
1. Introducción
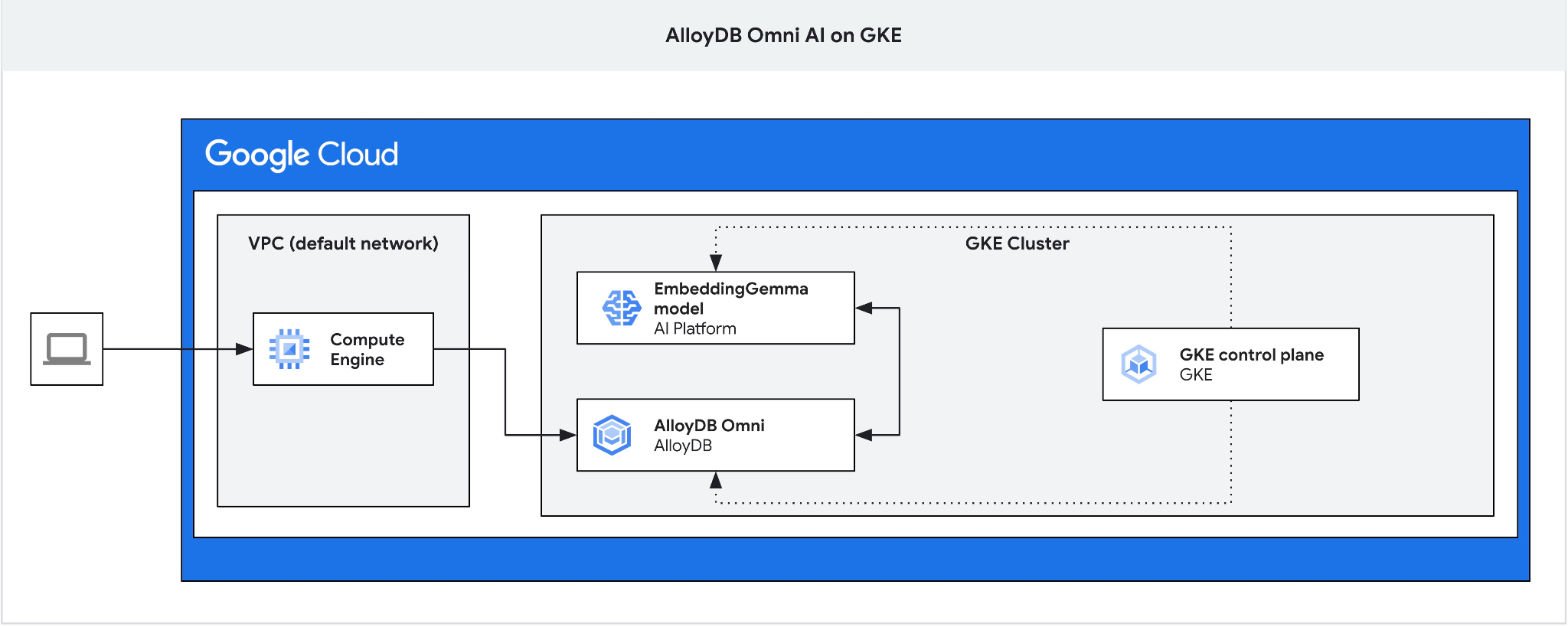
En este codelab, aprenderás a implementar AlloyDB Omni en GKE y a usarlo con un modelo de embedding abierto implementado en el mismo clúster de Kubernetes. La implementación de un modelo junto a la instancia de la base de datos en el mismo clúster de GKE reduce la latencia y las dependencias de los servicios de terceros. Además, la implementación local puede ser un requisito establecido por los equipos de seguridad y cumplimiento cuando los datos no deben salir de la organización y no se permite el uso de servicios de terceros.
Requisitos previos
- Conocimientos básicos sobre Google Cloud y la consola
- Conocimientos básicos de Kubernetes y GKE
- Habilidades básicas de la interfaz de línea de comandos y de Cloud Shell
Qué aprenderás
- Cómo implementar AlloyDB Omni en un clúster de Google Kubernetes
- Cómo conectarse a AlloyDB Omni
- Cómo cargar datos en AlloyDB Omni
- Cómo implementar un modelo de embedding abierto en GKE
- Cómo registrar un modelo de incorporación en AlloyDB Omni
- Cómo generar incorporaciones para la búsqueda semántica
- Cómo usar los embeddings generados para la búsqueda semántica en AlloyDB Omni
- Cómo crear y usar índices de vectores en AlloyDB
Requisitos
- Una cuenta de Google Cloud y un proyecto de Google Cloud
- Un navegador web, como Chrome, que admita la consola de Google Cloud y Cloud Shell
2. Configuración y requisitos
Configuración del proyecto
- Accede a la consola de Google Cloud. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.
Usar una cuenta personal en lugar de una cuenta laboral o educativa
- Crea un proyecto nuevo o reutiliza uno existente. Para crear un proyecto nuevo en la consola de Google Cloud, haz clic en el botón Seleccionar un proyecto en el encabezado, lo que abrirá una ventana emergente.

En la ventana Selecciona un proyecto, presiona el botón Proyecto nuevo, que abrirá un cuadro de diálogo para el proyecto nuevo.
En el cuadro de diálogo, ingresa el nombre del proyecto que prefieras y elige la ubicación.
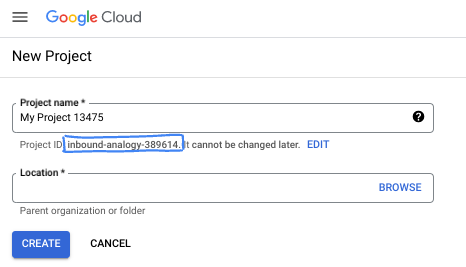
- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. El nombre del proyecto no se usa en las APIs de Google y se puede cambiar en cualquier momento.
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Google Cloud genera automáticamente un ID único, pero puedes personalizarlo. Si no te gusta el ID generado, puedes generar otro aleatorio o proporcionar el tuyo para verificar su disponibilidad. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto, que suele identificarse con el marcador de posición PROJECT_ID.
- Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
Habilitar facturación
Configura una cuenta de facturación personal
Si configuraste la facturación con créditos de Google Cloud, puedes omitir este paso.
Para configurar una cuenta de facturación personal, ve aquí para habilitar la facturación en la consola de Cloud.
Algunas notas:
- Completar este lab debería costar menos de USD 3 en recursos de Cloud.
- Puedes seguir los pasos al final de este lab para borrar recursos y evitar cargos adicionales.
- Los usuarios nuevos pueden acceder a la prueba gratuita de USD 300.
Inicia Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
También puedes presionar G y, luego, S. Esta secuencia activará Cloud Shell si estás en la consola de Google Cloud o usas este vínculo.
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
3. Antes de comenzar
Habilita la API
Resultado:
Para usar Google Kubernetes Engine (GKE) para las implementaciones de AlloyDB Omni y modelos abiertos, debes habilitar sus APIs respectivas en tu proyecto de Google Cloud.
En Cloud Shell, asegúrate de que tu ID del proyecto esté configurado:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Si no está definido en la configuración de Cloud Shell, configúralo con los siguientes comandos:
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Habilita todos los servicios necesarios con el siguiente comando:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
Resultado esperado
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Presentamos las APIs
- La API de Kubernetes Engine (
container.googleapis.com) te permite crear y administrar clústeres de Google Kubernetes Engine (GKE). Proporciona un entorno administrado para implementar, administrar y escalar tus aplicaciones alojadas en contenedores con la infraestructura de Google. - La API de Compute Engine (
compute.googleapis.com) te permite crear y administrar máquinas virtuales (VM), discos persistentes y parámetros de configuración de red. Proporciona la base de infraestructura como servicio (IaaS) principal necesaria para ejecutar tus cargas de trabajo y alojar la infraestructura subyacente de muchos servicios administrados.
4. Implementa AlloyDB Omni en GKE
Para implementar AlloyDB Omni en GKE, debemos preparar un clúster de Kubernetes según los requisitos que se indican en los requisitos del operador de AlloyDB Omni.
Crea un clúster de GKE
Debemos implementar un clúster de GKE estándar con una configuración de grupo suficiente para implementar un Pod con una instancia de AlloyDB Omni. Para AlloyDB Omni, necesitamos al menos 2 CPU y 8 GB de RAM, y algo de espacio para los contenedores de servicios de supervisión y operadores. Usaremos el tipo de VM e2-standard-4.
Configura las variables de entorno para tu implementación.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
Luego, usamos gcloud para crear el clúster de GKE estándar.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Resultado esperado en la consola:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
Prepara el clúster
Debemos instalar los componentes necesarios, como el servicio cert-manager, que es un administrador de certificados nativo para Kubernetes. Podemos seguir los pasos de la documentación para la instalación de cert-manager.
Usamos la herramienta de línea de comandos de Kubernetes, kubectl, que ya está instalada en Cloud Shell de forma predeterminada. Antes de usar la utilidad, debemos obtener las credenciales de nuestro clúster.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
Ahora podemos usar kubectl para instalar cert-manager:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
Resultado esperado de la consola (oculto):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
Instala AlloyDB Omni
El operador de AlloyDB Omni se puede instalar con la utilidad de Helm.
Ejecuta el siguiente comando para instalar el operador de AlloyDB Omni:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
Resultado esperado de la consola (oculto):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
Cuando se instala el operador de AlloyDB Omni, podemos continuar con la implementación de nuestro clúster de base de datos.
A continuación, se muestra un ejemplo de manifiesto de implementación con el parámetro googleMLExtension habilitado y un balanceador de cargas interno (privado):
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
El valor secreto de la contraseña es una representación en Base64 de la palabra de contraseña "VeryStrongPassword". La forma más confiable es usar Google Secret Manager para almacenar el valor de la contraseña. Puedes obtener más información al respecto en la documentación.
Guarda el manifiesto como my-omni.yaml para aplicarlo en el siguiente paso. Si estás en Cloud Shell, puedes hacerlo con el editor presionando el botón "Abrir editor" en la parte superior derecha de la terminal.
Después de guardar el archivo con el nombre my-omni.yaml, presiona el botón "Abrir terminal" para volver a la terminal.
Aplica el manifiesto my-omni.yaml al clúster con la utilidad kubectl:
kubectl apply -f my-omni.yaml
Resultado esperado en la consola:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
Verifica el estado de tu clúster my-omni con la utilidad kubectl:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Durante la implementación, el clúster pasa por diferentes fases y, finalmente, debería terminar con el estado DBClusterReady.
Resultado esperado en la consola:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
Conéctate a AlloyDB Omni
Conexión con un pod de Kubernetes
Cuando el clúster esté listo, podremos usar los archivos binarios del cliente de PostgreSQL en el pod de la instancia de AlloyDB Omni. Encontramos el ID del Pod y, luego, usamos kubectl para conectarnos directamente al Pod y ejecutar el software cliente. La contraseña es VeryStrongPassword, como se configuró a través del Secret de Kubernetes en el manifiesto my-omni.yaml:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Resultado de muestra de la consola:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. Implementa el modelo de IA en GKE
Para probar la integración de IA de AlloyDB Omni con modelos locales, debemos implementar un modelo en el clúster. Usaremos el modelo EmbeddingGemma de Google.
Crea un grupo de nodos para el modelo
Para ejecutar el modelo, debemos preparar un grupo de nodos para ejecutar la inferencia. Podemos ejecutarlo con un grupo solo de CPU o con un grupo con aceleradores de GPU. El enfoque solo de CPU podría ser más factible en algunas regiones debido a la alta simultaneidad de los recursos. En nuestro lab, usaremos el enfoque de CPU, pero el mejor enfoque desde el punto de vista del rendimiento es un grupo con aceleradores gráficos que usa una configuración de nodo como g2-standard-8 con el acelerador L4 de Nvidia.
Grupo de nodos basado en la CPU
Crea un grupo de nodos con nodos e2-standard-32. Limitaremos nuestra extracción a un nodo para ahorrar recursos.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
Resultado esperado
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
Obtén el token de Hugging Face
En este lab, usamos una asociación con Hugging Face para implementar el modelo EmbeddingGemma, y, para ello, necesitamos obtener un token de Hugging Face.
Sigue los pasos que se indican a continuación para generar un token nuevo si aún no tienes uno.
- Inicia sesión o regístrate en el sitio de Hugging Face con los vínculos Log In o Sign Up que se encuentran en la esquina superior derecha.
- Haz clic en Tu perfil -> Tokens de acceso.
- Confirma tu identidad
- Haz clic en Create new token.
- Elige un nombre para tu token
- Selecciona un rol para el token. Necesitas al menos el privilegio de lectura.
- Haz clic en Crear token en la parte inferior de la página.
- Copia el token generado y guárdalo para usarlo más adelante.
También debes aceptar las condiciones para acceder a los archivos y al contenido relacionados con EmbeddingGemma en Hugging Face en la página https://huggingface.co/google/embeddinggemma-300m.
Crea un secreto de Kubernetes con el token
En la sesión de Cloud Shell, ejecuta el siguiente comando (reemplaza el valor de HF_TOKEN por tu token de HF):
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
Prepara el manifiesto de implementación
Para implementar el modelo, debemos preparar un manifiesto de implementación.
Usamos el modelo EmbeddingGemma de Google de Hugging Face. Puedes leer la tarjeta del modelo aquí. Para implementar el modelo, usaremos un enfoque basado en las instrucciones de Hugging Face y el paquete de implementación de GitHub.
Clona el paquete desde GitHub
git clone https://github.com/huggingface/Google-Cloud-Containers
Ajusta el manifiesto para la interfaz de incorporación de texto (tei) en los nodos de CPU. Debemos reemplazar varios parámetros, incluidos el modelo, la imagen y la asignación correcta de recursos, y agregar el secreto del token de Hugging Face a la configuración.
Edita el manifiesto (con cualquier editor disponible)
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
A continuación, se muestra un manifiesto corregido para la implementación en un grupo basado en CPU.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
Implementa el modelo
Implementa el modelo aplicando el manifiesto modificado para las implementaciones de CPU.
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
Verifica las implementaciones
kubectl get pods
Verifica el servicio del modelo
kubectl get service tei-service
Se supone que debe mostrar el tipo de servicio en ejecución ClusterIP.
Resultado de muestra:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
La dirección CLUSTER-IP del servicio es la que usaremos como dirección de extremo. La incorporación del modelo puede responder por URI http://34.118.233.48:8080/embed. Se usará más adelante cuando registres el modelo en AlloyDB Omni.
Podemos probarlo exponiéndolo con el comando kubectl port-forward.
kubectl port-forward service/tei-service 8080:8080
Si usas Cloud Shell, el reenvío de puertos puede ejecutarse en una sesión de Cloud Shell, y necesitamos otra sesión para probarlo.
Abre otra pestaña de Cloud Shell con el signo "+" en la parte superior.
Ejecuta un comando curl en la nueva sesión de shell.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
Debería devolver un array de vectores como en el siguiente ejemplo de resultado (oculto):
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
Si vemos los números, podemos confirmar que probamos el modelo correctamente y que ahora podemos registrarlo en nuestro AlloyDB Omni para usarlo directamente desde SQL.
6. Registra el modelo en AlloyDB Omni
Para probar cómo funciona AlloyDB Omni con el modelo implementado, debemos crear una base de datos y registrar el modelo.
Crea la base de datos
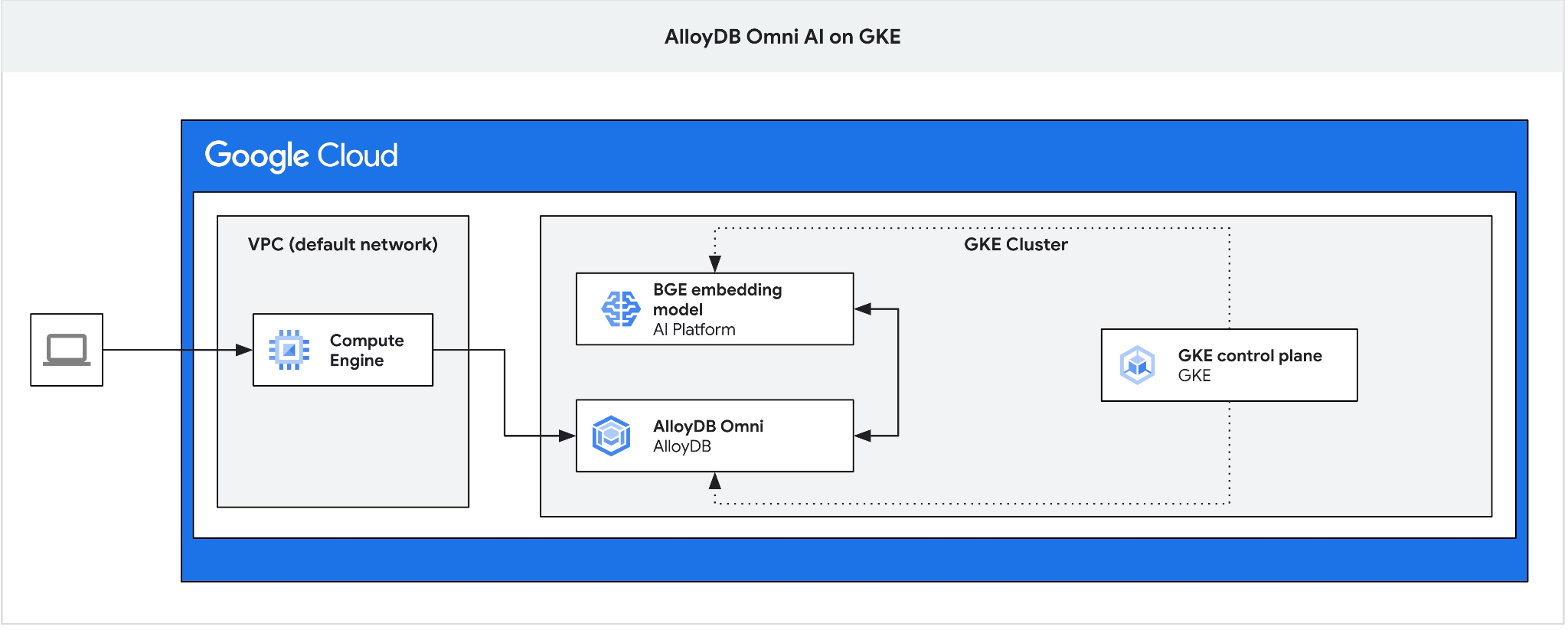
Crea una VM de GCE como un jump box para conectarte a AlloyDB Omni desde tu VM de cliente y crear una base de datos.
Necesitamos la jump box, ya que el balanceador de cargas externo de GKE para Omni te brinda acceso desde la VPC con direcciones IP privadas, pero no te permite conectarte desde fuera de la VPC. En general, es más seguro y no expone tu instancia de base de datos a Internet. Consulta el diagrama para mayor claridad.
Para crear una VM en la sesión de Cloud Shell, ejecuta el siguiente comando:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
Busca la IP del extremo de AlloyDB Omni con kubectl en Cloud Shell:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Anota el valor de PRIMARYENDPOINT.
A continuación, se muestra un ejemplo de resultado:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
La dirección 10.131.0.33 es la IP que usaremos en nuestros ejemplos para conectarnos a la instancia de AlloyDB Omni.
Conéctate a la VM con gcloud:
gcloud compute ssh instance-1 --zone=$ZONE
Si se te solicita que generes una clave SSH, sigue las instrucciones. Obtén más información sobre la conexión SSH en la documentación.
En la sesión de SSH de la VM, instala el cliente de PostgreSQL:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Exporta la variable de IP del balanceador de cargas de AlloyDB Omni con el siguiente ejemplo (reemplaza IP por la IP de tu balanceador de cargas):
export INSTANCE_IP=10.131.0.33
Conéctate a AlloyDB Omni. La contraseña es VeryStrongPassword, como se configuró a través del hash en my-omni.yaml:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
En la sesión de psql establecida, ejecuta lo siguiente:
create database demo;
Sal de la sesión y conéctate a la demostración de la base de datos (o simplemente puedes ejecutar \c demo en la misma sesión).
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Crea funciones de transformación
Para los modelos de incorporación de terceros, debemos crear funciones de transformación que formateen la entrada y la salida según el formato que esperan el modelo y nuestras funciones internas. Estas funciones actúan como traductores para realizar la conversión de formato entre diferentes interfaces.
A continuación, se muestra la función de transformación que controla la entrada:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
Ejecuta el código proporcionado mientras estás conectado a la base de datos de demostración, como se muestra en el resultado de ejemplo:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
Y aquí está la función de salida que transforma la respuesta del modelo en el array de números reales:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
Ejecútalo en la misma sesión:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
Registra el modelo
Ahora podemos registrar el modelo en la base de datos.
Esta es la llamada al procedimiento para registrar el modelo con el nombre embeddinggemma. Usamos el nombre del servicio tei-service en nuestro parámetro model_request_url cuando registramos el modelo. Ese es el nombre interno del servicio del clúster de Kubernetes y se traduce a la IP interna del clúster de GKE:
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
Ejecuta el código proporcionado mientras estás conectado a la base de datos de demostración:
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
Podemos probar el modelo de registro con la siguiente consulta de prueba, que debería devolver un array de números reales.
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
No te sorprendas por la demora prolongada antes de recibir los datos vectoriales. Para esta prueba, usamos un grupo de nodos basados en CPU para alojar el modelo de incorporación, y funciona mucho más rápido en nodos con GPU.
7. Prueba el modelo en AlloyDB Omni
Carga de datos
Para probar cómo funciona nuestro AlloyDB Omni con el modelo implementado, debemos cargar algunos datos. Usé los mismos datos que en uno de los otros codelabs para la búsqueda de vectores en AlloyDB.
Una forma de cargar los datos es usar el SDK de Google Cloud y el software cliente de PostgreSQL. Podemos usar la misma VM del cliente. El SDK de Google Cloud ya debería estar instalado allí si usaste los valores predeterminados para la imagen de VM. Sin embargo, si usaste una imagen personalizada sin el SDK de Google, puedes agregarla siguiendo la documentación.
Exporta la IP del balanceador de cargas de AlloyDB Omni como en el siguiente ejemplo (reemplaza IP por la IP de tu balanceador de cargas):
export INSTANCE_IP=10.131.0.33
Conéctate a la base de datos y habilita la extensión pgvector.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
En la sesión de psql, haz lo siguiente:
CREATE EXTENSION IF NOT EXISTS vector;
Sal de la sesión de psql y, en la sesión de línea de comandos, ejecuta comandos para cargar los datos en la base de datos de demostración.
Crea las tablas. El siguiente comando obtendrá el archivo cymbal_demo_schema.sql y ejecutará el SQL con todas las definiciones de tablas en la base de datos de demostración:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
Resultado esperado en la consola:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
Esta es la lista de tablas creadas:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Resultado:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
Carga datos en la tabla cymbal_products:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
Resultado esperado en la consola:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
A continuación, se muestra una muestra de algunas filas de la tabla cymbal_products.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Resultado:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
Carga datos en la tabla cymbal_inventory:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
Resultado esperado en la consola:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
A continuación, se muestra una muestra de algunas filas de la tabla cymbal_inventory.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Resultado:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
Carga datos en la tabla cymbal_stores:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
Resultado esperado en la consola:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
A continuación, se muestra una muestra de algunas filas de la tabla cymbal_stores.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Resultado:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
Build Embeddings
Conéctate a la base de datos de demostración con psql y crea embeddings para los productos que se describen en la tabla cymbal_products en función de las descripciones de los productos.
Conéctate a la base de datos de demostración:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Usamos una tabla cymbal_embedding con una columna de embedding para almacenar nuestros embeddings y usamos la descripción del producto como entrada de texto para la función.
Habilita la sincronización para tus consultas y, luego, compáralas con los modelos remotos:
\timing
Ejecuta la consulta para compilar los embeddings:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
Resultado esperado en la consola:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
En este ejemplo, la creación de incorporaciones tardó alrededor de 8 minutos. Esto es normal para el grupo de nodos basado en la CPU. En el caso de un grupo con aceleradores de GPU, puede ser mucho más rápido según el tipo de GPU.
Ejecutar consultas de prueba
Conéctate a la base de datos de demostración con psql y habilita la medición del tiempo para medir el tiempo de ejecución de nuestras consultas, como lo hicimos para compilar las incorporaciones.
Busquemos los 5 productos principales que coinciden con una solicitud como "¿Qué tipo de árboles frutales crecen bien aquí?" usando la distancia coseno como algoritmo para la búsqueda de vectores.
En la sesión de psql, ejecuta lo siguiente:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Resultado esperado en la consola:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
La consulta se ejecutó durante 83 ms y devolvió una lista de árboles de la tabla cymbal_products que coincidían con la solicitud y que tenían inventario disponible en la tienda con el número 1583.
Crea el índice de ANN
Cuando solo tenemos un conjunto de datos pequeño, es fácil usar la búsqueda exacta para analizar todos los embeddings, pero, a medida que crecen los datos, también aumentan el tiempo de carga y el tiempo de respuesta. Para mejorar el rendimiento, puedes crear índices en tus datos de incorporación. A continuación, se muestra un ejemplo de cómo hacerlo con el índice ScaNN de Google para datos vectoriales.
Si perdiste la conexión a la base de datos de demostración, vuelve a conectarte:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Habilita la extensión alloydb_scann:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Compila el índice:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
Prueba la misma consulta que antes y compara los resultados:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
El tiempo de ejecución de la consulta se redujo ligeramente, y esa mejora sería más notable con conjuntos de datos más grandes. Los resultados son bastante similares y obtuvimos los mismos 5 árboles principales en el resultado.
Prueba otras consultas y obtén más información para elegir un índice de vectores en la documentación.
Y no olvides que AlloyDB Omni tiene más funciones y labs.
8. Limpia el entorno
Ahora podemos borrar nuestro clúster de GKE con AlloyDB Omni y un modelo de IA
Borra el clúster de GKE.
En Cloud Shell, ejecuta el siguiente comando:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
Resultado esperado en la consola:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
Borrar VM
En Cloud Shell, ejecuta el siguiente comando:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Resultado esperado en la consola:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
Si creaste un proyecto nuevo para este codelab, puedes borrarlo por completo: https://console.cloud.google.com/cloud-resource-manager
9. Felicitaciones
Felicitaciones por completar el codelab.
Temas abordados
- Cómo implementar AlloyDB Omni en un clúster de Google Kubernetes
- Cómo conectarse a AlloyDB Omni
- Cómo cargar datos en AlloyDB Omni
- Cómo implementar un modelo de embedding abierto en GKE
- Cómo registrar un modelo de incorporación en AlloyDB Omni
- Cómo generar incorporaciones para la búsqueda semántica
- Cómo usar los embeddings generados para la búsqueda semántica en AlloyDB Omni
- Cómo crear y usar índices de vectores en AlloyDB
Puedes obtener más información para trabajar con la IA en AlloyDB Omni en la documentación.
10. Encuesta
Resultado: