
1. Introdução
Neste codelab, você vai aprender a implantar o AlloyDB Omni no GKE e usá-lo com um modelo de incorporação aberto implantado no mesmo cluster do Kubernetes. A implantação de um modelo ao lado da instância de banco de dados no mesmo cluster do GKE reduz a latência e as dependências de serviços de terceiros. Além disso, a implantação local pode ser um requisito estabelecido pela segurança e conformidade quando os dados não podem sair da organização e o uso de serviços de terceiros não é permitido.
Pré-requisitos
- Conhecimentos básicos sobre o Google Cloud e o console
- Conhecimento básico do Kubernetes e do GKE
- Habilidades básicas na interface de linha de comando e no Cloud Shell
O que você vai aprender
- Como implantar o AlloyDB Omni em um cluster do Google Kubernetes
- Como se conectar ao AlloyDB Omni
- Como carregar dados no AlloyDB Omni
- Como implantar um modelo de incorporação aberta no GKE
- Como registrar um modelo de incorporação no AlloyDB Omni
- Como gerar embeddings para pesquisa semântica
- Como usar embeddings gerados para pesquisa semântica no AlloyDB Omni
- Como criar e usar índices vetoriais no AlloyDB
O que é necessário
- Uma conta e um projeto do Google Cloud
- Um navegador da Web, como o Chrome, que seja compatível com o console do Google Cloud e o Cloud Shell
2. Configuração e requisitos
Configuração do projeto
- Faça login no Console do Google Cloud. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.
Use uma conta pessoal em vez de uma conta escolar ou de trabalho.
- Crie um novo projeto ou reutilize um existente. Para criar um projeto no console do Google Cloud, clique no botão "Selecionar um projeto" no cabeçalho, que vai abrir uma janela pop-up.

Na janela "Selecionar um projeto", clique no botão "Novo projeto", que vai abrir uma caixa de diálogo para o novo projeto.
Na caixa de diálogo, coloque o nome do projeto de sua preferência e escolha o local.
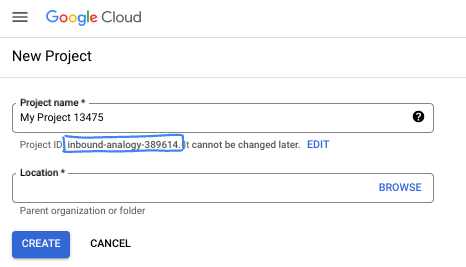
- O Nome do projeto é o nome de exibição para os participantes do projeto. O nome do projeto não é usado pelas APIs do Google e pode ser alterado a qualquer momento.
- O ID do projeto é exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Google Cloud gera automaticamente um ID exclusivo, mas você pode personalizar. Se você não gostar do ID gerado, crie outro aleatório ou forneça o seu para verificar a disponibilidade. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, que normalmente é identificado com o marcador de posição PROJECT_ID.
- Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
Ativar faturamento
Configurar uma conta de faturamento pessoal
Se você configurou o faturamento usando créditos do Google Cloud, pule esta etapa.
Para configurar uma conta de faturamento pessoal, acesse este link e ative o faturamento no console do Cloud.
Algumas observações:
- A conclusão deste laboratório custa menos de US $3 em recursos do Cloud.
- Siga as etapas no final deste laboratório para excluir recursos e evitar mais cobranças.
- Novos usuários podem aproveitar o teste sem custos financeiros de US$300.
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
Ou pressione G e S. Essa sequência vai ativar o Cloud Shell se você estiver no console do Google Cloud ou usar este link.
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
3. Antes de começar
Ativar API
Saída:
Para usar o Google Kubernetes Engine (GKE) com o AlloyDB Omni e implantações de modelos abertos, ative as APIs respectivas no projeto do Google Cloud.
No Cloud Shell, verifique se o ID do projeto está configurado:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Se não estiver definido na configuração do Cloud Shell, configure usando os seguintes comandos:
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Ative todos os serviços necessários:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
Resultado esperado
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Apresentação das APIs
- A API Kubernetes Engine (
container.googleapis.com) permite criar e gerenciar clusters do Google Kubernetes Engine (GKE). Ele oferece um ambiente gerenciado para implantação, gerenciamento e escalonamento de aplicativos conteinerizados usando a infraestrutura do Google. - A API Compute Engine (
compute.googleapis.com) permite criar e gerenciar máquinas virtuais (VMs), discos permanentes e configurações de rede. Ela fornece a base principal de infraestrutura como serviço (IaaS) necessária para executar suas cargas de trabalho e hospedar a infraestrutura subjacente de muitos serviços gerenciados.
4. Implantar o AlloyDB Omni no GKE
Para implantar o AlloyDB Omni no GKE, é necessário preparar um cluster do Kubernetes seguindo os requisitos listados em Requisitos do operador do AlloyDB Omni.
Criar um cluster do GKE
Precisamos implantar um cluster padrão do GKE com uma configuração de pool suficiente para implantar um pod com uma instância do AlloyDB Omni. Para o AlloyDB Omni, precisamos de pelo menos 2 CPUs e 8 GB de RAM, além de espaço para contêineres de serviços de operador e monitoramento. Vamos usar o tipo de VM e2-standard-4.
Configure as variáveis de ambiente para sua implantação.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
Em seguida, usamos o gcloud para criar o cluster padrão do GKE.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Saída esperada do console:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
Preparar o cluster
Precisamos instalar componentes necessários, como o serviço cert-manager, um gerenciador de certificados nativo para Kubernetes. Podemos seguir as etapas na documentação para instalação do cert-manager.
Usamos a ferramenta de linha de comando do Kubernetes, kubectl, que já está instalada no Cloud Shell por padrão. Antes de usar o utilitário, precisamos receber as credenciais do cluster.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
Agora podemos usar o kubectl para instalar o cert-manager:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
Saída esperada do console (editada):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
Instalar o AlloyDB Omni
O operador do AlloyDB Omni pode ser instalado usando o utilitário helm.
Execute o comando a seguir para instalar o operador do AlloyDB Omni:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
Saída esperada do console (editada):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
Quando o operador do AlloyDB Omni estiver instalado, podemos continuar com a implantação do cluster de banco de dados.
Confira um exemplo de manifesto de implantação com o parâmetro googleMLExtension ativado e um balanceador de carga interno (privado):
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
O valor secreto da senha é uma representação Base64 da palavra "VeryStrongPassword". A maneira mais confiável é usar o gerenciador de secrets do Google para armazenar o valor da senha. Leia mais sobre isso na documentação.
Salve o manifesto como my-omni.yaml para ser aplicado na próxima etapa. Se você estiver no Cloud Shell, use o editor clicando no botão "Abrir editor" no canto superior direito do terminal.
Depois de salvar o arquivo com o nome my-omni.yaml, volte ao terminal pressionando o botão "Abrir terminal".
Aplique o manifesto my-omni.yaml ao cluster usando o utilitário kubectl:
kubectl apply -f my-omni.yaml
Saída esperada do console:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
Verifique o status do cluster my-omni usando o utilitário kubectl:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Durante a implantação, o cluster passa por diferentes fases e, por fim, termina com o estado DBClusterReady.
Saída esperada do console:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
Conectar-se ao AlloyDB Omni
Conectar usando um pod do Kubernetes
Quando o cluster estiver pronto, poderemos usar os binários do cliente PostgreSQL no pod da instância do AlloyDB Omni. Encontramos o ID do pod e usamos o kubectl para nos conectar diretamente a ele e executar o software cliente. A senha é VeryStrongPassword, conforme definido pelo secret do Kubernetes no manifesto my-omni.yaml:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Exemplo de saída do console:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. Implantar um modelo de IA no GKE
Para testar a integração de IA do AlloyDB Omni com modelos locais, precisamos implantar um modelo no cluster. Vamos usar o modelo EmbeddingGemma do Google.
Criar um pool de nós para o modelo
Para executar o modelo, precisamos preparar um pool de nós para executar a inferência. Podemos executar usando um pool somente de CPU ou um pool com aceleradores de GPU. A abordagem somente de CPU pode ser mais viável em algumas regiões devido à alta simultaneidade dos recursos. No laboratório, vamos usar a abordagem de CPU, mas a melhor abordagem do ponto de vista do desempenho é um pool com aceleradores gráficos usando uma configuração de nó como g2-standard-8 com acelerador L4 Nvidia.
Pool de nós baseado em CPU
Crie um pool de nós com nós e2-standard-32. Vamos limitar o pull a um nó para economizar recursos.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
Resultado esperado
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
Receber token do Hugging Face
Neste laboratório, usamos uma parceria com o Hugging Face para implantar o modelo EmbeddingGemma. Para isso, precisamos de um token do Hugging Face.
Siga as etapas abaixo para gerar um novo token, caso ainda não tenha um:
- Faça login ou inscreva-se no site do Hugging Face usando os links "Fazer login" ou "Inscrever-se" no canto superior direito.
- Clique em "Seu perfil" -> "Tokens de acesso".
- Confirmar sua identidade
- Clique em "Criar novo token".
- Escolha um nome para seu token
- Selecione uma função para o token. Você precisa ter pelo menos o privilégio de leitura.
- Clique em "Criar token" na parte de baixo da página.
- Copie o token gerado e salve para uso posterior.
Você também precisa aceitar as condições para acessar arquivos e conteúdo relacionados ao EmbeddingGemma no Hugging Face na página https://huggingface.co/google/embeddinggemma-300m.
Crie um secret do Kubernetes usando o token
Na sessão do Cloud Shell, execute (substitua o valor de HF_TOKEN pelo seu token da HF).
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
Preparar o manifesto de implantação
Para implantar o modelo, precisamos preparar um manifesto de implantação.
Estamos usando o modelo EmbeddingGemma do Google no Hugging Face. Leia o card do modelo aqui. Para implantar o modelo, vamos usar uma abordagem baseada nas instruções do Hugging Face e no pacote de implantação do GitHub.
Clonar o pacote do GitHub
git clone https://github.com/huggingface/Google-Cloud-Containers
Ajuste o manifesto para tei (interface de incorporação de texto) em nós da CPU. Precisamos substituir vários parâmetros, incluindo o modelo, a imagem, a alocação correta de recursos, e adicionar o segredo do token do Hugging Face à configuração.
Edite o manifesto usando qualquer editor disponível.
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
Confira um manifesto corrigido para implantação em um pool baseado em CPU.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
Implantar o modelo
Implante o modelo aplicando o manifesto modificado para implantações de CPU.
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
Verificar as implantações
kubectl get pods
Verificar o serviço de modelo
kubectl get service tei-service
Ele deve mostrar o tipo de serviço em execução ClusterIP.
Exemplo de resposta:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
O CLUSTER-IP do serviço é o que vamos usar como endereço de endpoint. A incorporação do modelo pode responder pelo URI http://34.118.233.48:8080/embed. Ele será usado mais tarde, quando você registrar o modelo no AlloyDB Omni.
Podemos testar isso expondo o serviço usando o comando kubectl port-forward.
kubectl port-forward service/tei-service 8080:8080
Se você estiver usando o Cloud Shell, o encaminhamento de porta poderá estar em execução em uma sessão do Cloud Shell, e precisaremos de outra sessão para testá-lo.
Abra outra guia do Cloud Shell pelo sinal "+" na parte superior.
e execute um comando curl na nova sessão do shell.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
Ele vai retornar uma matriz de vetores como no exemplo de saída a seguir (ocultado):
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
Se virmos os números, poderemos confirmar que testamos o modelo com sucesso e agora podemos registrá-lo no AlloyDB Omni para ser usado diretamente do SQL.
6. Registrar o modelo no AlloyDB Omni
Para testar como o AlloyDB Omni funciona com o modelo implantado, precisamos criar um banco de dados e registrar o modelo.
Criar banco de dados
Crie uma VM do GCE como uma jump box para se conectar ao AlloyDB Omni na VM do cliente e criar um banco de dados.
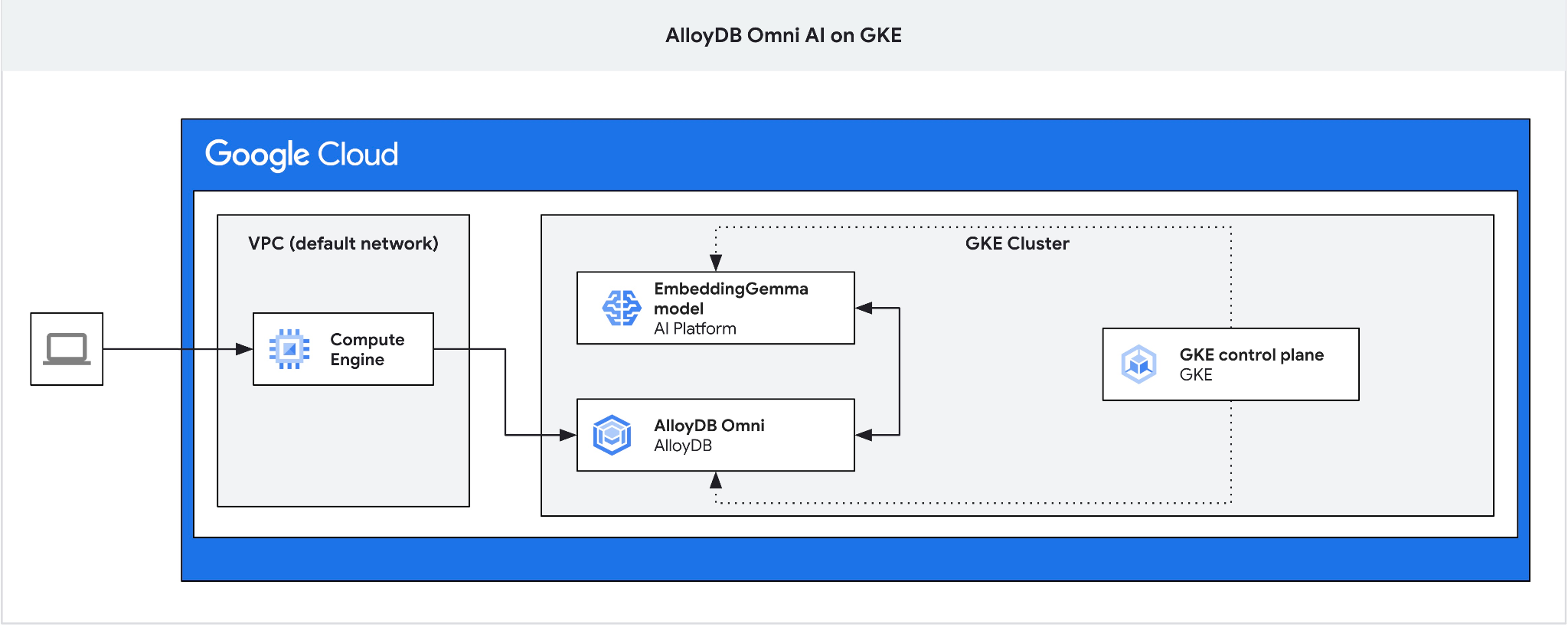
Precisamos da jump box porque o balanceador de carga externo do GKE para o Omni permite o acesso da VPC usando endereçamento IP privado, mas não permite a conexão de fora da VPC. Ele é mais seguro em geral e não expõe sua instância de banco de dados à Internet. Confira o diagrama para mais detalhes.
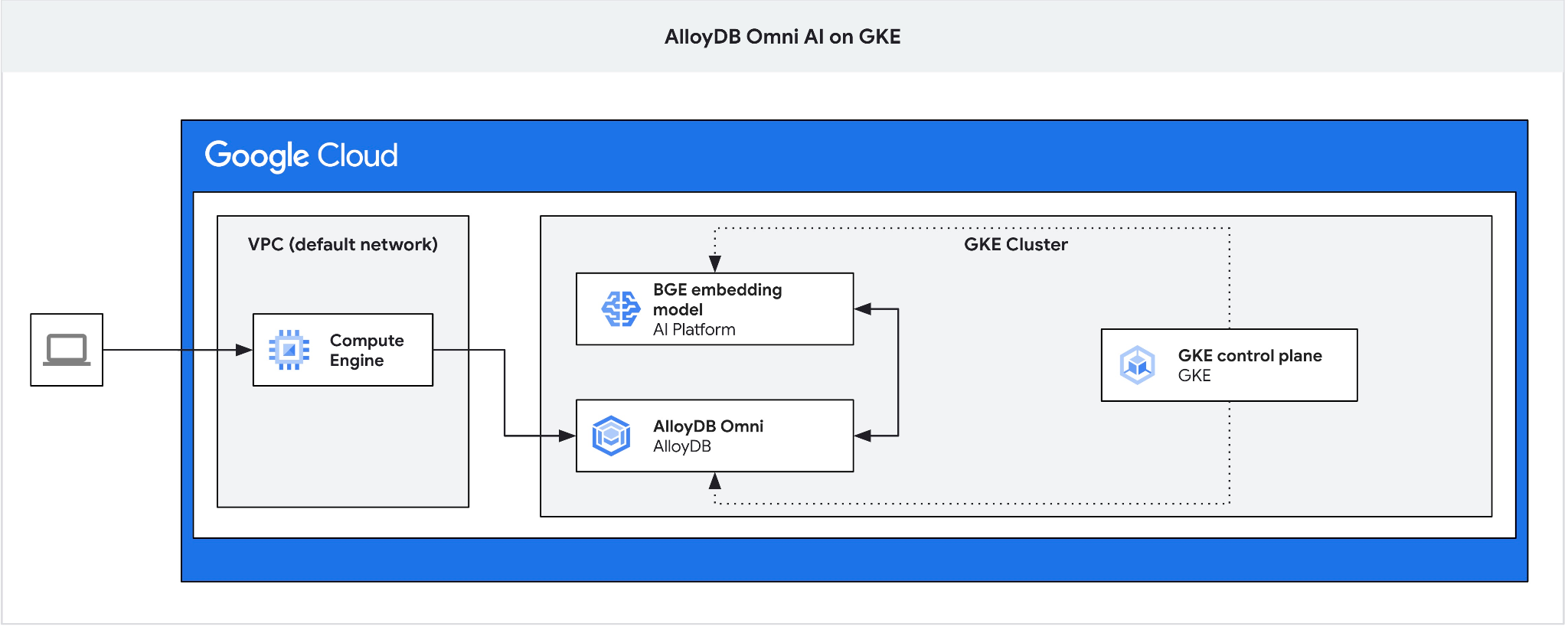
Para criar uma VM na sessão do Cloud Shell, execute:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
Encontre o IP do endpoint do AlloyDB Omni usando kubectl no Cloud Shell:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Anote o PRIMARYENDPOINT.
Este um exemplo de saída:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
O 10.131.0.33 é o IP que vamos usar nos nossos exemplos para nos conectar à instância do AlloyDB Omni.
Conecte-se à VM usando o gcloud:
gcloud compute ssh instance-1 --zone=$ZONE
Se for solicitada a geração de chaves SSH, siga as instruções. Leia mais sobre a conexão SSH na documentação.
Na sessão SSH da VM, instale o cliente PostgreSQL:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Exporte a variável de IP do balanceador de carga do AlloyDB Omni usando o exemplo a seguir (substitua IP pelo IP do seu balanceador de carga):
export INSTANCE_IP=10.131.0.33
Conecte-se ao AlloyDB Omni. A senha é VeryStrongPassword, conforme definido pelo hash em my-omni.yaml:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Na sessão psql estabelecida, execute:
create database demo;
Saia da sessão e conecte-se à demonstração do banco de dados ou execute \c demo na mesma sessão.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Criar funções de transformação
Para modelos de embedding de terceiros, precisamos criar funções de transformação que formatam a entrada e a saída para o formato esperado pelo modelo e pelas nossas funções internas. Essas funções atuam como tradutores para fazer a conversão de formato entre diferentes interfaces.
Esta é a função de transformação que processa a entrada:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
Execute o código fornecido enquanto estiver conectado ao banco de dados de demonstração, conforme mostrado na saída de exemplo:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
E aqui está a função de saída que transforma a resposta do modelo na matriz de números reais:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
Execute na mesma sessão:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
Registrar o modelo
Agora podemos registrar o modelo no banco de dados.
Confira a chamada de procedimento para registrar o modelo com o nome embeddinggemma. Usamos o nome do serviço tei-service no parâmetro model_request_url ao registrar o modelo. Esse é o nome do serviço interno do cluster do Kubernetes e é traduzido para o IP interno no cluster do GKE:
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
Execute o código fornecido enquanto estiver conectado ao banco de dados de demonstração:
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
Podemos testar o modelo de registro usando a seguinte consulta de teste, que deve retornar uma matriz de números reais.
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
Não se surpreenda com a demora para receber os dados de volta. Para este teste, usamos um pool de nós baseado em CPU para hospedar o modelo de embedding, que funciona muito mais rápido em nós com GPU.
7. Testar o modelo no AlloyDB Omni
Carregar dados
Para testar como o AlloyDB Omni funciona com o modelo implantado, precisamos carregar alguns dados. Usei os mesmos dados de um dos outros codelabs para pesquisa de vetores no AlloyDB.
Uma maneira de carregar os dados é usar o SDK do Google Cloud e o software cliente do PostgreSQL. Podemos usar a mesma VM do cliente. O SDK do Google Cloud já vai estar instalado se você tiver usado os padrões para a imagem da VM. Mas se você usou uma imagem personalizada sem o SDK do Google, siga a documentação para adicioná-la.
Exporte o IP do balanceador de carga do AlloyDB Omni, como no exemplo a seguir (substitua IP pelo IP do seu balanceador de carga):
export INSTANCE_IP=10.131.0.33
Conecte-se ao banco de dados e ative a extensão pgvector.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Na sessão psql:
CREATE EXTENSION IF NOT EXISTS vector;
Saia da sessão psql e, na sessão da linha de comando, execute comandos para carregar os dados no banco de dados de demonstração.
Crie as tabelas. O comando a seguir vai extrair o arquivo cymbal_demo_schema.sql e executar o SQL com todas as definições de tabelas no banco de dados de demonstração:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
Saída esperada do console:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
Esta é a lista de tabelas criadas:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Saída:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
Carregue dados na tabela cymbal_products:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
Saída esperada do console:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
Confira uma amostra de algumas linhas da tabela cymbal_products.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Saída:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
Carregue dados na tabela cymbal_inventory:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
Saída esperada do console:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
Confira uma amostra de algumas linhas da tabela cymbal_inventory.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Saída:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
Carregue dados na tabela cymbal_stores:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
Saída esperada do console:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
Confira uma amostra de algumas linhas da tabela cymbal_stores.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Saída:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
Criar embeddings
Conecte-se ao banco de dados de demonstração usando psql e crie embeddings para os produtos descritos na tabela "cymbal_products" com base nas descrições dos produtos.
Conecte-se ao banco de dados de demonstração:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Estamos usando uma tabela "cymbal_embedding" com embedding de coluna para armazenar nossos embeddings e usamos a descrição do produto como entrada de texto para a função.
Ative a geração de registros de tempo para suas consultas e compare depois com modelos remotos:
\timing
Execute a consulta para criar os embeddings:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
Saída esperada do console:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
Neste exemplo, a criação de incorporações levou cerca de 8 minutos. Isso é esperado para um pool de nós baseado em CPU. Para um pool com aceleradores de GPU, pode ser significativamente mais rápido, dependendo do tipo de GPU.
Executar consultas de teste
Conecte-se ao banco de dados de demonstração usando psql e ative a medição de tempo para medir o tempo de execução das consultas, como fizemos para criar incorporações.
Vamos encontrar os cinco principais produtos que correspondem a uma solicitação como "Que tipo de árvores frutíferas crescem bem aqui?" usando a distância de cosseno como o algoritmo para pesquisa vetorial.
Na sessão psql, execute:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Saída esperada do console:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
A consulta foi executada em 83 ms e retornou uma lista de árvores da tabela "cymbal_products" que correspondiam à solicitação e tinham inventário disponível na loja com o número 1583.
Criar índice ANN
Quando temos apenas um pequeno conjunto de dados, é fácil usar a pesquisa exata para verificar todos os embeddings. No entanto, quando os dados aumentam, o tempo de carregamento e resposta também aumenta. Para melhorar a performance, crie índices nos seus dados de incorporação. Confira um exemplo de como fazer isso usando o índice ScaNN do Google para dados de vetor.
Reconecte-se ao banco de dados de demonstração se você perdeu a conexão:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Ative a extensão alloydb_scann:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Crie o índice:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
Tente a mesma consulta de antes e compare os resultados:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
O tempo de execução da consulta foi ligeiramente reduzido, e esse ganho seria mais perceptível com conjuntos de dados maiores. Os resultados são bem parecidos, e as cinco árvores principais são as mesmas.
Tente outras consultas e leia mais sobre como escolher o índice de vetor na documentação.
E não se esqueça de que o AlloyDB Omni tem mais recursos e laboratórios.
8. Limpar o ambiente
Agora podemos excluir nosso cluster do GKE com o AlloyDB Omni e um modelo de IA.
Excluir cluster do GKE
No Cloud Shell, execute:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
Saída esperada do console:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
Excluir VM
No Cloud Shell, execute:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Saída esperada do console:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
Se você criou um novo projeto para este codelab, exclua o projeto completo: https://console.cloud.google.com/cloud-resource-manager
9. Parabéns
Parabéns por concluir o codelab.
O que vimos
- Como implantar o AlloyDB Omni em um cluster do Google Kubernetes
- Como se conectar ao AlloyDB Omni
- Como carregar dados no AlloyDB Omni
- Como implantar um modelo de incorporação aberta no GKE
- Como registrar um modelo de incorporação no AlloyDB Omni
- Como gerar embeddings para pesquisa semântica
- Como usar embeddings gerados para pesquisa semântica no AlloyDB Omni
- Como criar e usar índices vetoriais no AlloyDB
Leia mais sobre como trabalhar com IA no AlloyDB Omni na documentação.
10. Pesquisa
Saída: