
1. Introduction
Dans cet atelier de programmation, vous allez apprendre à déployer AlloyDB Omni et à utiliser le moteur de données en colonnes pour améliorer les performances des requêtes.
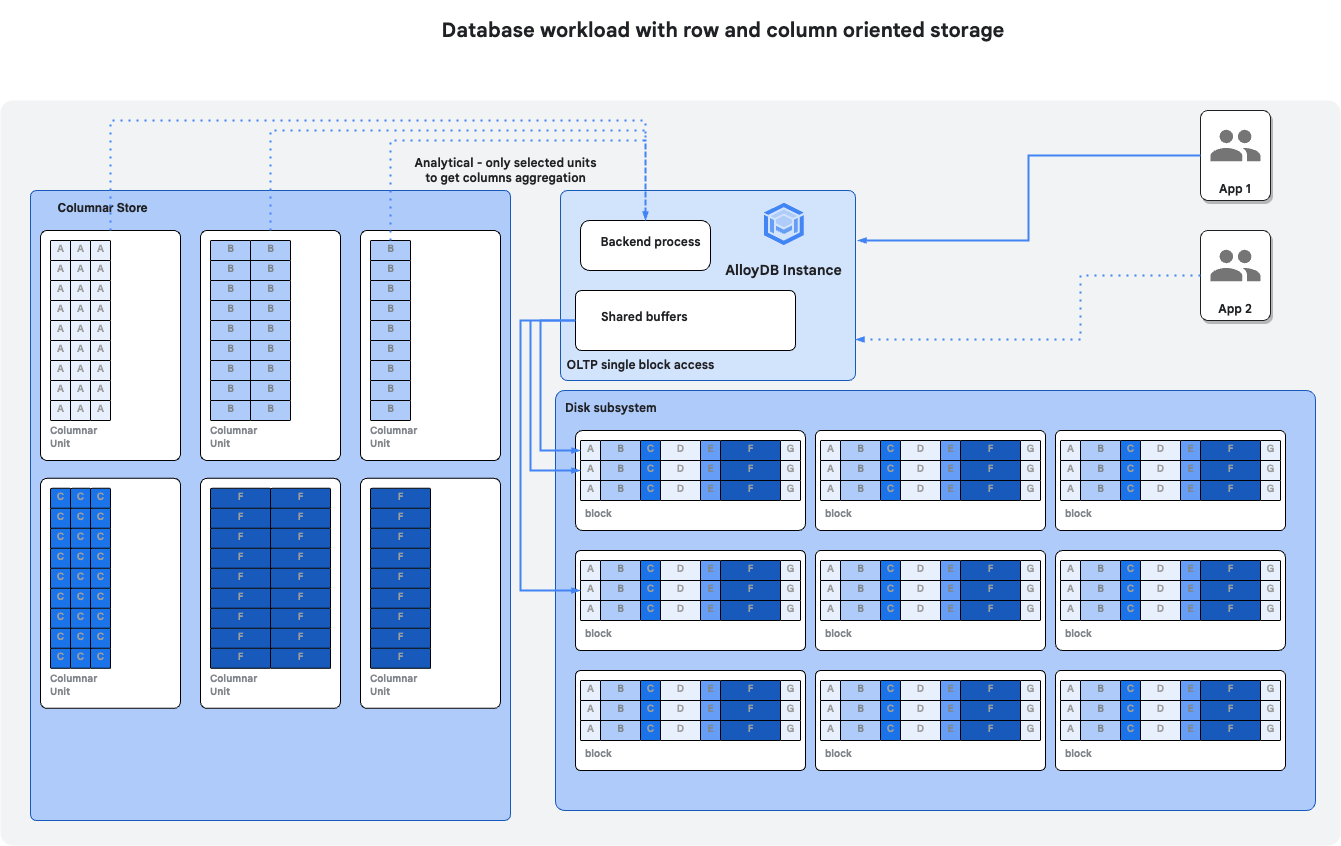
Prérequis
- Connaissances de base concernant la console Google Cloud
- Compétences de base concernant l'interface de ligne de commande et Google Shell
Points abordés
- Déployer AlloyDB Omni sur une VM GCE dans Google Cloud
- Se connecter à AlloyDB Omni
- Charger des données dans AlloyDB Omni
- Activer le moteur de données en colonnes
- Vérifier le moteur de données en colonnes en mode automatique
- Remplir manuellement le store orienté colonnes
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome
2. Préparation
Configuration de l'environnement au rythme de chacun
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. Si vous n'avez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.

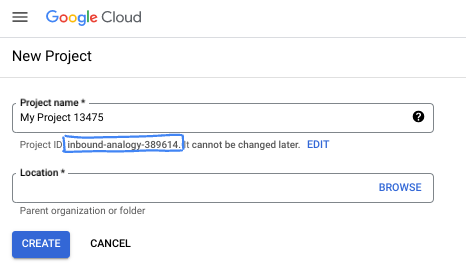
- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :

Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Avant de commencer
Activer l'API
Résultat :
Dans Cloud Shell, assurez-vous que l'ID de votre projet est configuré :
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
S'il n'est pas défini dans la configuration Cloud Shell, configurez-le à l'aide des commandes suivantes.
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Activez tous les services nécessaires :
gcloud services enable compute.googleapis.com
Résultat attendu
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-14650] student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Déployer AlloyDB Omni sur GCE
Pour déployer AlloyDB Omni sur GCE, nous devons préparer une machine virtuelle avec une configuration et un logiciel compatibles. Voici un exemple de déploiement d'AlloyDB Omni sur une VM basée sur Debian.
Créer une VM GCE
Nous devons déployer une VM avec une configuration acceptable pour le processeur, la mémoire et le stockage. Nous allons utiliser l'image Debian par défaut avec une taille de disque système augmentée à 20 Go pour accueillir les fichiers de base de données AlloyDB Omni.
Nous pouvons utiliser Cloud Shell ou un terminal sur lequel le SDK Cloud est installé.
Toutes les étapes sont également décrites dans le guide de démarrage rapide d'AlloyDB Omni.
Configurez les variables d'environnement pour votre déploiement.
export ZONE=us-central1-a
export MACHINE_TYPE=n2-highmem-2
export DISK_SIZE=20
export MACHINE_NAME=omni01
Nous utilisons ensuite gcloud pour créer la VM GCE.
gcloud compute instances create $MACHINE_NAME \
--project=$(gcloud info --format='value(config.project)') \
--zone=$ZONE --machine-type=$MACHINE_TYPE \
--metadata=enable-os-login=true \
--create-disk=auto-delete=yes,boot=yes,size=$DISK_SIZE,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" \
--format="value(name)"),type=pd-ssd
Résultat attendu sur la console :
gleb@cloudshell:~ (gleb-test-short-001-415614)$ export ZONE=us-central1-a
export MACHINE_TYPE=n2-highmem-2
export DISK_SIZE=20
export MACHINE_NAME=omni01
gleb@cloudshell:~ (gleb-test-short-001-415614)$ gcloud compute instances create $MACHINE_NAME \
--project=$(gcloud info --format='value(config.project)') \
--zone=$ZONE --machine-type=$MACHINE_TYPE \
--metadata=enable-os-login=true \
--create-disk=auto-delete=yes,boot=yes,size=$DISK_SIZE,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" \
--format="value(name)"),type=pd-ssd
Created [https://www.googleapis.com/compute/v1/projects/gleb-test-short-001-415614/zones/us-central1-a/instances/omni01].
WARNING: Some requests generated warnings:
- Disk size: '20 GB' is larger than image size: '10 GB'. You might need to resize the root repartition manually if the operating system does not support automatic resizing. See https://cloud.google.com/compute/docs/disks/add-persistent-disk#resize_pd for details.
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: n2-highmem-2
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
gleb@cloudshell:~ (gleb-test-short-001-415614)$
Installer AlloyDB Omni
Connectez-vous à la VM créée :
gcloud compute ssh omni01 --zone $ZONE
Résultat attendu sur la console :
gleb@cloudshell:~ (gleb-test-short-001-415614)$ gcloud compute ssh omni01 --zone $ZONE Warning: Permanently added 'compute.5615760774496706107' (ECDSA) to the list of known hosts. Linux omni01.us-central1-a.c.gleb-test-short-003-421517.internal 6.1.0-20-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.85-1 (2024-04-11) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. gleb@omni01:~$
Exécutez la commande suivante dans le terminal connecté.
Installez Docker sur la VM :
sudo apt update
sudo apt-get -y install docker.io
Résultat attendu sur la console (masqué) :
gleb@omni01:~$ sudo apt update sudo apt-get -y install docker.io Get:1 file:/etc/apt/mirrors/debian.list Mirrorlist [30 B] Get:5 file:/etc/apt/mirrors/debian-security.list Mirrorlist [39 B] Get:7 https://packages.cloud.google.com/apt google-compute-engine-bookworm-stable InRelease [5146 B] Get:8 https://packages.cloud.google.com/apt cloud-sdk-bookworm InRelease [6406 B] Get:9 https://packages.cloud.google.com/apt google-compute-engine-bookworm-stable/main amd64 Packages [1916 B] Get:2 https://deb.debian.org/debian bookworm InRelease [151 kB] ... Setting up binutils (2.40-2) ... Setting up needrestart (3.6-4+deb12u1) ... Processing triggers for man-db (2.11.2-2) ... Processing triggers for libc-bin (2.36-9+deb12u4) ... gleb@omni01:~$
Définissez le mot de passe de l'utilisateur postgres :
export PGPASSWORD=<your password>
Créez un répertoire pour les données AlloyDB Omni. Il s'agit d'une approche facultative, mais recommandée. Par défaut, les données sont créées à l'aide de la couche de système de fichiers éphémère Docker et tout est détruit lorsque le conteneur Docker est supprimé. En les conservant séparément, vous pouvez gérer les conteneurs indépendamment de vos données et, si vous le souhaitez, les placer dans un stockage avec de meilleures caractéristiques d'E/S.
Voici une commande permettant de créer un répertoire dans le répertoire personnel de l'utilisateur, où toutes les données seront placées :
mkdir -p $HOME/alloydb-data
Déployez le conteneur AlloyDB Omni :
sudo docker run --name my-omni \
-e POSTGRES_PASSWORD=$PGPASSWORD \
-p 5432:5432 \
-v $HOME/alloydb-data:/var/lib/postgresql/data \
-v /dev/shm:/dev/shm \
-d google/alloydbomni
Résultat attendu sur la console (masqué) :
gleb@omni01:~$ export PGPASSWORD=StrongPassword gleb@omni01:~$ sudo docker run --name my-omni \ -e POSTGRES_PASSWORD=$PGPASSWORD \ -p 5432:5432 \ -v $HOME/alloydb-data:/var/lib/postgresql/data \ -v /dev/shm:/dev/shm \ -d google/alloydbomni Unable to find image 'google/alloydbomni:latest' locally latest: Pulling from google/alloydbomni 71215d55680c: Pull complete ... 2e0ec3fe1804: Pull complete Digest: sha256:d6b155ea4c7363ef99bf45a9dc988ce5467df5ae8cd3c0f269ae9652dd1982a6 Status: Downloaded newer image for google/alloydbomni:latest 56de4ae0018314093c8b048f69a1e9efe67c6c8117f44c8e1dc829a2d4666cd2 gleb@omni01:~$
Installez le logiciel client PostgreSQL sur la VM (facultatif, car il est censé être déjà installé) :
sudo apt install -y postgresql-client
Résultat attendu sur la console :
gleb@omni01:~$ sudo apt install -y postgresql-client Reading package lists... Done Building dependency tree... Done Reading state information... Done postgresql-client is already the newest version (15+248). 0 upgraded, 0 newly installed, 0 to remove and 4 not upgraded.
Connectez-vous à AlloyDB Omni :
psql -h localhost -U postgres
Résultat attendu sur la console :
gleb@omni01:~$ psql -h localhost -U postgres psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) Type "help" for help. postgres=#
Déconnectez-vous d'AlloyDB Omni :
exit
Résultat attendu sur la console :
postgres=# exit gleb@omni01:~$
5. Préparer une base de données de test
Pour tester le moteur de données en colonnes, nous devons créer une base de données et la remplir avec des données de test.
Créer une base de données
Se connecter à la VM AlloyDB Omni et créer une base de données
Dans la session Cloud Shell, exécutez :
gcloud config set project $(gcloud config get-value project)
Connectez-vous à la VM AlloyDB Omni :
ZONE=us-central1-a
gcloud compute ssh omni01 --zone $ZONE
Résultat attendu sur la console :
student@cloudshell:~ (gleb-test-short-001-416213)$ gcloud config set project $(gcloud config get-value project) Updated property [core/project]. student@cloudshell:~ (gleb-test-short-001-416213)$ ZONE=us-central1-a gcloud compute ssh omni01 --zone $ZONE Linux omni01.us-central1-a.c.gleb-test-short-003-421517.internal 6.1.0-20-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.85-1 (2024-04-11) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. Last login: Mon Mar 4 18:17:55 2024 from 35.237.87.44 student@omni01:~$
Dans la session SSH établie, exécutez :
export PGPASSWORD=<your password>
psql -h localhost -U postgres -c "CREATE DATABASE quickstart_db"
Résultat attendu sur la console :
student@omni01:~$ psql -h localhost -U postgres -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@omni01:~$
Créer un tableau avec des données d'exemple
Pour nos tests, nous allons utiliser des données publiques sur les producteurs d'assurance agréés dans l'Iowa. Vous trouverez cet ensemble de données sur le site Web du gouvernement de l'Iowa : https://data.iowa.gov/Regulation/Insurance-Producers-Licensed-in-Iowa/n4cc-vqyk/about_data .
Nous devons d'abord créer une table.
Dans la VM GCE, exécutez :
psql -h localhost -U postgres -d quickstart_db -c "DROP TABLE if exists insurance_producers_licensed_in_iowa;
CREATE TABLE insurance_producers_licensed_in_iowa (
npn int8,
last_name text,
first_name text,
address_line_1 text,
address_line_2 text,
address_line_3 text,
city text,
state text,
zip int4,
firstactivedate timestamp,
expirydate timestamp,
business_phone text,
email text,
physical_location text,
iowaresident text,
loa_has_crop text,
loa_has_surety text,
loa_has_ah text,
loa_has_life text,
loa_has_variable text,
loa_has_personal_lines text,
loa_has_credit text,
loa_has_excess text,
loa_has_property text,
loa_has_casualty text,
loa_has_reciprocal text
);"
Résultat attendu sur la console :
otochkin@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "DROP TABLE if exists insurance_producers_licensed_in_iowa;
CREATE TABLE insurance_producers_licensed_in_iowa (
npn int8,
last_name text,
first_name text,
address_line_1 text,
address_line_2 text,
address_line_3 text,
city text,
state text,
zip int4,
firstactivedate timestamp,
expirydate timestamp,
business_phone text,
email text,
physical_location text,
iowaresident text,
loa_has_crop text,
loa_has_surety text,
loa_has_ah text,
loa_has_life text,
loa_has_variable text,
loa_has_personal_lines text,
loa_has_credit text,
loa_has_excess text,
loa_has_property text,
loa_has_casualty text,
loa_has_reciprocal text
);"
NOTICE: table "insurance_producers_licensed_in_iowa" does not exist, skipping
DROP TABLE
CREATE TABLE
otochkin@omni01:~$
Chargez des données dans la table.
Dans la VM GCE, exécutez :
curl https://data.iowa.gov/api/views/n4cc-vqyk/rows.csv | psql -h localhost -U postgres -d quickstart_db -c "\copy insurance_producers_licensed_in_iowa from stdin csv header"
Résultat attendu sur la console :
otochkin@omni01:~$ curl https://data.iowa.gov/api/views/n4cc-vqyk/rows.csv | psql -h localhost -U postgres -d quickstart_db -c "\copy insurance_producers_licensed_in_iowa from stdin csv header"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 39.3M 0 39.3M 0 0 1004k 0 --:--:-- 0:00:40 --:--:-- 1028k
COPY 210898
otochkin@omni01:~$
Nous avons chargé 210 898 enregistrements sur les producteurs d'assurance dans notre base de données et pouvons effectuer des tests.
Exécuter des requêtes de test
Connectez-vous à quickstart_db à l'aide de psql et activez le timing pour mesurer le temps d'exécution de nos requêtes.
Dans la VM GCE, exécutez :
psql -h localhost -U postgres -d quickstart_db
Résultat attendu sur la console :
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db
psql (13.14 (Debian 13.14-0+deb11u1), server 15.5
WARNING: psql major version 13, server major version 15.
Some psql features might not work.
Type "help" for help.
quickstart_db=#
Dans la session PSQL, exécutez :
\timing
Résultat attendu sur la console :
quickstart_db=# \timing Timing is on. quickstart_db=#
Trouvons les cinq villes qui comptent le plus de producteurs d'assurance vendant des assurances accident et maladie, et dont la licence est valide au moins pour les six prochains mois.
Dans la session PSQL, exécutez :
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Résultat attendu sur la console :
quickstart_db=# SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 1885
OMAHA | 1656
KANSAS CITY | 1279
AUSTIN | 1254
MIAMI | 1003
(5 rows)
Time: 94.965 ms
Exécutez une requête de test, de préférence plusieurs fois, pour obtenir un temps d'exécution fiable. Nous pouvons constater que le temps moyen pour renvoyer le résultat est d'environ 94 ms. Dans les étapes suivantes, nous allons activer le moteur de données en colonnes AlloyDB et voir s'il peut améliorer les performances.
Quittez la session psql :
exit
6. Activer le moteur de données en colonnes
Nous devons maintenant activer le moteur de données en colonnes sur notre AlloyDB Omni.
Mettre à jour les paramètres AlloyDB Omni
Nous devons définir le paramètre d'instance "google_columnar_engine.enabled" sur "on" pour notre AlloyDB Omni, ce qui nécessite un redémarrage.
Mettez à jour le fichier postgresql.conf dans le répertoire /var/alloydb/config et redémarrez l'instance.
Dans la VM GCE, exécutez :
sudo docker exec my-omni /bin/bash -c "echo google_columnar_engine.enabled=true >>/var/lib/postgresql/data/postgresql.conf"
sudo docker exec my-omni /bin/bash -c "echo shared_preload_libraries=\'google_columnar_engine,google_job_scheduler,google_db_advisor,google_storage\' >>/var/lib/postgresql/data/postgresql.conf"
sudo docker stop my-omni
sudo docker start my-omni
Résultat attendu sur la console :
student@omni01:~$ sudo docker exec my-omni /bin/bash -c "echo google_columnar_engine.enabled=true >>/var/lib/postgresql/data/postgresql.conf" sudo docker exec my-omni /bin/bash -c "echo shared_preload_libraries=\'google_columnar_engine,google_job_scheduler,google_db_advisor,google_storage\' >>/var/lib/postgresql/data/postgresql.conf" sudo docker stop my-omni sudo docker start my-omni my-omni my-omni student@omni01:~$
Vérifier le moteur de données en colonnes
Connectez-vous à la base de données à l'aide de psql et vérifiez le moteur de données en colonnes.
Se connecter à la base de données AlloyDB Omni
Dans la session SSH de la VM, connectez-vous à la base de données :
psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.enabled"
La commande doit afficher le moteur de colonnes activé.
Résultat attendu sur la console :
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.enabled" google_columnar_engine.enabled -------------------------------- on (1 row)
7. Comparaison des performances
Nous pouvons maintenant remplir le store du moteur de données en colonnes et vérifier les performances.
Remplissage automatique du magasin de données en colonnes
Par défaut, le job qui remplit le magasin s'exécute toutes les heures. Nous allons réduire ce délai à 10 minutes pour éviter l'attente.
Dans la VM GCE, exécutez :
sudo docker exec my-omni /bin/bash -c "echo google_columnar_engine.auto_columnarization_schedule=\'EVERY 10 MINUTES\' >>/var/lib/postgresql/data/postgresql.conf"
sudo docker stop my-omni
sudo docker start my-omni
Voici le résultat attendu :
student@omni01:~$ sudo docker exec my-omni /bin/bash -c "echo google_columnar_engine.auto_columnarization_schedule=\'EVERY 5 MINUTES\' >>/var/lib/postgresql/data/postgresql.conf" sudo docker stop my-omni sudo docker start my-omni my-omni my-omni student@omni01:~$
Vérifier les paramètres
Dans la VM GCE, exécutez :
psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.auto_columnarization_schedule;"
Résultat attendu :
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "show google_columnar_engine.auto_columnarization_schedule;" google_columnar_engine.auto_columnarization_schedule ------------------------------------------------------ EVERY 10 MINUTES (1 row) student@omni01:~$
Vérifiez les objets dans le Columnar Store. Ce champ doit être vide.
Dans la VM GCE, exécutez :
psql -h localhost -U postgres -d quickstart_db -c "SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;"
Résultat attendu :
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;" database_name | schema_name | relation_name | column_name ---------------+-------------+---------------+------------- (0 rows) student@omni01:~$
Connectez-vous à la base de données et exécutez plusieurs fois la même requête que nous avons exécutée précédemment.
Dans la VM GCE, exécutez :
psql -h localhost -U postgres -d quickstart_db
Dans la session PSQL.
Activer le timing
\timing
Exécutez la requête plusieurs fois :
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Résultat attendu :
quickstart_db=# SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 1885
OMAHA | 1656
KANSAS CITY | 1279
AUSTIN | 1254
MIAMI | 1003
(5 rows)
Time: 94.289 ms
quickstart_db=# SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 1885
OMAHA | 1656
KANSAS CITY | 1279
AUSTIN | 1254
MIAMI | 1003
(5 rows)
Time: 94.608 ms
quickstart_db=#
Attendez 10 minutes et vérifiez si les colonnes de la table insurance_producers_licensed_in_iowa ont été insérées dans le columnar store.
SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;
Résultat attendu :
quickstart_db=# SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns; database_name | schema_name | relation_name | column_name ---------------+-------------+--------------------------------------+------------- quickstart_db | public | insurance_producers_licensed_in_iowa | city quickstart_db | public | insurance_producers_licensed_in_iowa | expirydate quickstart_db | public | insurance_producers_licensed_in_iowa | loa_has_ah (3 rows) Time: 0.643 ms
Nous pouvons maintenant exécuter à nouveau la requête pour la table "insurance_producers_licensed_in_iowa" et voir si les performances se sont améliorées.
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Résultat attendu :
quickstart_db=# SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 1885
OMAHA | 1656
KANSAS CITY | 1279
AUSTIN | 1254
MIAMI | 1003
(5 rows)
Time: 14.380 ms
quickstart_db=# SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
city | count
-------------+-------
TAMPA | 1885
OMAHA | 1656
KANSAS CITY | 1279
AUSTIN | 1254
MIAMI | 1003
(5 rows)
Time: 13.279 ms
Le temps d'exécution est passé de 94 ms à 14 ms. Si vous ne constatez aucune amélioration, vous pouvez vérifier si les colonnes ont bien été renseignées dans le magasin de colonnes en consultant la vue g_columnar_columns.
SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
Résultat attendu :
quickstart_db=# select relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
relation_name | column_name | column_type | status | size_in_bytes
--------------------------------------+-------------+-------------+--------+---------------
insurance_producers_licensed_in_iowa | city | text | Usable | 664231
insurance_producers_licensed_in_iowa | expirydate | timestamp | Usable | 212434
insurance_producers_licensed_in_iowa | loa_has_ah | text | Usable | 211734
(3 rows)
Nous pouvons maintenant vérifier si le plan d'exécution de la requête utilise le moteur en colonnes.
Dans la session PSQL, exécutez :
EXPLAIN (ANALYZE,SETTINGS,BUFFERS)
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Résultat attendu :
quickstart_db=# EXPLAIN (ANALYZE,SETTINGS,BUFFERS)
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=2279.72..2279.73 rows=5 width=17) (actual time=12.248..12.252 rows=5 loops=1)
-> Sort (cost=2279.72..2292.91 rows=5277 width=17) (actual time=12.246..12.248 rows=5 loops=1)
Sort Key: (count(*)) DESC
Sort Method: top-N heapsort Memory: 25kB
-> HashAggregate (cost=2139.30..2192.07 rows=5277 width=17) (actual time=10.235..11.250 rows=7555 loops=1)
Group Key: city
Batches: 1 Memory Usage: 1169kB
-> Append (cost=20.00..1669.24 rows=94012 width=9) (actual time=10.231..10.233 rows=94286 loops=1)
-> Custom Scan (columnar scan) on insurance_producers_licensed_in_iowa (cost=20.00..1665.22 rows=94011 width=9) (actual time=10.229..10.231 rows=94286 loops=1)
Filter: ((loa_has_ah = 'Yes'::text) AND (expirydate > (now() + '6 mons'::interval)))
Rows Removed by Columnar Filter: 116612
Rows Aggregated by Columnar Scan: 94286
Columnar cache search mode: native
-> Seq Scan on insurance_producers_licensed_in_iowa (cost=0.00..4.02 rows=1 width=9) (never executed)
Filter: ((loa_has_ah = 'Yes'::text) AND (expirydate > (now() + '6 mons'::interval)))
Planning Time: 0.216 ms
Execution Time: 12.353 ms
Nous pouvons voir que l'opération "Seq Scan" sur le segment de table business_licenses n'a jamais été exécutée et que l'opération "Custom Scan (columnar scan)" a été utilisée à la place. Cela nous a permis de réduire le temps de réponse de 94 ms à 12 ms.
Si nous souhaitons effacer le contenu rempli automatiquement à partir du moteur de données en colonnes, nous pouvons le faire à l'aide de la fonction SQL google_columnar_engine_reset_recommendation.
Dans la session PSQL, exécutez :
SELECT google_columnar_engine_reset_recommendation(drop_columns => true);
Les colonnes renseignées seront effacées. Vous pouvez le vérifier dans les vues g_columnar_columns et g_columnar_recommended_columns, comme indiqué précédemment.
SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns;
SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
Résultat attendu :
quickstart_db=# SELECT database_name, schema_name, relation_name, column_name FROM g_columnar_recommended_columns; database_name | schema_name | relation_name | column_name ---------------+-------------+---------------+------------- (0 rows) Time: 0.447 ms quickstart_db=# select relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns; relation_name | column_name | column_type | status | size_in_bytes ---------------+-------------+-------------+--------+--------------- (0 rows) Time: 0.556 ms quickstart_db=#
Remplissage manuel du magasin en colonnes
Nous pouvons ajouter manuellement des colonnes au Columnar Engine Store à l'aide de fonctions SQL ou spécifier les entités requises dans les indicateurs d'instance pour les charger automatiquement au démarrage de l'instance.
Ajoutons les mêmes colonnes qu'avant à l'aide de la fonction SQL google_columnar_engine_add.
Dans la session PSQL, exécutez :
SELECT google_columnar_engine_add(relation => 'insurance_producers_licensed_in_iowa', columns => 'city,expirydate,loa_has_ah');
Nous pouvons vérifier le résultat à l'aide de la même vue g_columnar_columns :
SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
Résultat attendu :
quickstart_db=# SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns;
relation_name | column_name | column_type | status | size_in_bytes
--------------------------------------+-------------+-------------+--------+---------------
insurance_producers_licensed_in_iowa | city | text | Usable | 664231
insurance_producers_licensed_in_iowa | expirydate | timestamp | Usable | 212434
insurance_producers_licensed_in_iowa | loa_has_ah | text | Usable | 211734
(3 rows)
Time: 0.692 ms
quickstart_db=#
Pour vérifier que le magasin en colonnes est utilisé, exécutez la même requête qu'auparavant et examinez le plan d'exécution :
EXPLAIN (ANALYZE,SETTINGS,BUFFERS)
SELECT city, count(*)
FROM insurance_producers_licensed_in_iowa
WHERE loa_has_ah ='Yes' and expirydate > now() + interval '6 MONTH'
GROUP BY city ORDER BY count(*) desc limit 5;
Quittez la session psql :
exit
Si nous redémarrons le conteneur AlloyDB Omni, nous pouvons constater que toutes les informations en colonnes sont perdues.
Dans la session shell, exécutez :
sudo docker stop my-omni
sudo docker start my-omni
Patientez 5 à 10 secondes, puis exécutez la commande suivante :
psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns"
Résultat attendu :
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns" relation_name | column_name | column_type | status | size_in_bytes ---------------+-------------+-------------+--------+--------------- (0 rows)
Pour repopuler automatiquement les colonnes lors du redémarrage, nous pouvons les ajouter en tant que flags de base de données à nos paramètres AlloyDB Omni. Nous ajoutons le flag google_columnar_engine.relations=‘quickstart_db.public.insurance_producers_licensed_in_iowa(city,expirydate,loa_has_ah)' et redémarrons le conteneur.
Dans la session shell, exécutez :
sudo docker exec my-omni /bin/bash -c "echo google_columnar_engine.relations=\'quickstart_db.public.insurance_producers_licensed_in_iowa\(city,expirydate,loa_has_ah\)\' >>/var/lib/postgresql/data/postgresql.conf"
sudo docker stop my-omni
sudo docker start my-omni
Ensuite, nous pouvons voir que les colonnes ont été ajoutées automatiquement au Columnar Store après le démarrage.
Patientez 5 à 10 secondes, puis exécutez la commande suivante :
psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns"
Résultat attendu :
student@omni01:~$ psql -h localhost -U postgres -d quickstart_db -c "SELECT relation_name,column_name,column_type,status,size_in_bytes from g_columnar_columns"
relation_name | column_name | column_type | status | size_in_bytes
--------------------------------------+-------------+-------------+--------+---------------
insurance_producers_licensed_in_iowa | city | text | Usable | 664231
insurance_producers_licensed_in_iowa | expirydate | timestamp | Usable | 212434
insurance_producers_licensed_in_iowa | loa_has_ah | text | Usable | 211734
(3 rows)
8. Nettoyer l'environnement
Nous pouvons maintenant détruire notre VM AlloyDB Omni.
Supprimer la VM GCE
Dans Cloud Shell, exécutez :
export GCEVM=omni01
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Résultat attendu sur la console :
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=omni01
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
9. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation.
Points abordés
- Déployer AlloyDB Omni sur une VM GCE dans Google Cloud
- Se connecter à AlloyDB Omni
- Charger des données dans AlloyDB Omni
- Activer le moteur de données en colonnes
- Vérifier le moteur de données en colonnes en mode automatique
- Remplir manuellement le store orienté colonnes
Pour en savoir plus sur l'utilisation du moteur columnar, consultez la documentation.
10. Enquête
Résultat :