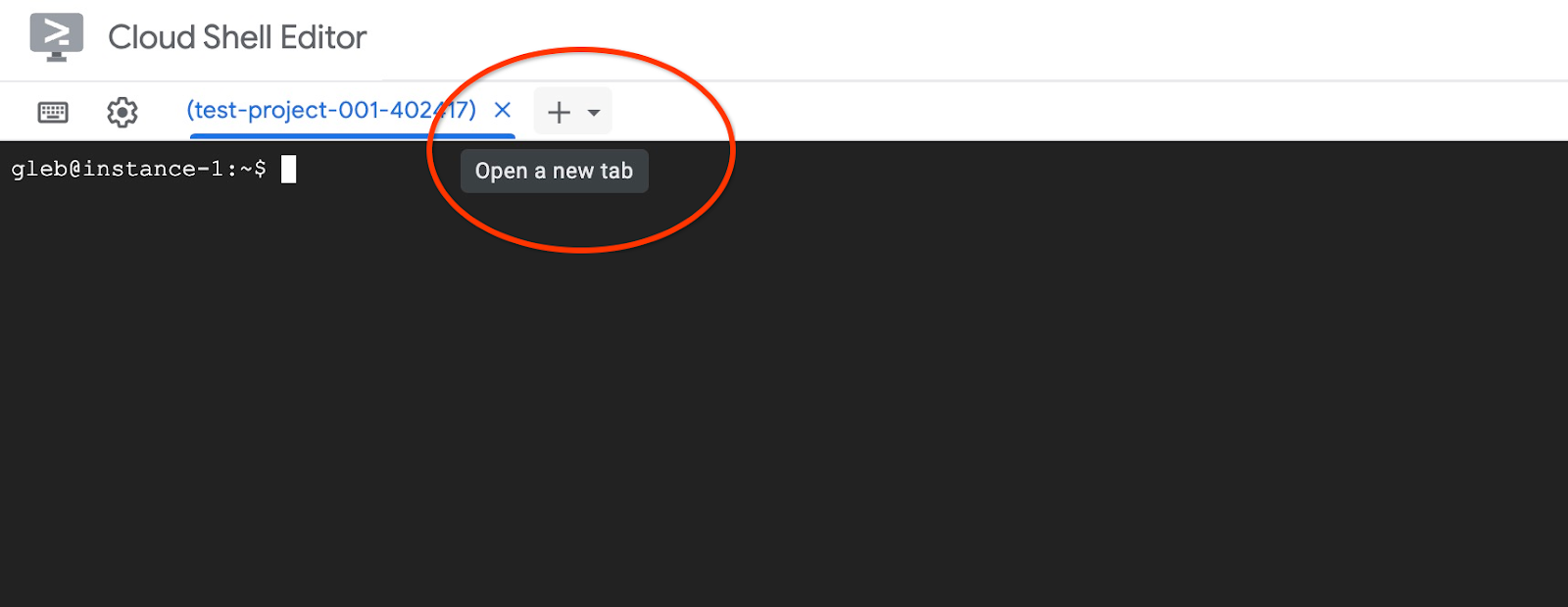
В новой вкладке облачной оболочки выполните:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Закройте вкладку, выполнив одну из команд, указанных на вкладке, например, «Выход»:
exit
Подключитесь к AlloyDB Studio
В следующих главах все команды SQL, требующие подключения к базе данных, можно выполнить альтернативным способом в AlloyDB Studio. Для выполнения команды необходимо открыть веб-консоль вашего кластера AlloyDB, щелкнув по основному экземпляру.
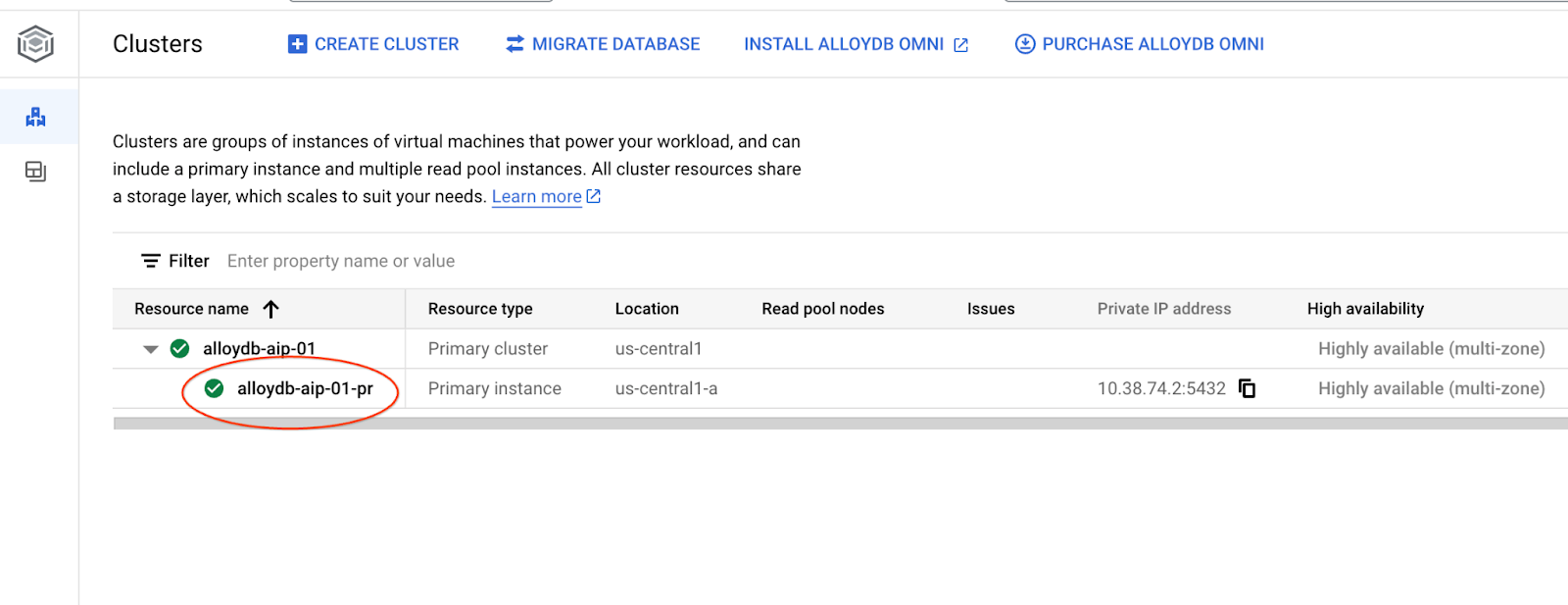
Затем нажмите на AlloyDB Studio слева:
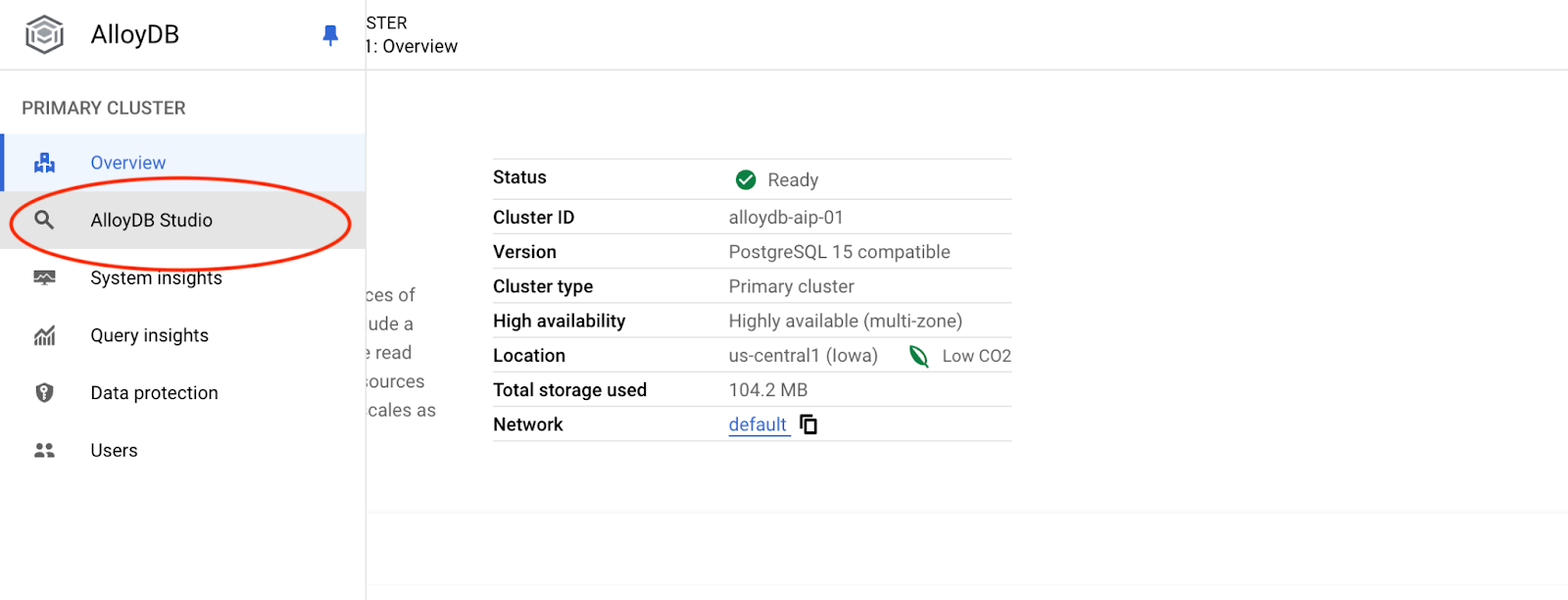
Выберите базу данных postgres, пользователя postgres и введите пароль, указанный при создании кластера. Затем нажмите кнопку «Аутентифицировать».
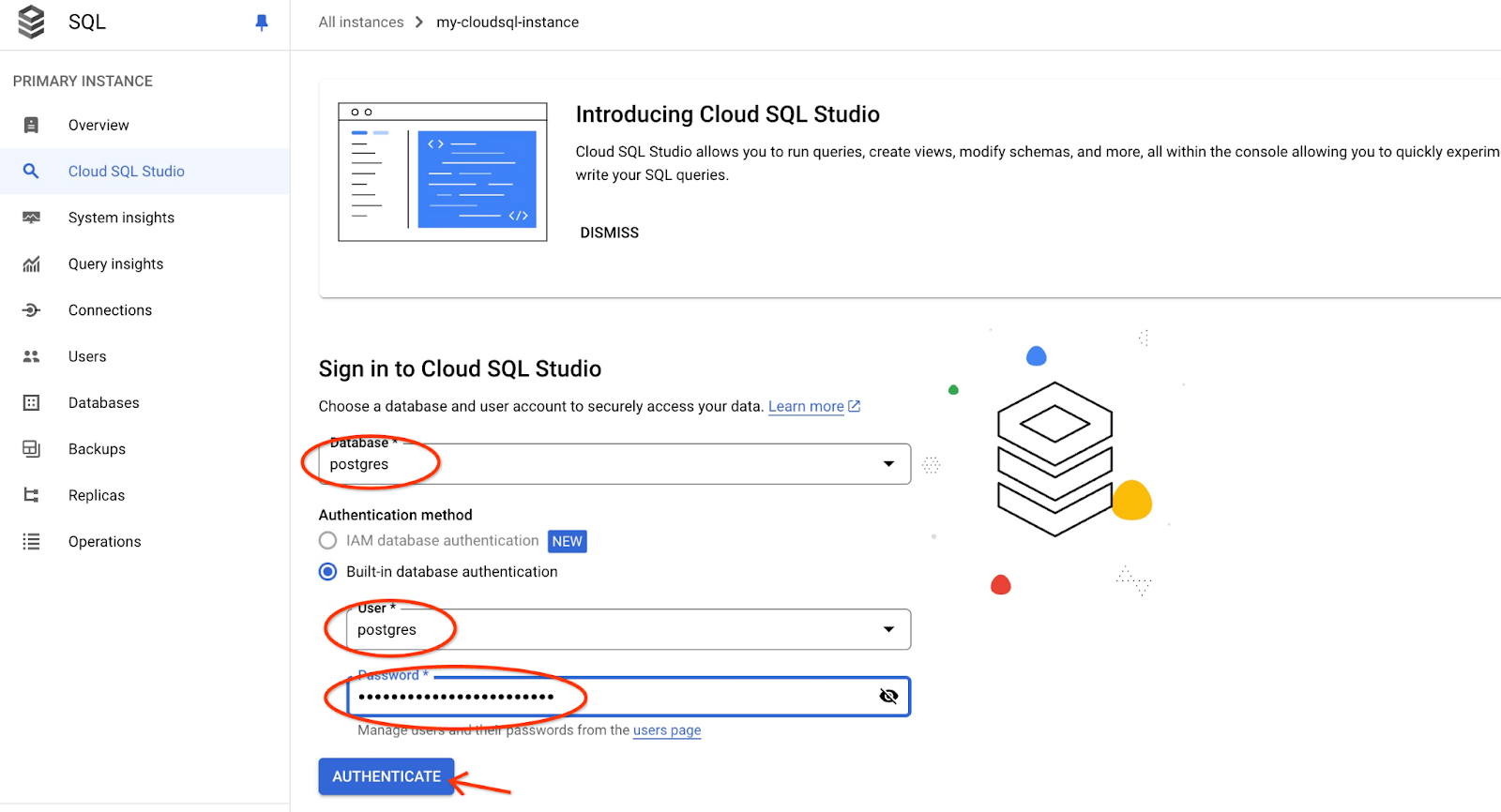
Откроется интерфейс AlloyDB Studio. Чтобы выполнить команды в базе данных, щелкните вкладку "Редактор 1" справа.
Открывается интерфейс, в котором можно выполнять команды SQL.
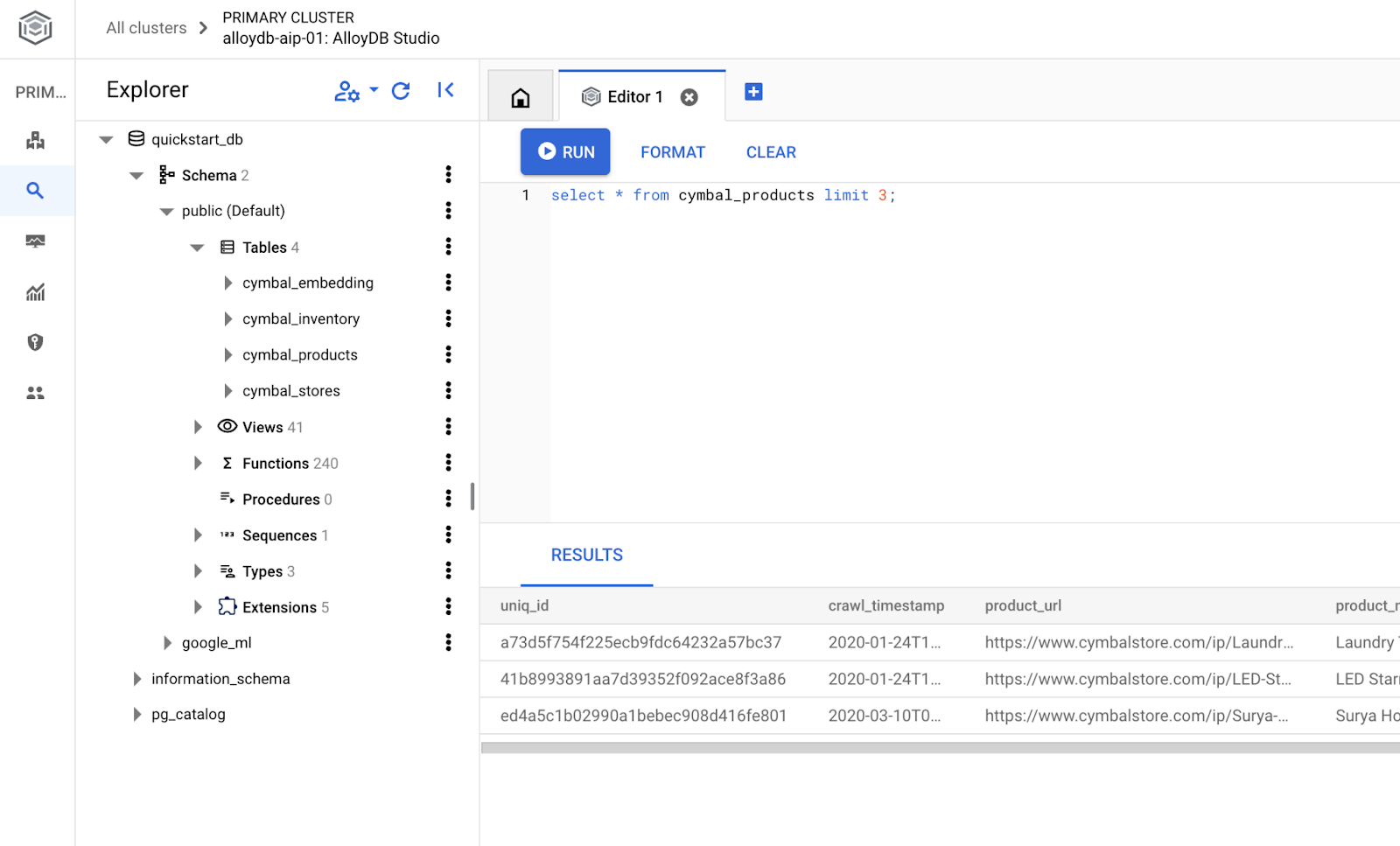
Создать базу данных
Быстрый старт создания базы данных.
В редакторе AlloyDB Studio выполните следующую команду.
Создать базу данных:
CREATE DATABASE quickstart_db
Ожидаемый результат:
Statement executed successfully
Подключитесь к quickstart_db
Для переключения между пользователем и базой данных повторно подключитесь к студии, используя соответствующую кнопку.
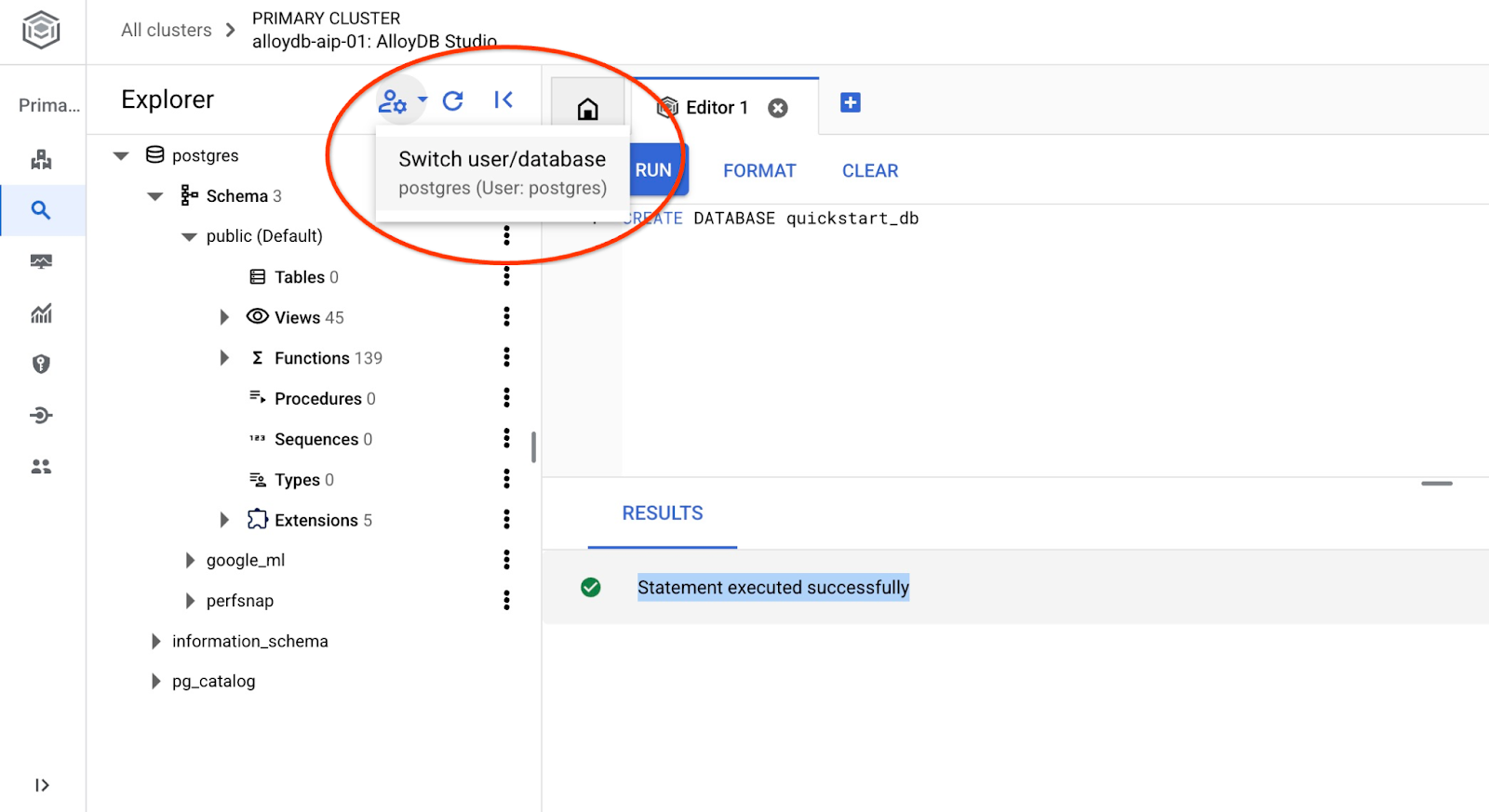
Выберите из выпадающего списка новую базу данных quickstart_db и используйте те же имя пользователя и пароль, что и раньше.
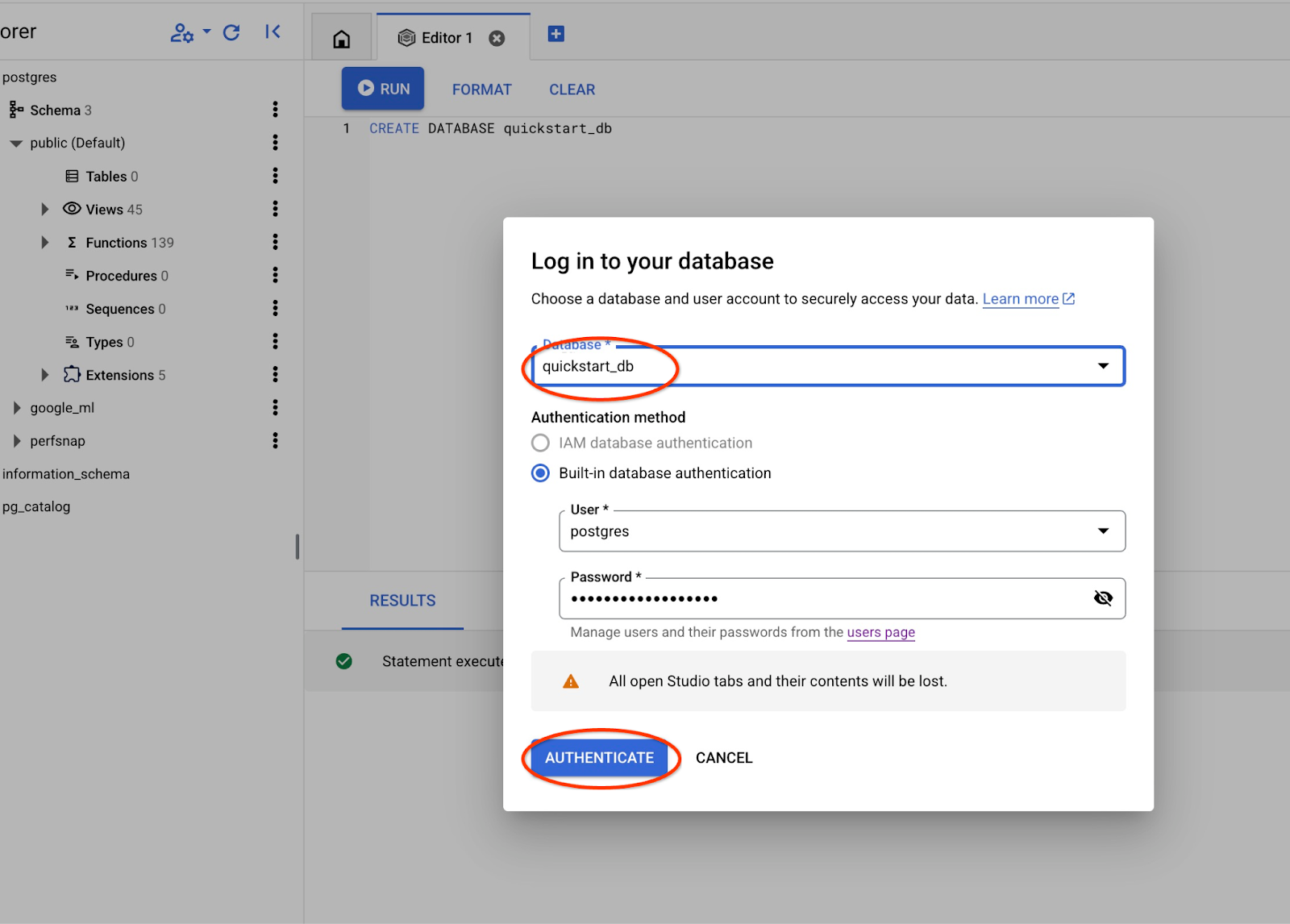
Это откроет новое соединение, через которое вы сможете работать с объектами из базы данных quickstart_db.
6. Пример данных
Теперь нам нужно создать объекты в базе данных и загрузить данные. Мы будем использовать вымышленный магазин "Cymbal ecomm" с набором таблиц для онлайн-магазинов. Он содержит несколько таблиц, связанных своими ключами, что напоминает схему реляционной базы данных.
Набор данных подготавливается и размещается в виде SQL-файла, который можно загрузить в базу данных с помощью интерфейса импорта. В облачной оболочке выполните следующие команды:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic.sql' --user=postgres --sql
Эта команда использует SDK AlloyDB, создает схему ecomm, а затем импортирует тестовые данные непосредственно из хранилища GCS в базу данных, создавая все необходимые объекты и вставляя данные.
После импорта мы можем проверить таблицы в AlloyDB Studio.
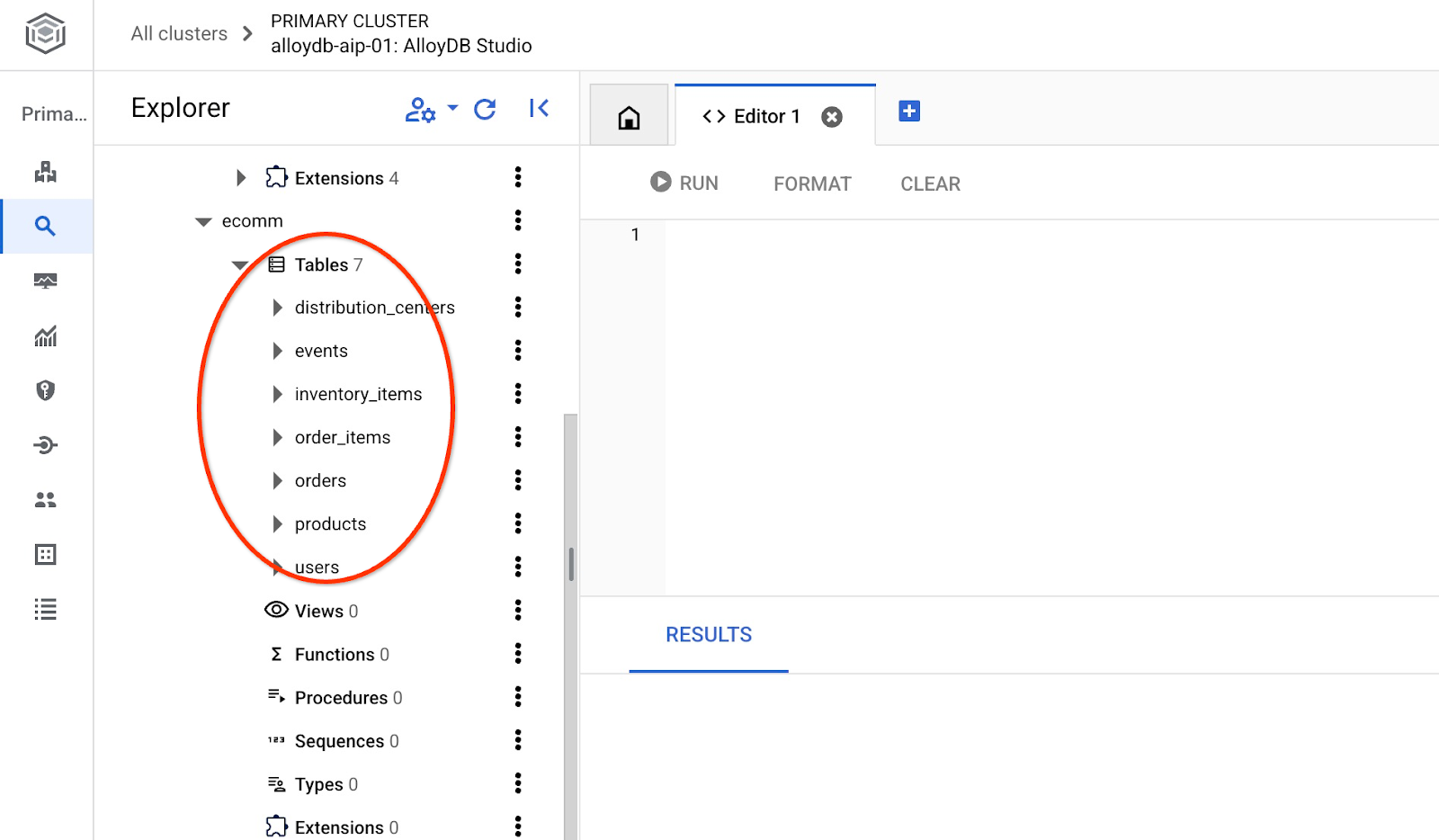
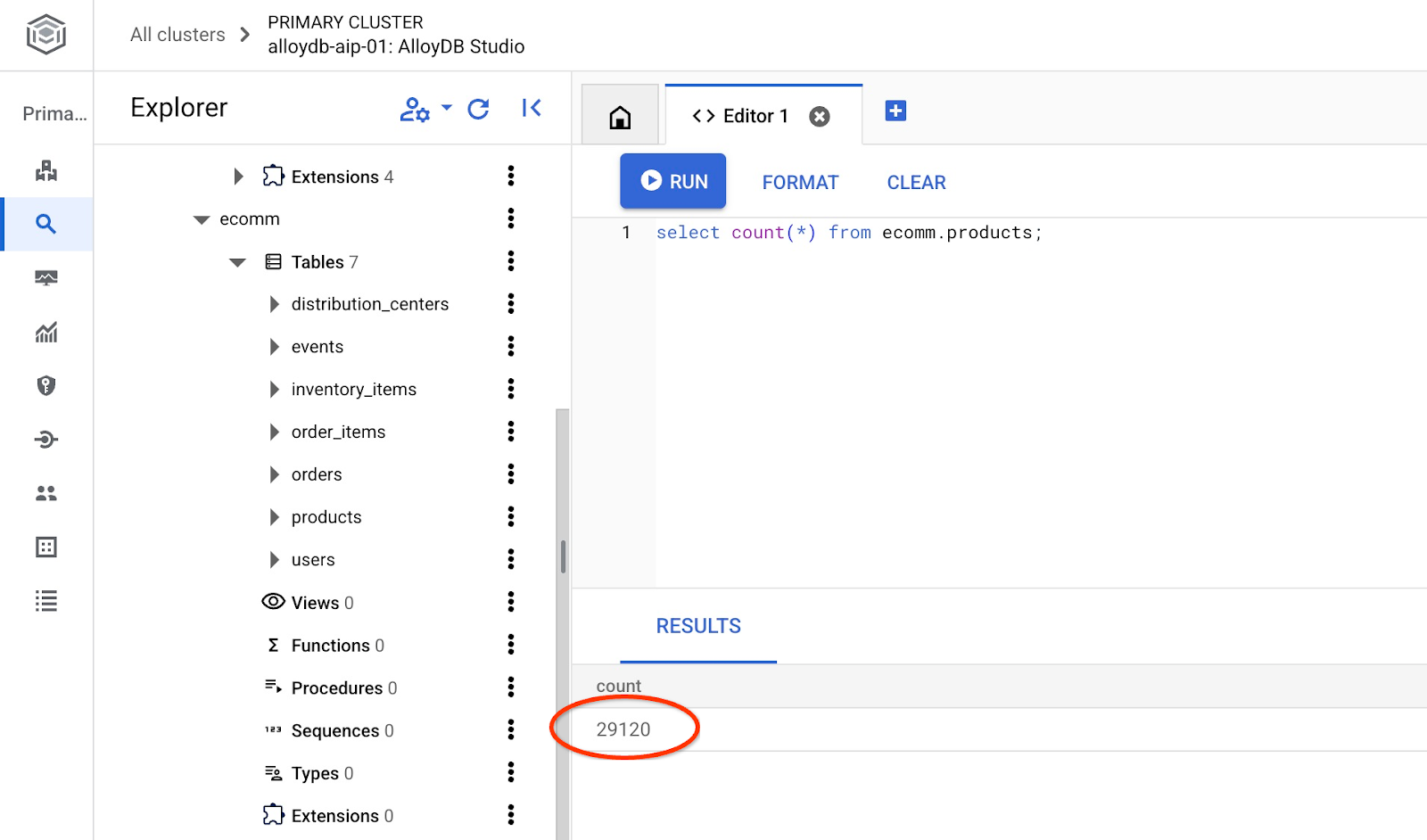
И проверьте количество строк в таблице.
7. Настройка NL SQL
В этой главе мы настроим NL для работы с вашей тестовой схемой.
Установите расширение alloydb_nl_ai.
Нам необходимо установить расширение alloydb_ai_nl в нашу базу данных. Перед этим нужно установить флаг alloydb_ai_nl.enabled в значение on.
В сессии Cloud Shell выполните следующие действия:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb instances update $ADBCLUSTER-pr \
--cluster=$ADBCLUSTER \
--region=$REGION \
--database-flags=alloydb_ai_nl.enabled=on
Это запустит обновление экземпляра. Вы можете отслеживать статус обновляемого экземпляра в веб-консоли:
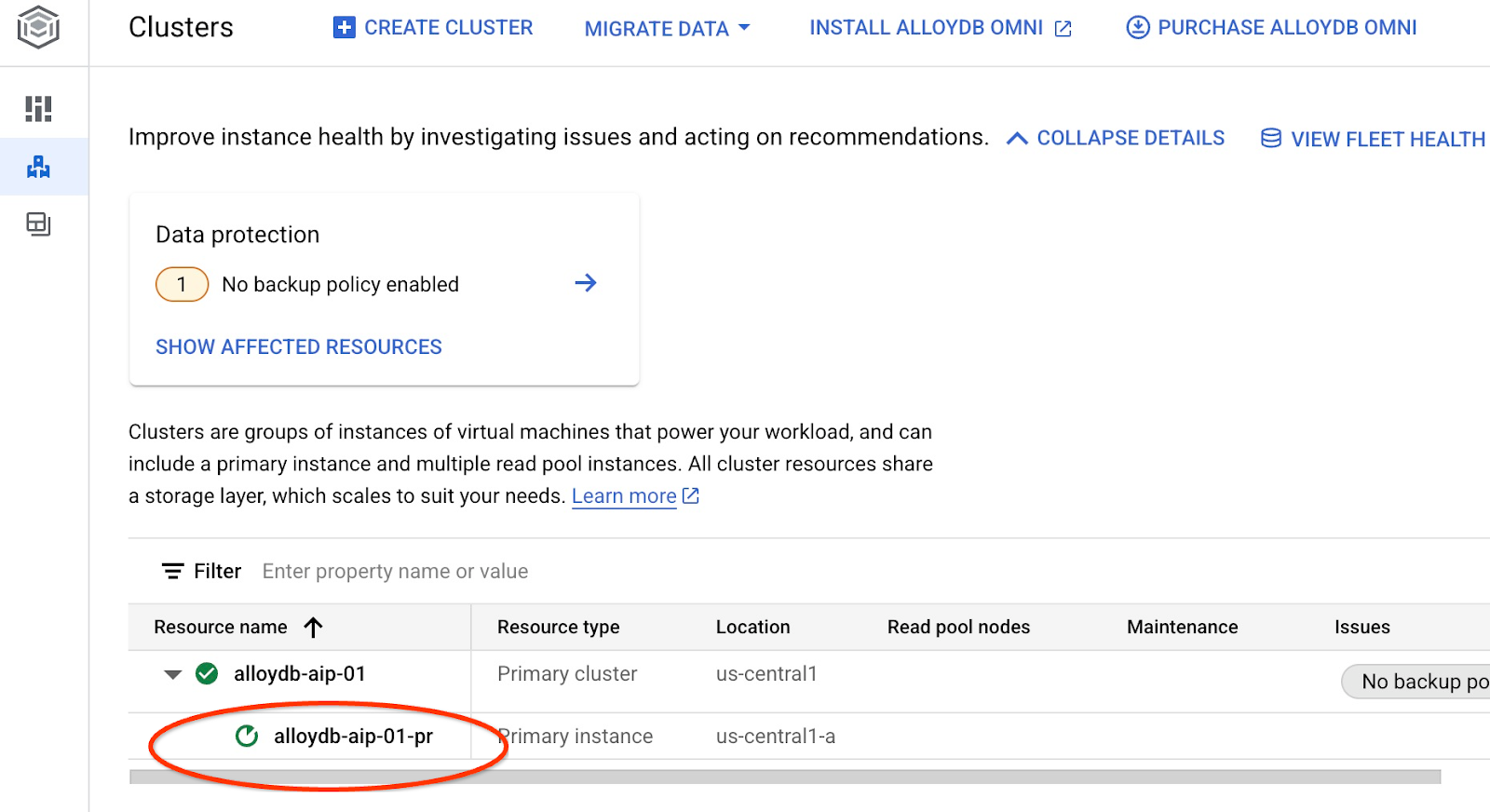
После обновления экземпляра (когда его статус станет зеленым) вы можете включить расширение alloydb_ai_nl.
В AlloyDB Studio выполните следующие действия:
CREATE EXTENSION IF NOT EXISTS google_ml_integration;
CREATE EXTENSION alloydb_ai_nl cascade;
Создайте конфигурацию на естественном языке.
Для использования расширений необходимо создать конфигурацию. Конфигурация необходима для связывания приложений с определенными схемами, шаблонами запросов и конечными точками моделей. Давайте создадим конфигурацию с идентификатором cymbal_ecomm_config .
В AlloyDB Studio выполните следующие действия:
SELECT
alloydb_ai_nl.g_create_configuration(
configuration_id => 'cymbal_ecomm_config'
);
Теперь мы можем зарегистрировать нашу схему ecomm в конфигурации. Мы импортировали данные в схему ecomm, поэтому собираемся добавить эту схему в нашу конфигурацию NL.
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'register_schema',
configuration_id_in => 'cymbal_ecomm_config',
schema_names_in => '{ecomm}'
);
8. Добавление контекста к NL SQL
Добавить общий контекст
Мы можем добавить некоторый контекст к нашей зарегистрированной схеме. Контекст призван помочь получить лучшие результаты в ответ на запросы пользователей. Например, мы можем указать, что определенный бренд является предпочтительным для пользователя, даже если это явно не указано. Давайте сделаем Clades (вымышленный бренд) нашим брендом по умолчанию.
В AlloyDB Studio выполните:
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'add_general_context',
configuration_id_in => 'cymbal_ecomm_config',
general_context_in => '{"If the user doesn''t clearly define preferred brand then use Clades."}'
);
Давайте проверим, как в данном случае работает общий контекст.
В AlloyDB Studio выполните:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
);
В сгенерированном запросе используется наш бренд по умолчанию, определенный ранее в общем контексте:
{"sql": "SELECT count(*) FROM \"ecomm\".\"products\" WHERE \"brand\" = 'Clades'", "method": "default", "prompt": "", "retries": 0, "time(ms)": {"llm": 505.628000, "magic": 424.019000}, "error_msg": "", "nl_question": "How many products do we have of our preferred brand?", "toolbox_used": false}
Мы можем привести его в порядок и вывести в качестве результата только SQL-запрос.
Например:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Вывод очищен:
SELECT count(*) FROM "ecomm"."products" WHERE "brand" = 'Clades'
Вы заметили, что система автоматически выбрала таблицу inventory_items вместо таблицы products и использовала её для построения запроса. В некоторых случаях это может сработать, но не для нашей схемы. В нашем случае таблица inventory_items используется для отслеживания продаж, что может ввести в заблуждение, если у вас нет инсайдерской информации. Позже мы рассмотрим, как сделать наши запросы более точными.
Контекст схемы
Контекст схемы описывает объекты схемы, такие как таблицы, представления и отдельные столбцы, хранящие информацию в виде комментариев в объектах схемы.
Мы можем создать его автоматически для всех объектов схемы в нашей конфигурации, используя следующий запрос:
SELECT
alloydb_ai_nl.generate_schema_context(
nl_config_id => 'cymbal_ecomm_config',
overwrite_if_exist => TRUE
);
Параметр "TRUE" указывает на необходимость перегенерации контекста и его перезаписи. Выполнение займет некоторое время в зависимости от модели данных. Чем больше связей и соединений, тем дольше может занять процесс.
После создания контекста мы можем проверить, что было создано для таблицы товаров на складе, используя следующий запрос:
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.inventory_items';
Вывод очищен:
The `ecomm.inventory_items` table stores information about individual inventory items in an e-commerce system. Each item is uniquely identified by an `id` (primary key). The table tracks the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn't been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men's and women's apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.
Создается впечатление, что в описании отсутствуют некоторые ключевые моменты, касающиеся отражения перемещения товаров в таблице inventory_items. Мы можем обновить его, добавив эту важную информацию в контекст для связи ecomm.inventory_items.
SELECT alloydb_ai_nl.update_generated_relation_context(
relation_name => 'ecomm.inventory_items',
relation_context => 'The `ecomm.inventory_items` table stores information about moving and sales of inventory items in an e-commerce system. Each movement is uniquely identified by an `id` (primary key) and used in order_items table as `inventory_item_id`. The table tracks sales and movements for the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the movement for the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn''t been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men''s and women''s apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.'
);
Также мы можем проверить точность описания в нашей таблице товаров.
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.products';
Я обнаружил, что автоматически сгенерированный контекст для таблицы товаров достаточно точен и не требует никаких изменений.
Я также проверил информацию по каждому столбцу в обеих таблицах и тоже убедился в ее правильности.
Давайте применим сгенерированный контекст для ecomm.inventory_items и ecomm.products к нашей конфигурации.
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.inventory_items',
overwrite_if_exist => TRUE
);
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.products',
overwrite_if_exist => TRUE
);
Помните наш запрос для генерации SQL-запроса на вопрос «Сколько товаров нашей любимой марки у нас есть?»? Теперь мы можем повторить его и посмотреть, изменился ли результат.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Вот новый результат.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
Теперь проверка осуществляется по адресу ecomm.products, что более точно и возвращает около 300 товаров вместо 5000 операций с товарными позициями.
9. Работа с индексом ценности
Метод связывания значений обогащает запросы на естественном языке, соединяя фразы, обозначающие значения, с предварительно зарегистрированными типами концепций и названиями столбцов. Это может помочь сделать результаты более предсказуемыми.
Настройте индекс значений.
Мы можем сделать наши запросы, используя столбец brand в таблице products, и обеспечить более стабильный поиск товаров с определенными брендами, определив тип концепции и связав его со столбцом ecomm.products.brand.
Давайте создадим концепцию и свяжем её с колонкой:
SELECT alloydb_ai_nl.add_concept_type(
concept_type_in => 'brand_name',
match_function_in => 'alloydb_ai_nl.get_concept_and_value_generic_entity_name',
additional_info_in => '{
"description": "Concept type for brand name.",
"examples": "SELECT alloydb_ai_nl.get_concept_and_value_generic_entity_name(''Auto Forge'')" }'::jsonb
);
SELECT alloydb_ai_nl.associate_concept_type(
column_names_in => 'ecomm.products.brand',
concept_type_in => 'brand_name',
nl_config_id_in => 'cymbal_ecomm_config'
);
Вы можете проверить эту концепцию, запросив информацию из функции alloydb_ai_nl.list_concept_types().
SELECT alloydb_ai_nl.list_concept_types();
Затем мы можем создать индекс в нашей конфигурации для всех созданных и предварительно настроенных ассоциаций:
SELECT alloydb_ai_nl.create_value_index(
nl_config_id_in => 'cymbal_ecomm_config'
);
Используйте индекс стоимости
Если вы выполняете SQL-запрос, используя названия брендов, но не указывая, что это именно название бренда, это помогает правильно идентифицировать сущность и столбец. Вот сам запрос:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many Clades do we have?'
) ->> 'sql';
Результат показывает правильное определение слова «Clades» как названия бренда.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
10. Работа с шаблонами запросов
Шаблоны запросов помогают определять стабильные запросы для критически важных бизнес-приложений, снижая неопределенность и повышая точность.
Создайте шаблон запроса
Давайте создадим шаблон запроса, объединяющий несколько таблиц, чтобы получить информацию о клиентах, которые покупали продукцию "Republic Outpost" в прошлом году. Мы знаем, что запрос может использовать либо таблицу ecomm.products, либо таблицу ecomm.inventory_items, поскольку обе содержат информацию о брендах. Но таблица products содержит в 15 раз меньше строк и индекс по первичному ключу для объединения. Возможно, использование таблицы products будет более эффективным. Поэтому мы создаем шаблон для запроса.
SELECT alloydb_ai_nl.add_template(
nl_config_id => 'cymbal_ecomm_config',
intent => 'List the last names and the country of all customers who bought products of `Republic Outpost` in the last year.',
sql => 'SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = ''Republic Outpost'' AND oi.created_at >= DATE_TRUNC(''year'', CURRENT_DATE - INTERVAL ''1 year'') AND oi.created_at < DATE_TRUNC(''year'', CURRENT_DATE)',
sql_explanation => 'To answer this question, JOIN `ecomm.users` with `ecom.order_items` on having the same `users.id` and `order_items.user_id`, and JOIN the result with ecom.products on having the same `order_items.product_id` and `products.id`. Then filter rows with products.brand = ''Republic Outpost'' and by `order_items.created_at` for the last year. Return the `last_name` and the `country` of the users with matching records.',
check_intent => TRUE
);
Теперь мы можем запросить создание запроса.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
) ->> 'sql';
И это позволяет получить желаемый результат.
SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = 'Republic Outpost' AND oi.created_at >= DATE_TRUNC('year', CURRENT_DATE - INTERVAL '1 year') AND oi.created_at < DATE_TRUNC('year', CURRENT_DATE)
Или вы можете выполнить запрос напрямую, используя следующий запрос:
SELECT
alloydb_ai_nl.execute_nl_query(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
);
Результат будет возвращен в формате JSON, который можно будет разобрать.
execute_nl_query
--------------------------------------------------------
{"last_name":"Adams","country":"China"}
{"last_name":"Adams","country":"Germany"}
{"last_name":"Aguilar","country":"China"}
{"last_name":"Allen","country":"China"}
11. Очистка окружающей среды
После завершения лабораторной работы удалите экземпляры AlloyDB и кластер.
Удалите кластер AlloyDB и все его экземпляры.
Если вы использовали пробную версию AlloyDB, не удаляйте пробный кластер, если планируете тестировать другие тестовые среды и ресурсы с его помощью. Вы не сможете создать другой пробный кластер в том же проекте.
Кластер уничтожается с помощью опции force, которая также удаляет все экземпляры, принадлежащие кластеру.
В облачной оболочке укажите переменные проекта и среды на случай, если соединение было разорвано и все предыдущие настройки были потеряны:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Удалите кластер:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Удалить резервные копии AlloyDB
Удалите все резервные копии AlloyDB для кластера:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Поздравляем!
Поздравляем с завершением практического занятия! Теперь вы можете попробовать реализовать собственные решения, используя возможности NL2SQL в AlloyDB. Мы рекомендуем попробовать другие практические занятия, связанные с AlloyDB и AlloyDB AI. В этом практическом занятии вы можете узнать, как работают мультимодальные эмбеддинги в AlloyDB.
Что мы рассмотрели
- Как развернуть AlloyDB для PostgreSQL
- Как включить обработку естественного языка с помощью AlloyDB AI
- Как создать и настроить конфигурацию для обработки естественного языка с помощью ИИ.
- Как генерировать SQL-запросы и получать результаты, используя естественный язык.
13. Опрос
Выход: