
1. Giriş
Bu codelab'de, AlloyDB Omni'yi GKE'ye dağıtmayı ve aynı Kubernetes kümesine dağıtılan açık yerleştirme modeliyle kullanmayı öğreneceksiniz. Bir modelin aynı GKE kümesindeki veritabanı örneğinin yanına dağıtılması, gecikmeyi ve üçüncü taraf hizmetlerine olan bağımlılıkları azaltır. Ayrıca, verilerin kuruluş dışına çıkmaması gerektiğinde ve üçüncü taraf hizmetlerinin kullanımına izin verilmediğinde güvenlik ve uygunluk tarafından yerel dağıtım zorunlu kılınabilir.
Ön koşullar
- Google Cloud ve konsol hakkında temel düzeyde bilgi sahibi olmak
- Kubernetes ve GKE hakkında temel bilgiler
- Komut satırı arayüzü ve Cloud Shell'de temel beceriler
Neler öğreneceksiniz?
- AlloyDB Omni'yi Google Kubernetes kümesine dağıtma
- AlloyDB Omni'ye bağlanma
- AlloyDB Omni'ye veri yükleme
- GKE'ye açık yerleştirme modeli dağıtma
- AlloyDB Omni'ye yerleştirme modeli kaydetme
- Semantik arama için yerleştirilmiş öğeler oluşturma
- AlloyDB Omni'de semantik arama için oluşturulan yerleştirmeleri kullanma
- AlloyDB'de vektör dizinleri oluşturma ve kullanma
Gerekenler
- Google Cloud hesabı ve Google Cloud projesi
- Google Cloud Console ve Cloud Shell'i destekleyen Chrome gibi bir web tarayıcısı
2. Kurulum ve Gereksinimler
Proje Kurulumu
- Google Cloud Console'da oturum açın. Gmail veya Google Workspace hesabınız yoksa hesap oluşturmanız gerekir.
İş veya okul hesabı yerine kişisel hesap kullanıyorsanız.
- Yeni bir proje oluşturun veya mevcut bir projeyi yeniden kullanın. Google Cloud Console'da yeni bir proje oluşturmak için üstbilgide bir pop-up pencere açacak olan Proje seç düğmesini tıklayın.

Proje seçin penceresinde Yeni Proje düğmesini tıklayın. Bu işlem, yeni proje için bir iletişim kutusu açar.
İletişim kutusunda tercih ettiğiniz proje adını girin ve konumu seçin.
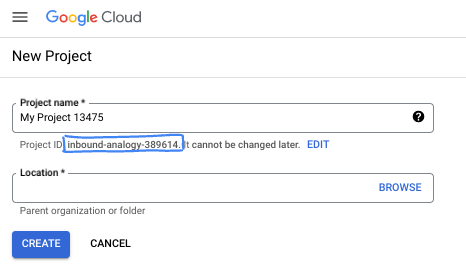
- Proje adı, bu projenin katılımcıları için görünen addır. Proje adı, Google API'leri tarafından kullanılmaz ve istediğiniz zaman değiştirilebilir.
- Proje kimliği, tüm Google Cloud projelerinde benzersizdir ve sabittir (ayarlandıktan sonra değiştirilemez). Google Cloud Console, benzersiz bir kimliği otomatik olarak oluşturur ancak bu kimliği özelleştirebilirsiniz. Oluşturulan kimliği beğenmediyseniz başka bir rastgele kimlik oluşturabilir veya kendi kimliğinizi girerek kullanılabilirliğini kontrol edebilirsiniz. Çoğu codelab'de, genellikle PROJECT_ID yer tutucusuyla tanımlanan proje kimliğinize başvurmanız gerekir.
- Bazı API'lerin kullandığı üçüncü bir değer olan Proje Numarası da vardır. Bu üç değer hakkında daha fazla bilgiyi belgelerde bulabilirsiniz.
Faturalandırmayı etkinleştirme
Kişisel faturalandırma hesabı oluşturma
Faturalandırmayı Google Cloud kredilerini kullanarak ayarladıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturmak için Cloud Console'da faturalandırmayı etkinleştirmek üzere buraya gidin.
Bazı notlar:
- Bu laboratuvarı tamamlamak için 3 ABD dolarından daha az tutarda bulut kaynağı kullanmanız gerekir.
- Daha fazla ücret ödememek için bu laboratuvarın sonundaki adımları uygulayarak kaynakları silebilirsiniz.
- Yeni kullanıcılar 300 ABD doları değerinde ücretsiz deneme sürümünden yararlanabilir.
Cloud Shell'i başlatma
Google Cloud, dizüstü bilgisayarınızdan uzaktan çalıştırılabilir. Ancak bu codelab'de, Cloud'da çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacaksınız.
Google Cloud Console'da sağ üstteki araç çubuğunda Cloud Shell simgesini tıklayın:
Alternatif olarak G, ardından S tuşuna basabilirsiniz. Bu sıra, Google Cloud Console'da veya bu bağlantıyı kullanıyorsanız Cloud Shell'i etkinleştirir.
Ortamın temel hazırlığı ve bağlanması yalnızca birkaç dakikanızı alır. İşlem tamamlandığında aşağıdakine benzer bir sonuç görürsünüz:

Bu sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin sunar ve Google Cloud üzerinde çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu codelab'deki tüm çalışmalarınızı tarayıcıda yapabilirsiniz. Herhangi bir şey yüklemeniz gerekmez.
3. Başlamadan önce
API'yi etkinleştirme
Çıkış:
AlloyDB Omni ve açık model dağıtımları için Google Kubernetes Engine'i (GKE) kullanmak istiyorsanız Google Cloud projenizde ilgili API'leri etkinleştirmeniz gerekir.
Cloud Shell'de proje kimliğinizin ayarlandığından emin olun:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Cloud Shell yapılandırmasında tanımlanmamışsa aşağıdaki komutları kullanarak ayarlayın.
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Gerekli tüm hizmetleri etkinleştirin:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
Beklenen çıktı
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
API'lerle tanışın
- Kubernetes Engine API (
container.googleapis.com), Google Kubernetes Engine (GKE) kümeleri oluşturmanıza ve yönetmenize olanak tanır. Google'ın altyapısını kullanarak container mimarisine alınmış uygulamalarınızı dağıtmanız, yönetmeniz ve ölçeklendirmeniz için yönetilen bir ortam sunar. - Compute Engine API (
compute.googleapis.com), sanal makineler (VM'ler), kalıcı diskler ve ağ ayarları oluşturup yönetmenize olanak tanır. İş yüklerinizi çalıştırmak ve birçok yönetilen hizmetin temel altyapısını barındırmak için gereken temel Hizmet Olarak Altyapı (IaaS) temelini sağlar.
4. GKE'de AlloyDB Omni'yi dağıtma
AlloyDB Omni'yi GKE'ye dağıtmak için AlloyDB Omni operatör gereksinimleri bölümünde listelenen koşulları karşılayan bir Kubernetes kümesi hazırlamamız gerekir.
GKE kümesi oluşturma
AlloyDB Omni örneği içeren bir pod'u dağıtmak için yeterli havuz yapılandırmasına sahip standart bir GKE kümesi dağıtmamız gerekir. AlloyDB Omni için en az 2 CPU ve 8 GB RAM gerekir. Ayrıca operatör ve izleme hizmetleri kapsayıcıları için biraz alan olması gerekir. e2-standard-4 sanal makine türünü kullanacağız.
Dağıtımınız için ortam değişkenlerini ayarlayın.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
Ardından, GKE standart kümesini oluşturmak için gcloud'u kullanırız.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Beklenen konsol çıkışı:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
Kümeyi hazırlama
Kubernetes için yerel sertifika yöneticisi olan cert-manager hizmeti gibi gerekli bileşenleri yüklememiz gerekir. cert-manager yükleme ile ilgili dokümandaki adımları uygulayabiliriz.
Varsayılan olarak Cloud Shell'de yüklü olan Kubernetes komut satırı aracı kubectl'yi kullanırız. Yardımcı programı kullanmadan önce kümemiz için kimlik bilgilerini almamız gerekir.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
Artık cert-manager'ı yüklemek için kubectl'yi kullanabiliriz:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
Beklenen konsol çıkışı(redaksiyonlu):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
AlloyDB Omni'yi yükleme
AlloyDB Omni operatörü, Helm yardımcı programı kullanılarak yüklenebilir.
AlloyDB Omni operatörünü yüklemek için aşağıdaki komutu çalıştırın:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
Beklenen konsol çıkışı(redaksiyonlu):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
AlloyDB Omni operatörü yüklendiğinde veritabanı kümemizin dağıtımına devam edebiliriz.
Aşağıda, googleMLExtension parametresinin etkinleştirildiği ve dahili (özel) yük dengeleyicinin kullanıldığı bir dağıtım manifesti örneği verilmiştir:
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
Şifrenin gizli değeri, "VeryStrongPassword" şifre kelimesinin Base64 gösterimidir. Daha güvenilir yöntem, şifre değerini depolamak için Google Secret Manager'ı kullanmaktır. Bu konu hakkında daha fazla bilgiyi dokümanlarda bulabilirsiniz.
Manifest'i bir sonraki adımda uygulanacak şekilde my-omni.yaml olarak kaydedin. Cloud Shell'deyseniz terminalin sağ üst kısmındaki "Open Editor" (Düzenleyiciyi Aç) düğmesini kullanarak düzenleyiciyi açabilirsiniz.
Dosyayı my-omni.yaml adıyla kaydettikten sonra "Open Terminal" (Terminali Aç) düğmesine basarak terminale geri dönün.
kubectl yardımcı programını kullanarak my-omni.yaml manifestini kümeye uygulayın:
kubectl apply -f my-omni.yaml
Beklenen konsol çıkışı:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
kubectl yardımcı programını kullanarak my-omni küme durumunuzu kontrol edin:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Dağıtım sırasında küme farklı aşamalardan geçer ve sonunda DBClusterReady durumuyla sonuçlanır.
Beklenen konsol çıkışı:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
AlloyDB Omni'ye bağlanma
Kubernetes kapsülünü kullanarak bağlanma
Küme hazır olduğunda AlloyDB Omni örneği pod'unda PostgreSQL istemci ikililerini kullanabiliriz. Pod kimliğini buluruz ve ardından doğrudan poda bağlanıp istemci yazılımını çalıştırmak için kubectl'yi kullanırız. my-omni.yaml manifest dosyasındaki Kubernetes gizli anahtarı aracılığıyla ayarlanan şifre VeryStrongPassword'dür:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Örnek konsol çıktısı:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. GKE'de yapay zeka modeli dağıtma
AlloyDB Omni yapay zeka entegrasyonunu yerel modellerle test etmek için kümeye bir model dağıtmamız gerekir. Google'ın EmbeddingGemma modelini kullanacağız.
Model için düğüm havuzu oluşturma
Modeli çalıştırmak için çıkarım çalıştırmak üzere bir düğüm havuzu hazırlamamız gerekir. Yalnızca CPU havuzu veya GPU hızlandırıcıları olan bir havuz kullanarak çalıştırabiliriz. Kaynaklar için eşzamanlılık oranının yüksek olması nedeniyle bazı bölgelerde yalnızca CPU yaklaşımı daha uygun olabilir. Laboratuvarımızda CPU yaklaşımını kullanacağız ancak performans açısından en iyi yaklaşım, L4 Nvidia hızlandırıcı ile g2-standard-8 gibi bir düğüm yapılandırması kullanan grafik hızlandırıcılar içeren bir havuzdur.
CPU tabanlı düğüm havuzu
e2-standard-32 düğümlerine sahip bir düğüm havuzu oluşturun. Kaynak tasarrufu için çekme işlemimizi tek bir düğümle sınırlayacağız.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
Beklenen çıktı
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
Hugging Face jetonu alma
Bu laboratuvarda, EmbeddingGemma modelini dağıtmak için Hugging Face ile ortaklık yapıyoruz. Bunu yapmak için Hugging Face jetonu almamız gerekiyor.
Daha önce jeton almadıysanız yeni bir jeton oluşturmak için aşağıdaki adımları uygulayın.
- Sağ üst köşedeki Giriş Yap veya Kaydol bağlantılarını kullanarak Hugging Face sitesinde oturum açın ya da kaydolun.
- Profiliniz -> Erişim Jetonları'nı tıklayın.
- Kimliğinizi doğrulayın
- Yeni jeton oluştur'u tıklayın.
- Jetonunuz için bir ad seçin
- Jeton için bir rol seçin. En azından Okuma ayrıcalığına sahip olmanız gerekir.
- Sayfanın alt kısmındaki "Jeton oluştur"u tıklayın.
- Oluşturulan jetonu kopyalayın ve daha sonra kullanmak üzere kaydedin.
Ayrıca, https://huggingface.co/google/embeddinggemma-300m sayfasında Hugging Face'teki EmbeddingGemma ile ilgili dosyalara ve içeriklere erişmek için koşulları kabul etmeniz gerekir.
Jetonu kullanarak Kubernetes gizli anahtarı oluşturma
Cloud Shell oturumunda aşağıdaki komutu çalıştırın (HF_TOKEN değerini HF jetonunuzla değiştirin).
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
Dağıtım Manifestini Hazırlama
Modeli dağıtmak için bir dağıtım manifestosu hazırlamamız gerekir.
Hugging Face'in EmbeddingGemma modelini kullanıyoruz. Model kartını buradan inceleyebilirsiniz. Modeli dağıtmak için Hugging Face'in talimatlarına ve GitHub'daki dağıtım paketine dayalı bir yaklaşım kullanacağız.
Paketi GitHub'dan kopyalama
git clone https://github.com/huggingface/Google-Cloud-Containers
CPU düğümlerinde tei (text embedding interface) için manifesti ayarlayın. Model, resim ve doğru kaynak ayırma da dahil olmak üzere çeşitli parametreleri değiştirmemiz ve yapılandırmaya Hugging Face jetonu gizli anahtarını eklememiz gerekiyor.
Manifest dosyasını düzenleyin (kullanılabilir herhangi bir düzenleyiciyi kullanarak)
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
CPU tabanlı bir havuzda dağıtım için düzeltilmiş bir manifest aşağıda verilmiştir.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
Modeli Dağıtma
CPU dağıtımları için değiştirilmiş manifesti uygulayarak modeli dağıtın.
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
Dağıtımları doğrulama
kubectl get pods
Model hizmetini doğrulama
kubectl get service tei-service
Çalışan hizmet türü ClusterIP'yi göstermesi gerekir.
Örnek çıktı:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
Hizmetin CLUSTER-IP'si, uç nokta adresimiz olarak kullanacağımız IP'dir. Model yerleştirme, http://34.118.233.48:8080/embed URI'siyle yanıt verebilir. Bu kimlik, modeli AlloyDB Omni'ye kaydederken daha sonra kullanılır.
kubectl port-forward komutunu kullanarak hizmeti kullanıma sunarak test edebiliriz.
kubectl port-forward service/tei-service 8080:8080
Cloud Shell kullanıyorsanız bağlantı noktası yönlendirme bir Cloud Shell oturumunda çalışıyor olabilir ve bunu test etmek için başka bir oturuma ihtiyacımız vardır.
En üstteki "+" işaretini kullanarak başka bir Cloud Shell sekmesi açın.
Yeni kabuk oturumunda bir curl komutu çalıştırın.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
Aşağıdaki örnek çıktıdaki gibi bir vektör dizisi döndürmelidir (redaksiyonlu):
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
Bu sayıları görürsek modeli başarıyla test ettiğimizi ve artık doğrudan SQL'den kullanılmak üzere AlloyDB Omni'mize kaydedebileceğimizi onaylayabiliriz.
6. Modeli AlloyDB Omni'ye kaydetme
AlloyDB Omni'nin dağıtılan modelle nasıl çalıştığını test etmek için bir veritabanı oluşturup modeli kaydetmemiz gerekir.
Veritabanı Oluşturma
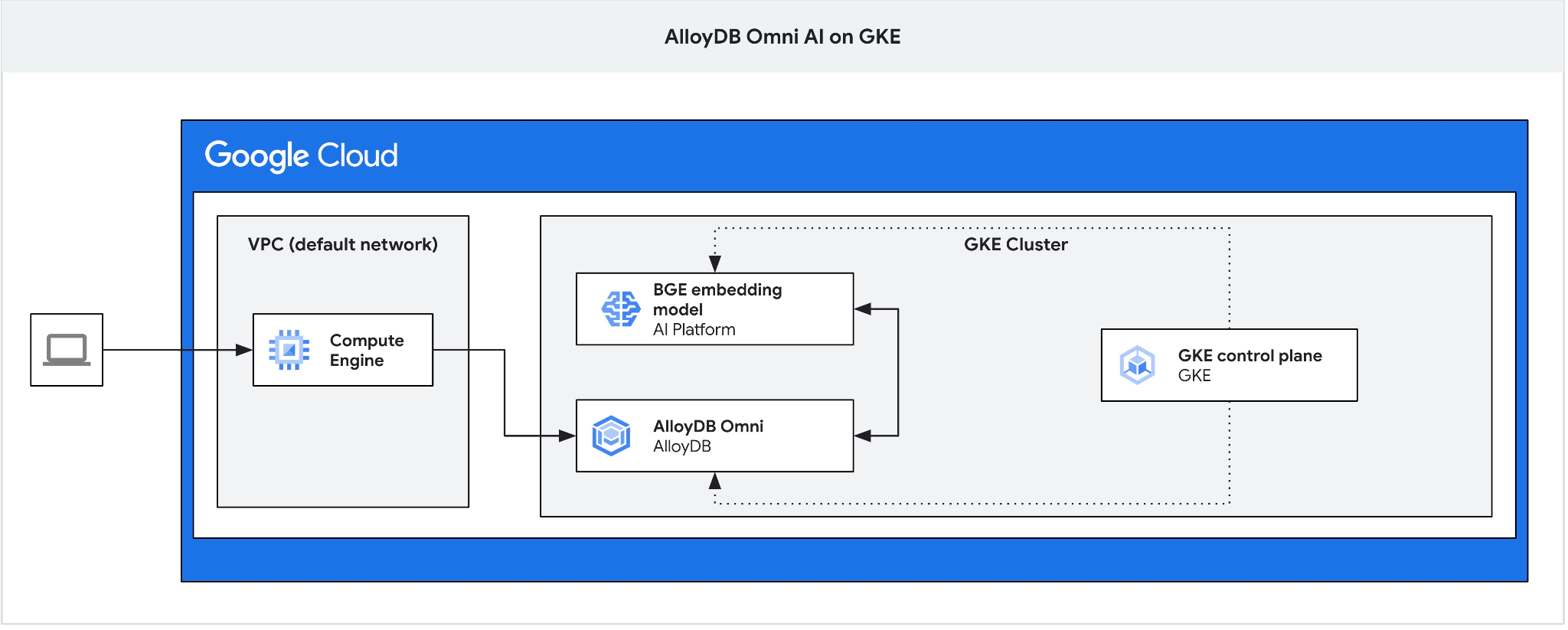
İstemci sanal makinenizden AlloyDB Omni'ye bağlanmak ve veritabanı oluşturmak için atlama kutusu olarak bir GCE sanal makinesi oluşturun.
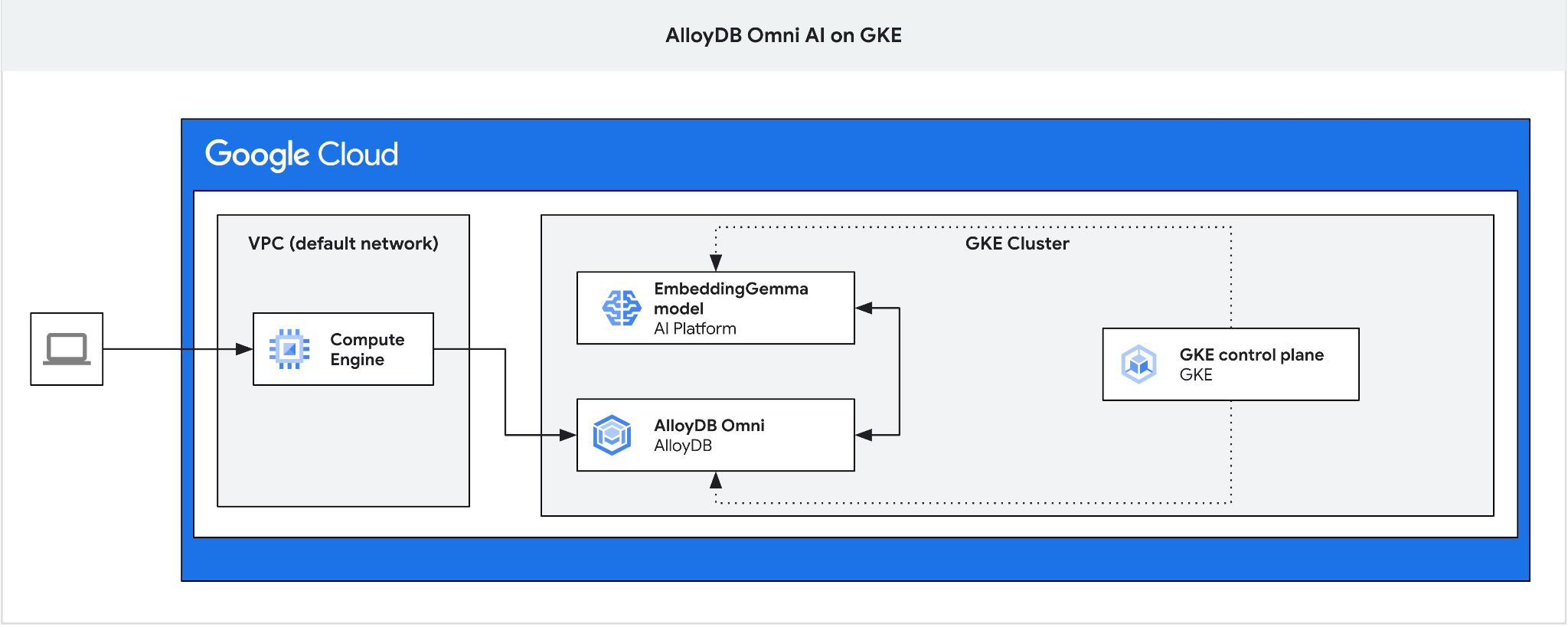
Omni için GKE harici yük dengeleyici, özel IP adresleme kullanarak VPC'den erişmenize olanak tanır ancak VPC dışından bağlanmanıza izin vermediğinden jump box'a ihtiyacımız var. Genel olarak daha güvenlidir ve veritabanı örneğinizi internete açık hale getirmez. Lütfen diyagramın netliğini kontrol edin.
Cloud Shell oturumunda sanal makine oluşturmak için şunu çalıştırın:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
Cloud Shell'de kubectl kullanarak AlloyDB Omni uç noktası IP'sini bulun:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
PRIMARYENDPOINT değerini not edin.
Örnek bir çıkış aşağıda verilmiştir:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33, AlloyDB Omni örneğine bağlanmak için örneklerimizde kullanacağımız IP'dir.
gcloud kullanarak sanal makineye bağlanma:
gcloud compute ssh instance-1 --zone=$ZONE
İstenirse SSH anahtarı oluşturma talimatlarını uygulayın. SSH bağlantısı hakkında daha fazla bilgiyi belgelerde bulabilirsiniz.
Sanal makineye yönelik SSH oturumunda PostgreSQL istemcisini yükleyin:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Aşağıdaki örneği kullanarak AlloyDB Omni yük dengeleyici IP değişkenini dışa aktarın (IP yerine yük dengeleyicinizin IP'sini yazın):
export INSTANCE_IP=10.131.0.33
AlloyDB Omni'ye bağlanmak için my-omni.yaml içindeki karma ile ayarlanan şifre VeryStrongPassword'dır:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Oluşturulan psql oturumunda şunu çalıştırın:
create database demo;
Oturumdan çıkın ve veritabanı demosuna bağlanın (veya aynı oturumda \c demo komutunu çalıştırabilirsiniz).
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Dönüştürme işlevleri oluşturma
3. taraf yerleştirme modelleri için, giriş ve çıkışı modelin ve dahili işlevlerimizin beklediği biçimde biçimlendiren dönüştürme işlevleri oluşturmamız gerekir. Bu işlevler, farklı arayüzler arasında biçim dönüştürme işlemini gerçekleştirmek için çevirmen görevi görür.
Girişi işleyen dönüştürme işlevini aşağıda bulabilirsiniz:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
Örnek çıktıda gösterildiği gibi, demo veritabanına bağlıyken sağlanan kodu yürütün:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
Aşağıda, modelden gelen yanıtı gerçek sayılar dizisine dönüştüren çıkış işlevi yer almaktadır:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
Aynı oturumda yürütün:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
Modeli kaydetme
Artık modeli veritabanına kaydedebiliriz.
embeddinggemma adlı modeli kaydetmek için kullanılan prosedür çağrısı aşağıda verilmiştir. Modeli kaydederken tei-service hizmet adını model_request_url parametremizde kullanırız. Bu, dahili Kubernetes kümesi hizmet adıdır ve GKE kümesindeki dahili IP'ye çevrilir:
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
Demo veritabanına bağlıyken sağlanan kodu yürütün:
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
Kayıt modelini, gerçek sayılar dizisi döndürmesi gereken aşağıdaki test sorgusuyla test edebiliriz.
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
Vektör verilerini geri almadan önce uzun bir süre beklemeniz gerekebilir. Bu testte, yerleştirme modelini barındırmak için CPU tabanlı düğüm havuzu kullanıyoruz. Bu model, GPU'lu düğümlerde çok daha hızlı çalışıyor.
7. AlloyDB Omni'de modeli test etme
Veri Yükleme
AlloyDB Omni'nin dağıtılan modelle nasıl çalıştığını test etmek için bazı verileri yüklememiz gerekir. AlloyDB'de vektör araması için diğer codelab'lerden birinde kullanılan verileri kullandım.
Verileri yüklemenin bir yolu, Google Cloud SDK'yı ve PostgreSQL istemci yazılımını kullanmaktır. Aynı istemci sanal makinesini kullanabiliriz. Sanal makine görüntüsü için varsayılanları kullandıysanız Google Cloud SDK zaten yüklenmiş olmalıdır. Ancak Google SDK'sız özel bir resim kullandıysanız dokümanlardaki talimatları uygulayarak bu resmi ekleyebilirsiniz.
AlloyDB Omni yük dengeleyici IP'sini aşağıdaki örnekteki gibi dışa aktarın (IP yerine yük dengeleyici IP'nizi girin):
export INSTANCE_IP=10.131.0.33
Veritabanına bağlanın ve pgvector uzantısını etkinleştirin.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
psql oturumunda:
CREATE EXTENSION IF NOT EXISTS vector;
psql oturumundan çıkın ve komut satırı oturumunda verileri demo veritabanına yüklemek için komutları yürütün.
Tabloları oluşturun. Aşağıdaki komut, cymbal_demo_schema.sql dosyasını alır ve SQL'i demo veritabanındaki tüm tablo tanımlarıyla birlikte yürütür:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
Beklenen konsol çıkışı:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
Oluşturulan tabloların listesi:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Çıkış:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
cymbal_products tablosuna veri yükleme:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
Beklenen konsol çıkışı:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
cymbal_products tablosundaki birkaç satırın örneğini aşağıda bulabilirsiniz.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Çıkış:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
cymbal_inventory tablosuna veri yükleme:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
Beklenen konsol çıkışı:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
cymbal_inventory tablosundaki birkaç satırın örneğini aşağıda bulabilirsiniz.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Çıkış:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
cymbal_stores tablosuna veri yükleme:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
Beklenen konsol çıkışı:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
cymbal_stores tablosundaki birkaç satırın örneğini aşağıda bulabilirsiniz.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Çıkış:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
Yerleştirmeler Oluşturma
psql kullanarak demo veritabanına bağlanın ve ürün açıklamalarına göre cymbal_products tablosunda açıklanan ürünler için yerleştirilmiş öğeler oluşturun.
Demo veritabanına bağlanın:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Yerleştirmelerimizi depolamak için sütun yerleştirme içeren bir cymbal_embedding tablosu kullanıyoruz ve işlev için metin girişi olarak ürün açıklamasını kullanıyoruz.
Daha sonra uzaktan modellerle karşılaştırmak için sorgularınızın zamanlamasını etkinleştirin:
\timing
Yerleştirmeleri oluşturmak için sorguyu çalıştırın:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
Beklenen konsol çıkışı:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
Bu örnekte, yerleştirme oluşturma işlemi yaklaşık 8 dakika sürdü. Bu durum, CPU tabanlı düğüm havuzunda beklenir. GPU hızlandırıcıları olan bir havuzda, GPU türüne bağlı olarak önemli ölçüde daha hızlı olabilir.
Test Sorguları Çalıştırma
psql kullanarak demo veritabanına bağlanın ve yerleştirme oluştururken yaptığımız gibi sorgularımızın yürütme süresini ölçmek için zamanlamayı etkinleştirin.
Vektör aramasında algoritma olarak kosinüs uzaklığını kullanarak "Burada hangi tür meyve ağaçları iyi yetişir?" gibi bir istekle eşleşen ilk 5 ürünü bulalım.
psql oturumunda şunu çalıştırın:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Beklenen konsol çıkışı:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
Sorgu 83 ms sürdü ve cymbal_products tablosundaki, istekle eşleşen ve 1583 numaralı mağazada envanteri bulunan ağaçların listesini döndürdü.
ANN dizini oluşturma
Yalnızca küçük bir veri kümemiz olduğunda tüm yerleştirmeleri tarayan tam arama kullanmak kolaydır ancak veriler büyüdükçe yükleme ve yanıt süresi de artar. Performansı artırmak için yerleştirme verilerinizde dizinler oluşturabilirsiniz. Vektör verileri için Google ScaNN dizinini kullanarak bunu nasıl yapacağınızla ilgili bir örneği aşağıda bulabilirsiniz.
Bağlantıyı kaybettiyseniz demo veritabanına yeniden bağlanın:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
alloydb_scann uzantısını etkinleştirin:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Dizini oluşturun:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
Önceki sorguyu tekrar deneyin ve sonuçları karşılaştırın:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
Sorgu yürütme süresi biraz kısaldı ve bu kazanç daha büyük veri kümelerinde daha belirgin olacaktır. Sonuçlar oldukça benzer ve sonuçta aynı ilk 5 ağaç gösteriliyor.
Diğer sorguları deneyin ve dokümanlardan vektör dizini seçme hakkında daha fazla bilgi edinin.
Ayrıca AlloyDB Omni'de daha fazla özellik ve laboratuvar olduğunu unutmayın.
8. Ortamı temizleme
Artık AlloyDB Omni ve bir yapay zeka modeliyle GKE kümemizi silebiliriz.
GKE kümesini silme
Cloud Shell'de şunu çalıştırın:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
Beklenen konsol çıkışı:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
Sanal makineyi sil
Cloud Shell'de şunu çalıştırın:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Beklenen konsol çıkışı:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
Bu codelab için yeni bir proje oluşturduysanız bunun yerine projenin tamamını silebilirsiniz: https://console.cloud.google.com/cloud-resource-manager
9. Tebrikler
Codelab'i tamamladığınız için tebrik ederiz.
İşlediğimiz konular
- AlloyDB Omni'yi Google Kubernetes kümesine dağıtma
- AlloyDB Omni'ye bağlanma
- AlloyDB Omni'ye veri yükleme
- GKE'ye açık yerleştirme modeli dağıtma
- AlloyDB Omni'ye yerleştirme modeli kaydetme
- Semantik arama için yerleştirilmiş öğeler oluşturma
- AlloyDB Omni'de semantik arama için oluşturulan yerleştirmeleri kullanma
- AlloyDB'de vektör dizinleri oluşturma ve kullanma
AlloyDB Omni'de yapay zekayla çalışma hakkında daha fazla bilgiyi belgelerde bulabilirsiniz.
10. Anket
Çıkış: