
1. はじめに
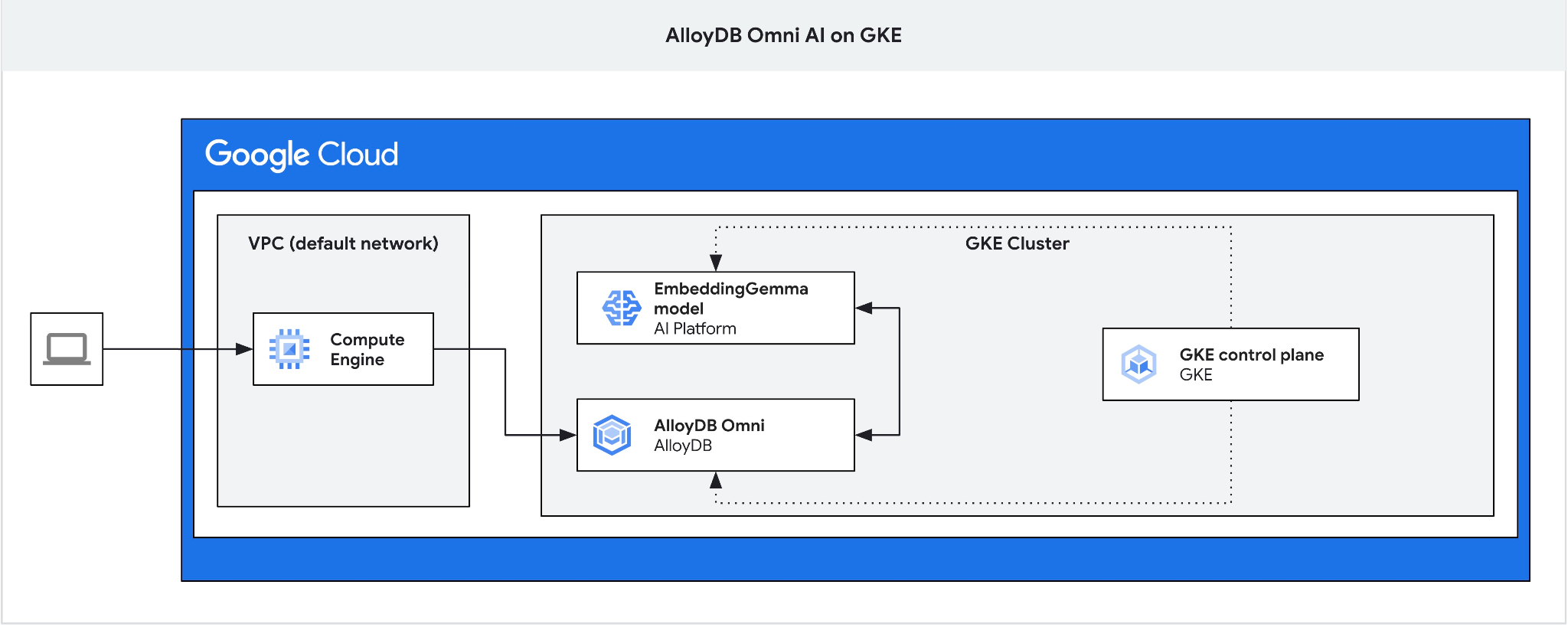
この Codelab では、GKE に AlloyDB Omni をデプロイし、同じ Kubernetes クラスタにデプロイされたオープン エンベディング モデルで使用する方法について学習します。同じ GKE クラスタ内のデータベース インスタンスの横にモデルをデプロイすると、レイテンシとサードパーティ サービスへの依存関係が軽減されます。また、データが組織外に漏洩してはならない場合や、サードパーティ サービスの利用が許可されていない場合、セキュリティとコンプライアンスによってローカル デプロイが要件として設定されることもあります。
前提条件
- Google Cloud とコンソールの基本的な知識
- Kubernetes と GKE の基礎知識
- コマンドライン インターフェースと Cloud Shell の基本的なスキル
学習内容
- Google Kubernetes クラスタに AlloyDB Omni をデプロイする方法
- AlloyDB Omni に接続する方法
- AlloyDB Omni にデータを読み込む方法
- オープン エンベディング モデルを GKE にデプロイする方法
- AlloyDB Omni にエンベディング モデルを登録する方法
- セマンティック検索用のエンベディングを生成する方法
- AlloyDB Omni で生成されたエンベディングをセマンティック検索に使用する方法
- AlloyDB でベクトル インデックスを作成して使用する方法
必要なもの
- Google Cloud アカウントと Google Cloud プロジェクト
- Google Cloud コンソールと Cloud Shell をサポートするウェブブラウザ(Chrome など)
2. 設定と要件
プロジェクトのセットアップ
- Google Cloud コンソールにログインします。Gmail アカウントも Google Workspace アカウントもまだお持ちでない場合は、アカウントを作成してください。
仕事用または学校用のアカウントではなく、個人用のアカウントを使用します。
- 新しいプロジェクトを作成するか、既存のプロジェクトを再利用します。Google Cloud コンソールで新しいプロジェクトを作成するには、ヘッダーで [プロジェクトを選択] ボタンをクリックします。ポップアップ ウィンドウが開きます。

[プロジェクトを選択] ウィンドウで [新しいプロジェクト] ボタンを押すと、新しいプロジェクトのダイアログ ボックスが開きます。
ダイアログ ボックスで、任意のプロジェクト名を入力し、ロケーションを選択します。
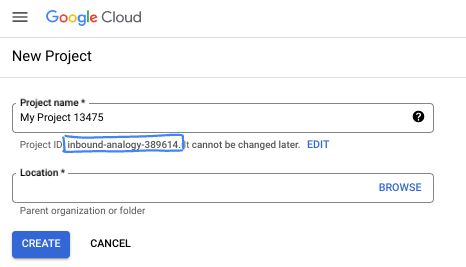
- プロジェクト名は、このプロジェクトの参加者に表示される名称です。プロジェクト名は Google API では使用されず、いつでも変更できます。
- プロジェクト ID は、すべての Google Cloud プロジェクトにおいて一意でなければならず、不変です(設定後は変更できません)。Google Cloud コンソールでは一意の ID が自動的に生成されますが、カスタマイズすることもできます。生成された ID が気に入らない場合は、別のランダムな ID を生成するか、独自の ID を指定して使用可能かどうかを確認できます。ほとんどの Codelab では、プロジェクト ID を参照する必要があります。通常、プロジェクト ID はプレースホルダ PROJECT_ID で識別されます。
- なお、3 つ目の値として、一部の API が使用するプロジェクト番号があります。これら 3 つの値について詳しくは、こちらのドキュメントをご覧ください。
課金を有効にする
個人用の請求先アカウントを設定する
Google Cloud クレジットを使用して課金を設定した場合は、この手順をスキップできます。
個人用の請求先アカウントを設定するには、Cloud コンソールでこちらに移動して課金を有効にします。
注意事項:
- このラボを完了するのにかかる Cloud リソースの費用は 3 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、それ以上の料金は発生しません。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud Console で、右上のツールバーにある Cloud Shell アイコンをクリックします。
または、G キーを押してから S キーを押します。このシーケンスは、Google Cloud コンソール内からアクセスした場合、またはこのリンクを使用した場合に Cloud Shell をアクティブにします。
プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
3. はじめに
API を有効にする
出力:
AlloyDB Omni とオープンモデルのデプロイに Google Kubernetes Engine(GKE)を使用するには、Google Cloud プロジェクトでそれぞれの API を有効にする必要があります。
Cloud Shell で、プロジェクト ID が設定されていることを確認します。
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Cloud Shell 構成で定義されていない場合は、次のコマンドを使用して設定します。
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
必要なサービスをすべて有効にします。
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
想定される出力
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
API の概要
- Kubernetes Engine API(
container.googleapis.com)を使用すると、Google Kubernetes Engine(GKE)クラスタを作成して管理できます。Google のインフラストラクチャを使用して、コンテナ化されたアプリケーションのデプロイ、管理、スケーリングを行えるマネージド環境を提供します。 - Compute Engine API(
compute.googleapis.com)を使用すると、仮想マシン(VM)、永続ディスク、ネットワーク設定を作成して管理できます。これは、ワークロードの実行と、多くのマネージド サービスの基盤となるインフラストラクチャのホストに必要な、Infrastructure-as-a-Service(IaaS)の基盤となるものです。
4. GKE に AlloyDB Omni をデプロイする
GKE に AlloyDB Omni をデプロイするには、AlloyDB Omni Operator の要件に記載されている要件に従って Kubernetes クラスタを準備する必要があります。
GKE クラスタを作成する
AlloyDB Omni インスタンスを含む Pod をデプロイするのに十分なプール構成で、標準の GKE クラスタをデプロイする必要があります。AlloyDB Omni には、少なくとも 2 つの CPU と 8 GB の RAM が必要です。また、オペレーターとモニタリング サービスのコンテナ用の空き容量も必要です。ここでは、e2-standard-4 VM タイプを使用します。
デプロイの環境変数を設定します。
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
次に、gcloud を使用して GKE Standard クラスタを作成します。
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
想定されるコンソール出力:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
クラスタを準備する
cert-manager サービス(kubernetes のネイティブ証明書マネージャー)などの必要なコンポーネントをインストールする必要があります。cert-manager のインストールに関するドキュメントの手順に沿って操作します。
Kubernetes コマンドライン ツール kubectl を使用します。これは、デフォルトで Cloud Shell にインストールされています。ユーティリティを使用する前に、クラスタの認証情報を取得する必要があります。
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
kubectl を使用して cert-manager をインストールできるようになりました。
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
想定されるコンソール出力(秘匿化済み):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
AlloyDB Omni をインストール
AlloyDB Omni Operator は、helm ユーティリティを使用してインストールできます。
次のコマンドを実行して、AlloyDB Omni Operator をインストールします。
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
想定されるコンソール出力(秘匿化済み):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
AlloyDB Omni Operator がインストールされたら、データベース クラスタのデプロイに進みます。
googleMLExtension パラメータと内部(プライベート)ロードバランサが有効になっているデプロイ マニフェストの例を次に示します。
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
パスワードのシークレット値は、パスワード「VeryStrongPassword」の Base64 表現です。より信頼性の高い方法は、Google Secret Manager を使用してパスワード値を保存することです。詳しくは、こちらのドキュメントをご覧ください。
次のステップで適用するために、マニフェストを my-omni.yaml として保存します。Cloud Shell を使用している場合は、ターミナルの右上にある [エディタを開く] ボタンを押してエディタを使用します。
my-omni.yaml という名前でファイルを保存したら、[ターミナルを開く] ボタンを押してターミナルに戻ります。
kubectl ユーティリティを使用して、my-omni.yaml マニフェストをクラスタに適用します。
kubectl apply -f my-omni.yaml
想定されるコンソール出力:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
kubectl ユーティリティを使用して、my-omni クラスタのステータスを確認します。
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
デプロイ中、クラスタはさまざまなフェーズを経て、最終的に DBClusterReady 状態になります。
想定されるコンソール出力:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
AlloyDB Omni に接続する
Kubernetes Pod を使用して接続する
クラスタの準備ができたら、AlloyDB Omni インスタンス Pod で PostgreSQL クライアント バイナリを使用できます。Pod ID を見つけてから、kubectl を使用して Pod に直接接続し、クライアント ソフトウェアを実行します。パスワードは、my-omni.yaml マニフェストの Kubernetes Secret で設定されている VeryStrongPassword です。
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
コンソールの出力例:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. GKE に AI モデルをデプロイする
ローカルモデルで AlloyDB Omni AI インテグレーションをテストするには、モデルをクラスタにデプロイする必要があります。Google の EmbeddingGemma モデルを使用します。
モデルのノードプールを作成する
モデルを実行するには、推論を実行するノードプールを準備する必要があります。CPU のみのプールまたは GPU アクセラレータを含むプールを使用して実行できます。リソースの同時実行性が高いため、一部の地域では CPU のみのアプローチがより実現可能になる可能性があります。このラボでは CPU アプローチを使用しますが、パフォーマンスの観点から最適なアプローチは、L4 Nvidia アクセラレータで g2-standard-8 などのノード構成を使用するグラフィック アクセラレータを含むプールです。
CPU ベースのノードプール
e2-standard-32 ノードを含むノードプールを作成します。リソースを節約するため、プルを 1 つのノードに制限します。
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
想定される出力
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
Hugging Face トークンを取得する
このラボでは、Hugging Face とのパートナーシップを利用して EmbeddingGemma モデルをデプロイします。そのためには、Hugging Face トークンを取得する必要があります。
トークンをまだ生成していない場合は、次の手順に沿って生成します。
- Hugging Face サイトの右上にある [Log In](ログイン)または [Sign Up](登録)リンクを使用して、ログインまたは登録します。
- [Your Profile] -> [Access Tokens] をクリックします。
- 本人確認
- [Create new token] をクリックします
- トークンの名前を選択する
- トークンのロールを選択します。少なくとも読み取り権限が必要です。
- ページの下部にある [トークンを作成] をクリックします。
- 生成されたトークンをコピーして、後で使用できるように保存します。
また、Hugging Face の EmbeddingGemma に関連するファイルとコンテンツにアクセスするには、https://huggingface.co/google/embeddinggemma-300m のページで条件に同意する必要があります。
トークンを使用して Kubernetes Secret を作成する
Cloud Shell セッションで実行します(HF_TOKEN の値は実際の HF トークンに置き換えてください)。
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
Deployment マニフェストを準備する
モデルをデプロイするには、デプロイ マニフェストを準備する必要があります。
Hugging Face の Google の EmbeddingGemma モデルを使用しています。モデルカードはこちらでご覧いただけます。モデルをデプロイするには、Hugging Face の手順と GitHub のデプロイ パッケージに基づくアプローチを使用します。
GitHub からパッケージのクローンを作成する
git clone https://github.com/huggingface/Google-Cloud-Containers
CPU ノードの tei(テキスト エンベディング インターフェース)のマニフェストを調整します。モデル、イメージ、正しいリソース割り当てなどのいくつかのパラメータを置き換え、Hugging Face トークン シークレットを構成に追加する必要があります。
マニフェストを編集する(利用可能なエディタを使用)
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
CPU ベースのプールにデプロイするための修正されたマニフェストを次に示します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
モデルをデプロイする
CPU デプロイ用に変更したマニフェストを適用して、モデルをデプロイします。
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
デプロイを確認する
kubectl get pods
モデルサービスを確認する
kubectl get service tei-service
実行中の Service タイプ ClusterIP が表示されます。
出力例:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
サービス用の CLUSTER-IP をエンドポイント アドレスとして使用します。モデル エンベディングは、URI http://34.118.233.48:8080/embed で応答できます。これは、後で AlloyDB Omni にモデルを登録するときに使用されます。
kubectl port-forward コマンドを使用して公開することで、テストできます。
kubectl port-forward service/tei-service 8080:8080
Cloud Shell を使用している場合、ポート転送は 1 つの Cloud Shell セッションで実行できます。テストするには別のセッションが必要です。
上部の「+」記号を選択して、別の Cloud Shell タブを開きます。
新しいシェル セッションで curl コマンドを実行します。
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
次のサンプル出力(編集済み)のようなベクトル配列が返されます。
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
数値が表示されれば、モデルのテストが成功し、AlloyDB Omni に登録して SQL から直接使用できることを確認できます。
6. AlloyDB Omni にモデルを登録する
AlloyDB Omni がデプロイされたモデルと連携して動作するかどうかをテストするには、データベースを作成してモデルを登録する必要があります。
データベースを作成する
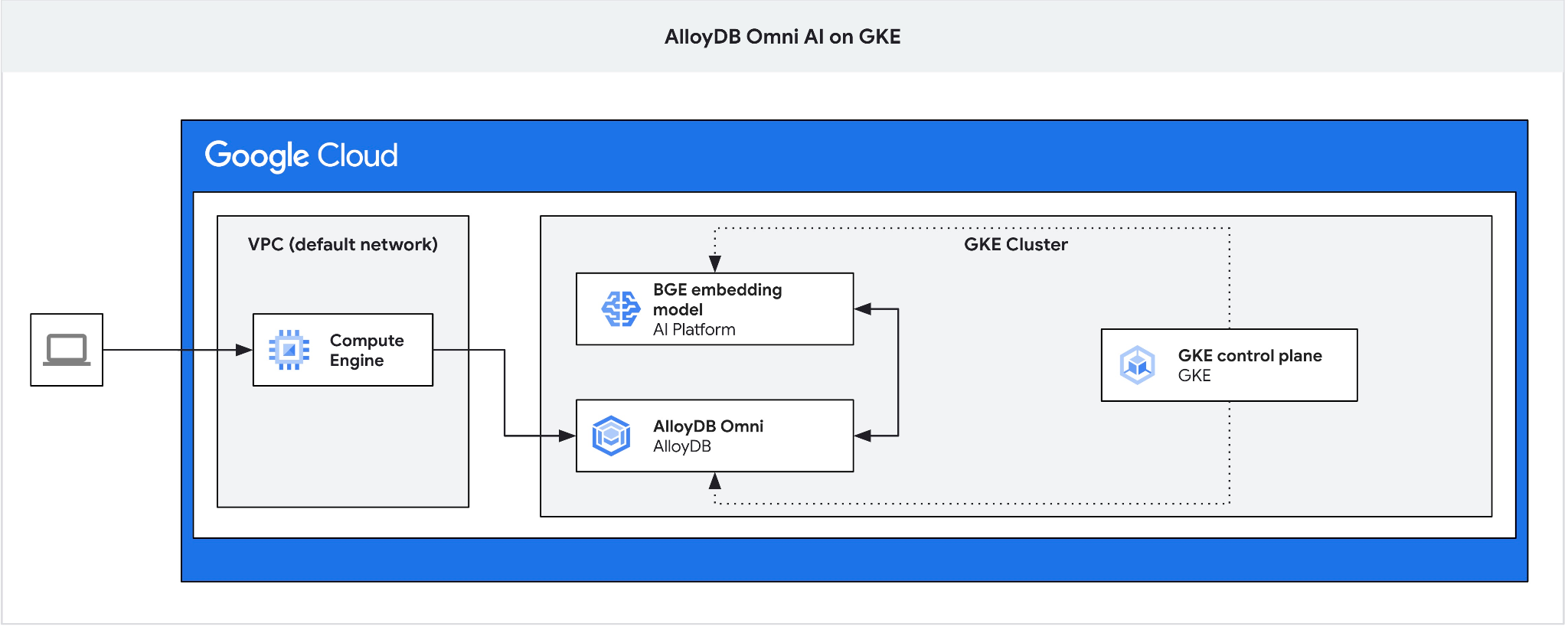
クライアント VM から AlloyDB Omni に接続してデータベースを作成するためのジャンプボックスとして GCE VM を作成します。
Omni の GKE 外部ロードバランサは、プライベート IP アドレスを使用して VPC からアクセスできますが、VPC の外部から接続することはできません。そのため、ジャンプボックスが必要です。一般的にセキュリティが高く、データベース インスタンスがインターネットに公開されません。図でご確認ください。
Cloud Shell セッションで VM を作成するには、次のコマンドを実行します。
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
Cloud Shell で kubectl を使用して AlloyDB Omni エンドポイントの IP を見つけます。
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
PRIMARYENDPOINT をメモします。
出力の例を次に示します。
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33 は、AlloyDB Omni インスタンスに接続するために例で使用する IP です。
gcloud を使用して VM に接続します。
gcloud compute ssh instance-1 --zone=$ZONE
SSH 認証鍵の生成を求められたら、手順に沿って操作します。SSH 接続の詳細については、ドキュメントをご覧ください。
VM への ssh セッションで、PostgreSQL クライアントをインストールします。
sudo apt-get update
sudo apt-get install --yes postgresql-client
次の例を使用して、AlloyDB Omni ロードバランサの IP 変数をエクスポートします(IP はロードバランサの IP に置き換えます)。
export INSTANCE_IP=10.131.0.33
AlloyDB Omni に接続します。パスワードは my-omni.yaml のハッシュで設定された VeryStrongPassword です。
psql "host=$INSTANCE_IP user=postgres sslmode=require"
確立された psql セッションで、次のコマンドを実行します。
create database demo;
セッションを終了してデータベース デモに接続します(または、同じセッションで \c demo を実行することもできます)。
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
変換関数を作成する
サードパーティのエンベディング モデルの場合、モデルと内部関数で想定される形式に入力と出力をフォーマットする変換関数を作成する必要があります。これらの関数は、異なるインターフェース間で形式変換を行うための変換ツールとして機能します。
入力処理を行う変換関数は次のとおりです。
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
サンプル出力に示すように、デモ データベースに接続した状態で、提供されたコードを実行します。
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
モデルからのレスポンスを実数の配列に変換する出力関数は次のとおりです。
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
同じセッションで実行します。
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
モデルを登録する
これで、モデルをデータベースに登録できます。
モデルを名前 embeddinggemma で登録するプロシージャ呼び出しは次のとおりです。モデルを登録するときに、model_request_url パラメータで tei-service サービス名を使用します。これは内部 Kubernetes クラスタ サービス名で、GKE クラスタの内部 IP に変換されます。
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
デモ データベースに接続した状態で、提供されたコードを実行します。
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
次のテストクエリを使用して、登録モデルをテストできます。このクエリは実数の配列を返します。
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
ベクトルデータが返ってくるまでに時間がかかっても、驚かないでください。このテストでは、エンベディング モデルをホストするために CPU ベースのノードプールを使用します。GPU を搭載したノードでは、はるかに高速に動作します。
7. AlloyDB Omni でモデルをテストする
データの読み込み
AlloyDB Omni がデプロイされたモデルとどのように連携するかをテストするには、データを読み込む必要があります。AlloyDB のベクトル検索に関する他の Codelab の 1 つと同じデータを使用しました。
データを読み込む方法の 1 つは、Google Cloud SDK と PostgreSQL クライアント ソフトウェアを使用することです。同じクライアント VM を使用できます。VM イメージのデフォルトを使用している場合は、Google Cloud SDK がすでにインストールされています。ただし、Google SDK を使用せずにカスタム イメージを使用している場合は、ドキュメントに沿って追加できます。
次の例のように AlloyDB Omni ロードバランサの IP をエクスポートします(IP はロードバランサの IP に置き換えます)。
export INSTANCE_IP=10.131.0.33
データベースに接続し、pgvector 拡張機能を有効にします。
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
psql セッションで次の操作を行います。
CREATE EXTENSION IF NOT EXISTS vector;
psql セッションを終了し、コマンドライン セッションでコマンドを実行して、デモ データベースにデータを読み込みます。
テーブルを作成します。次のコマンドは、cymbal_demo_schema.sql ファイルを取得し、デモ データベース内のすべてのテーブル定義を使用して SQL を実行します。
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
想定されるコンソール出力:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
作成されたテーブルのリストは次のとおりです。
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
出力:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
cymbal_products テーブルにデータを読み込みます。
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
想定されるコンソール出力:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
cymbal_products テーブルの数行のサンプルを次に示します。
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
出力:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
cymbal_inventory テーブルにデータを読み込みます。
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
想定されるコンソール出力:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
cymbal_inventory テーブルの数行のサンプルを次に示します。
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
出力:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
cymbal_stores テーブルにデータを読み込みます。
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
想定されるコンソール出力:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
cymbal_stores テーブルの数行のサンプルを次に示します。
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
出力:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
エンベディングを構築する
psql を使用してデモ データベースに接続し、cymbal_products テーブルに記述されている商品のエンベディングを商品説明に基づいて構築します。
デモ データベースに接続します。
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
ここでは、列エンベディングを含む cymbal_embedding テーブルを使用してエンベディングを保存し、関数へのテキスト入力として商品説明を使用しています。
クエリのタイミングを有効にして、後でリモートモデルと比較します。
\timing
クエリを実行してエンベディングを構築します。
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
想定されるコンソール出力:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
この例では、エンベディングの構築に約 8 分かかりました。これは、CPU ベースのノードプールでは想定されることです。GPU アクセラレータを使用するプールの場合、GPU のタイプによっては大幅に高速化できます。
テストクエリを実行する
psql を使用してデモ データベースに接続し、エンベディングの構築と同様に、クエリの実行時間を測定するためのタイミングを有効にします。
ベクトル検索のアルゴリズムとしてコサイン距離を使用して、「この地域でよく育つ果樹は何ですか?」というリクエストに一致する上位 5 つの商品を見つけます。
psql セッションで、次のコマンドを実行します。
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
想定されるコンソール出力:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
クエリは 83 ミリ秒で実行され、リクエストに一致し、番号 1583 の店舗で在庫がある cymbal_products テーブルのツリーのリストを返しました。
ANN インデックスを構築する
データセットが小さい場合は、すべてのエンベディングをスキャンする完全一致検索を簡単に使用できますが、データが増加すると、読み込み時間と応答時間も増加します。パフォーマンスを向上させるには、エンベディング データにインデックスを作成します。ベクトルデータに Google ScaNN インデックスを使用してこれを行う方法の例を次に示します。
接続が切断された場合は、デモ データベースに再接続します。
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
alloydb_scann 拡張機能を有効にします。
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
インデックスをビルドします。
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
前と同じクエリを試して、結果を比較します。
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
クエリの実行時間がわずかに短縮されました。この効果は、大規模なデータセットでより顕著になります。結果は非常に似ており、上位 5 つのツリーは同じでした。
別のクエリを試して、ドキュメントでベクトル インデックスの選択について詳しくご覧ください。
AlloyDB Omni には、さらに多くの機能とラボがあります。
8. 環境をクリーンアップする
これで、AlloyDB Omni と AI モデルを使用して GKE クラスタを削除できます。
GKE クラスタを削除する
Cloud Shell で、次のコマンドを実行します。
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
想定されるコンソール出力:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
VM の削除
Cloud Shell で、次のコマンドを実行します。
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
想定されるコンソール出力:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
この Codelab 用に新しいプロジェクトを作成した場合は、代わりにプロジェクト全体を削除できます。https://console.cloud.google.com/cloud-resource-manager
9. 完了
以上で、この Codelab は完了です。
学習した内容
- Google Kubernetes クラスタに AlloyDB Omni をデプロイする方法
- AlloyDB Omni に接続する方法
- AlloyDB Omni にデータを読み込む方法
- オープン エンベディング モデルを GKE にデプロイする方法
- AlloyDB Omni にエンベディング モデルを登録する方法
- セマンティック検索用のエンベディングを生成する方法
- AlloyDB Omni で生成されたエンベディングをセマンティック検索に使用する方法
- AlloyDB でベクトル インデックスを作成して使用する方法
AlloyDB Omni での AI の使用について詳しくは、ドキュメントをご覧ください。
10. アンケート
出力: