
1. Introducción
En el vertiginoso panorama de datos actual, las estadísticas en tiempo real son fundamentales para tomar decisiones fundamentadas. En este codelab, se te guiará para que compiles una canalización de evaluación en tiempo real. Comenzaremos aprovechando el framework de Apache Beam, que ofrece un modelo de programación unificado para los datos de transmisión y por lotes. Esto simplifica significativamente el desarrollo de canalizaciones, ya que abstrae la compleja lógica de procesamiento distribuido que, de lo contrario, tendrías que compilar desde cero. Una vez que definas tu canalización con Beam, la ejecutarás sin problemas en Google Cloud Dataflow, un servicio completamente administrado que proporciona una escala y un rendimiento incomparables para tus necesidades de procesamiento de datos.
En este codelab, aprenderás a diseñar una canalización de Apache Beam escalable para la inferencia del aprendizaje automático, desarrollar un ModelHandler personalizado para integrar el modelo Gemini de Vertex AI, aprovechar la ingeniería de instrucciones para la clasificación de texto inteligente en flujos de datos y, luego, implementar y operar esta canalización de inferencia de AA de transmisión en Google Cloud Dataflow. Al final, obtendrás estadísticas valiosas para aplicar el aprendizaje automático a la comprensión de datos en tiempo real y la evaluación continua en los flujos de trabajo de ingeniería, en especial para mantener una IA conversacional sólida y centrada en el usuario.
Situación
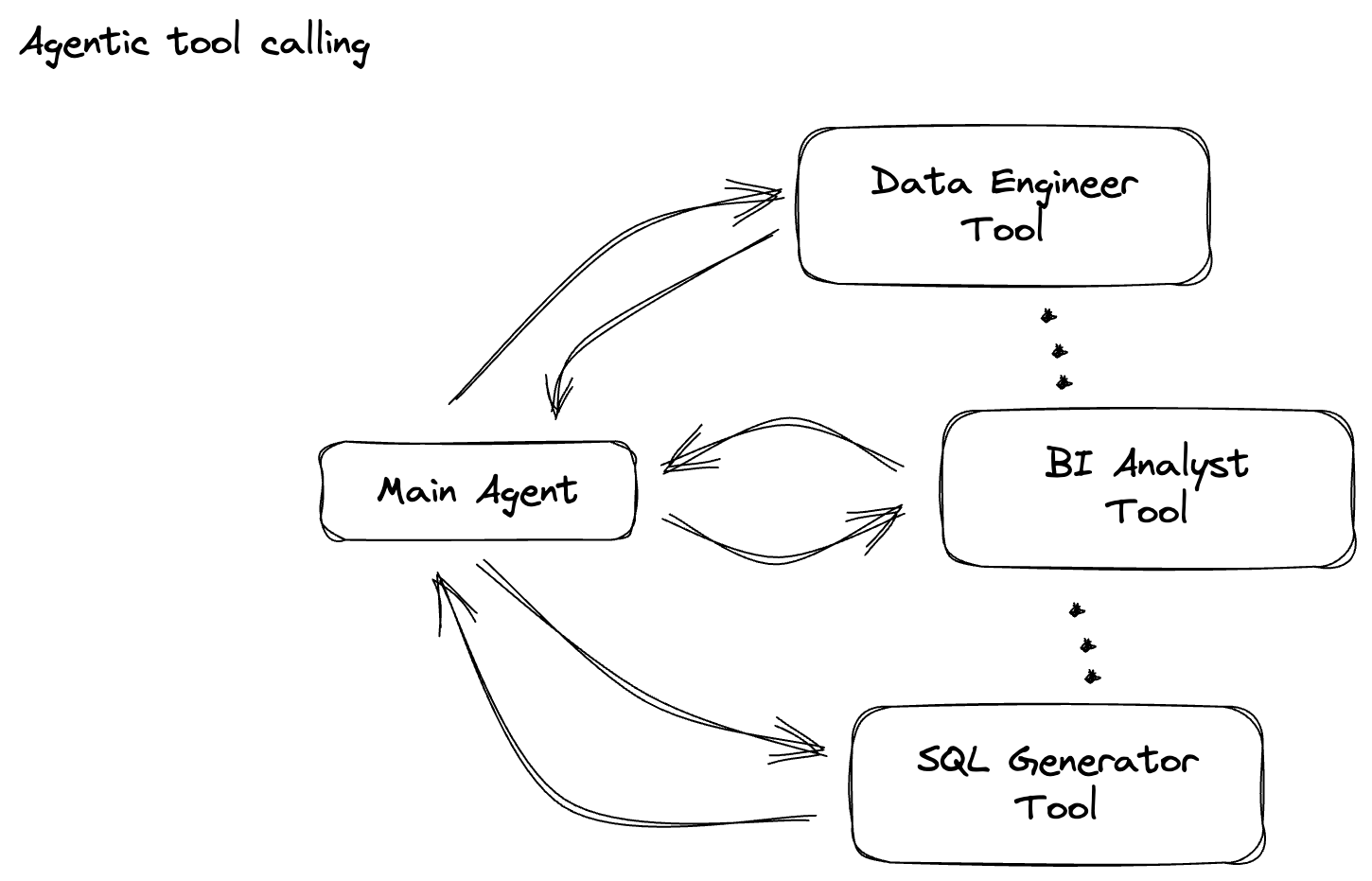
Tu empresa creó un agente de datos. Tu agente de datos, creado con el Kit de desarrollo de agentes (ADK), está equipado con varias capacidades especializadas para ayudarte con las tareas relacionadas con los datos. Imagínalo como un asistente de datos versátil, listo para manejar diversas solicitudes, desde actuar como analista de BI para generar informes detallados hasta un ingeniero de datos que te ayude a crear canalizaciones de datos sólidas, o un generador de SQL que cree instrucciones de SQL precisas y mucho más. Cada interacción que tiene este agente y cada respuesta que genera se almacenan automáticamente en Firestore. Pero ¿por qué necesitamos una canalización aquí?
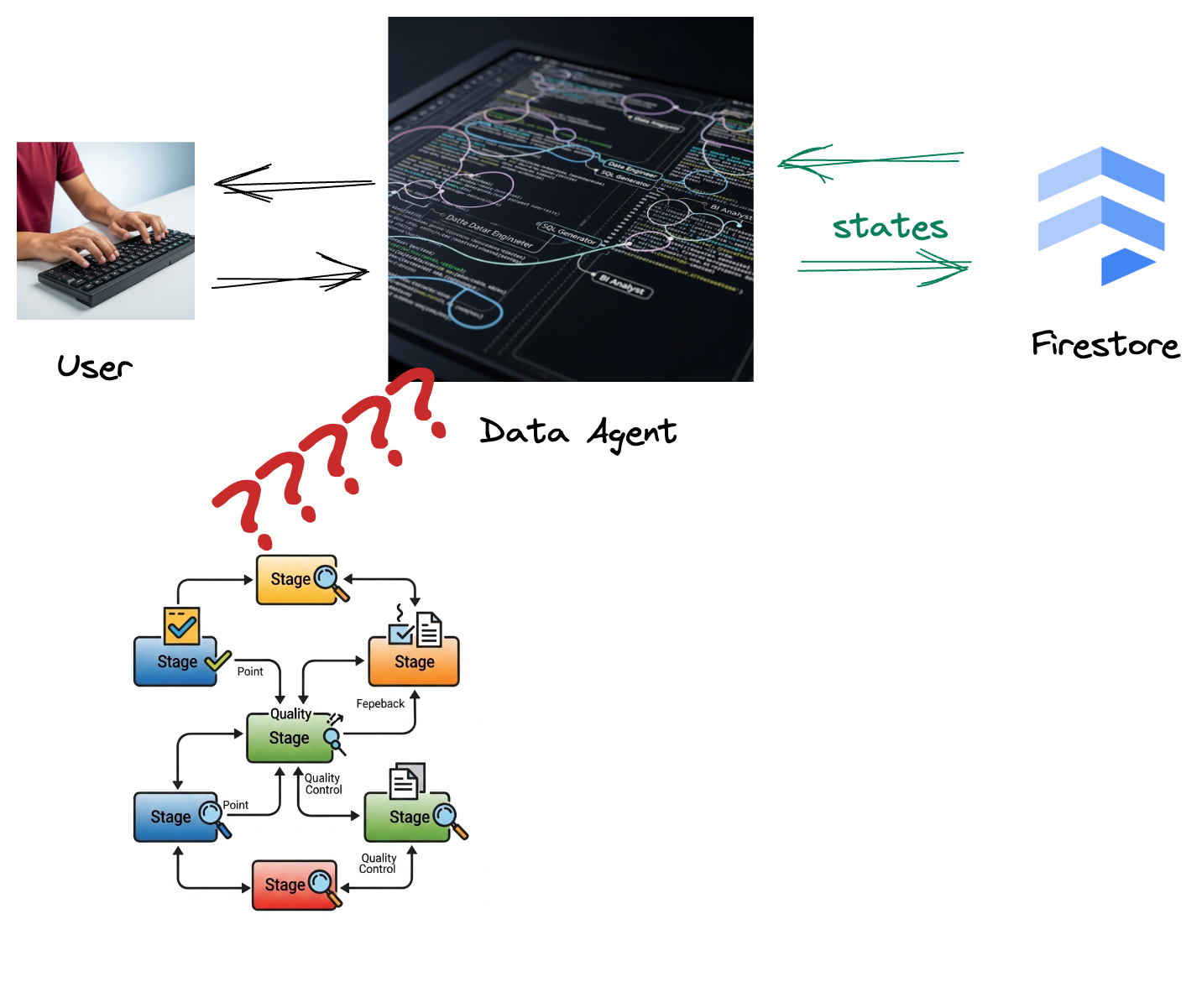
Esto se debe a que, desde Firestore, un activador envía sin problemas estos datos de interacción a Pub/Sub, lo que garantiza que podamos procesar y analizar de inmediato estas conversaciones críticas en tiempo real.
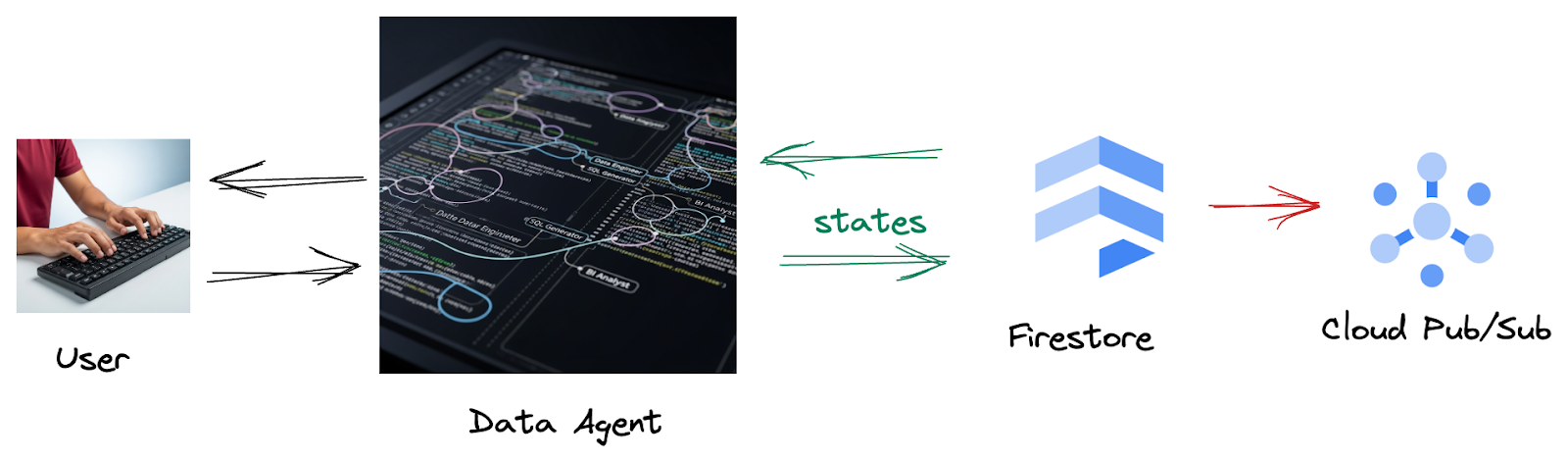
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información sobre cómo verificar si la facturación está habilitada en un proyecto.
- Haz clic en este vínculo para activar Cloud Shell. Puedes alternar entre la terminal de Cloud Shell (para ejecutar comandos de Cloud) y el editor (para compilar proyectos) haciendo clic en el botón correspondiente de Cloud Shell.
- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con el ID de tu proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
- Habilita las APIs requeridas con el siguiente comando. Este proceso puede tardar unos minutos, así que ten paciencia.
gcloud services enable \
dataflow.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Asegúrate de tener Python 3.10 o versiones posteriores.
- Instala paquetes de Python
Instala las bibliotecas de Python requeridas para Apache Beam, Google Cloud Vertex AI y la IA generativa de Google en tu entorno de Cloud Shell.
pip install apache-beam[gcp] google-genai
- Clona el repo de GitHub y cambia al directorio de demostración.
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/beam_as_eval
Consulta la documentación para ver los comandos y el uso de gcloud.
3. Cómo usar el repositorio de GitHub proporcionado
El repositorio de GitHub asociado con este codelab, que se encuentra en https://github.com/GoogleCloudPlatform/devrel-demos/tree/main/data-analytics/beam_as_eval , está organizado para facilitar una experiencia de aprendizaje guiada. Contiene código esqueleto que se alinea con cada parte distinta del codelab, lo que garantiza una progresión clara a través del material.
Dentro del repositorio, encontrarás dos carpetas principales: "complete" y "incomplete". La carpeta "complete" contiene código completamente funcional para cada paso, lo que te permite ejecutar y observar el resultado previsto. Por el contrario, la carpeta "incomplete" proporciona código de los pasos anteriores, y deja secciones específicas marcadas entre ##### START STEP <NUMBER> ##### y ##### END STEP <NUMBER> ##### para que las completes como parte de los ejercicios. Esta estructura te permite aprovechar el conocimiento previo mientras participas activamente en los desafíos de programación.
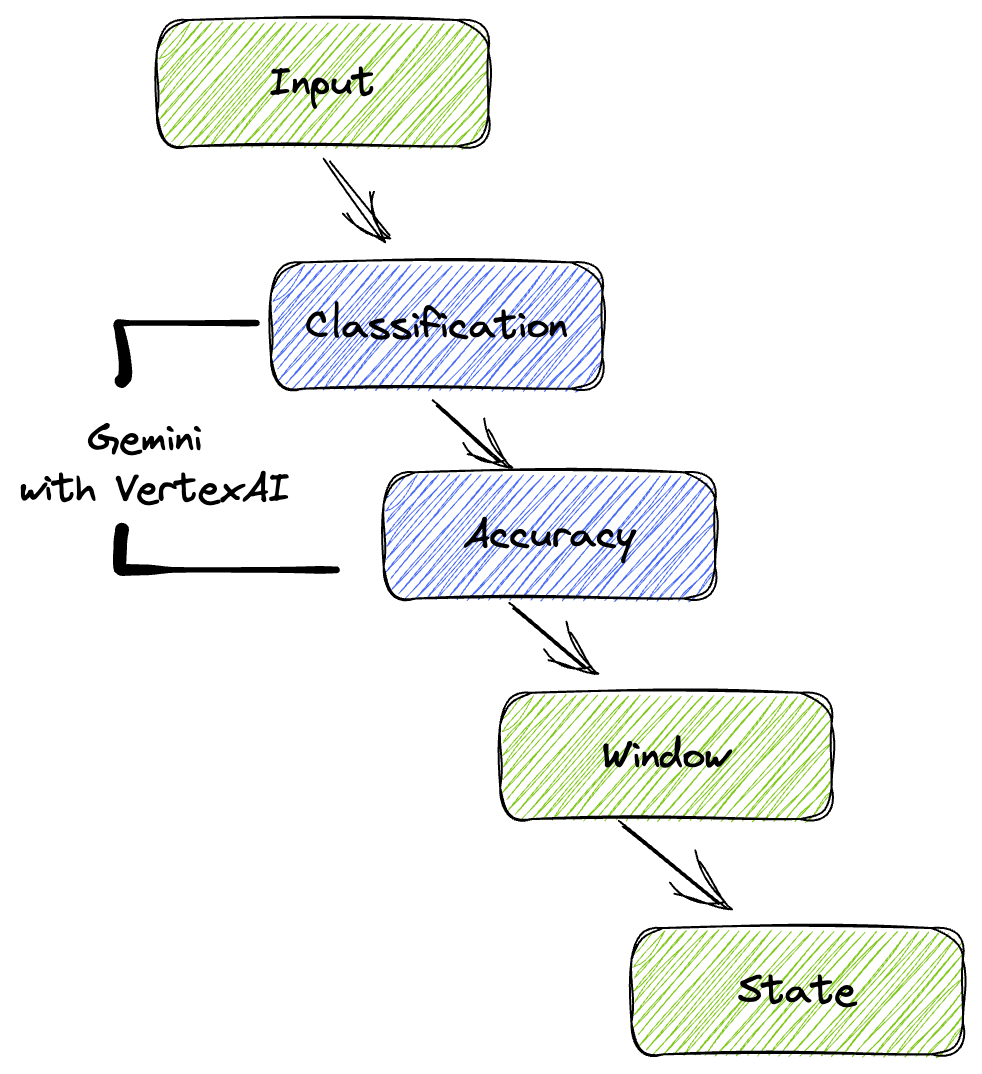
4. Descripción general de la arquitectura
Nuestra canalización proporciona un patrón potente y escalable para integrar la inferencia de AA en los flujos de datos. Así es como encajan las piezas:
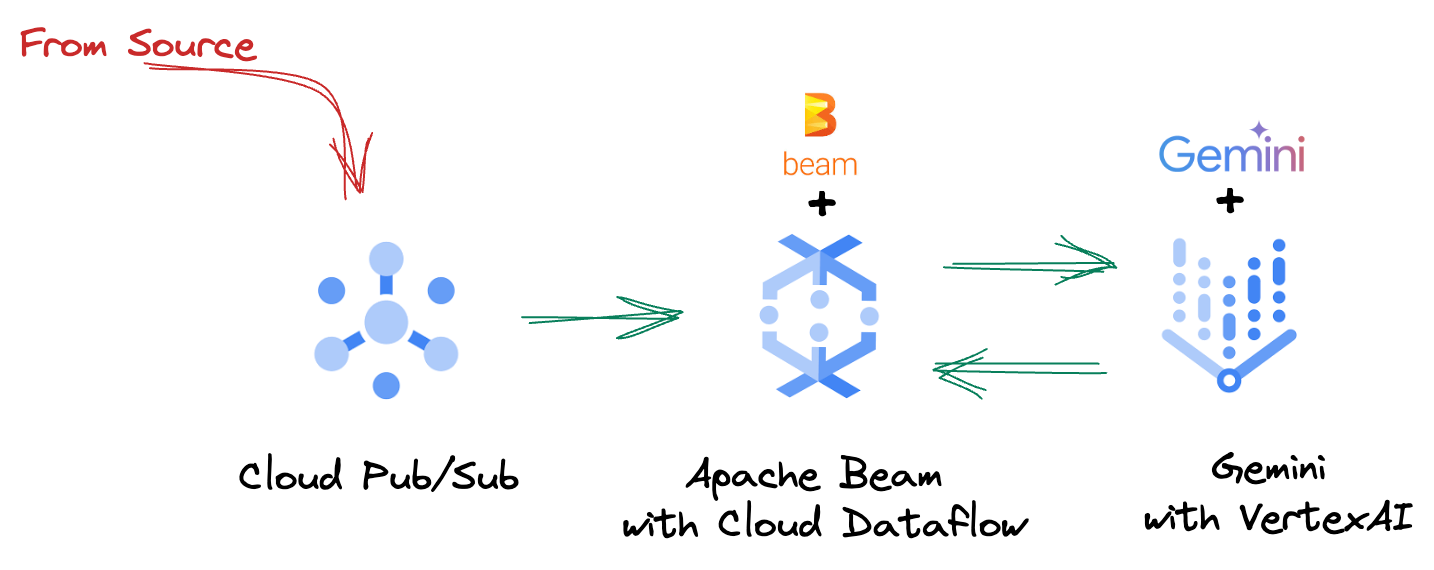
En tu canalización de Beam, codificarás varias entradas de forma condicional y, luego, cargarás modelos personalizados con la transformación llave en mano RunInference. Aunque en el ejemplo se usa Gemini con Vertex AI, se muestra cómo crearías esencialmente varios ModelHandlers para que se ajusten a la cantidad de modelos que tienes. Por último, usarás un DoFn con estado para hacer un seguimiento de los eventos y emitirlos de manera controlada.
5. Transferencia de datos
Primero, configurarás tu canalización para que ingiera datos. Usarás Pub/Sub para la transmisión en tiempo real, pero, para facilitar el desarrollo, también crearás un modo de prueba. Este test_mode te permite ejecutar la canalización de forma local con datos de muestra predefinidos, por lo que no necesitas una transmisión en vivo de Pub/Sub para ver si tu canalización funciona.
Para esta sección, usa gemini_beam_pipeline_step1.py.
- Con el objeto de canalización p proporcionado, codifica una entrada de Pub/Sub y escribe la salida como una PCollection.
- Además, usa una marca para determinar si se configuró TEST_MODE.
- Si se configuró TEST_MODE, cambia a analizar el array TEST_DATA como entrada.
Esto no es necesario, pero ayuda a acortar el proceso para que no tengas que involucrar a Pub/Sub tan pronto.
Este es un ejemplo del código:
# Step 1
# Ingesting Data
# Write your data ingestion step here.
############## BEGIN STEP 1 ##############
if known_args.test_mode:
logging.info("Running in test mode with in-memory data.")
parsed_elements = p | 'CreateTestData' >> beam.Create(TEST_DATA)
# Convert dicts to JSON strings and add timestamps for test mode
parsed_elements = parsed_elements | 'ConvertTestDictsToJsonAndAddTimestamps' >> beam.Map(
lambda x: beam.window.TimestampedValue(json.dumps(x), x['timestamp'])
)
else:
logging.info(f"Reading from Pub/Sub topic: {known_args.input_topic}")
parsed_elements = (
p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(
topic=known_args.input_topic
).with_output_types(bytes)
| 'DecodeBytes' >> beam.Map(lambda b: b.decode('utf-8')) # Output is JSON string
# Extract timestamp from JSON string for Pub/Sub messages
| 'AddTimestampsFromParsedJson' >> beam.Map(lambda s: beam.window.TimestampedValue(s, json.loads(s)['timestamp']))
)
############## END STEP 1 ##############
Para probar este código, ejecuta lo siguiente:
python gemini_beam_pipeline_step1.py --project $PROJECT_ID --runner DirectRunner --test_mode
En este paso, se deben emitir todos los registros y se deben registrar en stdout.
Deberías obtener un resultado como el siguiente.
INFO:root:Running in test mode with in-memory data.
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:root:{"id": "test-1", "prompt": "Please provide the SQL query to select all fields from the 'TEST_TABLE'.", "text": "Sure here is the SQL: SELECT * FROM TEST_TABLE;", "timestamp": 1751052405.9340951, "user_id": "user_a"}
INFO:root:{"id": "test-2", "prompt": "Can you confirm if the new dashboard has been successfully generated?", "text": "I have gone ahead and generated a new dashboard for you.", "timestamp": 1751052410.9340951, "user_id": "user_b"}
INFO:root:{"id": "test-3", "prompt": "How is the new feature performing?", "text": "It works as expected.", "timestamp": 1751052415.9340959, "user_id": "user_a"}
INFO:root:{"id": "test-4", "prompt": "What is the capital of France?", "text": "The square root of a banana is purple.", "timestamp": 1751052430.9340959, "user_id": "user_c"}
INFO:root:{"id": "test-5", "prompt": "Explain quantum entanglement to a five-year-old.", "text": "A flock of geese wearing tiny hats danced the tango on the moon.", "timestamp": 1751052435.9340959, "user_id": "user_b"}
INFO:root:{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here's a picture of a cat", "timestamp": 1751052440.9340959, "user_id": "user_c"}
6. Cómo compilar una PTransform para la clasificación de instrucciones de LLM
A continuación, compilarás un PTransform para clasificar instrucciones. Esto implica usar el modelo de Gemini de Vertex AI para categorizar el texto entrante. Definirás un GeminiModelHandler personalizado que cargue el modelo de Gemini y, luego, le indique cómo clasificar el texto en categorías como "INGENIERO DE DATOS", "ANALISTA DE BI" o "GENERADOR DE SQL".
Para usarlo, debes compararlo con las llamadas a herramientas reales en el registro. Esto no se aborda en este codelab, pero podrías enviarlo a un nivel inferior y compararlo. Es posible que algunas sean ambiguas, y esto sirve como un excelente punto de datos adicional para garantizar que tu agente llame a las herramientas adecuadas.
Para esta sección, usa gemini_beam_pipeline_step2.py.
- Compila tu ModelHandler personalizado. Sin embargo, en lugar de devolver un objeto del modelo en load_model, devuelve el genai.Client.
- Código que necesitarás para crear la función run_inference del ModelHandler personalizado. Se proporcionó una instrucción de ejemplo:
La instrucción puede ser algo como lo siguiente:
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilities.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambiguous. Choose only one.
Finally, always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
- Genera los resultados como una PCollection para la siguiente PTransform.
Este es un ejemplo del código:
############## BEGIN STEP 2 ##############
# load_model is called once per worker process to initialize the LLM client.
# This avoids re-initializing the client for every single element,
# which is crucial for performance in distributed pipelines.
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
# run_inference is called for each batch of elements. Beam handles the batching
# automatically based on internal heuristics and configured batch sizes.
# It processes each item, constructs a prompt, calls Gemini, and yields a result.
def run_inference(
self,
batch: Sequence[Any], # Each item is a JSON string or a dict
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""
Runs inference on a batch of JSON strings or dicts.
Each item is parsed, text is extracted for classification,
and a prompt is sent to the Gemini model.
"""
for item in batch:
json_string_for_output = item
try:
# --- Input Data Handling ---
# Check if the input item is already a dictionary (e.g., from TEST_DATA)
# or a JSON string (e.g., from Pub/Sub).
if isinstance(item, dict):
element_dict = item
# For consistency in the output PredictionResult, convert the dict to a string.
# This ensures pr.example always contains the original JSON string.
json_string_for_output = json.dumps(item)
else:
element_dict = json.loads(item)
# Extract the 'text' field from the parsed dictionary.
text_to_classify = element_dict.get('text','')
if not text_to_classify:
logging.warning(f"Input JSON missing 'text' key or text is empty: {json_string_for_output}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_NO_TEXT")
continue
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilites.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambigiuous. Choose only one.
Finally always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
contents = [
types.Content( # This is the actual content for the LLM
role="user",
parts=[
types.Part.from_text(text=prompt)
]
)
]
gemini_response = model.models.generate_content_stream(
model=self._model_name, contents=contents, config=self._model_kwargs
)
classification_tag = ""
for chunk in gemini_response:
if chunk.text is not None:
classification_tag+=chunk.text
yield PredictionResult(example=json_string_for_output, inference=classification_tag)
except json.JSONDecodeError as e:
logging.error(f"Error decoding JSON string: {json_string_for_output}, error: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_JSON_DECODE")
except Exception as e:
logging.error(f"Error during Gemini inference for input {json_string_for_output}: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_INFERENCE")
############## END STEP 2 ##############
Para probar este código, ejecuta lo siguiente:
python gemini_beam_pipeline_step2.py --project $PROJECT_ID --runner DirectRunner --test_mode
Este paso debería devolver una inferencia de Gemini. Clasificará los resultados según lo solicitado en la instrucción.
Deberías obtener un resultado como el siguiente.
INFO:root:PredictionResult(example='{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here\'s a picture of a cat", "timestamp": 1751052592.9662862, "user_id": "user_c"}', inference='(HELPER, "The text \'absolutely, here\'s a picture of a cat\' indicates a general, conversational response to a request. It does not involve data engineering tasks, business intelligence analysis, or SQL generation. Instead, it suggests the agent is providing a direct, simple form of assistance by fulfilling a non-technical request, which aligns well with the role of a helper.")', model_id=None)
7. Cómo compilar un LLM como juez
Después de clasificar las instrucciones, evaluarás la precisión de las respuestas del modelo. Esto implica otra llamada al modelo de Gemini, pero, esta vez, le pedirás que califique qué tan bien el "texto" cumple con la "instrucción" original en una escala del 0.0 al 1.0. Esto te ayuda a comprender la calidad del resultado de la IA. Crearás un GeminiAccuracyModelHandler independiente para esta tarea.

Para esta sección, usa gemini_beam_pipeline_step3.py.
- Compila tu ModelHandler personalizado. Sin embargo, en lugar de devolver un objeto del modelo en load_model, devuelve el genai.Client tal como lo hiciste antes.
- Código que necesitarás para crear la función run_inference del ModelHandler personalizado. Se proporcionó una instrucción de ejemplo:
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
Un aspecto que se debe tener en cuenta aquí es que, básicamente, creaste dos modelos diferentes en la misma canalización. En este ejemplo en particular, también usas una llamada a Gemini con Vertex AI, pero, con el mismo concepto, puedes elegir usar y cargar otros modelos. Esto simplifica la administración de modelos y te permite usar varios modelos en la misma canalización de Beam.
- Genera los resultados como una PCollection para la siguiente PTransform.
Este es un ejemplo del código:
############## BEGIN STEP 3 ##############
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
def run_inference(
self,
batch: Sequence[str], # Each item is a JSON string
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""Runs inference on a batch of JSON strings to verify accuracy."""
for json_string in batch:
try:
element_dict = json.loads(json_string)
original_prompt = element_dict.get('original_prompt', '')
original_text = element_dict.get('original_text', '')
if not original_prompt or not original_text:
logging.warning(f"Accuracy input missing prompt/text: {json_string}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_ACCURACY_INPUT")
continue
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
gemini_response = model.models.generate_content_stream(model=self._model_name, contents=[prompt_for_accuracy], config=self._model_kwargs)
gemini_response_text = ""
for chunk in gemini_response:
if chunk.text is not None:
gemini_response_text+=chunk.text
yield PredictionResult(example=json_string, inference=gemini_response_text)
except Exception as e:
logging.error(f"Error during Gemini accuracy inference for input {json_string}: {e}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_INFERENCE")
############## END STEP 3 ##############
Para probar este código, ejecuta lo siguiente:
python gemini_beam_pipeline_step3.py --project $PROJECT_ID --runner DirectRunner --test_mode
Este paso también debe devolver una inferencia, comentar y devolver una puntuación sobre la precisión con la que Gemini cree que respondió la herramienta.
Deberías obtener un resultado como el siguiente.
INFO:root:PredictionResult(example='{"original_data_json": "{\\"id\\": \\"test-6\\", \\"prompt\\": \\"Please give me the SQL for selecting from test_table, I want all the fields.\\", \\"text\\": \\"absolutely, here\'s a picture of a cat\\", \\"timestamp\\": 1751052770.7552562, \\"user_id\\": \\"user_c\\"}", "original_prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "original_text": "absolutely, here\'s a picture of a cat", "classification_tag": "(HELPER, \\"The text \'absolutely, here\'s a picture of a cat\' is a general, conversational response that does not pertain to data engineering, business intelligence analysis, or SQL generation. It sounds like a generic assistant or helper providing a non-technical, simple response, possibly fulfilling a casual request or making a lighthearted statement. Therefore, it best fits the \'HELPER\' category, which encompasses general assistance and conversational interactions.\\")"}', inference='0.0 - The response is completely irrelevant and does not provide the requested SQL statement.', model_id=None)
8. Ventanas y análisis de resultados
Ahora, segmentarás tus resultados para analizarlos en intervalos de tiempo específicos. Usarás ventanas fijas para agrupar los datos, lo que te permitirá obtener estadísticas agregadas. Después de la segmentación, analizarás los resultados sin procesar de Gemini en un formato más estructurado, que incluye los datos originales, la etiqueta de clasificación, la puntuación de precisión y la explicación.

Para esta sección, usa gemini_beam_pipeline_step4.py.
- Agrega una ventana de tiempo fija de 60 segundos para que todos los datos se coloquen dentro de una ventana de 60 segundos.
Este es un ejemplo del código:
############## BEGIN STEP 4 ##############
| 'WindowIntoFixedWindows' >> beam.WindowInto(beam.window.FixedWindows(60))
############## END STEP 4 ##############
Para probar este código, ejecuta lo siguiente:
python gemini_beam_pipeline_step4.py --project $PROJECT_ID --runner DirectRunner --test_mode
Este paso es informativo. Busca tu ventana. Esto se mostrará como una marca de tiempo de inicio o detención de la ventana.
Deberías obtener un resultado como el siguiente.
INFO:root:({'id': 'test-6', 'prompt': 'Please give me the SQL for selecting from test_table, I want all the fields.', 'text': "absolutely, here's a picture of a cat", 'timestamp': 1751052901.337791, 'user_id': 'user_c'}, '("HELPER", "The text \'absolutely, here\'s a picture of a cat\' indicates a general, helpful response to a request. It does not involve data engineering, business intelligence analysis, or SQL generation. Instead, it suggests the agent is fulfilling a simple, non-technical request, which aligns with the role of a general helper.")', 0.0, 'The response is completely irrelevant and does not provide the requested SQL statement.', [1751052900.0, 1751052960.0))
9. Cómo contar resultados buenos y malos con el procesamiento con estado
Por último, usarás un DoFn con estado para contar los resultados "buenos" y "malos" dentro de cada ventana. Un resultado "bueno" podría ser una interacción con una puntuación de precisión alta, mientras que un resultado "malo" indica una puntuación baja. Este procesamiento con estado te permite mantener recuentos y hasta recopilar ejemplos de interacciones "malas" con el tiempo, lo que es fundamental para supervisar el estado y el rendimiento de tu chatbot en tiempo real.
Para esta sección, usa gemini_beam_pipeline_step5.py.
- Crea una función con estado. Necesitarás dos estados: (1) para hacer un seguimiento de la cantidad de recuentos incorrectos y (2) para conservar los registros incorrectos que se mostrarán. Usa los codificadores adecuados para garantizar que el sistema pueda tener un buen rendimiento.
- Cada vez que veas los valores de una inferencia incorrecta, querrás hacer un seguimiento de ambos y emitirlos al final de la ventana. Recuerda restablecer los estados después de emitir. Este último es solo para fines ilustrativos, no intentes mantener todos estos en la memoria en un entorno real.
Este es un ejemplo del código:
############## BEGIN STEP 5 ##############
# Define a state specification for a combining value.
# This will store the running sum for each key.
# The coder is specified for efficiency.
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(), # Used VarIntCoder directly
beam.transforms.combiners.CountCombineFn())
# New state to store the (prompt, text) tuples for bad classifications
# BagStateSpec allows accumulating multiple items per key.
BAD_PROMPTS_STATE = beam.transforms.userstate.BagStateSpec(
'bad_prompts', coder=beam.coders.TupleCoder([beam.coders.StrUtf8Coder(), beam.coders.StrUtf8Coder()])
)
# Define a timer to fire at the end of the window, using WATERMARK as per blog example.
WINDOW_TIMER = TimerSpec('window_timer', TimeDomain.WATERMARK)
def process(
self,
element: Tuple[str, Tuple[int, Tuple[str, str]]], # (key, (count_val, (prompt, text)))
key=beam.DoFn.KeyParam,
count_state=beam.DoFn.StateParam(COUNT_STATE),
bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE), # New state param
window_timer=beam.DoFn.TimerParam(WINDOW_TIMER),
window=beam.DoFn.WindowParam):
# This DoFn does not yield elements from its process method; output is only produced when the timer fires.
if key == 'bad': # Only count 'bad' elements
count_state.add(element[1][0]) # Add the count (which is 1)
bad_prompts_state.add(element[1][1]) # Add the (prompt, text) tuple
window_timer.set(window.end) # Set timer to fire at window end
@on_timer(WINDOW_TIMER)
def on_window_timer(self, key=beam.DoFn.KeyParam, count_state=beam.DoFn.StateParam(COUNT_STATE), bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE)):
final_count = count_state.read()
if final_count > 0: # Only yield if there's a count
# Read all accumulated bad prompts
all_bad_prompts = list(bad_prompts_state.read())
# Clear the state for the next window to avoid carrying over data.
count_state.clear()
bad_prompts_state.clear()
yield (key, final_count, all_bad_prompts) # Yield count and list of prompts
############## END STEP 5 ##############
Para probar este código, ejecuta lo siguiente:
python gemini_beam_pipeline_step5.py --project $PROJECT_ID --runner DirectRunner --test_mode
En este paso, se deberían mostrar todos los recuentos. Experimenta con el tamaño de la ventana y verás que los lotes serán diferentes. La ventana predeterminada se ajustará en un minuto, así que intenta usar 30 segundos o otro período, y verás que los lotes y los recuentos difieren.
Deberías obtener un resultado como el siguiente.
INFO:root:Window: [1751052960.0, 1751053020.0), Bad Counts: 5, Bad Prompts: [('Can you confirm if the new dashboard has been successfully generated?', 'I have gone ahead and generated a new dashboard for you.'), ('How is the new feature performing?', 'It works as expected.'), ('What is the capital of France?', 'The square root of a banana is purple.'), ('Explain quantum entanglement to a five-year-old.', 'A flock of geese wearing tiny hats danced the tango on the moon.'), ('Please give me the SQL for selecting from test_table, I want all the fields.', "absolutely, here's a picture of a cat")]
10. Realiza una limpieza
- Borra el proyecto de Google Cloud (opcional, pero recomendado para los codelabs): Si este proyecto se creó solo para este codelab y ya no lo necesitas, borrar todo el proyecto es la forma más completa de garantizar que se quiten todos los recursos.
- Ve a la página Administrar recursos en la consola de Google Cloud.
- Elige tu proyecto.
- Haz clic en Borrar proyecto y sigue las instrucciones en pantalla.
11. ¡Felicitaciones!
¡Felicitaciones por completar el codelab! Compilaste correctamente una canalización de inferencia de AA en tiempo real con Apache Beam y Gemini en Dataflow. Aprendiste a aprovechar el poder de la IA generativa en tus flujos de datos para extraer estadísticas valiosas y lograr una ingeniería de datos más inteligente y automatizada.