
১. ভূমিকা
এই কোডল্যাবে আপনি শিখবেন কিভাবে GKE-তে AlloyDB Omni ডেপ্লয় করতে হয় এবং একই Kubernetes ক্লাস্টারে ডেপ্লয় করা একটি ওপেন এমবেডিং মডেলের সাথে এটি ব্যবহার করতে হয়। একই GKE ক্লাস্টারে ডাটাবেস ইনস্ট্যান্সের পাশে একটি মডেল ডেপ্লয় করলে ল্যাটেন্সি এবং থার্ড-পার্টি সার্ভিসের উপর নির্ভরতা কমে যায়। এছাড়াও, যখন ডেটা প্রতিষ্ঠানের বাইরে যাওয়া উচিত নয় এবং থার্ড-পার্টি সার্ভিসের ব্যবহার অনুমোদিত নয়, তখন নিরাপত্তা ও কমপ্লায়েন্সের কারণে লোকাল ডেপ্লয়মেন্ট একটি আবশ্যকতা হতে পারে।
পূর্বশর্ত
- গুগল ক্লাউড, কনসোল সম্পর্কে প্রাথমিক ধারণা
- Kubernetes এবং GKE সম্পর্কে প্রাথমিক জ্ঞান
- কমান্ড লাইন ইন্টারফেস এবং ক্লাউড শেলে প্রাথমিক দক্ষতা
আপনি যা শিখবেন
- গুগল কুবারনেটিস ক্লাস্টারে কীভাবে অ্যালয়ডিবি ওমনি স্থাপন করবেন
- AlloyDB Omni-এর সাথে কীভাবে সংযোগ করবেন
- AlloyDB Omni-তে কীভাবে ডেটা লোড করবেন
- GKE-তে কীভাবে একটি ওপেন এমবেডিং মডেল স্থাপন করবেন
- AlloyDB Omni-তে এমবেডিং মডেল কীভাবে রেজিস্টার করবেন
- সিমান্টিক সার্চের জন্য এমবেডিং কীভাবে তৈরি করবেন
- AlloyDB Omni-তে সিমান্টিক সার্চের জন্য জেনারেটেড এমবেডিং কীভাবে ব্যবহার করবেন
- AlloyDB-তে ভেক্টর ইনডেক্স কীভাবে তৈরি এবং ব্যবহার করবেন
আপনার যা যা লাগবে
- একটি গুগল ক্লাউড অ্যাকাউন্ট এবং গুগল ক্লাউড প্রজেক্ট
- ক্রোমের মতো একটি ওয়েব ব্রাউজার যা গুগল ক্লাউড কনসোল এবং ক্লাউড শেল সমর্থন করে।
২. সেটআপ এবং প্রয়োজনীয়তা
প্রজেক্ট সেটআপ
- Google Cloud Console- এ সাইন-ইন করুন। যদি আপনার আগে থেকে Gmail বা Google Workspace অ্যাকাউন্ট না থাকে, তবে আপনাকে একটি তৈরি করতে হবে।
কর্মক্ষেত্র বা শিক্ষা প্রতিষ্ঠানের অ্যাকাউন্টের পরিবর্তে ব্যক্তিগত অ্যাকাউন্ট ব্যবহার করুন।
- একটি নতুন প্রজেক্ট তৈরি করুন অথবা বিদ্যমান কোনো প্রজেক্ট পুনরায় ব্যবহার করুন। গুগল ক্লাউড কনসোলে একটি নতুন প্রজেক্ট তৈরি করতে, হেডারে থাকা 'Select a project' বোতামটিতে ক্লিক করুন, যা একটি পপ-আপ উইন্ডো খুলবে।

'Select a project' উইন্ডোতে 'New Project' বোতামটি চাপুন, যা নতুন প্রজেক্টের জন্য একটি ডায়ালগ বক্স খুলবে।
ডায়ালগ বক্সে আপনার পছন্দের প্রজেক্টের নাম দিন এবং অবস্থান নির্বাচন করুন।
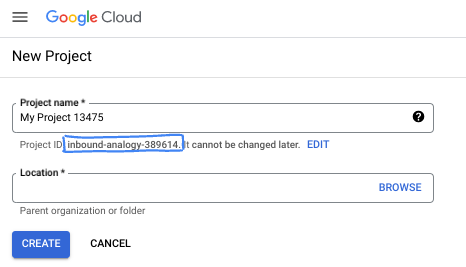
- প্রজেক্টের নামটি এই প্রকল্পের অংশগ্রহণকারীদের জন্য প্রদর্শিত নাম। প্রজেক্টের নামটি গুগল এপিআই দ্বারা ব্যবহৃত হয় না এবং এটি যেকোনো সময় পরিবর্তন করা যেতে পারে।
- প্রজেক্ট আইডি সমস্ত গুগল ক্লাউড প্রজেক্ট জুড়ে অনন্য এবং অপরিবর্তনীয় (একবার সেট করার পর এটি পরিবর্তন করা যায় না)। গুগল ক্লাউড কনসোল স্বয়ংক্রিয়ভাবে একটি অনন্য আইডি তৈরি করে, কিন্তু আপনি এটি কাস্টমাইজ করতে পারেন। তৈরি করা আইডিটি আপনার পছন্দ না হলে, আপনি এলোমেলোভাবে আরেকটি তৈরি করতে পারেন অথবা সেটির প্রাপ্যতা যাচাই করার জন্য আপনার নিজের আইডি দিতে পারেন। বেশিরভাগ কোডল্যাবে, আপনাকে আপনার প্রজেক্ট আইডি উল্লেখ করতে হবে, যা সাধারণত PROJECT_ID নামক প্লেসহোল্ডার দ্বারা চিহ্নিত করা হয়।
- আপনার অবগতির জন্য জানাচ্ছি যে, তৃতীয় একটি ভ্যালু রয়েছে, যা হলো প্রজেক্ট নম্বর , এবং কিছু এপিআই এটি ব্যবহার করে থাকে। ডকুমেন্টেশনে এই তিনটি ভ্যালু সম্পর্কে আরও বিস্তারিত জানুন।
বিলিং সক্ষম করুন
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করুন
আপনি যদি গুগল ক্লাউড ক্রেডিট ব্যবহার করে বিলিং সেট আপ করেন, তাহলে এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করতে, ক্লাউড কনসোলে বিলিং চালু করার জন্য এখানে যান ।
কিছু নোট:
- এই ল্যাবটি সম্পন্ন করতে ক্লাউড রিসোর্সে ৩ মার্কিন ডলারের কম খরচ হওয়া উচিত।
- পরবর্তী চার্জ এড়াতে, এই ল্যাবের শেষে দেওয়া ধাপগুলো অনুসরণ করে আপনি রিসোর্সগুলো মুছে ফেলতে পারেন।
- নতুন ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়ালের জন্য যোগ্য।
ক্লাউড শেল শুরু করুন
যদিও গুগল ক্লাউড আপনার ল্যাপটপ থেকে দূরবর্তীভাবে পরিচালনা করা যায়, এই কোডল্যাবে আপনি গুগল ক্লাউড শেল ব্যবহার করবেন, যা ক্লাউডে চালিত একটি কমান্ড লাইন পরিবেশ।
গুগল ক্লাউড কনসোল থেকে, উপরের ডানদিকের টুলবারে থাকা ক্লাউড শেল আইকনটিতে ক্লিক করুন:
বিকল্পভাবে আপনি প্রথমে G এবং তারপর S চাপতে পারেন। আপনি যদি গুগল ক্লাউড কনসোলের মধ্যে থাকেন, তাহলে এই ক্রমটি ক্লাউড শেল সক্রিয় করবে অথবা এই লিঙ্কটি ব্যবহার করুন।
পরিবেশটি প্রস্তুত করতে এবং এর সাথে সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগবে। এটি শেষ হলে, আপনি এইরকম কিছু দেখতে পাবেন:

এই ভার্চুয়াল মেশিনটিতে আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এই কোডল্যাবে আপনার সমস্ত কাজ একটি ব্রাউজারের মধ্যেই করা যাবে। আপনাকে কিছুই ইনস্টল করতে হবে না।
৩. শুরু করার আগে
এপিআই সক্ষম করুন
আউটপুট:
AlloyDB Omni এবং ওপেন মডেল ডেপ্লয়মেন্টের জন্য Google Kubernetes Engine (GKE) ব্যবহার করতে হলে, আপনার Google Cloud প্রজেক্টে সেগুলোর নিজ নিজ API সক্রিয় করতে হবে।
ক্লাউড শেলের ভিতরে, নিশ্চিত করুন যে আপনার প্রজেক্ট আইডি সেটআপ করা আছে:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
যদি এটি ক্লাউড শেল কনফিগারেশনে সংজ্ঞায়িত না থাকে, তাহলে নিম্নলিখিত কমান্ডগুলি ব্যবহার করে এটি সেট আপ করুন।
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
সকল প্রয়োজনীয় পরিষেবা সক্রিয় করুন:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
প্রত্যাশিত আউটপুট
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
এপিআইগুলো চালু করা হচ্ছে
- Kubernetes Engine API (
container.googleapis.com) আপনাকে Google Kubernetes Engine (GKE) ক্লাস্টার তৈরি এবং পরিচালনা করার সুযোগ দেয়। এটি গুগলের পরিকাঠামো ব্যবহার করে আপনার কন্টেইনারাইজড অ্যাপ্লিকেশনগুলো ডেপ্লয়, পরিচালনা এবং স্কেল করার জন্য একটি নিয়ন্ত্রিত পরিবেশ প্রদান করে। - কম্পিউট ইঞ্জিন এপিআই (
compute.googleapis.com) আপনাকে ভার্চুয়াল মেশিন (VM), পারসিস্টেন্ট ডিস্ক এবং নেটওয়ার্ক সেটিংস তৈরি ও পরিচালনা করার সুযোগ দেয়। এটি আপনার ওয়ার্কলোড চালানোর জন্য এবং অনেক পরিচালিত পরিষেবার অন্তর্নিহিত পরিকাঠামো হোস্ট করার জন্য প্রয়োজনীয় মূল ইনফ্রাস্ট্রাকচার-অ্যাজ-এ-সার্ভিস (IaaS) ভিত্তি প্রদান করে।
৪. GKE-তে AlloyDB Omni স্থাপন করুন
GKE-তে AlloyDB Omni স্থাপন করার জন্য, আমাদের AlloyDB Omni অপারেটরের প্রয়োজনীয়তা (AloyDB Omni operator requirements) -তে তালিকাভুক্ত শর্তাবলী অনুসরণ করে একটি Kubernetes ক্লাস্টার প্রস্তুত করতে হবে।
একটি GKE ক্লাস্টার তৈরি করুন
আমাদের একটি স্ট্যান্ডার্ড GKE ক্লাস্টার স্থাপন করতে হবে, যার পুল কনফিগারেশনটি AlloyDB Omni ইনস্ট্যান্স সহ একটি পড স্থাপনের জন্য যথেষ্ট হবে। AlloyDB Omni-এর জন্য আমাদের কমপক্ষে ২টি সিপিইউ এবং ৮ জিবি র্যাম প্রয়োজন, এবং অপারেটর ও মনিটরিং সার্ভিসেস কন্টেইনারগুলোর জন্য কিছু জায়গা রাখতে হবে। আমরা e2-standard-4 ভিএম টাইপটি ব্যবহার করতে যাচ্ছি।
আপনার ডেপ্লয়মেন্টের জন্য এনভায়রনমেন্ট ভেরিয়েবলগুলো সেট আপ করুন।
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
তারপর আমরা gcloud ব্যবহার করে GKE স্ট্যান্ডার্ড ক্লাস্টার তৈরি করি।
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
ক্লাস্টার প্রস্তুত করুন
আমাদের প্রয়োজনীয় কম্পোনেন্টগুলো ইনস্টল করতে হবে, যেমন cert-manager সার্ভিস – যা Kubernetes-এর জন্য নেটিভ সার্টিফিকেট ম্যানেজার। cert-manager ইনস্টলেশনের জন্য আমরা ডকুমেন্টেশনে দেওয়া ধাপগুলো অনুসরণ করতে পারি।
আমরা Kubernetes কমান্ড-লাইন টুল kubectl ব্যবহার করি, যা ক্লাউড শেলে ডিফল্টভাবে আগে থেকেই ইনস্টল করা থাকে। ইউটিলিটিটি ব্যবহার করার আগে আমাদের ক্লাস্টারের জন্য ক্রেডেনশিয়াল সংগ্রহ করতে হবে।
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
এখন আমরা kubectl ব্যবহার করে cert-manager ইনস্টল করতে পারি:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
প্রত্যাশিত কনসোল আউটপুট (সংশোধিত):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
AlloyDB Omni ইনস্টল করুন
হেলম ইউটিলিটি ব্যবহার করে অ্যালয়ডিবি ওমনি অপারেটর ইনস্টল করা যায়।
AlloyDB Omni অপারেটর ইনস্টল করতে নিম্নলিখিত কমান্ডটি চালান:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
প্রত্যাশিত কনসোল আউটপুট (সংশোধিত):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
AlloyDB Omni অপারেটরটি ইনস্টল হয়ে গেলে আমরা আমাদের ডাটাবেস ক্লাস্টার স্থাপনের কাজ শুরু করতে পারি।
এখানে googleMLExtension প্যারামিটার সক্রিয় এবং অভ্যন্তরীণ (প্রাইভেট) লোড ব্যালেন্সার সহ একটি ডিপ্লয়মেন্ট ম্যানিফেস্টের উদাহরণ দেওয়া হলো:
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
পাসওয়ার্ডের গোপন মানটি হলো "VeryStrongPassword" শব্দটির Base64 রূপ। পাসওয়ার্ডের মান সংরক্ষণ করার জন্য গুগল সিক্রেট ম্যানেজার ব্যবহার করাই সবচেয়ে নির্ভরযোগ্য উপায়। আপনি ডকুমেন্টেশনে এ সম্পর্কে আরও পড়তে পারেন।
পরবর্তী ধাপে প্রয়োগ করার জন্য ম্যানিফেস্টটি my-omni.yaml নামে সংরক্ষণ করুন। আপনি যদি ক্লাউড শেলে থাকেন, তবে টার্মিনালের উপরের ডানদিকে থাকা "ওপেন এডিটর" বোতামটি চেপে এডিটর ব্যবহার করে এটি করতে পারেন।
my-omni.yaml নামে ফাইলটি সেভ করার পর "ওপেন টার্মিনাল" বাটনটি চেপে টার্মিনালে ফিরে যান।
kubectl ইউটিলিটি ব্যবহার করে ক্লাস্টারে my-omni.yaml ম্যানিফেস্টটি প্রয়োগ করুন:
kubectl apply -f my-omni.yaml
প্রত্যাশিত কনসোল আউটপুট:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
kubectl ইউটিলিটি ব্যবহার করে আপনার my-omni ক্লাস্টারের অবস্থা পরীক্ষা করুন:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
ডেপ্লয়মেন্টের সময় ক্লাস্টারটি বিভিন্ন ধাপের মধ্য দিয়ে যায় এবং অবশেষে DBClusterReady অবস্থায় শেষ হয়।
প্রত্যাশিত কনসোল আউটপুট:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
AlloyDB Omni-এর সাথে সংযোগ করুন
কুবারনেটিস পড ব্যবহার করে সংযোগ করুন
ক্লাস্টারটি প্রস্তুত হয়ে গেলে আমরা AlloyDB Omni ইনস্ট্যান্স পডে PostgreSQL ক্লায়েন্ট বাইনারিগুলো ব্যবহার করতে পারি। আমরা পড আইডি খুঁজে বের করি এবং তারপর kubectl ব্যবহার করে সরাসরি পডে সংযোগ স্থাপন করে ক্লায়েন্ট সফটওয়্যারটি চালাই। পাসওয়ার্ডটি হলো VeryStrongPassword , যা my-omni.yaml ম্যানিফেস্টে kubernetes secret-এর মাধ্যমে সেট করা হয়েছে।
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
নমুনা কনসোল আউটপুট:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
৫. GKE-তে AI মডেল স্থাপন করুন
লোকাল মডেলের সাথে AlloyDB Omni AI ইন্টিগ্রেশন পরীক্ষা করার জন্য আমাদের ক্লাস্টারে একটি মডেল ডেপ্লয় করতে হবে। আমরা গুগলের EmbeddingGemma মডেলটি ব্যবহার করতে যাচ্ছি।
মডেলের জন্য একটি নোড পুল তৈরি করুন
মডেলটি চালানোর জন্য আমাদের ইনফারেন্স চালানোর জন্য একটি নোড পুল প্রস্তুত করতে হবে। আমরা এটি শুধুমাত্র সিপিইউ পুল অথবা জিপিইউ অ্যাক্সিলারেটর সহ একটি পুল ব্যবহার করে চালাতে পারি। রিসোর্সের উচ্চ কনকারেন্সির কারণে কিছু অঞ্চলে শুধুমাত্র সিপিইউ পদ্ধতিটি বেশি কার্যকর হতে পারে। আমাদের ল্যাবে আমরা সিপিইউ পদ্ধতিটি ব্যবহার করতে যাচ্ছি, কিন্তু পারফরম্যান্সের দৃষ্টিকোণ থেকে সেরা পদ্ধতি হলো গ্রাফিক অ্যাক্সিলারেটর সহ একটি পুল, যেখানে L4 এনভিডিয়া অ্যাক্সিলারেটর সহ g2-standard-8-এর মতো নোড কনফিগারেশন ব্যবহার করা হয়।
সিপিইউ ভিত্তিক নোড পুল
e2-standard-32 টি নোড দিয়ে একটি নোড পুল তৈরি করুন। রিসোর্স সাশ্রয়ের জন্য আমরা পুলকে একটি নোডে সীমাবদ্ধ রাখব।
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
প্রত্যাশিত আউটপুট
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
আলিঙ্গনের মুখের টোকেন পান
এই ল্যাবে আমরা EmbeddingGemma মডেলটি স্থাপন করার জন্য Hugging Face-এর সাথে একটি অংশীদারিত্ব ব্যবহার করি এবং তা করার জন্য আমাদের একটি Hugging Face টোকেন পেতে হয়।
আপনার যদি আগে টোকেন না থাকে, তাহলে একটি নতুন টোকেন তৈরি করতে নিচের ধাপগুলো অনুসরণ করুন।
- উপরের ডান কোণায় থাকা লগ ইন অথবা সাইন আপ লিঙ্ক ব্যবহার করে হাগিং ফেস সাইটে লগ ইন বা সাইন আপ করুন।
- আপনার প্রোফাইলে ক্লিক করুন -> অ্যাক্সেস টোকেন
- আপনার পরিচয় নিশ্চিত করুন
- নতুন টোকেন তৈরি করতে ক্লিক করুন
- আপনার টোকেনের জন্য একটি নাম বেছে নিন
- টোকেনটির জন্য একটি ভূমিকা নির্বাচন করুন - আপনার অন্তত পঠন অধিকার (Read privilege) প্রয়োজন।
- পৃষ্ঠার নীচে টোকেন তৈরি করুন-এ ক্লিক করুন।
- তৈরি হওয়া টোকেনটি কপি করে পরবর্তীতে ব্যবহারের জন্য সংরক্ষণ করুন।
এছাড়াও, Hugging Face-এ EmbeddingGemma সম্পর্কিত ফাইল এবং কন্টেন্ট অ্যাক্সেস করার জন্য আপনাকে https://huggingface.co/google/embeddinggemma-300m পেজটির শর্তাবলী মেনে নিতে হবে।
টোকেন ব্যবহার করে একটি কুবারনেটিস সিক্রেট তৈরি করুন
ক্লাউড শেল সেশনে এটি চালান (HF_TOKEN-এর মানটি আপনার HF টোকেন দিয়ে প্রতিস্থাপন করুন)।
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
মোতায়েন ম্যানিফেস্ট প্রস্তুত করুন
মডেলটি ডেপ্লয় করার জন্য আমাদের একটি ডেপ্লয়মেন্ট ম্যানিফেস্ট প্রস্তুত করতে হবে।
আমরা হাগিং ফেস (Hugging Face) থেকে গুগলের এমবেডিংজেমা (EmbeddingGemma) মডেলটি ব্যবহার করছি। আপনি এখানে মডেল কার্ডটি পড়তে পারেন। মডেলটি ডেপ্লয় করার জন্য আমরা হাগিং ফেস-এর নির্দেশাবলী এবং গিটহাব (GitHub)-এর ডেপ্লয়মেন্ট প্যাকেজের উপর ভিত্তি করে একটি পদ্ধতি ব্যবহার করতে যাচ্ছি।
গিটহাব থেকে প্যাকেজটি ক্লোন করুন
git clone https://github.com/huggingface/Google-Cloud-Containers
সিপিইউ নোডগুলিতে টিইআই (টেক্সট এমবেডিং ইন্টারফেস)-এর জন্য ম্যানিফেস্টটি অ্যাডজাস্ট করুন। আমাদের মডেল, ইমেজ সহ বেশ কিছু প্যারামিটার প্রতিস্থাপন করতে হবে, সঠিক রিসোর্স বরাদ্দ নিশ্চিত করতে হবে এবং কনফিগারেশনে হাগিং ফেস টোকেন সিক্রেট যোগ করতে হবে।
যেকোনো উপলব্ধ এডিটর ব্যবহার করে ম্যানিফেস্টটি সম্পাদনা করুন।
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
সিপিইউ ভিত্তিক পুলে ডেপ্লয়মেন্টের জন্য এখানে একটি সংশোধিত ম্যানিফেস্ট দেওয়া হলো।
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
মডেলটি স্থাপন করুন
সিপিইউ ডেপ্লয়মেন্টের জন্য সংশোধিত ম্যানিফেস্টটি প্রয়োগ করে মডেলটি ডেপ্লয় করুন।
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
স্থাপনগুলি যাচাই করুন
kubectl get pods
মডেল পরিষেবা যাচাই করুন
kubectl get service tei-service
এটিতে চলমান পরিষেবা প্রকার ClusterIP দেখানোর কথা।
নমুনা আউটপুট:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
সার্ভিসটির ক্লাস্টার-আইপি-ই আমরা আমাদের এন্ডপয়েন্ট অ্যাড্রেস হিসেবে ব্যবহার করব। মডেল এমবেডিং http://34.118.233.48:8080/embed এই ইউআরআই-এর মাধ্যমে সাড়া দিতে পারে। এটি পরে অ্যালয়ডিবি অমনি-তে মডেলটি রেজিস্টার করার সময় ব্যবহৃত হবে।
আমরা kubectl port-forward কমান্ড ব্যবহার করে এটিকে উন্মুক্ত করে পরীক্ষা করতে পারি।
kubectl port-forward service/tei-service 8080:8080
আপনি যদি ক্লাউড শেল ব্যবহার করেন, তাহলে পোর্ট ফরওয়ার্ডিং একটি ক্লাউড শেল সেশনে চালানো যেতে পারে এবং এটি পরীক্ষা করার জন্য আমাদের আরেকটি সেশনের প্রয়োজন হবে।
উপরে থাকা "+" চিহ্নটি ব্যবহার করে আরেকটি ক্লাউড শেল ট্যাব খুলুন।
এবং নতুন শেল সেশনে একটি কার্ল (curl) কমান্ড চালান।
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
এটির নিম্নলিখিত নমুনা আউটপুটের (সংশোধিত) মতো একটি ভেক্টর অ্যারে ফেরত দেওয়া উচিত:
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
সংখ্যাগুলো দেখলে আমরা নিশ্চিত হতে পারি যে আমরা মডেলটি সফলভাবে পরীক্ষা করেছি এবং এখন এটিকে সরাসরি SQL থেকে ব্যবহারের জন্য আমাদের AlloyDB Omni-তে নিবন্ধন করতে পারি।
৬. AlloyDB Omni-তে মডেলটি নিবন্ধন করুন
ডেপ্লয় করা মডেলের সাথে আমাদের AlloyDB Omni কীভাবে কাজ করে তা পরীক্ষা করার জন্য, আমাদের একটি ডাটাবেস তৈরি করে মডেলটি রেজিস্টার করতে হবে।
ডাটাবেস তৈরি করুন
আপনার ক্লায়েন্ট ভিএম থেকে অ্যালয়ডিবি অমনি-তে সংযোগ স্থাপন করতে এবং একটি ডেটাবেস তৈরি করতে, একটি জাম্প বক্স হিসেবে একটি জিসিই ভিএম তৈরি করুন।
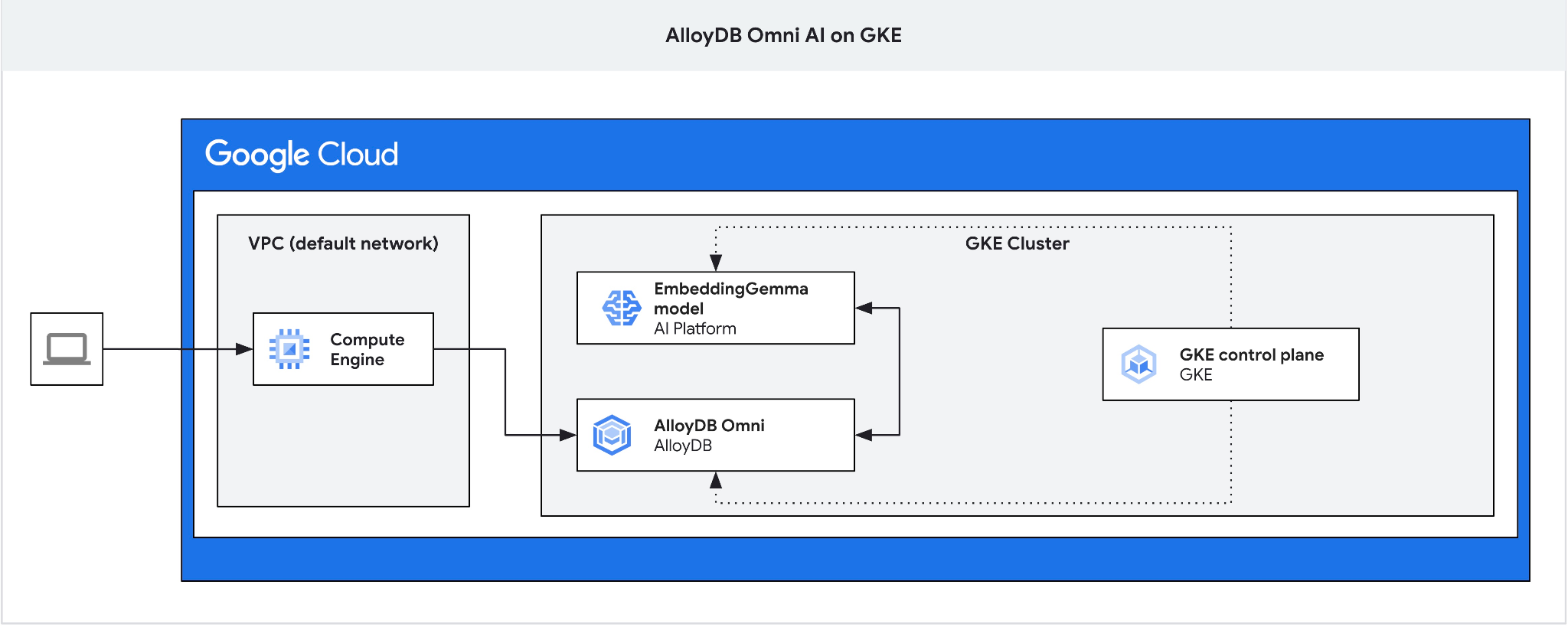
আমাদের জাম্প বক্সটি প্রয়োজন, কারণ Omni-এর জন্য GKE এক্সটার্নাল লোড ব্যালেন্সারটি আপনাকে প্রাইভেট আইপি অ্যাড্রেসিং ব্যবহার করে VPC থেকে অ্যাক্সেস দিলেও, VPC-এর বাইরে থেকে সংযোগ করার অনুমতি দেয় না। এটি সাধারণত অধিক সুরক্ষিত এবং আপনার ডাটাবেস ইনস্ট্যান্সকে ইন্টারনেটে উন্মুক্ত করে না। বিষয়টি পরিষ্কারভাবে বোঝার জন্য অনুগ্রহ করে ডায়াগ্রামটি দেখুন।
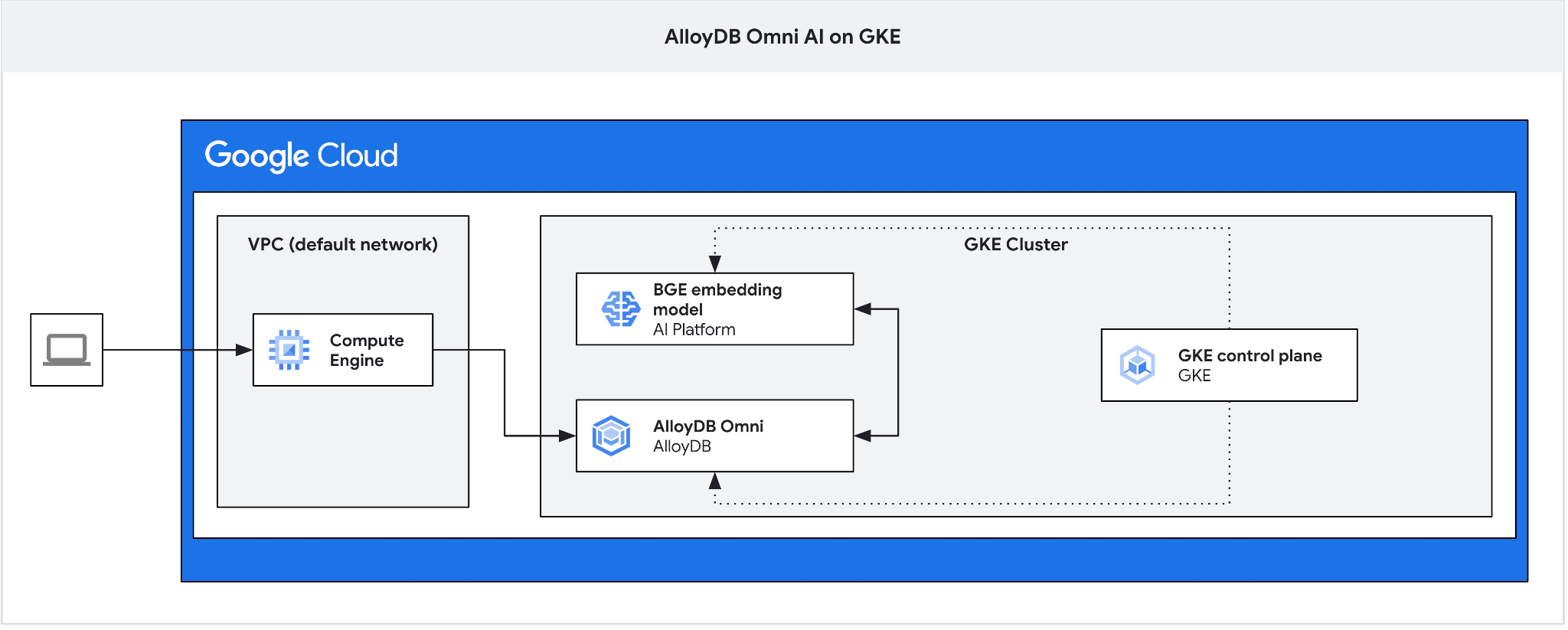
ক্লাউড শেল সেশনে একটি ভিএম তৈরি করতে নিম্নলিখিত কমান্ডটি চালান:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
ক্লাউড শেলে kubectl ব্যবহার করে AlloyDB Omni এন্ডপয়েন্ট IP খুঁজুন:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
PRIMARYENDPOINT- টি লিখে রাখুন।
এখানে একটি উদাহরণ আউটপুট দেওয়া হলো:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
আমাদের উদাহরণগুলিতে AlloyDB Omni ইনস্ট্যান্সের সাথে সংযোগ করার জন্য আমরা 10.131.0.33 আইপি ব্যবহার করব।
gcloud ব্যবহার করে VM-এ সংযোগ করুন:
gcloud compute ssh instance-1 --zone=$ZONE
ssh কী তৈরি করতে বলা হলে, নির্দেশাবলী অনুসরণ করুন। ডকুমেন্টেশনে ssh সংযোগ সম্পর্কে আরও পড়ুন।
ভিএম-এর ssh সেশনে PostgreSQL ক্লায়েন্ট ইনস্টল করুন:
sudo apt-get update
sudo apt-get install --yes postgresql-client
নিম্নলিখিত উদাহরণটি ব্যবহার করে AlloyDB Omni লোড ব্যালেন্সার IP ভেরিয়েবলটি এক্সপোর্ট করুন (IP-এর জায়গায় আপনার লোড ব্যালেন্সারের IP বসান):
export INSTANCE_IP=10.131.0.33
AlloyDB Omni-তে সংযোগ করুন, পাসওয়ার্ডটি হলো VeryStrongPassword যা my-omni.yaml এ হ্যাশের মাধ্যমে সেট করা হয়েছে:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
প্রতিষ্ঠিত psql সেশনে চালান:
create database demo;
সেশন থেকে বেরিয়ে আসুন এবং ডেমো ডাটাবেসে সংযোগ করুন (অথবা আপনি একই সেশনে কেবল \c demo চালাতে পারেন)।
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
রূপান্তর ফাংশন তৈরি করুন
থার্ড-পার্টি এমবেডিং মডেলের জন্য আমাদের ট্রান্সফর্ম ফাংশন তৈরি করতে হয়, যা ইনপুট ও আউটপুটকে মডেল এবং আমাদের অভ্যন্তরীণ ফাংশনগুলোর প্রত্যাশিত ফরম্যাটে রূপান্তর করে। এই ফাংশনগুলো বিভিন্ন ইন্টারফেসের মধ্যে ফরম্যাট রূপান্তর করার জন্য অনুবাদক হিসেবে কাজ করে।
এই হলো ট্রান্সফর্ম ফাংশন যা ইনপুটটি পরিচালনা করে:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
ডেমো ডেটাবেসের সাথে সংযুক্ত থাকা অবস্থায় প্রদত্ত কোডটি চালান, যেমনটি নমুনা আউটপুটে দেখানো হয়েছে:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
এবং এখানে সেই আউটপুট ফাংশনটি রয়েছে যা মডেল থেকে প্রাপ্ত প্রতিক্রিয়াকে বাস্তব সংখ্যার অ্যারেতে রূপান্তরিত করে:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
একই সেশনে এটি সম্পাদন করুন:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
মডেলটি নিবন্ধন করুন
এখন আমরা ডেটাবেসে মডেলটি নিবন্ধন করতে পারি।
এখানে embeddinggemma নামের মডেলটি রেজিস্টার করার প্রসিডিউর কলটি দেওয়া হলো। মডেলটি রেজিস্টার করার সময় আমরা আমাদের model_request_url প্যারামিটারে tei-service সার্ভিস নেমটি ব্যবহার করি। এটি হলো অভ্যন্তরীণ কুবারনেটিস ক্লাস্টারের সার্ভিস নেম এবং এটি GKE ক্লাস্টারের অভ্যন্তরীণ IP-তে রূপান্তরিত হয়:
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
ডেমো ডাটাবেসের সাথে সংযুক্ত থাকা অবস্থায় প্রদত্ত কোডটি চালান:
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
আমরা নিম্নলিখিত টেস্ট কোয়েরিটি ব্যবহার করে রেজিস্টার মডেলটি পরীক্ষা করতে পারি, যা একটি বাস্তব সংখ্যার অ্যারে ফেরত দেবে।
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
ভেক্টর ডেটা ফেরত পেতে দীর্ঘ বিলম্ব দেখে অবাক হবেন না। এই পরীক্ষার জন্য আমরা এমবেডিং মডেলটি হোস্ট করতে সিপিইউ-ভিত্তিক নোড পুল ব্যবহার করি এবং এটি জিপিইউ-যুক্ত নোডগুলিতে অনেক দ্রুত কাজ করে।
৭. AlloyDB Omni-তে মডেলটি পরীক্ষা করুন
ডেটা লোড করুন
ডেপ্লয় করা মডেলের সাথে আমাদের AlloyDB Omni কীভাবে কাজ করে তা পরীক্ষা করার জন্য আমাদের কিছু ডেটা লোড করতে হবে। আমি AlloyDB-তে ভেক্টর সার্চের জন্য অন্য একটি কোডল্যাবের ব্যবহৃত ডেটাই ব্যবহার করেছি।
ডেটা লোড করার একটি উপায় হলো গুগল ক্লাউড এসডিকে (Google Cloud SDK) এবং পোস্টগ্রেসকিউএল (PostgreSQL) ক্লায়েন্ট সফটওয়্যার ব্যবহার করা। আমরা একই ক্লায়েন্ট ভিএম (VM) ব্যবহার করতে পারি। আপনি যদি ভিএম ইমেজের জন্য ডিফল্টগুলো ব্যবহার করে থাকেন, তাহলে গুগল ক্লাউড এসডিকে সেখানে আগে থেকেই ইনস্টল করা থাকার কথা। কিন্তু আপনি যদি গুগল এসডিকে ছাড়া কোনো কাস্টম ইমেজ ব্যবহার করে থাকেন, তাহলে ডকুমেন্টেশন অনুসরণ করে এটি যোগ করতে পারেন।
নিম্নলিখিত উদাহরণের মতো AlloyDB Omni লোড ব্যালেন্সারের IP এক্সপোর্ট করুন (IP-এর জায়গায় আপনার লোড ব্যালেন্সারের IP বসান):
export INSTANCE_IP=10.131.0.33
ডাটাবেসে সংযোগ করুন এবং pgvector এক্সটেনশনটি সক্রিয় করুন।
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
psql সেশনে:
CREATE EXTENSION IF NOT EXISTS vector;
psql সেশন থেকে বেরিয়ে আসুন এবং কমান্ড লাইন সেশনে ডেমো ডেটাবেসে ডেটা লোড করার জন্য কমান্ডগুলো চালান।
টেবিলগুলো তৈরি করুন। নিম্নলিখিত কমান্ডটি cymbal_demo_schema.sql ফাইলটি খুঁজে বের করবে এবং ডেমো ডেটাবেসের সমস্ত টেবিলের সংজ্ঞা সহ SQL কোডটি কার্যকর করবে:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
এখানে তৈরি করা টেবিলগুলোর তালিকা দেওয়া হলো:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
আউটপুট:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
cymbal_products টেবিলে ডেটা লোড করুন:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
এখানে cymbal_products টেবিলের কয়েকটি সারির একটি নমুনা দেওয়া হলো।
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
আউটপুট:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
cymbal_inventory টেবিলে ডেটা লোড করুন:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
এখানে cymbal_inventory টেবিলের কয়েকটি সারির একটি নমুনা দেওয়া হলো।
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
আউটপুট:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
cymbal_stores টেবিলে ডেটা লোড করুন:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
এখানে cymbal_stores টেবিলের কয়েকটি সারির একটি নমুনা দেওয়া হলো।
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
আউটপুট:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
এমবেডিং তৈরি করুন
psql ব্যবহার করে ডেমো ডেটাবেসে সংযোগ স্থাপন করুন এবং পণ্যের বিবরণের উপর ভিত্তি করে cymbal_products টেবিলে বর্ণিত পণ্যগুলির জন্য এমবেডিং তৈরি করুন।
ডেমো ডাটাবেসে সংযোগ করুন:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
আমরা আমাদের এমবেডিংগুলো সংরক্ষণ করার জন্য 'embedding' কলামসহ একটি 'cymbal_embedding' টেবিল ব্যবহার করছি এবং ফাংশনের টেক্সট ইনপুট হিসেবে পণ্যের বিবরণ ব্যবহার করি।
পরবর্তীতে রিমোট মডেলগুলোর সাথে তুলনা করার জন্য আপনার কোয়েরিগুলোর টাইমিং চালু করুন।
\timing
এমবেডিংগুলো তৈরি করতে কোয়েরিটি চালান:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
প্রত্যাশিত কনসোল আউটপুট:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
এই উদাহরণে, এমবেডিং তৈরি করতে প্রায় ৮ মিনিট সময় লেগেছে। সিপিইউ-ভিত্তিক নোড পুলের জন্য এটি প্রত্যাশিত। জিপিইউ অ্যাক্সিলারেটরযুক্ত পুলের ক্ষেত্রে, জিপিইউ-এর ধরনের ওপর নির্ভর করে এটি উল্লেখযোগ্যভাবে দ্রুত হতে পারে।
টেস্ট কোয়েরি চালান
এমবেডিং তৈরির মতোই, psql ব্যবহার করে ডেমো ডেটাবেসে সংযোগ করুন এবং আমাদের কোয়েরিগুলোর এক্সিকিউশন টাইম পরিমাপ করার জন্য টাইমিং চালু করুন।
চলুন, ভেক্টর অনুসন্ধানের অ্যালগরিদম হিসেবে কোসাইন ডিসটেন্স ব্যবহার করে "এখানে কোন ধরনের ফলের গাছ ভালো জন্মায়?"-এর মতো একটি অনুরোধের সাথে মেলে এমন শীর্ষ ৫টি পণ্য খুঁজে বের করি।
psql সেশনে চালান:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
প্রত্যাশিত কনসোল আউটপুট:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
কোয়েরিটি ৮৩ মিলিসেকেন্ড সময় নিয়ে চলেছে এবং cymbal_products টেবিল থেকে অনুরোধের সাথে মিলে যাওয়া ও দোকানে ১৫৮৩ নম্বর হিসেবে মজুত থাকা গাছগুলোর একটি তালিকা ফেরত দিয়েছে।
এএনএন সূচক তৈরি করুন
যখন আমাদের কাছে অল্প পরিমাণ ডেটা সেট থাকে, তখন সমস্ত এমবেডিং স্ক্যান করে এক্সাক্ট সার্চ ব্যবহার করা সহজ হয়, কিন্তু ডেটার পরিমাণ বাড়লে লোড এবং রেসপন্স টাইমও বেড়ে যায়। পারফরম্যান্স উন্নত করার জন্য আপনি আপনার এমবেডিং ডেটার উপর ইনডেক্স তৈরি করতে পারেন। ভেক্টর ডেটার জন্য গুগল স্ক্যান (Google ScaNN) ইনডেক্স ব্যবহার করে এটি কীভাবে করতে হয়, তার একটি উদাহরণ এখানে দেওয়া হলো।
সংযোগ বিচ্ছিন্ন হয়ে গেলে ডেমো ডেটাবেসে পুনরায় সংযোগ করুন:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
alloydb_scann এক্সটেনশনটি সক্রিয় করুন:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
সূচকটি তৈরি করুন:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
আগের মতো একই কোয়েরিটি চেষ্টা করুন এবং ফলাফলগুলো তুলনা করুন:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
কোয়েরি সম্পাদনের সময় সামান্য কমেছে এবং বড় ডেটাসেটের ক্ষেত্রে এই উন্নতি আরও বেশি লক্ষণীয় হবে। ফলাফলগুলো বেশ কাছাকাছি এবং আমরা ফলাফলে একই শীর্ষ ৫টি ট্রি পেয়েছি।
অন্যান্য কোয়েরি চেষ্টা করুন এবং ডকুমেন্টেশনে ভেক্টর ইনডেক্স নির্বাচন সম্পর্কে আরও পড়ুন।
আর ভুলে যাবেন না যে AlloyDB Omni-তে আরও বেশি ফিচার ও ল্যাব রয়েছে।
৮. পরিবেশ পরিষ্কার করুন
এখন আমরা AlloyDB Omni এবং একটি AI মডেল সহ আমাদের GKE ক্লাস্টারটি মুছে ফেলতে পারি।
GKE ক্লাস্টার মুছুন
ক্লাউড শেলে চালান:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
ভিএম মুছে ফেলুন
ক্লাউড শেলে চালান:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
আপনি যদি এই কোডল্যাবের জন্য একটি নতুন প্রজেক্ট তৈরি করে থাকেন, তাহলে তার পরিবর্তে সম্পূর্ণ প্রজেক্টটি ডিলিট করে দিতে পারেন: https://console.cloud.google.com/cloud-resource-manager
৯. অভিনন্দন
কোডল্যাবটি সম্পন্ন করার জন্য অভিনন্দন।
আমরা যা আলোচনা করেছি
- গুগল কুবারনেটিস ক্লাস্টারে কীভাবে অ্যালয়ডিবি ওমনি স্থাপন করবেন
- AlloyDB Omni-এর সাথে কীভাবে সংযোগ করবেন
- AlloyDB Omni-তে কীভাবে ডেটা লোড করবেন
- GKE-তে কীভাবে একটি ওপেন এমবেডিং মডেল স্থাপন করবেন
- AlloyDB Omni-তে এমবেডিং মডেল কীভাবে রেজিস্টার করবেন
- সিমান্টিক সার্চের জন্য এমবেডিং কীভাবে তৈরি করবেন
- AlloyDB Omni-তে সিমান্টিক সার্চের জন্য জেনারেটেড এমবেডিং কীভাবে ব্যবহার করবেন
- AlloyDB-তে ভেক্টর ইনডেক্স কীভাবে তৈরি এবং ব্যবহার করবেন
AlloyDB Omni-তে AI নিয়ে কাজ করার বিষয়ে আপনি ডকুমেন্টেশন থেকে আরও জানতে পারবেন।
১০. জরিপ
আউটপুট: