
1. Einführung
In der schnelllebigen Datenlandschaft von heute sind Echtzeitinformationen entscheidend für fundierte Entscheidungen. In diesem Codelab erfahren Sie, wie Sie eine Echtzeit-Evaluierungspipeline erstellen. Wir beginnen mit dem Apache Beam-Framework, das ein einheitliches Programmiermodell für Batch- und Streamingdaten bietet. Dadurch wird die Pipelineentwicklung erheblich vereinfacht, da die komplexe Logik für verteiltes Computing abstrahiert wird, die Sie sonst von Grund auf neu erstellen müssten. Sobald Ihre Pipeline mit Beam definiert ist, können Sie sie nahtlos in Google Cloud Dataflow ausführen. Dieser vollständig verwaltete Dienst bietet eine beispiellose Skalierbarkeit und Leistung für Ihre Datenverarbeitungsanforderungen.
In diesem Codelab erfahren Sie, wie Sie eine skalierbare Apache Beam-Pipeline für Machine-Learning-Inferenz entwerfen, einen benutzerdefinierten ModelHandler entwickeln, um das Gemini-Modell von Vertex AI einzubinden, Prompt-Engineering für die intelligente Textklassifizierung in Datenstreams nutzen und diese Streaming-ML-Inferenzpipeline in Google Cloud Dataflow bereitstellen und ausführen. Am Ende erhalten Sie wertvolle Einblicke in die Anwendung von maschinellem Lernen für das Verständnis von Echtzeitdaten und die kontinuierliche Evaluierung in Engineering-Workflows, insbesondere für die Aufrechterhaltung einer robusten und nutzerorientierten konversationellen KI.
Szenario
Ihr Unternehmen hat einen Datenagenten erstellt. Ihr Daten-KI-Agent, der mit dem Agent Development Kit (ADK) erstellt wurde, ist mit verschiedenen speziellen Funktionen ausgestattet, um Sie bei datenbezogenen Aufgaben zu unterstützen. Stellen Sie sich Gemini als vielseitigen Datenassistenten vor, der in der Lage ist, verschiedene Anfragen zu bearbeiten. Er kann als BI-Analyst fungieren, um aussagekräftige Berichte zu erstellen, als Data Engineer, um robuste Datenpipelines zu entwickeln, oder als SQL-Generator, um präzise SQL-Anweisungen zu erstellen. Jede Interaktion dieses Agents und jede Antwort, die er generiert, wird automatisch in Firestore gespeichert. Aber warum brauchen wir hier eine Pipeline?
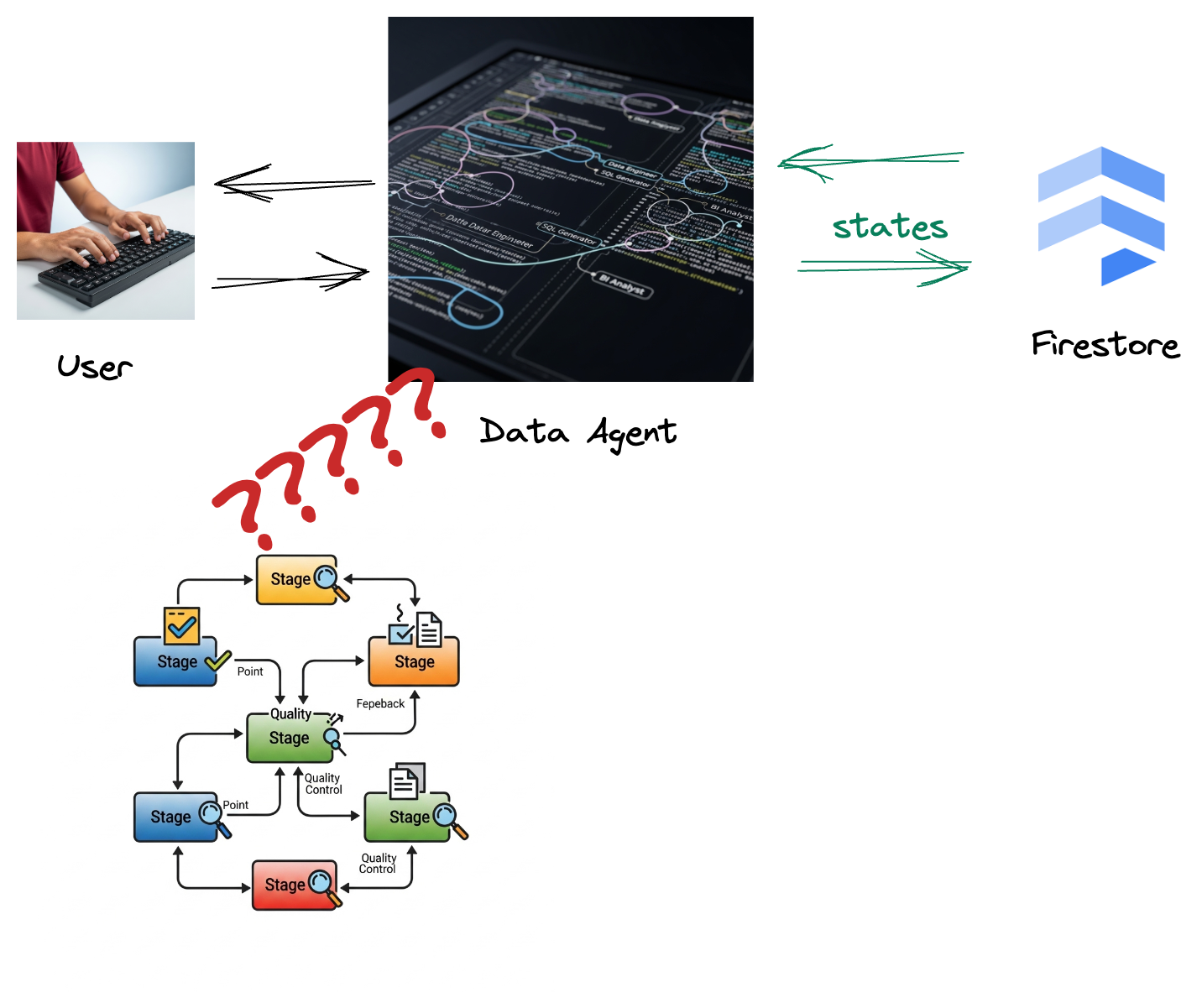
Da ein Trigger diese Interaktionsdaten nahtlos von Firestore an Pub/Sub sendet, können wir diese wichtigen Unterhaltungen sofort in Echtzeit verarbeiten und analysieren.
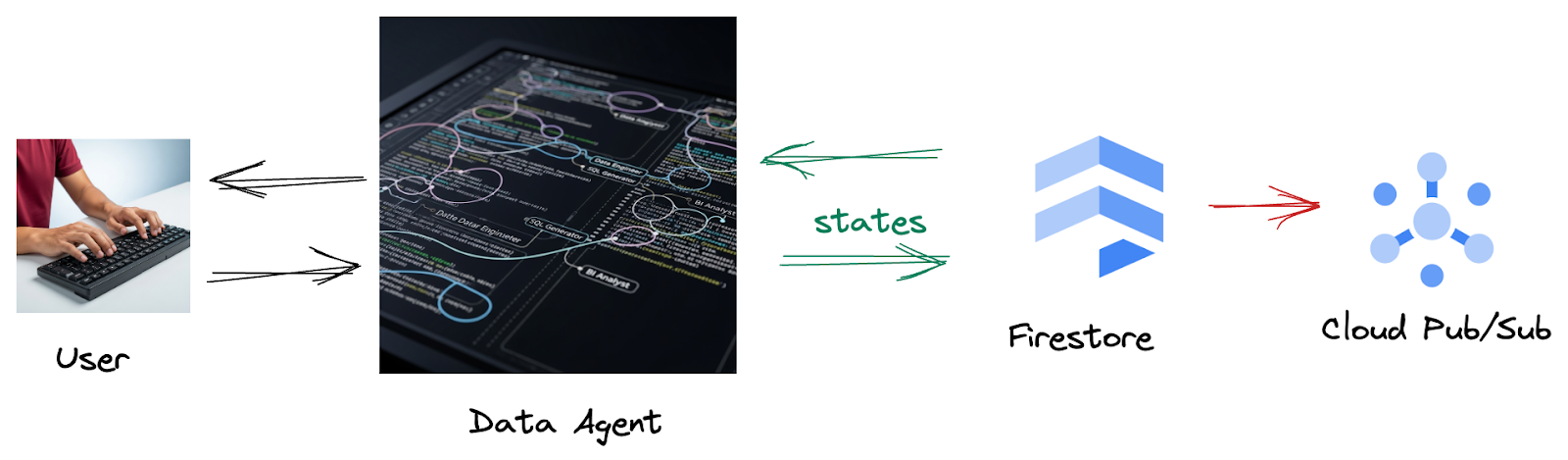
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
- Aktivieren Sie Cloud Shell, indem Sie auf diesen Link klicken. Sie können zwischen dem Cloud Shell-Terminal (zum Ausführen von Cloud-Befehlen) und dem Editor (zum Erstellen von Projekten) wechseln, indem Sie in Cloud Shell auf die entsprechende Schaltfläche klicken.
- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
- Aktivieren Sie die erforderlichen APIs mit dem unten gezeigten Befehl. Das kann einige Minuten dauern.
gcloud services enable \
dataflow.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Achten Sie darauf, dass Sie Python 3.10 oder höher verwenden.
- Python-Pakete installieren
Installieren Sie die erforderlichen Python-Bibliotheken für Apache Beam, Google Cloud Vertex AI und Google Generative AI in Ihrer Cloud Shell-Umgebung.
pip install apache-beam[gcp] google-genai
- Klonen Sie das GitHub-Repository und wechseln Sie in das Demoverzeichnis.
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/beam_as_eval
Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
3. Verwendung des bereitgestellten GitHub-Repositorys
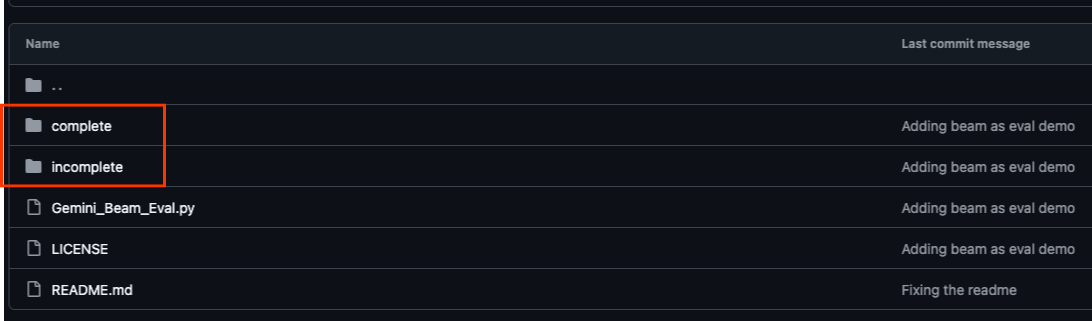
Das mit diesem Codelab verknüpfte GitHub-Repository unter https://github.com/GoogleCloudPlatform/devrel-demos/tree/main/data-analytics/beam_as_eval ist so organisiert, dass ein geführter Lernprozess möglich ist. Es enthält Skelettcode, der auf die einzelnen Abschnitte des Codelabs abgestimmt ist, sodass das Material klar strukturiert ist.
Im Repository finden Sie zwei Hauptordner: „complete“ und „incomplete“. Der Ordner „complete“ enthält voll funktionsfähigen Code für jeden Schritt, sodass Sie die beabsichtigte Ausgabe ausführen und beobachten können. Im Ordner „incomplete“ finden Sie Code aus vorherigen Schritten. Bestimmte Abschnitte sind zwischen ##### START STEP <NUMBER> ##### und ##### END STEP <NUMBER> ##### markiert und müssen im Rahmen der Übungen von Ihnen vervollständigt werden. Diese Struktur ermöglicht es Ihnen, auf Ihrem Vorwissen aufzubauen und gleichzeitig aktiv an den Programmieraufgaben teilzunehmen.
4. Architekturübersicht
Unsere Pipeline bietet ein leistungsstarkes und skalierbares Muster für die Integration von ML-Inferenz in Datenstreams. So fügen sich die einzelnen Teile zusammen:
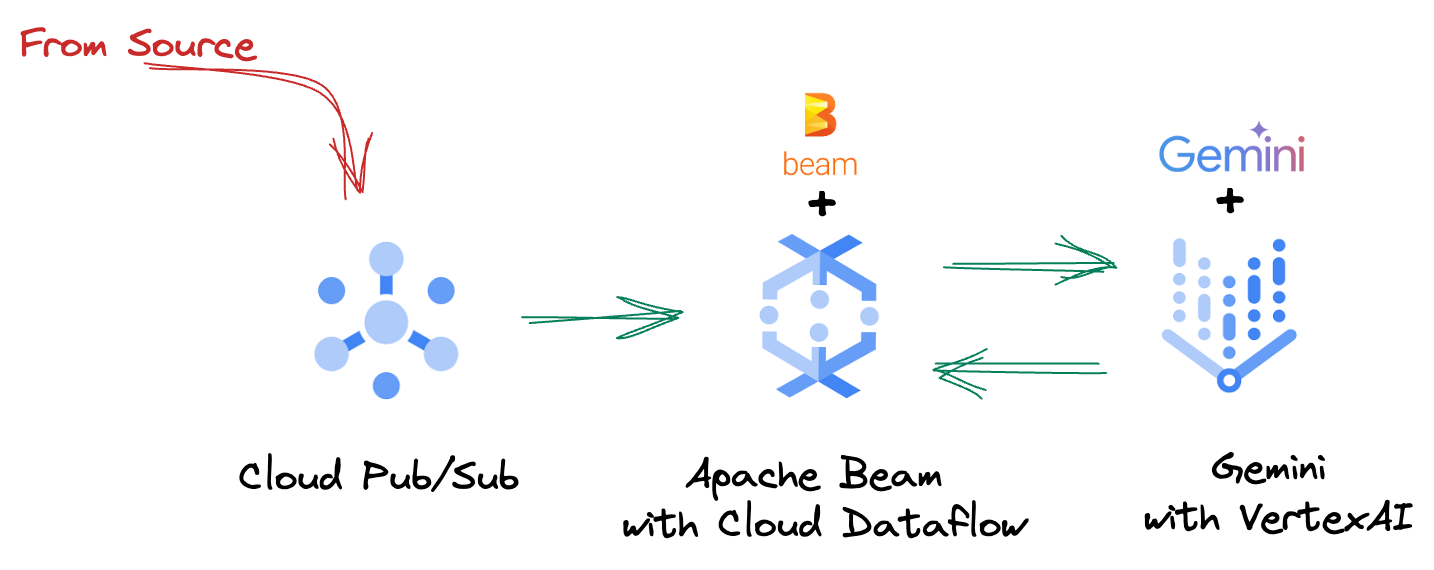
In Ihrer Beam-Pipeline codieren Sie mehrere Eingaben bedingt und laden dann benutzerdefinierte Modelle mit der sofort einsatzbereiten Transformation RunInference. Auch wenn Sie im Beispiel Gemini mit Vertex AI verwenden, wird gezeigt, wie Sie im Grunde mehrere ModelHandler erstellen, die der Anzahl der Modelle entsprechen, die Sie haben. Schließlich verwenden Sie ein zustandsbehaftetes DoFn, um Ereignisse zu verfolgen und kontrolliert auszugeben.
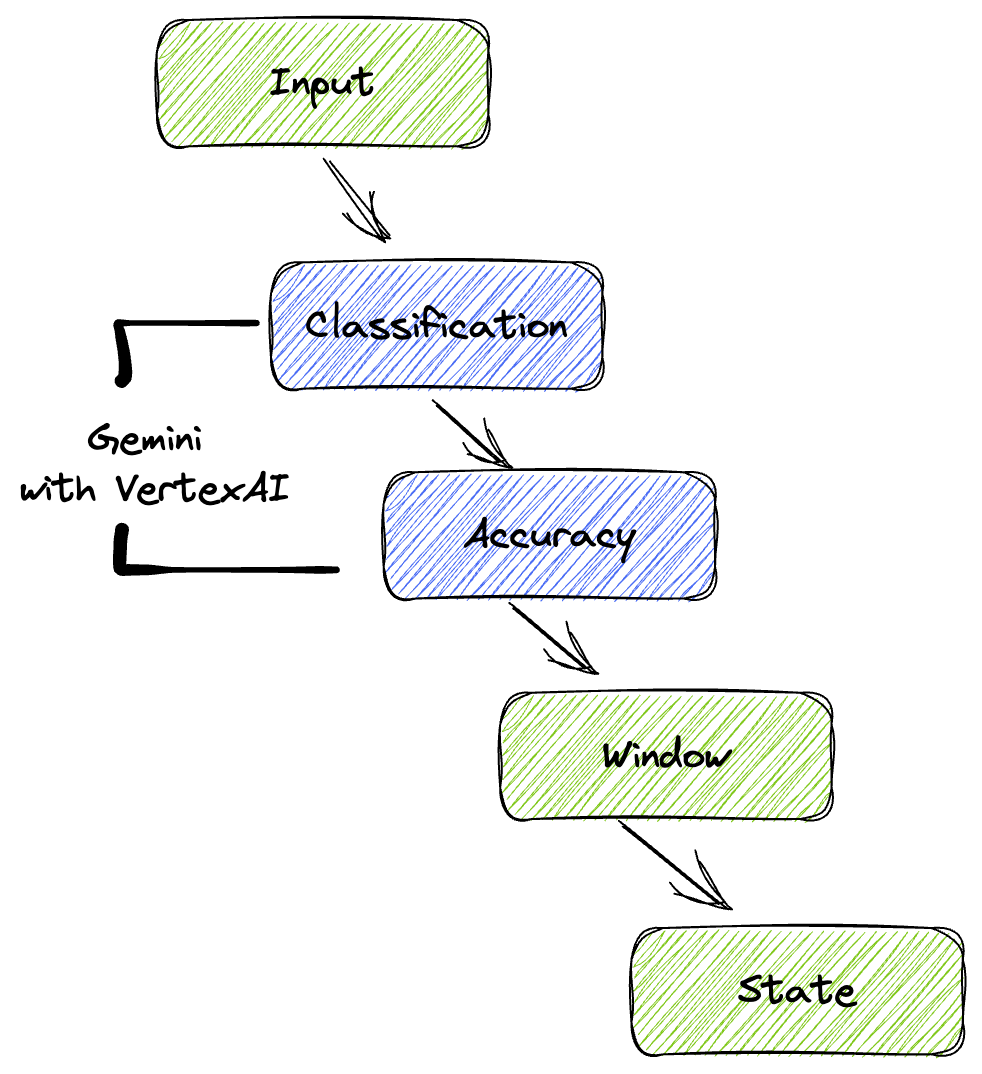
5. Daten aufnehmen
Zuerst richten Sie Ihre Pipeline für die Aufnahme von Daten ein. Sie verwenden Pub/Sub für das Echtzeit-Streaming, erstellen aber auch einen Testmodus, um die Entwicklung zu vereinfachen. Mit diesem test_mode können Sie die Pipeline lokal mit vordefinierten Beispieldaten ausführen. Sie benötigen also keinen Live-Pub/Sub-Stream, um zu sehen, ob Ihre Pipeline funktioniert.
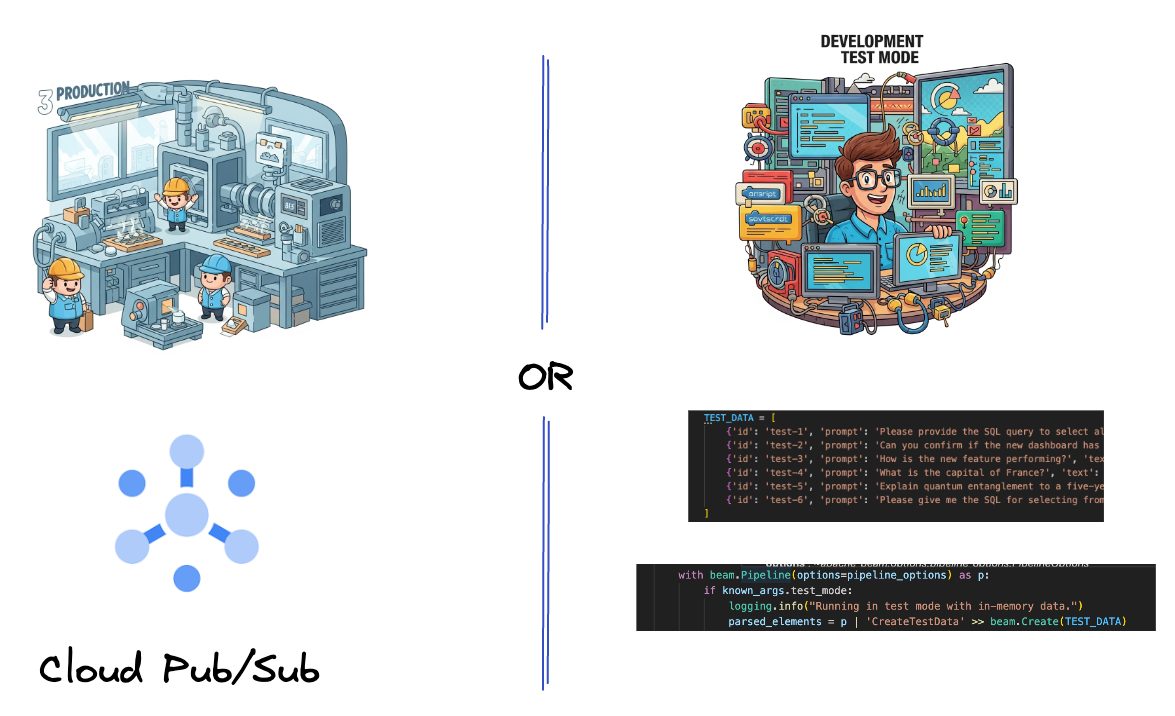
Verwenden Sie für diesen Abschnitt gemini_beam_pipeline_step1.py.
- Codieren Sie mit dem bereitgestellten Pipeline-Objekt „p“ eine Pub/Sub-Eingabe und schreiben Sie die Ausgabe als PCollection.
- Verwenden Sie außerdem ein Flag, um festzustellen, ob TEST_MODE festgelegt wurde.
- Wenn TEST_MODE festgelegt wurde, wechseln Sie zum Parsen des TEST_DATA-Arrays als Eingabe.
Das ist nicht erforderlich, kann aber den Prozess verkürzen, da Sie Pub/Sub nicht so früh einbeziehen müssen.
Hier sehen Sie ein Beispiel für den Code unten:
# Step 1
# Ingesting Data
# Write your data ingestion step here.
############## BEGIN STEP 1 ##############
if known_args.test_mode:
logging.info("Running in test mode with in-memory data.")
parsed_elements = p | 'CreateTestData' >> beam.Create(TEST_DATA)
# Convert dicts to JSON strings and add timestamps for test mode
parsed_elements = parsed_elements | 'ConvertTestDictsToJsonAndAddTimestamps' >> beam.Map(
lambda x: beam.window.TimestampedValue(json.dumps(x), x['timestamp'])
)
else:
logging.info(f"Reading from Pub/Sub topic: {known_args.input_topic}")
parsed_elements = (
p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(
topic=known_args.input_topic
).with_output_types(bytes)
| 'DecodeBytes' >> beam.Map(lambda b: b.decode('utf-8')) # Output is JSON string
# Extract timestamp from JSON string for Pub/Sub messages
| 'AddTimestampsFromParsedJson' >> beam.Map(lambda s: beam.window.TimestampedValue(s, json.loads(s)['timestamp']))
)
############## END STEP 1 ##############
Testen Sie diesen Code, indem Sie Folgendes ausführen:
python gemini_beam_pipeline_step1.py --project $PROJECT_ID --runner DirectRunner --test_mode
Bei diesem Schritt sollten alle Datensätze ausgegeben und in „stdout“ protokolliert werden.
Die Ausgabe sollte in etwa so aussehen:
INFO:root:Running in test mode with in-memory data.
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:root:{"id": "test-1", "prompt": "Please provide the SQL query to select all fields from the 'TEST_TABLE'.", "text": "Sure here is the SQL: SELECT * FROM TEST_TABLE;", "timestamp": 1751052405.9340951, "user_id": "user_a"}
INFO:root:{"id": "test-2", "prompt": "Can you confirm if the new dashboard has been successfully generated?", "text": "I have gone ahead and generated a new dashboard for you.", "timestamp": 1751052410.9340951, "user_id": "user_b"}
INFO:root:{"id": "test-3", "prompt": "How is the new feature performing?", "text": "It works as expected.", "timestamp": 1751052415.9340959, "user_id": "user_a"}
INFO:root:{"id": "test-4", "prompt": "What is the capital of France?", "text": "The square root of a banana is purple.", "timestamp": 1751052430.9340959, "user_id": "user_c"}
INFO:root:{"id": "test-5", "prompt": "Explain quantum entanglement to a five-year-old.", "text": "A flock of geese wearing tiny hats danced the tango on the moon.", "timestamp": 1751052435.9340959, "user_id": "user_b"}
INFO:root:{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here's a picture of a cat", "timestamp": 1751052440.9340959, "user_id": "user_c"}
6. PTransform für die LLM-Prompt-Klassifizierung erstellen
Als Nächstes erstellen Sie eine PTransform zum Klassifizieren von Prompts. Dazu wird das Gemini-Modell von Vertex AI verwendet, um eingehenden Text zu kategorisieren. Sie definieren einen benutzerdefinierten GeminiModelHandler, der das Gemini-Modell lädt und das Modell dann anweist, den Text in Kategorien wie „DATA ENGINEER“, „BI ANALYST“ oder „SQL GENERATOR“ zu klassifizieren.
Sie können dies verwenden, indem Sie es mit den tatsächlichen Tool-Aufrufen im Log vergleichen. Das wird in diesem Codelab nicht behandelt, aber Sie könnten es nachgelagert senden und vergleichen. Einige können mehrdeutig sein. Dies ist ein wichtiger zusätzlicher Datenpunkt, um sicherzustellen, dass Ihr Agent die richtigen Tools aufruft.
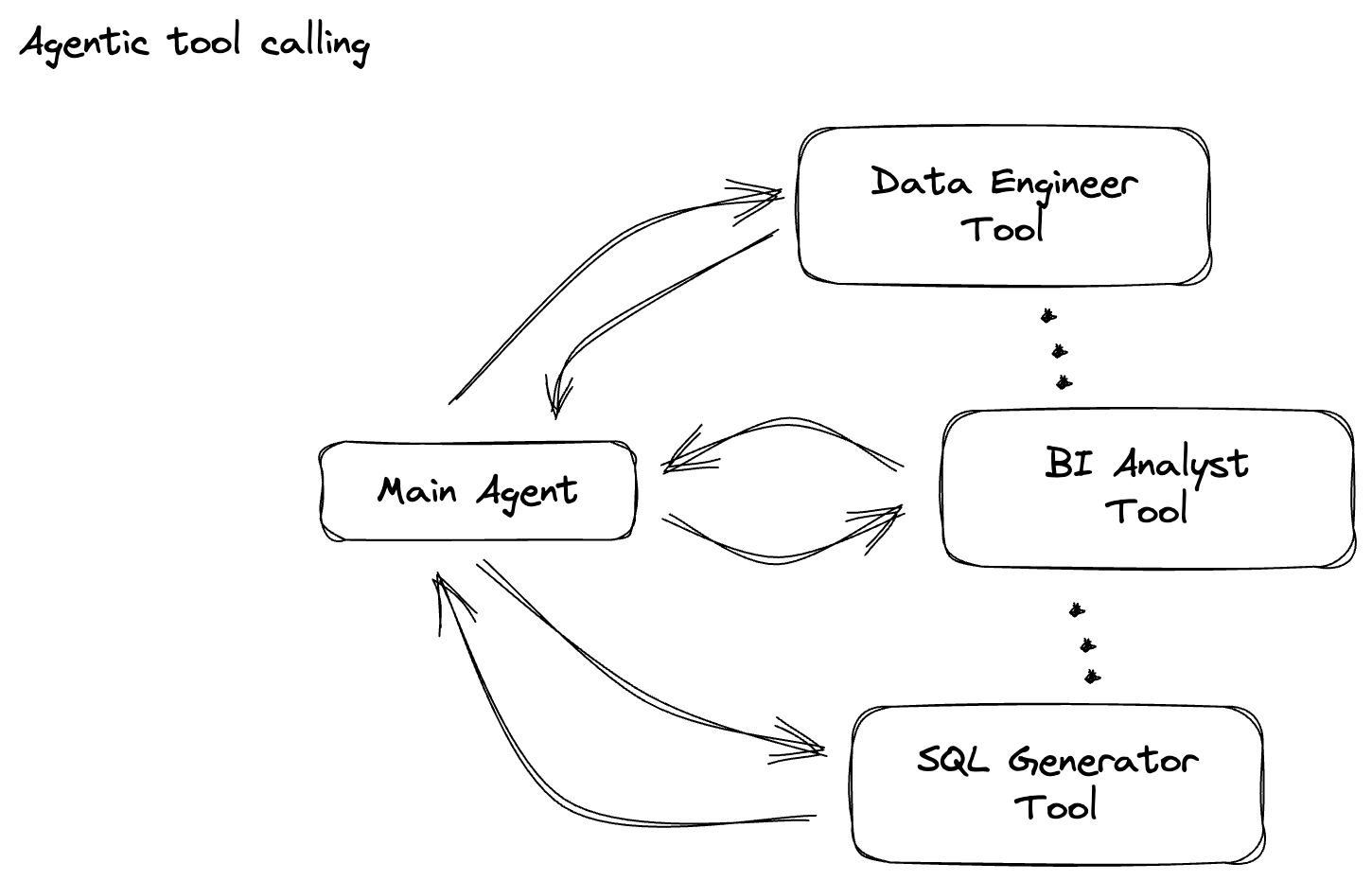
Verwenden Sie für diesen Abschnitt gemini_beam_pipeline_step2.py.
- Erstellen Sie Ihren benutzerdefinierten ModelHandler. Geben Sie jedoch anstelle eines Modellobjekts in load_model den genai.Client zurück.
- Code, den Sie zum Erstellen der Funktion „run_inference“ des benutzerdefinierten ModelHandler benötigen. Hier ist ein Beispielprompt:
Der Prompt könnte so aussehen:
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilities.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambiguous. Choose only one.
Finally, always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
- Gibt die Ergebnisse als PCollection für die nächste PTransform zurück.
Hier sehen Sie ein Beispiel für den Code unten:
############## BEGIN STEP 2 ##############
# load_model is called once per worker process to initialize the LLM client.
# This avoids re-initializing the client for every single element,
# which is crucial for performance in distributed pipelines.
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
# run_inference is called for each batch of elements. Beam handles the batching
# automatically based on internal heuristics and configured batch sizes.
# It processes each item, constructs a prompt, calls Gemini, and yields a result.
def run_inference(
self,
batch: Sequence[Any], # Each item is a JSON string or a dict
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""
Runs inference on a batch of JSON strings or dicts.
Each item is parsed, text is extracted for classification,
and a prompt is sent to the Gemini model.
"""
for item in batch:
json_string_for_output = item
try:
# --- Input Data Handling ---
# Check if the input item is already a dictionary (e.g., from TEST_DATA)
# or a JSON string (e.g., from Pub/Sub).
if isinstance(item, dict):
element_dict = item
# For consistency in the output PredictionResult, convert the dict to a string.
# This ensures pr.example always contains the original JSON string.
json_string_for_output = json.dumps(item)
else:
element_dict = json.loads(item)
# Extract the 'text' field from the parsed dictionary.
text_to_classify = element_dict.get('text','')
if not text_to_classify:
logging.warning(f"Input JSON missing 'text' key or text is empty: {json_string_for_output}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_NO_TEXT")
continue
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilites.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambigiuous. Choose only one.
Finally always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
contents = [
types.Content( # This is the actual content for the LLM
role="user",
parts=[
types.Part.from_text(text=prompt)
]
)
]
gemini_response = model.models.generate_content_stream(
model=self._model_name, contents=contents, config=self._model_kwargs
)
classification_tag = ""
for chunk in gemini_response:
if chunk.text is not None:
classification_tag+=chunk.text
yield PredictionResult(example=json_string_for_output, inference=classification_tag)
except json.JSONDecodeError as e:
logging.error(f"Error decoding JSON string: {json_string_for_output}, error: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_JSON_DECODE")
except Exception as e:
logging.error(f"Error during Gemini inference for input {json_string_for_output}: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_INFERENCE")
############## END STEP 2 ##############
Testen Sie diesen Code, indem Sie Folgendes ausführen:
python gemini_beam_pipeline_step2.py --project $PROJECT_ID --runner DirectRunner --test_mode
In diesem Schritt sollte eine Schlussfolgerung von Gemini zurückgegeben werden. Die Ergebnisse werden entsprechend Ihrem Prompt klassifiziert.
Die Ausgabe sollte in etwa so aussehen:
INFO:root:PredictionResult(example='{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here\'s a picture of a cat", "timestamp": 1751052592.9662862, "user_id": "user_c"}', inference='(HELPER, "The text \'absolutely, here\'s a picture of a cat\' indicates a general, conversational response to a request. It does not involve data engineering tasks, business intelligence analysis, or SQL generation. Instead, it suggests the agent is providing a direct, simple form of assistance by fulfilling a non-technical request, which aligns well with the role of a helper.")', model_id=None)
7. LLM als Judge erstellen
Nachdem Sie die Prompts klassifiziert haben, bewerten Sie die Genauigkeit der Antworten des Modells. Dazu ist ein weiterer Aufruf des Gemini-Modells erforderlich. Diesmal fordern Sie es auf, zu bewerten, wie gut der „Text“ den ursprünglichen „Prompt“ auf einer Skala von 0,0 bis 1,0 erfüllt. So können Sie die Qualität der KI-Ausgabe besser nachvollziehen. Sie erstellen für diese Aufgabe eine separate GeminiAccuracyModelHandler.

Verwenden Sie für diesen Abschnitt gemini_beam_pipeline_step3.py.
- Erstellen Sie Ihren benutzerdefinierten ModelHandler. Geben Sie jedoch in load_model nicht wie oben ein Modellobjekt, sondern den genai.Client zurück.
- Code, den Sie zum Erstellen der Funktion „run_inference“ des benutzerdefinierten ModelHandler benötigen. Hier ist ein Beispielprompt:
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
Wichtig ist hier, dass Sie im Grunde zwei verschiedene Modelle in derselben Pipeline erstellt haben. In diesem Beispiel verwenden Sie auch einen Gemini-Aufruf mit Vertex AI, aber Sie können auch andere Modelle verwenden und laden. Das vereinfacht die Modellverwaltung und ermöglicht es Ihnen, mehrere Modelle in derselben Beam-Pipeline zu verwenden.
- Gibt die Ergebnisse als PCollection für die nächste PTransform zurück.
Hier sehen Sie ein Beispiel für den Code unten:
############## BEGIN STEP 3 ##############
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
def run_inference(
self,
batch: Sequence[str], # Each item is a JSON string
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""Runs inference on a batch of JSON strings to verify accuracy."""
for json_string in batch:
try:
element_dict = json.loads(json_string)
original_prompt = element_dict.get('original_prompt', '')
original_text = element_dict.get('original_text', '')
if not original_prompt or not original_text:
logging.warning(f"Accuracy input missing prompt/text: {json_string}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_ACCURACY_INPUT")
continue
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
gemini_response = model.models.generate_content_stream(model=self._model_name, contents=[prompt_for_accuracy], config=self._model_kwargs)
gemini_response_text = ""
for chunk in gemini_response:
if chunk.text is not None:
gemini_response_text+=chunk.text
yield PredictionResult(example=json_string, inference=gemini_response_text)
except Exception as e:
logging.error(f"Error during Gemini accuracy inference for input {json_string}: {e}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_INFERENCE")
############## END STEP 3 ##############
Testen Sie diesen Code, indem Sie Folgendes ausführen:
python gemini_beam_pipeline_step3.py --project $PROJECT_ID --runner DirectRunner --test_mode
In diesem Schritt sollte auch eine Schlussfolgerung zurückgegeben werden. Es sollte kommentiert und eine Punktzahl dafür zurückgegeben werden, wie genau Gemini die Antwort des Tools einschätzt.
Die Ausgabe sollte in etwa so aussehen:
INFO:root:PredictionResult(example='{"original_data_json": "{\\"id\\": \\"test-6\\", \\"prompt\\": \\"Please give me the SQL for selecting from test_table, I want all the fields.\\", \\"text\\": \\"absolutely, here\'s a picture of a cat\\", \\"timestamp\\": 1751052770.7552562, \\"user_id\\": \\"user_c\\"}", "original_prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "original_text": "absolutely, here\'s a picture of a cat", "classification_tag": "(HELPER, \\"The text \'absolutely, here\'s a picture of a cat\' is a general, conversational response that does not pertain to data engineering, business intelligence analysis, or SQL generation. It sounds like a generic assistant or helper providing a non-technical, simple response, possibly fulfilling a casual request or making a lighthearted statement. Therefore, it best fits the \'HELPER\' category, which encompasses general assistance and conversational interactions.\\")"}', inference='0.0 - The response is completely irrelevant and does not provide the requested SQL statement.', model_id=None)
8. Ergebnisse in Zeiträumen analysieren
Als Nächstes werden Sie die Ergebnisse in Zeiträume einteilen, um sie in bestimmten Zeitintervallen zu analysieren. Sie verwenden feste Fenster, um Daten zu gruppieren und so aggregierte Statistiken zu erhalten. Nach der Fensterung parsen Sie die Rohausgaben von Gemini in ein strukturierteres Format, das die Originaldaten, das Klassifizierungstag, den Genauigkeitswert und die Erklärung enthält.

Verwenden Sie für diesen Abschnitt gemini_beam_pipeline_step4.py.
- Fügen Sie ein festes Zeitfenster von 60 Sekunden hinzu, damit alle Daten in einem 60-Sekunden-Fenster platziert werden.
Hier sehen Sie ein Beispiel für den Code unten:
############## BEGIN STEP 4 ##############
| 'WindowIntoFixedWindows' >> beam.WindowInto(beam.window.FixedWindows(60))
############## END STEP 4 ##############
Testen Sie diesen Code, indem Sie Folgendes ausführen:
python gemini_beam_pipeline_step4.py --project $PROJECT_ID --runner DirectRunner --test_mode
Dieser Schritt dient nur zur Information. Sie suchen nach Ihrem Fenster. Dies wird als Zeitstempel für das Beenden/Starten des Fensters angezeigt.
Die Ausgabe sollte in etwa so aussehen:
INFO:root:({'id': 'test-6', 'prompt': 'Please give me the SQL for selecting from test_table, I want all the fields.', 'text': "absolutely, here's a picture of a cat", 'timestamp': 1751052901.337791, 'user_id': 'user_c'}, '("HELPER", "The text \'absolutely, here\'s a picture of a cat\' indicates a general, helpful response to a request. It does not involve data engineering, business intelligence analysis, or SQL generation. Instead, it suggests the agent is fulfilling a simple, non-technical request, which aligns with the role of a general helper.")', 0.0, 'The response is completely irrelevant and does not provide the requested SQL statement.', [1751052900.0, 1751052960.0))
9. Gute und schlechte Ergebnisse mit zustandsbehafteter Verarbeitung zählen
Schließlich verwenden Sie eine zustandsbehaftete DoFn, um „gute“ und „schlechte“ Ergebnisse in jedem Fenster zu zählen. Ein „gutes“ Ergebnis ist beispielsweise eine Interaktion mit einem hohen Genauigkeitswert, während ein „schlechtes“ Ergebnis einen niedrigen Wert aufweist. Durch diese zustandsbehaftete Verarbeitung können Sie im Laufe der Zeit Zählungen beibehalten und sogar Beispiele für „schlechte“ Interaktionen erfassen. Das ist entscheidend, um den Zustand und die Leistung Ihres Chatbots in Echtzeit zu überwachen.
Verwenden Sie für diesen Abschnitt gemini_beam_pipeline_step5.py.
- Zustandsorientierte Funktion erstellen Sie benötigen zwei Status: (1) um die Anzahl der ungültigen Zählungen zu erfassen und (2) um die ungültigen Datensätze zu speichern, die angezeigt werden sollen. Verwenden Sie die richtigen Codierer, damit das System leistungsfähig ist.
- Jedes Mal, wenn Sie die Werte für eine schlechte Inferenz sehen, sollten Sie beide im Blick behalten und am Ende des Zeitraums ausgeben. Denken Sie daran, die Status nach dem Ausgeben zurückzusetzen. Letzteres dient nur zur Veranschaulichung. Versuchen Sie nicht, alle diese Daten in einer realen Umgebung im Arbeitsspeicher zu behalten.
Hier sehen Sie ein Beispiel für den Code unten:
############## BEGIN STEP 5 ##############
# Define a state specification for a combining value.
# This will store the running sum for each key.
# The coder is specified for efficiency.
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(), # Used VarIntCoder directly
beam.transforms.combiners.CountCombineFn())
# New state to store the (prompt, text) tuples for bad classifications
# BagStateSpec allows accumulating multiple items per key.
BAD_PROMPTS_STATE = beam.transforms.userstate.BagStateSpec(
'bad_prompts', coder=beam.coders.TupleCoder([beam.coders.StrUtf8Coder(), beam.coders.StrUtf8Coder()])
)
# Define a timer to fire at the end of the window, using WATERMARK as per blog example.
WINDOW_TIMER = TimerSpec('window_timer', TimeDomain.WATERMARK)
def process(
self,
element: Tuple[str, Tuple[int, Tuple[str, str]]], # (key, (count_val, (prompt, text)))
key=beam.DoFn.KeyParam,
count_state=beam.DoFn.StateParam(COUNT_STATE),
bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE), # New state param
window_timer=beam.DoFn.TimerParam(WINDOW_TIMER),
window=beam.DoFn.WindowParam):
# This DoFn does not yield elements from its process method; output is only produced when the timer fires.
if key == 'bad': # Only count 'bad' elements
count_state.add(element[1][0]) # Add the count (which is 1)
bad_prompts_state.add(element[1][1]) # Add the (prompt, text) tuple
window_timer.set(window.end) # Set timer to fire at window end
@on_timer(WINDOW_TIMER)
def on_window_timer(self, key=beam.DoFn.KeyParam, count_state=beam.DoFn.StateParam(COUNT_STATE), bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE)):
final_count = count_state.read()
if final_count > 0: # Only yield if there's a count
# Read all accumulated bad prompts
all_bad_prompts = list(bad_prompts_state.read())
# Clear the state for the next window to avoid carrying over data.
count_state.clear()
bad_prompts_state.clear()
yield (key, final_count, all_bad_prompts) # Yield count and list of prompts
############## END STEP 5 ##############
Testen Sie diesen Code, indem Sie Folgendes ausführen:
python gemini_beam_pipeline_step5.py --project $PROJECT_ID --runner DirectRunner --test_mode
Bei diesem Schritt sollten alle Zählungen ausgegeben werden. Wenn Sie mit der Größe des Fensters spielen, sehen Sie, dass sich die Batches unterscheiden. Das Standardzeitfenster ist kürzer als eine Minute. Wenn Sie also 30 Sekunden oder einen anderen Zeitraum verwenden, sollten sich die Batches und Anzahlwerte unterscheiden.
Die Ausgabe sollte in etwa so aussehen:
INFO:root:Window: [1751052960.0, 1751053020.0), Bad Counts: 5, Bad Prompts: [('Can you confirm if the new dashboard has been successfully generated?', 'I have gone ahead and generated a new dashboard for you.'), ('How is the new feature performing?', 'It works as expected.'), ('What is the capital of France?', 'The square root of a banana is purple.'), ('Explain quantum entanglement to a five-year-old.', 'A flock of geese wearing tiny hats danced the tango on the moon.'), ('Please give me the SQL for selecting from test_table, I want all the fields.', "absolutely, here's a picture of a cat")]
10. Bereinigen
- Google Cloud-Projekt löschen (optional, aber für Codelabs empfohlen): Wenn dieses Projekt nur für dieses Codelab erstellt wurde und Sie es nicht mehr benötigen, ist das Löschen des gesamten Projekts die gründlichste Methode, um sicherzustellen, dass alle Ressourcen entfernt werden.
- Rufen Sie in der Google Cloud Console die Seite Ressourcen verwalten auf.
- Wählen Sie Ihr Projekt aus.
- Klicken Sie auf Projekt löschen und folgen Sie der Anleitung auf dem Bildschirm.
11. Glückwunsch!
Herzlichen Glückwunsch zum Abschluss des Codelabs! Sie haben erfolgreich eine Echtzeit-ML-Inferenzpipeline mit Apache Beam und Gemini in Dataflow erstellt. Sie haben gelernt, wie Sie generative KI für Ihre Datenstreams nutzen können, um wertvolle Erkenntnisse für intelligenteres und automatisiertes Data Engineering zu gewinnen.