
1. Pengantar
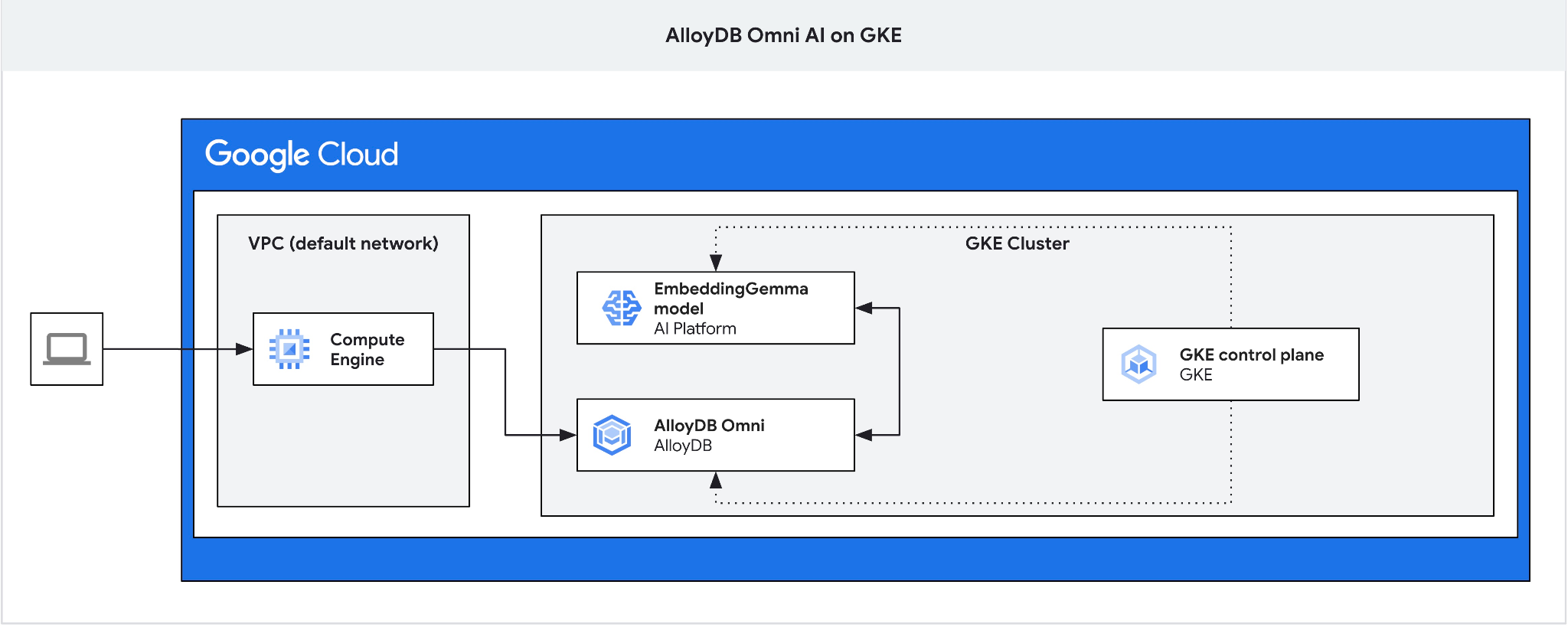
Dalam codelab ini, Anda akan mempelajari cara men-deploy AlloyDB Omni di GKE dan menggunakannya dengan model penyematan terbuka yang di-deploy di cluster Kubernetes yang sama. Deployment model di samping instance database dalam cluster GKE yang sama akan mengurangi latensi dan dependensi pada layanan pihak ketiga. Selain itu, deployment lokal mungkin merupakan persyaratan yang ditetapkan oleh keamanan dan kepatuhan jika data tidak boleh keluar dari organisasi dan penggunaan layanan pihak ketiga tidak diizinkan.
Prasyarat
- Pemahaman dasar tentang Google Cloud, konsol
- Pengetahuan dasar tentang Kubernetes dan GKE
- Keterampilan dasar dalam antarmuka command line dan Cloud Shell
Yang akan Anda pelajari
- Cara men-deploy AlloyDB Omni di cluster Google Kubernetes
- Cara terhubung ke AlloyDB Omni
- Cara memuat data ke AlloyDB Omni
- Cara men-deploy model penyematan terbuka ke GKE
- Cara mendaftarkan model sematan di AlloyDB Omni
- Cara membuat embedding untuk penelusuran semantik
- Cara menggunakan embedding yang dihasilkan untuk penelusuran semantik di AlloyDB Omni
- Cara membuat dan menggunakan indeks vektor di AlloyDB
Yang Anda butuhkan
- Akun Google Cloud dan Project Google Cloud
- Browser web seperti Chrome yang mendukung Konsol Google Cloud dan Cloud Shell
2. Penyiapan dan Persyaratan
Penyiapan Project
- Login ke Konsol Google Cloud. Jika belum memiliki akun Gmail atau Google Workspace, Anda harus membuatnya.
Gunakan akun pribadi, bukan akun kantor atau sekolah.
- Buat project baru atau gunakan kembali project yang sudah ada. Untuk membuat project baru di Konsol Google Cloud, di header, klik tombol Pilih project yang akan membuka jendela pop-up.

Di jendela Select a project, tekan tombol New Project yang akan membuka kotak dialog untuk project baru.
Di kotak dialog, masukkan Nama project yang Anda inginkan dan pilih lokasi.
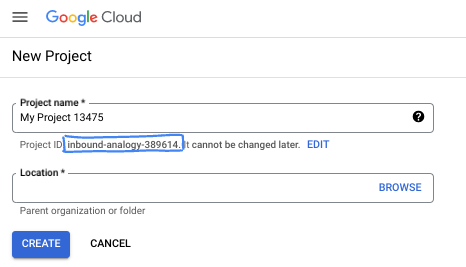
- Project name adalah nama tampilan untuk peserta project ini. Nama project tidak digunakan oleh Google API, dan dapat diubah kapan saja.
- Project ID bersifat unik di semua project Google Cloud dan tidak dapat diubah (tidak dapat diubah setelah ditetapkan). Konsol Google Cloud otomatis membuat ID unik, tetapi Anda dapat menyesuaikannya. Jika tidak menyukai ID yang dibuat, Anda dapat membuat ID acak lain atau memberikan ID Anda sendiri untuk memeriksa ketersediaannya. Di sebagian besar codelab, Anda harus merujuk project ID Anda, yang biasanya diidentifikasi dengan placeholder PROJECT_ID.
- Sebagai informasi, ada nilai ketiga, Project Number, yang digunakan oleh beberapa API. Pelajari lebih lanjut ketiga nilai ini di dokumentasi.
Aktifkan Penagihan
Menyiapkan akun penagihan pribadi
Jika menyiapkan penagihan menggunakan kredit Google Cloud, Anda dapat melewati langkah ini.
Untuk menyiapkan akun penagihan pribadi, buka di sini untuk mengaktifkan penagihan di Cloud Console.
Beberapa Catatan:
- Menyelesaikan lab ini akan dikenai biaya kurang dari $3 USD untuk resource Cloud.
- Anda dapat mengikuti langkah-langkah di akhir lab ini untuk menghapus resource agar tidak dikenai biaya lebih lanjut.
- Pengguna baru memenuhi syarat untuk mengikuti program Uji Coba Gratis senilai$300 USD.
Mulai Cloud Shell
Meskipun Google Cloud dapat dioperasikan dari jarak jauh menggunakan laptop Anda, dalam codelab ini, Anda akan menggunakan Google Cloud Shell, lingkungan command line yang berjalan di Cloud.
Dari Google Cloud Console, klik ikon Cloud Shell di toolbar kanan atas:
Atau, Anda dapat menekan G, lalu S. Urutan ini akan mengaktifkan Cloud Shell jika Anda berada dalam Konsol Google Cloud atau menggunakan link ini.
Hanya perlu waktu beberapa saat untuk penyediaan dan terhubung ke lingkungan. Jika sudah selesai, Anda akan melihat tampilan seperti ini:

Mesin virtual ini berisi semua alat pengembangan yang Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Semua pekerjaan Anda dalam codelab ini dapat dilakukan di browser. Anda tidak perlu menginstal apa pun.
3. Sebelum memulai
Aktifkan API
Output:
Untuk menggunakan Google Kubernetes Engine (GKE) untuk deployment AlloyDB Omni dan model terbuka, Anda harus mengaktifkan API masing-masing di project Google Cloud Anda.
Di dalam Cloud Shell, pastikan project ID Anda sudah disiapkan:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Jika tidak ditentukan dalam konfigurasi cloud shell, siapkan menggunakan perintah berikut
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Aktifkan semua layanan yang diperlukan:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
Output yang diharapkan
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Memperkenalkan API
- Kubernetes Engine API (
container.googleapis.com) memungkinkan Anda membuat dan mengelola cluster Google Kubernetes Engine (GKE). Layanan ini menyediakan lingkungan terkelola untuk men-deploy, mengelola, dan menskalakan aplikasi dalam container menggunakan infrastruktur Google. - Compute Engine API (
compute.googleapis.com) memungkinkan Anda membuat dan mengelola mesin virtual (VM), persistent disk, dan setelan jaringan. Layanan ini menyediakan fondasi Infrastructure-as-a-Service (IaaS) inti yang diperlukan untuk menjalankan beban kerja Anda dan menghosting infrastruktur yang mendasarinya untuk banyak layanan terkelola.
4. Men-deploy AlloyDB Omni di GKE
Untuk men-deploy AlloyDB Omni di GKE, kita perlu menyiapkan cluster Kubernetes dengan mengikuti persyaratan yang tercantum dalam persyaratan operator AlloyDB Omni.
Membuat Cluster GKE
Kita perlu men-deploy cluster GKE standar dengan konfigurasi pool yang cukup untuk men-deploy pod dengan instance AlloyDB Omni. Untuk AlloyDB Omni, kita memerlukan minimal 2 CPU dan RAM 8 GB serta memiliki ruang untuk container layanan pemantauan dan operator. Kita akan menggunakan jenis VM e2-standard-4.
Siapkan variabel lingkungan untuk deployment Anda.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
Kemudian, kita menggunakan gcloud untuk membuat cluster standar GKE.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Output konsol yang diharapkan:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
Menyiapkan Cluster
Kita perlu menginstal komponen yang diperlukan seperti layanan cert-manager - pengelola sertifikat native untuk kubernetes. Kita dapat mengikuti langkah-langkah dalam dokumentasi untuk penginstalan cert-manager
Kita menggunakan alat command line Kubernetes, kubectl, yang sudah terinstal di Cloud Shell secara default. Sebelum menggunakan utilitas, kita perlu mendapatkan kredensial untuk cluster.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
Sekarang kita dapat menggunakan kubectl untuk menginstal cert-manager:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
Output konsol yang diharapkan (disamarkan):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
Menginstal AlloyDB Omni
Operator AlloyDB Omni dapat diinstal menggunakan utilitas helm.
Jalankan perintah berikut untuk menginstal operator AlloyDB Omni:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
Output konsol yang diharapkan (disamarkan):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
Setelah operator AlloyDB Omni diinstal, kita dapat melanjutkan dengan deployment cluster database.
Berikut adalah contoh manifes deployment dengan parameter googleMLExtension yang diaktifkan dan load balancer internal (pribadi).:
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
Nilai rahasia untuk sandi adalah representasi Base64 dari kata sandi "VeryStrongPassword". Cara yang lebih andal adalah menggunakan pengelola secret Google untuk menyimpan nilai sandi. Anda dapat membaca selengkapnya di dokumentasi.
Simpan manifes sebagai my-omni.yaml untuk diterapkan pada langkah berikutnya. Jika Anda berada di Cloud Shell, Anda dapat melakukannya menggunakan editor dengan menekan tombol "Open Editor" di kanan atas terminal.
Setelah menyimpan file dengan nama my-omni.yaml, kembali ke terminal dengan menekan tombol "Open Terminal".
Terapkan manifes my-omni.yaml ke cluster menggunakan utilitas kubectl:
kubectl apply -f my-omni.yaml
Output konsol yang diharapkan:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
Periksa status cluster my-omni menggunakan utilitas kubectl:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Selama deployment, cluster akan melalui berbagai fase dan pada akhirnya akan berakhir dengan status DBClusterReady.
Output konsol yang diharapkan:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
Menghubungkan ke AlloyDB Omni
Menghubungkan Menggunakan Pod Kubernetes
Setelah cluster siap, kita dapat menggunakan biner klien PostgreSQL di pod instance AlloyDB Omni. Kita menemukan ID pod, lalu menggunakan kubectl untuk terhubung langsung ke pod dan menjalankan software klien. Sandi adalah VeryStrongPassword seperti yang ditetapkan melalui secret Kubernetes dalam manifes my-omni.yaml:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Contoh output konsol:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. Men-deploy Model AI di GKE
Untuk menguji integrasi AI AlloyDB Omni dengan model lokal, kita perlu men-deploy model ke cluster. Kita akan menggunakan model EmbeddingGemma Google.
Membuat Node Pool untuk Model
Untuk menjalankan model, kita perlu menyiapkan node pool untuk menjalankan inferensi. Kita dapat menjalankannya menggunakan kumpulan khusus CPU atau kumpulan dengan akselerator GPU. Pendekatan CPU saja mungkin lebih layak di beberapa region karena konkurensi tinggi untuk resource. Di lab kami, kami akan menggunakan pendekatan CPU, tetapi pendekatan terbaik dari sudut pandang performa adalah pool dengan akselerator grafis menggunakan konfigurasi node seperti g2-standard-8 dengan akselerator Nvidia L4.
Node Pool Berbasis CPU
Buat node pool dengan node e2-standard-32. Kita akan membatasi penarikan ke satu node untuk menghemat resource.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
Output yang diharapkan
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
Mendapatkan Token Hugging Face
Di lab ini, kita menggunakan kemitraan dengan Hugging Face untuk men-deploy model EmbeddingGemma dan untuk melakukannya, kita perlu mendapatkan token Hugging Face.
Ikuti langkah-langkah di bawah untuk membuat token baru jika Anda belum pernah membuatnya.
- Login atau daftar di situs Hugging Face menggunakan link Log In atau Sign Up di pojok kanan atas.
- Klik Profil Anda -> Token Akses
- Konfirmasi identitas
- Klik Buat token baru
- Pilih nama untuk token Anda
- Pilih peran untuk token - Anda memerlukan setidaknya hak istimewa Baca
- Klik Buat token di bagian bawah halaman
- Salin token yang dihasilkan dan simpan untuk digunakan nanti
Anda juga harus menyetujui persyaratan untuk mengakses file dan konten terkait EmbeddingGemma di Hugging Face di halaman https://huggingface.co/google/embeddinggemma-300m
Buat secret Kubernetes menggunakan token
Di sesi cloud shell, jalankan (ganti nilai HF_TOKEN dengan token HF Anda).
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
Menyiapkan Manifes Deployment
Untuk men-deploy model, kita perlu menyiapkan manifes deployment.
Kami menggunakan model EmbeddingGemma Google dari Hugging Face. Anda dapat membaca kartu model di sini. Untuk men-deploy model, kita akan menggunakan pendekatan berdasarkan petunjuk dari Hugging Face dan paket deployment dari GitHub.
Clone paket dari GitHub
git clone https://github.com/huggingface/Google-Cloud-Containers
Sesuaikan manifes untuk tei (text embedding interface) pada node CPU. Kita perlu mengganti beberapa parameter termasuk model, gambar, alokasi resource yang benar, dan menambahkan rahasia token Hugging Face ke konfigurasi.
Edit manifes (menggunakan editor yang tersedia)
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
Berikut adalah manifes yang telah dikoreksi untuk deployment di pool berbasis CPU.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
Men-deploy Model
Deploy model dengan menerapkan manifes yang diubah untuk deployment CPU.
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
Memverifikasi deployment
kubectl get pods
Memverifikasi layanan model
kubectl get service tei-service
Seharusnya menampilkan jenis layanan yang sedang berjalan ClusterIP
Contoh output:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
CLUSTER-IP untuk layanan adalah yang akan kita gunakan sebagai alamat endpoint. Penyematan model dapat merespons dengan URI http://34.118.233.48:8080/embed. Nama ini akan digunakan nanti saat Anda mendaftarkan model di AlloyDB Omni.
Kita dapat mengujinya dengan mengeksposnya menggunakan perintah kubectl port-forward.
kubectl port-forward service/tei-service 8080:8080
Jika Anda menggunakan Cloud Shell, penerusan port dapat berjalan di satu sesi Cloud Shell dan kita memerlukan sesi lain untuk mengujinya.
Buka tab Cloud Shell lain menggunakan tanda "+" di bagian atas.
Lalu, jalankan perintah curl di sesi shell baru.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
Responsnya akan berupa array vektor seperti dalam contoh output berikut (disamarkan):
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
Jika kita melihat angka-angka tersebut, kita dapat mengonfirmasi bahwa kita telah berhasil menguji model dan kini dapat mendaftarkannya di AlloyDB Omni untuk digunakan langsung dari SQL.
6. Mendaftarkan Model di AlloyDB Omni
Untuk menguji cara kerja AlloyDB Omni dengan model yang di-deploy, kita perlu membuat database dan mendaftarkan model.
Buat Database
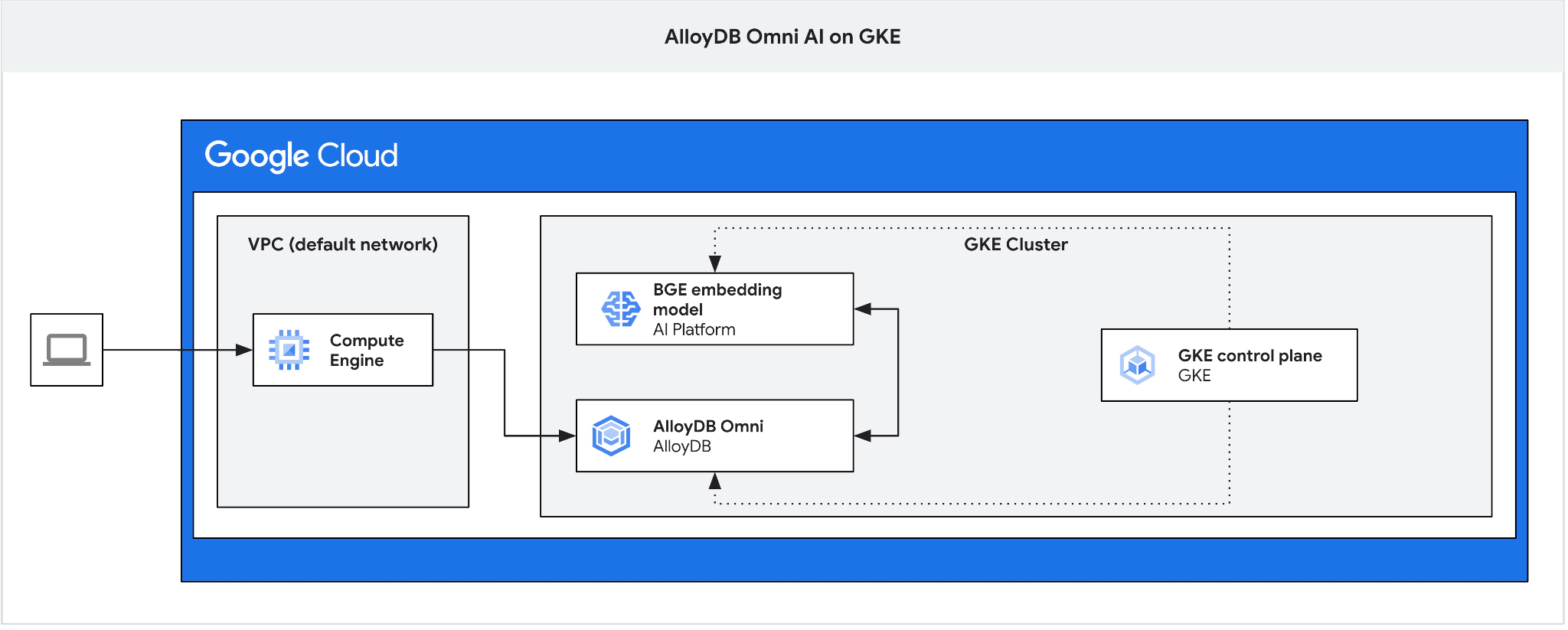
Buat VM GCE sebagai jump box untuk terhubung ke AlloyDB Omni dari VM klien Anda dan buat database.
Kita memerlukan jump box karena load balancer eksternal GKE untuk Omni memberi Anda akses dari VPC menggunakan pengalamatan IP pribadi, tetapi tidak memungkinkan Anda terhubung dari luar VPC. Secara umum, cara ini lebih aman dan tidak mengekspos instance database Anda ke internet. Periksa diagram untuk memastikan kejelasan.
Untuk membuat VM di sesi Cloud Shell, jalankan:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
Temukan IP endpoint AlloyDB Omni menggunakan kubectl di Cloud Shell:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Catat PRIMARYENDPOINT.
Berikut contoh output-nya:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33 adalah IP yang akan kita gunakan dalam contoh untuk terhubung ke instance AlloyDB Omni.
Hubungkan ke VM menggunakan gcloud:
gcloud compute ssh instance-1 --zone=$ZONE
Jika diminta untuk membuat kunci SSH, ikuti petunjuknya. Baca selengkapnya tentang koneksi SSH dalam dokumentasi.
Di sesi SSH ke VM, instal klien PostgreSQL:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Ekspor variabel IP load balancer AlloyDB Omni menggunakan contoh berikut (ganti IP dengan IP load balancer Anda):
export INSTANCE_IP=10.131.0.33
Hubungkan ke AlloyDB Omni, sandinya adalah VeryStrongPassword seperti yang ditetapkan melalui hash di my-omni.yaml:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Dalam sesi psql yang sudah dibuat, jalankan:
create database demo;
Keluar dari sesi dan hubungkan ke demo database (atau Anda cukup menjalankan \c demo dalam sesi yang sama)
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Membuat fungsi transformasi
Untuk model penyematan pihak ketiga, kita perlu membuat fungsi transformasi yang memformat input dan output ke format yang diharapkan oleh model dan fungsi internal kita. Fungsi tersebut berfungsi sebagai penerjemah untuk melakukan konversi format antar-antarmuka yang berbeda.
Berikut adalah fungsi transformasi yang menangani input:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
Jalankan kode yang diberikan saat terhubung ke database demo seperti yang ditunjukkan dalam output contoh:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
Berikut adalah fungsi output yang mengubah respons dari model menjadi array bilangan riil:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
Jalankan di sesi yang sama:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
Mendaftarkan model
Sekarang kita dapat mendaftarkan model di database.
Berikut adalah panggilan prosedur untuk mendaftarkan model dengan nama embeddinggemma. Kita menggunakan nama layanan tei-service dalam parameter model_request_url saat mendaftarkan model. Itu adalah nama layanan cluster kubernetes internal dan diterjemahkan ke IP internal di cluster GKE:
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
Jalankan kode yang diberikan saat terhubung ke database demo:
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
Kita dapat menguji model register menggunakan kueri pengujian berikut yang akan menampilkan array angka riil.
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
Jangan kaget dengan penundaan yang lama sebelum mendapatkan kembali data vektor. Untuk pengujian ini, kita menggunakan node pool berbasis CPU untuk menghosting model embedding dan model ini bekerja jauh lebih cepat di node dengan GPU.
7. Menguji Model di AlloyDB Omni
Memuat Data
Untuk menguji cara AlloyDB Omni kami bekerja dengan model yang di-deploy, kita perlu memuat beberapa data. Saya menggunakan data yang sama seperti di salah satu codelab lainnya untuk penelusuran vektor di AlloyDB.
Salah satu cara untuk memuat data adalah dengan menggunakan Google Cloud SDK dan software klien PostgreSQL. Kita dapat menggunakan VM klien yang sama. Google Cloud SDK seharusnya sudah terinstal di sana jika Anda menggunakan setelan default untuk image VM. Namun, jika Anda telah menggunakan gambar kustom tanpa Google SDK, Anda dapat menambahkannya dengan mengikuti dokumentasi.
Ekspor IP load balancer AlloyDB Omni seperti dalam contoh berikut (ganti IP dengan IP load balancer Anda):
export INSTANCE_IP=10.131.0.33
Hubungkan ke database dan aktifkan ekstensi pgvector.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Di sesi psql:
CREATE EXTENSION IF NOT EXISTS vector;
Keluar dari sesi psql dan di sesi command line, jalankan perintah untuk memuat data ke database demo.
Buat tabel. Perintah berikut akan mendapatkan file cymbal_demo_schema.sql dan menjalankan SQL dengan semua definisi tabel dalam database demo:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
Output konsol yang diharapkan:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
Berikut adalah daftar tabel yang dibuat:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Output:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
Memuat data ke tabel cymbal_products:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
Output konsol yang diharapkan:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
Berikut adalah contoh beberapa baris dari tabel cymbal_products.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Output:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
Memuat data ke tabel cymbal_inventory:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
Output konsol yang diharapkan:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
Berikut adalah contoh beberapa baris dari tabel cymbal_inventory.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Output:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
Memuat data ke tabel cymbal_stores:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
Output konsol yang diharapkan:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
Berikut adalah contoh beberapa baris dari tabel cymbal_stores.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Output:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
Membangun Embedding
Hubungkan ke database demo menggunakan psql dan buat embedding untuk produk yang dijelaskan dalam tabel cymbal_products berdasarkan deskripsi produk.
Hubungkan ke database demo:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Kita menggunakan tabel cymbal_embedding dengan embedding kolom untuk menyimpan embedding dan menggunakan deskripsi produk sebagai input teks ke fungsi.
Aktifkan pengaturan waktu untuk kueri Anda guna membandingkan nanti dengan model jarak jauh.:
\timing
Jalankan kueri untuk membuat embedding:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
Output konsol yang diharapkan:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
Dalam contoh ini, pembuatan sematan memerlukan waktu sekitar 8 menit. Hal ini diharapkan untuk node pool berbasis CPU. Untuk pool dengan akselerator GPU, prosesnya bisa jauh lebih cepat, bergantung pada jenis GPU.
Menjalankan Kueri Pengujian
Hubungkan ke database demo menggunakan psql dan aktifkan pengaturan waktu untuk mengukur waktu eksekusi kueri seperti yang kita lakukan untuk membuat sematan.
Mari kita temukan 5 produk teratas yang cocok dengan permintaan seperti "Apa jenis pohon buah yang tumbuh dengan baik di sini?" menggunakan jarak kosinus sebagai algoritma untuk penelusuran vektor.
Dalam sesi psql, jalankan:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Output konsol yang diharapkan:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
Kueri berjalan selama 83 md dan menampilkan daftar pohon dari tabel cymbal_products yang cocok dengan permintaan dan dengan inventaris yang tersedia di toko dengan nomor 1583.
Membangun Indeks ANN
Jika hanya memiliki set data kecil, Anda dapat dengan mudah menggunakan penelusuran persis yang memindai semua sematan, tetapi jika data bertambah, waktu pemuatan dan respons juga akan meningkat. Untuk meningkatkan performa, Anda dapat membuat indeks pada data sematan. Berikut adalah contoh cara melakukannya menggunakan indeks ScaNN Google untuk data vektor.
Hubungkan kembali ke database demo jika koneksi Anda terputus:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Aktifkan ekstensi alloydb_scann:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Buat indeks:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
Coba kueri yang sama seperti sebelumnya dan bandingkan hasilnya:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
Waktu eksekusi kueri telah sedikit berkurang dan peningkatan ini akan lebih terlihat dengan set data yang lebih besar. Hasilnya cukup mirip dan kita mendapatkan 5 pohon teratas yang sama dalam hasilnya.
Coba kueri lain dan baca selengkapnya tentang memilih indeks vektor dalam dokumentasi.
Jangan lupa bahwa AlloyDB Omni memiliki lebih banyak fitur dan lab.
8. Membersihkan lingkungan
Sekarang kita dapat menghapus cluster GKE dengan AlloyDB Omni dan model AI
Menghapus Cluster GKE
Di Cloud Shell, jalankan:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
Output konsol yang diharapkan:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
Menghapus VM
Di Cloud Shell, jalankan:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Output konsol yang diharapkan:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
Jika Anda membuat project baru untuk codelab ini, Anda dapat menghapus seluruh project: https://console.cloud.google.com/cloud-resource-manager
9. Selamat
Selamat, Anda telah menyelesaikan codelab.
Yang telah kita bahas
- Cara men-deploy AlloyDB Omni di cluster Google Kubernetes
- Cara terhubung ke AlloyDB Omni
- Cara memuat data ke AlloyDB Omni
- Cara men-deploy model penyematan terbuka ke GKE
- Cara mendaftarkan model sematan di AlloyDB Omni
- Cara membuat embedding untuk penelusuran semantik
- Cara menggunakan embedding yang dihasilkan untuk penelusuran semantik di AlloyDB Omni
- Cara membuat dan menggunakan indeks vektor di AlloyDB
Anda dapat membaca selengkapnya tentang cara menggunakan AI di AlloyDB Omni dalam dokumentasi.
10. Survei
Output: