
1. Giới thiệu
Trong lớp học lập trình này, bạn sẽ tìm hiểu cách triển khai AlloyDB Omni trên GKE và sử dụng AlloyDB Omni với một mô hình nhúng mở được triển khai trong cùng một cụm Kubernetes. Việc triển khai một mô hình bên cạnh phiên bản cơ sở dữ liệu trong cùng một cụm GKE giúp giảm độ trễ và các phần phụ thuộc vào dịch vụ bên thứ ba. Ngoài ra, việc triển khai cục bộ có thể là một yêu cầu do bộ phận bảo mật và tuân thủ thiết lập khi dữ liệu không được rời khỏi tổ chức và không được phép sử dụng các dịch vụ của bên thứ ba.
Điều kiện tiên quyết
- Có kiến thức cơ bản về Google Cloud Console
- Kiến thức cơ bản về Kubernetes và GKE
- Kỹ năng cơ bản về giao diện dòng lệnh và Cloud Shell
Kiến thức bạn sẽ học được
- Cách triển khai AlloyDB Omni trên cụm Google Kubernetes
- Cách kết nối với AlloyDB Omni
- Cách tải dữ liệu lên AlloyDB Omni
- Cách triển khai một mô hình nhúng mở vào GKE
- Cách đăng ký mô hình nhúng trong AlloyDB Omni
- Cách tạo các vectơ nhúng cho tính năng tìm kiếm ngữ nghĩa
- Cách sử dụng các mục nhúng được tạo để tìm kiếm ngữ nghĩa trong AlloyDB Omni
- Cách tạo và sử dụng chỉ mục vectơ trong AlloyDB
Bạn cần có
- Tài khoản Google Cloud và dự án trên Google Cloud
- Một trình duyệt web như Chrome hỗ trợ bảng điều khiển Cloud và Cloud Shell
2. Thiết lập và yêu cầu
Thiết lập dự án
- Đăng nhập vào Google Cloud Console. Nếu chưa có tài khoản Gmail hoặc Google Workspace, bạn phải tạo một tài khoản.
Sử dụng tài khoản cá nhân thay vì tài khoản trường học hoặc tài khoản do nơi làm việc cấp.
- Tạo một dự án mới hoặc sử dụng lại một dự án hiện có. Để tạo một dự án mới trong bảng điều khiển Google Cloud, trong tiêu đề, hãy nhấp vào nút Chọn dự án. Thao tác này sẽ mở một cửa sổ bật lên.

Trong cửa sổ Chọn một dự án, hãy nhấn vào nút Dự án mới. Thao tác này sẽ mở một hộp thoại cho dự án mới.
Trong hộp thoại, hãy nhập tên Dự án mà bạn muốn và chọn vị trí.
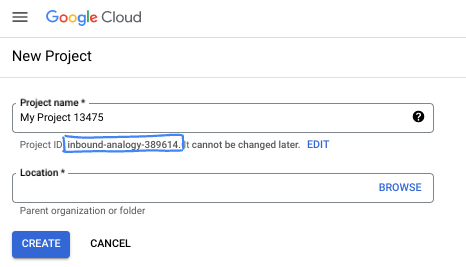
- Tên dự án là tên hiển thị của những người tham gia dự án này. Tên dự án không được các API của Google sử dụng và bạn có thể thay đổi tên này bất cứ lúc nào.
- Mã dự án là mã duy nhất trên tất cả các dự án trên Google Cloud và không thể thay đổi (bạn không thể thay đổi mã này sau khi đã đặt). Bảng điều khiển Cloud của Google tự động tạo một mã nhận dạng duy nhất, nhưng bạn có thể tuỳ chỉnh mã này. Nếu không thích mã nhận dạng được tạo, bạn có thể tạo một mã nhận dạng ngẫu nhiên khác hoặc cung cấp mã nhận dạng của riêng bạn để kiểm tra xem mã đó có còn trống hay không. Trong hầu hết các lớp học lập trình, bạn sẽ cần tham chiếu đến mã dự án của mình. Mã này thường được xác định bằng phần giữ chỗ PROJECT_ID.
- Để bạn nắm được thông tin, có một giá trị thứ ba là Số dự án mà một số API sử dụng. Tìm hiểu thêm về cả 3 giá trị này trong tài liệu.
Bật tính năng thanh toán
Thiết lập tài khoản thanh toán cá nhân
Nếu thiết lập thông tin thanh toán bằng tín dụng Google Cloud, bạn có thể bỏ qua bước này.
Để thiết lập tài khoản thanh toán cá nhân, hãy truy cập vào đây để bật tính năng thanh toán trong Cloud Console.
