
1. מבוא
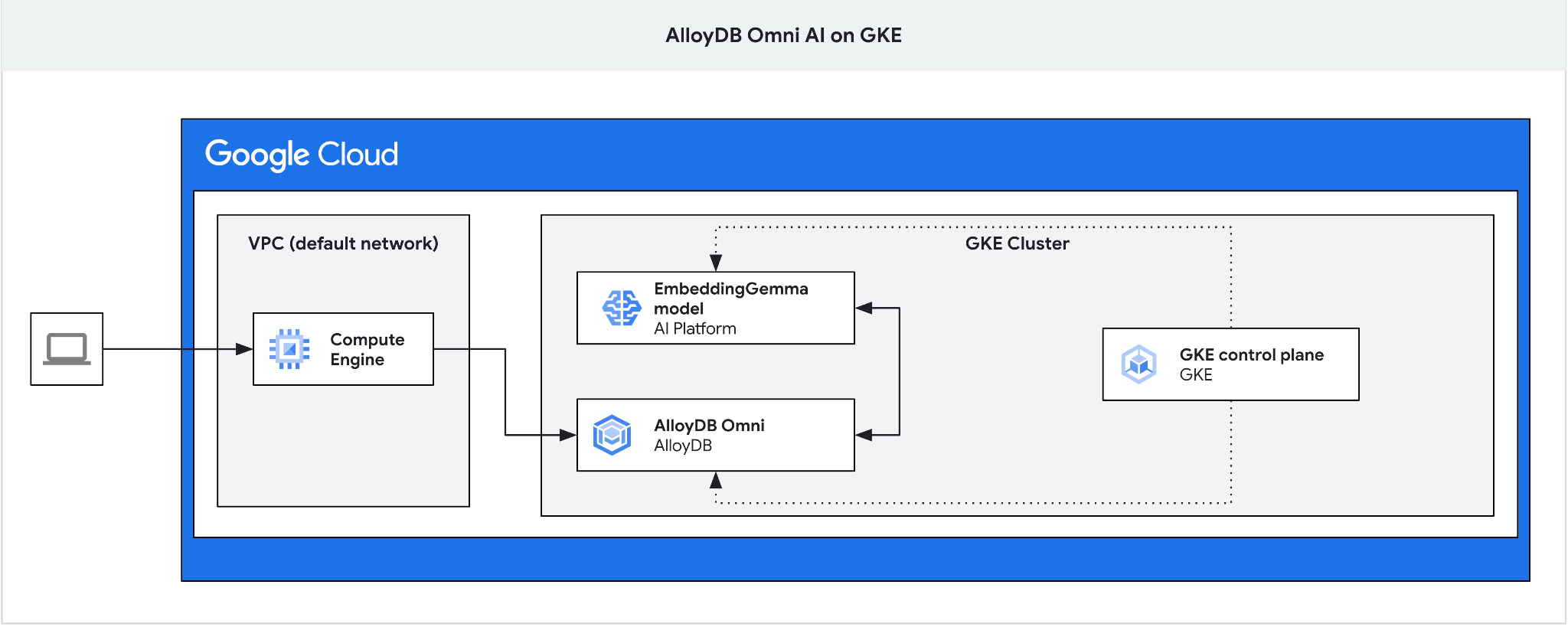
ב-Codelab הזה תלמדו איך לפרוס את AlloyDB Omni ב-GKE ולהשתמש בו עם מודל הטמעה פתוח שנפרס באותו אשכול Kubernetes. פריסת מודל לצד מופע מסד הנתונים באותו אשכול GKE מצמצמת את זמן האחזור ואת התלות בשירותי צד שלישי. בנוסף, יכול להיות שהפריסה המקומית היא דרישה שנקבעה על ידי צוות האבטחה והתאימות, במקרים שבהם הנתונים לא אמורים לצאת מהארגון והשימוש בשירותי צד שלישי אסור.
דרישות מוקדמות
- הבנה בסיסית של Google Cloud ושל המסוף
- ידע בסיסי ב-Kubernetes וב-GKE
- מיומנויות בסיסיות בממשק שורת הפקודה וב-Cloud Shell
מה תלמדו
- איך פורסים את AlloyDB Omni באשכול Google Kubernetes
- איך מתחברים ל-AlloyDB Omni
- איך טוענים נתונים ל-AlloyDB Omni
- איך פורסים מודל הטמעה פתוח ב-GKE
- איך רושמים מודל הטמעה ב-AlloyDB Omni
- איך ליצור הטמעות לחיפוש סמנטי
- איך משתמשים בהטמעות שנוצרו לחיפוש סמנטי ב-AlloyDB Omni
- איך יוצרים אינדקסים של וקטורים ב-AlloyDB ואיך משתמשים בהם
מה תצטרכו
- חשבון Google Cloud ופרויקט Google Cloud
- דפדפן אינטרנט כמו Chrome שתומך במסוף Google Cloud וב-Cloud Shell
2. הגדרה ודרישות
הגדרת פרויקט
- נכנסים ל-מסוף Google Cloud. אם עדיין אין לכם חשבון Gmail או Google Workspace, אתם צריכים ליצור חשבון.
משתמשים בחשבון לשימוש אישי במקום בחשבון לצורכי עבודה או בחשבון בית ספרי.
- יוצרים פרויקט חדש או משתמשים בפרויקט קיים. כדי ליצור פרויקט חדש במסוף Google Cloud, לוחצים בכותרת על הלחצן 'בחירת פרויקט' שפותח חלון קופץ.

בחלון Select a project (בחירת פרויקט), לוחצים על הלחצן New Project (פרויקט חדש) כדי לפתוח תיבת דו-שיח לפרויקט החדש.
בתיבת הדו-שיח, מזינים את שם הפרויקט המועדף ובוחרים את המיקום.
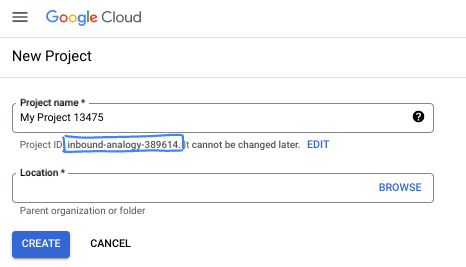
- שם הפרויקט הוא השם המוצג של הפרויקט הזה למשתתפים. השם של הפרויקט לא משמש את Google APIs, ואפשר לשנות אותו בכל שלב.
- מזהה הפרויקט הוא ייחודי לכל הפרויקטים ב-Google Cloud ואי אפשר לשנות אותו אחרי שהוא מוגדר. מסוף Google Cloud יוצר באופן אוטומטי מזהה ייחודי, אבל אפשר להתאים אותו אישית. אם לא אהבתם את המזהה שנוצר, אתם יכולים ליצור מזהה אקראי אחר או לספק מזהה משלכם כדי לבדוק אם הוא זמין. ברוב ה-codelabs, תצטרכו להפנות למזהה הפרויקט שלכם, שבדרך כלל מזוהה באמצעות placeholder בשם PROJECT_ID.
- לידיעתכם, יש ערך שלישי, מספר פרויקט, שחלק מממשקי ה-API משתמשים בו. במאמרי העזרה מפורט מידע נוסף על שלושת הערכים האלה.
הפעלת החיוב
הגדרה של חשבון לחיוב לשימוש אישי
אם הגדרתם חיוב באמצעות קרדיטים ל-Google Cloud, אתם יכולים לדלג על השלב הזה.
כדי להגדיר חשבון לחיוב לשימוש אישי, עוברים לכאן כדי להפעיל את החיוב ב-Cloud Console.
הערות:
- העלות של השלמת ה-Lab הזה במשאבי Cloud צריכה להיות פחות מ-3 דולר ארה"ב.
- כדי למחוק משאבים ולמנוע חיובים נוספים, אפשר לבצע את השלבים בסוף ה-Lab הזה.
- משתמשים חדשים זכאים לתקופת ניסיון בחינם בשווי 300$.
מפעילים את Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-codelab הזה תשתמשו ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:
אפשר גם ללחוץ על G ואז על S. אם אתם נמצאים במסוף Google Cloud, או אם אתם משתמשים בקישור הזה, רצף הפעולות הזה יפעיל את Cloud Shell.
יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, אמור להופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
3. לפני שמתחילים
הפעלת ה-API
פלט:
כדי להשתמש ב-Google Kubernetes Engine (GKE) עבור פריסות של AlloyDB Omni ומודלים פתוחים, צריך להפעיל את ממשקי ה-API המתאימים בפרויקט שלכם ב-Google Cloud.
ב-Cloud Shell, מוודאים שמזהה הפרויקט מוגדר:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
אם הוא לא מוגדר בהגדרות של Cloud Shell, מגדירים אותו באמצעות הפקודות הבאות
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
מפעילים את כל השירותים הנדרשים:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
הפלט הצפוי
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
מבוא לממשקי ה-API
- Kubernetes Engine API (
container.googleapis.com) מאפשר לכם ליצור ולנהל אשכולות של Google Kubernetes Engine (GKE). היא מספקת סביבה מנוהלת לפריסה, לניהול ולהתאמה לעומס (scaling) של אפליקציות בקונטיינרים באמצעות התשתית של Google. - Compute Engine API (
compute.googleapis.com) מאפשר לכם ליצור ולנהל מכונות וירטואליות (VM), דיסקים לאחסון מתמיד והגדרות רשת. היא מספקת את הבסיס של תשתית כשירות (IaaS) שנדרש להפעלת עומסי העבודה ולאירוח התשתית הבסיסית של שירותים מנוהלים רבים.
4. פריסת AlloyDB Omni ב-GKE
כדי לפרוס את AlloyDB Omni ב-GKE, צריך להכין אשכול Kubernetes בהתאם לדרישות שמפורטות במאמר בנושא דרישות האופרטור של AlloyDB Omni.
יצירת אשכול GKE
אנחנו צריכים לפרוס אשכול GKE רגיל עם הגדרת מאגר מספיקה לפריסת pod עם מופע AlloyDB Omni. ב-AlloyDB Omni אנחנו צריכים לפחות 2 מעבדים ו-8GB של RAM, וצריך שיהיה מקום למיכלים של שירותי הפעלה וניטור. נשתמש בסוג המכונה הווירטואלית e2-standard-4.
מגדירים את משתני הסביבה לפריסה.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
לאחר מכן משתמשים ב-gcloud כדי ליצור את אשכול GKE הרגיל.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
הפלט הצפוי במסוף:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
הכנת האשכול
אנחנו צריכים להתקין רכיבים נדרשים כמו שירות cert-manager – מנהל אישורים מקורי ל-Kubernetes. אפשר לפעול לפי השלבים שמפורטים בתיעוד בנושא התקנת cert-manager
אנחנו משתמשים בכלי שורת הפקודה של Kubernetes, kubectl, שכבר מותקן ב-Cloud Shell כברירת מחדל. לפני שמשתמשים בכלי, צריך לקבל פרטי כניסה לאשכול.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
עכשיו אפשר להשתמש ב-kubectl כדי להתקין את cert-manager:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
הפלט הצפוי במסוף(צונזר):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
התקנת AlloyDB Omni
אפשר להתקין את האופרטור של AlloyDB Omni באמצעות כלי ה-Helm.
מריצים את הפקודה הבאה כדי להתקין את האופרטור של AlloyDB Omni:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
הפלט הצפוי במסוף(צונזר):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
אחרי שמתקינים את האופרטור AlloyDB Omni, אפשר להמשיך לפריסה של אשכול מסד הנתונים.
הנה דוגמה למניפסט פריסה עם הפרמטר googleMLExtension מופעל ומאזן עומסים פנימי (פרטי):
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
הערך הסודי של הסיסמה הוא ייצוג Base64 של המילה VeryStrongPassword. הדרך המהימנה יותר היא להשתמש במנהל הסודות של Google כדי לאחסן את ערך הסיסמה. מידע נוסף זמין במאמרי העזרה.
שומרים את קובץ המניפסט בשם my-omni.yaml כדי להשתמש בו בשלב הבא. אם אתם ב-Cloud Shell, אתם יכולים לעשות את זה באמצעות העורך. לשם כך, לוחצים על הלחצן Open Editor (פתיחת העורך) בפינה השמאלית העליונה של הטרמינל.
אחרי ששומרים את הקובץ בשם my-omni.yaml, חוזרים לטרמינל על ידי לחיצה על הלחצן 'פתיחת טרמינל'.
מחילים את קובץ המניפסט my-omni.yaml על האשכול באמצעות כלי השירות kubectl:
kubectl apply -f my-omni.yaml
הפלט הצפוי במסוף:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
בודקים את הסטטוס של אשכול my-omni באמצעות כלי השירות kubectl:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
במהלך הפריסה, האשכול עובר שלבים שונים ובסופו של דבר אמור להגיע למצב DBClusterReady.
הפלט הצפוי במסוף:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
התחברות ל-AlloyDB Omni
חיבור באמצעות Kubernetes Pod
כשהאשכול מוכן, אפשר להשתמש בקובצי ההפעלה של לקוח PostgreSQL בתא של מכונת AlloyDB Omni. אנחנו מאתרים את מזהה הפוד ואז משתמשים ב-kubectl כדי להתחבר ישירות לפוד ולהפעיל תוכנת לקוח. הסיסמה היא VeryStrongPassword כפי שהוגדרה באמצעות סוד kubernetes במניפסט my-omni.yaml:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
פלט לדוגמה במסוף:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. פריסת מודל AI ב-GKE
כדי לבדוק את השילוב של AlloyDB Omni AI עם מודלים מקומיים, צריך לפרוס מודל באשכול. אנחנו נשתמש במודל EmbeddingGemma של Google.
יצירת מאגר צמתים למודל
כדי להריץ את המודל, צריך להכין מאגר צמתים להרצת היקש. אפשר להריץ אותו באמצעות מאגר של מעבדים בלבד או מאגר עם מאיצי GPU. גישה שמבוססת על CPU בלבד עשויה להיות מעשית יותר באזורים מסוימים בגלל רמת ה-concurrency הגבוהה של המשאבים. במעבדה שלנו נשתמש בגישת המעבד, אבל הגישה הכי טובה מבחינת ביצועים היא מאגר עם מאיצי גרפיקה באמצעות הגדרת צומת כמו g2-standard-8 עם מאיץ L4 Nvidia.
מאגר צמתים מבוסס-CPU
יוצרים מאגר צמתים עם צמתים מסוג e2-standard-32. כדי לחסוך במשאבים, נגביל את המשיכה שלנו לצומת אחד.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
הפלט הצפוי
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
קבלת טוקן של Hugging Face
בשיעור ה-Lab הזה נשתמש בשותפות עם Hugging Face כדי לפרוס את מודל EmbeddingGemma. לשם כך, נצטרך לקבל טוקן של Hugging Face.
אם אין לכם טוקן, אתם יכולים ליצור טוקן חדש לפי השלבים הבאים.
- מתחברים או נרשמים לאתר Hugging Face באמצעות הקישורים 'כניסה' או 'הרשמה' בפינה השמאלית העליונה.
- לוחצים על 'הפרופיל שלך' -> 'אסימוני גישה'.
- אימות זהותך
- לוחצים על 'יצירת טוקן חדש'.
- בחירת שם לטוקן
- בוחרים תפקיד לטוקן – נדרשת לפחות הרשאת קריאה
- לוחצים על 'יצירת טוקן' בתחתית הדף.
- מעתיקים את האסימון שנוצר ושומרים אותו לשימוש מאוחר יותר
בנוסף, צריך לאשר את התנאים כדי לגשת לקבצים ולתוכן שקשורים ל-EmbeddingGemma ב-Hugging Face בדף https://huggingface.co/google/embeddinggemma-300m.
יצירת סוד ב-Kubernetes באמצעות הטוקן
בסשן של Cloud Shell, מריצים את הפקודה (מחליפים את הערך של HF_TOKEN באסימון HF שלכם).
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
הכנת מניפסט הפריסה
כדי לפרוס את המודל, צריך להכין מניפסט פריסה.
אנחנו משתמשים במודל EmbeddingGemma של Google מ-Hugging Face. כרטיס המודל זמין כאן. כדי לפרוס את המודל, נשתמש בגישה שמבוססת על ההוראות של Hugging Face ועל חבילת הפריסה מ-GitHub.
שיבוט החבילה מ-GitHub
git clone https://github.com/huggingface/Google-Cloud-Containers
התאמת המניפסט ל-TEI (ממשק להטמעת טקסט) בצמתי CPU. אנחנו צריכים להחליף כמה פרמטרים, כולל המודל, התמונה, הקצאת המשאבים הנכונה, ולהוסיף את הסוד של טוקן Hugging Face להגדרה.
עורכים את קובץ המניפסט (באמצעות כל כלי עריכה זמין)
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
כאן מוצג קובץ מניפסט מתוקן לפריסה במאגר שמבוסס על מעבד.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
פריסת המודל
מבצעים פריסה של המודל על ידי החלת המניפסט ששונה על פריסות של מעבד.
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
אימות הפריסות
kubectl get pods
אימות של שירות המודל
kubectl get service tei-service
הוא אמור להציג את סוג השירות הפועל ClusterIP
פלט לדוגמה:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
כתובת ה-CLUSTER-IP של השירות היא הכתובת שבה נשתמש ככתובת נקודת הקצה. המודל להטמעה יכול להגיב באמצעות URI http://34.118.233.48:8080/embed. הוא ישמש אתכם בהמשך, כשתרשמו את המודל ב-AlloyDB Omni.
אפשר לבדוק את זה באמצעות חשיפה של האפליקציה באמצעות הפקודה kubectl port-forward.
kubectl port-forward service/tei-service 8080:8080
אם אתם משתמשים ב-Cloud Shell, העברת הפורטים יכולה לפעול בסשן אחד של Cloud Shell, ואנחנו צריכים סשן נוסף כדי לבדוק אותה.
פותחים כרטיסייה נוספת ב-Cloud Shell באמצעות הסימן '+' בחלק העליון.
מריצים פקודת curl בסשן החדש של המעטפת.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
הפונקציה אמורה להחזיר מערך וקטורי כמו בדוגמת הפלט הבאה (הוסר מידע):
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
אם נראה את המספרים, נוכל לאשר שבדקנו את המודל בהצלחה ועכשיו נוכל לרשום אותו ב-AlloyDB Omni שלנו כדי להשתמש בו ישירות מ-SQL.
6. רישום המודל ב-AlloyDB Omni
כדי לבדוק איך AlloyDB Omni פועל עם המודל שנפרס, צריך ליצור מסד נתונים ולרשום את המודל.
יצירת מסד נתונים
יוצרים מכונה וירטואלית ב-GCE כתיבת קפיצה כדי להתחבר ל-AlloyDB Omni מהמכונה הווירטואלית של הלקוח וליצור מסד נתונים.
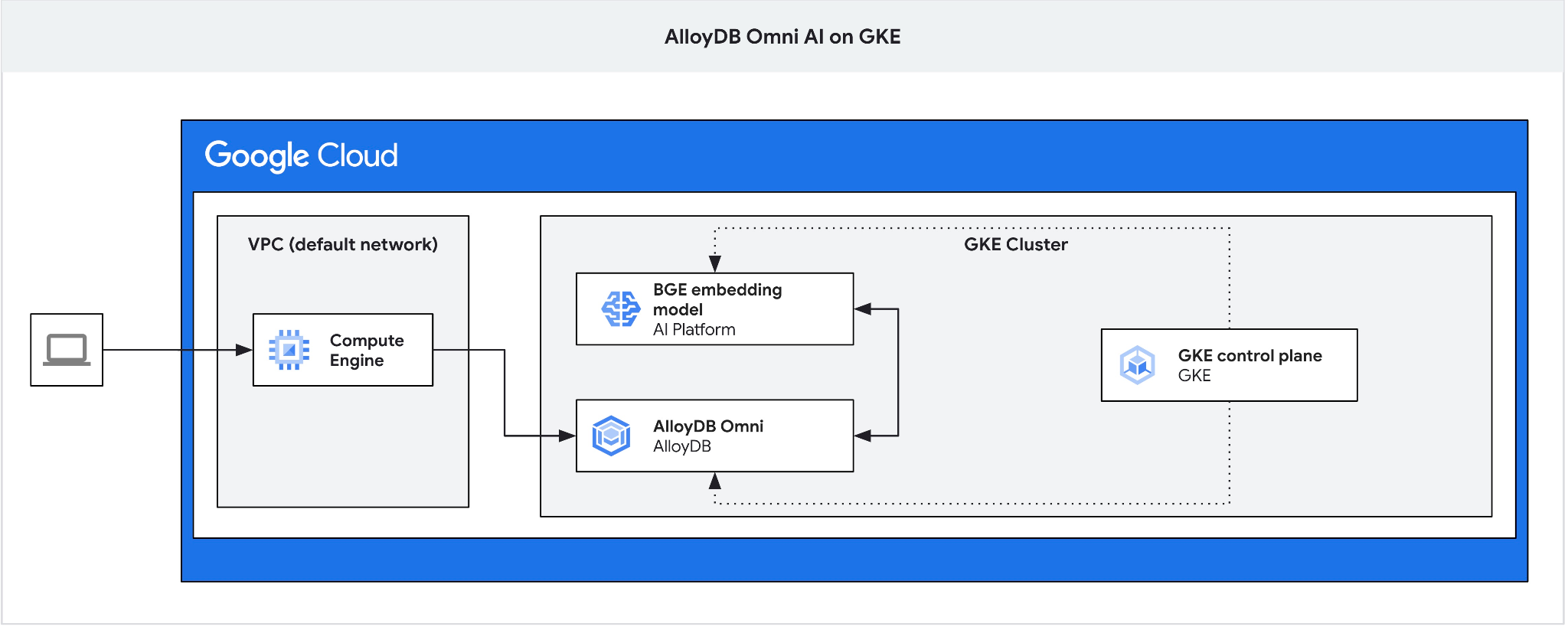
אנחנו צריכים את תיבת הניתוב כי מאזן העומסים החיצוני של GKE ל-Omni מאפשר גישה מ-VPC באמצעות כתובות IP פרטיות, אבל לא מאפשר להתחבר מחוץ ל-VPC. הוא מאובטח יותר באופן כללי, ולא חושף את מופע מסד הנתונים שלכם לאינטרנט. כדאי לעיין בתרשים לשם הבהרה.
כדי ליצור מכונה וירטואלית בסשן Cloud Shell, מריצים את הפקודה:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
כדי למצוא את כתובת ה-IP של נקודת הקצה של AlloyDB Omni באמצעות kubectl ב-Cloud Shell:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
רושמים את PRIMARYENDPOINT.
פלט לדוגמה:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33 הוא כתובת ה-IP שבה נשתמש בדוגמאות שלנו כדי להתחבר למופע AlloyDB Omni.
מתחברים למכונה הווירטואלית באמצעות gcloud:
gcloud compute ssh instance-1 --zone=$ZONE
אם מתבקשים ליצור מפתח SSH, פועלים לפי ההוראות. מידע נוסף על חיבור SSH מופיע במאמרי העזרה.
בסשן ה-SSH למכונה הווירטואלית, מתקינים את לקוח PostgreSQL:
sudo apt-get update
sudo apt-get install --yes postgresql-client
מייצאים את משתנה ה-IP של מאזן העומסים של AlloyDB Omni באמצעות הדוגמה הבאה (מחליפים את IP בכתובת ה-IP של מאזן העומסים):
export INSTANCE_IP=10.131.0.33
מתחברים ל-AlloyDB Omni, הסיסמה היא VeryStrongPassword כפי שהוגדרה באמצעות הגיבוב ב-my-omni.yaml:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
בסשן psql שנוצר, מריצים את הפקודה:
create database demo;
יוצאים מהסשן ומתחברים להדגמה של מסד הנתונים (או פשוט מריצים את הפקודה \c demo באותו סשן)
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
יצירת פונקציות טרנספורמציה
במקרה של מודלים להטמעה של צד שלישי, צריך ליצור פונקציות טרנספורמציה שמגדירות את הפורמט של הקלט והפלט לפורמט שהמודל והפונקציות הפנימיות שלנו מצפים לו. הפונקציות האלה פועלות כמתרגמות כדי לבצע המרת פורמט בין ממשקים שונים.
זו פונקציית הטרנספורמציה שמטפלת בקלט:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
מריצים את הקוד שמופיע בדוגמה של הפלט, בזמן שאתם מחוברים למסד הנתונים של ההדגמה:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
והנה פונקציית הפלט שממירה את התשובה מהמודל למערך של מספרים ממשיים:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
מריצים אותו באותו סשן:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
רישום המודל
עכשיו אפשר לרשום את המודל במסד הנתונים.
זו קריאת הפרוצדורה לרישום המודל עם השם embeddinggemma. אנחנו משתמשים בשם השירות tei-service בפרמטר model_request_url שלנו כשאנחנו רושמים את המודל. זהו שם השירות הפנימי של אשכול Kubernetes, והוא מתורגם לכתובת ה-IP הפנימית באשכול GKE:
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
מריצים את הקוד שסופק בזמן שמתחברים למסד הנתונים של ההדגמה:
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
אפשר לבדוק את מודל הרישום באמצעות שאילתת הבדיקה הבאה, שאמורה להחזיר מערך של מספרים אמיתיים.
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
אל תופתעו אם יעבור זמן רב עד שתקבלו את נתוני הווקטור. בבדיקה הזו אנחנו משתמשים במאגר צמתים מבוסס-CPU כדי לארח את מודל ההטמעה, והוא פועל הרבה יותר מהר בצמתים עם GPU.
7. בדיקת המודל ב-AlloyDB Omni
טעינת נתונים
כדי לבדוק איך AlloyDB Omni עובד עם המודל שפרסתם, צריך לטעון נתונים. השתמשתי באותם נתונים כמו באחד מה-codelab האחרים לחיפוש וקטורי ב-AlloyDB.
אחת מהדרכים לטעון את הנתונים היא באמצעות Google Cloud SDK ותוכנת הלקוח של PostgreSQL. אנחנו יכולים להשתמש באותה מכונה וירטואלית של הלקוח. אם השתמשתם בברירות המחדל לתמונת ה-VM, Google Cloud SDK כבר אמור להיות מותקן שם. אבל אם השתמשתם בתמונה בהתאמה אישית בלי Google SDK, תוכלו להוסיף אותה לפי המסמכים.
מייצאים את כתובת ה-IP של מאזן העומסים של AlloyDB Omni כמו בדוגמה הבאה (מחליפים את IP בכתובת ה-IP של מאזן העומסים):
export INSTANCE_IP=10.131.0.33
מתחברים למסד הנתונים ומפעילים את התוסף pgvector.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
בסשן psql:
CREATE EXTENSION IF NOT EXISTS vector;
יוצאים מהסשן של psql ובסשן של שורת הפקודה מריצים פקודות כדי לטעון את הנתונים למסד הנתונים של ההדגמה.
יוצרים את הטבלאות. הפקודה הבאה תוריד את הקובץ cymbal_demo_schema.sql ותריץ את ה-SQL עם כל הגדרות הטבלאות במסד הנתונים של ההדגמה:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
הפלט הצפוי במסוף:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
זו רשימת הטבלאות שנוצרו:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
פלט:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
טוענים נתונים לטבלה cymbal_products:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
הפלט הצפוי במסוף:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
הנה דוגמה לכמה שורות מהטבלה cymbal_products.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
פלט:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
טוענים נתונים לטבלה cymbal_inventory:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
הפלט הצפוי במסוף:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
הנה דוגמה לכמה שורות מהטבלה cymbal_inventory.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
פלט:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
טוענים נתונים לטבלה cymbal_stores:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
הפלט הצפוי במסוף:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
הנה דוגמה לכמה שורות מהטבלה cymbal_stores.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
פלט:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
יצירת הטמעות
מתחברים למסד הנתונים של ההדגמה באמצעות psql ויוצרים הטמעות למוצרים שמתוארים בטבלה cymbal_products על סמך תיאורי המוצרים.
מתחברים למסד הנתונים של ההדגמה:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
אנחנו משתמשים בטבלת cymbal_embedding עם הטמעת עמודות כדי לאחסן את ההטמעות, ואנחנו משתמשים בתיאור המוצר כקלט הטקסט לפונקציה.
מפעילים את התזמון של השאילתות כדי להשוות אותן בהמשך למודלים מרוחקים.
\timing
מריצים את השאילתה כדי ליצור את ההטמעות:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
הפלט הצפוי במסוף:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
בדוגמה הזו, יצירת ההטמעות נמשכה כ-8 דקות. זה צפוי למאגר צמתים שמבוסס על מעבד. במאגר עם מאיצי GPU, יכול להיות שהפעולה תהיה מהירה משמעותית, בהתאם לסוג ה-GPU.
הרצת שאילתות בדיקה
מתחברים למסד הנתונים של ההדגמה באמצעות psql ומפעילים את התזמון כדי למדוד את זמן הביצוע של השאילתות, כמו שעשינו כשבנינו את ההטמעות.
נניח שאנחנו רוצים למצוא את 5 המוצרים המובילים שתואמים לבקשה כמו "אילו עצי פרי גדלים טוב באזור הזה?" באמצעות מרחק קוסינוס כאלגוריתם לחיפוש וקטורי.
בסשן psql, מריצים את הפקודה:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
הפלט הצפוי במסוף:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
השאילתה רצה במשך 83 אלפיות השנייה והחזירה רשימה של עצים מהטבלה cymbal_products שתואמים לבקשה, ושיש להם מלאי זמין בחנות עם המספר 1583.
יצירת אינדקס ANN
אם יש לנו רק קבוצת נתונים קטנה, קל להשתמש בחיפוש מדויק שסורק את כל ההטמעות, אבל ככל שהנתונים גדלים, זמן הטעינה והתגובה מתארכים. כדי לשפר את הביצועים, אפשר ליצור אינדקסים על נתוני ההטמעה. הנה דוגמה לאופן שבו אפשר לעשות זאת באמצעות אינדקס Google ScaNN לנתוני וקטורים.
אם החיבור למסד הנתונים של ההדגמה אבד, צריך להתחבר אליו מחדש:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
מפעילים את התוסף alloydb_scann:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
יוצרים את האינדקס:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
מנסים להריץ את אותה שאילתה כמו קודם ומשווים את התוצאות:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
זמן ההמתנה לביצוע השאילתה התקצר מעט, והשיפור הזה יהיה מורגש יותר במערכי נתונים גדולים יותר. התוצאות דומות מאוד וקיבלנו את אותם 5 עצים מובילים בתוצאה.
אפשר לנסות שאילתות אחרות ולקרוא מידע נוסף על בחירת אינדקס וקטורי במסמכי התיעוד.
בנוסף, ל-AlloyDB Omni יש עוד תכונות ו-Labs.
8. ניקוי הסביבה
עכשיו אפשר למחוק את אשכול GKE עם AlloyDB Omni ומודל AI
מחיקה של אשכול GKE
ב-Cloud Shell, מריצים את הפקודה:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
הפלט הצפוי במסוף:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
מחיקת מכונת VM
ב-Cloud Shell, מריצים את הפקודה:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
הפלט הצפוי במסוף:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
אם יצרתם פרויקט חדש בשביל ה-Codelab הזה, אתם יכולים למחוק את הפרויקט כולו: https://console.cloud.google.com/cloud-resource-manager
9. מזל טוב
כל הכבוד, סיימתם את ה-Codelab.
מה נכלל
- איך פורסים את AlloyDB Omni באשכול Google Kubernetes
- איך מתחברים ל-AlloyDB Omni
- איך טוענים נתונים ל-AlloyDB Omni
- איך פורסים מודל הטמעה פתוח ב-GKE
- איך רושמים מודל הטמעה ב-AlloyDB Omni
- איך ליצור הטמעות לחיפוש סמנטי
- איך משתמשים בהטמעות שנוצרו לחיפוש סמנטי ב-AlloyDB Omni
- איך יוצרים אינדקסים של וקטורים ב-AlloyDB ואיך משתמשים בהם
מידע נוסף על עבודה עם AI ב-AlloyDB Omni זמין בתיעוד.
10. סקר
פלט: