
۱. مقدمه
در چشمانداز پرشتاب دادههای امروزی، بینشهای بلادرنگ برای تصمیمگیریهای آگاهانه بسیار مهم هستند. این آزمایشگاه کد شما را در ساخت یک خط لوله ارزیابی بلادرنگ راهنمایی میکند. ما با استفاده از چارچوب Apache Beam شروع خواهیم کرد، که یک مدل برنامهنویسی یکپارچه برای دادههای دستهای و جریانی ارائه میدهد. این امر با حذف منطق محاسبات توزیعشده پیچیدهای که در غیر این صورت باید از ابتدا بسازید، توسعه خط لوله را به طور قابل توجهی ساده میکند. پس از تعریف خط لوله شما با استفاده از Beam، میتوانید آن را به طور یکپارچه در Google Cloud Dataflow اجرا کنید، یک سرویس کاملاً مدیریتشده که مقیاس و عملکرد بینظیری را برای نیازهای پردازش دادههای شما ارائه میدهد.
در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه یک خط لوله مقیاسپذیر Apache Beam را برای استنتاج یادگیری ماشین معماری کنید، یک ModelHandler سفارشی برای ادغام مدل Gemini در Vertex AI توسعه دهید، از مهندسی سریع برای طبقهبندی هوشمند متن در جریانهای داده استفاده کنید و این خط لوله استنتاج یادگیری ماشینی در حال جریان را در Google Cloud Dataflow مستقر و راهاندازی کنید. در پایان، بینشهای ارزشمندی در مورد بهکارگیری یادگیری ماشین برای درک دادههای بلادرنگ و ارزیابی مداوم در گردشهای کاری مهندسی، بهویژه برای حفظ هوش مصنوعی مکالمهای قوی و کاربر محور، به دست خواهید آورد.
سناریو
شرکت شما یک عامل داده ساخته است. عامل داده شما که با کیت توسعه عامل (ADK) ساخته شده است، به قابلیتهای تخصصی مختلفی برای کمک به وظایف مرتبط با داده مجهز شده است. آن را به عنوان یک دستیار داده همه کاره تصور کنید که آماده رسیدگی به درخواستهای متنوع است، از ایفای نقش به عنوان تحلیلگر BI برای تولید گزارشهای دقیق گرفته تا یک مهندس داده که به شما در ساخت خطوط داده قوی کمک میکند، یا یک مولد SQL که دستورات SQL دقیقی را ایجاد میکند و موارد دیگر. هر تعاملی که این عامل دارد، هر پاسخی که تولید میکند، به طور خودکار در Firestore ذخیره میشود. اما چرا ما در اینجا به یک خط لوله نیاز داریم؟
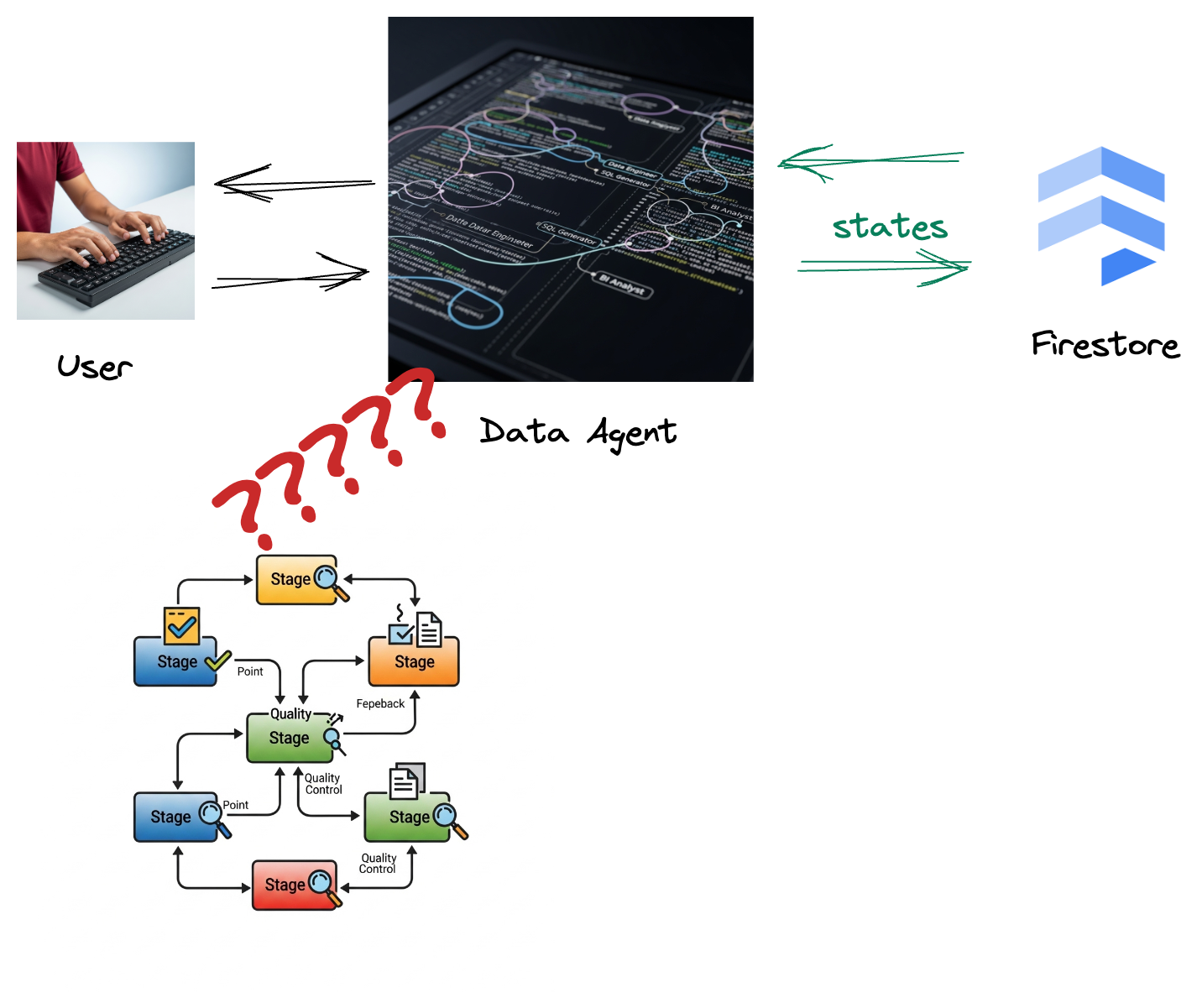
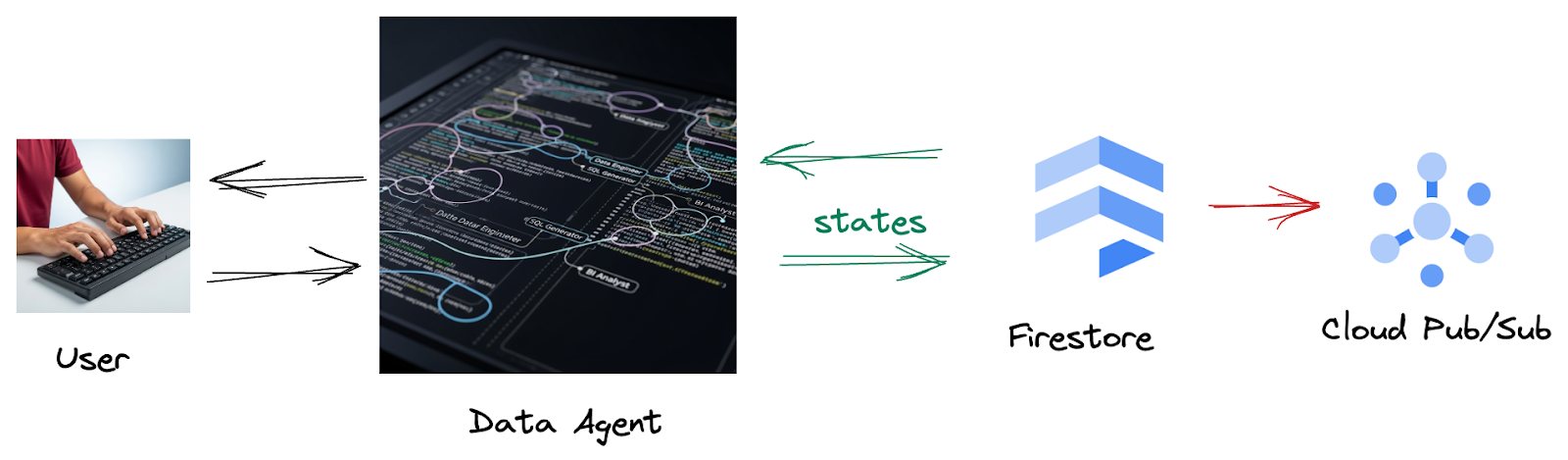
زیرا از طریق Firestore، یک trigger به طور یکپارچه این دادههای تعاملی را به Pub/Sub ارسال میکند و تضمین میکند که ما میتوانیم بلافاصله این مکالمات حیاتی را در زمان واقعی پردازش و تجزیه و تحلیل کنیم.
۲. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- با کلیک روی این لینک، Cloud Shell را فعال کنید. میتوانید با کلیک روی دکمه مربوطه از Cloud Shell، بین Cloud Shell Terminal (برای اجرای دستورات ابری) و Editor (برای ساخت پروژهها) جابجا شوید.
- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
- API های مورد نیاز را از طریق دستور زیر فعال کنید. این کار ممکن است چند دقیقه طول بکشد، پس لطفاً صبور باشید.
gcloud services enable \
dataflow.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- حتماً پایتون ۳.۱۰+ داشته باشید
- نصب بستههای پایتون
کتابخانههای پایتون مورد نیاز برای Apache Beam، Google Cloud Vertex AI و Google Generative AI را در محیط Cloud Shell خود نصب کنید.
pip install apache-beam[gcp] google-genai
- مخزن گیتهاب را کلون کنید و به دایرکتوری demo بروید.
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/beam_as_eval
برای دستورات و نحوهی استفاده از gcloud به مستندات آن مراجعه کنید.
۳. نحوه استفاده از مخزن گیتهاب ارائه شده
مخزن گیتهاب مرتبط با این آزمایشگاه کد، که در آدرس https://github.com/GoogleCloudPlatform/devrel-demos/tree/main/data-analytics/beam_as_eval قرار دارد، برای تسهیل یک تجربه یادگیری هدایتشده سازماندهی شده است. این مخزن شامل کدی است که با هر بخش مجزا از آزمایشگاه کد همسو است و پیشرفت واضحی را در طول مطالب تضمین میکند.
در مخزن، دو پوشه اصلی پیدا خواهید کرد: «کامل» و «ناقص». پوشه «کامل» کدهای کاملاً کاربردی هر مرحله را در خود جای داده و به شما امکان میدهد خروجی مورد نظر را اجرا و مشاهده کنید. برعکس، پوشه «ناقص» کدهای مراحل قبلی را ارائه میدهد و بخشهای خاصی را بین ##### START STEP <NUMBER> ##### و ##### END STEP <NUMBER> ##### میکند تا بتوانید آنها را به عنوان بخشی از تمرینها تکمیل کنید. این ساختار به شما امکان میدهد تا ضمن شرکت فعال در چالشهای کدنویسی، بر دانش قبلی خود بیفزایید.
۴. بررسی اجمالی معماری
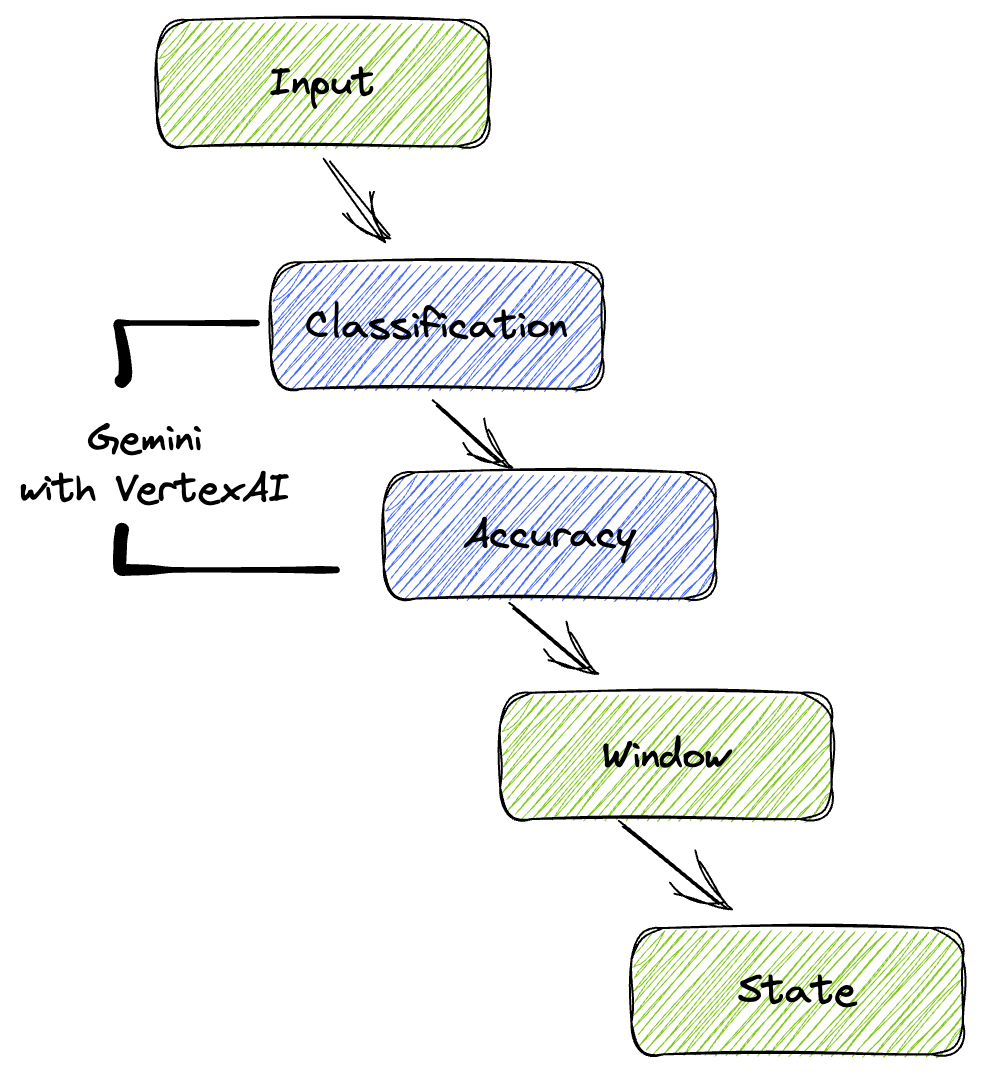
خط لوله ما یک الگوی قدرتمند و مقیاسپذیر برای ادغام استنتاج یادگیری ماشینی در جریانهای داده ارائه میدهد. در اینجا نحوه قرارگیری قطعات در کنار هم آورده شده است:
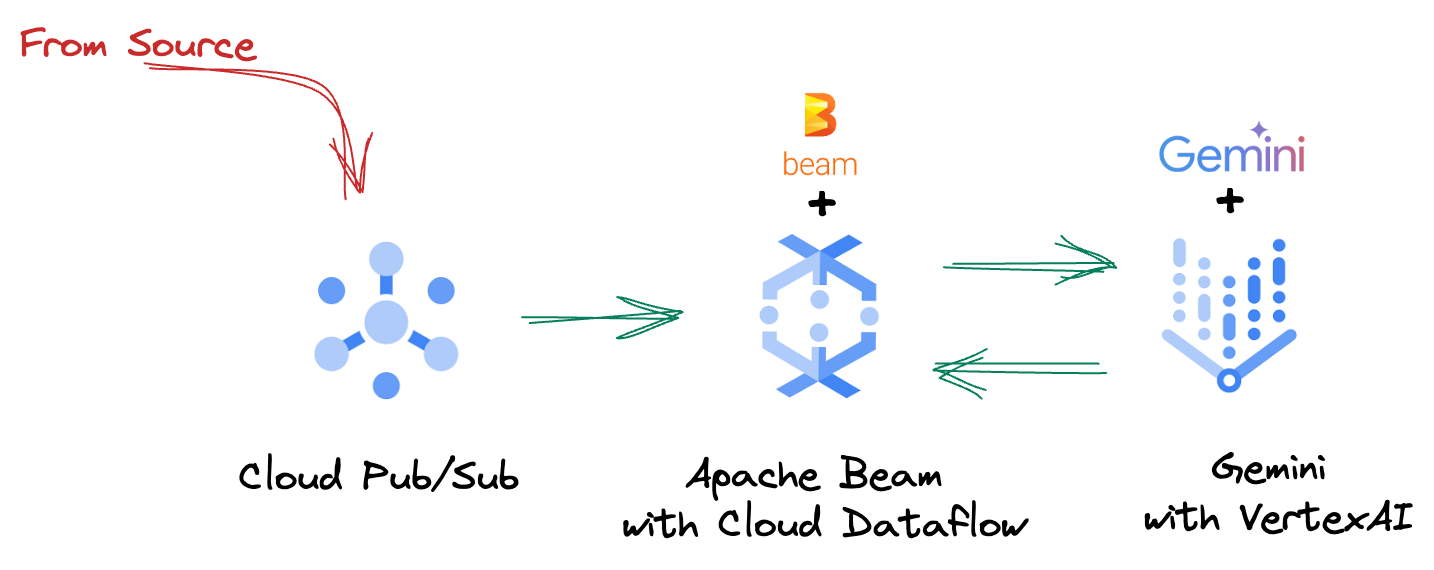
در خط تولید Beam خود، چندین ورودی را به صورت شرطی کدنویسی خواهید کرد و سپس مدلهای سفارشی را با تبدیل RunInference بارگذاری خواهید کرد. اگرچه در مثال از Gemini با VertexAI استفاده میکنید، اما این نشان میدهد که چگونه اساساً چندین ModelHandler ایجاد میکنید تا با تعداد مدلهایی که دارید متناسب باشند. در نهایت، از یک DoFn با وضعیت (stateful DoFn) برای پیگیری رویدادها و انتشار آنها به شیوهای کنترلشده استفاده خواهید کرد.
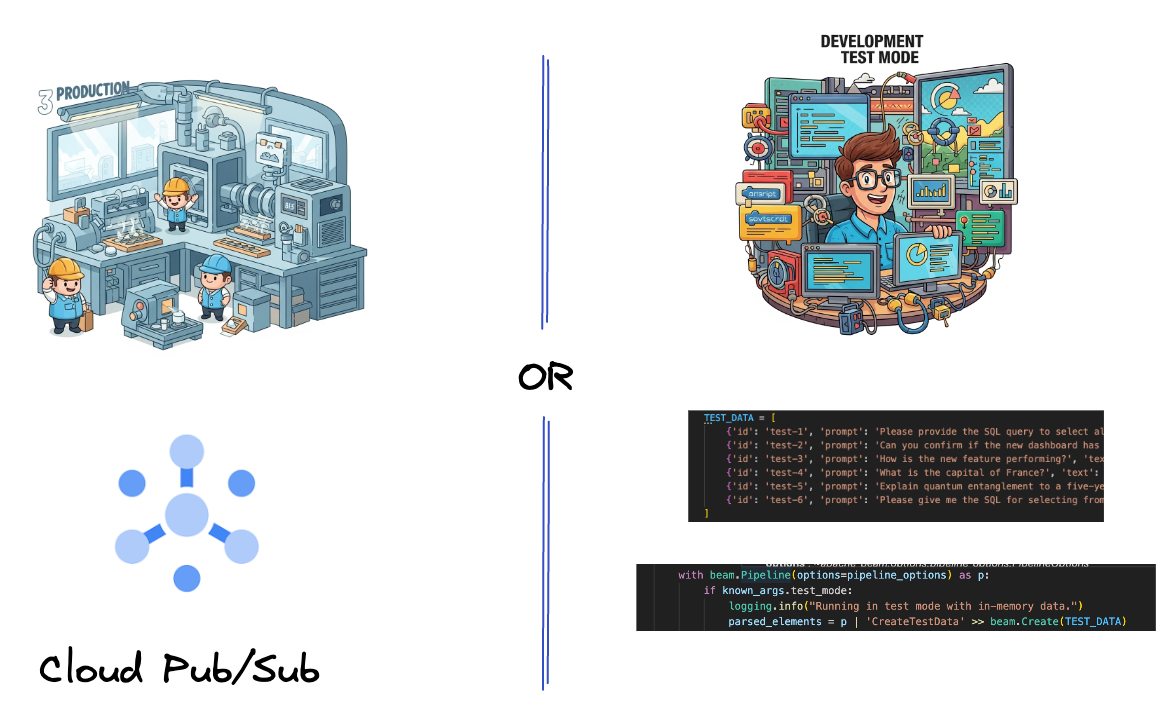
۵. دریافت دادهها
ابتدا، شما خط لوله خود را برای دریافت دادهها تنظیم خواهید کرد. شما از Pub/Sub برای پخش زنده استفاده خواهید کرد، اما برای آسانتر کردن توسعه، یک حالت آزمایشی نیز ایجاد خواهید کرد. این test_mode به شما امکان میدهد خط لوله را به صورت محلی با استفاده از دادههای نمونه از پیش تعریف شده اجرا کنید، بنابراین برای بررسی عملکرد خط لوله خود نیازی به یک جریان زنده Pub/Sub ندارید.
برای این بخش از gemini_beam_pipeline_step1.py استفاده کنید.
- با استفاده از شیء خط لوله ارائه شده p، یک ورودی Pub/Sub را کدنویسی کنید و خروجی را به عنوان یک pCollection بنویسید.
- علاوه بر این، از یک پرچم برای تعیین اینکه آیا TEST_MODE تنظیم شده است یا خیر، استفاده کنید.
- اگر TEST_MODE تنظیم شده بود، به تجزیه آرایه TEST_DATA به عنوان ورودی بروید.
این کار ضروری نیست، اما به کوتاه شدن فرآیند کمک میکند، بنابراین نیازی نیست که Pub/Sub را اینقدر زود درگیر کنید.
در اینجا مثالی از کد زیر را مشاهده میکنید:
# Step 1
# Ingesting Data
# Write your data ingestion step here.
############## BEGIN STEP 1 ##############
if known_args.test_mode:
logging.info("Running in test mode with in-memory data.")
parsed_elements = p | 'CreateTestData' >> beam.Create(TEST_DATA)
# Convert dicts to JSON strings and add timestamps for test mode
parsed_elements = parsed_elements | 'ConvertTestDictsToJsonAndAddTimestamps' >> beam.Map(
lambda x: beam.window.TimestampedValue(json.dumps(x), x['timestamp'])
)
else:
logging.info(f"Reading from Pub/Sub topic: {known_args.input_topic}")
parsed_elements = (
p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(
topic=known_args.input_topic
).with_output_types(bytes)
| 'DecodeBytes' >> beam.Map(lambda b: b.decode('utf-8')) # Output is JSON string
# Extract timestamp from JSON string for Pub/Sub messages
| 'AddTimestampsFromParsedJson' >> beam.Map(lambda s: beam.window.TimestampedValue(s, json.loads(s)['timestamp']))
)
############## END STEP 1 ##############
این کد را با اجرای دستور زیر آزمایش کنید:
python gemini_beam_pipeline_step1.py --project $PROJECT_ID --runner DirectRunner --test_mode
این مرحله باید تمام رکوردها را منتشر کند و آنها را در stdout ثبت کند.
باید انتظار خروجی مانند زیر را داشته باشید.
INFO:root:Running in test mode with in-memory data.
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:root:{"id": "test-1", "prompt": "Please provide the SQL query to select all fields from the 'TEST_TABLE'.", "text": "Sure here is the SQL: SELECT * FROM TEST_TABLE;", "timestamp": 1751052405.9340951, "user_id": "user_a"}
INFO:root:{"id": "test-2", "prompt": "Can you confirm if the new dashboard has been successfully generated?", "text": "I have gone ahead and generated a new dashboard for you.", "timestamp": 1751052410.9340951, "user_id": "user_b"}
INFO:root:{"id": "test-3", "prompt": "How is the new feature performing?", "text": "It works as expected.", "timestamp": 1751052415.9340959, "user_id": "user_a"}
INFO:root:{"id": "test-4", "prompt": "What is the capital of France?", "text": "The square root of a banana is purple.", "timestamp": 1751052430.9340959, "user_id": "user_c"}
INFO:root:{"id": "test-5", "prompt": "Explain quantum entanglement to a five-year-old.", "text": "A flock of geese wearing tiny hats danced the tango on the moon.", "timestamp": 1751052435.9340959, "user_id": "user_b"}
INFO:root:{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here's a picture of a cat", "timestamp": 1751052440.9340959, "user_id": "user_c"}
۶. ساخت یک PTransform برای طبقهبندی سریع LLM
در مرحله بعد، یک PTransform برای طبقهبندی اعلانها خواهید ساخت. این شامل استفاده از مدل Gemini از Vertex AI برای طبقهبندی متن ورودی است. شما یک GeminiModelHandler سفارشی تعریف خواهید کرد که مدل Gemini را بارگذاری میکند و سپس به مدل دستور میدهد که چگونه متن را در دستههایی مانند "مهندس داده"، "تحلیلگر هوش تجاری" یا "مولد SQL" طبقهبندی کند.
شما میتوانید این را با مقایسه با فراخوانیهای ابزار واقعی در لاگ استفاده کنید. این موضوع در این آزمایشگاه کد پوشش داده نشده است، اما میتوانید آن را به پاییندست ارسال کرده و مقایسه کنید. ممکن است برخی موارد مبهم باشند و این به عنوان یک نقطه داده اضافی عالی برای اطمینان از اینکه عامل شما ابزارهای صحیح را فراخوانی میکند، عمل میکند.
برای این بخش از gemini_beam_pipeline_step2.py استفاده کنید.
- ModelHandler سفارشی خود را بسازید؛ با این حال، به جای بازگرداندن یک شیء مدل در load_model، genai.Client را برگردانید.
- کدی که برای ایجاد تابع run_inference از ModelHandler سفارشی نیاز دارید. یک نمونه prompt ارائه شده است:
این درخواست میتواند چیزی شبیه به موارد زیر باشد:
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilities.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambiguous. Choose only one.
Finally, always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
- نتایج را به عنوان یک pCollection برای pTransform بعدی ارائه دهید.
در اینجا مثالی از کد زیر را مشاهده میکنید:
############## BEGIN STEP 2 ##############
# load_model is called once per worker process to initialize the LLM client.
# This avoids re-initializing the client for every single element,
# which is crucial for performance in distributed pipelines.
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
# run_inference is called for each batch of elements. Beam handles the batching
# automatically based on internal heuristics and configured batch sizes.
# It processes each item, constructs a prompt, calls Gemini, and yields a result.
def run_inference(
self,
batch: Sequence[Any], # Each item is a JSON string or a dict
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""
Runs inference on a batch of JSON strings or dicts.
Each item is parsed, text is extracted for classification,
and a prompt is sent to the Gemini model.
"""
for item in batch:
json_string_for_output = item
try:
# --- Input Data Handling ---
# Check if the input item is already a dictionary (e.g., from TEST_DATA)
# or a JSON string (e.g., from Pub/Sub).
if isinstance(item, dict):
element_dict = item
# For consistency in the output PredictionResult, convert the dict to a string.
# This ensures pr.example always contains the original JSON string.
json_string_for_output = json.dumps(item)
else:
element_dict = json.loads(item)
# Extract the 'text' field from the parsed dictionary.
text_to_classify = element_dict.get('text','')
if not text_to_classify:
logging.warning(f"Input JSON missing 'text' key or text is empty: {json_string_for_output}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_NO_TEXT")
continue
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilites.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambigiuous. Choose only one.
Finally always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
contents = [
types.Content( # This is the actual content for the LLM
role="user",
parts=[
types.Part.from_text(text=prompt)
]
)
]
gemini_response = model.models.generate_content_stream(
model=self._model_name, contents=contents, config=self._model_kwargs
)
classification_tag = ""
for chunk in gemini_response:
if chunk.text is not None:
classification_tag+=chunk.text
yield PredictionResult(example=json_string_for_output, inference=classification_tag)
except json.JSONDecodeError as e:
logging.error(f"Error decoding JSON string: {json_string_for_output}, error: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_JSON_DECODE")
except Exception as e:
logging.error(f"Error during Gemini inference for input {json_string_for_output}: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_INFERENCE")
############## END STEP 2 ##############
این کد را با اجرای دستور زیر آزمایش کنید:
python gemini_beam_pipeline_step2.py --project $PROJECT_ID --runner DirectRunner --test_mode
این مرحله باید یک استنتاج از Gemini را برگرداند. این استنتاج نتایج را طبق درخواست شما طبقهبندی میکند.
باید انتظار خروجی مانند زیر را داشته باشید.
INFO:root:PredictionResult(example='{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here\'s a picture of a cat", "timestamp": 1751052592.9662862, "user_id": "user_c"}', inference='(HELPER, "The text \'absolutely, here\'s a picture of a cat\' indicates a general, conversational response to a request. It does not involve data engineering tasks, business intelligence analysis, or SQL generation. Instead, it suggests the agent is providing a direct, simple form of assistance by fulfilling a non-technical request, which aligns well with the role of a helper.")', model_id=None)
۷. ساختن یک قاضی LLM
پس از طبقهبندی دستورات، شما دقت پاسخهای مدل را ارزیابی خواهید کرد. این شامل فراخوانی دیگری به مدل Gemini میشود، اما این بار، شما از آن میخواهید که امتیاز دهد که «متن» چقدر «دستور» اصلی را در مقیاسی از 0.0 تا 1.0 برآورده میکند. این به شما کمک میکند تا کیفیت خروجی هوش مصنوعی را درک کنید. شما یک GeminiAccuracyModelHandler جداگانه برای این کار ایجاد خواهید کرد.

برای این بخش از gemini_beam_pipeline_step3.py استفاده کنید.
- ModelHandler سفارشی خود را بسازید؛ با این حال، به جای بازگرداندن یک شیء مدل در load_model، genai.Client را درست همانطور که در بالا انجام دادید، برگردانید.
- کدی که برای ایجاد تابع run_inference از ModelHandler سفارشی نیاز دارید. یک نمونه prompt ارائه شده است:
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
نکتهای که باید در اینجا به آن توجه کنید این است که شما اساساً دو مدل مختلف را در یک خط تولید (pipeline) ایجاد کردهاید. در این مثال خاص، شما همچنین از فراخوانی Gemini با VertexAI استفاده میکنید، اما در همان مفهوم، میتوانید از مدلهای دیگر نیز استفاده و آنها را بارگذاری کنید. این امر مدیریت مدل شما را ساده میکند و به شما امکان میدهد از چندین مدل در یک خط تولید Beam استفاده کنید.
- نتایج را به عنوان یک pCollection برای pTransform بعدی ارائه دهید.
در اینجا مثالی از کد زیر را مشاهده میکنید:
############## BEGIN STEP 3 ##############
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
def run_inference(
self,
batch: Sequence[str], # Each item is a JSON string
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""Runs inference on a batch of JSON strings to verify accuracy."""
for json_string in batch:
try:
element_dict = json.loads(json_string)
original_prompt = element_dict.get('original_prompt', '')
original_text = element_dict.get('original_text', '')
if not original_prompt or not original_text:
logging.warning(f"Accuracy input missing prompt/text: {json_string}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_ACCURACY_INPUT")
continue
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
gemini_response = model.models.generate_content_stream(model=self._model_name, contents=[prompt_for_accuracy], config=self._model_kwargs)
gemini_response_text = ""
for chunk in gemini_response:
if chunk.text is not None:
gemini_response_text+=chunk.text
yield PredictionResult(example=json_string, inference=gemini_response_text)
except Exception as e:
logging.error(f"Error during Gemini accuracy inference for input {json_string}: {e}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_INFERENCE")
############## END STEP 3 ##############
این کد را با اجرای دستور زیر آزمایش کنید:
python gemini_beam_pipeline_step3.py --project $PROJECT_ID --runner DirectRunner --test_mode
این مرحله همچنین باید یک استنتاج را برگرداند، باید نظر بدهد و امتیازی در مورد میزان دقت پاسخدهی ابزار از نظر Gemini ارائه دهد.
باید انتظار خروجی مانند زیر را داشته باشید.
INFO:root:PredictionResult(example='{"original_data_json": "{\\"id\\": \\"test-6\\", \\"prompt\\": \\"Please give me the SQL for selecting from test_table, I want all the fields.\\", \\"text\\": \\"absolutely, here\'s a picture of a cat\\", \\"timestamp\\": 1751052770.7552562, \\"user_id\\": \\"user_c\\"}", "original_prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "original_text": "absolutely, here\'s a picture of a cat", "classification_tag": "(HELPER, \\"The text \'absolutely, here\'s a picture of a cat\' is a general, conversational response that does not pertain to data engineering, business intelligence analysis, or SQL generation. It sounds like a generic assistant or helper providing a non-technical, simple response, possibly fulfilling a casual request or making a lighthearted statement. Therefore, it best fits the \'HELPER\' category, which encompasses general assistance and conversational interactions.\\")"}', inference='0.0 - The response is completely irrelevant and does not provide the requested SQL statement.', model_id=None)
۸. پنجرهبندی و تحلیل نتایج
اکنون، نتایج خود را برای تجزیه و تحلیل آنها در فواصل زمانی خاص، پنجرهبندی خواهید کرد. از پنجرههای ثابت برای گروهبندی دادهها استفاده خواهید کرد که به شما امکان میدهد بینشهای کلی دریافت کنید. پس از پنجرهبندی، خروجیهای خام Gemini را به قالبی ساختاریافتهتر، شامل دادههای اصلی، برچسب طبقهبندی، امتیاز دقت و توضیح، تجزیه خواهید کرد.

برای این بخش از gemini_beam_pipeline_step4.py استفاده کنید.
- یک بازه زمانی ثابت ۶۰ ثانیهای اضافه کنید تا تمام دادهها در یک بازه ۶۰ ثانیهای قرار گیرند.
در اینجا مثالی از کد زیر را مشاهده میکنید:
############## BEGIN STEP 4 ##############
| 'WindowIntoFixedWindows' >> beam.WindowInto(beam.window.FixedWindows(60))
############## END STEP 4 ##############
این کد را با اجرای دستور زیر آزمایش کنید:
python gemini_beam_pipeline_step4.py --project $PROJECT_ID --runner DirectRunner --test_mode
این مرحله آموزنده است، شما به دنبال پنجره خود هستید. این به عنوان مهر زمانی توقف/شروع پنجره نشان داده میشود.
باید انتظار خروجی مانند زیر را داشته باشید.
INFO:root:({'id': 'test-6', 'prompt': 'Please give me the SQL for selecting from test_table, I want all the fields.', 'text': "absolutely, here's a picture of a cat", 'timestamp': 1751052901.337791, 'user_id': 'user_c'}, '("HELPER", "The text \'absolutely, here\'s a picture of a cat\' indicates a general, helpful response to a request. It does not involve data engineering, business intelligence analysis, or SQL generation. Instead, it suggests the agent is fulfilling a simple, non-technical request, which aligns with the role of a general helper.")', 0.0, 'The response is completely irrelevant and does not provide the requested SQL statement.', [1751052900.0, 1751052960.0))
۹. شمارش نتایج خوب و بد با پردازش حالتمند
در نهایت، شما از یک DoFn با وضعیت (stateful DoFn) برای شمارش نتایج "خوب" و "بد" در هر پنجره استفاده خواهید کرد. یک نتیجه "خوب" ممکن است تعاملی با امتیاز دقت بالا باشد، در حالی که یک نتیجه "بد" نشان دهنده امتیاز پایین است. این پردازش با وضعیت به شما امکان میدهد تا شمارشها را حفظ کرده و حتی نمونههایی از تعاملات "بد" را در طول زمان جمعآوری کنید، که برای نظارت بر سلامت و عملکرد چتبات شما در زمان واقعی بسیار مهم است.
برای این بخش از gemini_beam_pipeline_step5.py استفاده کنید.
- یک تابع با وضعیت (stateful) ایجاد کنید. شما به دو وضعیت نیاز خواهید داشت: (1) برای پیگیری تعداد شمارشهای بد و (2) برای نمایش رکوردهای بد. از کدنویسهای مناسب استفاده کنید تا از عملکرد صحیح سیستم اطمینان حاصل شود.
- هر بار که مقادیر مربوط به یک استنتاج بد را میبینید، میخواهید هر دو را پیگیری کنید و آنها را در انتهای پنجره منتشر کنید. به یاد داشته باشید که حالتها را پس از انتشار، مجدداً تنظیم کنید. مورد دوم فقط برای اهداف توضیحی است، سعی نکنید همه اینها را در یک محیط واقعی در حافظه نگه دارید.
در اینجا مثالی از کد زیر را مشاهده میکنید:
############## BEGIN STEP 5 ##############
# Define a state specification for a combining value.
# This will store the running sum for each key.
# The coder is specified for efficiency.
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(), # Used VarIntCoder directly
beam.transforms.combiners.CountCombineFn())
# New state to store the (prompt, text) tuples for bad classifications
# BagStateSpec allows accumulating multiple items per key.
BAD_PROMPTS_STATE = beam.transforms.userstate.BagStateSpec(
'bad_prompts', coder=beam.coders.TupleCoder([beam.coders.StrUtf8Coder(), beam.coders.StrUtf8Coder()])
)
# Define a timer to fire at the end of the window, using WATERMARK as per blog example.
WINDOW_TIMER = TimerSpec('window_timer', TimeDomain.WATERMARK)
def process(
self,
element: Tuple[str, Tuple[int, Tuple[str, str]]], # (key, (count_val, (prompt, text)))
key=beam.DoFn.KeyParam,
count_state=beam.DoFn.StateParam(COUNT_STATE),
bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE), # New state param
window_timer=beam.DoFn.TimerParam(WINDOW_TIMER),
window=beam.DoFn.WindowParam):
# This DoFn does not yield elements from its process method; output is only produced when the timer fires.
if key == 'bad': # Only count 'bad' elements
count_state.add(element[1][0]) # Add the count (which is 1)
bad_prompts_state.add(element[1][1]) # Add the (prompt, text) tuple
window_timer.set(window.end) # Set timer to fire at window end
@on_timer(WINDOW_TIMER)
def on_window_timer(self, key=beam.DoFn.KeyParam, count_state=beam.DoFn.StateParam(COUNT_STATE), bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE)):
final_count = count_state.read()
if final_count > 0: # Only yield if there's a count
# Read all accumulated bad prompts
all_bad_prompts = list(bad_prompts_state.read())
# Clear the state for the next window to avoid carrying over data.
count_state.clear()
bad_prompts_state.clear()
yield (key, final_count, all_bad_prompts) # Yield count and list of prompts
############## END STEP 5 ##############
این کد را با اجرای دستور زیر آزمایش کنید:
python gemini_beam_pipeline_step5.py --project $PROJECT_ID --runner DirectRunner --test_mode
این مرحله باید تمام شمارشها را نمایش دهد، با اندازه پنجره بازی کنید و باید ببینید که دستهها متفاوت خواهند بود. پنجره پیشفرض ظرف یک دقیقه جا میشود، بنابراین از ۳۰ ثانیه یا یک بازه زمانی دیگر استفاده کنید و باید ببینید که دستهها و شمارشها متفاوت هستند.
باید انتظار خروجی مانند زیر را داشته باشید.
INFO:root:Window: [1751052960.0, 1751053020.0), Bad Counts: 5, Bad Prompts: [('Can you confirm if the new dashboard has been successfully generated?', 'I have gone ahead and generated a new dashboard for you.'), ('How is the new feature performing?', 'It works as expected.'), ('What is the capital of France?', 'The square root of a banana is purple.'), ('Explain quantum entanglement to a five-year-old.', 'A flock of geese wearing tiny hats danced the tango on the moon.'), ('Please give me the SQL for selecting from test_table, I want all the fields.', "absolutely, here's a picture of a cat")]
۱۰. تمیز کردن
- حذف پروژه گوگل کلود (اختیاری اما برای Codelabs توصیه میشود): اگر این پروژه صرفاً برای این Codelab ایجاد شده است و دیگر به آن نیازی ندارید، حذف کل پروژه کاملترین راه برای اطمینان از حذف تمام منابع است.
- به صفحه مدیریت منابع در کنسول گوگل کلود بروید.
- پروژه خود را انتخاب کنید.
- روی حذف پروژه کلیک کنید و دستورالعملهای روی صفحه را دنبال کنید.
۱۱. تبریک میگویم!
تبریک بابت تکمیل آزمایشگاه کد! شما با موفقیت یک خط لوله استنتاج یادگیری ماشینی بلادرنگ با استفاده از Apache Beam و Gemini روی Dataflow ساختید. شما یاد گرفتهاید که چگونه قدرت هوش مصنوعی مولد را به جریانهای داده خود بیاورید و بینشهای ارزشمندی را برای مهندسی دادههای هوشمندتر و خودکارتر استخراج کنید.