Một số ghi chú:
- Việc hoàn thành bài thực hành này sẽ tốn ít hơn 3 USD cho các tài nguyên trên đám mây.
- Bạn có thể làm theo các bước ở cuối bài thực hành này để xoá tài nguyên nhằm tránh bị tính thêm phí.
- Người dùng mới đủ điều kiện dùng thử miễn phí trị giá 300 USD.
Khởi động Cloud Shell
Mặc dù có thể vận hành Google Cloud từ xa trên máy tính xách tay, nhưng trong lớp học lập trình này, bạn sẽ sử dụng Google Cloud Shell, một môi trường dòng lệnh chạy trên Cloud.
Trên Bảng điều khiển Google Cloud, hãy nhấp vào biểu tượng Cloud Shell trên thanh công cụ ở trên cùng bên phải:
Hoặc bạn có thể nhấn G rồi nhấn S. Trình tự này sẽ kích hoạt Cloud Shell nếu bạn đang ở trong Google Cloud Console hoặc sử dụng đường liên kết này.
Quá trình này chỉ mất vài phút để cung cấp và kết nối với môi trường. Khi quá trình này kết thúc, bạn sẽ thấy như sau:

Máy ảo này được trang bị tất cả các công cụ phát triển mà bạn cần. Nó cung cấp một thư mục chính có dung lượng 5 GB và chạy trên Google Cloud, giúp tăng cường đáng kể hiệu suất mạng và hoạt động xác thực. Bạn có thể thực hiện mọi thao tác trong lớp học lập trình này trong trình duyệt. Bạn không cần cài đặt bất cứ thứ gì.
3. Trước khi bắt đầu
Bật API
Kết quả:
Để sử dụng Google Kubernetes Engine (GKE) cho việc triển khai AlloyDB Omni và các mô hình mở, bạn cần bật các API tương ứng trong dự án trên đám mây của mình.
Trong Cloud Shell, hãy đảm bảo bạn đã thiết lập mã dự án:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
Nếu chưa được xác định trong cấu hình Cloud Shell, hãy thiết lập bằng các lệnh sau
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
Bật tất cả các dịch vụ cần thiết:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
Kết quả đầu ra dự kiến
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Giới thiệu về các API
- Kubernetes Engine API (
container.googleapis.com) cho phép bạn tạo và quản lý các cụm Google Kubernetes Engine (GKE). Nền tảng này cung cấp một môi trường được quản lý để triển khai, quản lý và mở rộng quy mô các ứng dụng được chứa trong vùng chứa bằng cơ sở hạ tầng của Google. - Compute Engine API (
compute.googleapis.com) cho phép bạn tạo và quản lý máy ảo (VM), đĩa liên tục và chế độ cài đặt mạng. Nền tảng này cung cấp nền tảng Cơ sở hạ tầng dưới dạng dịch vụ (IaaS) cốt lõi cần thiết để chạy các khối lượng công việc và lưu trữ cơ sở hạ tầng cơ bản cho nhiều dịch vụ được quản lý.
4. Triển khai AlloyDB Omni trên GKE
Để triển khai AlloyDB Omni trên GKE, chúng ta cần chuẩn bị một cụm Kubernetes theo các yêu cầu được liệt kê trong phần Yêu cầu đối với trình điều khiển AlloyDB Omni.
Tạo một cụm GKE
Chúng ta cần triển khai một cụm GKE tiêu chuẩn có cấu hình nhóm đủ để triển khai một nhóm có phiên bản AlloyDB Omni. Đối với AlloyDB Omni, chúng ta cần ít nhất 2 CPU và 8 GB RAM, đồng thời có một số dung lượng cho các vùng chứa dịch vụ giám sát và người vận hành. Chúng ta sẽ sử dụng loại VM e2-standard-4.
Thiết lập các biến môi trường cho quá trình triển khai.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
Sau đó, chúng ta dùng gcloud để tạo cụm tiêu chuẩn GKE.
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Kết quả đầu ra dự kiến trên bảng điều khiển:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
Chuẩn bị Cụm
Chúng ta cần cài đặt các thành phần bắt buộc như dịch vụ cert-manager – trình quản lý chứng chỉ gốc cho kubernetes. Chúng ta có thể làm theo các bước trong tài liệu để cài đặt cert-manager
Chúng ta sẽ sử dụng công cụ dòng lệnh Kubernetes (kubectl) được cài đặt sẵn trong Cloud Shell theo mặc định. Trước khi sử dụng tiện ích này, chúng ta cần lấy thông tin đăng nhập cho cụm.
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
Bây giờ, chúng ta có thể dùng kubectl để cài đặt cert-manager:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.19.2/cert-manager.yaml
Kết quả đầu ra dự kiến trên bảng điều khiển(đã chỉnh sửa):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
Cài đặt AlloyDB Omni
Bạn có thể cài đặt trình cài đặt AlloyDB Omni bằng tiện ích helm.
Chạy lệnh sau để cài đặt trình điều khiển AlloyDB Omni:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
Kết quả đầu ra dự kiến trên bảng điều khiển(đã chỉnh sửa):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
Khi cài đặt trình điều khiển AlloyDB Omni, chúng ta có thể tiếp tục triển khai cụm cơ sở dữ liệu.
Sau đây là ví dụ về tệp kê khai triển khai có tham số googleMLExtension đã bật và bộ cân bằng tải nội bộ (riêng tư).
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.13.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
Giá trị bí mật cho mật khẩu là một giá trị Base64 biểu thị từ mật khẩu "VeryStrongPassword". Cách đáng tin cậy hơn là sử dụng trình quản lý bí mật của Google để lưu trữ giá trị mật khẩu. Bạn có thể đọc thêm về vấn đề này trong tài liệu.
Lưu tệp kê khai dưới dạng my-omni.yaml để áp dụng trong bước tiếp theo. Nếu đang ở trong Cloud Shell, bạn có thể thực hiện việc này bằng trình chỉnh sửa bằng cách nhấn vào nút "Open Editor" (Mở trình chỉnh sửa) ở trên cùng bên phải của thiết bị đầu cuối.
Sau khi lưu tệp có tên my-omni.yaml, hãy quay lại thiết bị đầu cuối bằng cách nhấn vào nút "Open Terminal" (Mở thiết bị đầu cuối).
Áp dụng tệp kê khai my-omni.yaml cho cụm bằng tiện ích kubectl:
kubectl apply -f my-omni.yaml
Kết quả đầu ra dự kiến trên bảng điều khiển:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
Kiểm tra trạng thái của cụm my-omni bằng tiện ích kubectl:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Trong quá trình triển khai, cụm sẽ trải qua nhiều giai đoạn và cuối cùng sẽ kết thúc ở trạng thái DBClusterReady.
Kết quả đầu ra dự kiến trên bảng điều khiển:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
Kết nối với AlloyDB Omni
Kết nối bằng Pod Kubernetes
Khi cụm đã sẵn sàng, chúng ta có thể sử dụng các tệp nhị phân của ứng dụng PostgreSQL trên nhóm phiên bản AlloyDB Omni. Chúng tôi tìm thấy mã nhận dạng nhóm rồi dùng kubectl để kết nối trực tiếp với nhóm và chạy phần mềm máy khách. Mật khẩu là VeryStrongPassword như được thiết lập thông qua kubernetes secret trong tệp kê khai my-omni.yaml:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Ví dụ về thông tin xuất trên bảng điều khiển:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. Triển khai mô hình AI trên GKE
Để kiểm thử tính năng tích hợp AI của AlloyDB Omni với các mô hình cục bộ, chúng ta cần triển khai một mô hình cho cụm. Chúng ta sẽ sử dụng mô hình EmbeddingGemma của Google.
Tạo Nhóm nút cho Mô hình
Để chạy mô hình, chúng ta cần chuẩn bị một bộ nút để chạy suy luận. Chúng ta có thể chạy nó bằng cách chỉ sử dụng nhóm CPU hoặc nhóm có bộ tăng tốc GPU. Phương pháp chỉ dùng CPU có thể phù hợp hơn ở một số khu vực do tính đồng thời cao đối với các tài nguyên. Trong phòng thí nghiệm, chúng ta sẽ sử dụng phương pháp CPU, nhưng phương pháp tốt nhất về hiệu suất là một nhóm có bộ tăng tốc đồ hoạ bằng cách sử dụng cấu hình nút như g2-standard-8 với bộ tăng tốc Nvidia L4.
Nhóm nút dựa trên CPU
Tạo một bộ nút có 32 nút e2-standard. Chúng ta sẽ giới hạn thao tác kéo xuống ở một nút để tiết kiệm tài nguyên.
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create cpupool \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=c3-standard-8 \
--num-nodes=1
Kết quả đầu ra dự kiến
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create cpupool \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=c3-standard-8 \
> --num-nodes=1
Creating node pool cpupool...done.
Created [https://container.googleapis.com/v1/projects/gleb-test-short-003-483115/zones/us-central1/clusters/alloydb-ai-gke/nodePools/cpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
cpupool c3-standard-8 100 1.34.1-gke.3355002
Lấy mã thông báo Hugging Face
Trong phòng thí nghiệm này, chúng tôi hợp tác với Hugging Face để triển khai mô hình EmbeddingGemma. Để làm như vậy, chúng tôi cần lấy một mã thông báo Hugging Face.
Hãy làm theo các bước bên dưới để tạo mã thông báo mới nếu bạn chưa có mã thông báo nào trước đây.
- Đăng nhập hoặc đăng ký trên trang web Hugging Face bằng cách sử dụng đường liên kết Đăng nhập hoặc Đăng ký ở góc trên bên phải.
- Nhấp vào Hồ sơ của bạn -> Mã truy cập
- Xác nhận danh tính của bạn
- Nhấp vào Tạo mã thông báo mới
- Chọn tên cho mã thông báo của bạn
- Chọn một vai trò cho mã thông báo – bạn cần có ít nhất đặc quyền Đọc
- Nhấp vào Tạo mã thông báo ở cuối trang
- Sao chép mã thông báo đã tạo và lưu mã này để sử dụng sau
Bạn cũng cần chấp nhận các điều kiện để truy cập vào các tệp và nội dung liên quan đến EmbeddingGemma trên Hugging Face tại trang https://huggingface.co/google/embeddinggemma-300m
Tạo một khoá bí mật kubernetes bằng mã thông báo
Trong phiên cloud shell, hãy thực thi (thay thế giá trị cho HF_TOKEN bằng mã thông báo HF của bạn).
export HF_TOKEN=hf_QjgW...lfrXF
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=$HF_TOKEN \
--dry-run=client -o yaml | kubectl apply -f -
Chuẩn bị tệp kê khai triển khai
Để triển khai mô hình, chúng ta cần chuẩn bị một tệp kê khai triển khai.
Chúng tôi đang sử dụng mô hình EmbeddingGemma của Google trên Hugging Face. Bạn có thể đọc thẻ mô hình tại đây. Để triển khai mô hình, chúng ta sẽ sử dụng một phương pháp dựa trên hướng dẫn của Hugging Face và gói triển khai của GitHub.
Sao chép gói từ GitHub
git clone https://github.com/huggingface/Google-Cloud-Containers
Điều chỉnh tệp kê khai cho tei (giao diện nhúng văn bản) trên các nút CPU. Chúng ta cần thay thế một số tham số, bao gồm cả mô hình, hình ảnh, việc phân bổ tài nguyên chính xác và thêm mã thông báo bí mật của Hugging Face vào cấu hình.
Chỉnh sửa tệp kê khai (bằng trình chỉnh sửa bất kỳ)
vi Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config/deployment.yaml
Sau đây là tệp kê khai đã được sửa cho việc triển khai trên một nhóm dựa trên CPU.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Google--embeddinggemma-300m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: ghcr.io/huggingface/text-embeddings-inference:cpu-latest
#image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cpu.1-4:latest
resources:
requests:
cpu: "6"
memory: "24Gi"
limits:
cpu: "6"
memory: "24Gi"
env:
- name: MODEL_ID
value: google/embeddinggemma-300m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_api_token
volumeMounts:
- mountPath: /tmp
name: tmp
volumes:
- name: tmp
emptyDir: {}
nodeSelector:
#cloud.google.com/compute-class: "Performance"
cloud.google.com/machine-family: "c3"
Triển khai mô hình
Triển khai mô hình bằng cách áp dụng tệp kê khai đã sửa đổi cho các lượt triển khai CPU.
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/cpu-config
Xác minh các quy trình triển khai
kubectl get pods
Xác minh dịch vụ mô hình
kubectl get service tei-service
Thao tác này sẽ cho thấy loại dịch vụ đang chạy ClusterIP
Kết quả mẫu:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
CLUSTER-IP cho dịch vụ là những gì chúng ta sẽ sử dụng làm địa chỉ điểm cuối. Hoạt động nhúng mô hình có thể phản hồi bằng URI http://34.118.233.48:8080/embed. Bạn sẽ sử dụng giá trị này sau khi đăng ký mô hình trong AlloyDB Omni.
Chúng ta có thể kiểm thử bằng cách hiển thị nó bằng lệnh chuyển tiếp cổng kubectl.
kubectl port-forward service/tei-service 8080:8080
Nếu đang dùng Cloud Shell, bạn có thể chạy tính năng chuyển tiếp cổng trong một phiên Cloud Shell và cần một phiên khác để kiểm thử tính năng này.
Mở một thẻ Cloud Shell khác bằng cách sử dụng dấu "+" ở trên cùng.
Và chạy lệnh curl trong phiên shell mới.
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
Lệnh này sẽ trả về một mảng vectơ như trong kết quả mẫu sau (đã chỉnh sửa):
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
Nếu thấy các con số này, chúng ta có thể xác nhận rằng mình đã kiểm thử thành công mô hình và giờ đây có thể đăng ký mô hình đó trong AlloyDB Omni để sử dụng trực tiếp từ SQL.
6. Đăng ký Mô hình trong AlloyDB Omni
Để kiểm thử cách AlloyDB Omni hoạt động với mô hình đã triển khai, chúng ta cần tạo một cơ sở dữ liệu và đăng ký mô hình đó.
Tạo cơ sở dữ liệu
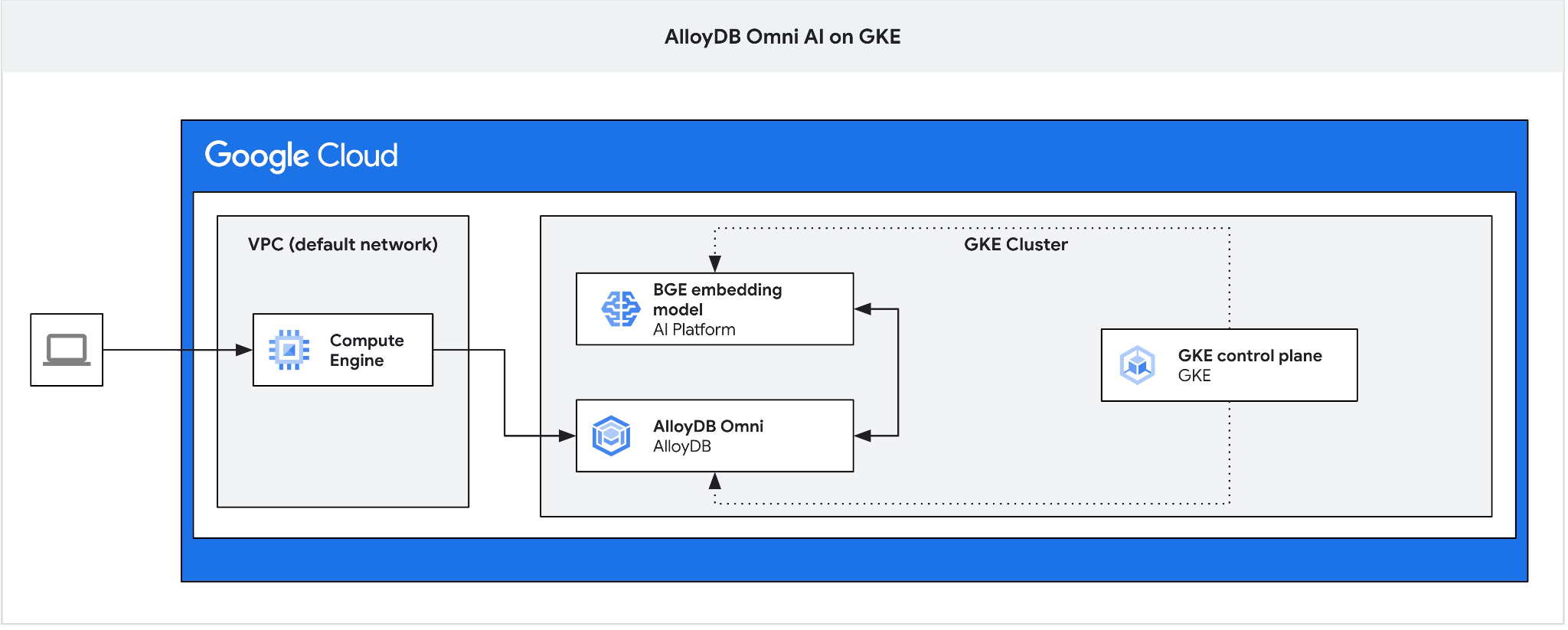
Tạo một máy ảo GCE làm hộp chuyển để kết nối với AlloyDB Omni từ máy ảo ứng dụng và tạo một cơ sở dữ liệu.
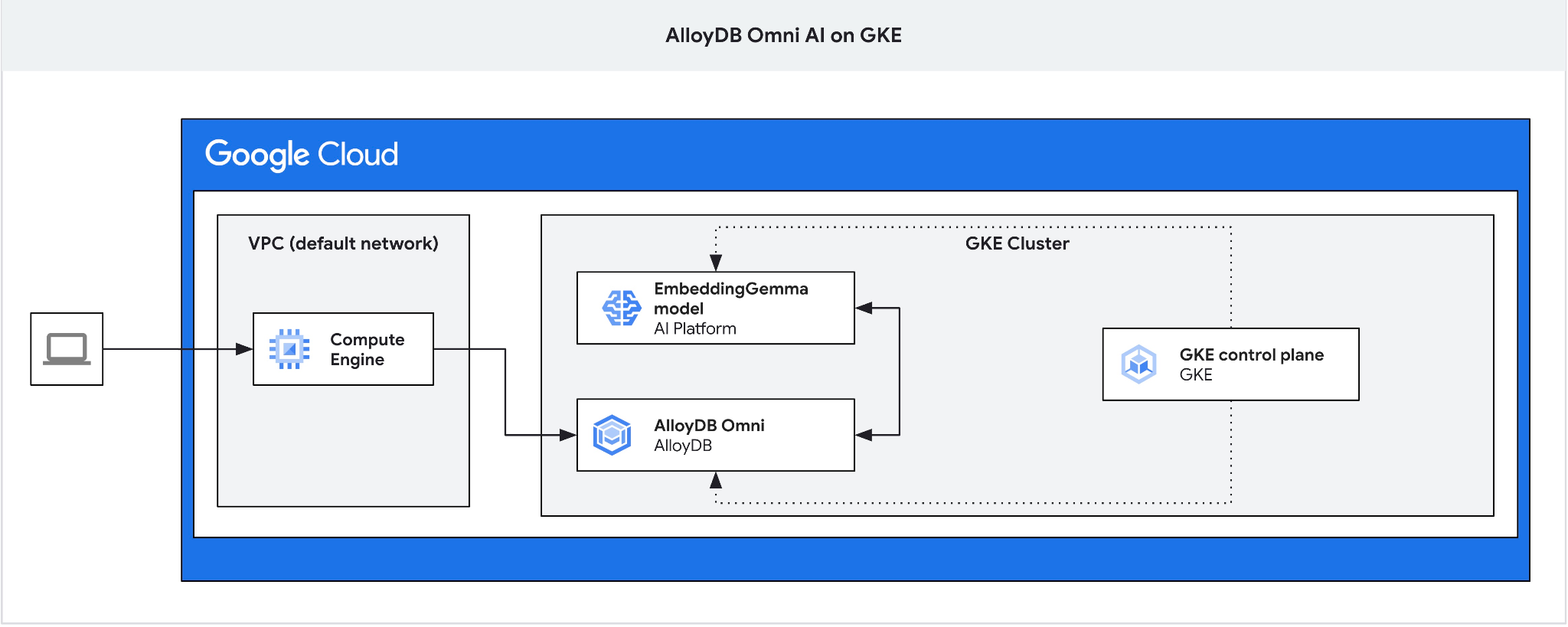
Chúng tôi cần hộp chuyển tiếp vì bộ cân bằng tải bên ngoài GKE cho Omni cho phép bạn truy cập từ VPC bằng cách sử dụng địa chỉ IP riêng tư nhưng không cho phép bạn kết nối từ bên ngoài VPC. Nhìn chung, phương thức này an toàn hơn và không để lộ phiên bản cơ sở dữ liệu của bạn trên Internet. Vui lòng xem sơ đồ để cho rõ ràng.
Để tạo một máy ảo trong phiên Cloud Shell, hãy thực thi:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
Tìm IP điểm cuối AlloyDB Omni bằng kubectl trong Cloud Shell:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
Ghi lại PRIMARYENDPOINT.
Sau đây là một ví dụ về kết quả:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33 là IP mà chúng ta sẽ sử dụng trong các ví dụ để kết nối với phiên bản AlloyDB Omni.
Kết nối với máy ảo bằng gcloud:
gcloud compute ssh instance-1 --zone=$ZONE
Nếu được nhắc tạo khoá SSH, hãy làm theo hướng dẫn. Đọc thêm về kết nối SSH trong tài liệu này.
Trong phiên ssh đến VM, hãy cài đặt ứng dụng PostgreSQL:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Xuất biến IP của trình cân bằng tải AlloyDB Omni bằng ví dụ sau (thay thế IP bằng IP của trình cân bằng tải):
export INSTANCE_IP=10.131.0.33
Kết nối với AlloyDB Omni, mật khẩu là VeryStrongPassword như được đặt thông qua hàm băm trong my-omni.yaml:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Trong phiên psql đã thiết lập, hãy thực thi:
create database demo;
Thoát phiên và kết nối với bản minh hoạ cơ sở dữ liệu (hoặc bạn chỉ cần chạy \c demo trong cùng một phiên)
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Tạo hàm biến đổi
Đối với các mô hình nhúng của bên thứ ba, chúng ta cần tạo các hàm biến đổi để định dạng đầu vào và đầu ra theo định dạng mà mô hình và các hàm nội bộ của chúng ta mong đợi. Những hàm này hoạt động như trình dịch để chuyển đổi định dạng giữa các giao diện khác nhau.
Sau đây là hàm biến đổi xử lý dữ liệu đầu vào:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
Thực thi mã được cung cấp trong khi kết nối với cơ sở dữ liệu minh hoạ như trong đầu ra mẫu:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
Và đây là hàm đầu ra giúp chuyển đổi phản hồi từ mô hình thành mảng số thực:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
Thực thi trong cùng một phiên:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
Đăng ký mô hình
Giờ đây, chúng ta có thể đăng ký mô hình trong cơ sở dữ liệu.
Sau đây là lệnh gọi quy trình để đăng ký mô hình có tên embeddinggemma. Chúng tôi sử dụng tên dịch vụ tei-service trong tham số model_request_url khi đăng ký mô hình. Đó là tên dịch vụ cụm kubernetes nội bộ và chuyển đổi thành IP nội bộ trong cụm GKE:
CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
Thực thi mã đã cung cấp trong khi kết nối với cơ sở dữ liệu minh hoạ:
demo=# CALL
google_ml.create_model(
model_id => 'embeddinggemma',
model_request_url => 'http://tei-service:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
Chúng ta có thể kiểm thử mô hình đăng ký bằng cách sử dụng truy vấn kiểm thử sau đây. Truy vấn này sẽ trả về một mảng số thực.
select google_ml.embedding('embeddinggemma','What is AlloyDB Omni?');
Đừng ngạc nhiên khi thấy độ trễ kéo dài trước khi nhận lại dữ liệu vectơ. Đối với thử nghiệm này, chúng tôi sử dụng nhóm nút dựa trên CPU để lưu trữ mô hình nhúng và mô hình này hoạt động nhanh hơn nhiều trên các nút có GPU.
7. Kiểm thử Mô hình trong AlloyDB Omni
Tải dữ liệu
Để kiểm thử cách AlloyDB Omni hoạt động với mô hình đã triển khai, chúng ta cần tải một số dữ liệu. Tôi đã sử dụng cùng một dữ liệu như trong một trong những lớp học lập trình khác để tìm kiếm vectơ trong AlloyDB.
Một cách để tải dữ liệu là sử dụng Google Cloud SDK và phần mềm máy khách PostgreSQL. Chúng ta có thể sử dụng cùng một máy ảo khách. Google Cloud SDK sẽ được cài đặt sẵn ở đó nếu bạn đã sử dụng các giá trị mặc định cho hình ảnh máy ảo. Nhưng nếu đã sử dụng một hình ảnh tuỳ chỉnh không có SDK của Google, bạn có thể thêm hình ảnh đó theo tài liệu.
Xuất IP của trình cân bằng tải AlloyDB Omni như trong ví dụ sau (thay thế IP bằng IP của trình cân bằng tải):
export INSTANCE_IP=10.131.0.33
Kết nối với cơ sở dữ liệu và bật tiện ích pgvector.
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Trong phiên psql:
CREATE EXTENSION IF NOT EXISTS vector;
Thoát phiên psql và trong phiên dòng lệnh, hãy thực thi các lệnh để tải dữ liệu vào cơ sở dữ liệu minh hoạ.
Tạo bảng. Lệnh sau đây sẽ lấy tệp cymbal_demo_schema.sql và thực thi SQL với tất cả các định nghĩa bảng trong cơ sở dữ liệu minh hoạ:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
Kết quả đầu ra dự kiến trên bảng điều khiển:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
Dưới đây là danh sách các bảng đã tạo:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Kết quả:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
Tải dữ liệu vào bảng cymbal_products:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
Kết quả đầu ra dự kiến trên bảng điều khiển:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
Dưới đây là mẫu của một vài hàng trong bảng cymbal_products.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Kết quả:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
Tải dữ liệu vào bảng cymbal_inventory:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
Kết quả đầu ra dự kiến trên bảng điều khiển:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
Dưới đây là mẫu của một vài hàng trong bảng cymbal_inventory.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Kết quả:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
Tải dữ liệu vào bảng cymbal_stores:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
Kết quả đầu ra dự kiến trên bảng điều khiển:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
Dưới đây là mẫu của một vài hàng trong bảng cymbal_stores.
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Kết quả:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
Tạo vectơ nhúng
Kết nối với cơ sở dữ liệu minh hoạ bằng psql và tạo các mục nhúng cho những sản phẩm được mô tả trong bảng cymbal_products dựa trên nội dung mô tả sản phẩm.
Kết nối với cơ sở dữ liệu minh hoạ:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Chúng tôi đang sử dụng bảng cymbal_embedding có tính năng nhúng cột để lưu trữ các mục nhúng và sử dụng nội dung mô tả sản phẩm làm dữ liệu đầu vào văn bản cho hàm.
Bật tính năng đo thời gian cho các truy vấn để so sánh sau này với các mô hình từ xa:
\timing
Chạy truy vấn để tạo các vectơ nhúng:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
Kết quả đầu ra dự kiến trên bảng điều khiển:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('embeddinggemma',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 497878.136 ms (08:17.878)
demo=#
Trong ví dụ này, việc tạo các vectơ nhúng mất khoảng 8 phút. Đây là điều dự kiến đối với bộ nút dựa trên CPU. Đối với một nhóm có trình tăng tốc GPU, quá trình này có thể diễn ra nhanh hơn đáng kể, tuỳ thuộc vào loại GPU.
Chạy truy vấn kiểm thử
Kết nối với cơ sở dữ liệu minh hoạ bằng psql và bật tính năng đo thời gian để đo thời gian thực thi cho các truy vấn của chúng ta như khi tạo các mục nhúng.
Hãy tìm 5 sản phẩm hàng đầu phù hợp với một yêu cầu như "Ở đây có loại cây ăn quả nào phát triển tốt?" bằng cách sử dụng khoảng cách cosine làm thuật toán cho tìm kiếm vectơ.
Trong phiên psql, hãy thực thi:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Kết quả đầu ra dự kiến trên bảng điều khiển:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 83.610 ms
demo=#
Truy vấn chạy 83 mili giây và trả về một danh sách các cây từ bảng cymbal_products khớp với yêu cầu và có hàng tồn kho tại cửa hàng có số 1583.
Tạo chỉ mục ANN
Khi chỉ có một tập dữ liệu nhỏ, bạn có thể dễ dàng sử dụng tính năng tìm kiếm chính xác để quét tất cả các mục nhúng. Tuy nhiên, khi dữ liệu tăng lên, thời gian tải và phản hồi cũng tăng theo. Để cải thiện hiệu suất, bạn có thể tạo chỉ mục trên dữ liệu nhúng. Dưới đây là ví dụ về cách thực hiện bằng cách sử dụng chỉ mục Google ScaNN cho dữ liệu vectơ.
Kết nối lại với cơ sở dữ liệu minh hoạ nếu bạn bị mất kết nối:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
Bật tiện ích alloydb_scann:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Tạo chỉ mục:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
Hãy thử dùng cùng một cụm từ tìm kiếm như trước và so sánh kết quả:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('embeddinggemma','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+--------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.5210549378080666
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.5639421771781971
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.5670010914504852
Rose Bush | This is a beautiful rose bush that will produce fragrant roses. It is a perennia | 50.00 | 93230 | 0.5731542622882957
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5750934653011995
(5 rows)
Time: 64.783 ms
Thời gian thực thi truy vấn đã giảm nhẹ và mức tăng này sẽ đáng chú ý hơn với các tập dữ liệu lớn hơn. Kết quả khá tương đồng và chúng tôi nhận được 5 cây hàng đầu giống nhau trong kết quả.
Hãy thử các truy vấn khác và đọc thêm về cách chọn chỉ mục vectơ trong tài liệu.
Đừng quên rằng AlloyDB Omni có nhiều tính năng và phòng thí nghiệm hơn.
8. Dọn dẹp môi trường
Giờ đây, chúng ta có thể xoá cụm GKE bằng AlloyDB Omni và một mô hình AI
Xoá cụm GKE
Trong Cloud Shell, hãy thực thi:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
Kết quả đầu ra dự kiến trên bảng điều khiển:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
Xoá máy ảo
Trong Cloud Shell, hãy thực thi:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Kết quả đầu ra dự kiến trên bảng điều khiển:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
Nếu đã tạo một dự án mới cho lớp học lập trình này, bạn có thể xoá toàn bộ dự án: https://console.cloud.google.com/cloud-resource-manager
9. Xin chúc mừng
Chúc mừng bạn đã hoàn thành lớp học lập trình này.
Nội dung đã đề cập
- Cách triển khai AlloyDB Omni trên cụm Google Kubernetes
- Cách kết nối với AlloyDB Omni
- Cách tải dữ liệu lên AlloyDB Omni
- Cách triển khai một mô hình nhúng mở vào GKE
- Cách đăng ký mô hình nhúng trong AlloyDB Omni
- Cách tạo các vectơ nhúng cho tính năng tìm kiếm ngữ nghĩa
- Cách sử dụng các mục nhúng được tạo để tìm kiếm ngữ nghĩa trong AlloyDB Omni
- Cách tạo và sử dụng chỉ mục vectơ trong AlloyDB
Bạn có thể đọc thêm về cách làm việc với AI trong AlloyDB Omni trong tài liệu.
10. Khảo sát
Kết quả: