
1. Introduzione
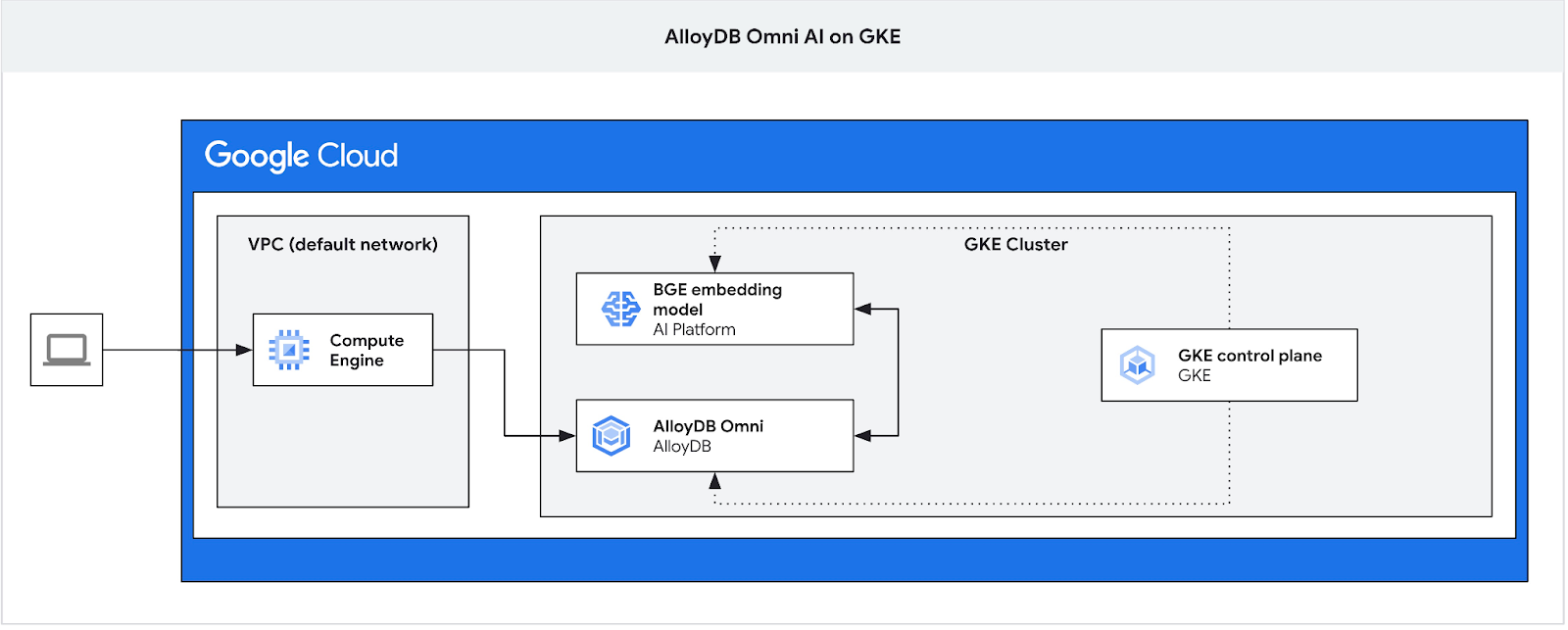
In questo codelab imparerai a eseguire il deployment di AlloyDB Omni su GKE e a utilizzarlo con un modello di embedding aperto di cui è stato eseguito il deployment nello stesso cluster Kubernetes. Il deployment di un modello accanto all'istanza del database nello stesso cluster GKE riduce la latenza e le dipendenze dai servizi di terze parti. Inoltre, potrebbe essere richiesto dai requisiti di sicurezza quando i dati non devono uscire dall'organizzazione e l'utilizzo di servizi di terze parti non è consentito.
Prerequisiti
- Una conoscenza di base di Google Cloud e della console
- Competenze di base nell'interfaccia a riga di comando e in Cloud Shell
Cosa imparerai a fare
- Come eseguire il deployment di AlloyDB Omni sul cluster Google Kubernetes
- Come connettersi ad AlloyDB Omni
- Come caricare dati in AlloyDB Omni
- Come eseguire il deployment di un modello di incorporamento aperto in GKE
- Come registrare il modello di incorporamento in AlloyDB Omni
- Come generare gli embedding per la ricerca semantica
- Come utilizzare gli embedding generati per la ricerca semantica in AlloyDB Omni
- Come creare e utilizzare gli indici vettoriali in AlloyDB
Che cosa ti serve
- Un account Google Cloud e un progetto Google Cloud
- Un browser web come Chrome che supporta la console Google Cloud e Cloud Shell
2. Configurazione e requisiti
Configurazione dell'ambiente autonomo
- Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.

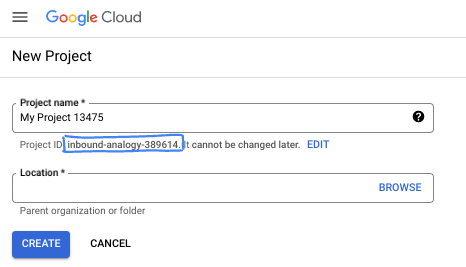
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi sempre aggiornarlo.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Cloud genera automaticamente una stringa univoca, di solito non ti interessa di cosa si tratta. Nella maggior parte dei codelab, dovrai fare riferimento all'ID progetto (in genere identificato come
PROJECT_ID). Se l'ID generato non ti piace, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e vedere se è disponibile. Non può essere modificato dopo questo passaggio e rimane per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
- Successivamente, devi abilitare la fatturazione in Cloud Console per utilizzare le risorse/API Cloud. Completare questo codelab non costa molto, se non nulla. Per arrestare le risorse ed evitare addebiti oltre a quelli previsti in questo tutorial, puoi eliminare le risorse che hai creato o il progetto. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:

Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Prima di iniziare
Abilita l'API
Output:
In Cloud Shell, assicurati che l'ID progetto sia configurato:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Se non è definito nel set di configurazione di Cloud Shell, configurarlo utilizzando i seguenti comandi
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Attiva tutti i servizi necessari:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
Output previsto:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Esegui il deployment di AlloyDB Omni su GKE
Per eseguire il deployment di AlloyDB Omni su GKE, dobbiamo preparare un cluster Kubernetes seguendo i requisiti elencati in Requisiti dell'operatore AlloyDB Omni.
Crea un cluster GKE
Dobbiamo eseguire il deployment di un cluster GKE standard con una configurazione del pool sufficiente per eseguire il deployment di un pod con l'istanza AlloyDB Omni. Per Omni sono necessari almeno 2 CPU e 8 GB di RAM, con un po' di spazio per i servizi di operatore e monitoraggio.
Configura le variabili di ambiente per il deployment.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
Poi utilizziamo gcloud per creare il cluster GKE Standard.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Output console previsto:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
Prepara il cluster
Dobbiamo installare i componenti richiesti, ad esempio il servizio cert-manager. Possiamo seguire i passaggi descritti nella documentazione per l'installazione di cert-manager.
Utilizziamo lo strumento a riga di comando Kubernetes, kubectl, già installato in Cloud Shell. Prima di utilizzare l'utilità, dobbiamo ottenere le credenziali per il nostro cluster.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
Ora possiamo utilizzare kubectl per installare cert-manager:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml
Output della console previsto(modificato):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
Installa AlloyDB Omni
L'operatore AlloyDB Omni può essere installato utilizzando l'utilità Helm.
Esegui il seguente comando per installare l'operatore AlloyDB Omni:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
Output della console previsto(modificato):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
Una volta installato l'operatore AlloyDB Omni, possiamo procedere con il deployment del nostro cluster di database.
Ecco un esempio di manifest di deployment con il parametro googleMLExtension abilitato e il bilanciatore del carico interno (privato):
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
Il valore del secret per la password è una rappresentazione Base64 della parola "VeryStrongPassword". Il modo più affidabile è utilizzare Google Secret Manager per archiviare il valore della password. Per saperne di più, consulta la documentazione.
Salva il manifest come my-omni.yaml da applicare nel passaggio successivo. Se ti trovi in Cloud Shell, puoi farlo utilizzando l'editor premendo il pulsante "Apri editor" in alto a destra del terminale.
Dopo aver salvato il file con il nome my-omni.yaml, torna al terminale premendo il pulsante "Apri terminale".
Applica il manifest my-omni.yaml al cluster utilizzando l'utilità kubectl:
kubectl apply -f my-omni.yaml
Output console previsto:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
Controlla lo stato del cluster my-omni utilizzando l'utilità kubectl:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Durante il deployment, il cluster attraversa diverse fasi e alla fine dovrebbe terminare con lo stato DBClusterReady.
Output console previsto:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
Connettersi ad AlloyDB Omni
Connessione tramite pod Kubernetes
Quando il cluster è pronto, possiamo utilizzare i file binari del client PostgreSQL nel pod dell'istanza AlloyDB Omni. Troviamo l'ID pod e poi utilizziamo kubectl per connetterci direttamente al pod ed eseguire il software client. La password è VeryStrongPassword come impostato tramite l'hash in my-omni.yaml:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Esempio di output della console:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. Esegui il deployment del modello di AI su GKE
Per testare l'integrazione dell'AI di AlloyDB Omni con i modelli locali, dobbiamo eseguire il deployment di un modello nel cluster.
Crea un pool di nodi per il modello
Per eseguire il modello, dobbiamo preparare un node pool per eseguire l'inferenza. L'approccio migliore dal punto di vista delle prestazioni è un pool con acceleratori grafici che utilizza una configurazione dei nodi come g2-standard-8 con acceleratore Nvidia L4.
Crea il node pool con l'acceleratore L4:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create gpupool \
--accelerator type=nvidia-l4,count=1,gpu-driver-version=latest \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=g2-standard-8 \
--num-nodes=1
Output previsto:
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create gpupool \
> --accelerator type=nvidia-l4,count=1,gpu-driver-version=latest \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=g2-standard-8 \
> --num-nodes=1
Note: Machines with GPUs have certain limitations which may affect your workflow. Learn more at https://cloud.google.com/kubernetes-engine/docs/how-to/gpus
Note: Starting in GKE 1.30.1-gke.115600, if you don't specify a driver version, GKE installs the default GPU driver for your node's GKE version.
Creating node pool gpupool...done.
Created [https://container.googleapis.com/v1/projects/student-test-001/zones/us-central1/clusters/alloydb-ai-gke/nodePools/gpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
gpupool g2-standard-8 100 1.31.4-gke.1183000
Prepara il manifest di deployment
Per eseguire il deployment del modello, dobbiamo preparare un manifest di deployment.
Utilizziamo il modello di embedding BGE Base v1.5 di Hugging Face. Puoi leggere la scheda del modello qui. Per eseguire il deployment del modello, possiamo utilizzare le istruzioni già preparate da Hugging Face e il pacchetto di deployment da GitHub.
Clona il pacchetto
git clone https://github.com/huggingface/Google-Cloud-Containers
Modifica il manifest sostituendo il valore cloud.google.com/gke-accelerator con nvidia-l4 e aggiungendo limiti alle risorse.
vi Google-Cloud-Containers/examples/gke/tei-deployment/gpu-config/deployment.yaml
Ecco un manifest corretto.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Snowflake--snowflake-arctic-embed-m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cu122.1-4.ubuntu2204:latest
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
env:
- name: MODEL_ID
value: Snowflake/snowflake-arctic-embed-m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
volumeMounts:
- mountPath: /dev/shm
name: dshm
- mountPath: /data
name: data
volumes:
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 1Gi
- name: data
emptyDir: {}
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
Esegui il deployment del modello
Dobbiamo preparare un service account e uno spazio dei nomi per il deployment.
Crea uno spazio dei nomi Kubernetes hf-gke-namespace.
export NAMESPACE=hf-gke-namespace
kubectl create namespace $NAMESPACE
Crea un service account Kubernetes
export SERVICE_ACCOUNT=hf-gke-service-account
kubectl create serviceaccount $SERVICE_ACCOUNT --namespace $NAMESPACE
Esegui il deployment del modello
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/gpu-config
Verifica i deployment
kubectl get pods
Verificare il servizio del modello
kubectl get service tei-service
Dovrebbe mostrare il tipo di servizio in esecuzione ClusterIP
Esempio di output:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
L'indirizzo CLUSTER-IP per il servizio è quello che utilizzeremo come indirizzo endpoint. L'incorporamento del modello può rispondere tramite l'URI http://34.118.233.48:8080/embed. Verrà utilizzato in un secondo momento quando registrerai il modello in AlloyDB Omni.
Possiamo testarlo esponendolo utilizzando il comando kubectl port-forward.
kubectl port-forward service/tei-service 8080:8080
Il port forwarding verrà eseguito in una sessione di Cloud Shell e abbiamo bisogno di un'altra sessione per testarlo.
Apri un'altra scheda di Cloud Shell utilizzando il segno "+" in alto.
ed esegui un comando curl nella nuova sessione della shell.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
Dovrebbe restituire un array di vettori come nell'output di esempio seguente (oscurato):
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
6. Registra il modello in AlloyDB Omni
Per testare il funzionamento di AlloyDB Omni con il modello di cui è stato eseguito il deployment, dobbiamo creare un database e registrare il modello.
Crea database
Crea una VM GCE come jump box, connettiti ad AlloyDB Omni dalla VM client e crea un database.
Abbiamo bisogno della jump box perché il bilanciatore del carico esterno GKE per Omni ti consente di accedere da VPC utilizzando l'indirizzamento IP privato, ma non ti consente di connetterti dall'esterno di VPC. È più sicuro in generale e non espone l'istanza del database a internet. Controlla il diagramma per maggiore chiarezza.
Per creare una VM nella sessione Cloud Shell, esegui:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
Trova l'IP dell'endpoint AlloyDB Omni utilizzando kubectl in Cloud Shell:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Annota PRIMARYENDPOINT. Ecco un esempio.
output:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33 è l'IP che utilizzeremo nei nostri esempi per connetterci all'istanza AlloyDB Omni.
Connettiti alla VM utilizzando gcloud:
gcloud compute ssh instance-1 --zone=$ZONE
Se ti viene chiesto di generare una chiave SSH, segui le istruzioni. Scopri di più sulla connessione SSH nella documentazione.
Nella sessione SSH alla VM, installa il client PostgreSQL:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Esporta l'IP del bilanciatore del carico AlloyDB Omni come nell'esempio seguente (sostituisci IP con l'IP del bilanciatore del carico):
export INSTANCE_IP=10.131.0.33
Connettiti ad AlloyDB Omni, la password è VeryStrongPassword come impostato tramite l'hash in my-omni.yaml:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Nella sessione psql stabilita, esegui:
create database demo;
Esci dalla sessione e connettiti alla demo del database (oppure puoi semplicemente eseguire "\c demo" nella stessa sessione)
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Creare funzioni di trasformazione
Per i modelli di embedding di terze parti, dobbiamo creare funzioni di trasformazione che formattino l'input e l'output nel formato previsto dal modello e dalle nostre funzioni interne.
Ecco la funzione di trasformazione che gestisce l'input:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
Esegui il codice fornito mentre sei connesso al database demo come mostrato nell'output di esempio:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
Ecco la funzione di output che trasforma la risposta del modello nell'array di numeri reali:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
Esegui nella stessa sessione:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
Registra il modello
Ora possiamo registrare il modello nel database.
Ecco la chiamata di procedura per registrare il modello con il nome bge-base-1.5, sostituisci l'IP 34.118.233.48 con l'indirizzo IP del servizio del modello (l'output di kubectl get service tei-service):
CALL
google_ml.create_model(
model_id => 'bge-base-1.5',
model_request_url => 'http://34.118.233.48:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
Esegui il codice fornito mentre sei connesso al database demo:
demo=# CALL
google_ml.create_model(
model_id => 'bge-base-1.5',
model_request_url => 'http://34.118.233.48:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
Possiamo testare il modello di registro utilizzando la seguente query di test, che dovrebbe restituire un array di numeri reali.
select google_ml.embedding('bge-base-1.5','What is AlloyDB Omni?');
7. Testare il modello in AlloyDB Omni
Carica dati
Per testare il funzionamento di AlloyDB Omni con il modello di cui è stato eseguito il deployment, dobbiamo caricare alcuni dati. Ho utilizzato gli stessi dati di una delle altre codelab per la ricerca vettoriale in AlloyDB.
Un modo per caricare i dati è utilizzare Google Cloud SDK e il software client PostgreSQL. Possiamo utilizzare la stessa VM client utilizzata per creare il database demo. Se hai utilizzato le impostazioni predefinite per l'immagine VM, Google Cloud SDK dovrebbe essere già installato. Se invece hai utilizzato un'immagine personalizzata senza Google SDK, puoi aggiungerla seguendo la documentazione.
Esporta l'IP del bilanciatore del carico AlloyDB Omni come nell'esempio seguente (sostituisci IP con l'IP del bilanciatore del carico):
export INSTANCE_IP=10.131.0.33
Connettiti al database e abilita l'estensione pgvector.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Nella sessione psql:
CREATE EXTENSION IF NOT EXISTS vector;
Esci dalla sessione psql ed esegui i comandi nella sessione della riga di comando per caricare i dati nel database demo.
Crea le tabelle:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
Output console previsto:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
Ecco l'elenco delle tabelle create:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Output:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
Carica i dati nella tabella cymbal_products:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
Output console previsto:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
Ecco un esempio di alcune righe della tabella cymbal_products.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Output:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
Carica i dati nella tabella cymbal_inventory:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
Output console previsto:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
Ecco un esempio di alcune righe della tabella cymbal_inventory.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Output:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
Carica i dati nella tabella cymbal_stores:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
Output console previsto:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
Ecco un esempio di alcune righe della tabella cymbal_stores
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Output:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
Build Embeddings
Connettiti al database demo utilizzando psql e crea embedding per i prodotti descritti nella tabella cymbal_products in base ai nomi e alle descrizioni dei prodotti.
Connettiti al database demo:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Utilizziamo una tabella cymbal_embedding con l'incorporamento delle colonne per archiviare gli incorporamenti e utilizziamo la descrizione del prodotto come input di testo per la funzione.
Attiva la misurazione dei tempi per le query per confrontarle in un secondo momento con i modelli remoti:
\timing
Esegui la query per creare gli incorporamenti:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('bge-base-1.5',product_description)::vector FROM cymbal_products;
Output console previsto:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('bge-base-1.5',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 11069.762 ms (00:11.070)
demo=#
In questo esempio, la creazione di incorporamenti per 941 record ha richiesto circa 11 secondi.
Esegui query di test
Connettiti al database demo utilizzando psql e attiva la misurazione del tempo per misurare il tempo di esecuzione delle query, come abbiamo fatto per la creazione degli incorporamenti.
Troviamo i primi 5 prodotti che corrispondono a una richiesta come "Quali tipi di alberi da frutto crescono bene qui?" utilizzando la distanza del coseno come algoritmo per la ricerca di vettori.
Nella sessione psql esegui:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('bge-base-1.5','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Output console previsto:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('bge-base-1.5','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.22753925487632942
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.23497374266229387
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.24215884459965364
California Redwood | This is a beautiful redwood tree that can grow to be over 300 feet tall. It is a | 1000.00 | 93230 | 0.24564130578287147
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.24846117929767153
(5 rows)
Time: 28.724 ms
demo=#
La query è stata eseguita in 28 ms e ha restituito un elenco di alberi dalla tabella cymbal_products corrispondenti alla richiesta e con inventario disponibile nel negozio con numero 1583.
Crea indice ANN
Quando abbiamo solo un piccolo set di dati, è facile utilizzare la ricerca esatta per eseguire la scansione di tutti gli incorporamenti, ma quando i dati aumentano, aumentano anche il tempo di caricamento e di risposta. Per migliorare le prestazioni, puoi creare indici sui dati di incorporamento. Ecco un esempio di come farlo utilizzando l'indice Google ScaNN per i dati vettoriali.
Riconnettiti al database demo se hai perso la connessione:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Abilita l'estensione alloydb_scann:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Crea l'indice:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
Prova la stessa query di prima e confronta i risultati:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('bge-base-1.5','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.22753925487632942
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.23497374266229387
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.24215884459965364
California Redwood | This is a beautiful redwood tree that can grow to be over 300 feet tall. It is a | 1000.00 | 93230 | 0.24564130578287147
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.2533482837690365
(5 rows)
Time: 14.665 ms
demo=#
Il tempo di esecuzione della query è leggermente diminuito e questo miglioramento sarebbe più evidente con set di dati più grandi. I risultati sono piuttosto simili e solo la ciliegia è stata sostituita dal pioppo Fremont.
Prova altre query e scopri di più sulla scelta dell'indice vettoriale nella documentazione.
Inoltre, non dimenticare che AlloyDB Omni ha più funzionalità e lab.
8. Pulizia dell'ambiente
Ora possiamo eliminare il cluster GKE con AlloyDB Omni e un modello di AI
Elimina cluster GKE
In Cloud Shell, esegui:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
Output console previsto:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
Elimina VM
In Cloud Shell, esegui:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Output console previsto:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
Se hai creato un nuovo progetto per questo codelab, puoi invece eliminare l'intero progetto: https://console.cloud.google.com/cloud-resource-manager
9. Complimenti
Congratulazioni per aver completato il codelab.
Argomenti trattati
- Come eseguire il deployment di AlloyDB Omni sul cluster Google Kubernetes
- Come connettersi ad AlloyDB Omni
- Come caricare dati in AlloyDB Omni
- Come eseguire il deployment di un modello di incorporamento aperto in GKE
- Come registrare il modello di incorporamento in AlloyDB Omni
- Come generare gli embedding per la ricerca semantica
- Come utilizzare gli embedding generati per la ricerca semantica in AlloyDB Omni
- Come creare e utilizzare gli indici vettoriali in AlloyDB
Per saperne di più sull'utilizzo dell'AI in AlloyDB Omni, consulta la documentazione.
10. Sondaggio
Output: