
1. مقدمة
في هذا الدرس التطبيقي حول الترميز، ستتعلّم كيفية تفعيل AlloyDB Omni على GKE واستخدامه مع نموذج تضمينات مفتوح تم تفعيله في مجموعة Kubernetes نفسها. يؤدي نشر نموذج بجانب مثيل قاعدة البيانات في مجموعة GKE نفسها إلى تقليل وقت الاستجابة والاعتماد على خدمات الجهات الخارجية. بالإضافة إلى ذلك، قد يكون النشر المحلي شرطًا تحدده إجراءات الأمان والامتثال عندما لا يُسمح بمغادرة البيانات للمؤسسة ولا يُسمح باستخدام خدمات تابعة لجهات خارجية.
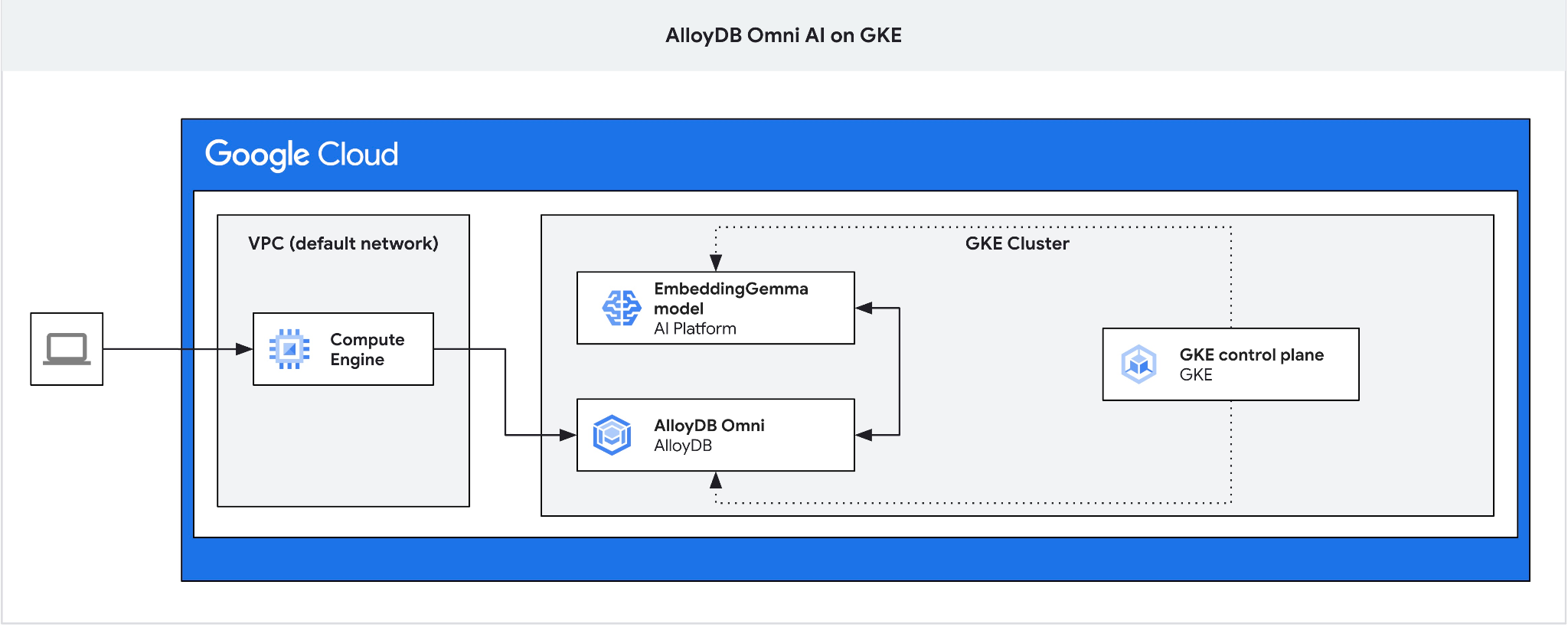
المتطلبات الأساسية
- فهم أساسي لـ Google Cloud وGoogle Cloud Console
- معرفة أساسية بمنصة Kubernetes وخدمة GKE
- مهارات أساسية في واجهة سطر الأوامر وCloud Shell
ما ستتعلمه
- كيفية نشر AlloyDB Omni على مجموعة Google Kubernetes
- كيفية الاتصال بـ AlloyDB Omni
- كيفية تحميل البيانات إلى AlloyDB Omni
- كيفية نشر نموذج تضمين مفتوح المصدر على GKE
- كيفية تسجيل نموذج التضمين في AlloyDB Omni
- كيفية إنشاء تضمينات للبحث الدلالي
- كيفية استخدام التضمينات التي تم إنشاؤها للبحث الدلالي في AlloyDB Omni
- كيفية إنشاء فهارس متّجهة واستخدامها في AlloyDB
المتطلبات
- حساب Google Cloud ومشروع Google Cloud
- متصفّح ويب، مثل Chrome، متوافق مع "وحدة تحكّم Google Cloud" وCloud Shell
2. الإعداد والمتطلبات
إعداد المشروع
- سجِّل الدخول إلى Google Cloud Console. إذا لم يكن لديك حساب على Gmail أو Google Workspace، عليك إنشاء حساب.
استخدام حساب شخصي بدلاً من حساب تديره المؤسسة التعليمية أو حساب تابع للعمل.
- أنشئ مشروعًا جديدًا أو أعِد استخدام مشروع حالي. لإنشاء مشروع جديد في Google Cloud Console، انقر على الزر "اختيار مشروع" في العنوان، ما سيؤدي إلى فتح نافذة منبثقة.

في نافذة "اختيار مشروع"، انقر على الزر "مشروع جديد" الذي سيفتح مربع حوار للمشروع الجديد.
في مربّع الحوار، أدخِل اسم المشروع المفضّل لديك واختَر الموقع الجغرافي.
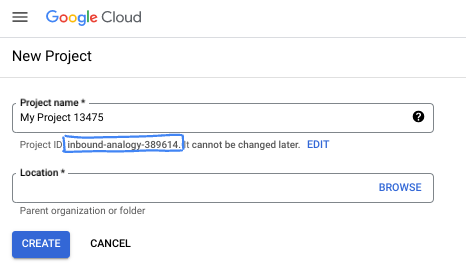
- اسم المشروع هو الاسم المعروض للمشاركين في هذا المشروع. لا تستخدم Google APIs اسم المشروع، ويمكن تغييره في أي وقت.
- رقم تعريف المشروع فريد في جميع مشاريع Google Cloud ولا يمكن تغييره (لا يمكن تغييره بعد ضبطه). تنشئ وحدة تحكّم Google Cloud تلقائيًا معرّفًا فريدًا، ولكن يمكنك تخصيصه. إذا لم يعجبك المعرّف الذي تم إنشاؤه، يمكنك إنشاء معرّف عشوائي آخر أو تقديم معرّفك الخاص للتحقّق من توفّره. في معظم دروس البرمجة، عليك الرجوع إلى رقم تعريف مشروعك، والذي يتم تحديده عادةً باستخدام العنصر النائب PROJECT_ID.
- للعلم، هناك قيمة ثالثة، وهي رقم المشروع، تستخدمها بعض واجهات برمجة التطبيقات. يمكنك الاطّلاع على مزيد من المعلومات عن كل هذه القيم الثلاث في المستندات.
تفعيل الفوترة
إعداد حساب فوترة شخصي
إذا أعددت الفوترة باستخدام أرصدة Google Cloud، يمكنك تخطّي هذه الخطوة.
لإعداد حساب فوترة شخصي، انتقِل إلى هنا لتفعيل الفوترة في Cloud Console.
ملاحظات:
- يجب أن تبلغ تكلفة إكمال هذا المختبر أقل من 3 دولارات أمريكية من موارد السحابة الإلكترونية.
- يمكنك اتّباع الخطوات في نهاية هذا المختبر لحذف الموارد وتجنُّب المزيد من الرسوم.
- يمكن للمستخدمين الجدد الاستفادة من فترة تجريبية مجانية بقيمة 300 دولار أمريكي.
بدء Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا الدرس العملي Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
من Google Cloud Console، انقر على رمز Cloud Shell في شريط الأدوات أعلى يسار الصفحة:
يمكنك بدلاً من ذلك الضغط على G ثم S. سيؤدي هذا التسلسل إلى تفعيل Cloud Shell إذا كنت تستخدم Google Cloud Console أو هذا الرابط.
لن يستغرق توفير البيئة والاتصال بها سوى بضع لحظات. عند الانتهاء، من المفترض أن يظهر لك ما يلي:

يتم تحميل هذه الآلة الافتراضية مزوّدة بكل أدوات التطوير التي ستحتاج إليها. توفّر هذه الخدمة دليلًا منزليًا ثابتًا بسعة 5 غيغابايت، وتعمل على Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إكمال جميع المهام في هذا الدرس العملي ضمن المتصفّح. لست بحاجة إلى تثبيت أي تطبيق.
3- قبل البدء
تفعيل واجهة برمجة التطبيقات
إخراج:
لاستخدام Google Kubernetes Engine (GKE) مع AlloyDB Omni وعمليات نشر النماذج المفتوحة، عليك تفعيل واجهات برمجة التطبيقات الخاصة بها في مشروعك على Google Cloud.
داخل Cloud Shell، تأكَّد من إعداد رقم تعريف مشروعك:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
إذا لم يتم تحديدها في مجموعة إعدادات Cloud Shell، يمكنك إعدادها باستخدام الأوامر التالية
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
فعِّل جميع الخدمات اللازمة:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
الناتج المتوقّع
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
لمحة عن واجهات برمجة التطبيقات
- تتيح لك Kubernetes Engine API (
container.googleapis.com) إنشاء مجموعات Google Kubernetes Engine (GKE) وإدارتها. توفّر هذه الخدمة بيئة مُدارة لنشر تطبيقاتك المحفوظة في حاويات وإدارتها وتوسيع نطاقها باستخدام البنية الأساسية من Google. - تتيح لك واجهة برمجة التطبيقات Compute Engine (
compute.googleapis.com) إنشاء الأجهزة الافتراضية والأقراص الثابتة وإعدادات الشبكة وإدارتها. توفّر هذه المنطقة الأساس المطلوب لتشغيل أحجام العمل واستضافة البنية التحتية الأساسية للعديد من الخدمات المُدارة.
4. نشر AlloyDB Omni على GKE
لنشر AlloyDB Omni على GKE، علينا إعداد مجموعة Kubernetes باتّباع المتطلبات الواردة في متطلبات مشغّل AlloyDB Omni.
إنشاء مجموعة GKE
علينا نشر مجموعة GKE عادية مع إعدادات مجمّعة كافية لنشر وحدة مع مثيل AlloyDB Omni. بالنسبة إلى AlloyDB Omni، نحتاج إلى وحدتَي معالجة مركزية (CPU) وذاكرة وصول عشوائي (RAM) بسعة 8 غيغابايت على الأقل، بالإضافة إلى بعض المساحة لحاويات خدمات المشغّل والمراقبة. سنستخدم نوع الجهاز الافتراضي e2-standard-4.
اضبط متغيّرات البيئة لعملية النشر.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
بعد ذلك، نستخدم gcloud لإنشاء مجموعة GKE العادية.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
إعداد المجموعة
علينا تثبيت المكوّنات المطلوبة، مثل خدمة cert-manager، وهي أداة إدارة الشهادات الأصلية في Kubernetes. يمكننا اتّباع الخطوات الواردة في المستندات الخاصة بتثبيت cert-manager.
نستخدم أداة سطر الأوامر Kubernetes، وهي kubectl، المثبَّتة تلقائيًا في Cloud Shell. قبل استخدام الأداة، علينا الحصول على بيانات اعتماد للمجموعة.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
يمكننا الآن استخدام kubectl لتثبيت cert-manager:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
الناتج المتوقّع في وحدة التحكّم(تم إخفاء بعض المعلومات):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
تثبيت AlloyDB Omni
يمكن تثبيت مشغّل AlloyDB Omni باستخدام أداة Helm.
نفِّذ الأمر التالي لتثبيت مشغّل AlloyDB Omni:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
الناتج المتوقّع في وحدة التحكّم(تم إخفاء بعض المعلومات):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
بعد تثبيت مشغّل AlloyDB Omni، يمكننا متابعة عملية نشر مجموعة قواعد البيانات.
في ما يلي مثال على بيان النشر مع تفعيل المَعلمة googleMLExtension وجهاز موازنة الحمل الداخلي (الخاص):
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
قيمة المفتاح السرّي لكلمة المرور هي تمثيل Base64 لكلمة المرور "VeryStrongPassword". الطريقة الأكثر موثوقية هي استخدام "مدير الأسرار" من Google لتخزين قيمة كلمة المرور. يمكنك الاطّلاع على مزيد من المعلومات حول هذا الموضوع في المستندات.
احفظ ملف البيان باسم my-omni.yaml ليتم تطبيقه في الخطوة التالية. إذا كنت تستخدم Cloud Shell، يمكنك إجراء ذلك باستخدام المحرّر من خلال النقر على الزر "فتح المحرّر" في أعلى يسار الجهاز الطرفي.
بعد حفظ الملف بالاسم my-omni.yaml، ارجع إلى الوحدة الطرفية من خلال النقر على الزر "فتح الوحدة الطرفية".
طبِّق ملف البيان my-omni.yaml على المجموعة باستخدام أداة kubectl:
kubectl apply -f my-omni.yaml
الناتج المتوقّع في وحدة التحكّم:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
تحقَّق من حالة مجموعة my-omni باستخدام أداة kubectl:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
أثناء عملية النشر، تمرّ المجموعة بمراحل مختلفة، ويجب أن تنتهي في النهاية بالحالة DBClusterReady.
الناتج المتوقّع في وحدة التحكّم:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
الاتصال بـ AlloyDB Omni
الاتصال باستخدام حزمة Kubernetes
عندما تكون المجموعة جاهزة، يمكننا استخدام ثنائيات عميل PostgreSQL على وحدة AlloyDB Omni. نعثر على معرّف الحزمة ثم نستخدم kubectl للاتصال مباشرةً بالحزمة وتشغيل برنامج العميل. كلمة المرور هي VeryStrongPassword كما تم ضبطها من خلال kubernetes secret في ملف my-omni.yaml:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
مثال على الناتج في وحدة التحكّم:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5- نشر نموذج الذكاء الاصطناعي على GKE
لاختبار دمج AlloyDB Omni AI مع النماذج المحلية، علينا نشر نموذج في المجموعة. سنستخدم نموذج EmbeddingGemma من Google.
إنشاء مجموعة عقدة للنموذج
لتشغيل النموذج، علينا إعداد مجموعة أجهزة ذات التخصيص نفسه لتشغيل الاستدلال. يمكننا تشغيلها باستخدام مجموعة تتضمّن وحدات معالجة مركزية فقط أو مجموعة تتضمّن مسرّعات وحدة معالجة الرسومات. قد يكون استخدام وحدة المعالجة المركزية فقط أكثر جدوى في بعض المناطق بسبب التزامن العالي للموارد. في مختبرنا، سنستخدم طريقة وحدة المعالجة المركزية، ولكنّ الطريقة الأفضل من ناحية الأداء هي مجموعة تتضمّن أدوات تسريع الرسومات باستخدام إعدادات عقدة مثل g2-standard-8 مع أداة تسريع L4 Nvidia.
مجموعة أجهزة ذات التخصيص نفسه المستندة إلى وحدة المعالجة المركزية
أنشئ مجموعة أجهزة ذات التخصيص نفسه تحتوي على 32 عقدة من فئة e2-standard. سنحصُر عملية السحب على عقدة واحدة لتوفير الموارد.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
الناتج المتوقّع
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
الحصول على رمز مميز من Hugging Face
في هذا المختبر، نستخدم شراكة مع Hugging Face لنشر نموذج EmbeddingGemma، ولإجراء ذلك، علينا الحصول على رمز مميّز من Hugging Face.
اتّبِع الخطوات التالية لإنشاء رمز جديد إذا لم يسبق لك الحصول على رمز.
- سجِّل الدخول أو اشترك في موقع Hugging Face الإلكتروني باستخدام رابطَي "تسجيل الدخول" أو "الاشتراك" في أعلى يسار الصفحة.
- انقر على "ملفك الشخصي" (Your Profile) -> "رموز الدخول" (Access Tokens).
- تأكيد هويتك
- انقر على "إنشاء رمز مميّز جديد"
- اختيار اسم للرمز المميّز
- اختَر دورًا للرمز المميّز - يجب أن يكون لديك إذن مميّز "القراءة" على الأقل
- انقر على "إنشاء رمز مميز" في أسفل الصفحة.
- انسخ الرمز المميز الذي تم إنشاؤه واحفظه لاستخدامه لاحقًا
عليك أيضًا الموافقة على الشروط للوصول إلى الملفات والمحتوى المرتبطَين بـ EmbeddingGemma على Hugging Face في الصفحة https://huggingface.co/google/embeddinggemma-300m
إنشاء سر kubernetes باستخدام الرمز المميّز
في جلسة Cloud Shell، نفِّذ الأمر التالي (استبدِل قيمة HF_TOKEN برمز HF المميّز).
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
إعداد بيان النشر
لنشر النموذج، علينا إعداد بيان النشر.
نحن نستخدم نموذج EmbeddingGemma من Google من Hugging Face. يمكنك الاطّلاع على بطاقة نموذج هنا. لنشر النموذج، سنستخدم طريقة تستند إلى التعليمات من Hugging Face وحزمة النشر من GitHub.
استنساخ الحزمة من GitHub
git clone https://github.com/huggingface/Google-Cloud-Containers
تعديل ملف البيان لواجهة تضمين النص (tei) على عُقد وحدة المعالجة المركزية علينا استبدال عدة مَعلمات، بما في ذلك النموذج والصورة وتخصيص الموارد بشكل صحيح، وإضافة سر رمز Hugging Face إلى الإعدادات.
تعديل ملف البيان (باستخدام أي محرر متاح)
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
في ما يلي ملف بيان معدَّل للنشر في مجموعة مستندة إلى وحدة معالجة مركزية.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
تفعيل النموذج
فعِّل النموذج من خلال تطبيق البيان المعدَّل على عمليات التفعيل على وحدات المعالجة المركزية.
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
التحقّق من عمليات النشر
kubectl get pods
التحقّق من خدمة النموذج
kubectl get service tei-service
من المفترض أن يعرض نوع الخدمة قيد التشغيل ClusterIP
مثال على الناتج:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
إنّ CLUSTER-IP للخدمة هو ما سنستخدمه كعنوان نقطة نهاية. يمكن أن يستجيب تضمين النموذج لعنوان URI http://34.118.233.48:8080/embed. سيتم استخدامها لاحقًا عند تسجيل النموذج في AlloyDB Omni.
يمكننا اختبارها من خلال عرضها باستخدام الأمر kubectl port-forward.
kubectl port-forward service/tei-service 8080:8080
إذا كنت تستخدم Cloud Shell، يمكن تشغيل إعادة توجيه المنفذ في إحدى جلسات Cloud Shell، ونحتاج إلى جلسة أخرى لاختبارها.
افتح علامة تبويب أخرى في Cloud Shell باستخدام الرمز "+" في أعلى الصفحة.
ونفِّذ أمر curl في جلسة وحدة التحكّم الجديدة.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
من المفترَض أن يتم عرض مصفوفة متّجهة كما في نموذج الإخراج التالي (تم إخفاء بعض المعلومات):
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
إذا رأينا الأرقام، يمكننا التأكّد من أنّنا اختبرنا النموذج بنجاح ويمكننا الآن تسجيله في AlloyDB Omni لاستخدامه مباشرةً من SQL.
6. تسجيل النموذج في AlloyDB Omni
لاختبار طريقة عمل AlloyDB Omni مع النموذج الذي تم نشره، علينا إنشاء قاعدة بيانات وتسجيل النموذج.
إنشاء قاعدة بيانات
أنشئ جهازًا افتراضيًا على GCE كجهاز وسيط للاتصال بـ AlloyDB Omni من الجهاز الافتراضي للعميل، ثم أنشئ قاعدة بيانات.
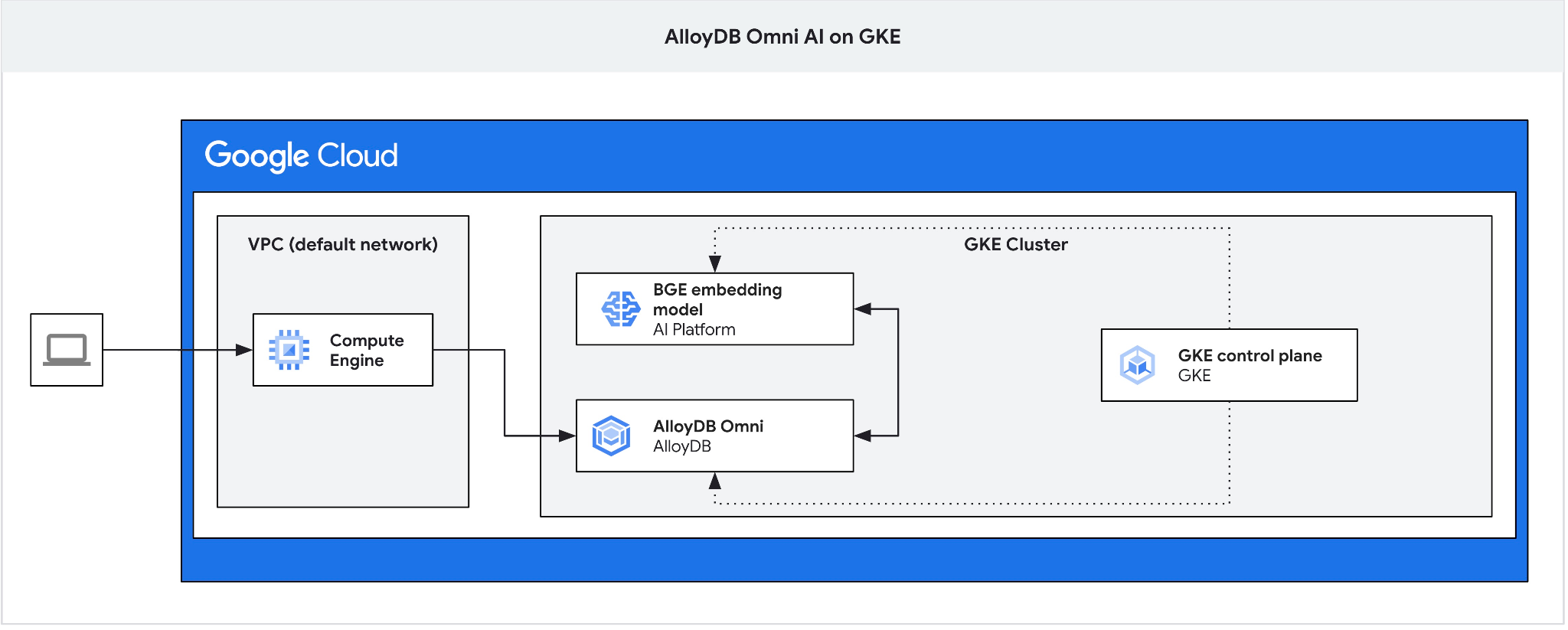
نحتاج إلى جهاز التوجيه السريع لأنّ موازن التحميل الخارجي في GKE لـ Omni يتيح لك الوصول من السحابة الإلكترونية الخاصة الافتراضية (VPC) باستخدام عناوين IP خاصة، ولكنّه لا يسمح لك بالاتصال من خارج السحابة الإلكترونية الخاصة الافتراضية (VPC). وهي أكثر أمانًا بشكل عام ولا تعرض مثيل قاعدة البيانات على الإنترنت. يُرجى الاطّلاع على الرسم التخطيطي للحصول على توضيح.
لإنشاء جهاز افتراضي في جلسة Cloud Shell، نفِّذ ما يلي:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
ابحث عن عنوان IP لنقطة نهاية AlloyDB Omni باستخدام kubectl في Cloud Shell:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
دوِّن قيمة PRIMARYENDPOINT.
في ما يلي مثال على الناتج:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33 هو عنوان IP الذي سنستخدمه في أمثلتنا للاتصال بمثيل AlloyDB Omni.
الاتصال بالجهاز الافتراضي باستخدام gcloud:
gcloud compute ssh instance-1 --zone=$ZONE
اتّبِع التعليمات إذا طُلب منك إنشاء مفتاح SSH. يمكنك الاطّلاع على مزيد من المعلومات عن اتصال SSH في المستندات.
في جلسة ssh الخاصة بالجهاز الافتراضي، ثبِّت عميل PostgreSQL:
sudo apt-get update
sudo apt-get install --yes postgresql-client
صدِّر متغيّر عنوان IP الخاص بموازنة الحمل في AlloyDB Omni باستخدام المثال التالي (استبدِل IP بعنوان IP الخاص بموازنة الحمل):
export INSTANCE_IP=10.131.0.33
اتّصِل بـ AlloyDB Omni، وكلمة المرور هي VeryStrongPassword كما تم ضبطها من خلال التجزئة في my-omni.yaml:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
في جلسة psql التي تم إنشاؤها، نفِّذ ما يلي:
create database demo;
اخرج من الجلسة واربطها بالإصدار التجريبي من قاعدة البيانات (أو يمكنك ببساطة تشغيل \c demo في الجلسة نفسها)
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
إنشاء دوال تحويل
بالنسبة إلى نماذج التضمين التابعة لجهات خارجية، علينا إنشاء دوال تحويل تعمل على تنسيق الإدخال والإخراج بالتنسيق الذي يتوقّعه النموذج ودوالنا الداخلية. تعمل هذه الدوال كمترجمات لإجراء تحويل التنسيق بين واجهات مختلفة.
في ما يلي دالة التحويل التي تعالج الإدخال:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
نفِّذ الرمز البرمجي المقدَّم أثناء الاتصال بقاعدة البيانات التجريبية كما هو موضّح في نموذج الإخراج:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
في ما يلي دالة الإخراج التي تحوّل الرد من النموذج إلى مصفوفة الأرقام الحقيقية:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
نفِّذها في الجلسة نفسها:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
تسجيل النموذج
يمكننا الآن تسجيل النموذج في قاعدة البيانات.
في ما يلي استدعاء الإجراء لتسجيل النموذج بالاسم embeddinggemma. نستخدم اسم خدمة tei-service في المَعلمة model_request_url عند تسجيل النموذج. هذا هو اسم خدمة مجموعة Kubernetes الداخلية ويتم تحويله إلى عنوان IP الداخلي في مجموعة GKE:
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
نفِّذ الرمز البرمجي المقدَّم أثناء الاتصال بقاعدة البيانات التجريبية:
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
يمكننا اختبار نموذج التسجيل باستخدام استعلام الاختبار التالي الذي من المفترض أن يعرض مصفوفة أرقام حقيقية.
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
لا تستغرب التأخير الطويل قبل استعادة بيانات المتجهات. بالنسبة إلى هذا الاختبار، نستخدم مجموعة عقد مستندة إلى وحدة المعالجة المركزية لاستضافة نموذج التضمين، ويعمل النموذج بشكل أسرع بكثير على العُقد التي تتضمّن وحدة معالجة الرسومات.
7. اختبار النموذج في AlloyDB Omni
تحميل البيانات
لاختبار طريقة عمل AlloyDB Omni مع النموذج الذي تم نشره، علينا تحميل بعض البيانات. استخدمتُ البيانات نفسها المستخدَمة في إحدى البرامج التعليمية الأخرى للبحث المتّجه في AlloyDB.
إحدى طرق تحميل البيانات هي استخدام Google Cloud SDK وبرنامج عميل PostgreSQL. يمكننا استخدام الجهاز الظاهري للعميل نفسه. من المفترض أن تكون حزمة تطوير البرامج (SDK) من Google Cloud مثبَّتة هناك إذا كنت قد استخدمت الإعدادات التلقائية لصورة الجهاز الافتراضي. ولكن إذا كنت قد استخدمت صورة مخصّصة بدون حزمة تطوير البرامج (SDK) من Google، يمكنك إضافتها باتّباع المستندات.
صدِّر عنوان IP الخاص بموازن الحمل في AlloyDB Omni كما في المثال التالي (استبدِل IP بعنوان IP الخاص بموازن الحمل):
export INSTANCE_IP=10.131.0.33
اربط بقاعدة البيانات وفعِّل إضافة pgvector.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
في جلسة psql:
CREATE EXTENSION IF NOT EXISTS vector;
اخرج من جلسة psql ونفِّذ الأوامر في جلسة سطر الأوامر لتحميل البيانات إلى قاعدة البيانات التجريبية.
أنشئ الجداول. سيؤدي الأمر التالي إلى الحصول على ملف cymbal_demo_schema.sql وتنفيذ SQL مع جميع تعريفات الجداول في قاعدة البيانات التجريبية:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
في ما يلي قائمة بالجداول التي تم إنشاؤها:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
إخراج:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
حمِّل البيانات إلى الجدول cymbal_products:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
في ما يلي عيّنة من بضعة صفوف من الجدول cymbal_products.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
إخراج:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
حمِّل البيانات إلى الجدول cymbal_inventory:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
في ما يلي عيّنة من بضعة صفوف من الجدول cymbal_inventory.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
إخراج:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
حمِّل البيانات إلى الجدول cymbal_stores:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
في ما يلي عيّنة من بضعة صفوف من الجدول cymbal_stores.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
إخراج:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
إنشاء عمليات التضمين
اربط بقاعدة البيانات التجريبية باستخدام psql وأنشئ تضمينات للمنتجات الموضّحة في جدول cymbal_products استنادًا إلى أوصاف المنتجات.
الربط بقاعدة البيانات التجريبية:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
نستخدم جدول cymbal_embedding مع تضمين الأعمدة لتخزين عمليات التضمين، ونستخدم وصف المنتج كمدخل نصي للدالة.
فعِّل ميزة "التوقيت" لطلبات البحث من أجل المقارنة لاحقًا مع النماذج البعيدة:
\timing
نفِّذ طلب البحث لإنشاء التضمينات:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
الناتج المتوقّع في وحدة التحكّم:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
في هذا المثال، استغرق إنشاء التضمينات حوالي 8 دقائق. وهذا متوقّع لمجموعة أجهزة ذات التخصيص نفسه المستندة إلى وحدة المعالجة المركزية. بالنسبة إلى مجموعة تتضمّن مسرّعات وحدة معالجة الرسومات، يمكن أن تكون أسرع بكثير استنادًا إلى نوع وحدة معالجة الرسومات.
تنفيذ طلبات بحث اختبارية
اتّصِل بقاعدة البيانات التجريبية باستخدام psql وفعِّل ميزة تحديد التوقيت لقياس وقت تنفيذ الاستعلامات كما فعلنا عند إنشاء التضمينات.
لنفترض أنّنا نريد العثور على أفضل 5 منتجات تتطابق مع طلب مثل "ما هي أنواع أشجار الفاكهة التي تنمو جيدًا هنا؟" باستخدام مسافة جيب التمام كخوارزمية للبحث المتّجه.
في جلسة psql، نفِّذ ما يلي:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
الناتج المتوقّع في وحدة التحكّم:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
تم تنفيذ طلب البحث في 83 ملي ثانية وعرض قائمة بالأشجار من جدول cymbal_products تطابق الطلب ويتوفّر منها مخزون في المتجر رقم 1583.
إنشاء فهرس ANN
عندما تكون لدينا مجموعة بيانات صغيرة فقط، يكون من السهل استخدام البحث المطابق من خلال فحص جميع التضمينات، ولكن عندما تزداد البيانات، يزداد أيضًا وقت التحميل والاستجابة. لتحسين الأداء، يمكنك إنشاء فهارس على بيانات التضمين. في ما يلي مثال على كيفية إجراء ذلك باستخدام فهرس ScaNN من Google لبيانات المتجهات.
أعِد الاتصال بقاعدة البيانات التجريبية إذا فقدت الاتصال:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
فعِّل إضافة alloydb_scann:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
إنشاء الفهرس:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
جرِّب الاستعلام نفسه كما كان من قبل وقارِن النتائج:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
انخفض وقت تنفيذ طلب البحث قليلاً، وسيكون هذا التحسّن أكثر وضوحًا مع مجموعات البيانات الأكبر. النتائج متشابهة إلى حدّ كبير، وحصلنا على نفس أفضل 5 أشجار في النتيجة.
جرِّب طلبات بحث أخرى واقرأ المزيد عن اختيار فهرس المتجهات في المستندات.
ولا تنسَ أنّ AlloyDB Omni تتضمّن المزيد من الميزات والتجارب.
8. إخلاء مساحة
يمكننا الآن حذف مجموعة GKE باستخدام AlloyDB Omni ونموذج الذكاء الاصطناعي.
حذف مجموعة GKE
في Cloud Shell، نفِّذ ما يلي:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
حذف رسالة البريد الصوتي
في Cloud Shell، نفِّذ ما يلي:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
إذا أنشأت مشروعًا جديدًا لهذا الدرس التطبيقي حول الترميز، يمكنك بدلاً من ذلك حذف المشروع بالكامل: https://console.cloud.google.com/cloud-resource-manager
9- تهانينا
تهانينا على إكمال هذا الدرس العملي.
المواضيع التي تناولناها
- كيفية نشر AlloyDB Omni على مجموعة Google Kubernetes
- كيفية الاتصال بـ AlloyDB Omni
- كيفية تحميل البيانات إلى AlloyDB Omni
- كيفية نشر نموذج تضمين مفتوح المصدر على GKE
- كيفية تسجيل نموذج التضمين في AlloyDB Omni
- كيفية إنشاء تضمينات للبحث الدلالي
- كيفية استخدام التضمينات التي تم إنشاؤها للبحث الدلالي في AlloyDB Omni
- كيفية إنشاء فهارس متّجهة واستخدامها في AlloyDB
يمكنك الاطّلاع على مزيد من المعلومات حول استخدام الذكاء الاصطناعي في AlloyDB Omni في المستندات.
10. استطلاع
إخراج: