
1. Einführung
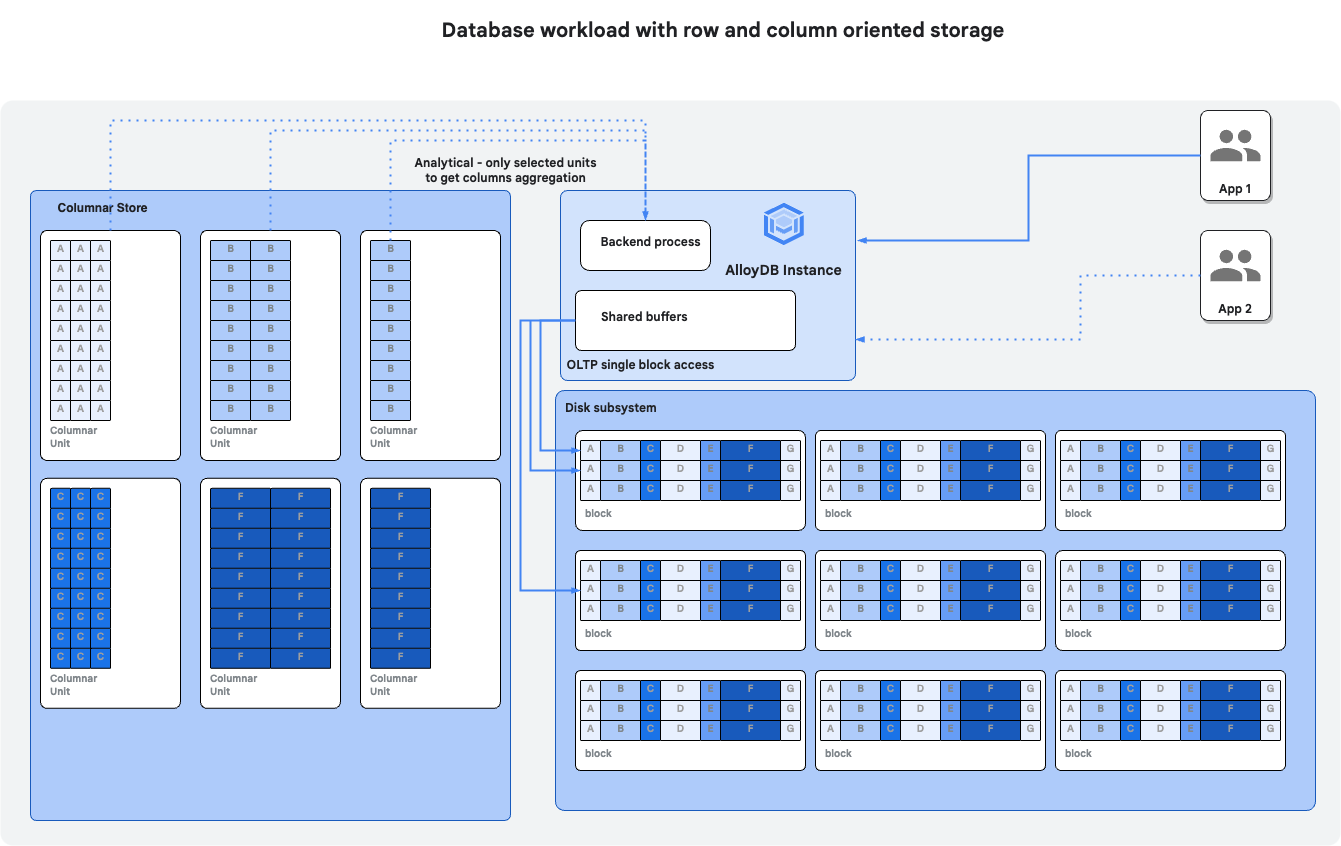
In diesem Codelab erfahren Sie, wie Sie AlloyDB Omni bereitstellen und die spaltenbasierte Engine verwenden, um die Leistung von Abfragen zu verbessern.
Voraussetzungen
- Grundlegende Kenntnisse der Google Cloud Console
- Grundkenntnisse in der Befehlszeile und Google Shell
Lerninhalte
- AlloyDB Omni auf einer GCE-VM in Google Cloud bereitstellen
- Verbindung zu AlloyDB Omni herstellen
- Daten in AlloyDB Omni laden
- Spaltenbasierte Engine aktivieren
- Spaltenbasierte Engine im automatischen Modus prüfen
- Spaltenspeicher manuell mit Daten füllen
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome
2. Einrichtung und Anforderungen
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Es handelt sich um einen String, der nicht von Google APIs verwendet wird. Sie können sie jederzeit aktualisieren.
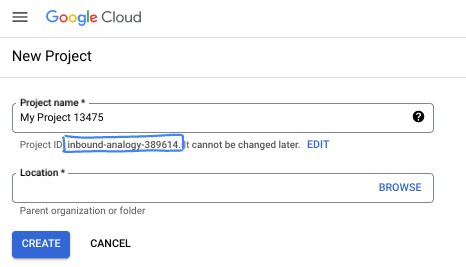
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich (kann nach dem Festlegen nicht mehr geändert werden). In der Cloud Console wird automatisch ein eindeutiger String generiert. Normalerweise ist es nicht wichtig, wie dieser String aussieht. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie einen eigenen Namen eingeben und prüfen, ob er verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Cloud-Ressourcen/-APIs zu verwenden. Die Durchführung dieses Codelabs kostet wenig oder gar nichts. Wenn Sie Ressourcen herunterfahren möchten, um Kosten zu vermeiden, die über diese Anleitung hinausgehen, können Sie die erstellten Ressourcen oder das Projekt löschen. Neue Google Cloud-Nutzer können am kostenlosen Testzeitraum mit einem Guthaben von 300 $ teilnehmen.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Hinweis
API aktivieren
Ausgabe:
Prüfen Sie in Cloud Shell, ob Ihre Projekt-ID eingerichtet ist:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Erwartete Ausgabe
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) our active configuration is: [cloudshell-14650] student@cloudshell:~ (test-project-001-402417)$
Wenn sie nicht in der Cloud Shell-Konfiguration definiert ist, richten Sie sie mit den folgenden Befehlen ein.
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Aktivieren Sie alle erforderlichen Dienste:
gcloud services enable compute.googleapis.com
Erwartete Ausgabe
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. AlloyDB Omni in GCE bereitstellen
Um AlloyDB Omni in GCE bereitzustellen, müssen wir eine virtuelle Maschine mit kompatibler Konfiguration und Software vorbereiten. Hier ist ein Beispiel für die Bereitstellung von AlloyDB Omni auf einer Debian-basierten VM.
GCE-VM erstellen
Wir müssen eine VM mit einer akzeptablen Konfiguration für CPU, Arbeitsspeicher und Speicher bereitstellen. Wir verwenden das Standard-Debian-Image mit einer auf 20 GB erhöhten Systemlaufwerkgröße, um die AlloyDB Omni-Datenbankdateien aufzunehmen.
Wir können die gestartete Cloud Shell oder ein Terminal mit installiertem Cloud SDK verwenden.
Alle Schritte sind auch in der Kurzanleitung für AlloyDB Omni beschrieben.
Richten Sie die Umgebungsvariablen für Ihre Bereitstellung ein.
export ZONE=us-central1-a
export MACHINE_TYPE=n2-highmem-2
export DISK_SIZE=20
export MACHINE_NAME=omni01
Anschließend verwenden wir gcloud, um die GCE-VM zu erstellen.
gcloud compute instances create $MACHINE_NAME \
--project=$(gcloud info --format='value(config.project)') \
--zone=$ZONE --machine-type=$MACHINE_TYPE \
--metadata=enable-os-login=true \
--create-disk=auto-delete=yes,boot=yes,size=$DISK_SIZE,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" \
--format="value(name)"),type=pd-ssd
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ export ZONE=us-central1-a
export MACHINE_TYPE=n2-highmem-2
export DISK_SIZE=20
export MACHINE_NAME=omni01
student@cloudshell:~ (test-project-001-402417)$ gcloud compute instances create $MACHINE_NAME \
--project=$(gcloud info --format='value(config.project)') \
--zone=$ZONE --machine-type=$MACHINE_TYPE \
--metadata=enable-os-login=true \
--create-disk=auto-delete=yes,boot=yes,size=$DISK_SIZE,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" \
--format="value(name)"),type=pd-ssd
Created [https://www.googleapis.com/compute/v1/projects/test-project-001-402417/zones/us-central1-a/instances/omni01].
WARNING: Some requests generated warnings:
- Disk size: '20 GB' is larger than image size: '10 GB'. You might need to resize the root repartition manually if the operating system does not support automatic resizing. See https://cloud.google.com/compute/docs/disks/add-persistent-disk#resize_pd for details.
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: n2-highmem-2
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (test-project-001-402417)$
AlloyDB Omni installieren
Stellen Sie eine Verbindung zur erstellten VM her:
gcloud compute ssh omni01 --zone $ZONE
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ gcloud compute ssh omni01 --zone $ZONE Warning: Permanently added 'compute.5615760774496706107' (ECDSA) to the list of known hosts. Linux omni01.us-central1-a.c.gleb-test-short-003-421517.internal 6.1.0-20-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.85-1 (2024-04-11) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@omni01:~$
Führen Sie den folgenden Befehl in Ihrem verbundenen Terminal aus.
Installieren Sie Docker auf der VM:
sudo apt update
sudo apt-get -y install docker.io
Erwartete Konsolenausgabe(redigiert):
student@omni01:~$ sudo apt update sudo apt-get -y install docker.io Get:1 file:/etc/apt/mirrors/debian.list Mirrorlist [30 B] Get:5 file:/etc/apt/mirrors/debian-security.list Mirrorlist [39 B] Get:7 https://packages.cloud.google.com/apt google-compute-engine-bookworm-stable InRelease [5146 B] Get:8 https://packages.cloud.google.com/apt cloud-sdk-bookworm InRelease [6406 B] Get:9 https://packages.cloud.google.com/apt google-compute-engine-bookworm-stable/main amd64 Packages [1916 B] Get:2 https://deb.debian.org/debian bookworm InRelease [151 kB] ... Setting up binutils (2.40-2) ... Setting up needrestart (3.6-4+deb12u1) ... Processing triggers for man-db (2.11.2-2) ... Processing triggers for libc-bin (2.36-9+deb12u4) ... student@omni01:~$
Legen Sie ein Passwort für den Postgres-Nutzer fest:
export PGPASSWORD=<your password>
Erstellen Sie ein Verzeichnis für AlloyDB Omni-Daten. Dies ist ein optionaler, aber empfohlener Ansatz. Standardmäßig werden die Daten mit der flüchtigen Dateisystemebene von Docker erstellt und alles wird gelöscht, wenn der Docker-Container gelöscht wird. Wenn Sie sie separat speichern, können Sie Container unabhängig von Ihren Daten verwalten und sie optional in einem Speicher mit besseren E/A-Eigenschaften platzieren.
Hier ist ein Befehl zum Erstellen eines Verzeichnisses im Basisverzeichnis des Nutzers, in dem alle Daten abgelegt werden:
mkdir -p $HOME/alloydb-data
AlloyDB Omni-Container bereitstellen:
sudo docker run --name my-omni \
-e POSTGRES_PASSWORD=$PGPASSWORD \
-p 5432:5432 \
-v $HOME/alloydb-data:/var/lib/postgresql/data \
-v /dev/shm:/dev/shm \
-d google/alloydbomni
Erwartete Konsolenausgabe(redigiert):
student@omni01:~$ export PGPASSWORD=StrongPassword student@omni01:~$ sudo docker run --name my-omni \ -e POSTGRES_PASSWORD=$PGPASSWORD \ -p 5432:5432 \ -v $HOME/alloydb-data:/var/lib/postgresql/data \ -v /dev/shm:/dev/shm \ -d google/alloydbomni Unable to find image 'google/alloydbomni:latest' locally latest: Pulling from google/alloydbomni 71215d55680c: Pull complete ... 2e0ec3fe1804: Pull complete Digest: sha256:d6b155ea4c7363ef99bf45a9dc988ce5467df5ae8cd3c0f269ae9652dd1982a6 Status: Downloaded newer image for google/alloydbomni:latest 56de4ae0018314093c8b048f69a1e9efe67c6c8117f44c8e1dc829a2d4666cd2 student@omni01:~$
Installieren Sie die PostgreSQL-Clientsoftware auf der VM (optional – sie sollte bereits installiert sein):
sudo apt install -y postgresql-client
Erwartete Konsolenausgabe:
student@omni01:~$ sudo apt install -y postgresql-client Reading package lists... Done Building dependency tree... Done Reading state information... Done postgresql-client is already the newest version (15+248). 0 upgraded, 0 newly installed, 0 to remove and 4 not upgraded.
Verbindung zu AlloyDB Omni herstellen:
psql -h localhost -U postgres
Erwartete Konsolenausgabe:
student@omni01:~$ psql -h localhost -U postgres
WARNING: psql major version 15, server major version 17.
Some psql features might not work.
Type "help" for help.
postgres=#
Verbindung zu AlloyDB Omni trennen:
exit
Erwartete Konsolenausgabe:
postgres=# exit student@omni01:~$
5. Testdatenbank vorbereiten
Zum Testen der spaltenbasierten Engine müssen wir eine Datenbank erstellen und mit einigen Testdaten füllen.
Datenbank erstellen
Verbindung zur AlloyDB Omni-VM herstellen und Datenbank erstellen
Führen Sie in der Cloud Shell-Sitzung Folgendes aus:
Verbindung zur AlloyDB Omni-VM herstellen:
ZONE=us-central1-a
gcloud compute ssh omni01 --zone $ZONE
Erwartete Konsolenausgabe:
student@cloudshell:~ (gleb-test-short-001-416213)$ ZONE=us-central1-a gcloud compute ssh omni01 --zone $ZONE Linux omni01.us-central1-a.c.gleb-test-short-003-421517.internal 6.1.0-20-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.85-1 (2024-04-11) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. Last login: Mon Mar 4 18:17:55 2024 from 35.237.87.44 student@omni01:~$
Führen Sie in der eingerichteten SSH-Sitzung den folgenden Befehl aus:
export PGPASSWORD=<your password>
psql -h localhost -U postgres -c "CREATE DATABASE quickstart_db"
Erwartete Konsolenausgabe:
student@omni01:~$ psql -h localhost -U postgres -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@omni01:~$
Tabelle mit Beispieldaten erstellen
Für unsere Tests verwenden wir öffentliche Daten zu in Iowa lizenzierten Versicherungsvertretern. Dieses Dataset finden Sie auf der Website der Regierung von Iowa: https://data.iowa.gov/catalog/dataset/669 .
Zuerst müssen wir eine Tabelle erstellen.
Führen Sie auf der GCE-VM Folgendes aus:
psql -h localhost -U postgres -d quickstart_db -c "DROP TABLE if exists insurance_producers_licensed_in_iowa;
CREATE TABLE insurance_producers_licensed_in_iowa (
npn int8,
last_name text,
first_name text,
address_line_1 text,
city text,
state text,
zip_code int4,
first_active_date timestamp,
expiry_date timestamp,
business_phone text,
email text,
iowa_resident text,
loa_has_crop text,
loa_has_surety text,
loa_has_ah text,
loa_has_life text,
loa_has_variable text,
loa_has_personal_lines text,
loa_has_credit text,
loa_has_excess text,
loa_has_property text,
loa_has_casualty text,
loa_has_reciprocal text,
latitude text,
longitude text,
physical_location text,
address_line_2 text,
address_line_3 text
);"
Erwartete Konsolenausgabe:
otochkin@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "DROP TABLE if exists insurance_producers_licensed_in_iowa;
CREATE TABLE insurance_producers_licensed_in_iowa (
npn int8,
last_name text,
first_name text,
address_line_1 text,
address_line_2 text,
address_line_3 text,
city text,
state text,
zip int4,
firstactivedate timestamp,
expirydate timestamp,
business_phone text,
email text,
physical_location text,
iowaresident text,
loa_has_crop text,
loa_has_surety text,
loa_has_ah text,
loa_has_life text,
loa_has_variable text,
loa_has_personal_lines text,
loa_has_credit text,
loa_has_excess text,
loa_has_property text,
loa_has_casualty text,
loa_has_reciprocal text
);"
NOTICE: table "insurance_producers_licensed_in_iowa" does not exist, skipping
DROP TABLE
CREATE TABLE
otochkin@omni01:~$
Laden Sie Daten in die Tabelle.
Führen Sie auf der GCE-VM Folgendes aus:
curl -L https://idh-be.iowa.gov/api/v1/datasets/669/rows.csv | sed '$d' | psql -h localhost -U postgres -d quickstart_db -c "\copy insurance_producers_licensed_in_iowa from stdin csv header"
Erwartete Konsolenausgabe:
otochkin@omni01:~$ curl -L https://idh-be.iowa.gov/api/v1/datasets/669/rows.csv | sed '$d' | psql -h localhost -U postgres -d quickstart_db -c "\copy insurance_producers_licensed_in_iowa from stdin csv header"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 48.0M 0 48.0M 0 0 33.9M 0 --:--:-- 0:00:01 --:--:-- 33.9M
COPY 226772
otochkin@omni01:~$
Wir haben 226.772 Datensätze zu Versicherungsvertretern in unsere Datenbank geladen und können einige Tests durchführen. Die Anzahl der Zeilen kann bei Ihnen abweichen, da das Dataset täglich aktualisiert wird.
Testabfragen ausführen
Stellen Sie mit psql eine Verbindung zu „quickstart_db“ her und aktivieren Sie die Zeitmessung, um die Ausführungszeit für unsere Abfragen zu messen.
Führen Sie auf der GCE-VM Folgendes aus:
psql -h localhost -U postgres -d quickstart_db
Erwartete Konsolenausgabe:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db
psql (15.18 (Debian 15.18-0+deb12u1), server 17.7)
WARNING: psql major version 15, server major version 17.
Some psql features might not work.
Type "help" for help.
quickstart_db=#
Führen Sie in der PSQL-Sitzung den folgenden Befehl aus:
\timing
Erwartete Konsolenausgabe:
quickstart_db=# \timing Timing is on. quickstart_db=#
Wir suchen die fünf Städte mit den meisten Versicherungsvertretern, die Unfall- und Krankenversicherungen verkaufen und deren Lizenz mindestens für die nächsten sechs Monate gültig ist.
Führen Sie in der PSQL-Sitzung den folgenden Befehl aus:
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Erwartete Konsolenausgabe:
quickstart_db=# SELECT city, count(*)
quickstart_db-# FROM insurance_producers_licensed_in_iowa
quickstart_db-# WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
quickstart_db-# GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 2159
OMAHA | 1527
MIAMI | 1293
KANSAS CITY | 1091
DALLAS | 1000
(5 rows)
Time: 90.492 ms
Führen Sie eine Testabfrage möglichst mehrmals aus, um eine zuverlässige Ausführungszeit zu erhalten. Die durchschnittliche Zeit für die Rückgabe des Ergebnisses beträgt etwa 94 ms. In den folgenden Schritten aktivieren wir die spaltenbasierte Engine von AlloyDB und prüfen, ob sich die Leistung dadurch verbessern lässt.
Beenden Sie die psql-Sitzung:
exit
6. Spaltenbasierte Engine aktivieren
Jetzt müssen wir die spaltenbasierte Engine in AlloyDB Omni aktivieren.
AlloyDB Omni-Parameter aktualisieren
Wir müssen den Instanzparameter „google_columnar_engine.enabled“ für unsere AlloyDB Omni-Instanz auf „on“ setzen. Dazu ist ein Neustart erforderlich.
Aktualisieren Sie die Datei „postgresql.conf“ im Verzeichnis „/var/alloydb/config“ und starten Sie die Instanz neu.
Führen Sie auf der GCE-VM Folgendes aus:
sudo docker exec my-omni /bin/bash -c "echo 'google_columnar_engine.enabled=true' >> /var/lib/postgresql/data/postgresql.conf" && \
sudo docker exec my-omni /bin/bash -c "echo \"shared_preload_libraries='google_columnar_engine,google_job_scheduler,google_db_advisor,google_storage'\" >> /var/lib/postgresql/data/postgresql.conf" && \
sudo docker restart my-omni
Erwartete Konsolenausgabe:
student@omni01:~$ sudo docker exec my-omni /bin/bash -c "echo 'google_columnar_engine.enabled=true' >> /var/lib/postgresql/data/postgresql.conf" && \ > sudo docker exec my-omni /bin/bash -c "echo \"shared_preload_libraries='google_columnar_engine,google_job_scheduler,google_db_advisor,google_storage'\" >> /var/lib/postgresql/data/postgresql.conf" && \ > sudo docker restart my-omni my-omni student@omni01:~$
Spaltenbasierte Engine überprüfen
Stellen Sie mit psql eine Verbindung zur Datenbank her und prüfen Sie die spaltenbasierte Engine.
Verbindung zur AlloyDB Omni-Datenbank herstellen
Stellen Sie in der VM-SSH-Sitzung eine Verbindung zur Datenbank her:
psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.enabled"
Der Befehl sollte die aktivierte spaltenorientierte Engine anzeigen.
Erwartete Konsolenausgabe:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.enabled" google_columnar_engine.enabled -------------------------------- on (1 row)
7. Leistungsvergleich
Wir können jetzt den spaltenbasierten Engine-Speicher füllen und die Leistung überprüfen.
Automatisches Befüllen des spaltenbasierten Speichers
Standardmäßig wird der Job, mit dem der Store gefüllt wird, stündlich ausgeführt. Wir werden diese Zeit auf 10 Minuten verkürzen, um Wartezeiten zu vermeiden.
Führen Sie auf der GCE-VM Folgendes aus:
sudo docker exec my-omni /bin/bash -c "echo google_columnar_engine.auto_columnarization_schedule=\'EVERY 10 MINUTES\' >>/var/lib/postgresql/data/postgresql.conf" && \
sudo docker restart my-omni
Und hier ist die erwartete Ausgabe:
sudo docker exec my-omni /bin/bash -c "echo google_columnar_engine.auto_columnarization_schedule=\'EVERY 10 MINUTES\' >>/var/lib/postgresql/data/postgresql.conf" && \ > sudo docker restart my-omni my-omni
Einstellungen überprüfen
Führen Sie auf der GCE-VM Folgendes aus:
psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.auto_columnarization_schedule;"
Erwartete Ausgabe:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.auto_columnarization_schedule;" google_columnar_engine.auto_columnarization_schedule ------------------------------------------------------ EVERY 10 MINUTES (1 row) student@omni01:~$
Prüfen Sie die Objekte im Columnar Store. Sie sollte leer sein.
Führen Sie auf der GCE-VM Folgendes aus:
psql -h localhost -U postgres -d quickstart_db -c "SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;"
Erwartete Ausgabe:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;" database_name | schema_name | relation_name | column_name ---------------+-------------+---------------+------------- (0 rows) student@omni01:~$
Stellen Sie eine Verbindung zur Datenbank her und führen Sie die gleiche Abfrage, die wir zuvor ausgeführt haben, mehrmals aus.
Führen Sie auf der GCE-VM Folgendes aus:
psql -h localhost -U postgres -d quickstart_db
In der PSQL-Sitzung.
Timing aktivieren
\timing
Führen Sie die Abfrage einige Male aus:
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Erwartete Ausgabe:
quickstart_db=# SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 1885
OMAHA | 1656
KANSAS CITY | 1279
AUSTIN | 1254
MIAMI | 1003
(5 rows)
Time: 81.428 ms
quickstart_db=# SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 1885
OMAHA | 1656
KANSAS CITY | 1279
AUSTIN | 1254
MIAMI | 1003
(5 rows)
Time: 82.608 ms
quickstart_db=#
Warten Sie 10 Minuten und prüfen Sie, ob die Spalten der Tabelle „insurance_producers_licensed_in_iowa“ in den spaltenorientierten Speicher übertragen wurden.
SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;
Erwartete Ausgabe:
quickstart_db=# SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns; database_name | schema_name | relation_name | column_name ---------------+-------------+--------------------------------------+------------- quickstart_db | public | insurance_producers_licensed_in_iowa | city quickstart_db | public | insurance_producers_licensed_in_iowa | expiry_date quickstart_db | public | insurance_producers_licensed_in_iowa | loa_has_ah (3 rows) Time: 0.643 ms
Jetzt können wir die Abfrage für die Tabelle „insurance_producers_licensed_in_iowa“ noch einmal ausführen und sehen, ob sich die Leistung verbessert hat.
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Erwartete Ausgabe:
quickstart_db=# SELECT city, count(*)
quickstart_db-# FROM insurance_producers_licensed_in_iowa
quickstart_db-# WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
quickstart_db-# GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 2159
OMAHA | 1527
MIAMI | 1293
KANSAS CITY | 1091
DALLAS | 1000
(5 rows)
Time: 11.757 ms
quickstart_db=# SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 2159
OMAHA | 1527
MIAMI | 1293
KANSAS CITY | 1091
DALLAS | 1000
(5 rows)
Time: 10.839 ms
Die Ausführungszeit ist von 82 ms auf 11 ms gesunken. Wenn Sie keine Verbesserungen sehen, können Sie prüfen, ob die Spalten erfolgreich in den spaltenorientierten Speicher eingefügt wurden. Sehen Sie dazu die Ansicht „g_columnar_columns“ an.
SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
Erwartete Ausgabe:
quickstart_db=# SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
relation_name | column_name | column_type | status | size_in_bytes
--------------------------------------+-------------+-------------+--------+---------------
insurance_producers_licensed_in_iowa | city | text | Usable | 637312
insurance_producers_licensed_in_iowa | expiry_date | timestamp | Usable | 228356
insurance_producers_licensed_in_iowa | loa_has_ah | text | Usable | 227608
(3 rows)
Jetzt können wir prüfen, ob im Abfrageausführungsplan die spaltenbasierte Engine verwendet wird.
Führen Sie in der PSQL-Sitzung den folgenden Befehl aus:
EXPLAIN (ANALYZE,SETTINGS,BUFFERS)
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Erwartete Ausgabe:
quickstart_db=# EXPLAIN (ANALYZE,SETTINGS,BUFFERS)
quickstart_db-# SELECT city, count(*)
quickstart_db-# FROM insurance_producers_licensed_in_iowa
quickstart_db-# WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
quickstart_db-# GROUP BY city ORDER BY count(*) desc limit 5;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=2398.48..2398.49 rows=5 width=17) (actual time=10.018..10.021 rows=5 loops=1)
-> Sort (cost=2398.48..2411.61 rows=5252 width=17) (actual time=10.017..10.019 rows=5 loops=1)
Sort Key: (count(*)) DESC
Sort Method: top-N heapsort Memory: 25kB
-> HashAggregate (cost=2258.73..2311.25 rows=5252 width=17) (actual time=8.320..9.212 rows=7695 loops=1)
Group Key: city
Batches: 1 Memory Usage: 913kB
-> Append (cost=20.00..1762.13 rows=99320 width=9) (actual time=8.314..8.315 rows=8595 loops=1)
-> Custom Scan (columnar scan) on insurance_producers_licensed_in_iowa (cost=20.00..1758.11 rows=99319 width=9) (actual time=8.311..8.312 rows=8595 loops=1)
Filter: ((loa_has_ah = 'Yes'::text) AND (expiry_date > (now() + '6 mons'::interval)))
Rows Removed by Columnar Filter: 127723
Rows Aggregated by Columnar Scan: 99049
Columnar cache search mode: native
-> Seq Scan on insurance_producers_licensed_in_iowa (cost=0.00..4.02 rows=1 width=9) (never executed)
Filter: ((loa_has_ah = 'Yes'::text) AND (expiry_date > (now() + '6 mons'::interval)))
Planning Time: 0.221 ms
Execution Time: 10.127 ms
(17 rows)
Time: 11.171 ms
Wir sehen, dass der Vorgang „Seq Scan“ für das Segment der Tabelle „business_licenses“ nie ausgeführt wurde und stattdessen „Custom Scan (columnar scan)“ verwendet wurde. So konnten wir die Antwortzeit von 82 auf 11 ms verkürzen.
Wenn wir die automatisch eingefügten Inhalte aus der Spalten-Engine entfernen möchten, können wir die SQL-Funktion google_columnar_engine_reset_recommendation verwenden.
Führen Sie in der PSQL-Sitzung den folgenden Befehl aus:
SELECT google_columnar_engine_reset_recommendation(drop_columns => true);
Dadurch werden die ausgefüllten Spalten gelöscht. Sie können das in den Ansichten „g_columnar_columns“ und „g_columnar_recommended_columns“ überprüfen, wie oben gezeigt.
SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;
SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
Erwartete Ausgabe:
quickstart_db=# SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns; database_name | schema_name | relation_name | column_name ---------------+-------------+---------------+------------- (0 rows) Time: 0.447 ms quickstart_db=# select relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns; relation_name | column_name | column_type | status | size_in_bytes ---------------+-------------+-------------+--------+--------------- (0 rows) Time: 0.556 ms quickstart_db=#
Manuelles Einrichten des spaltenbasierten Speichers
Wir können dem Columnar Engine Store manuell Spalten mit SQL-Funktionen hinzufügen oder die erforderlichen Entitäten in den Instanz-Flags angeben, damit sie beim Start der Instanz automatisch geladen werden.
Fügen wir mit der SQL-Funktion google_columnar_engine_add dieselben Spalten wie zuvor hinzu.
Führen Sie in der PSQL-Sitzung den folgenden Befehl aus:
SELECT google_columnar_engine_add(relation => 'insurance_producers_licensed_in_iowa', columns => 'city,expiry_date,loa_has_ah');
Das Ergebnis lässt sich mit derselben Ansicht g_columnar_columns überprüfen:
SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
Erwartete Ausgabe:
quickstart_db=# SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
relation_name | column_name | column_type | status | size_in_bytes
--------------------------------------+-------------+-------------+--------+---------------
insurance_producers_licensed_in_iowa | city | text | Usable | 664231
insurance_producers_licensed_in_iowa | expirydate | timestamp | Usable | 212434
insurance_producers_licensed_in_iowa | loa_has_ah | text | Usable | 211734
(3 rows)
Time: 0.692 ms
quickstart_db=#
Sie können prüfen, ob der spaltenorientierte Speicher verwendet wird, indem Sie dieselbe Abfrage wie zuvor ausführen und den Ausführungsplan untersuchen:
EXPLAIN (ANALYZE,SETTINGS,BUFFERS)
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expiry_date > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Beenden Sie die psql-Sitzung:
exit
Wenn wir den AlloyDB Omni-Container neu starten, sehen wir, dass alle spaltenbasierten Informationen verloren gehen.
Führen Sie in der Shell-Sitzung Folgendes aus:
sudo docker restart my-omni
Warten Sie 5–10 Sekunden und führen Sie dann Folgendes aus:
psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns"
Erwartete Ausgabe:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns" relation_name | column_name | column_type | status | size_in_bytes ---------------+-------------+-------------+--------+--------------- (0 rows)
Damit die Spalten beim Neustart automatisch neu gefüllt werden, können wir sie als Datenbank-Flags zu unseren AlloyDB Omni-Parametern hinzufügen. Wir fügen das Flag google_columnar_engine.relations=‘quickstart_db.public.insurance_producers_licensed_in_iowa(city,expirydate,loa_has_ah)' hinzu und starten den Container neu.
Führen Sie in der Shell-Sitzung Folgendes aus:
sudo docker exec my-omni /bin/bash -c "echo google_columnar_engine.relations=\'quickstart_db.public.insurance_producers_licensed_in_iowa\(city,expiry_date,loa_has_ah\)\' >>/var/lib/postgresql/data/postgresql.conf" && \
sudo docker restart my-omni
Danach sehen wir, dass die Spalten nach dem Start automatisch dem Spaltenspeicher hinzugefügt wurden.
Warten Sie 5–10 Sekunden und führen Sie dann Folgendes aus:
psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns"
Erwartete Ausgabe:
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns"
relation_name | column_name | column_type | status | size_in_bytes
--------------------------------------+-------------+-------------+--------+---------------
insurance_producers_licensed_in_iowa | city | text | Usable | 637312
insurance_producers_licensed_in_iowa | expiry_date | timestamp | Usable | 228356
insurance_producers_licensed_in_iowa | loa_has_ah | text | Usable | 227608
(3 rows)
8. Umgebung bereinigen
Jetzt können wir unsere AlloyDB Omni-VM löschen.
GCE-VM löschen
Führen Sie in Cloud Shell Folgendes aus:
export GCEVM=omni01
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=omni01
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
9. Glückwunsch
Herzlichen Glückwunsch zum Abschluss des Codelabs.
Behandelte Themen
- AlloyDB Omni auf einer GCE-VM in Google Cloud bereitstellen
- Verbindung zu AlloyDB Omni herstellen
- Daten in AlloyDB Omni laden
- Spaltenbasierte Engine aktivieren
- Spaltenbasierte Engine im automatischen Modus prüfen
- Spaltenspeicher manuell mit Daten füllen
Weitere Informationen zur Verwendung der Columnar Engine finden Sie in der Dokumentation.
10. Umfrage
Ausgabe: