
1. Wprowadzenie
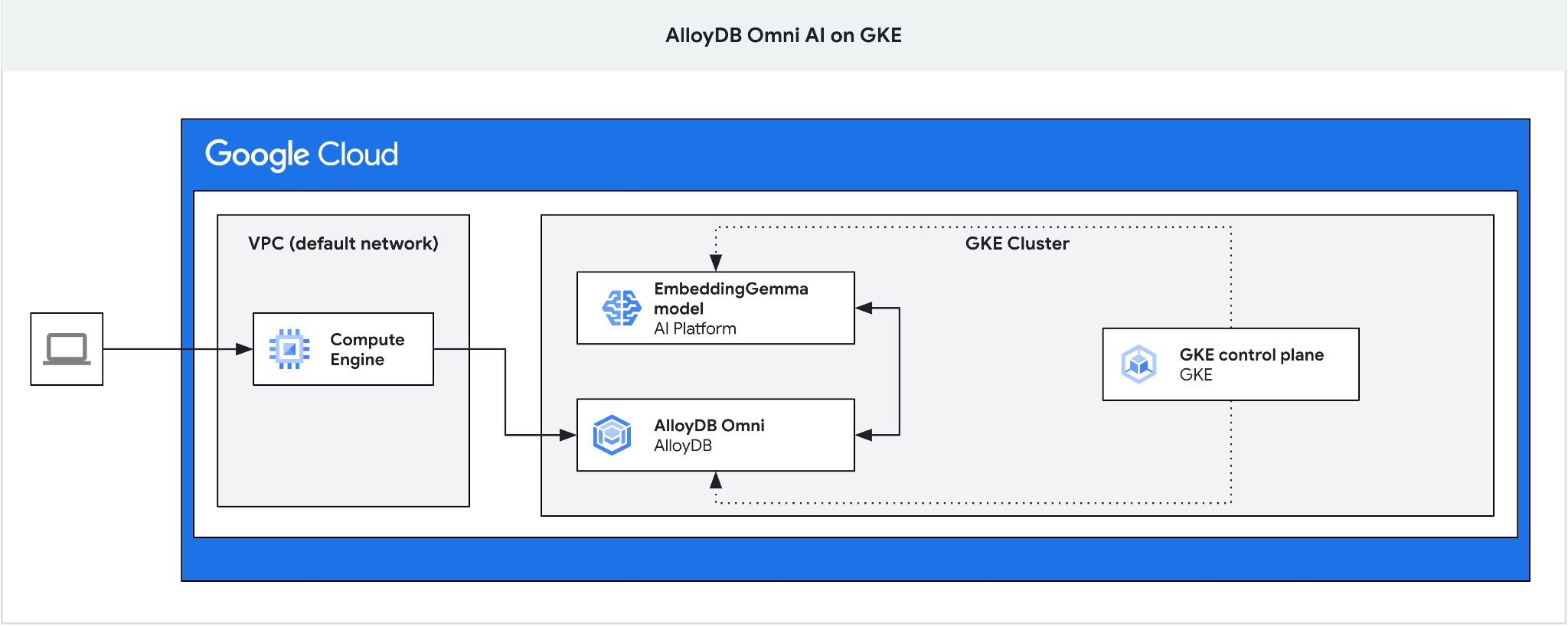
Z tego ćwiczenia w Codelabs dowiesz się, jak wdrożyć oprogramowanie AlloyDB Omni w GKE i używać go z otwartym modelem wektora dystrybucyjnego wdrożonym w tym samym klastrze Kubernetes. Wdrożenie modelu obok instancji bazy danych w tym samym klastrze GKE zmniejsza opóźnienia i zależności od usług innych firm. Dodatkowo wdrożenie lokalne może być wymaganiem dotyczącym bezpieczeństwa i zgodności, gdy dane nie powinny opuszczać organizacji, a korzystanie z usług innych firm jest niedozwolone.
Wymagania wstępne
- Podstawowa wiedza o Google Cloud i konsoli
- Podstawowa znajomość Kubernetes i GKE
- Podstawowe umiejętności w zakresie interfejsu wiersza poleceń i Cloud Shell
Czego się nauczysz
- Jak wdrożyć AlloyDB Omni w klastrze Google Kubernetes
- Jak połączyć się z AlloyDB Omni
- Wczytywanie danych do AlloyDB Omni
- Jak wdrożyć otwarty model wektora dystrybucyjnego w GKE
- Jak zarejestrować model wektora dystrybucyjnego w AlloyDB Omni
- Jak generować wektory dystrybucyjne na potrzeby wyszukiwania semantycznego
- Jak używać wygenerowanych wektorów dystrybucyjnych do wyszukiwania semantycznego w AlloyDB Omni
- Jak tworzyć i używać indeksów wektorowych w AlloyDB
Czego potrzebujesz
- Konto Google Cloud i projekt Google Cloud
- przeglądarka internetowa, np. Chrome, obsługująca konsolę Google Cloud i Cloud Shell;
2. Konfiguracja i wymagania
Konfiguracja projektu
- Zaloguj się w konsoli Google Cloud. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
- Utwórz nowy projekt lub użyj istniejącego. Aby utworzyć nowy projekt w konsoli Google Cloud, w nagłówku kliknij przycisk Wybierz projekt. Otworzy się okno wyskakujące.

W oknie Wybierz projekt kliknij przycisk Nowy projekt, który otworzy okno dialogowe nowego projektu.
W oknie dialogowym wpisz preferowaną nazwę projektu i wybierz lokalizację.
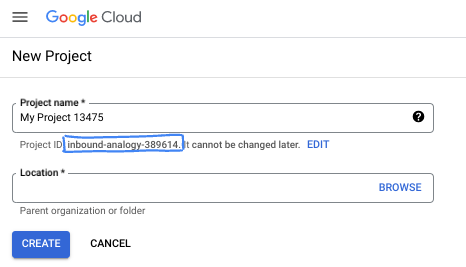
- Nazwa projektu to wyświetlana nazwa uczestników tego projektu. Nazwa projektu nie jest używana przez interfejsy API Google i można ją w każdej chwili zmienić.
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Google Cloud automatycznie generuje unikalny identyfikator, ale możesz go dostosować. Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować kolejny losowy identyfikator lub podać własny, aby sprawdzić jego dostępność. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu, który jest zwykle oznaczony symbolem zastępczym PROJECT_ID.
- Warto wiedzieć, że istnieje też trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
Włącz płatności
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w konsoli Google Cloud.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 3 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym module praktycznym będziesz używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Możesz też nacisnąć G, a potem S. Ta sekwencja aktywuje Cloud Shell, jeśli korzystasz z konsoli Google Cloud. Możesz też użyć tego linku.
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Zanim zaczniesz
Włącz API
Dane wyjściowe:
Aby używać Google Kubernetes Engine (GKE) do wdrażania AlloyDB Omni i otwartych modeli, musisz włączyć odpowiednie interfejsy API w projekcie Google Cloud.
W Cloud Shell sprawdź, czy identyfikator projektu jest skonfigurowany:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Jeśli nie jest zdefiniowany w konfiguracji Cloud Shell, skonfiguruj go za pomocą tych poleceń:
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Włącz wszystkie niezbędne usługi:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
Oczekiwane dane wyjściowe
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Przedstawiamy interfejsy API
- Kubernetes Engine API (
container.googleapis.com) umożliwia tworzenie klastrów Google Kubernetes Engine (GKE) i zarządzanie nimi. Jest to zarządzane środowisko służące do wdrażania i skalowania skonteneryzowanych aplikacji oraz do zarządzania nimi przy użyciu infrastruktury Google. - Compute Engine API (
compute.googleapis.com) umożliwia tworzenie maszyn wirtualnych, dysków trwałych i ustawień sieciowych oraz zarządzanie nimi. Zapewnia podstawową infrastrukturę jako usługę (IaaS) potrzebną do uruchamiania zbiorów zadań i hostowania infrastruktury bazowej dla wielu usług zarządzanych.
4. Wdrażanie AlloyDB Omni w GKE
Aby wdrożyć AlloyDB Omni w GKE, musimy przygotować klaster Kubernetes zgodnie z wymaganiami wymienionymi w sekcji Wymagania dotyczące operatora AlloyDB Omni.
Tworzenie klastra GKE
Musimy wdrożyć standardowy klaster GKE z konfiguracją puli wystarczającą do wdrożenia poda z instancją AlloyDB Omni. W przypadku AlloyDB Omni potrzebujemy co najmniej 2 procesorów i 8 GB pamięci RAM oraz trochę miejsca na kontenery operatora i usług monitorowania. Użyjemy typu maszyny wirtualnej e2-standard-4.
Skonfiguruj zmienne środowiskowe wdrożenia.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
Następnie używamy gcloud do utworzenia klastra standardowego GKE.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
Przygotowywanie klastra
Musimy zainstalować wymagane komponenty, takie jak usługa cert-manager – natywny menedżer certyfikatów dla Kubernetes. Możemy wykonać czynności opisane w dokumentacji dotyczącej instalacji cert-manager.
Używamy narzędzia wiersza poleceń Kubernetes, kubectl, które jest domyślnie zainstalowane w Cloud Shell. Zanim użyjemy narzędzia, musimy uzyskać dane logowania do naszego klastra.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
Teraz możemy użyć narzędzia kubectl do zainstalowania cert-manager:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
Oczekiwane dane wyjściowe konsoli(zredagowane):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
Instalowanie AlloyDB Omni
Operatora AlloyDB Omni można zainstalować za pomocą narzędzia Helm.
Aby zainstalować operatora AlloyDB Omni, uruchom to polecenie:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
Oczekiwane dane wyjściowe konsoli(zredagowane):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
Po zainstalowaniu operatora AlloyDB Omni możemy wdrożyć klaster bazy danych.
Oto przykład manifestu wdrożenia z włączonym parametrem googleMLExtension i wewnętrznym (prywatnym) systemem równoważenia obciążenia:
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
Wartość tajna hasła to reprezentacja Base64 słowa „VeryStrongPassword”. Bardziej niezawodnym sposobem jest użycie Menedżera tajnych danych Google do przechowywania wartości hasła. Więcej informacji na ten temat znajdziesz w dokumentacji.
Zapisz plik manifestu jako my-omni.yaml, aby zastosować go w następnym kroku. Jeśli korzystasz z Cloud Shell, możesz to zrobić w edytorze, klikając przycisk „Otwórz edytor” w prawym górnym rogu terminala.
Po zapisaniu pliku pod nazwą my-omni.yaml wróć do terminala, naciskając przycisk „Open Terminal” (Otwórz terminal).
Zastosuj plik manifestu my-omni.yaml do klastra za pomocą narzędzia kubectl:
kubectl apply -f my-omni.yaml
Oczekiwane dane wyjściowe konsoli:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
Sprawdź stan klastra my-omni za pomocą narzędzia kubectl:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Podczas wdrażania klaster przechodzi przez różne fazy i ostatecznie powinien osiągnąć stan DBClusterReady.
Oczekiwane dane wyjściowe konsoli:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
Łączenie się z AlloyDB Omni
Nawiązywanie połączenia za pomocą poda Kubernetes
Gdy klaster będzie gotowy, możemy użyć plików binarnych klienta PostgreSQL w podzie instancji AlloyDB Omni. Znajdujemy identyfikator poda, a następnie używamy narzędzia kubectl, aby bezpośrednio połączyć się z podem i uruchomić oprogramowanie klienta. Hasło to VeryStrongPassword, które zostało ustawione za pomocą obiektu tajnego Kubernetes w pliku manifestu my-omni.yaml:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Przykładowe dane wyjściowe konsoli:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. Wdrażanie modelu AI w GKE
Aby przetestować integrację AI AlloyDB Omni z modelami lokalnymi, musimy wdrożyć model w klastrze. Użyjemy modelu EmbeddingGemma od Google.
Tworzenie puli węzłów dla modelu
Aby uruchomić model, musimy przygotować pulę węzłów do wnioskowania. Możemy uruchomić go w puli tylko z procesorami lub w puli z akceleratorami GPU. W niektórych regionach podejście oparte wyłącznie na procesorze może być bardziej wykonalne ze względu na dużą równoczesność zasobów. W naszym laboratorium użyjemy podejścia opartego na procesorze, ale z punktu widzenia wydajności najlepszym rozwiązaniem jest pula z akceleratorami graficznymi korzystająca z konfiguracji węzła takiej jak g2-standard-8 z akceleratorem Nvidia L4.
Pula węzłów oparta na procesorze
Utwórz pulę węzłów z węzłami e2-standard-32. Aby zaoszczędzić zasoby, ograniczymy pobieranie do jednego węzła.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
Oczekiwane dane wyjściowe
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
Uzyskiwanie tokena Hugging Face
W tym module korzystamy z partnerstwa z Hugging Face, aby wdrożyć model EmbeddingGemma. W tym celu musimy uzyskać token Hugging Face.
Jeśli nie masz jeszcze tokena, wykonaj poniższe czynności, aby go wygenerować.
- Zaloguj się lub zarejestruj w witrynie Hugging Face, korzystając z linków Log In (Zaloguj się) lub Sign Up (Zarejestruj się) w prawym górnym rogu.
- Kliknij Twój profil –> Tokeny dostępu.
- Potwierdź swoją tożsamość
- Kliknij Utwórz nowy token.
- Wybierz nazwę tokena
- Wybierz rolę tokena – musisz mieć co najmniej uprawnienie do odczytu.
- Na dole strony kliknij Utwórz token.
- Skopiuj wygenerowany token i zapisz go do późniejszego wykorzystania.
Musisz też zaakceptować warunki dostępu do plików i treści związanych z modelem EmbeddingGemma w Hugging Face na stronie https://huggingface.co/google/embeddinggemma-300m.
Tworzenie obiektu tajnego Kubernetes za pomocą tokena
W sesji Cloud Shell wykonaj to polecenie (zastąp wartość HF_TOKEN swoim tokenem HF).
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
Przygotowywanie pliku manifestu wdrożenia
Aby wdrożyć model, musimy przygotować manifest wdrożenia.
Korzystamy z modelu EmbeddingGemma od Google z Hugging Face. Kartę modelu znajdziesz tutaj. Do wdrożenia modelu użyjemy podejścia opartego na instrukcjach z Hugging Face i pakiecie wdrożeniowym z GitHub.
Sklonuj pakiet z GitHuba.
git clone https://github.com/huggingface/Google-Cloud-Containers
Dostosuj plik manifestu dla interfejsu TEI (wektor dystrybucyjny tekstu) na węzłach CPU. Musimy zastąpić kilka parametrów, w tym model, obraz i prawidłową alokację zasobów, oraz dodać do konfiguracji tajny token Hugging Face.
Edytuj plik manifestu (w dowolnym dostępnym edytorze).
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
Oto poprawiony plik manifestu d=do wdrożenia w puli opartej na procesorze.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
Wdrażanie modelu
Wdróż model, stosując zmodyfikowany plik manifestu w przypadku wdrożeń na procesorze.
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
Sprawdzanie wdrożeń
kubectl get pods
Weryfikowanie usługi modelu
kubectl get service tei-service
Powinien wyświetlać typ działającej usługi ClusterIP.
Przykładowe dane wyjściowe:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
Adres CLUSTER-IP usługi będzie używany jako adres punktu końcowego. Osadzony model może odpowiadać za pomocą identyfikatora URI http://34.118.233.48:8080/embed. Będzie on używany później podczas rejestrowania modelu w AlloyDB Omni.
Możemy to sprawdzić, udostępniając go za pomocą polecenia kubectl port-forward.
kubectl port-forward service/tei-service 8080:8080
Jeśli używasz Cloud Shell, przekierowanie portów może działać w jednej sesji Cloud Shell, a do przetestowania go potrzebujemy innej sesji.
Otwórz kolejną kartę Cloud Shell, klikając znak „+” u góry.
Uruchom polecenie curl w nowej sesji powłoki.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
Powinien zwrócić tablicę wektorów podobną do tej w przykładzie poniżej (dane zostały usunięte):
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
Jeśli zobaczymy te liczby, będziemy mieć pewność, że model został przetestowany i możemy go zarejestrować w AlloyDB Omni, aby można go było używać bezpośrednio z SQL.
6. Rejestrowanie modelu w AlloyDB Omni
Aby sprawdzić, jak AlloyDB Omni działa z wdrożonym modelem, musimy utworzyć bazę danych i zarejestrować model.
Utwórz bazę danych
Utwórz maszynę wirtualną GCE jako serwer pośredniczący, aby połączyć się z AlloyDB Omni z maszyny wirtualnej klienta i utworzyć bazę danych.
Potrzebujemy serwera pośredniczącego, ponieważ zewnętrzny system równoważenia obciążenia GKE dla Omni zapewnia dostęp z VPC przy użyciu prywatnych adresów IP, ale nie umożliwia łączenia się z zewnątrz VPC. Jest ogólnie bezpieczniejsze i nie udostępnia instancji bazy danych w internecie. Sprawdź diagram w celu uniknięcia wątpliwości.
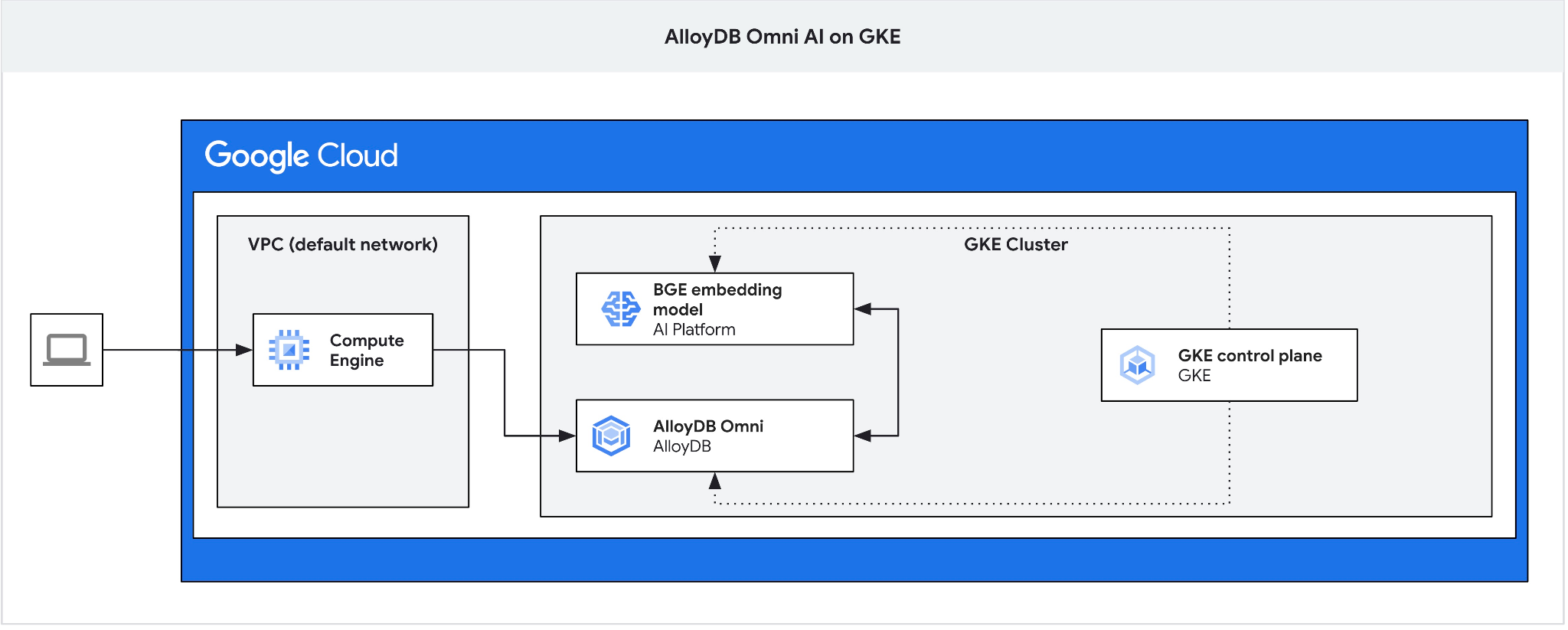
Aby utworzyć maszynę wirtualną w sesji Cloud Shell, wykonaj to polecenie:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
Znajdź adres IP punktu końcowego AlloyDB Omni za pomocą polecenia kubectl w Cloud Shell:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Zanotuj wartość PRIMARYENDPOINT.
Oto przykładowe dane wyjściowe:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33 to adres IP, którego będziemy używać w naszych przykładach do łączenia się z instancją AlloyDB Omni.
Nawiązywanie połączenia z maszyną wirtualną za pomocą gcloud:
gcloud compute ssh instance-1 --zone=$ZONE
Jeśli pojawi się prośba o wygenerowanie klucza SSH, postępuj zgodnie z instrukcjami. Więcej informacji o połączeniu SSH znajdziesz w dokumentacji.
W sesji SSH na maszynie wirtualnej zainstaluj klienta PostgreSQL:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Wyeksportuj zmienną adresu IP systemu równoważenia obciążenia AlloyDB Omni, korzystając z tego przykładu (zastąp IP adresem IP systemu równoważenia obciążenia):
export INSTANCE_IP=10.131.0.33
Połącz się z AlloyDB Omni, hasło to VeryStrongPassword, zgodnie z ustawieniami za pomocą skrótu w my-omni.yaml:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
W utworzonej sesji psql wykonaj to polecenie:
create database demo;
Zakończ sesję i połącz się z wersją demonstracyjną bazy danych (możesz też po prostu uruchomić \c demo w tej samej sesji).
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Tworzenie funkcji przekształcania
W przypadku modeli osadzania innych firm musimy utworzyć funkcje przekształcania, które formatują dane wejściowe i wyjściowe w sposób oczekiwany przez model i nasze funkcje wewnętrzne. Te funkcje działają jak tłumacze, umożliwiając konwersję formatów między różnymi interfejsami.
Oto funkcja przekształcenia, która obsługuje dane wejściowe:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
Wykonaj podany kod, gdy jesteś połączony z bazą danych demonstracyjnych, jak pokazano w przykładowym wyniku:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
A oto funkcja wyjściowa, która przekształca odpowiedź modelu w tablicę liczb rzeczywistych:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
Wykonaj go w tej samej sesji:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
Zarejestruj model
Teraz możemy zarejestrować model w bazie danych.
Oto wywołanie procedury, która rejestruje model o nazwie embeddinggemma. Podczas rejestracji modelu używamy nazwy usługi tei-service w parametrze model_request_url. Jest to wewnętrzna nazwa usługi klastra Kubernetes, która jest tłumaczona na wewnętrzny adres IP w klastrze GKE:
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
Wykonaj podany kod po połączeniu z bazą danych wersji demonstracyjnej:
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
Model rejestru możemy przetestować za pomocą tego zapytania testowego, które powinno zwrócić tablicę liczb rzeczywistych.
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
Nie zdziw się, jeśli na dane wektorowe trzeba będzie długo czekać. Do tego testu używamy puli węzłów opartej na procesorze, aby hostować model osadzania. Działa on znacznie szybciej na węzłach z GPU.
7. Testowanie modelu w AlloyDB Omni
Wczytywanie danych
Aby sprawdzić, jak AlloyDB Omni działa z wdrożonym modelem, musimy wczytać trochę danych. Użyłem tych samych danych co w jednym z innych ćwiczeń dotyczących wyszukiwania wektorowego w AlloyDB.
Jednym ze sposobów wczytywania danych jest użycie pakietu Google Cloud SDK i oprogramowania klienta PostgreSQL. Możemy użyć tej samej maszyny wirtualnej klienta. Jeśli używasz domyślnego obrazu maszyny wirtualnej, pakiet Google Cloud SDK powinien być już zainstalowany. Jeśli jednak używasz obrazu niestandardowego bez pakietu SDK Google, możesz go dodać, postępując zgodnie z dokumentacją.
Wyeksportuj adres IP systemu równoważenia obciążenia AlloyDB Omni, jak w tym przykładzie (zastąp IP adresem IP systemu równoważenia obciążenia):
export INSTANCE_IP=10.131.0.33
Połącz się z bazą danych i włącz rozszerzenie pgvector.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
W sesji psql:
CREATE EXTENSION IF NOT EXISTS vector;
Zakończ sesję psql i w sesji wiersza poleceń wykonaj polecenia, aby wczytać dane do bazy danych demo.
Utwórz tabele. To polecenie pobierze plik cymbal_demo_schema.sql i wykona SQL ze wszystkimi definicjami tabel w bazie danych demonstracyjnej:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
Oto lista utworzonych tabel:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Dane wyjściowe:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
Wczytaj dane do tabeli cymbal_products:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
Oto kilka przykładowych wierszy z tabeli cymbal_products.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Dane wyjściowe:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
Wczytaj dane do tabeli cymbal_inventory:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
Oto kilka przykładowych wierszy z tabeli cymbal_inventory.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Dane wyjściowe:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
Wczytaj dane do tabeli cymbal_stores:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
Oto kilka przykładowych wierszy z tabeli cymbal_stores.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Dane wyjściowe:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
Tworzenie wektorów dystrybucyjnych
Połącz się z bazą danych demo za pomocą psql i utwórz wektory osadzeń dla produktów opisanych w tabeli cymbal_products na podstawie opisów produktów.
Połącz się z bazą danych wersji demonstracyjnej:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Używamy tabeli cymbal_embedding z osadzaniem kolumn do przechowywania osadzeń, a jako dane wejściowe do funkcji tekstowej wykorzystujemy opis produktu.
Włącz pomiar czasu w przypadku zapytań, aby później porównać je z modelami zdalnymi:
\timing
Uruchom zapytanie, aby utworzyć osadzanie:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
Oczekiwane dane wyjściowe konsoli:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
W tym przykładzie utworzenie wektorów osadzania zajęło około 8 minut. Jest to oczekiwane w przypadku puli węzłów opartej na procesorze. W przypadku puli z akceleratorami GPU może to być znacznie szybsze w zależności od typu GPU.
Uruchom zapytania testowe
Połącz się z bazą danych w wersji demonstracyjnej za pomocą psql i włącz pomiar czasu, aby mierzyć czas wykonania zapytań, tak jak w przypadku tworzenia wektorów.
Znajdźmy 5 najlepszych produktów pasujących do zapytania „Jakie drzewa owocowe dobrze tu rosną?” przy użyciu odległości cosinusowej jako algorytmu wyszukiwania wektorowego.
W sesji psql wykonaj to polecenie:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Oczekiwane dane wyjściowe konsoli:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
Zapytanie zostało wykonane w 83 ms i zwróciło listę drzew z tabeli cymbal_products, które pasują do żądania i są dostępne w magazynie o numerze 1583.
Utwórz indeks ANN
Gdy mamy tylko mały zbiór danych, łatwo jest używać dokładnego wyszukiwania, które skanuje wszystkie wektory, ale gdy dane rosną, czas ładowania i odpowiedzi również się wydłuża. Aby zwiększyć wydajność, możesz utworzyć indeksy na podstawie danych o osadzaniu. Oto przykład, jak to zrobić za pomocą indeksu Google ScaNN w przypadku danych wektorowych.
Jeśli połączenie z bazą danych wersji demonstracyjnej zostało utracone, nawiąż je ponownie:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Włącz rozszerzenie alloydb_scann:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Utwórz indeks:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
Wykonaj to samo zapytanie co wcześniej i porównaj wyniki:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
Czas wykonania zapytania nieco się skrócił, a w przypadku większych zbiorów danych ta różnica byłaby bardziej zauważalna. Wyniki są dość podobne, a w pierwszej piątce znalazły się te same drzewa.
Wypróbuj inne zapytania i dowiedz się więcej o wybieraniu indeksu wektorowego w dokumentacji.
Pamiętaj, że AlloyDB Omni ma więcej funkcji i laboratoriów.
8. Zwalnianie miejsca w środowisku
Teraz możemy usunąć klaster GKE z AlloyDB Omni i modelem AI.
Usuwanie klastra GKE
W Cloud Shell wykonaj to polecenie:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
Usuń maszynę wirtualną
W Cloud Shell wykonaj to polecenie:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
Jeśli na potrzeby tego laboratorium utworzono nowy projekt, możesz go usunąć w całości: https://console.cloud.google.com/cloud-resource-manager
9. Gratulacje
Gratulujemy ukończenia ćwiczenia.
Omówione zagadnienia
- Jak wdrożyć AlloyDB Omni w klastrze Google Kubernetes
- Jak połączyć się z AlloyDB Omni
- Wczytywanie danych do AlloyDB Omni
- Jak wdrożyć otwarty model wektora dystrybucyjnego w GKE
- Jak zarejestrować model wektora dystrybucyjnego w AlloyDB Omni
- Jak generować wektory dystrybucyjne na potrzeby wyszukiwania semantycznego
- Jak używać wygenerowanych wektorów dystrybucyjnych do wyszukiwania semantycznego w AlloyDB Omni
- Jak tworzyć i używać indeksów wektorowych w AlloyDB
Więcej informacji o pracy z AI w AlloyDB Omni znajdziesz w dokumentacji.
10. Ankieta
Dane wyjściowe: