
1. Introduction
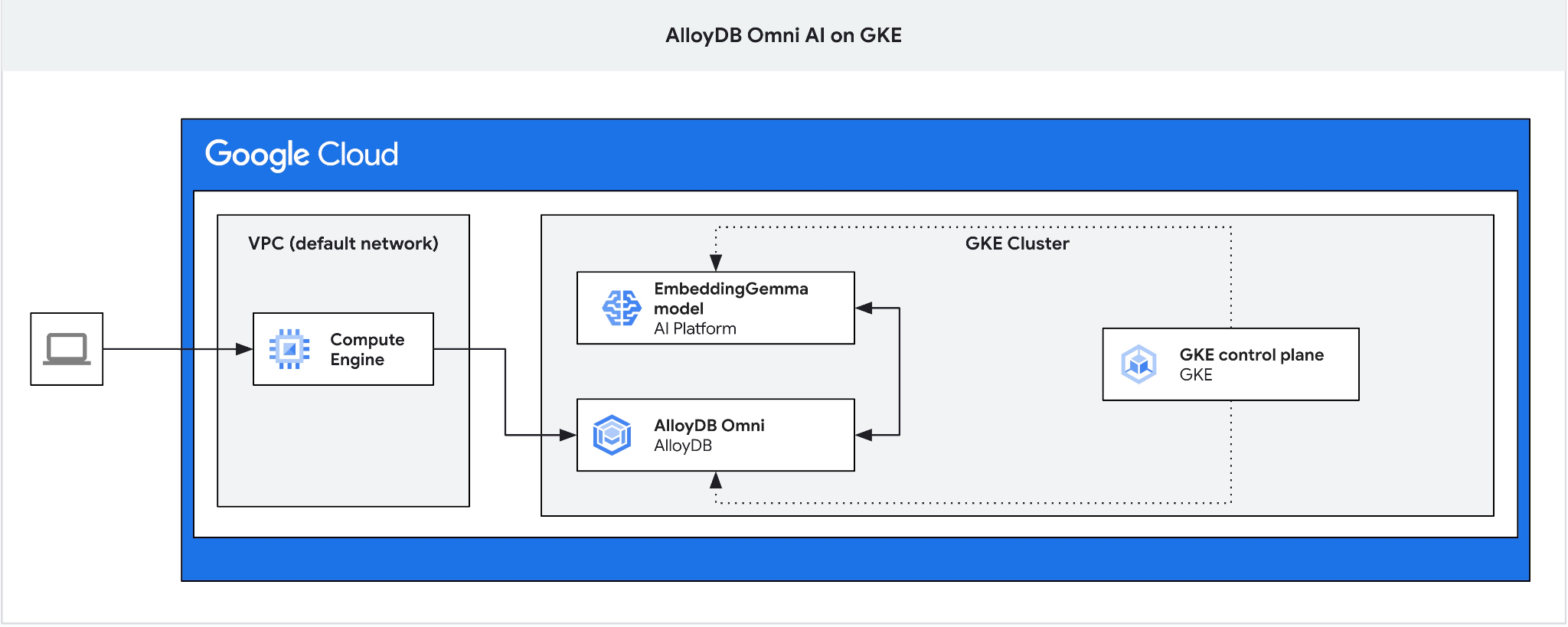
Dans cet atelier de programmation, vous allez apprendre à déployer AlloyDB Omni sur GKE et à l'utiliser avec un modèle d'embedding ouvert déployé dans le même cluster Kubernetes. Le déploiement d'un modèle à côté de l'instance de base de données dans le même cluster GKE réduit la latence et les dépendances vis-à-vis des services tiers. De plus, le déploiement local peut être une exigence de sécurité et de conformité lorsque les données ne doivent pas quitter l'organisation et que l'utilisation de services tiers n'est pas autorisée.
Prérequis
- Connaissances de base concernant la console Google Cloud
- Connaissances de base de Kubernetes et de GKE
- Compétences de base concernant l'interface de ligne de commande et Cloud Shell
Points abordés
- Déployer AlloyDB Omni sur un cluster Google Kubernetes
- Se connecter à AlloyDB Omni
- Charger des données dans AlloyDB Omni
- Déployer un modèle d'embedding ouvert sur GKE
- Enregistrer un modèle d'embedding dans AlloyDB Omni
- Générer des embeddings pour la recherche sémantique
- Utiliser les embeddings générés pour la recherche sémantique dans AlloyDB Omni
- Créer et utiliser des index vectoriels dans AlloyDB
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome, compatible avec la console Google Cloud et Cloud Shell
2. Préparation
Configuration du projet
- Connectez-vous à la console Google Cloud. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
- Créez un projet ou réutilisez-en un. Pour créer un projet dans la console Google Cloud, cliquez sur le bouton "Sélectionner un projet" dans l'en-tête. Une fenêtre pop-up s'ouvre.

Dans la fenêtre "Sélectionner un projet", cliquez sur le bouton "Nouveau projet" pour ouvrir une boîte de dialogue pour le nouveau projet.
Dans la boîte de dialogue, saisissez le nom de projet de votre choix et sélectionnez l'emplacement.
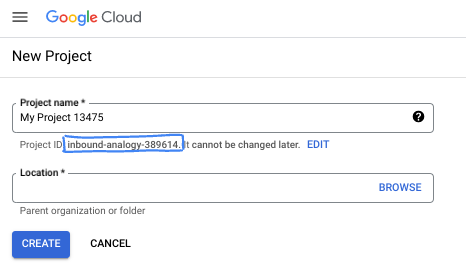
- Le nom du projet est le nom à afficher pour les participants au projet. Le nom du projet n'est pas utilisé par les API Google et peut être modifié à tout moment.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Google Cloud génère automatiquement un ID unique, mais vous pouvez le personnaliser. Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire ou fournir le vôtre pour vérifier sa disponibilité. Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet, généralement identifié par le code de substitution PROJECT_ID.
- Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
Activer la facturation
Configurer un compte de facturation personnel
Si vous configurez la facturation à l'aide de crédits Google Cloud, vous pouvez ignorer cette étape.
Pour configurer un compte de facturation personnel, cliquez ici pour activer la facturation dans la console Cloud.
Remarques :
- Cet atelier devrait vous coûter moins de 3 USD en ressources cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi des frais supplémentaires.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour profiter d'un crédit de 300$.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Vous pouvez également appuyer sur G, puis sur S. Cette séquence activera Cloud Shell si vous êtes dans la console Google Cloud ou si vous utilisez ce lien.
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Avant de commencer
Activer l'API
Résultat :
Pour utiliser Google Kubernetes Engine (GKE) pour les déploiements AlloyDB Omni et les modèles ouverts, vous devez activer leurs API respectives dans votre projet Google Cloud.
Dans Cloud Shell, assurez-vous que l'ID de votre projet est configuré :
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Si elle n'est pas définie dans la configuration Cloud Shell, configurez-la à l'aide des commandes suivantes.
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Activez tous les services nécessaires :
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
Résultat attendu
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Présentation des API
- L'API Kubernetes Engine (
container.googleapis.com) vous permet de créer et de gérer des clusters Google Kubernetes Engine (GKE). Il fournit un environnement géré permettant de déployer, gérer et faire évoluer vos applications conteneurisées à l'aide de l'infrastructure Google. - L'API Compute Engine (
compute.googleapis.com) vous permet de créer et de gérer des machines virtuelles (VM), des disques persistants et des paramètres réseau. Elle fournit la base IaaS (Infrastructure as a Service) requise pour exécuter vos charges de travail et héberger l'infrastructure sous-jacente de nombreux services gérés.
4. Déployer AlloyDB Omni sur GKE
Pour déployer AlloyDB Omni sur GKE, nous devons préparer un cluster Kubernetes en respectant les exigences listées dans les exigences de l'opérateur AlloyDB Omni.
Créer un cluster GKE
Nous devons déployer un cluster GKE Standard avec une configuration de pool suffisante pour déployer un pod avec une instance AlloyDB Omni. Pour AlloyDB Omni, nous avons besoin d'au moins deux processeurs et de 8 Go de RAM, et d'un peu d'espace pour les conteneurs de services d'opérateur et de surveillance. Nous allons utiliser le type de VM e2-standard-4.
Configurez les variables d'environnement pour votre déploiement.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
Nous utilisons ensuite gcloud pour créer le cluster GKE Standard.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Résultat attendu sur la console :
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
Préparer le cluster
Nous devons installer les composants requis, tels que le service cert-manager, qui est un gestionnaire de certificats natif pour Kubernetes. Nous pouvons suivre les étapes de la documentation pour l'installation de cert-manager.
Nous utilisons l'outil de ligne de commande Kubernetes, kubectl, qui est déjà installé par défaut dans Cloud Shell. Avant d'utiliser l'utilitaire, nous devons obtenir les identifiants de notre cluster.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
Nous pouvons maintenant utiliser kubectl pour installer cert-manager :
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
Résultat attendu sur la console (masqué) :
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
Installer AlloyDB Omni
L'opérateur AlloyDB Omni peut être installé à l'aide de l'utilitaire Helm.
Exécutez la commande suivante pour installer l'opérateur AlloyDB Omni :
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
Résultat attendu sur la console (masqué) :
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
Une fois l'opérateur AlloyDB Omni installé, nous pouvons déployer notre cluster de bases de données.
Voici un exemple de fichier manifeste de déploiement avec le paramètre googleMLExtension activé et un équilibreur de charge interne (privé) :
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
La valeur secrète du mot de passe est une représentation Base64 du mot de passe "VeryStrongPassword". La méthode la plus fiable consiste à utiliser Google Secret Manager pour stocker la valeur du mot de passe. Pour en savoir plus, consultez la documentation.
Enregistrez le fichier manifeste sous le nom my-omni.yaml pour l'appliquer à l'étape suivante. Si vous êtes dans Cloud Shell, vous pouvez le faire à l'aide de l'éditeur en appuyant sur le bouton "Ouvrir l'éditeur" en haut à droite du terminal.
Après avoir enregistré le fichier sous le nom my-omni.yaml, revenez au terminal en appuyant sur le bouton "Ouvrir le terminal".
Appliquez le fichier manifeste my-omni.yaml au cluster à l'aide de l'utilitaire kubectl :
kubectl apply -f my-omni.yaml
Résultat attendu sur la console :
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
Vérifiez l'état de votre cluster my-omni à l'aide de l'utilitaire kubectl :
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Lors du déploiement, le cluster passe par différentes phases et devrait finalement atteindre l'état DBClusterReady.
Résultat attendu sur la console :
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
Se connecter à AlloyDB Omni
Se connecter à l'aide d'un pod Kubernetes
Une fois le cluster prêt, nous pouvons utiliser les binaires du client PostgreSQL sur le pod de l'instance AlloyDB Omni. Nous trouvons l'ID du pod, puis nous utilisons kubectl pour nous connecter directement au pod et exécuter le logiciel client. Le mot de passe est VeryStrongPassword, tel qu'il est défini via le secret Kubernetes dans le fichier manifeste my-omni.yaml :
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Exemple de résultat de la console :
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. Déployer un modèle d'IA sur GKE
Pour tester l'intégration de l'IA AlloyDB Omni avec des modèles locaux, nous devons déployer un modèle sur le cluster. Nous allons utiliser le modèle EmbeddingGemma de Google.
Créer un pool de nœuds pour le modèle
Pour exécuter le modèle, nous devons préparer un pool de nœuds pour exécuter l'inférence. Nous pouvons l'exécuter à l'aide d'un pool de processeurs uniquement ou d'un pool avec des accélérateurs GPU. L'approche basée uniquement sur le processeur peut être plus réalisable dans certaines régions en raison de la forte simultanéité des ressources. Dans notre atelier, nous allons utiliser l'approche CPU, mais la meilleure approche du point de vue des performances est un pool avec des accélérateurs graphiques utilisant une configuration de nœud telle que g2-standard-8 avec un accélérateur Nvidia L4.
Pool de nœuds basé sur le processeur
Créez un pool de nœuds avec des nœuds e2-standard-32. Nous allons limiter notre extraction à un seul nœud pour économiser des ressources.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
Résultat attendu
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
Obtenir un jeton Hugging Face
Dans cet atelier, nous utilisons un partenariat avec Hugging Face pour déployer le modèle EmbeddingGemma. Pour ce faire, nous devons obtenir un jeton Hugging Face.
Suivez les étapes ci-dessous pour générer un nouveau jeton si vous n'en avez pas encore.
- Connectez-vous ou inscrivez-vous sur le site Hugging Face en cliquant sur les liens "Log In" (Se connecter) ou "Sign Up" (S'inscrire) en haut à droite.
- Cliquez sur Votre profil > Jetons d'accès.
- Confirmez votre identité
- Cliquez sur "Créer un jeton".
- Choisissez un nom pour votre jeton.
- Sélectionnez un rôle pour le jeton (vous devez au moins disposer du privilège "Lecture").
- Cliquez sur "Créer un jeton" en bas de la page.
- Copiez le jeton généré et enregistrez-le pour une utilisation ultérieure.
Vous devez également accepter les conditions d'accès aux fichiers et contenus liés à EmbeddingGemma sur Hugging Face, sur la page https://huggingface.co/google/embeddinggemma-300m.
Créez un secret Kubernetes à l'aide du jeton.
Dans la session Cloud Shell, exécutez la commande suivante (remplacez la valeur de HF_TOKEN par votre jeton HF).
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
Préparer le fichier manifeste de déploiement
Pour déployer le modèle, nous devons préparer un fichier manifeste de déploiement.
Nous utilisons le modèle EmbeddingGemma de Google provenant de Hugging Face. Pour lire la fiche du modèle, cliquez ici. Pour déployer le modèle, nous allons utiliser une approche basée sur les instructions de Hugging Face et le package de déploiement de GitHub.
Cloner le package depuis GitHub
git clone https://github.com/huggingface/Google-Cloud-Containers
Ajustez le fichier manifeste pour l'interface d'embedding de texte (tei) sur les nœuds de processeur. Nous devons remplacer plusieurs paramètres, y compris le modèle, l'image et l'allocation de ressources correcte, et ajouter le secret du jeton Hugging Face à la configuration.
Modifiez le fichier manifeste (à l'aide de n'importe quel éditeur disponible).
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
Voici un fichier manifeste corrigé pour le déploiement sur un pool basé sur le processeur.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
Déployer le modèle
Déployez le modèle en appliquant le fichier manifeste modifié pour les déploiements de processeur.
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
Vérifier les déploiements
kubectl get pods
Vérifier le service de modèle
kubectl get service tei-service
Il est censé afficher le type de service en cours d'exécution ClusterIP.
Exemple de résultat :
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
Nous allons utiliser l'adresse CLUSTER-IP du service comme adresse de point de terminaison. L'intégration du modèle peut répondre par l'URI http://34.118.233.48:8080/embed. Il sera utilisé ultérieurement lorsque vous enregistrerez le modèle dans AlloyDB Omni.
Nous pouvons le tester en l'exposant à l'aide de la commande kubectl port-forward.
kubectl port-forward service/tei-service 8080:8080
Si vous utilisez Cloud Shell, le transfert de port peut s'exécuter dans une session Cloud Shell. Nous avons besoin d'une autre session pour le tester.
Ouvrez un autre onglet Cloud Shell à l'aide du signe "+" situé en haut.
Exécutez une commande curl dans la nouvelle session shell.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
Il devrait renvoyer un tableau de vecteurs semblable à l'exemple de résultat suivant (masqué) :
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
Si nous voyons les chiffres, nous pouvons confirmer que nous avons testé le modèle avec succès et que nous pouvons maintenant l'enregistrer dans AlloyDB Omni pour l'utiliser directement à partir de SQL.
6. Enregistrer le modèle dans AlloyDB Omni
Pour tester le fonctionnement d'AlloyDB Omni avec le modèle déployé, nous devons créer une base de données et enregistrer le modèle.
Créer une base de données
Créez une VM GCE en tant que jump box pour vous connecter à AlloyDB Omni depuis votre VM cliente et créer une base de données.
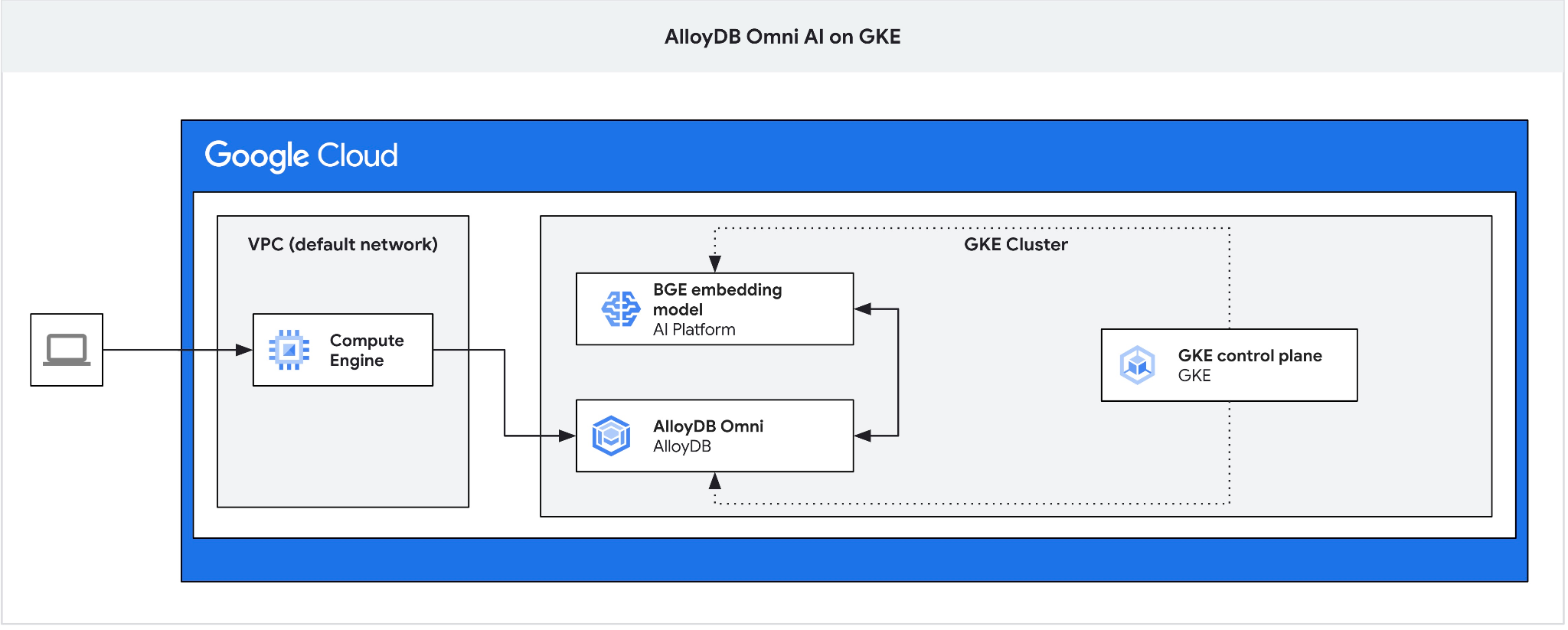
Nous avons besoin de la jump box, car l'équilibreur de charge externe GKE pour Omni vous permet d'accéder au VPC à l'aide d'adresses IP privées, mais ne vous permet pas de vous connecter depuis l'extérieur du VPC. Elle est plus sécurisée en général et n'expose pas votre instance de base de données à Internet. Veuillez consulter le schéma pour plus de clarté.
Pour créer une VM dans la session Cloud Shell, exécutez :
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
Recherchez l'adresse IP du point de terminaison AlloyDB Omni à l'aide de kubectl dans Cloud Shell :
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Notez l'PRIMARYENDPOINT.
Voici un exemple de résultat:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33 est l'adresse IP que nous utiliserons dans nos exemples pour nous connecter à l'instance AlloyDB Omni.
Connectez-vous à la VM à l'aide de gcloud :
gcloud compute ssh instance-1 --zone=$ZONE
Si vous êtes invité à générer une clé SSH, suivez les instructions. Pour en savoir plus sur la connexion SSH, consultez la documentation.
Dans la session SSH de la VM, installez le client PostgreSQL :
sudo apt-get update
sudo apt-get install --yes postgresql-client
Exportez la variable d'adresse IP de l'équilibreur de charge AlloyDB Omni en utilisant l'exemple suivant (remplacez IP par l'adresse IP de votre équilibreur de charge) :
export INSTANCE_IP=10.131.0.33
Connectez-vous à AlloyDB Omni. Le mot de passe est VeryStrongPassword, tel qu'il est défini via le hachage dans my-omni.yaml :
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Dans la session psql établie, exécutez :
create database demo;
Quittez la session et connectez-vous à la démo de la base de données (ou exécutez simplement \c demo dans la même session).
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Créer des fonctions de transformation
Pour les modèles d'embedding tiers, nous devons créer des fonctions de transformation qui mettent en forme l'entrée et la sortie dans le format attendu par le modèle et nos fonctions internes. Ces fonctions servent de traducteurs pour convertir les formats entre différentes interfaces.
Voici la fonction de transformation qui gère l'entrée :
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
Exécutez le code fourni tout en étant connecté à la base de données de démonstration, comme indiqué dans l'exemple de résultat :
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
Voici la fonction de sortie qui transforme la réponse du modèle en tableau de nombres réels :
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
Exécutez-le dans la même session :
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
Enregistrer le modèle
Nous pouvons maintenant enregistrer le modèle dans la base de données.
Voici l'appel de procédure pour enregistrer le modèle sous le nom embeddinggemma. Nous utilisons le nom de service tei-service dans notre paramètre model_request_url lorsque nous enregistrons le modèle. Il s'agit du nom de service de cluster Kubernetes interne, qui se traduit par l'adresse IP interne du cluster GKE :
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
Exécutez le code fourni lorsque vous êtes connecté à la base de données de démonstration :
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
Nous pouvons tester le modèle d'enregistrement à l'aide de la requête de test suivante, qui devrait renvoyer un tableau de nombres réels.
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
Ne soyez pas surpris par le délai prolongé avant de récupérer les données vectorielles. Pour ce test, nous utilisons un pool de nœuds basé sur le processeur pour héberger le modèle d'embedding. Il fonctionne beaucoup plus rapidement sur les nœuds avec GPU.
7. Tester le modèle dans AlloyDB Omni
Charger des données
Pour tester le fonctionnement d'AlloyDB Omni avec le modèle déployé, nous devons charger des données. J'ai utilisé les mêmes données que dans l'un des autres ateliers de programmation pour la recherche vectorielle dans AlloyDB.
Pour charger les données, vous pouvez utiliser le Google Cloud SDK et le logiciel client PostgreSQL. Nous pouvons utiliser la même VM cliente. Le SDK Google Cloud devrait déjà être installé si vous avez utilisé les valeurs par défaut pour l'image de VM. Toutefois, si vous avez utilisé une image personnalisée sans le SDK Google, vous pouvez l'ajouter en suivant la documentation.
Exportez l'adresse IP de l'équilibreur de charge AlloyDB Omni comme dans l'exemple suivant (remplacez IP par l'adresse IP de votre équilibreur de charge) :
export INSTANCE_IP=10.131.0.33
Connectez-vous à la base de données et activez l'extension pgvector.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Dans la session psql :
CREATE EXTENSION IF NOT EXISTS vector;
Quittez la session psql et exécutez des commandes dans la session de ligne de commande pour charger les données dans la base de données de démonstration.
Créez les tables. La commande suivante récupère le fichier cymbal_demo_schema.sql et exécute le code SQL avec toutes les définitions de tables dans la base de données de démonstration :
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
Résultat attendu sur la console :
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
Voici la liste des tables créées :
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Résultat :
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
Chargez les données dans la table cymbal_products :
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
Résultat attendu sur la console :
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
Voici un exemple de quelques lignes du tableau cymbal_products.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Résultat :
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
Chargez les données dans la table cymbal_inventory :
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
Résultat attendu sur la console :
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
Voici un exemple de quelques lignes du tableau cymbal_inventory.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Résultat :
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
Chargez les données dans la table cymbal_stores :
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
Résultat attendu sur la console :
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
Voici un exemple de quelques lignes du tableau cymbal_stores.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Résultat :
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
Créer des embeddings
Connectez-vous à la base de données de démonstration à l'aide de psql et créez des embeddings pour les produits décrits dans la table cymbal_products en fonction des descriptions des produits.
Connectez-vous à la base de données de démonstration :
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Nous utilisons une table cymbal_embedding avec un embedding de colonne pour stocker nos embeddings et nous utilisons la description du produit comme entrée de texte pour la fonction.
Activez le timing pour vos requêtes afin de les comparer ultérieurement avec des modèles distants :
\timing
Exécutez la requête pour créer les embeddings :
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
Résultat attendu sur la console :
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
Dans cet exemple, la création d'embeddings a pris environ huit minutes. Ce comportement est normal pour un pool de nœuds basé sur le processeur. Pour un pool avec des accélérateurs GPU, cela peut être beaucoup plus rapide en fonction du type de GPU.
Exécuter des requêtes de test
Connectez-vous à la base de données de démonstration à l'aide de psql et activez le timing pour mesurer le temps d'exécution de nos requêtes, comme nous l'avons fait pour la création d'embeddings.
Trouvons les cinq meilleurs produits correspondant à une requête telle que "Quels types d'arbres fruitiers poussent bien ici ?" en utilisant la distance de cosinus comme algorithme pour la recherche vectorielle.
Dans la session psql, exécutez :
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Résultat attendu sur la console :
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
La requête s'est exécutée en 83 ms et a renvoyé une liste d'arbres de la table cymbal_products correspondant à la requête et avec un inventaire disponible dans le magasin numéro 1583.
Créer un index ANN
Lorsque nous ne disposons que d'un petit ensemble de données, il est facile d'utiliser la recherche exacte en analysant tous les embeddings. Toutefois, lorsque les données augmentent, le temps de chargement et de réponse augmente également. Pour améliorer les performances, vous pouvez créer des index sur vos données d'embedding. Voici un exemple d'utilisation de l'index ScaNN de Google pour les données vectorielles.
Si vous avez perdu la connexion à la base de données de démonstration, reconnectez-vous :
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Activez l'extension alloydb_scann :
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Créez l'index :
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
Exécutez la même requête que précédemment et comparez les résultats :
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
Le temps d'exécution des requêtes a légèrement diminué. Ce gain serait plus visible avec des ensembles de données plus volumineux. Les résultats sont assez similaires et nous avons obtenu les cinq mêmes arbres en tête du résultat.
Essayez d'autres requêtes et découvrez comment choisir un index vectoriel dans la documentation.
N'oubliez pas qu'AlloyDB Omni propose plus de fonctionnalités et de labs.
8. Nettoyer l'environnement
Nous pouvons maintenant supprimer notre cluster GKE avec AlloyDB Omni et un modèle d'IA.
Supprimer un cluster GKE
Dans Cloud Shell, exécutez :
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
Résultat attendu sur la console :
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
Supprimer la VM
Dans Cloud Shell, exécutez :
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Résultat attendu sur la console :
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
Si vous avez créé un projet pour cet atelier de programmation, vous pouvez supprimer le projet complet : https://console.cloud.google.com/cloud-resource-manager
9. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation.
Points abordés
- Déployer AlloyDB Omni sur un cluster Google Kubernetes
- Se connecter à AlloyDB Omni
- Charger des données dans AlloyDB Omni
- Déployer un modèle d'embedding ouvert sur GKE
- Enregistrer un modèle d'embedding dans AlloyDB Omni
- Générer des embeddings pour la recherche sémantique
- Utiliser les embeddings générés pour la recherche sémantique dans AlloyDB Omni
- Créer et utiliser des index vectoriels dans AlloyDB
Pour en savoir plus sur l'utilisation de l'IA dans AlloyDB Omni, consultez la documentation.
10. Enquête
Résultat :