
1. บทนำ
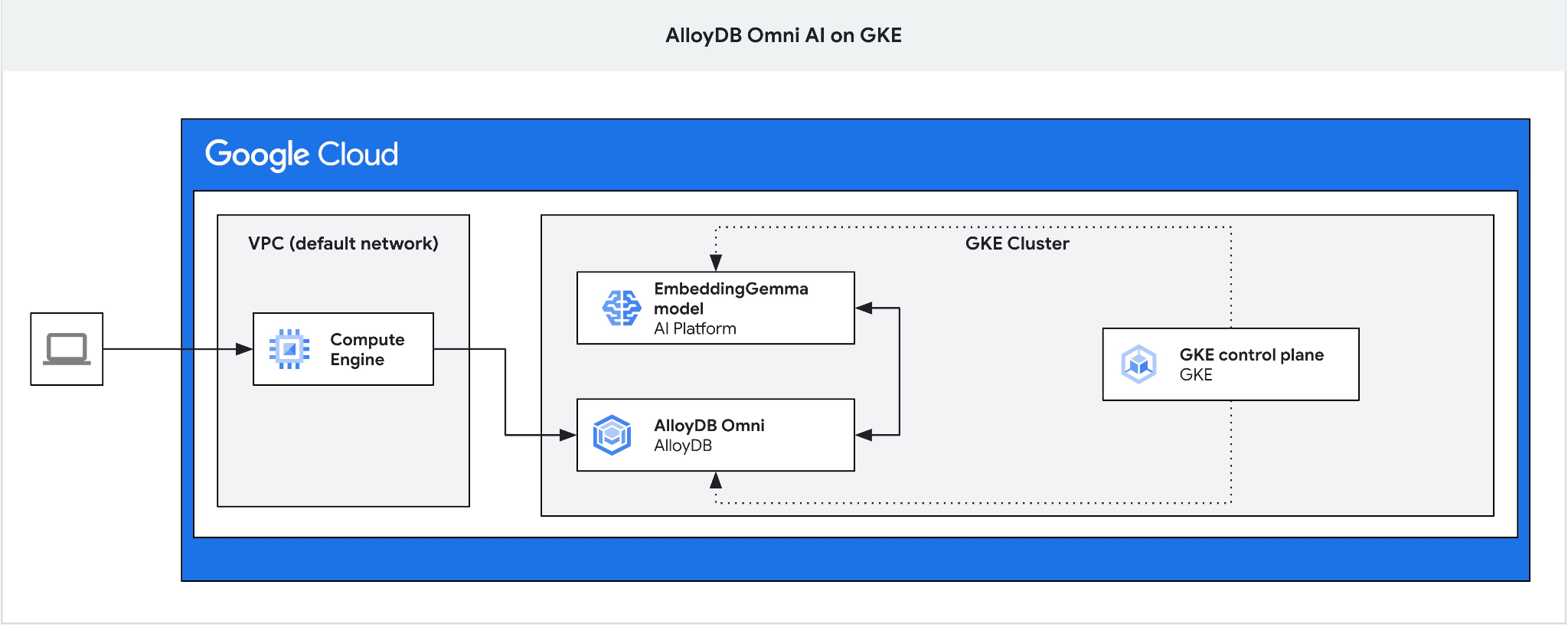
ในโค้ดแล็บนี้ คุณจะได้เรียนรู้วิธีทำให้ AlloyDB Omni ใช้งานได้ใน GKE และวิธีใช้กับโมเดลการฝังแบบเปิดที่ทำให้ใช้งานได้ในคลัสเตอร์ Kubernetes เดียวกัน การติดตั้งใช้งานโมเดลข้างอินสแตนซ์ฐานข้อมูลในคลัสเตอร์ GKE เดียวกันจะช่วยลดเวลาในการตอบสนองและการพึ่งพาบริการของบุคคลที่สาม นอกจากนี้ การติดตั้งใช้งานในพื้นที่อาจเป็นข้อกำหนดที่กำหนดโดยทีมรักษาความปลอดภัยและการปฏิบัติตามข้อกำหนดในกรณีที่ข้อมูลไม่ควรออกจากองค์กรและไม่อนุญาตให้ใช้บริการของบุคคลที่สาม
ข้อกำหนดเบื้องต้น
- ความเข้าใจพื้นฐานเกี่ยวกับ Google Cloud และคอนโซล
- มีความรู้พื้นฐานเกี่ยวกับ Kubernetes และ GKE
- ทักษะพื้นฐานในอินเทอร์เฟซบรรทัดคำสั่งและ Cloud Shell
สิ่งที่คุณจะได้เรียนรู้
- วิธีทำให้ AlloyDB Omni ใช้งานได้ในคลัสเตอร์ Google Kubernetes
- วิธีเชื่อมต่อกับ AlloyDB Omni
- วิธีโหลดข้อมูลไปยัง AlloyDB Omni
- วิธีทำให้โมเดลการฝังแบบเปิดใช้งานได้ใน GKE
- วิธีลงทะเบียนโมเดลการฝังใน AlloyDB Omni
- วิธีสร้างการฝังสำหรับการค้นหาเชิงความหมาย
- วิธีใช้การฝังที่สร้างขึ้นสำหรับการค้นหาเชิงความหมายใน AlloyDB Omni
- วิธีสร้างและใช้ดัชนีเวกเตอร์ใน AlloyDB
สิ่งที่คุณต้องมี
- บัญชี Google Cloud และโปรเจ็กต์ Google Cloud
- เว็บเบราว์เซอร์ เช่น Chrome ที่รองรับ Google Cloud Console และ Cloud Shell
2. การตั้งค่าและข้อกำหนด
การตั้งค่าโปรเจ็กต์
- ลงชื่อเข้าใช้ Google Cloud Console หากยังไม่มีบัญชี Gmail หรือ Google Workspace คุณต้องสร้างบัญชี
ใช้บัญชีส่วนตัวแทนบัญชีงานหรือบัญชีโรงเรียน
- สร้างโปรเจ็กต์ใหม่หรือนำโปรเจ็กต์ที่มีอยู่มาใช้ซ้ำ หากต้องการสร้างโปรเจ็กต์ใหม่ใน Google Cloud Console ให้คลิกปุ่มเลือกโปรเจ็กต์ในส่วนหัว ซึ่งจะเปิดหน้าต่างป๊อปอัป

ในหน้าต่างเลือกโปรเจ็กต์ ให้กดปุ่มโปรเจ็กต์ใหม่ ซึ่งจะเปิดกล่องโต้ตอบสำหรับโปรเจ็กต์ใหม่
ในกล่องโต้ตอบ ให้ป้อนชื่อโปรเจ็กต์ที่ต้องการและเลือกตำแหน่ง
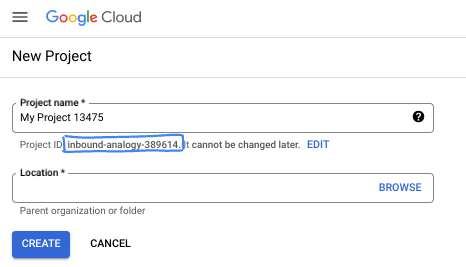
- ชื่อโปรเจ็กต์คือชื่อที่แสดงสำหรับผู้เข้าร่วมโปรเจ็กต์นี้ Google APIs จะไม่ใช้ชื่อโปรเจ็กต์ และคุณเปลี่ยนชื่อได้ทุกเมื่อ
- รหัสโปรเจ็กต์จะไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมดและเปลี่ยนแปลงไม่ได้ (เปลี่ยนไม่ได้หลังจากตั้งค่าแล้ว) คอนโซล Google Cloud จะสร้างรหัสที่ไม่ซ้ำกันโดยอัตโนมัติ แต่คุณสามารถปรับแต่งได้ หากไม่ชอบรหัสที่สร้างขึ้น คุณสามารถสร้างรหัสแบบสุ่มอีกรหัสหนึ่งหรือระบุรหัสของคุณเองเพื่อตรวจสอบความพร้อมใช้งานได้ ใน Codelab ส่วนใหญ่ คุณจะต้องอ้างอิงรหัสโปรเจ็กต์ ซึ่งโดยปกติจะระบุด้วยตัวยึดตำแหน่ง PROJECT_ID
- โปรดทราบว่ายังมีค่าที่ 3 ซึ่งคือหมายเลขโปรเจ็กต์ที่ API บางตัวใช้ ดูข้อมูลเพิ่มเติมเกี่ยวกับค่าทั้ง 3 นี้ได้ในเอกสารประกอบ
เปิดใช้การเรียกเก็บเงิน
ตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว
หากตั้งค่าการเรียกเก็บเงินโดยใช้เครดิต Google Cloud คุณจะข้ามขั้นตอนนี้ได้
หากต้องการตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว ให้ไปที่นี่เพื่อเปิดใช้การเรียกเก็บเงินใน Cloud Console
ข้อควรทราบ
- การทำ Lab นี้ให้เสร็จสมบูรณ์ควรมีค่าใช้จ่ายน้อยกว่า $3 USD ในทรัพยากรระบบคลาวด์
- คุณสามารถทำตามขั้นตอนที่ส่วนท้ายของแล็บนี้เพื่อลบทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติม
- ผู้ใช้ใหม่มีสิทธิ์ใช้ช่วงทดลองใช้ฟรีมูลค่า$300 USD
เริ่มต้น Cloud Shell
แม้ว่าคุณจะใช้งาน Google Cloud จากระยะไกลจากแล็ปท็อปได้ แต่ใน Codelab นี้คุณจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์
จาก Google Cloud Console ให้คลิกไอคอน Cloud Shell ในแถบเครื่องมือด้านขวาบน
หรือจะกด G แล้วตามด้วย S ก็ได้ ลำดับนี้จะเปิดใช้งาน Cloud Shell หากคุณอยู่ใน Google Cloud Console หรือใช้ลิงก์นี้
การจัดสรรและเชื่อมต่อกับสภาพแวดล้อมจะใช้เวลาเพียงไม่กี่นาที เมื่อเสร็จแล้ว คุณควรเห็นข้อความคล้ายกับตัวอย่างต่อไปนี้

เครื่องเสมือนนี้มาพร้อมเครื่องมือพัฒนาซอฟต์แวร์ทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานบน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก คุณสามารถทำงานทั้งหมดใน Codelab นี้ได้ภายในเบราว์เซอร์ คุณไม่จำเป็นต้องติดตั้งอะไร
3. ก่อนเริ่มต้น
เปิดใช้ API
เอาต์พุต:
หากต้องการใช้ Google Kubernetes Engine (GKE) สำหรับการติดตั้งใช้งาน AlloyDB Omni และโมเดลแบบเปิด คุณต้องเปิดใช้ API ที่เกี่ยวข้องในโปรเจ็กต์ Google Cloud
ใน Cloud Shell ให้ตรวจสอบว่าได้ตั้งค่ารหัสโปรเจ็กต์แล้ว
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
หากไม่ได้กำหนดไว้ในการกำหนดค่า Cloud Shell ให้ตั้งค่าโดยใช้คำสั่งต่อไปนี้
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
เปิดใช้บริการที่จำเป็นทั้งหมด
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
ผลลัพธ์ที่คาดหวัง
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
ขอแนะนำ API
- Kubernetes Engine API (
container.googleapis.com) ช่วยให้คุณสร้างและจัดการคลัสเตอร์ Google Kubernetes Engine (GKE) ได้ โดยมีสภาพแวดล้อมที่มีการจัดการสำหรับการทำให้แอปพลิเคชันที่มีคอนเทนเนอร์ใช้งานได้ จัดการ และปรับขนาดโดยใช้โครงสร้างพื้นฐานของ Google - Compute Engine API (
compute.googleapis.com) ช่วยให้คุณสร้างและจัดการเครื่องเสมือน (VM), Persistent Disk และการตั้งค่าเครือข่ายได้ โดยมีพื้นฐานด้าน Infrastructure-as-a-Service (IaaS) หลักที่จำเป็นต่อการเรียกใช้เวิร์กโหลดและโฮสต์โครงสร้างพื้นฐานที่อยู่เบื้องหลังสำหรับบริการที่มีการจัดการจำนวนมาก
4. ทำให้ AlloyDB Omni ใช้งานได้ใน GKE
หากต้องการติดตั้งใช้งาน AlloyDB Omni ใน GKE เราต้องเตรียมคลัสเตอร์ Kubernetes ตามข้อกำหนดที่ระบุไว้ในข้อกำหนดของตัวดำเนินการ AlloyDB Omni
สร้างคลัสเตอร์ GKE
เราต้องติดตั้งใช้งานคลัสเตอร์ GKE มาตรฐานที่มีการกำหนดค่าพูลเพียงพอที่จะติดตั้งใช้งานพ็อดที่มีอินสแตนซ์ AlloyDB Omni สำหรับ AlloyDB Omni เราต้องการ CPU อย่างน้อย 2 ตัวและ RAM 8 GB และมีพื้นที่สำหรับคอนเทนเนอร์ของบริการตรวจสอบและผู้ให้บริการ เราจะใช้ VM ประเภท e2-standard-4
ตั้งค่าตัวแปรสภาพแวดล้อมสำหรับการติดตั้งใช้งาน
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
จากนั้นเราจะใช้ gcloud เพื่อสร้างคลัสเตอร์มาตรฐาน GKE
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
เอาต์พุตของคอนโซลที่คาดไว้
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
เตรียมคลัสเตอร์
เราต้องติดตั้งคอมโพเนนต์ที่จำเป็น เช่น บริการ cert-manager ซึ่งเป็นตัวจัดการใบรับรองดั้งเดิมสำหรับ Kubernetes เราสามารถทำตามขั้นตอนในเอกสารประกอบสำหรับการติดตั้ง cert-manager
เราใช้เครื่องมือบรรทัดคำสั่งของ Kubernetes ซึ่งก็คือ kubectl ซึ่งติดตั้งไว้ใน Cloud Shell โดยค่าเริ่มต้นอยู่แล้ว ก่อนใช้ยูทิลิตี เราต้องรับข้อมูลเข้าสู่ระบบสำหรับคลัสเตอร์
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
ตอนนี้เราใช้ kubectl เพื่อติดตั้ง cert-manager ได้แล้ว
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
เอาต์พุตของคอนโซลที่คาดไว้(แก้ไข)
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
ติดตั้ง AlloyDB Omni
คุณติดตั้งตัวดำเนินการ AlloyDB Omni ได้โดยใช้ยูทิลิตี Helm
เรียกใช้คำสั่งต่อไปนี้เพื่อติดตั้งตัวดำเนินการ AlloyDB Omni
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
เอาต์พุตของคอนโซลที่คาดไว้(แก้ไข)
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
เมื่อติดตั้งตัวดำเนินการ AlloyDB Omni แล้ว เราจะติดตามผลการติดตั้งใช้งานคลัสเตอร์ฐานข้อมูลได้
ตัวอย่างไฟล์ Manifest การติดตั้งใช้งานที่มีพารามิเตอร์ googleMLExtension ที่เปิดใช้และตัวโหลดบาลานซ์ภายใน (ส่วนตัว) มีดังนี้
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
ค่าลับสำหรับรหัสผ่านคือการแสดงรหัสผ่านคำว่า "VeryStrongPassword" ในรูปแบบ Base64 วิธีที่น่าเชื่อถือกว่าคือการใช้ Google Secret Manager เพื่อจัดเก็บค่ารหัสผ่าน อ่านข้อมูลเพิ่มเติมได้ในเอกสารประกอบ
บันทึกไฟล์ Manifest เป็น my-omni.yaml เพื่อนำไปใช้ในขั้นตอนถัดไป หากอยู่ใน Cloud Shell คุณสามารถทำได้โดยใช้เครื่องมือแก้ไขโดยกดปุ่ม "เปิดเครื่องมือแก้ไข" ที่ด้านขวาบนของเทอร์มินัล
หลังจากบันทึกไฟล์ด้วยชื่อ my-omni.yaml แล้ว ให้กลับไปที่เทอร์มินัลโดยกดปุ่ม "เปิดเทอร์มินัล"
ใช้ไฟล์ Manifest my-omni.yaml กับคลัสเตอร์โดยใช้ยูทิลิตี kubectl
kubectl apply -f my-omni.yaml
เอาต์พุตของคอนโซลที่คาดไว้
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
ตรวจสอบสถานะคลัสเตอร์ my-omni โดยใช้ยูทิลิตี kubectl ดังนี้
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
ในระหว่างการติดตั้งใช้งาน คลัสเตอร์จะผ่านขั้นตอนต่างๆ และควรสิ้นสุดด้วยสถานะ DBClusterReady
เอาต์พุตของคอนโซลที่คาดไว้
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
เชื่อมต่อกับ AlloyDB Omni
เชื่อมต่อโดยใช้พ็อด Kubernetes
เมื่อคลัสเตอร์พร้อมแล้ว เราจะใช้ไบนารีของไคลเอ็นต์ PostgreSQL ในพ็อดอินสแตนซ์ AlloyDB Omni ได้ เราจะค้นหารหัสพ็อด จากนั้นใช้ kubectl เพื่อเชื่อมต่อกับพ็อดโดยตรงและเรียกใช้ซอฟต์แวร์ไคลเอ็นต์ รหัสผ่านคือ VeryStrongPassword ตามที่ตั้งค่าผ่าน Kubernetes Secret ในไฟล์ Manifest my-omni.yaml
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
ตัวอย่างเอาต์พุตของคอนโซล
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. ทำให้โมเดล AI ใช้งานได้ใน GKE
หากต้องการทดสอบการผสานรวม AI ของ AlloyDB Omni กับโมเดลในเครื่อง เราต้องติดตั้งใช้งานโมเดลกับคลัสเตอร์ เราจะใช้โมเดล EmbeddingGemma ของ Google
สร้าง Node Pool สำหรับโมเดล
หากต้องการเรียกใช้โมเดล เราต้องเตรียม Node Pool เพื่อเรียกใช้การอนุมาน เราสามารถเรียกใช้โดยใช้พูล CPU เท่านั้นหรือพูลที่มีตัวเร่ง GPU ก็ได้ การใช้เฉพาะ CPU อาจเป็นไปได้มากกว่าในบางภูมิภาคเนื่องจากมีการทำงานพร้อมกันสูงสำหรับทรัพยากร ในห้องทดลอง เราจะใช้วิธี CPU แต่แนวทางที่ดีที่สุดในแง่ของประสิทธิภาพคือพูลที่มีตัวเร่งกราฟิกซึ่งใช้การกำหนดค่าโหนด เช่น g2-standard-8 ที่มีตัวเร่ง L4 Nvidia
Node Pool ที่อิงตาม CPU
สร้าง Node Pool ที่มีโหนด e2-standard-32 เราจะจำกัดการดึงข้อมูลไว้ที่ 1 โหนดเพื่อประหยัดทรัพยากร
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
ผลลัพธ์ที่คาดหวัง
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
รับโทเค็น Hugging Face
ในแล็บนี้ เราใช้การเป็นพาร์ทเนอร์กับ Hugging Face เพื่อทำให้โมเดล EmbeddingGemma ใช้งานได้ และในการดำเนินการดังกล่าว เราต้องรับโทเค็น Hugging Face
ทำตามขั้นตอนด้านล่างเพื่อสร้างโทเค็นใหม่หากคุณยังไม่มี
- เข้าสู่ระบบหรือลงชื่อสมัครใช้ในเว็บไซต์ Hugging Face โดยใช้ลิงก์เข้าสู่ระบบหรือลงชื่อสมัครใช้ที่มุมขวาบน
- คลิกโปรไฟล์ของคุณ -> โทเค็นการเข้าถึง
- ยืนยันตัวตนของคุณ
- คลิกสร้างโทเค็นใหม่
- เลือกชื่อสำหรับโทเค็น
- เลือกบทบาทสำหรับโทเค็น โดยคุณต้องมีสิทธิ์อ่านเป็นอย่างน้อย
- คลิกสร้างโทเค็นที่ด้านล่างของหน้า
- คัดลอกโทเค็นที่สร้างขึ้นและบันทึกไว้เพื่อใช้ในภายหลัง
นอกจากนี้ คุณต้องยอมรับเงื่อนไขเพื่อเข้าถึงไฟล์และเนื้อหาที่เกี่ยวข้องกับ EmbeddingGemma ใน Hugging Face ที่หน้า https://huggingface.co/google/embeddinggemma-300m
สร้างข้อมูลลับของ Kubernetes โดยใช้โทเค็น
ในเซสชัน Cloud Shell ให้เรียกใช้ (แทนที่ค่าสำหรับ HF_TOKEN ด้วยโทเค็น HF ของคุณ)
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
เตรียมไฟล์ Manifest การติดตั้งใช้งาน
หากต้องการทำให้โมเดลใช้งานได้ เราต้องเตรียมไฟล์ Manifest การทำให้ใช้งานได้
เราใช้โมเดล EmbeddingGemma ของ Google จาก Hugging Face อ่านการ์ดโมเดลได้ที่นี่ ในการติดตั้งใช้งานโมเดล เราจะใช้แนวทางตามวิธีการจาก Hugging Face และแพ็กเกจการติดตั้งใช้งานจาก GitHub
โคลนแพ็กเกจจาก GitHub
git clone https://github.com/huggingface/Google-Cloud-Containers
ปรับไฟล์ Manifest สำหรับ TEI (Text Embedding Interface) ในโหนด CPU เราต้องแทนที่พารามิเตอร์หลายรายการ ซึ่งรวมถึงโมเดล รูปภาพ การจัดสรรทรัพยากรที่ถูกต้อง และเพิ่มข้อมูลลับของโทเค็น Hugging Face ลงในการกำหนดค่า
แก้ไขไฟล์ Manifest (โดยใช้โปรแกรมแก้ไขที่มี)
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
ต่อไปนี้คือไฟล์ Manifest ที่แก้ไขแล้วสำหรับการติดตั้งใช้งานในพูลที่ใช้ CPU
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
ทำให้โมเดลใช้งานได้
ทําให้โมเดลใช้งานได้โดยใช้ไฟล์ Manifest ที่แก้ไขแล้วสําหรับการติดตั้งใช้งาน CPU
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
ยืนยันการติดตั้งใช้งาน
kubectl get pods
ยืนยันบริการโมเดล
kubectl get service tei-service
ควรแสดงประเภทบริการที่กำลังทำงานอยู่ ClusterIP
ตัวอย่างเอาต์พุต
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
CLUSTER-IP สำหรับบริการคือสิ่งที่เราจะใช้เป็นที่อยู่ปลายทาง การฝังโมเดลสามารถตอบกลับได้โดยใช้ URI http://34.118.233.48:8080/embed ระบบจะใช้ในภายหลังเมื่อคุณลงทะเบียนโมเดลใน AlloyDB Omni
เราสามารถทดสอบได้โดยการเปิดเผยโดยใช้คำสั่ง kubectl port-forward
kubectl port-forward service/tei-service 8080:8080
หากคุณใช้ Cloud Shell การส่งต่อพอร์ตจะทำงานในเซสชัน Cloud Shell หนึ่งได้ และเราต้องใช้เซสชันอื่นเพื่อทดสอบ
เปิดแท็บ Cloud Shell อีกแท็บโดยใช้เครื่องหมาย "+" ที่ด้านบน
และเรียกใช้คำสั่ง curl ในเซสชัน Shell ใหม่
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
โดยควรแสดงผลอาร์เรย์เวกเตอร์ดังตัวอย่างเอาต์พุตต่อไปนี้ (แก้ไข)
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
หากเราเห็นตัวเลขดังกล่าว ก็จะยืนยันได้ว่าเราได้ทดสอบโมเดลเรียบร้อยแล้ว และตอนนี้สามารถลงทะเบียนโมเดลใน AlloyDB Omni เพื่อใช้จาก SQL ได้โดยตรง
6. ลงทะเบียนโมเดลใน AlloyDB Omni
หากต้องการทดสอบว่า AlloyDB Omni ทำงานกับโมเดลที่ใช้งานจริงอย่างไร เราต้องสร้างฐานข้อมูลและลงทะเบียนโมเดล
สร้างฐานข้อมูล
สร้าง GCE VM เป็นจัมป์บ็อกซ์เพื่อเชื่อมต่อกับ AlloyDB Omni จาก VM ไคลเอ็นต์และสร้างฐานข้อมูล
เราต้องใช้ Jump Box เนื่องจากตัวจัดสรรภาระงานภายนอกของ GKE สำหรับ Omni จะให้สิทธิ์เข้าถึงจาก VPC โดยใช้การกำหนดที่อยู่ IP ส่วนตัว แต่ไม่อนุญาตให้คุณเชื่อมต่อจากภายนอก VPC โดยทั่วไปแล้วจะมีความปลอดภัยมากกว่าและไม่เปิดเผยอินสแตนซ์ฐานข้อมูลของคุณต่ออินเทอร์เน็ต โปรดดูแผนภาพเพื่อความชัดเจน
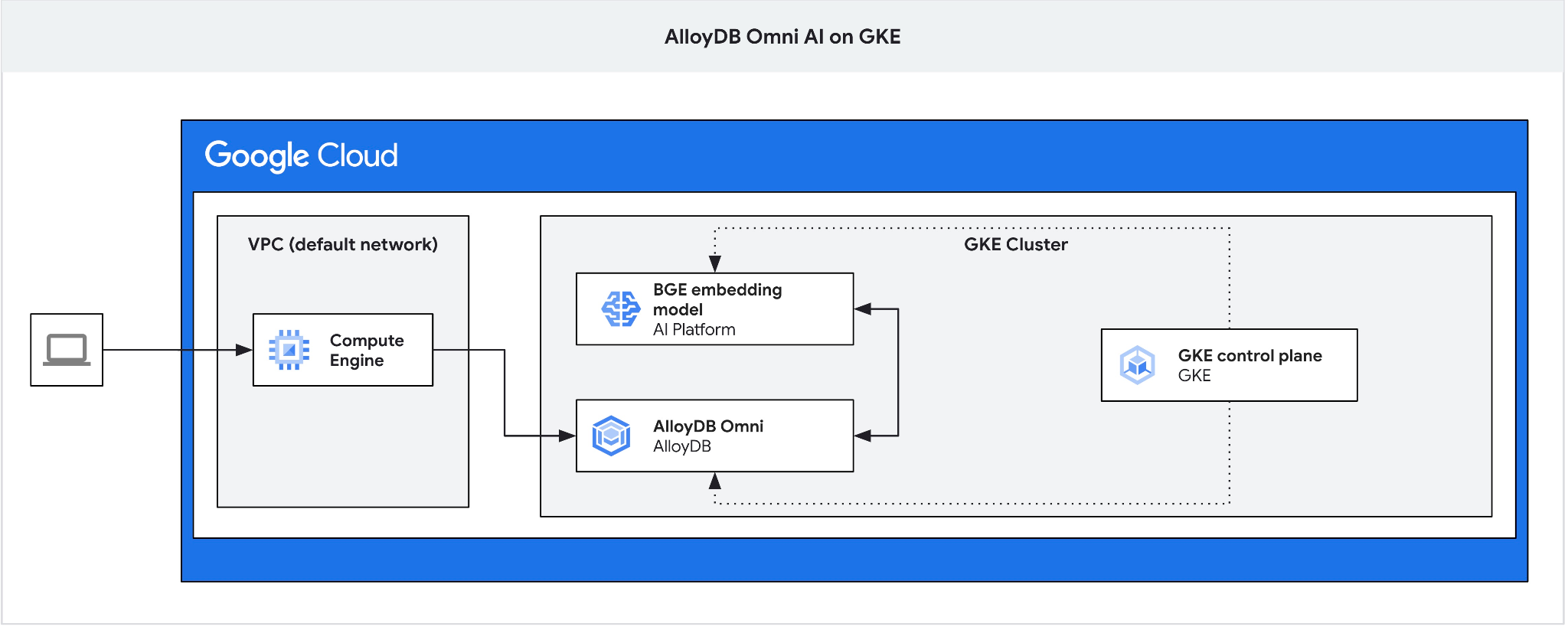
หากต้องการสร้าง VM ในเซสชัน Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
ค้นหา IP ของปลายทาง AlloyDB Omni โดยใช้ kubectl ใน Cloud Shell ดังนี้
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
จด PRIMARYENDPOINT
ตัวอย่างเอาต์พุตมีดังนี้
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33 คือ IP ที่เราจะใช้ในตัวอย่างเพื่อเชื่อมต่อกับอินสแตนซ์ AlloyDB Omni
เชื่อมต่อกับ VM โดยใช้ gcloud
gcloud compute ssh instance-1 --zone=$ZONE
หากได้รับข้อความแจ้งให้สร้างคีย์ SSH ให้ทำตามวิธีการ อ่านเพิ่มเติมเกี่ยวกับการเชื่อมต่อ SSH ในเอกสารประกอบ
ในเซสชัน SSH ไปยัง VM ให้ติดตั้งไคลเอ็นต์ PostgreSQL โดยใช้คำสั่งต่อไปนี้
sudo apt-get update
sudo apt-get install --yes postgresql-client
ส่งออกตัวแปร IP ของตัวจัดสรรภาระงาน AlloyDB Omni โดยใช้ตัวอย่างต่อไปนี้ (แทนที่ IP ด้วย IP ของตัวจัดสรรภาระงาน)
export INSTANCE_IP=10.131.0.33
เชื่อมต่อกับ AlloyDB Omni รหัสผ่านคือ VeryStrongPassword ตามที่ตั้งค่าผ่านแฮชใน my-omni.yaml
psql "host=$INSTANCE_IP user=postgres sslmode=require"
ในเซสชัน psql ที่สร้างขึ้น ให้เรียกใช้คำสั่งต่อไปนี้
create database demo;
ออกจากเซสชันและเชื่อมต่อกับเดโมฐานข้อมูล (หรือจะเรียกใช้ \c demo ในเซสชันเดียวกันก็ได้)
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
สร้างฟังก์ชันการเปลี่ยนรูปแบบ
สําหรับโมเดลการฝังของบุคคลที่สาม เราต้องสร้างฟังก์ชันการแปลงซึ่งจัดรูปแบบอินพุตและเอาต์พุตเป็นรูปแบบที่โมเดลและฟังก์ชันภายในของเราคาดหวัง ฟังก์ชันเหล่านั้นจะทำหน้าที่เป็นตัวแปลเพื่อแปลงรูปแบบระหว่างอินเทอร์เฟซต่างๆ
ต่อไปนี้คือฟังก์ชันการแปลงที่จัดการอินพุต
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
เรียกใช้โค้ดที่ระบุขณะเชื่อมต่อกับฐานข้อมูลเดโมตามที่แสดงในเอาต์พุตตัวอย่าง
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
และนี่คือฟังก์ชันเอาต์พุตที่แปลงการตอบกลับจากโมเดลเป็นอาร์เรย์ของจำนวนจริง
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
เรียกใช้ในเซสชันเดียวกัน
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
ลงทะเบียนโมเดล
ตอนนี้เราสามารถลงทะเบียนโมเดลในฐานข้อมูลได้แล้ว
นี่คือการเรียกขั้นตอนเพื่อลงทะเบียนโมเดลที่มีชื่อ embeddinggemma เราใช้tei-serviceชื่อบริการในพารามิเตอร์ model_request_url เมื่อลงทะเบียนโมเดล ซึ่งเป็นชื่อบริการคลัสเตอร์ Kubernetes ภายในและแปลงเป็น IP ภายในในคลัสเตอร์ GKE
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
เรียกใช้โค้ดที่ระบุขณะเชื่อมต่อกับฐานข้อมูลสาธิต
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
เราสามารถทดสอบโมเดลรีจิสเตอร์ได้โดยใช้การค้นหาทดสอบต่อไปนี้ ซึ่งควรแสดงผลอาร์เรย์ของตัวเลขจริง
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
อย่าแปลกใจหากได้รับข้อมูลเวกเตอร์กลับมาล่าช้ากว่าปกติ สำหรับการทดสอบนี้ เราใช้ Node Pool ที่ใช้ CPU เพื่อโฮสต์โมเดลการฝัง และโมเดลจะทำงานได้เร็วกว่ามากในโหนดที่มี GPU
7. ทดสอบโมเดลใน AlloyDB Omni
โหลดข้อมูล
หากต้องการทดสอบว่า AlloyDB Omni ทำงานกับโมเดลที่ใช้งานจริงอย่างไร เราต้องโหลดข้อมูลบางส่วน ฉันใช้ข้อมูลเดียวกับใน Codelab อื่นๆ สำหรับการค้นหาเวกเตอร์ใน AlloyDB
วิธีหนึ่งในการโหลดข้อมูลคือการใช้ Google Cloud SDK และซอฟต์แวร์ไคลเอ็นต์ PostgreSQL เราสามารถใช้ VM ไคลเอ็นต์เดียวกันได้ หากใช้ค่าเริ่มต้นสำหรับอิมเมจ VM คุณควรติดตั้ง Google Cloud SDK ไว้แล้ว แต่หากใช้รูปภาพที่กำหนดเองโดยไม่มี Google SDK คุณจะเพิ่มรูปภาพได้โดยทำตามเอกสารประกอบ
ส่งออก IP ของตัวจัดสรรภาระงาน AlloyDB Omni ดังตัวอย่างต่อไปนี้ (แทนที่ IP ด้วย IP ของตัวจัดสรรภาระงาน)
export INSTANCE_IP=10.131.0.33
เชื่อมต่อกับฐานข้อมูลและเปิดใช้ส่วนขยาย pgvector
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
ในเซสชัน psql ให้ทำดังนี้
CREATE EXTENSION IF NOT EXISTS vector;
ออกจากเซสชัน psql และในเซสชันบรรทัดคำสั่ง ให้เรียกใช้คำสั่งเพื่อโหลดข้อมูลไปยังฐานข้อมูลสาธิต
สร้างตาราง คำสั่งต่อไปนี้จะรับไฟล์ cymbal_demo_schema.sql และเรียกใช้ SQL พร้อมคำจำกัดความตารางทั้งหมดในฐานข้อมูลเดโม
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
เอาต์พุตของคอนโซลที่คาดไว้
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
รายการตารางที่สร้างมีดังนี้
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
เอาต์พุต:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
โหลดข้อมูลลงในตาราง cymbal_products
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
เอาต์พุตของคอนโซลที่คาดไว้
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
นี่คือตัวอย่างแถวบางส่วนจากตาราง cymbal_products
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
เอาต์พุต:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
โหลดข้อมูลลงในตาราง cymbal_inventory
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
เอาต์พุตของคอนโซลที่คาดไว้
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
นี่คือตัวอย่างแถวบางส่วนจากตาราง cymbal_inventory
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
เอาต์พุต:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
โหลดข้อมูลลงในตาราง cymbal_stores
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
เอาต์พุตของคอนโซลที่คาดไว้
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
นี่คือตัวอย่างแถวบางส่วนจากตาราง cymbal_stores
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
เอาต์พุต:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
สร้างการฝัง
เชื่อมต่อกับฐานข้อมูลการสาธิตโดยใช้ psql และสร้างการฝังสำหรับผลิตภัณฑ์ที่อธิบายไว้ในตาราง cymbal_products โดยอิงตามคำอธิบายผลิตภัณฑ์
เชื่อมต่อกับฐานข้อมูลสาธิต
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
เราใช้ตาราง cymbal_embedding ที่มีการฝังคอลัมน์เพื่อจัดเก็บการฝัง และใช้คำอธิบายผลิตภัณฑ์เป็นอินพุตข้อความสำหรับฟังก์ชัน
เปิดใช้การจับเวลาสำหรับการค้นหาเพื่อเปรียบเทียบกับโมเดลระยะไกลในภายหลัง
\timing
เรียกใช้การค้นหาเพื่อสร้างการฝัง
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
เอาต์พุตของคอนโซลที่คาดไว้
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
ในตัวอย่างนี้ การสร้างการฝังใช้เวลาประมาณ 8 นาที ซึ่งเป็นลักษณะที่คาดไว้สำหรับ Node Pool ที่ใช้ CPU สำหรับพูลที่มีตัวเร่ง GPU อาจเร็วกว่ามาก ทั้งนี้ขึ้นอยู่กับประเภท GPU
เรียกใช้การทดสอบการค้นหา
เชื่อมต่อกับฐานข้อมูลตัวอย่างโดยใช้ psql และเปิดใช้การจับเวลาเพื่อวัดเวลาในการดำเนินการสำหรับคำค้นหาของเราเช่นเดียวกับการสร้างการฝัง
มาค้นหาผลิตภัณฑ์ 5 อันดับแรกที่ตรงกับคำขอ เช่น "ต้นไม้ผลไม้ชนิดใดที่เติบโตได้ดีที่นี่" โดยใช้ระยะทางโคไซน์เป็นอัลกอริทึมสำหรับการค้นหาเวกเตอร์
ในเซสชัน psql ให้เรียกใช้คำสั่งต่อไปนี้
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
เอาต์พุตของคอนโซลที่คาดไว้
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
คําค้นหาทํางาน 83 มิลลิวินาทีและแสดงรายการต้นไม้จากตาราง cymbal_products ที่ตรงกับคําขอและมีสินค้าคงคลังพร้อมจำหน่ายในร้านค้าหมายเลข 1583
สร้างดัชนี ANN
เมื่อมีชุดข้อมูลขนาดเล็ก การใช้การค้นหาที่ตรงกันทุกประการเพื่อสแกนการฝังทั้งหมดก็เป็นเรื่องง่าย แต่เมื่อข้อมูลเพิ่มขึ้น เวลาในการโหลดและการตอบสนองก็จะเพิ่มขึ้นด้วย คุณสร้างดัชนีในข้อมูลการฝังเพื่อปรับปรุงประสิทธิภาพได้ ต่อไปนี้คือตัวอย่างวิธีดำเนินการโดยใช้ดัชนี ScaNN ของ Google สำหรับข้อมูลเวกเตอร์
เชื่อมต่อฐานข้อมูลเดโมอีกครั้งหากการเชื่อมต่อขาดหาย
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
เปิดใช้ส่วนขยาย alloydb_scann โดยทำดังนี้
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
สร้างดัชนี
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
ลองใช้คำค้นหาเดิมและเปรียบเทียบผลลัพธ์
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
เวลาในการดำเนินการคำค้นหาลดลงเล็กน้อย และการเพิ่มขึ้นนี้จะเห็นได้ชัดเจนยิ่งขึ้นเมื่อใช้ชุดข้อมูลขนาดใหญ่ ผลลัพธ์ค่อนข้างคล้ายกัน และเราได้ต้นไม้ 5 อันดับแรกเหมือนกันในผลลัพธ์
ลองใช้คำค้นหาอื่นๆ และอ่านเพิ่มเติมเกี่ยวกับการเลือกดัชนีเวกเตอร์ในเอกสารประกอบ
และอย่าลืมว่า AlloyDB Omni มีฟีเจอร์และ Labs เพิ่มเติม
8. ล้างข้อมูลในสภาพแวดล้อม
ตอนนี้เราสามารถลบคลัสเตอร์ GKE ที่มี AlloyDB Omni และโมเดล AI ได้แล้ว
ลบ คลัสเตอร์ GKE
ใน Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
เอาต์พุตของคอนโซลที่คาดไว้
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
ลบ VM
ใน Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
เอาต์พุตของคอนโซลที่คาดไว้
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
หากสร้างโปรเจ็กต์ใหม่สำหรับ Codelab นี้ คุณสามารถลบโปรเจ็กต์ทั้งหมดแทนได้ที่ https://console.cloud.google.com/cloud-resource-manager
9. ขอแสดงความยินดี
ขอแสดงความยินดีที่ทำ Codelab เสร็จสมบูรณ์
สิ่งที่เราได้พูดถึง
- วิธีทำให้ AlloyDB Omni ใช้งานได้ในคลัสเตอร์ Google Kubernetes
- วิธีเชื่อมต่อกับ AlloyDB Omni
- วิธีโหลดข้อมูลไปยัง AlloyDB Omni
- วิธีทำให้โมเดลการฝังแบบเปิดใช้งานได้ใน GKE
- วิธีลงทะเบียนโมเดลการฝังใน AlloyDB Omni
- วิธีสร้างการฝังสำหรับการค้นหาเชิงความหมาย
- วิธีใช้การฝังที่สร้างขึ้นสำหรับการค้นหาเชิงความหมายใน AlloyDB Omni
- วิธีสร้างและใช้ดัชนีเวกเตอร์ใน AlloyDB
อ่านเพิ่มเติมเกี่ยวกับการทำงานกับ AI ใน AlloyDB Omni ได้ในเอกสารประกอบ
10. แบบสำรวจ
เอาต์พุต: