
1. Введение
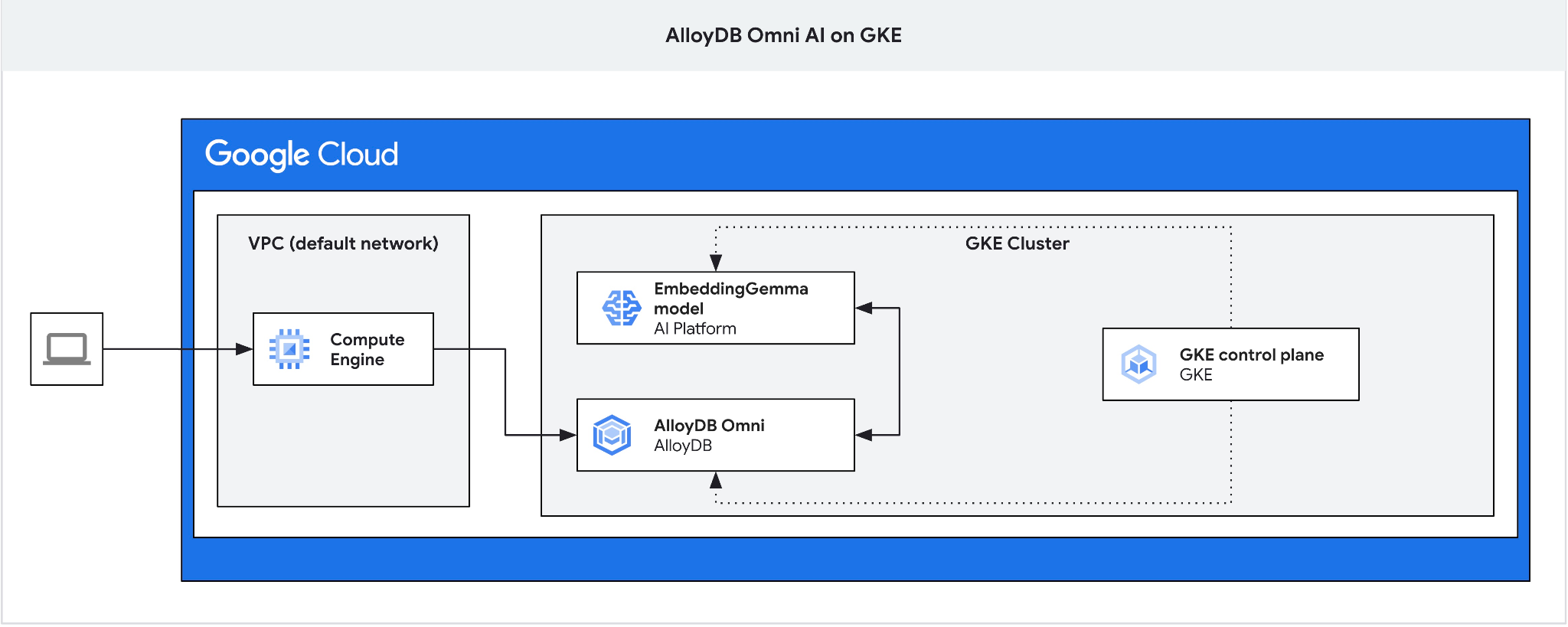
В этом практическом занятии вы узнаете, как развернуть AlloyDB Omni в GKE и использовать его с моделью открытого встраивания, развернутой в том же кластере Kubernetes. Развертывание модели рядом с экземпляром базы данных в том же кластере GKE снижает задержку и зависимость от сторонних сервисов. Кроме того, локальное развертывание может быть требованием, установленным в соответствии с требованиями безопасности и соответствия стандартам, когда данные не должны покидать организацию, а использование сторонних сервисов запрещено.
Предварительные требования
- Базовое понимание Google Cloud и консоли.
- Базовые знания Kubernetes и GKE.
- Базовые навыки работы с командной строкой и Cloud Shell.
Что вы узнаете
- Как развернуть AlloyDB Omni в кластере Google Kubernetes
- Как подключиться к AlloyDB Omni
- Как загрузить данные в AlloyDB Omni
- Как развернуть модель открытого встраивания в GKE
- Как зарегистрировать модель встраивания в AlloyDB Omni
- Как сгенерировать векторные представления для семантического поиска
- Как использовать сгенерированные векторные представления для семантического поиска в AlloyDB Omni
- Как создавать и использовать векторные индексы в AlloyDB
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, такой как Chrome , поддерживающий консоль Google Cloud и Cloud Shell.
2. Настройка и требования
Настройка проекта
- Войдите в консоль Google Cloud . Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .
Используйте личный аккаунт вместо рабочего или учебного.
- Создайте новый проект или используйте существующий. Чтобы создать новый проект в консоли Google Cloud, в заголовке нажмите кнопку «Выбрать проект», после чего откроется всплывающее окно.

В окне «Выберите проект» нажмите кнопку «Новый проект», после чего откроется диалоговое окно для создания нового проекта.
В диалоговом окне введите желаемое название проекта и выберите местоположение.
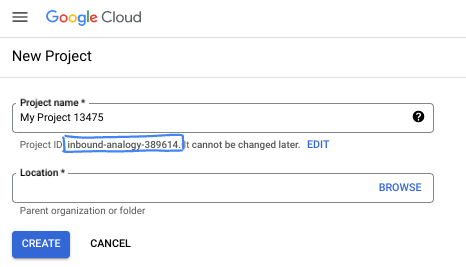
- Название проекта — это отображаемое имя участников данного проекта. Название проекта не используется API Google и может быть изменено в любое время.
- Идентификатор проекта (Project ID) уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Google Cloud автоматически генерирует уникальный идентификатор, но вы можете настроить его. Если вам не нравится сгенерированный идентификатор, вы можете сгенерировать другой случайный или указать свой собственный, чтобы проверить его доступность. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта, который обычно обозначается заполнителем PROJECT_ID.
- К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
Включить выставление счетов
Создайте личный платежный аккаунт.
Если вы настроили оплату с использованием кредитов Google Cloud, этот шаг можно пропустить.
Чтобы настроить личный платежный аккаунт, перейдите сюда, чтобы включить оплату в облачной консоли.
Несколько замечаний:
- Выполнение этой лабораторной работы должно обойтись менее чем в 3 доллара США в виде облачных ресурсов.
- В конце этой лабораторной работы вы можете выполнить действия по удалению ресурсов, чтобы избежать дальнейших списаний средств.
- Новые пользователи могут воспользоваться бесплатной пробной версией стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
В качестве альтернативы вы можете нажать G, а затем S. Эта последовательность активирует Cloud Shell, если вы находитесь в консоли Google Cloud, или воспользуйтесь этой ссылкой .
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
3. Прежде чем начать
Включить API
Выход:
Для использования Google Kubernetes Engine (GKE) для развертывания AlloyDB Omni и открытых моделей необходимо включить соответствующие API в вашем проекте Google Cloud.
Внутри Cloud Shell убедитесь, что идентификатор вашего проекта указан правильно:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Если это не определено в конфигурации Cloud Shell, настройте это с помощью следующих команд.
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Включите все необходимые службы:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
Ожидаемый результат
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Представляем API.
- API Kubernetes Engine (
container.googleapis.com) позволяет создавать и управлять кластерами Google Kubernetes Engine (GKE). Он предоставляет управляемую среду для развертывания, управления и масштабирования контейнеризированных приложений с использованием инфраструктуры Google. - API Compute Engine (
compute.googleapis.com) позволяет создавать и управлять виртуальными машинами (ВМ), постоянными дисками и сетевыми настройками. Он предоставляет базовую инфраструктуру как услугу (IaaS), необходимую для запуска ваших рабочих нагрузок и размещения базовой инфраструктуры для множества управляемых сервисов.
4. Разверните AlloyDB Omni в GKE.
Для развертывания AlloyDB Omni в GKE необходимо подготовить кластер Kubernetes в соответствии с требованиями, указанными в описании требований к оператору AlloyDB Omni .
Создайте кластер GKE.
Нам необходимо развернуть стандартный кластер GKE с достаточной конфигурацией пула для развертывания пода с экземпляром AlloyDB Omni. Для AlloyDB Omni требуется как минимум 2 ЦП и 8 ГБ ОЗУ, а также место для контейнеров операторских и мониторинговых служб. Мы будем использовать тип виртуальной машины e2-standard-4 .
Настройте переменные среды для развертывания.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
Затем мы используем gcloud для создания стандартного кластера GKE.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Ожидаемый вывод в консоль:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
Подготовка кластера
Нам необходимо установить необходимые компоненты, такие как служба cert-manager — собственный менеджер сертификатов для Kubernetes. Можно следовать инструкциям по установке cert-manager, приведенным в документации.
Мы используем инструмент командной строки Kubernetes, kubectl, который уже установлен в Cloud Shell по умолчанию. Перед использованием утилиты нам необходимо получить учетные данные для нашего кластера.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
Теперь мы можем использовать kubectl для установки cert-manager:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
Ожидаемый вывод в консоль (засекречено):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
Установите AlloyDB Omni
Для установки оператора AlloyDB Omni можно использовать утилиту Helm.
Для установки оператора AlloyDB Omni выполните следующую команду:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
Ожидаемый вывод в консоль (засекречено):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
После установки оператора AlloyDB Omni мы можем приступить к развертыванию нашего кластера баз данных.
Вот пример манифеста развертывания с включенным параметром googleMLExtension и внутренним (приватным) балансировщиком нагрузки:
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
Секретное значение пароля представляет собой кодовое слово "VeryStrongPassword" в формате Base64 . Более надежный способ — использовать Google Secret Manager для хранения значения пароля. Подробнее об этом можно прочитать в документации .
Сохраните манифест как my-omni.yaml, чтобы он был применен на следующем шаге. Если вы находитесь в Cloud Shell, вы можете сделать это с помощью редактора, нажав кнопку «Открыть редактор» в правом верхнем углу терминала.
После сохранения файла с именем my-omni.yaml вернитесь в терминал, нажав кнопку «Открыть терминал».
Примените манифест my-omni.yaml к кластеру с помощью утилиты kubectl:
kubectl apply -f my-omni.yaml
Ожидаемый вывод в консоль:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
Проверьте состояние вашего кластера my-omni с помощью утилиты kubectl:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
В процессе развертывания кластер проходит различные фазы и в конечном итоге должен перейти в состояние DBClusterReady .
Ожидаемый вывод в консоль:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
Подключитесь к AlloyDB Omni
Подключение с помощью пода Kubernetes
Когда кластер будет готов, мы сможем использовать бинарные файлы клиента PostgreSQL на экземпляре AlloyDB Omni. Мы находим идентификатор пода, а затем используем kubectl для прямого подключения к поду и запуска клиентского программного обеспечения. Пароль — VeryStrongPassword , заданный через секрет Kubernetes в манифесте my-omni.yaml:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Пример вывода в консоль:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. Развертывание модели ИИ на GKE
Для тестирования интеграции AlloyDB Omni AI с локальными моделями нам необходимо развернуть модель в кластере. Мы будем использовать модель EmbeddingGemma от Google.
Создайте пул узлов для модели.
Для запуска модели нам необходимо подготовить пул узлов для выполнения инференса. Мы можем использовать пул только с процессорами или пул с графическими ускорителями. Подход только с процессорами может быть более целесообразным в некоторых регионах из-за высокой конкуренции за ресурсы. В нашей лаборатории мы будем использовать подход с процессорами, но с точки зрения производительности наилучшим вариантом является пул с графическими ускорителями, использующий конфигурацию узлов, например, g2-standard-8 с ускорителем L4 Nvidia.
Пул узлов на основе ЦП
Создайте пул узлов с пакетом e2-standard-32. Мы ограничим количество запрашиваемых узлов одним, чтобы сэкономить ресурсы.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
Ожидаемый результат
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
Получите токен "Обнимающее лицо"
В этой лабораторной работе мы используем партнерство с Hugging Face для развертывания модели EmbeddingGemma, и для этого нам необходимо получить токен Hugging Face.
Выполните следующие шаги, чтобы сгенерировать новый токен, если у вас его еще нет.
- Войдите или зарегистрируйтесь на сайте Hugging Face, используя ссылки «Вход» или «Регистрация» в правом верхнем углу.
- Нажмите «Ваш профиль» -> «Токены доступа».
- Подтвердите свою личность.
- Нажмите «Создать новый токен».
- Выберите название для своего токена
- Выберите роль для токена — вам потребуется как минимум право на чтение.
- Нажмите кнопку «Создать токен» внизу страницы.
- Скопируйте сгенерированный токен и сохраните его для дальнейшего использования.
Также вам необходимо принять условия доступа к файлам и контенту, связанным с EmbeddingGemma на Hugging Face, на странице https://huggingface.co/google/embeddinggemma-300m.
Создайте секрет Kubernetes, используя токен.
В сессии облачной оболочки выполните команду (замените значение HF_TOKEN на ваш HF-токен).
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
Подготовка манифеста развертывания
Для развертывания модели необходимо подготовить манифест развертывания.
Мы используем модель EmbeddingGemma от Google, предоставленную Hugging Face. С описанием модели можно ознакомиться здесь . Для развертывания модели мы будем использовать подход, основанный на инструкциях Hugging Face и пакете развертывания с GitHub.
Клонируйте пакет из GitHub.
git clone https://github.com/huggingface/Google-Cloud-Containers
Необходимо внести изменения в манифест для TEI (интерфейс встраивания текста) на ЦП-узлах. Требуется заменить несколько параметров, включая модель, изображение, правильно распределить ресурсы и добавить секретный токен Hugging Face в конфигурацию.
Отредактируйте манифест (используя любой доступный редактор).
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
Вот исправленный манифест d=для развертывания в пуле с использованием ЦП.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
Разверните модель
Разверните модель, применив измененный манифест для развертывания на ЦП.
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
Проверьте развертывания.
kubectl get pods
Проверьте модель службы
kubectl get service tei-service
Предполагается, что будет отображаться тип запущенной службы ClusterIP.
Пример выходных данных:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
IP-адрес кластера для сервиса — это то, что мы будем использовать в качестве адреса конечной точки. Встраивание модели может отвечать по URI http://34.118.233.48:8080/embed. Он будет использоваться позже при регистрации модели в AlloyDB Omni.
Мы можем проверить это, открыв доступ к нему с помощью команды kubectl port-forward.
kubectl port-forward service/tei-service 8080:8080
Если вы используете Cloud Shell, то переадресация портов может выполняться в рамках одной сессии Cloud Shell, а для тестирования потребуется еще одна сессия.
Откройте еще одну вкладку Cloud Shell, используя знак "+" вверху.
И выполните команду curl в новой сессии оболочки.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
Функция должна возвращать векторный массив, как в следующем примере выходных данных (засекречено):
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
Если мы посмотрим на цифры, то сможем подтвердить, что успешно протестировали модель и теперь можем зарегистрировать её в нашей базе данных AlloyDB Omni для непосредственного использования из SQL-запросов.
6. Зарегистрируйте модель в AlloyDB Omni.
Чтобы проверить, как наша база данных AlloyDB Omni работает с развернутой моделью, нам необходимо создать базу данных и зарегистрировать модель.
Создать базу данных
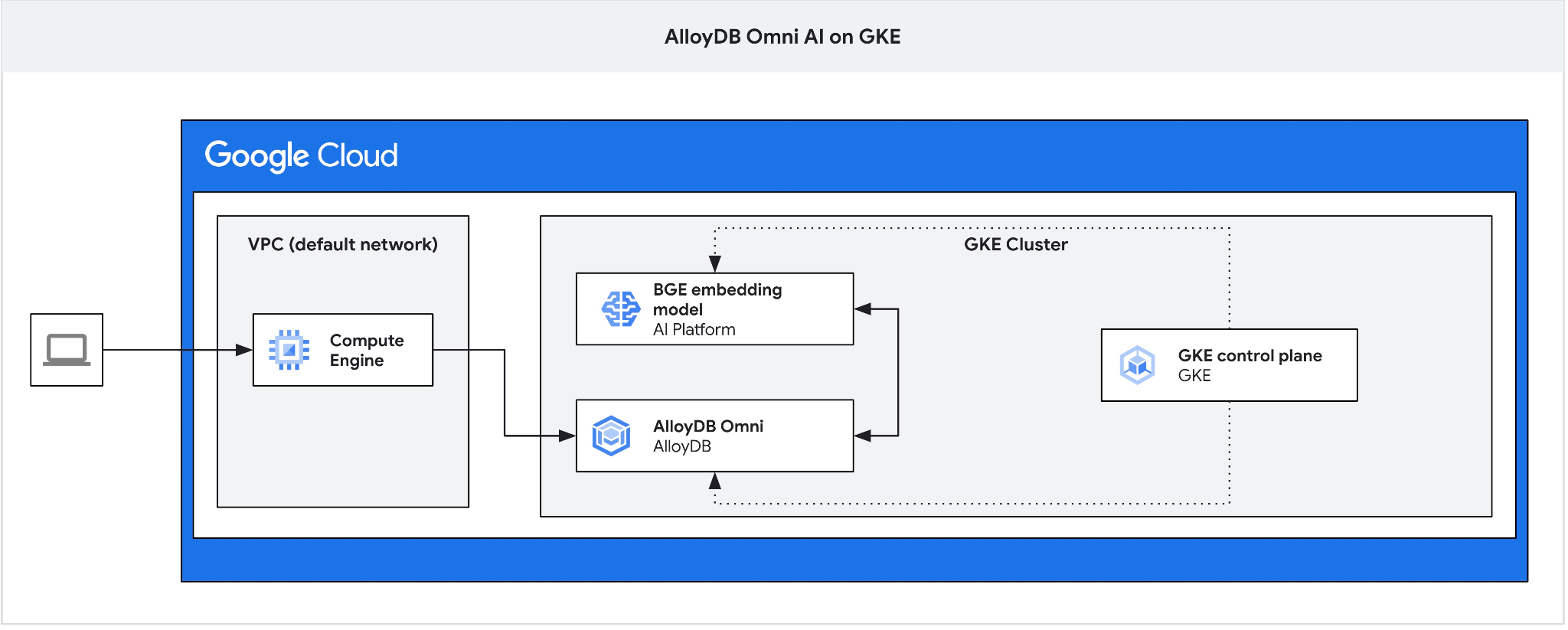
Создайте виртуальную машину GCE в качестве промежуточного сервера для подключения к AlloyDB Omni с вашей клиентской виртуальной машины и создайте базу данных.
Нам нужен промежуточный сервер, поскольку внешний балансировщик нагрузки GKE для Omni обеспечивает доступ из VPC с использованием частных IP-адресов, но не позволяет подключаться извне VPC. В целом, это более безопасно и не раскрывает ваш экземпляр базы данных в интернете. Пожалуйста, ознакомьтесь со схемой для большей ясности.
Для создания виртуальной машины в сеансе Cloud Shell выполните следующую команду:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
Найдите IP-адрес конечной точки AlloyDB Omni с помощью команды kubectl в Cloud Shell:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Запишите PRIMARYENDPOINT .
Вот пример выходных данных:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
IP-адрес 10.131.0.33 — это тот адрес, который мы будем использовать в наших примерах для подключения к экземпляру AlloyDB Omni.
Подключитесь к виртуальной машине с помощью gcloud:
gcloud compute ssh instance-1 --zone=$ZONE
Если появится запрос на генерацию SSH-ключа, следуйте инструкциям. Подробнее о SSH-подключении см. в документации .
В SSH-сессии к виртуальной машине установите клиент PostgreSQL:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Экспортируйте переменную IP-адреса балансировщика нагрузки AlloyDB Omni, используя следующий пример (замените IP на IP-адрес вашего балансировщика нагрузки):
export INSTANCE_IP=10.131.0.33
Подключитесь к AlloyDB Omni, пароль — VeryStrongPassword , заданный с помощью хеша в файле my-omni.yaml :
psql "host=$INSTANCE_IP user=postgres sslmode=require"
В установленной сессии psql выполните:
create database demo;
Выйдите из сессии и подключитесь к демонстрационной версии базы данных (или вы можете просто запустить команду \c demo в той же сессии).
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Создайте функции преобразования
Для моделей встраивания сторонних приложений нам необходимо создать функции преобразования, которые форматируют входные и выходные данные в соответствии с форматом, ожидаемым моделью и нашими внутренними функциями. Эти функции выступают в роли трансляторов, осуществляя преобразование формата между различными интерфейсами.
Вот функция преобразования, которая обрабатывает входные данные:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
Выполните предоставленный код, подключившись к демонстрационной базе данных, как показано в примере выходных данных:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
А вот функция вывода, которая преобразует ответ от модели в массив действительных чисел:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
Выполните это в той же сессии:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
Зарегистрируйте модель
Теперь мы можем зарегистрировать модель в базе данных.
Вот вызов процедуры для регистрации модели с именем embeddinggemma . При регистрации модели мы используем имя службы tei-service в параметре model_request_url . Это внутреннее имя службы кластера Kubernetes, которое преобразуется во внутренний IP-адрес кластера GKE:
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
Выполните предоставленный код, подключившись к демонстрационной базе данных:
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
Мы можем протестировать модель регистра, используя следующий тестовый запрос, который должен вернуть массив действительных чисел.
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
Не удивляйтесь длительной задержке перед получением векторных данных. Для этого теста мы используем пул узлов с процессорами для размещения модели встраивания, и на узлах с графическими процессорами это работает намного быстрее.
7. Протестируйте модель в AlloyDB Omni.
Загрузка данных
Чтобы проверить, как наша база данных AlloyDB Omni работает с развернутой моделью, нам нужно загрузить некоторые данные. Я использовал те же данные, что и в одном из других практических заданий по векторному поиску в AlloyDB.
Один из способов загрузки данных — использование Google Cloud SDK и клиентского программного обеспечения PostgreSQL. Мы можем использовать одну и ту же клиентскую виртуальную машину. Google Cloud SDK должен быть уже установлен, если вы использовали настройки по умолчанию для образа виртуальной машины. Но если вы использовали собственный образ без Google SDK, вы можете добавить его, следуя документации .
Экспортируйте IP-адрес балансировщика нагрузки AlloyDB Omni, как показано в следующем примере (замените IP на IP-адрес вашего балансировщика нагрузки):
export INSTANCE_IP=10.131.0.33
Подключитесь к базе данных и включите расширение pgvector.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
В сессии psql:
CREATE EXTENSION IF NOT EXISTS vector;
Закройте сессию psql и в командной строке выполните команды для загрузки данных в демонстрационную базу данных.
Создайте таблицы. Следующая команда получит файл cymbal_demo_schema.sql и выполнит SQL-запрос со всеми определениями таблиц в демонстрационной базе данных:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
Ожидаемый вывод в консоль:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
Вот список созданных таблиц:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Выход:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
Загрузите данные в таблицу cymbal_products :
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
Ожидаемый вывод в консоль:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
Вот несколько примеров строк из таблицы cymbal_products .
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Выход:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
Загрузите данные в таблицу cymbal_inventory :
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
Ожидаемый вывод в консоль:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
Вот несколько примеров строк из таблицы cymbal_inventory .
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Выход:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
Загрузите данные в таблицу cymbal_stores :
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
Ожидаемый вывод в консоль:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
Вот несколько примеров строк из таблицы cymbal_stores .
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Выход:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
Создание эмбеддингов
Подключитесь к демонстрационной базе данных с помощью psql и создайте эмбеддинги для продуктов, описанных в таблице cymbal_products, на основе описаний продуктов.
Подключитесь к демонстрационной базе данных:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Для хранения наших эмбеддингов мы используем таблицу cymbal_embedding со столбцом embedding, а в качестве текстового входного параметра для функции используем описание продукта.
Включите отображение времени выполнения запросов для последующего сравнения с удаленными моделями.
\timing
Выполните запрос для построения эмбеддингов:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
Ожидаемый вывод в консоль:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
В этом примере создание эмбеддингов заняло около 8 минут. Это ожидаемо для пула узлов на базе ЦП. Для пула с графическими ускорителями это может быть значительно быстрее в зависимости от типа графического процессора.
Выполнить тестовые запросы
Подключитесь к демонстрационной базе данных с помощью psql и включите измерение времени выполнения запросов, как мы это делали при построении эмбеддингов.
Давайте найдем 5 лучших товаров, соответствующих запросу типа "Какие фруктовые деревья хорошо растут здесь?", используя косинусное расстояние в качестве алгоритма векторного поиска.
В сессии psql выполните:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Ожидаемый вывод в консоль:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
Запрос выполнился за 83 мс и вернул список деревьев из таблицы cymbal_products, соответствующих запросу и имеющих в наличии в магазине номер 1583.
Создание индекса ИНС
Когда у нас небольшой набор данных, легко использовать точный поиск, сканирующий все эмбеддинги, но по мере роста объема данных увеличиваются и время загрузки, и время отклика. Для повышения производительности можно создавать индексы на основе данных эмбеддингов. Вот пример того, как это сделать, используя индекс Google ScaNN для векторных данных.
Если соединение прервалось, повторно подключитесь к демонстрационной базе данных:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Включите расширение alloydb_scann:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Создать индекс:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
Попробуйте выполнить тот же запрос, что и раньше, и сравните результаты:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
Время выполнения запроса немного сократилось, и этот выигрыш будет более заметен при работе с большими наборами данных. Результаты довольно похожи, и в итоге мы получили те же 5 лучших деревьев.
Попробуйте другие запросы и ознакомьтесь с дополнительной информацией о выборе векторного индекса в документации .
И не забывайте, что AlloyDB Omni обладает ещё большим количеством функций и тестовых площадок.
8. Очистка окружающей среды
Теперь мы можем удалить наш кластер GKE с помощью AlloyDB Omni и модели искусственного интеллекта.
Удалить кластер GKE
В оболочке Cloud Shell выполните:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
Ожидаемый вывод в консоль:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
Удалить виртуальную машину
В оболочке Cloud Shell выполните:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Ожидаемый вывод в консоль:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
Если вы создали новый проект для этого практического занятия, вы можете удалить весь проект целиком: https://console.cloud.google.com/cloud-resource-manager
9. Поздравляем!
Поздравляем с завершением практического занятия!
Что мы рассмотрели
- Как развернуть AlloyDB Omni в кластере Google Kubernetes
- Как подключиться к AlloyDB Omni
- Как загрузить данные в AlloyDB Omni
- Как развернуть модель открытого встраивания в GKE
- Как зарегистрировать модель встраивания в AlloyDB Omni
- Как сгенерировать векторные представления для семантического поиска
- Как использовать сгенерированные векторные представления для семантического поиска в AlloyDB Omni
- Как создавать и использовать векторные индексы в AlloyDB
Более подробную информацию о работе с ИИ в AlloyDB Omni можно найти в документации .
10. Опрос
Выход: