
1. Giriş
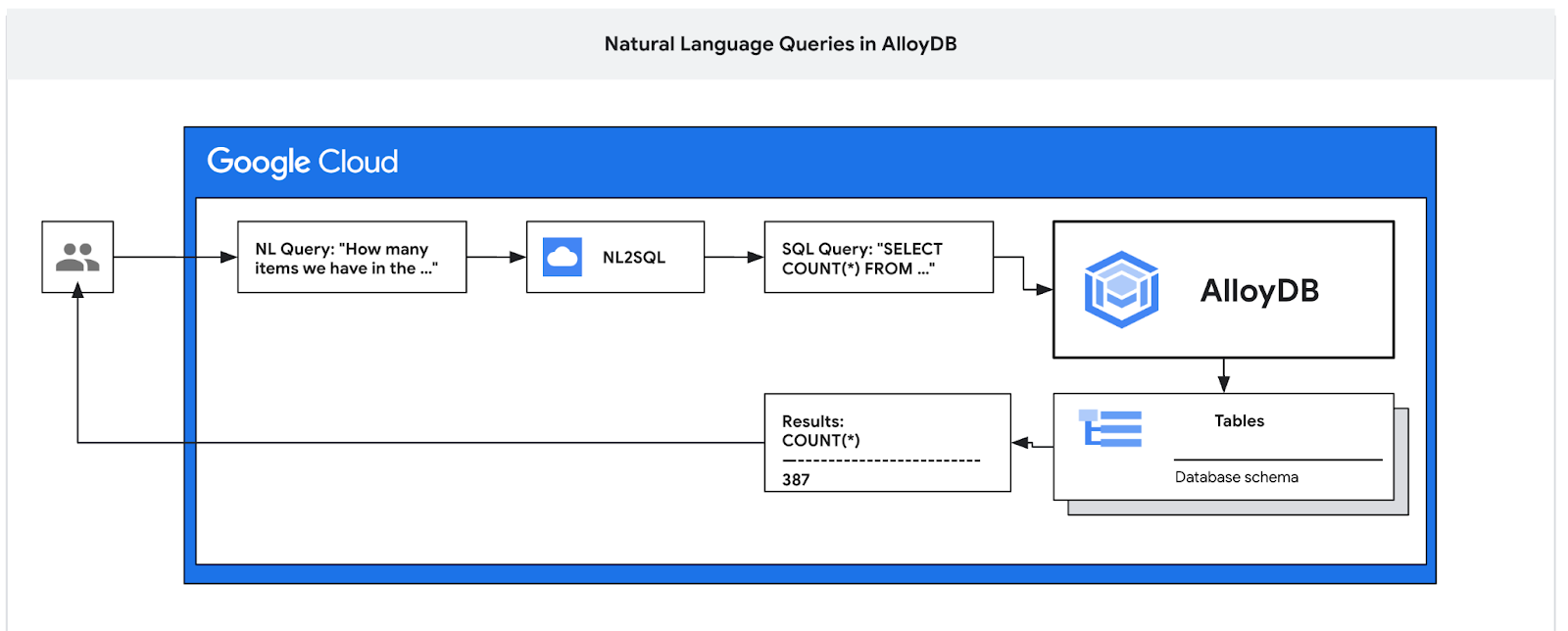
Bu codelab'de AlloyDB'yi nasıl dağıtacağınızı ve verileri sorgulamak, yapılandırmayı tahmin edilebilir ve verimli sorgular için ayarlamak üzere yapay zeka doğal dilini nasıl kullanacağınızı öğreneceksiniz. Bu laboratuvar, AlloyDB AI özelliklerine ayrılmış bir laboratuvar koleksiyonunun parçasıdır. Belgelerdeki AlloyDB AI sayfasında daha fazla bilgi edinebilirsiniz.
Ön koşullar
- Google Cloud ve konsol hakkında temel düzeyde bilgi sahibi olmak
- Komut satırı arayüzü ve Cloud Shell'de temel beceriler
Neler öğreneceksiniz?
- AlloyDB for Postgres'i dağıtma
- AlloyDB AI doğal dilini etkinleştirme
- Yapay zeka doğal dili için yapılandırma oluşturma ve ayarlama
- Doğal dili kullanarak SQL sorguları oluşturma ve sonuç alma
Gerekenler
- Google Cloud hesabı ve Google Cloud projesi
- Google Cloud Console ve Cloud Shell'i destekleyen Chrome gibi bir web tarayıcısı
2. Kurulum ve Gereksinimler
Yönlendirmesiz ortam kurulumu
- Google Cloud Console'da oturum açın ve yeni bir proje oluşturun veya mevcut bir projeyi yeniden kullanın. Gmail veya Google Workspace hesabınız yoksa hesap oluşturmanız gerekir.

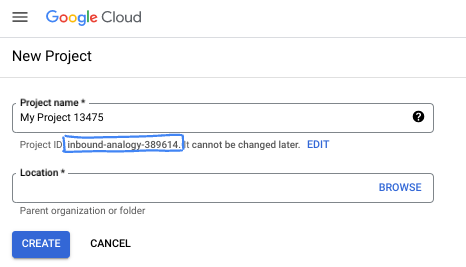
- Proje adı, bu projenin katılımcıları için görünen addır. Google API'leri tarafından kullanılmayan bir karakter dizesidir. Bu bilgiyi istediğiniz zaman güncelleyebilirsiniz.
- Proje kimliği, tüm Google Cloud projelerinde benzersizdir ve sabittir (ayarlandıktan sonra değiştirilemez). Cloud Console, benzersiz bir dizeyi otomatik olarak oluşturur. Genellikle bu dizenin ne olduğuyla ilgilenmezsiniz. Çoğu codelab'de proje kimliğinize (genellikle
PROJECT_IDolarak tanımlanır) başvurmanız gerekir. Oluşturulan kimliği beğenmezseniz başka bir rastgele kimlik oluşturabilirsiniz. Dilerseniz kendi adınızı deneyerek kullanılabilir olup olmadığını kontrol edebilirsiniz. Bu adım tamamlandıktan sonra değiştirilemez ve proje süresince geçerli kalır. - Bazı API'lerin kullandığı üçüncü bir değer olan Proje Numarası da vardır. Bu üç değer hakkında daha fazla bilgiyi belgelerde bulabilirsiniz.
- Ardından, Cloud kaynaklarını/API'lerini kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir. Bu codelab'i tamamlamak neredeyse hiç maliyetli değildir. Bu eğitimin ötesinde faturalandırılmayı önlemek için kaynakları kapatmak üzere oluşturduğunuz kaynakları veya projeyi silebilirsiniz. Yeni Google Cloud kullanıcıları 300 ABD doları değerinde ücretsiz deneme programından yararlanabilir.
Cloud Shell'i başlatma
Google Cloud, dizüstü bilgisayarınızdan uzaktan çalıştırılabilir. Ancak bu codelab'de, Cloud'da çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacaksınız.
Google Cloud Console'da sağ üstteki araç çubuğunda Cloud Shell simgesini tıklayın:
Ortamın temel hazırlığı ve bağlanması yalnızca birkaç dakikanızı alır. İşlem tamamlandığında aşağıdakine benzer bir sonuç görürsünüz:

Bu sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin sunar ve Google Cloud üzerinde çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu codelab'deki tüm çalışmalarınızı tarayıcıda yapabilirsiniz. Herhangi bir şey yüklemeniz gerekmez.
3. Başlamadan önce
API'yi etkinleştirme
Cloud Shell'de proje kimliğinizin ayarlandığından emin olun:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID ortam değişkenini ayarlayın:
PROJECT_ID=$(gcloud config get-value project)
Gerekli tüm hizmetleri etkinleştirin:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
discoveryengine.googleapis.com \
secretmanager.googleapis.com
Beklenen çıktı
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB'yi dağıtma
AlloyDB kümesi ve birincil örnek oluşturun. Aşağıdaki prosedürde, Google Cloud SDK kullanılarak nasıl AlloyDB kümesi ve örneği oluşturulacağı açıklanmaktadır. Konsol yaklaşımını tercih ederseniz buradaki belgeleri inceleyebilirsiniz.
AlloyDB kümesi oluşturmadan önce, gelecekteki AlloyDB örneği tarafından kullanılacak VPC'mizde kullanılabilir bir özel IP aralığına ihtiyacımız vardır. Bu kimlik yoksa oluşturmamız, dahili Google hizmetleri tarafından kullanılacak şekilde atamamız ve ardından küme ile örneği oluşturabilmemiz gerekir.
Özel IP aralığı oluşturma
AlloyDB için VPC'mizde özel hizmet erişimi yapılandırmasını ayarlamamız gerekiyor. Buradaki varsayım, projede "varsayılan" VPC ağının olduğu ve tüm işlemler için bu ağın kullanılacağıdır.
Özel IP aralığını oluşturun:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Ayrılan IP aralığını kullanarak özel bağlantı oluşturma:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
AlloyDB kümesi oluşturma
Bu bölümde, us-central1 bölgesinde bir AlloyDB kümesi oluşturuyoruz.
Postgres kullanıcısı için şifre tanımlayın. Kendi şifrenizi tanımlayabilir veya rastgele bir işlev kullanarak şifre oluşturabilirsiniz.
export PGPASSWORD=`openssl rand -hex 12`
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
PostgreSQL şifresini ileride kullanmak üzere not edin.
echo $PGPASSWORD
Gelecekte postgres kullanıcısı olarak örneğe bağlanmak için bu şifreye ihtiyacınız olacaktır. Daha sonra kullanabilmek için bu kodu bir yere yazmanızı veya kopyalamanızı öneririz.
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Ücretsiz deneme kümesi oluşturma
AlloyDB'yi daha önce kullanmadıysanız ücretsiz bir deneme kümesi oluşturabilirsiniz:
Bölgeyi ve AlloyDB küme adını tanımlayın. us-central1 bölgesini ve alloydb-aip-01'i küme adı olarak kullanacağız:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Kümeyi oluşturmak için komutu çalıştırın:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Beklenen konsol çıkışı:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Aynı Cloud Shell oturumunda kümemiz için bir AlloyDB birincil örneği oluşturun. Bağlantınız kesilirse bölge ve küme adı ortam değişkenlerini tekrar tanımlamanız gerekir.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
AlloyDB Standard kümesi oluşturma
Projedeki ilk AlloyDB kümeniz değilse standart küme oluşturma işlemine devam edin.
Bölgeyi ve AlloyDB küme adını tanımlayın. us-central1 bölgesini ve alloydb-aip-01'i küme adı olarak kullanacağız:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Kümeyi oluşturmak için komutu çalıştırın:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Beklenen konsol çıkışı:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Aynı Cloud Shell oturumunda kümemiz için bir AlloyDB birincil örneği oluşturun. Bağlantınız kesilirse bölge ve küme adı ortam değişkenlerini tekrar tanımlamanız gerekir.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Veritabanını Hazırlama
Veritabanı oluşturmamız, Vertex AI entegrasyonunu etkinleştirmemiz, veritabanı nesneleri oluşturmamız ve verileri içe aktarmamız gerekiyor.
AlloyDB'ye Gerekli İzinleri Verme
AlloyDB hizmet aracısına Vertex AI izinleri ekleyin.
En üstteki "+" işaretini kullanarak başka bir Cloud Shell sekmesi açın.
Yeni Cloud Shell sekmesinde şunu çalıştırın:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Sekmede "exit" komutunu çalıştırarak sekmeyi kapatın:
exit
AlloyDB Studio'ya bağlanma
Aşağıdaki bölümlerde, veritabanına bağlantı gerektiren tüm SQL komutları alternatif olarak AlloyDB Studio'da yürütülebilir. Komutu çalıştırmak için birincil örneği tıklayarak AlloyDB kümenizin web konsolu arayüzünü açmanız gerekir.
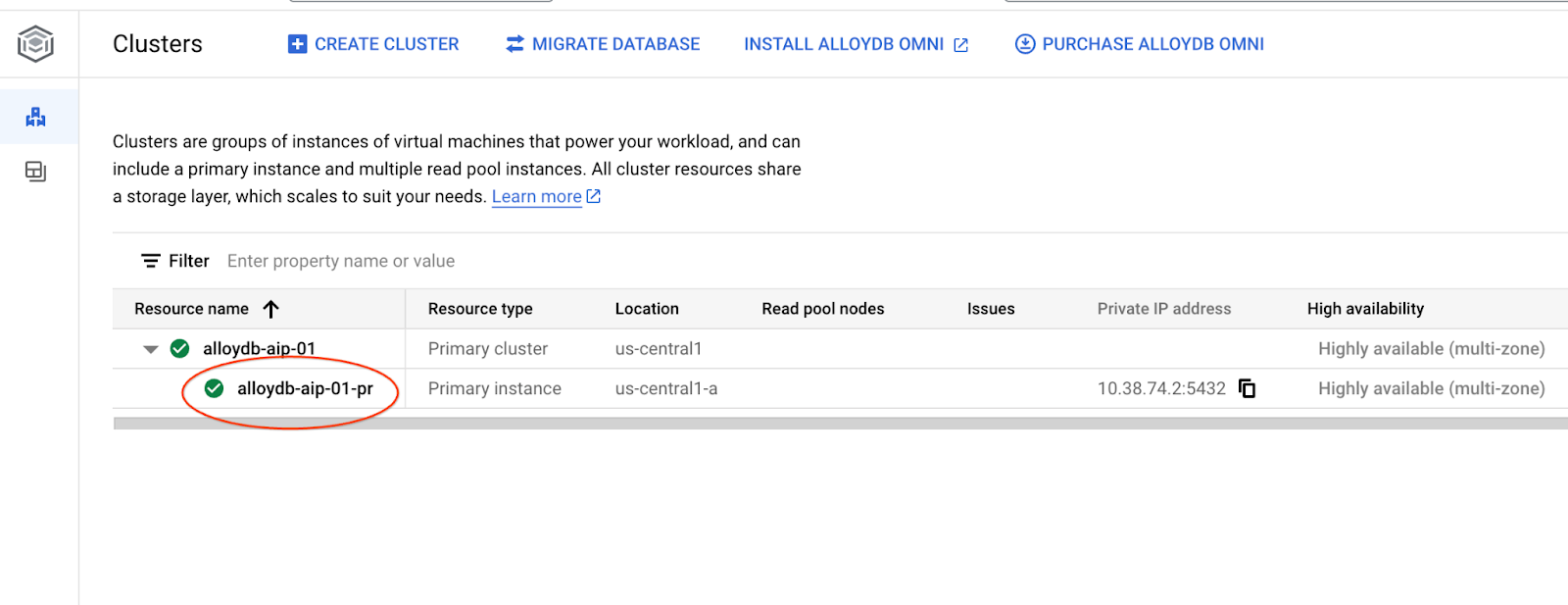
Ardından sol taraftaki AlloyDB Studio'yu tıklayın:
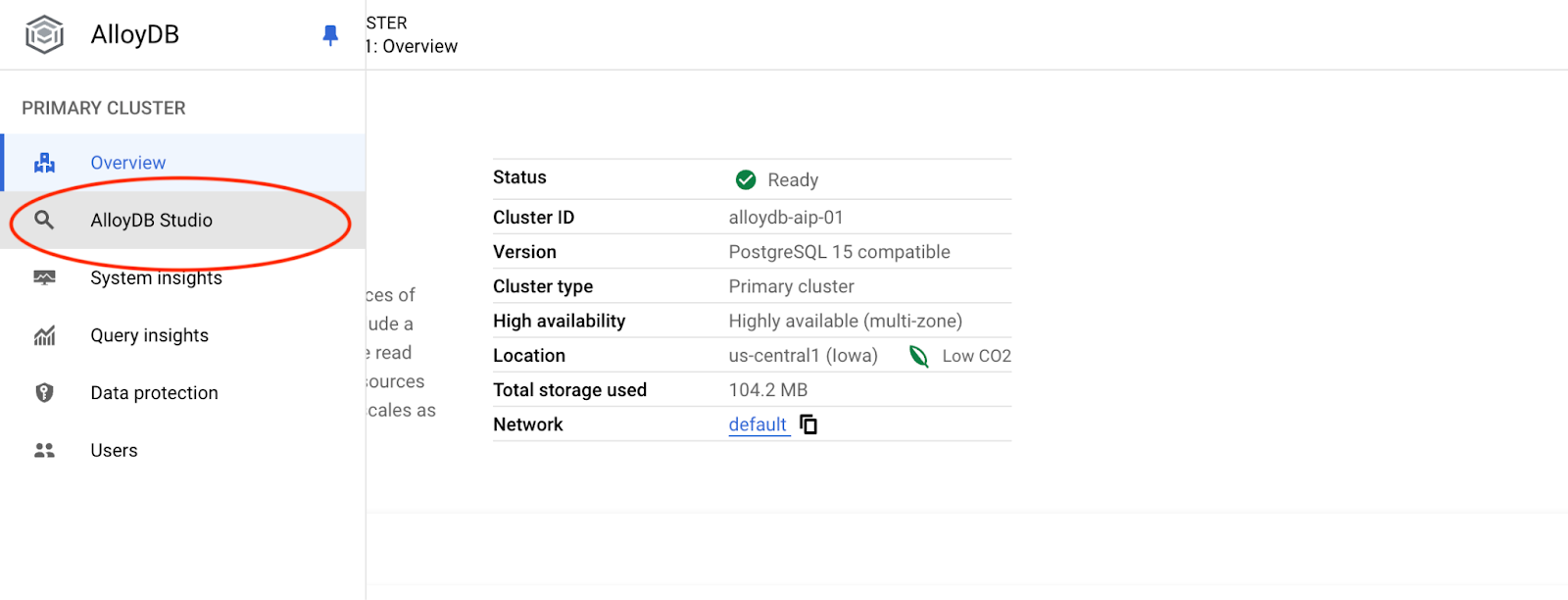
Postgres veritabanını ve postgres kullanıcısını seçin, ardından küme oluşturulurken not edilen şifreyi girin. Ardından "Kimlik doğrulama" düğmesini tıklayın.
AlloyDB Studio arayüzü açılır. Veritabanındaki komutları çalıştırmak için sağdaki "Editor 1" sekmesini tıklayın.
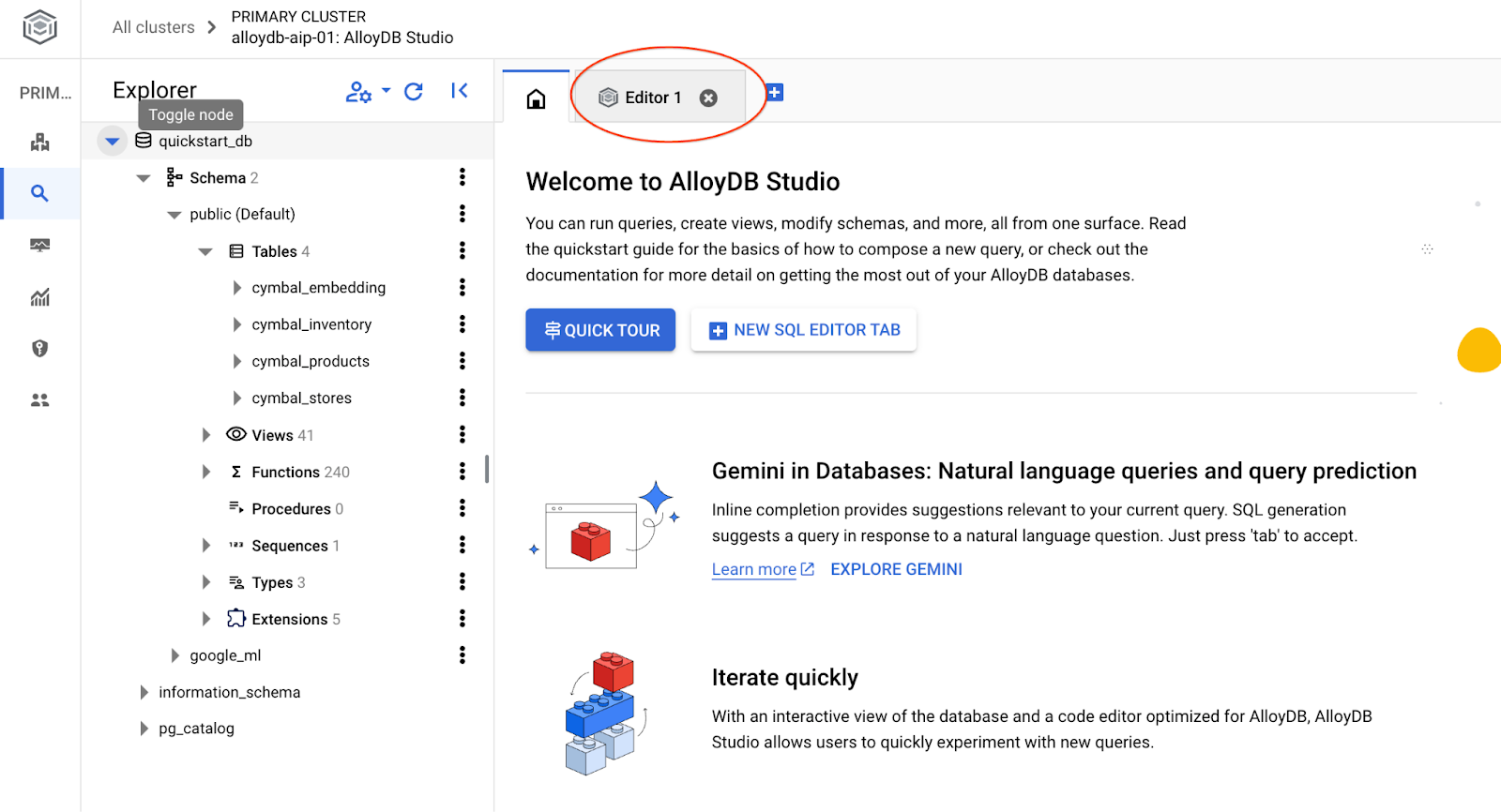
SQL komutlarını çalıştırabileceğiniz bir arayüz açılır.
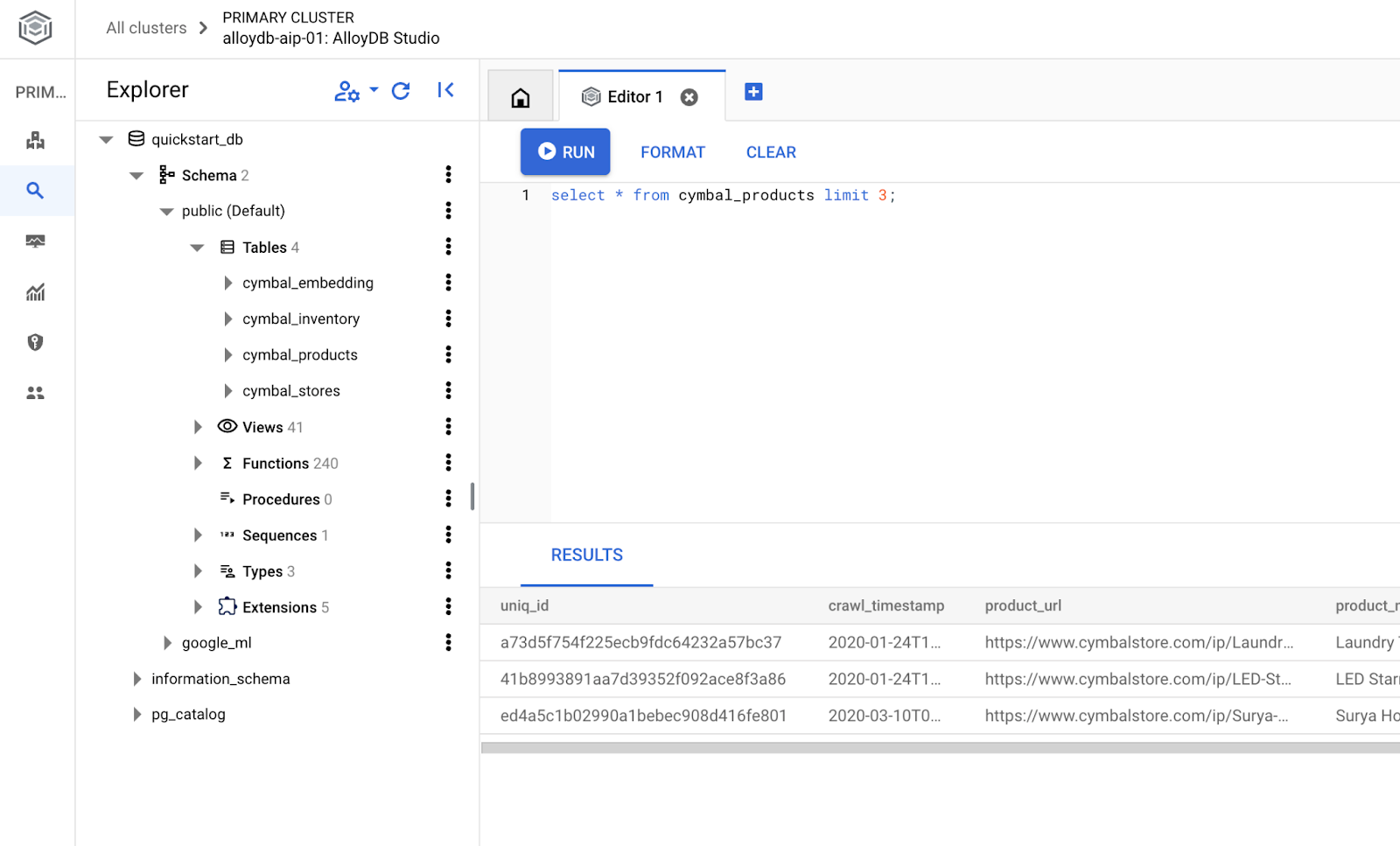
Veritabanı Oluşturma
Veritabanı oluşturma hızlı başlangıç kılavuzu.
AlloyDB Studio Düzenleyici'de aşağıdaki komutu yürütün.
Veritabanı oluşturma:
CREATE DATABASE quickstart_db
Beklenen çıktı:
Statement executed successfully
quickstart_db'ye bağlanma
Kullanıcı/veritabanı değiştirme düğmesini kullanarak stüdyoya yeniden bağlanın.
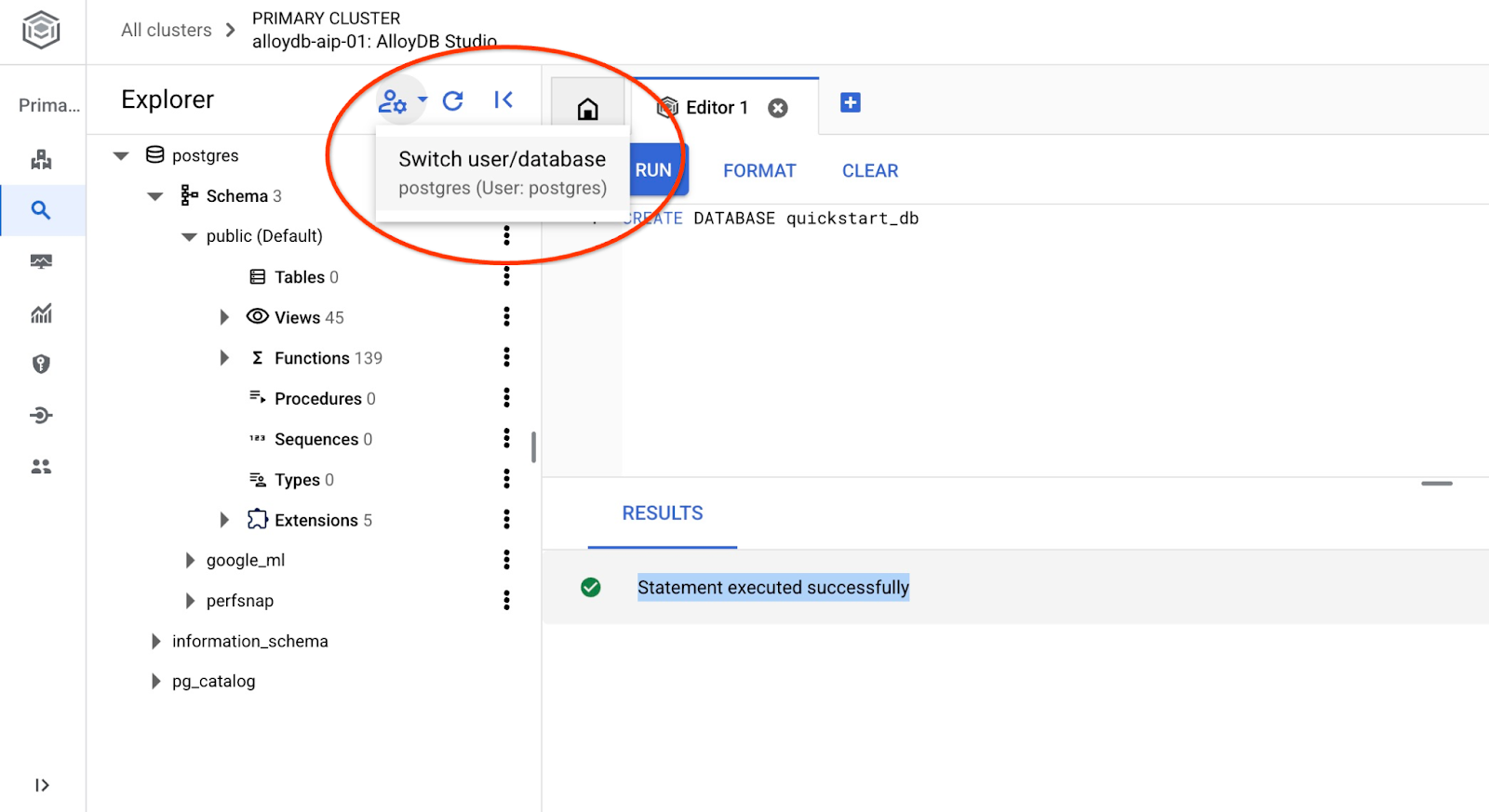
Açılır listeden yeni quickstart_db veritabanını seçin ve daha önce kullandığınız kullanıcı ile şifreyi kullanın.
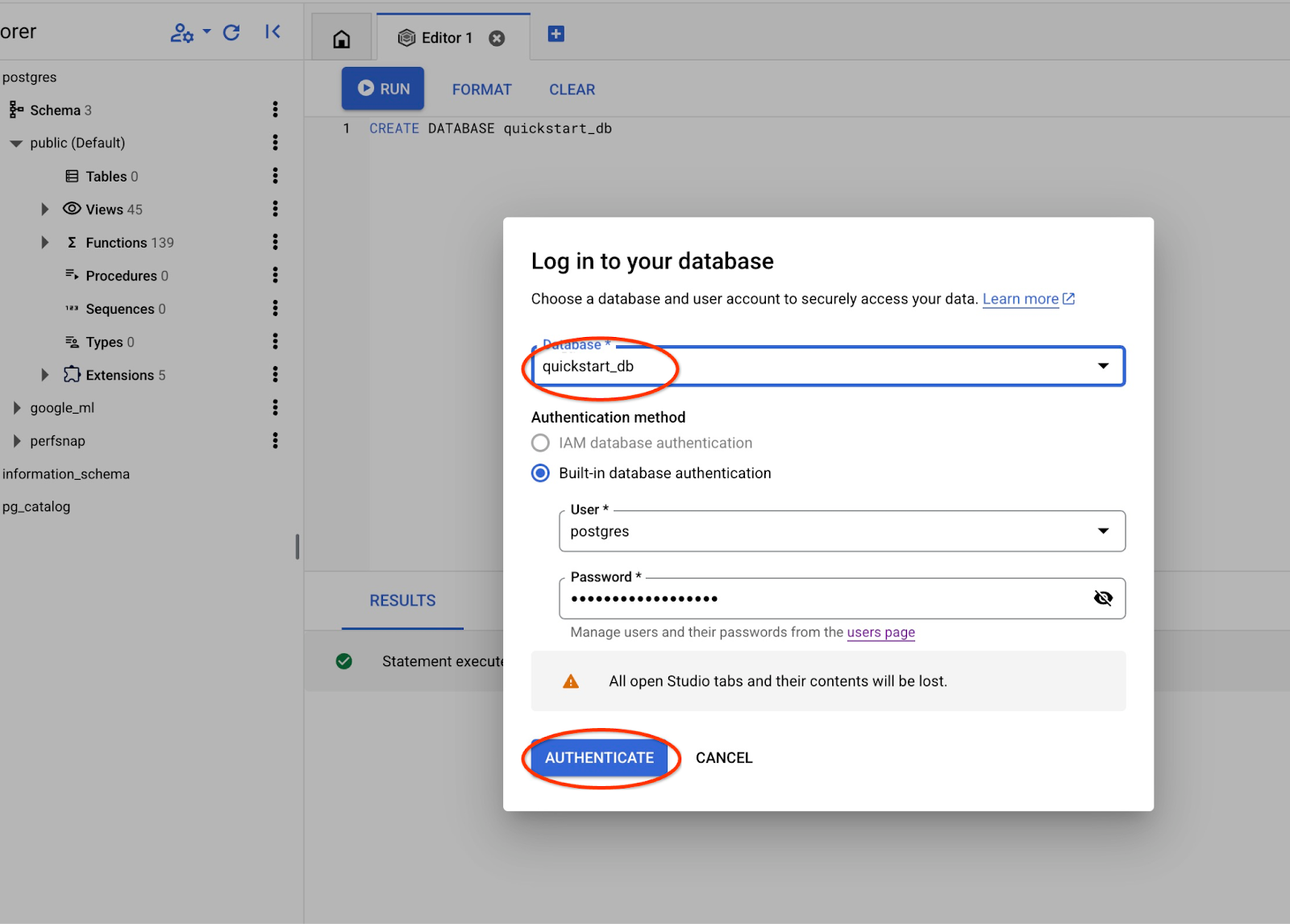
quickstart_db veritabanındaki nesnelerle çalışabileceğiniz yeni bir bağlantı açılır.
6. Örnek Veriler
Şimdi veritabanında nesneler oluşturmamız ve verileri yüklememiz gerekiyor. Online mağazalar için bir dizi tablo içeren kurgusal bir "Cymbal e-ticaret" mağazası kullanacağız. İlişkisel veritabanı şemasına benzeyen anahtarlarla bağlanmış çeşitli tablolar içerir.
Veri kümesi hazırlanır ve içe aktarma arayüzü kullanılarak veritabanına yüklenebilen bir SQL dosyası olarak yerleştirilir. Cloud Shell'de aşağıdaki komutları çalıştırın:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters import $ADBCLUSTER --region=$REGION --database=quickstart_db --gcs-uri='gs://sample-data-and-media/ecomm-retail/ecom_generic.sql' --user=postgres --sql
Komut, AlloyDB SDK'sını kullanır, bir e-ticaret şeması oluşturur ve ardından gerekli tüm nesneleri oluşturup verileri ekleyerek örnek verileri doğrudan GCS paketinden veritabanına aktarır.
İçe aktarma işleminden sonra tabloları AlloyDB Studio'da kontrol edebiliriz.
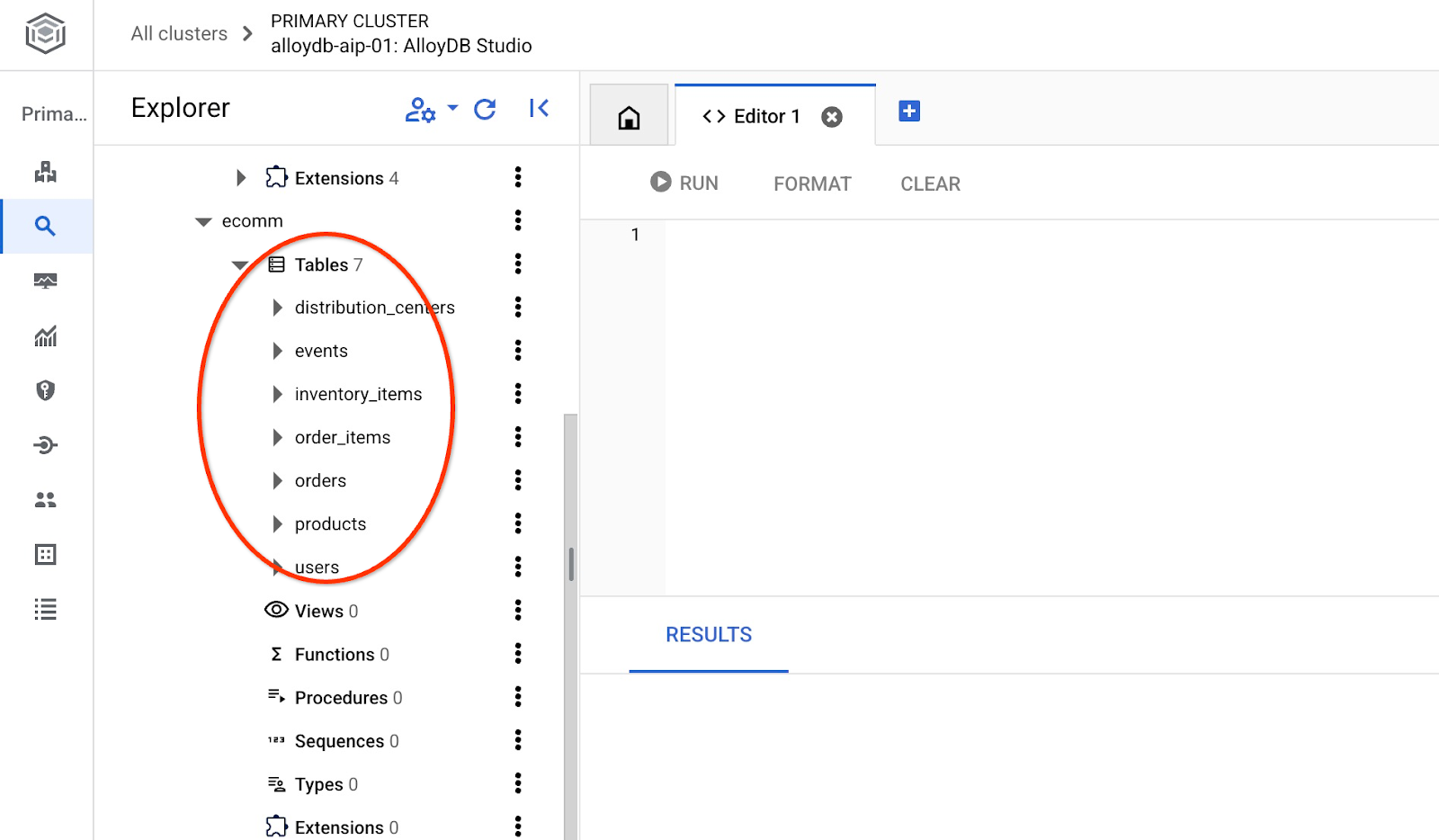
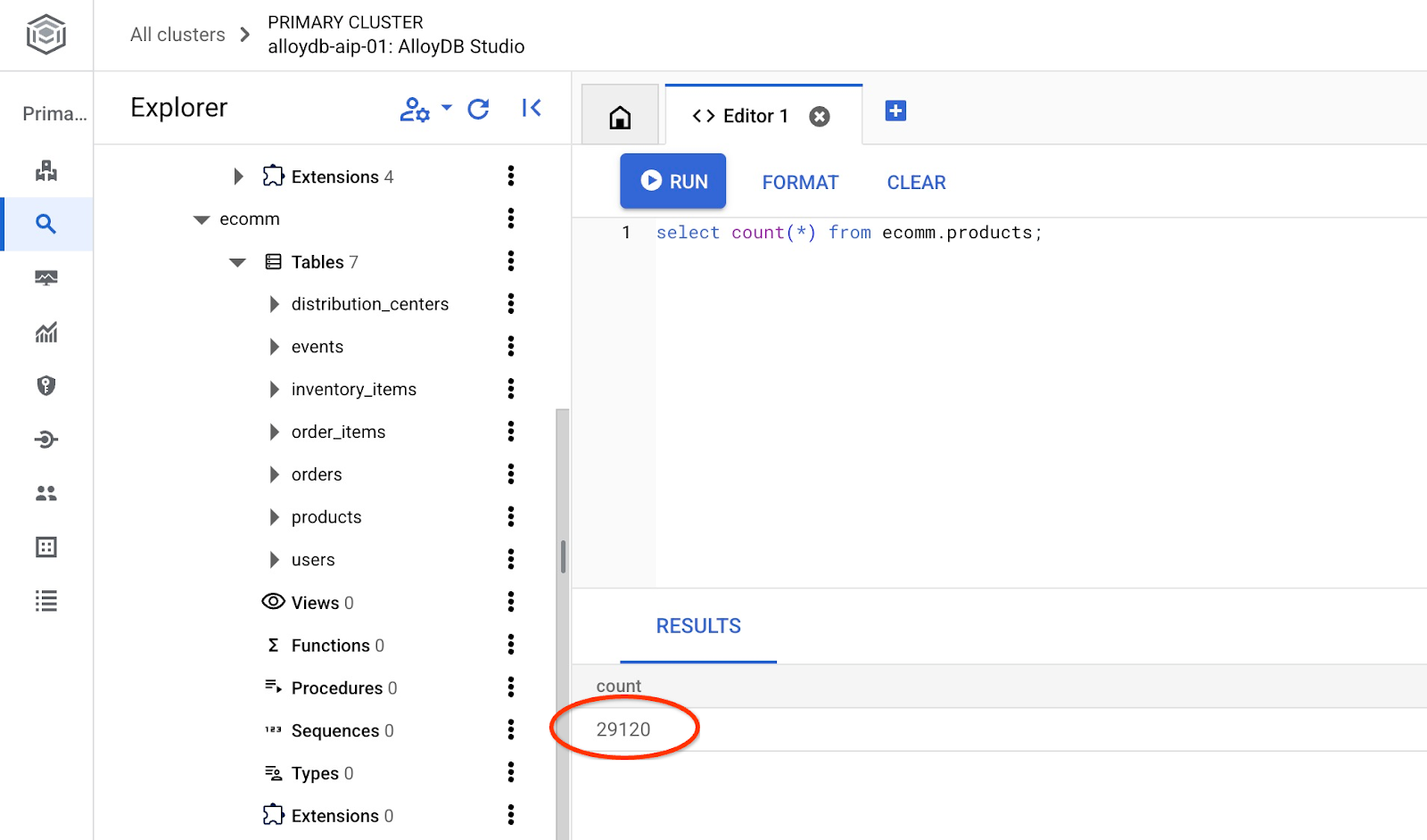
Ayrıca tablodaki satır sayısını doğrulayın.
7. NL SQL'i yapılandırma
Bu bölümde, NL'yi örnek şemanızla çalışacak şekilde yapılandıracağız.
alloydb_nl_ai uzantısını yükleme
Veritabanımıza alloydb_ai_nl uzantısını yüklememiz gerekiyor. Bunu yapmadan önce alloydb_ai_nl.enabled veritabanı işaretini "on" olarak ayarlamamız gerekir.
Cloud Shell oturumunda şunu çalıştırın:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb instances update $ADBCLUSTER-pr \
--cluster=$ADBCLUSTER \
--region=$REGION \
--database-flags=alloydb_ai_nl.enabled=on
Bu işlem, örnek güncellemeyi başlatır. Güncellenen örneğin durumunu web konsolunda görebilirsiniz:
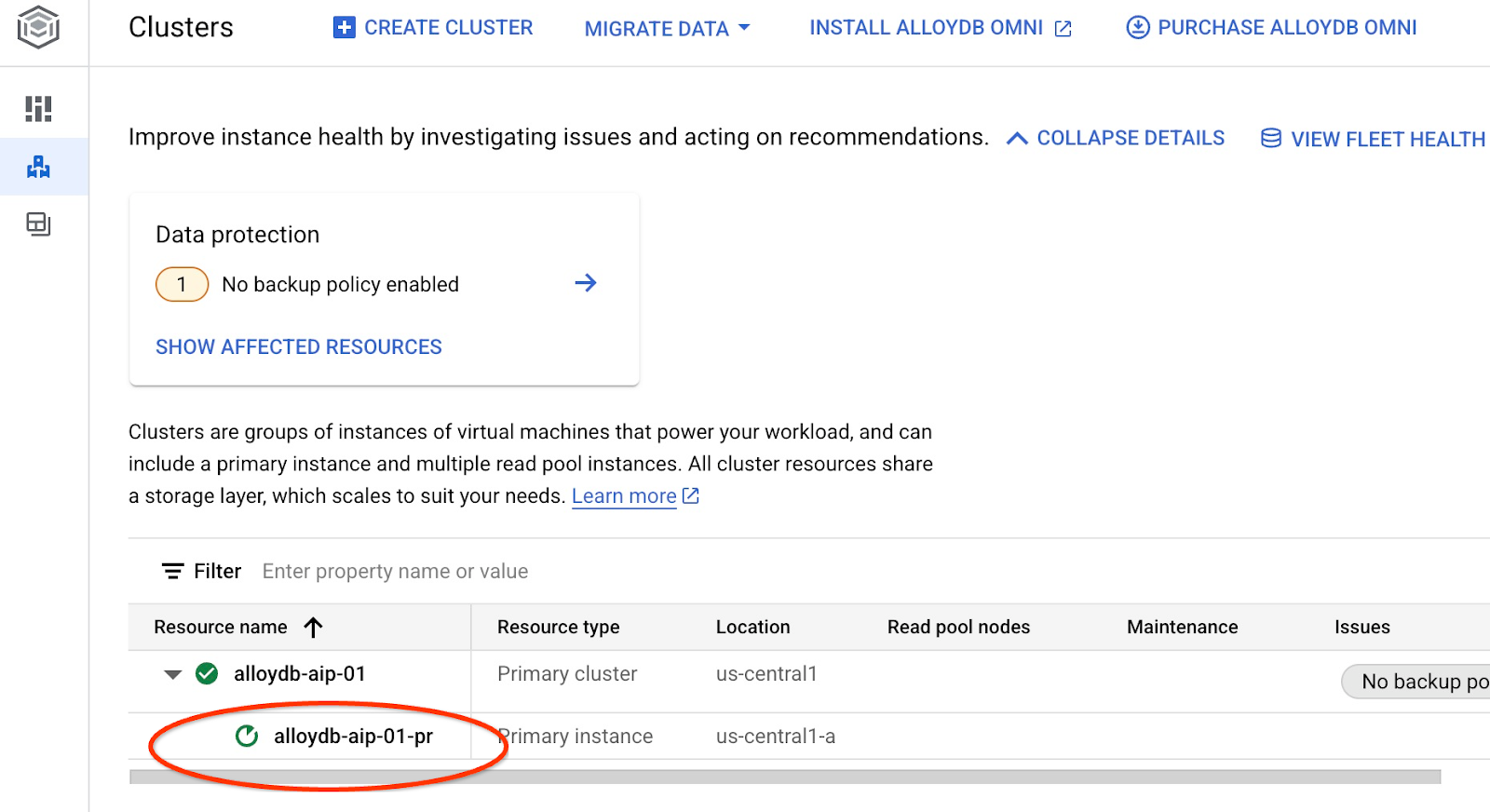
Örnek güncellendiğinde (örnek durumu yeşil olduğunda) alloydb_ai_nl uzantısını etkinleştirebilirsiniz.
AlloyDB Studio'da yürütün.
CREATE EXTENSION IF NOT EXISTS google_ml_integration;
CREATE EXTENSION alloydb_ai_nl cascade;
Doğal dil yapılandırması oluşturma
Uzantıları kullanmak için bir yapılandırma oluşturmamız gerekir. Uygulamaları belirli şemalar, sorgu şablonları ve model uç noktalarıyla ilişkilendirmek için yapılandırma gereklidir. cymbal_ecomm_config kimlikli bir yapılandırma oluşturalım.
AlloyDB Studio'da yürütün.
SELECT
alloydb_ai_nl.g_create_configuration(
configuration_id => 'cymbal_ecomm_config'
);
Artık e-ticaret şemamızı yapılandırmaya kaydedebiliriz. Verileri e-ticaret şemasına aktardığımız için bu şemayı NL yapılandırmamıza ekleyeceğiz.
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'register_schema',
configuration_id_in => 'cymbal_ecomm_config',
schema_names_in => '{ecomm}'
);
8. Doğal Dil SQL'e Bağlam Ekleme
Genel bağlam ekleme
Kayıtlı şemamız için biraz bağlam bilgisi ekleyebiliriz. Bağlam, kullanıcı isteklerine karşılık olarak daha iyi sonuçlar oluşturmaya yardımcı olur. Örneğin, açıkça tanımlanmamış olsa bile bir markanın kullanıcı için tercih edilen marka olduğunu söyleyebiliriz. Clades'i (kurgusal marka) varsayılan markamız olarak ayarlayalım.
AlloyDB Studio'da şunu çalıştırın:
SELECT
alloydb_ai_nl.g_manage_configuration(
operation => 'add_general_context',
configuration_id_in => 'cymbal_ecomm_config',
general_context_in => '{"If the user doesn''t clearly define preferred brand then use Clades."}'
);
Genel bağlamın bizim için nasıl çalıştığını doğrulayalım.
AlloyDB Studio'da şunu çalıştırın:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
);
Oluşturulan sorgu, genel bağlamda daha önce tanımlanan varsayılan markamızı kullanıyor:
{"sql": "SELECT count(*) FROM \"ecomm\".\"products\" WHERE \"brand\" = 'Clades'", "method": "default", "prompt": "", "retries": 0, "time(ms)": {"llm": 505.628000, "magic": 424.019000}, "error_msg": "", "nl_question": "How many products do we have of our preferred brand?", "toolbox_used": false}
Bu ifadeyi temizleyip yalnızca SQL ifadesini çıkış olarak üretebiliriz.
Örneğin:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Temizlenen çıkış:
SELECT count(*) FROM "ecomm"."products" WHERE "brand" = 'Clades'
Sorguyu oluşturmak için ürünler yerine envanter_öğeleri tablosunun otomatik olarak seçildiğini ve kullanıldığını fark ettiniz. Bu yöntem bazı durumlarda işe yarayabilir ancak şemamız için uygun değildir. Bizim durumumuzda inventory_items tablosu, satışları izlemek için kullanılıyor. İçeriden bilgi sahibi değilseniz bu tablo yanıltıcı olabilir. Sorgularımızı nasıl daha doğru hale getirebileceğimizi daha sonra kontrol edeceğiz.
Şema bağlamı
Şema bağlamı, bilgileri şema nesnelerinde yorum olarak depolayan tablolar, görünümler ve bağımsız sütunlar gibi şema nesnelerini açıklar.
Aşağıdaki sorguyu kullanarak tanımlı yapılandırmamızdaki tüm şema nesneleri için otomatik olarak oluşturabiliriz:
SELECT
alloydb_ai_nl.generate_schema_context(
nl_config_id => 'cymbal_ecomm_config',
overwrite_if_exist => TRUE
);
"TRUE" parametresi, bağlamı yeniden oluşturup üzerine yazmamızı sağlar. Yürütme, veri modeline bağlı olarak biraz zaman alır. Ne kadar çok ilişki ve bağlantınız varsa bu işlem o kadar uzun sürebilir.
Bağlamı oluşturduktan sonra şu sorguyu kullanarak envanter öğeleri tablosu için ne oluşturduğunu kontrol edebiliriz:
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.inventory_items';
Temizlenen çıkış:
The `ecomm.inventory_items` table stores information about individual inventory items in an e-commerce system. Each item is uniquely identified by an `id` (primary key). The table tracks the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn't been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men's and women's apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.
Açıklamada, envanter_öğeleri tablosunun öğelerin hareketini yansıttığı bazı önemli bölümler eksik gibi görünüyor. Bu anahtar bilgileri ecomm.inventory_items ilişkisinin bağlamına ekleyerek güncelleyebiliriz.
SELECT alloydb_ai_nl.update_generated_relation_context(
relation_name => 'ecomm.inventory_items',
relation_context => 'The `ecomm.inventory_items` table stores information about moving and sales of inventory items in an e-commerce system. Each movement is uniquely identified by an `id` (primary key) and used in order_items table as `inventory_item_id`. The table tracks sales and movements for the `product_id` (foreign key referencing `ecomm.products`), the timestamp when the movement for the item was `created_at`, and the timestamp when it was `sold_at` (which can be null if the item hasn''t been sold). The `cost` represents the cost of the item to the business, while `product_retail_price` is the price at which the item is sold. Additional product details include `product_category`, `product_name`, `product_brand`, `product_department`, and `product_sku` (stock keeping unit). The `product_distribution_center_id` (foreign key referencing `ecomm.distribution_centers`) indicates the distribution center where the item is located. The table includes information on both men''s and women''s apparel across various categories like jeans, tops & tees, activewear, sleep & lounge, intimates, swim, and accessories. The `sold_at` column indicates whether an item has been sold and when.'
);
Ayrıca, ürün tablomuzun açıklamasının doğruluğunu da doğrulayabiliriz.
SELECT
object_context
FROM
alloydb_ai_nl.generated_schema_context_view
WHERE
schema_object = 'ecomm.products';
Ürün tablosu için otomatik olarak oluşturulan bağlamın oldukça doğru olduğunu ve herhangi bir değişiklik gerektirmediğini gördüm.
Ayrıca her iki tablodaki sütunlarla ilgili bilgileri de kontrol ettim ve bunların da doğru olduğunu gördüm.
Oluşturulan bağlamı ecomm.inventory_items ve ecomm.products için yapılandırmamıza uygulayalım.
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.inventory_items',
overwrite_if_exist => TRUE
);
SELECT alloydb_ai_nl.apply_generated_relation_context(
relation_name => 'ecomm.products',
overwrite_if_exist => TRUE
);
"Tercih ettiğimiz markanın kaç ürünü var?" sorusu için SQL oluşturma sorgumuzu hatırlıyor musunuz? ? Şimdi bunu tekrarlayabilir ve çıktının değişip değişmediğini görebiliriz.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many products do we have of our preferred brand?'
) ->> 'sql';
Yeni çıkış aşağıda verilmiştir.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
Şu anda daha doğru olan ecomm.products'ı kontrol ediyor ve envanter öğeleriyle ilgili 5.000 işlem yerine yaklaşık 300 ürün döndürüyor.
9. Değer diziniyle çalışma
Değer bağlama, değer ifadelerini önceden kaydedilmiş kavram türlerine ve sütun adlarına bağlayarak doğal dil sorgularını zenginleştirir. Sonuçların daha tahmin edilebilir olmasına yardımcı olabilir.
Değer dizinini yapılandırma
Ürünler tablosundaki marka sütununu kullanarak sorgularımızı oluşturabilir ve kavram türünü tanımlayıp ecomm.products.brand sütunuyla ilişkilendirerek markaları daha kararlı olan ürünleri arayabiliriz.
Kavramı oluşturup sütunla ilişkilendirelim:
SELECT alloydb_ai_nl.add_concept_type(
concept_type_in => 'brand_name',
match_function_in => 'alloydb_ai_nl.get_concept_and_value_generic_entity_name',
additional_info_in => '{
"description": "Concept type for brand name.",
"examples": "SELECT alloydb_ai_nl.get_concept_and_value_generic_entity_name(''Auto Forge'')" }'::jsonb
);
SELECT alloydb_ai_nl.associate_concept_type(
column_names_in => 'ecomm.products.brand',
concept_type_in => 'brand_name',
nl_config_id_in => 'cymbal_ecomm_config'
);
alloydb_ai_nl.list_concept_types() işlevini sorgulayarak kavramı doğrulayabilirsiniz.
SELECT alloydb_ai_nl.list_concept_types();
Ardından, oluşturulan ve önceden oluşturulmuş tüm ilişkilendirmeler için yapılandırmamızda dizini oluşturabiliriz:
SELECT alloydb_ai_nl.create_value_index(
nl_config_id_in => 'cymbal_ecomm_config'
);
Değer dizinini kullanma
Marka adlarını kullanarak SQL oluşturmak için sorgu çalıştırırsanız ancak bunun bir marka adı olduğunu tanımlamazsanız bu, öğeyi ve sütunu doğru şekilde tanımlamaya yardımcı olur. Sorgu:
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'How many Clades do we have?'
) ->> 'sql';
Çıkışta ise "Clades" kelimesinin marka adı olarak doğru şekilde tanımlandığı gösteriliyor.
SELECT COUNT(*) FROM "ecomm"."products" WHERE "brand" = 'Clades';
10. Sorgu şablonlarıyla çalışma
Sorgu şablonları, işletme açısından kritik uygulamalar için kararlı sorgular tanımlamaya yardımcı olarak belirsizliği azaltır ve doğruluğu artırır.
Sorgu şablonu oluşturma
Geçen yıl "Republic Outpost" ürünlerini satın alan müşteriler hakkında bilgi edinmek için birkaç tabloyu birleştiren bir sorgu şablonu oluşturalım. Her ikisinde de markalarla ilgili bilgiler bulunduğundan sorgunun ecomm.products tablosunu veya ecomm.inventory_items tablosunu kullanabileceğini biliyoruz. Ancak products tablosunda 15 kat daha az satır ve birleştirme için birincil anahtarda bir dizin vardır. Ürün tablosunu kullanmak daha verimli olabilir. Bu nedenle, sorgu için bir şablon oluşturuyoruz.
SELECT alloydb_ai_nl.add_template(
nl_config_id => 'cymbal_ecomm_config',
intent => 'List the last names and the country of all customers who bought products of `Republic Outpost` in the last year.',
sql => 'SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = ''Republic Outpost'' AND oi.created_at >= DATE_TRUNC(''year'', CURRENT_DATE - INTERVAL ''1 year'') AND oi.created_at < DATE_TRUNC(''year'', CURRENT_DATE)',
sql_explanation => 'To answer this question, JOIN `ecomm.users` with `ecom.order_items` on having the same `users.id` and `order_items.user_id`, and JOIN the result with ecom.products on having the same `order_items.product_id` and `products.id`. Then filter rows with products.brand = ''Republic Outpost'' and by `order_items.created_at` for the last year. Return the `last_name` and the `country` of the users with matching records.',
check_intent => TRUE
);
Artık sorgu oluşturma isteğinde bulunabiliriz.
SELECT
alloydb_ai_nl.get_sql(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
) ->> 'sql';
Ve istenen çıktıyı üretir.
SELECT DISTINCT u."last_name", u."country" FROM "ecomm"."users" AS u INNER JOIN "ecomm"."order_items" AS oi ON u.id = oi."user_id" INNER JOIN "ecomm"."products" AS ep ON oi.product_id = ep.id WHERE ep.brand = 'Republic Outpost' AND oi.created_at >= DATE_TRUNC('year', CURRENT_DATE - INTERVAL '1 year') AND oi.created_at < DATE_TRUNC('year', CURRENT_DATE)
Alternatif olarak, aşağıdaki sorguyu kullanarak sorguyu doğrudan yürütebilirsiniz:
SELECT
alloydb_ai_nl.execute_nl_query(
nl_config_id => 'cymbal_ecomm_config',
nl_question => 'Show me last name and country about customers who bought "Republic Outpost" products last year.'
);
Sonuçları ayrıştırılabilecek JSON biçiminde döndürür.
execute_nl_query
--------------------------------------------------------
{"last_name":"Adams","country":"China"}
{"last_name":"Adams","country":"Germany"}
{"last_name":"Aguilar","country":"China"}
{"last_name":"Allen","country":"China"}
11. Ortamı temizleme
Laboratuvarı tamamladığınızda AlloyDB örneklerini ve kümeyi yok edin.
AlloyDB kümesini ve tüm örnekleri silme
AlloyDB'nin deneme sürümünü kullandıysanız Deneme kümesini kullanarak diğer laboratuvarları ve kaynakları test etmeyi planlıyorsanız deneme kümesini silmeyin. Aynı projede başka bir deneme kümesi oluşturamazsınız.
Küme, zorlama seçeneğiyle yok edilir. Bu seçenek, kümeye ait tüm örnekleri de siler.
Bağlantınız kesildiyse ve önceki tüm ayarlar kaybolduysa Cloud Shell'de proje ve ortam değişkenlerini tanımlayın:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Kümeyi silme:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB Yedeklemelerini Silme
Kümenin tüm AlloyDB yedeklerini silin:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Beklenen konsol çıkışı:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
12. Tebrikler
Codelab'i tamamladığınız için tebrik ederiz. Artık AlloyDB'nin NL2SQL özelliklerini kullanarak kendi çözümlerinizi uygulamayı deneyebilirsiniz. AlloyDB ve AlloyDB AI ile ilgili diğer codelab'leri denemenizi öneririz. AlloyDB'de çok formatlı yerleştirme işlemlerinin nasıl çalıştığını bu codelab'de inceleyebilirsiniz.
İşlediğimiz konular
- AlloyDB for Postgres'i dağıtma
- AlloyDB AI doğal dilini etkinleştirme
- Yapay zeka doğal dili için yapılandırma oluşturma ve ayarlama
- Doğal dili kullanarak SQL sorguları oluşturma ve sonuç alma
13. Anket
Çıkış: