
۱. مقدمه
در این آزمایشگاه کد، نحوهی استقرار AlloyDB Omni روی GKE و استفاده از آن با یک مدل تعبیهی باز مستقر در همان کلاستر Kubernetes را خواهید آموخت. استقرار یک مدل در کنار نمونهی پایگاه داده در همان کلاستر GKE، تأخیر و وابستگی به سرویسهای شخص ثالث را کاهش میدهد. علاوه بر این، استقرار محلی ممکن است الزامی باشد که توسط امنیت و انطباقها تنظیم شده باشد، زمانی که دادهها نباید سازمان را ترک کنند و استفاده از سرویسهای شخص ثالث مجاز نیست.
پیشنیازها
- درک اولیه از گوگل کلود، کنسول
- آشنایی اولیه با Kubernetes و GKE
- مهارتهای پایه در رابط خط فرمان و Cloud Shell
آنچه یاد خواهید گرفت
- نحوه استقرار AlloyDB Omni در کلاستر Google Kubernetes
- نحوه اتصال به AlloyDB Omni
- نحوه بارگذاری دادهها در AlloyDB Omni
- نحوه استقرار یک مدل تعبیه باز در GKE
- نحوه ثبت مدل جاسازی در AlloyDB Omni
- نحوه تولید جاسازیها برای جستجوی معنایی
- نحوه استفاده از جاسازیهای تولید شده برای جستجوی معنایی در AlloyDB Omni
- نحوه ایجاد و استفاده از شاخصهای برداری در AlloyDB
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم که از کنسول گوگل کلود و کلود شل پشتیبانی میکند
۲. تنظیمات و الزامات
راهاندازی پروژه
- وارد کنسول ابری گوگل شوید. اگر از قبل حساب جیمیل یا گوگل ورکاسپیس ندارید، باید یکی ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید.
- یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. برای ایجاد یک پروژه جدید در کنسول Google Cloud، در سربرگ، روی دکمه «انتخاب پروژه» کلیک کنید که یک پنجره بازشو باز میشود.

در پنجره انتخاب پروژه، دکمه «پروژه جدید» را فشار دهید که یک کادر محاورهای برای پروژه جدید باز میکند.
در کادر محاورهای، نام پروژه مورد نظر خود را وارد کرده و مکان را انتخاب کنید.
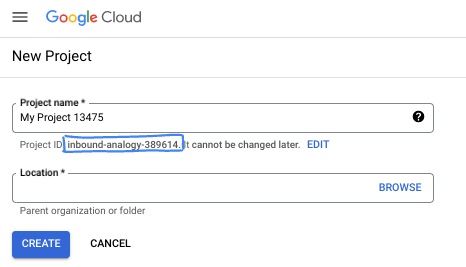
- نام پروژه ، نام نمایشی برای شرکتکنندگان این پروژه است. نام پروژه توسط APIهای گوگل استفاده نمیشود و میتوان آن را در هر زمانی تغییر داد.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، دیگر قابل تغییر نیست). کنسول گوگل کلود به طور خودکار یک شناسه منحصر به فرد تولید میکند، اما میتوانید آن را سفارشی کنید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید یا شناسه خودتان را برای بررسی در دسترس بودن آن ارائه دهید. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را که معمولاً با عبارت PROJECT_ID مشخص میشود، ارجاع دهید.
- برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
فعال کردن صورتحساب
یک حساب پرداخت شخصی تنظیم کنید
اگر صورتحساب را با استفاده از اعتبارهای Google Cloud تنظیم کردهاید، میتوانید از این مرحله صرف نظر کنید.
برای تنظیم یک حساب پرداخت شخصی، به اینجا بروید تا پرداخت را در کنسول ابری فعال کنید .
برخی نکات:
- تکمیل این آزمایشگاه باید کمتر از ۳ دلار آمریکا از طریق منابع ابری هزینه داشته باشد.
- شما میتوانید مراحل انتهای این آزمایش را برای حذف منابع دنبال کنید تا از هزینههای بیشتر جلوگیری شود.
- کاربران جدید واجد شرایط استفاده از دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
همچنین میتوانید دکمههای G و سپس S را فشار دهید. اگر در کنسول ابری گوگل باشید یا از این لینک استفاده کنید، این توالی، Cloud Shell را فعال میکند.
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. قبل از شروع
فعال کردن API
خروجی:
برای استفاده از موتور گوگل کوبرنتیز (GKE) برای استقرار AlloyDB Omni و مدلهای باز، باید APIهای مربوطه را در پروژه Google Cloud خود فعال کنید.
در داخل Cloud Shell، مطمئن شوید که شناسه پروژه شما تنظیم شده است:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
اگر در پیکربندی پوسته ابری تعریف نشده است، آن را با استفاده از دستورات زیر تنظیم کنید
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
فعال کردن تمام سرویسهای لازم:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
خروجی مورد انتظار
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
معرفی API ها
- رابط برنامهنویسی کاربردی موتور Kubernetes (
container.googleapis.com) به شما امکان میدهد خوشههای موتور Google Kubernetes (GKE) را ایجاد و مدیریت کنید. این رابط، محیطی مدیریتشده برای استقرار، مدیریت و مقیاسبندی برنامههای کانتینریشده شما با استفاده از زیرساخت گوگل فراهم میکند. - رابط برنامهنویسی کاربردی موتور محاسبات (compute Engine API ) (
compute.googleapis.com) به شما امکان میدهد ماشینهای مجازی (VM)، دیسکهای پایدار و تنظیمات شبکه را ایجاد و مدیریت کنید. این رابط، پایه و اساس زیرساخت به عنوان سرویس (IaaS) مورد نیاز برای اجرای بارهای کاری شما و میزبانی زیرساختهای اساسی برای بسیاری از سرویسهای مدیریتشده را فراهم میکند.
۴. AlloyDB Omni را روی GKE مستقر کنید
برای استقرار AlloyDB Omni روی GKE، باید یک کلاستر Kubernetes مطابق با الزامات ذکر شده در الزامات عملگر AlloyDB Omni آماده کنیم.
ایجاد یک خوشه GKE
ما باید یک کلاستر استاندارد GKE با پیکربندی Pool کافی برای استقرار یک pod با نمونه AlloyDB Omni مستقر کنیم. برای AlloyDB Omni به حداقل ۲ پردازنده و ۸ گیگابایت رم نیاز داریم و مقداری فضا برای کانتینرهای اپراتور و سرویسهای نظارتی نیز در نظر گرفتهایم. ما قصد داریم از نوع ماشین مجازی e2-standard-4 استفاده کنیم.
متغیرهای محیطی را برای استقرار خود تنظیم کنید.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
سپس از gcloud برای ایجاد خوشه استاندارد GKE استفاده میکنیم.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
خروجی مورد انتظار کنسول:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
خوشه را آماده کنید
ما باید اجزای مورد نیاز مانند سرویس cert-manager - مدیریت گواهینامههای بومی برای kubernetes را نصب کنیم. میتوانیم مراحل موجود در مستندات نصب cert-manager را دنبال کنیم.
ما از ابزار خط فرمان Kubernetes، kubectl، استفاده میکنیم که به طور پیشفرض در Cloud Shell نصب شده است. قبل از استفاده از این ابزار، باید اعتبارنامههای مربوط به کلاستر خود را دریافت کنیم.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
حالا میتوانیم از kubectl برای نصب cert-manager استفاده کنیم:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
خروجی مورد انتظار کنسول (حذف شده):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
نصب AlloyDB Omni
نصب اپراتور AlloyDB Omni با استفاده از ابزار helm امکانپذیر است.
برای نصب عملگر AlloyDB Omni، دستور زیر را اجرا کنید:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
خروجی مورد انتظار کنسول (حذف شده):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
وقتی عملگر AlloyDB Omni نصب شد، میتوانیم استقرار خوشه پایگاه داده خود را پیگیری کنیم.
در اینجا مثالی از مانیفست استقرار با پارامتر googleMLExtension فعال و متعادلکننده بار داخلی (خصوصی) آورده شده است:
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
مقدار مخفی برای رمز عبور، یک نمایش Base64 از کلمه عبور "VeryStrongPassword" است. روش مطمئنتر، استفاده از Google secret manager برای ذخیره مقدار رمز عبور است. میتوانید اطلاعات بیشتر را در مستندات بخوانید.
مانیفست را با نام my-omni.yaml ذخیره کنید تا در مرحله بعدی اعمال شود. اگر در Cloud Shell هستید، میتوانید این کار را با استفاده از ویرایشگر و با فشار دادن دکمه "Open Editor" در سمت راست بالای ترمینال انجام دهید.
پس از ذخیره فایل با نام my-omni.yaml، با فشردن دکمه «باز کردن ترمینال» به ترمینال بازگردید.
با استفاده از ابزار kubectl، فایل my-omni.yaml manifest را روی کلاستر اعمال کنید:
kubectl apply -f my-omni.yaml
خروجی مورد انتظار کنسول:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
وضعیت کلاستر my-omni خود را با استفاده از ابزار kubectl بررسی کنید:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
در طول استقرار، کلاستر مراحل مختلفی را طی میکند و در نهایت باید به حالت DBClusterReady برسد.
خروجی مورد انتظار کنسول:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
اتصال به AlloyDB Omni
اتصال با استفاده از Kubernetes Pod
وقتی کلاستر آماده شد، میتوانیم از فایلهای باینری کلاینت PostgreSQL روی پاد نمونه AlloyDB Omni استفاده کنیم. شناسه پاد را پیدا میکنیم و سپس از kubectl برای اتصال مستقیم به پاد و اجرای نرمافزار کلاینت استفاده میکنیم. رمز عبور VeryStrongPassword است که از طریق kubernetes secret در فایل my-omni.yaml manifest تنظیم شده است:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
نمونه خروجی کنسول:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
۵. مدل هوش مصنوعی را روی GKE مستقر کنید
برای آزمایش یکپارچهسازی AlloyDB Omni AI با مدلهای محلی، باید یک مدل را در کلاستر مستقر کنیم. ما قصد داریم از مدل EmbeddingGemma گوگل استفاده کنیم.
ایجاد یک Node Pool برای مدل
برای اجرای مدل، باید یک مجموعه گره برای اجرای استنتاج آماده کنیم. میتوانیم آن را با استفاده از یک مجموعه فقط CPU یا یک مجموعه با شتابدهندههای GPU اجرا کنیم. رویکرد فقط CPU ممکن است در برخی مناطق به دلیل همزمانی بالا برای منابع، امکانپذیرتر باشد. در آزمایشگاه ما، قصد داریم از رویکرد CPU استفاده کنیم، اما بهترین رویکرد از نظر عملکرد، یک مجموعه با شتابدهندههای گرافیکی با استفاده از پیکربندی گره مانند g2-standard-8 با شتابدهنده L4 Nvidia است.
استخر گره مبتنی بر CPU
یک مخزن گره با گرههای e2-standard-32 ایجاد کنید. ما قصد داریم برای صرفهجویی در منابع، کشش خود را به یک گره محدود کنیم.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
خروجی مورد انتظار
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
دریافت توکن چهره در آغوش گرفتن
در این آزمایشگاه ما از همکاری با Hugging Face برای استقرار مدل EmbeddingGemma استفاده میکنیم و برای انجام این کار باید یک توکن Hugging Face دریافت کنیم.
اگر قبلاً توکنی نداشتهاید، مراحل زیر را برای تولید توکن جدید دنبال کنید.
- با استفاده از لینکهای ورود یا ثبت نام در گوشه بالا سمت راست، وارد سایت Hugging Face شوید یا ثبت نام کنید.
- روی نمایه خود کلیک کنید -> توکنهای دسترسی
- هویت خود را تأیید کنید
- روی ایجاد توکن جدید کلیک کنید
- یک نام برای توکن خود انتخاب کنید
- نقشی را برای توکن انتخاب کنید - حداقل به امتیاز خواندن نیاز دارید
- روی ایجاد توکن در پایین صفحه کلیک کنید
- توکن تولید شده را کپی کنید و برای استفاده بعدی ذخیره کنید
همچنین برای دسترسی به فایلها و محتوای مربوط به EmbeddingGemma در Hugging Face در صفحه https://huggingface.co/google/embeddinggemma-300m باید شرایط را بپذیرید.
با استفاده از توکن، یک راز kubernetes ایجاد کنید
در جلسه پوسته ابری، دستور زیر را اجرا کنید (مقدار HF_TOKEN را با توکن HF خود جایگزین کنید).
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
آمادهسازی مانیفست استقرار
برای استقرار مدل، باید یک مانیفست استقرار (deployment manifest) تهیه کنیم.
ما از مدل EmbeddingGemma گوگل از Hugging Face استفاده میکنیم. میتوانید کارت مدل را اینجا بخوانید. برای استقرار مدل، از رویکردی مبتنی بر دستورالعملهای Hugging Face و بسته استقرار از GitHub استفاده خواهیم کرد.
بسته را از گیتهاب کلون کنید
git clone https://github.com/huggingface/Google-Cloud-Containers
مانیفست مربوط به tei (رابط تعبیه متن) را روی گرههای CPU تنظیم کنید. ما باید چندین پارامتر از جمله مدل، تصویر، تخصیص صحیح منابع را جایگزین کنیم و رمز توکن Hugging Face را به پیکربندی اضافه کنیم.
ویرایش مانیفست (با استفاده از هر ویرایشگر موجود)
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
در اینجا یک مانیفست اصلاحشده d= برای استقرار در یک استخر مبتنی بر CPU آمده است.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
استقرار مدل
مدل را با اعمال مانیفست اصلاحشده برای استقرار CPU مستقر کنید.
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
استقرارها را تأیید کنید
kubectl get pods
سرویس مدل را تأیید کنید
kubectl get service tei-service
قرار است نوع سرویس در حال اجرا ClusterIP را نشان دهد.
خروجی نمونه:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
CLUSTER-IP برای سرویس، چیزی است که ما به عنوان آدرس نقطه پایانی خود استفاده خواهیم کرد. مدل تعبیه شده میتواند از طریق آدرس اینترنتی http://34.118.233.48:8080/embed پاسخ دهد. این آدرس بعداً هنگام ثبت مدل در AlloyDB Omni استفاده خواهد شد.
میتوانیم آن را با استفاده از دستور port-forward در kubectl آزمایش کنیم.
kubectl port-forward service/tei-service 8080:8080
اگر از Cloud Shell استفاده میکنید، پورت فورواردینگ میتواند در یک جلسه Cloud Shell اجرا شود و برای آزمایش آن به جلسه دیگری نیاز داریم.
با استفاده از علامت "+" در بالا، یک تب Cloud Shell دیگر باز کنید.
و یک دستور curl را در جلسه پوسته جدید اجرا کنید.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
باید یک آرایه برداری مانند خروجی نمونه زیر (ویرایش شده) برگرداند:
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
اگر اعداد را ببینیم، میتوانیم تأیید کنیم که مدل را با موفقیت آزمایش کردهایم و اکنون میتوانیم آن را در AlloyDB Omni خود ثبت کنیم تا مستقیماً از SQL استفاده شود.
۶. مدل را در AlloyDB Omni ثبت کنید
برای آزمایش نحوه عملکرد AlloyDB Omni با مدل مستقر شده، باید یک پایگاه داده ایجاد کنیم و مدل را ثبت کنیم.
ایجاد پایگاه داده
یک ماشین مجازی GCE به عنوان یک Jump Box ایجاد کنید تا از ماشین مجازی کلاینت خود به AlloyDB Omni متصل شوید و یک پایگاه داده ایجاد کنید.
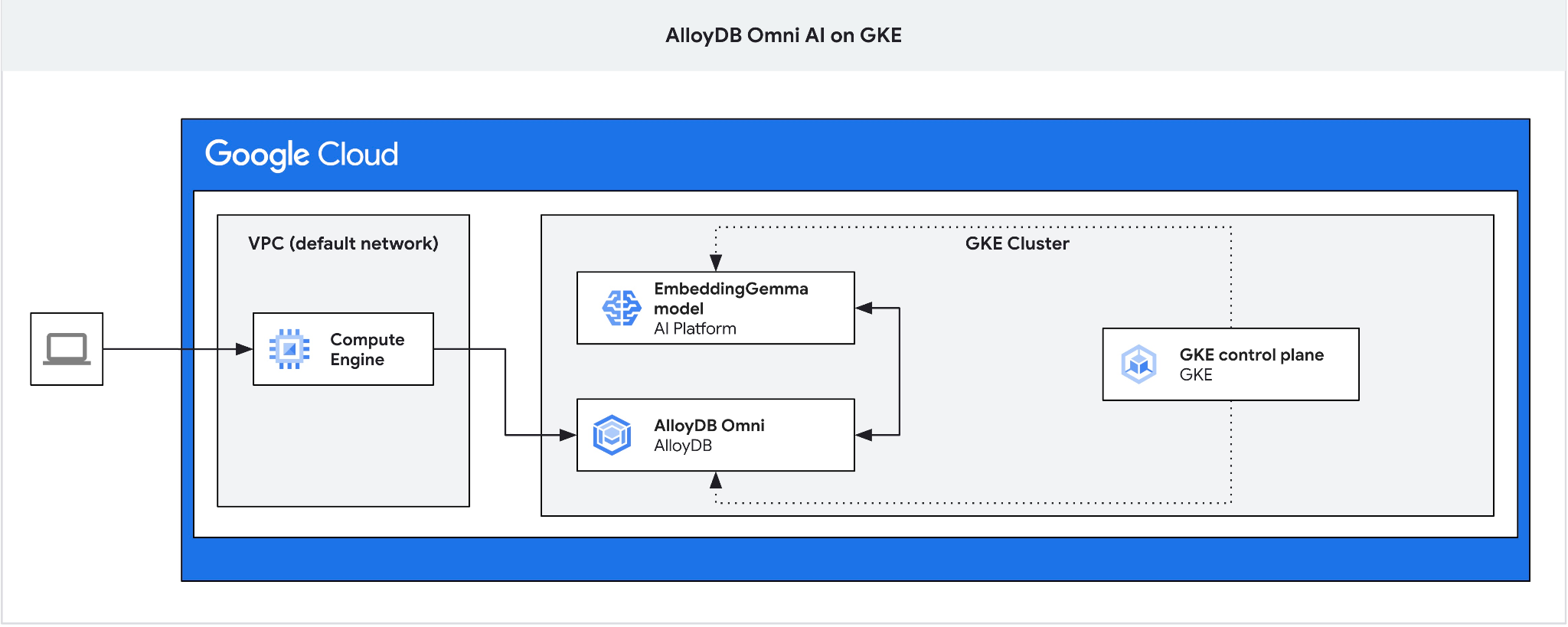
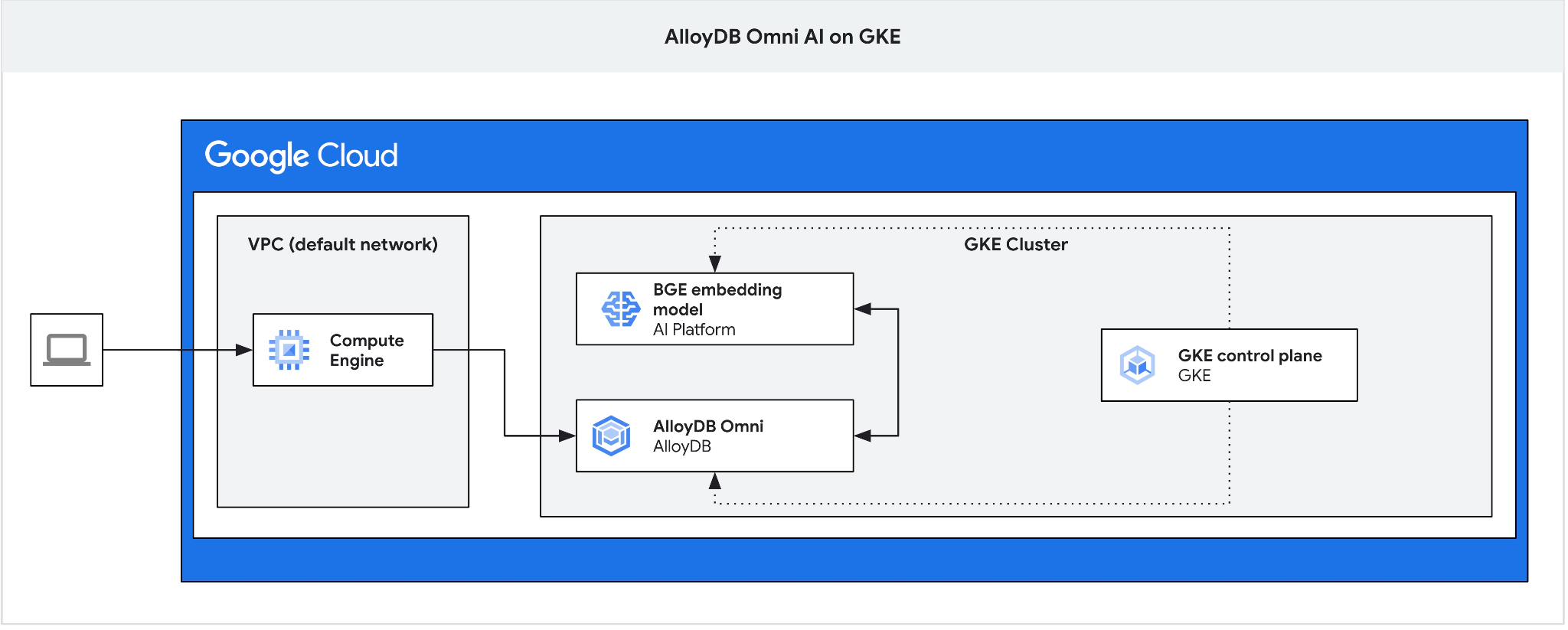
ما به جامپ باکس نیاز داریم زیرا متعادلکننده بار خارجی GKE برای Omni به شما امکان دسترسی از VPC با استفاده از آدرسدهی IP خصوصی را میدهد اما به شما اجازه اتصال از خارج از VPC را نمیدهد. این روش به طور کلی امنتر است و نمونه پایگاه داده شما را در معرض اینترنت قرار نمیدهد. لطفاً برای وضوح بیشتر، نمودار را بررسی کنید.
برای ایجاد یک ماشین مجازی در جلسه Cloud Shell، دستور زیر را اجرا کنید:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
پیدا کردن IP نقطه پایانی AlloyDB Omni با استفاده از kubectl در Cloud Shell:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
PRIMARYENDPOINT را یادداشت کنید.
در اینجا یک مثال خروجی آورده شده است:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33 آدرس IP است که ما در مثالهای خود برای اتصال به نمونه AlloyDB Omni از آن استفاده خواهیم کرد.
اتصال به ماشین مجازی با استفاده از gcloud:
gcloud compute ssh instance-1 --zone=$ZONE
اگر از شما خواسته شد که کلید ssh ایجاد کنید، دستورالعملها را دنبال کنید. برای اطلاعات بیشتر در مورد اتصال ssh به مستندات مراجعه کنید.
در جلسه ssh به ماشین مجازی، کلاینت PostgreSQL را نصب کنید:
sudo apt-get update
sudo apt-get install --yes postgresql-client
متغیر IP مربوط به متعادلکننده بار AlloyDB Omni را با استفاده از مثال زیر صادر کنید (به جای IP، IP متعادلکننده بار خود را قرار دهید):
export INSTANCE_IP=10.131.0.33
به AlloyDB Omni متصل شوید، رمز عبور VeryStrongPassword است که از طریق هش در my-omni.yaml تنظیم شده است:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
در جلسه psql ایجاد شده، دستور زیر را اجرا کنید:
create database demo;
از جلسه خارج شوید و به نسخه آزمایشی پایگاه داده متصل شوید (یا میتوانید به سادگی \c demo در همان جلسه اجرا کنید)
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
ایجاد توابع تبدیل
برای مدلهای جاسازی شخص ثالث، باید توابع تبدیلی ایجاد کنیم که ورودی و خروجی را به فرمت مورد انتظار مدل و توابع داخلی ما تبدیل کنند. این توابع به عنوان مترجم عمل میکنند تا تبدیل فرمت را بین رابطهای مختلف انجام دهند.
تابع تبدیلی که ورودی را مدیریت میکند، به صورت زیر است:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
کد ارائه شده را هنگام اتصال به پایگاه داده آزمایشی، همانطور که در خروجی نمونه نشان داده شده است، اجرا کنید:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
و این هم تابع خروجی که پاسخ را از مدل به آرایه اعداد حقیقی تبدیل میکند:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
آن را در همان جلسه اجرا کنید:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
مدل را ثبت کنید
حالا میتوانیم مدل را در پایگاه داده ثبت کنیم.
در اینجا فراخوانی روال برای ثبت مدل با نام embeddinggemma آمده است. ما هنگام ثبت مدل از نام سرویس tei-service در پارامتر model_request_url خود استفاده میکنیم. این نام سرویس کلاستر داخلی kubernetes است و به IP داخلی در کلاستر GKE ترجمه میشود:
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
کد ارائه شده را هنگام اتصال به پایگاه داده آزمایشی اجرا کنید:
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
میتوانیم مدل ثبات را با استفاده از کوئری تست زیر آزمایش کنیم که باید یک آرایه از اعداد حقیقی را برگرداند.
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
از تأخیر طولانی قبل از دریافت دادههای برداری تعجب نکنید. برای این آزمایش، ما از گرههای مبتنی بر CPU برای میزبانی مدل جاسازی استفاده میکنیم و این مدل روی گرههای دارای GPU بسیار سریعتر عمل میکند.
۷. مدل را در AlloyDB Omni تست کنید
بارگذاری داده
برای آزمایش نحوه عملکرد AlloyDB Omni با مدل مستقر شده، باید مقداری داده بارگذاری کنیم. من از همان دادههای موجود در یکی از آزمایشگاههای کد دیگر برای جستجوی برداری در AlloyDB استفاده کردم.
یک راه برای بارگذاری دادهها، استفاده از Google Cloud SDK و نرمافزار کلاینت PostgreSQL است. میتوانیم از همان ماشین مجازی کلاینت استفاده کنیم. اگر از پیشفرضها برای تصویر ماشین مجازی استفاده کردهاید، Google Cloud SDK باید از قبل آنجا نصب شده باشد. اما اگر از یک تصویر سفارشی بدون Google SDK استفاده کردهاید، میتوانید آن را طبق مستندات اضافه کنید.
IP مربوط به Load balancer مربوط به AlloyDB Omni را مانند مثال زیر صادر کنید (به جای IP، IP مربوط به Load balancer خود را قرار دهید):
export INSTANCE_IP=10.131.0.33
به پایگاه داده متصل شوید و افزونه pgvector را فعال کنید.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
در جلسه psql:
CREATE EXTENSION IF NOT EXISTS vector;
از جلسه psql خارج شوید و در جلسه خط فرمان، دستوراتی را برای بارگذاری دادهها در پایگاه داده آزمایشی اجرا کنید.
جداول را ایجاد کنید. دستور زیر فایل cymbal_demo_schema.sql را دریافت کرده و SQL را با تمام تعاریف جداول در پایگاه داده آزمایشی اجرا میکند:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
خروجی مورد انتظار کنسول:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
لیست جداول ایجاد شده به شرح زیر است:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
خروجی:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
بارگذاری دادهها در جدول cymbal_products :
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
خروجی مورد انتظار کنسول:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
در اینجا نمونهای از چند ردیف از جدول cymbal_products آورده شده است.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
خروجی:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
بارگذاری دادهها در جدول cymbal_inventory :
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
خروجی مورد انتظار کنسول:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
در اینجا نمونهای از چند ردیف از جدول cymbal_inventory آورده شده است.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
خروجی:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
بارگذاری دادهها در جدول cymbal_stores :
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
خروجی مورد انتظار کنسول:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
در اینجا نمونهای از چند ردیف از جدول cymbal_stores آورده شده است.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
خروجی:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
جاسازیهای ساخت
با استفاده از psql به پایگاه داده آزمایشی متصل شوید و بر اساس توضیحات محصولات، جاسازیهایی برای محصولات شرح داده شده در جدول cymbal_products ایجاد کنید.
اتصال به پایگاه داده نسخه آزمایشی:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
ما از یک جدول cymbal_embedding با قابلیت تعبیه ستون برای ذخیره جاسازیهای خود استفاده میکنیم و از توضیحات محصول به عنوان ورودی متن به تابع استفاده میکنیم.
زمانبندی را برای کوئریهای خود فعال کنید تا بعداً با مدلهای از راه دور مقایسه شوند.:
\timing
برای ساخت جاسازیها، کوئری زیر را اجرا کنید:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
خروجی مورد انتظار کنسول:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
در این مثال، ساخت جاسازیها حدود ۸ دقیقه طول کشید. این برای یک استخر گره مبتنی بر CPU قابل انتظار است. برای یک استخر با شتابدهندههای GPU، بسته به نوع GPU، میتواند به طور قابل توجهی سریعتر باشد.
اجرای کوئریهای آزمایشی
با استفاده از psql به پایگاه داده آزمایشی متصل شوید و زمانبندی را برای اندازهگیری زمان اجرای کوئریهایمان فعال کنید، همانطور که برای ساخت جاسازیها انجام دادیم.
بیایید با استفاده از فاصله کسینوسی به عنوان الگوریتم جستجوی برداری، 5 محصول برتر منطبق با درخواستی مانند «چه نوع درختان میوهای اینجا خوب رشد میکنند؟» را پیدا کنیم.
در جلسه psql اجرا کنید:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
خروجی مورد انتظار کنسول:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
این پرسوجو ۸۳ میلیثانیه اجرا شد و فهرستی از درختان را از جدول cymbal_products که با درخواست مطابقت داشتند و موجودی آنها در فروشگاه با شماره ۱۵۸۳ موجود بود، بازگرداند.
ساخت شاخص شبکه عصبی مصنوعی (ANN)
وقتی فقط یک مجموعه داده کوچک داریم، استفاده از جستجوی دقیق و اسکن همه جاسازیها آسان است، اما وقتی دادهها افزایش مییابند، زمان بارگذاری و پاسخ نیز افزایش مییابد. برای بهبود عملکرد، میتوانید شاخصهایی را روی دادههای جاسازی خود ایجاد کنید. در اینجا مثالی از نحوه انجام این کار با استفاده از شاخص Google ScaNN برای دادههای برداری آورده شده است.
اگر اتصال قطع شده است، دوباره به پایگاه داده آزمایشی متصل شوید:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
افزونه alloydb_scann را فعال کنید:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
ساخت ایندکس:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
همان کوئری قبلی را امتحان کنید و نتایج را مقایسه کنید:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
زمان اجرای پرسوجو کمی کاهش یافته است و این افزایش در مجموعه دادههای بزرگتر قابل توجهتر خواهد بود. نتایج کاملاً مشابه هستند و ما همان ۵ درخت برتر را در نتیجه گرفتیم.
پرسوجوهای دیگر را امتحان کنید و درباره انتخاب شاخص برداری در مستندات بیشتر بخوانید.
و فراموش نکنید که AlloyDB Omni ویژگیها و آزمایشگاههای بیشتری دارد.
۸. محیط را تمیز کنید
حالا میتوانیم کلاستر GKE خود را با AlloyDB Omni و یک مدل هوش مصنوعی حذف کنیم.
حذف خوشه GKE
در Cloud Shell اجرا کنید:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
خروجی مورد انتظار کنسول:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
حذف ماشین مجازی
در Cloud Shell اجرا کنید:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
خروجی مورد انتظار کنسول:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
اگر برای این آزمایشگاه کد، پروژه جدیدی ایجاد کردهاید، میتوانید کل پروژه را حذف کنید: https://console.cloud.google.com/cloud-resource-manager
۹. تبریک
تبریک میگویم که آزمایشگاه کد را تمام کردی.
آنچه ما پوشش دادهایم
- نحوه استقرار AlloyDB Omni در کلاستر Google Kubernetes
- نحوه اتصال به AlloyDB Omni
- نحوه بارگذاری دادهها در AlloyDB Omni
- نحوه استقرار یک مدل تعبیه باز در GKE
- نحوه ثبت مدل جاسازی در AlloyDB Omni
- نحوه تولید جاسازیها برای جستجوی معنایی
- نحوه استفاده از جاسازیهای تولید شده برای جستجوی معنایی در AlloyDB Omni
- نحوه ایجاد و استفاده از شاخصهای برداری در AlloyDB
میتوانید اطلاعات بیشتر در مورد کار با هوش مصنوعی در AlloyDB Omni را در مستندات مطالعه کنید.
۱۰. نظرسنجی
خروجی: