
1. Introduction
Dans le paysage de données actuel en constante évolution, les insights en temps réel sont essentiels pour prendre des décisions éclairées. Cet atelier de programmation vous guidera dans la création d'un pipeline d'évaluation en temps réel. Nous allons commencer par exploiter le framework Apache Beam, qui offre un modèle de programmation unifié pour les données par lot et par flux. Cela simplifie considérablement le développement de pipelines en éliminant la logique de calcul distribué complexe que vous devriez autrement créer de toutes pièces. Une fois votre pipeline défini à l'aide de Beam, vous l'exécuterez de manière fluide sur Google Cloud Dataflow, un service entièrement géré qui offre une évolutivité et des performances inégalées pour vos besoins de traitement des données.
Dans cet atelier de programmation, vous allez apprendre à concevoir un pipeline Apache Beam évolutif pour l'inférence du machine learning, à développer un ModelHandler personnalisé pour intégrer le modèle Gemini de Vertex AI, à exploiter l'ingénierie des requêtes pour la classification intelligente de texte dans les flux de données, et à déployer et exploiter ce pipeline d'inférence ML en streaming sur Google Cloud Dataflow. À la fin de ce cours, vous aurez acquis des connaissances précieuses sur l'application du machine learning pour comprendre les données en temps réel et l'évaluation continue dans les workflows d'ingénierie, en particulier pour maintenir une IA conversationnelle robuste et axée sur l'utilisateur.
Scénario
Votre entreprise a créé un agent de données. Votre agent de données, conçu avec l'Agent Development Kit (ADK), est doté de diverses fonctionnalités spécialisées pour vous aider à effectuer des tâches liées aux données. Imaginez-le comme un assistant de données polyvalent, prêt à traiter diverses demandes : il peut agir en tant qu'analyste BI pour générer des rapports perspicaces, en tant qu'ingénieur de données pour vous aider à créer des pipelines de données robustes, en tant que générateur SQL pour créer des instructions SQL précises, et bien plus encore. Chaque interaction de cet agent et chaque réponse qu'il génère sont automatiquement stockées dans Firestore. Mais pourquoi avons-nous besoin d'un pipeline ici ?
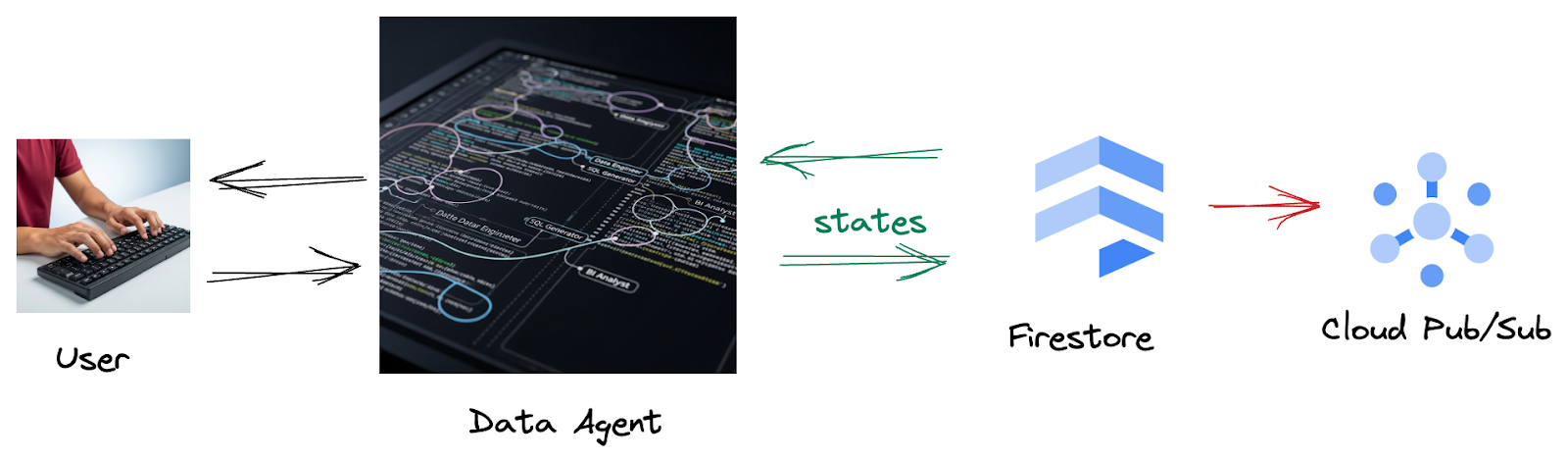
En effet, à partir de Firestore, un déclencheur envoie de manière transparente ces données d'interaction à Pub/Sub, ce qui nous permet de traiter et d'analyser immédiatement ces conversations critiques en temps réel.
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Cliquez sur ce lien pour activer Cloud Shell. Vous pouvez basculer entre le terminal Cloud Shell (pour exécuter des commandes cloud) et l'éditeur (pour créer des projets) en cliquant sur le bouton correspondant dans Cloud Shell.
- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
- Activez les API requises à l'aide de la commande ci-dessous. Cette opération peut prendre quelques minutes. Veuillez patienter.
gcloud services enable \
dataflow.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Assurez-vous d'avoir Python 3.10 ou version ultérieure.
- Installer des packages Python
Installez les bibliothèques Python requises pour Apache Beam, Google Cloud Vertex AI et Google Generative AI dans votre environnement Cloud Shell.
pip install apache-beam[gcp] google-genai
- Clonez le dépôt GitHub et accédez au répertoire de démonstration.
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/beam_as_eval
Consultez la documentation pour connaître les commandes gcloud et leur utilisation.
3. Utiliser le dépôt GitHub fourni
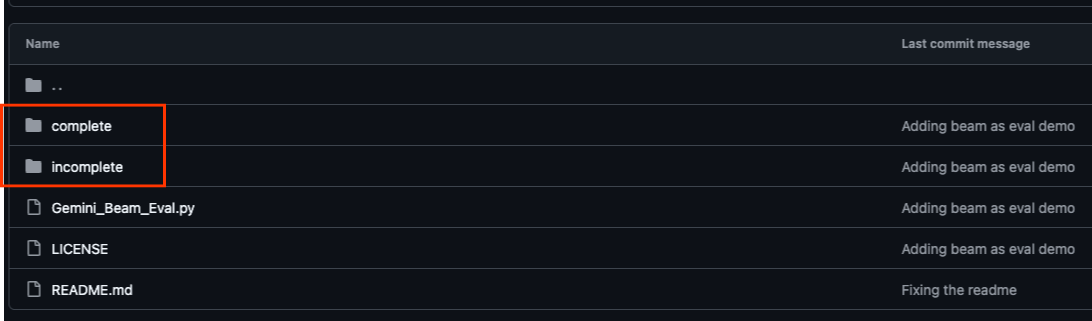
Le dépôt GitHub associé à cet atelier de programmation, disponible à l'adresse https://github.com/GoogleCloudPlatform/devrel-demos/tree/main/data-analytics/beam_as_eval , est organisé pour faciliter l'apprentissage guidé. Il contient un squelette de code qui correspond à chaque partie distincte de l'atelier de programmation, ce qui garantit une progression claire dans le contenu.
Dans le dépôt, vous trouverez deux dossiers principaux : "complete" (terminé) et "incomplete" (incomplet). Le dossier "complete" contient du code entièrement fonctionnel pour chaque étape, ce qui vous permet d'exécuter le code et d'observer le résultat attendu. À l'inverse, le dossier "incomplete" fournit le code des étapes précédentes, en laissant des sections spécifiques marquées entre ##### START STEP <NUMBER> ##### et ##### END STEP <NUMBER> ##### à compléter dans le cadre des exercices. Cette structure vous permet de vous appuyer sur vos connaissances préalables tout en participant activement aux défis de programmation.
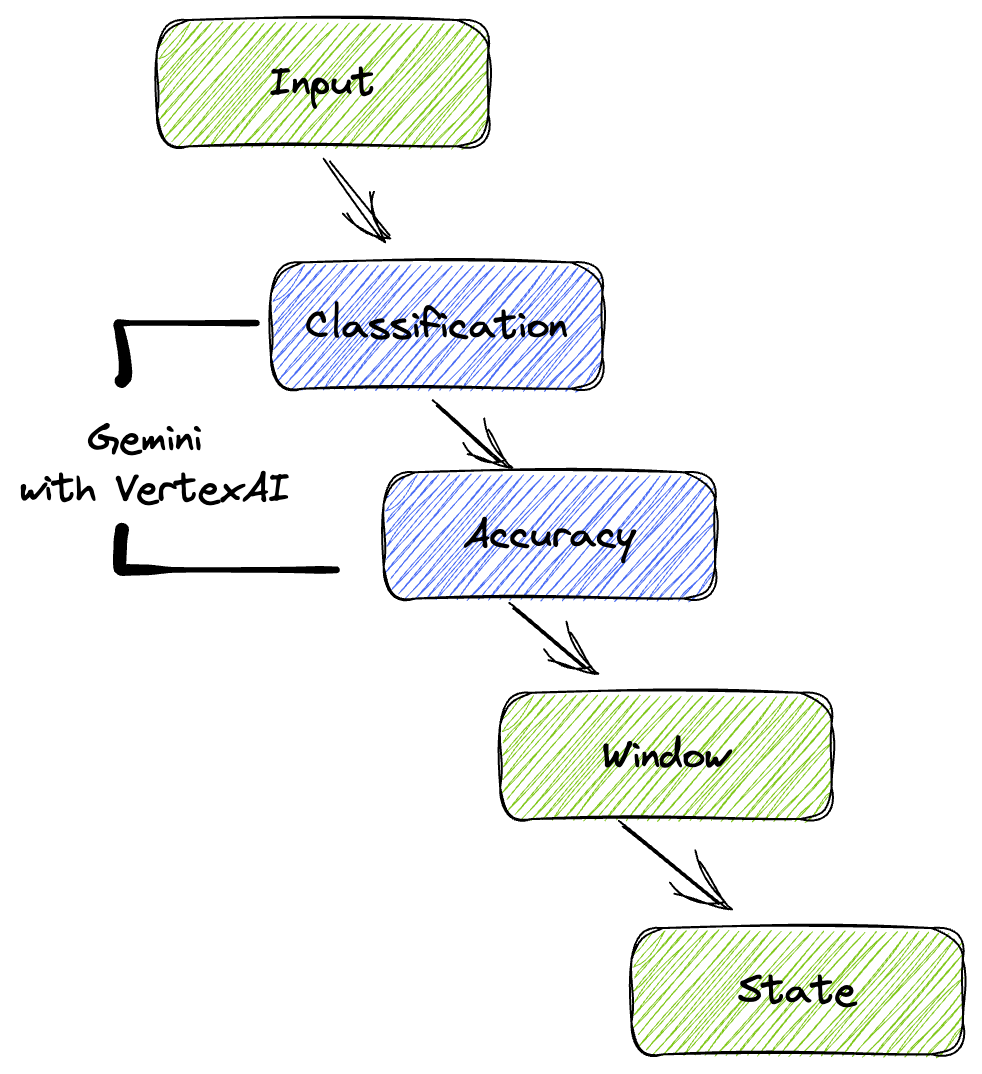
4. Présentation de l'architecture
Notre pipeline fournit un modèle puissant et évolutif pour intégrer l'inférence de ML dans les flux de données. Voici comment les différents éléments s'articulent :
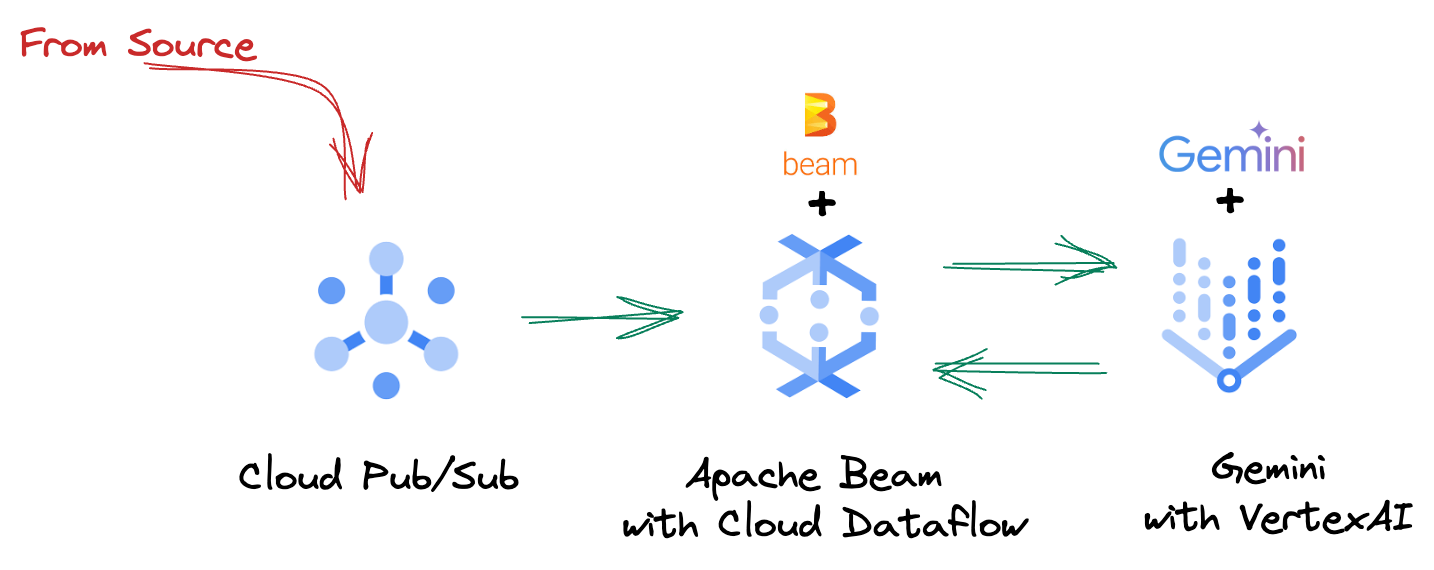
Dans votre pipeline Beam, vous allez coder plusieurs entrées de manière conditionnelle, puis charger des modèles personnalisés avec la transformation clé en main RunInference. Même si vous utilisez Gemini avec Vertex AI dans l'exemple, il montre comment créer plusieurs ModelHandlers pour s'adapter au nombre de modèles dont vous disposez. Enfin, vous utiliserez un DoFn avec état pour suivre les événements et les émettre de manière contrôlée.
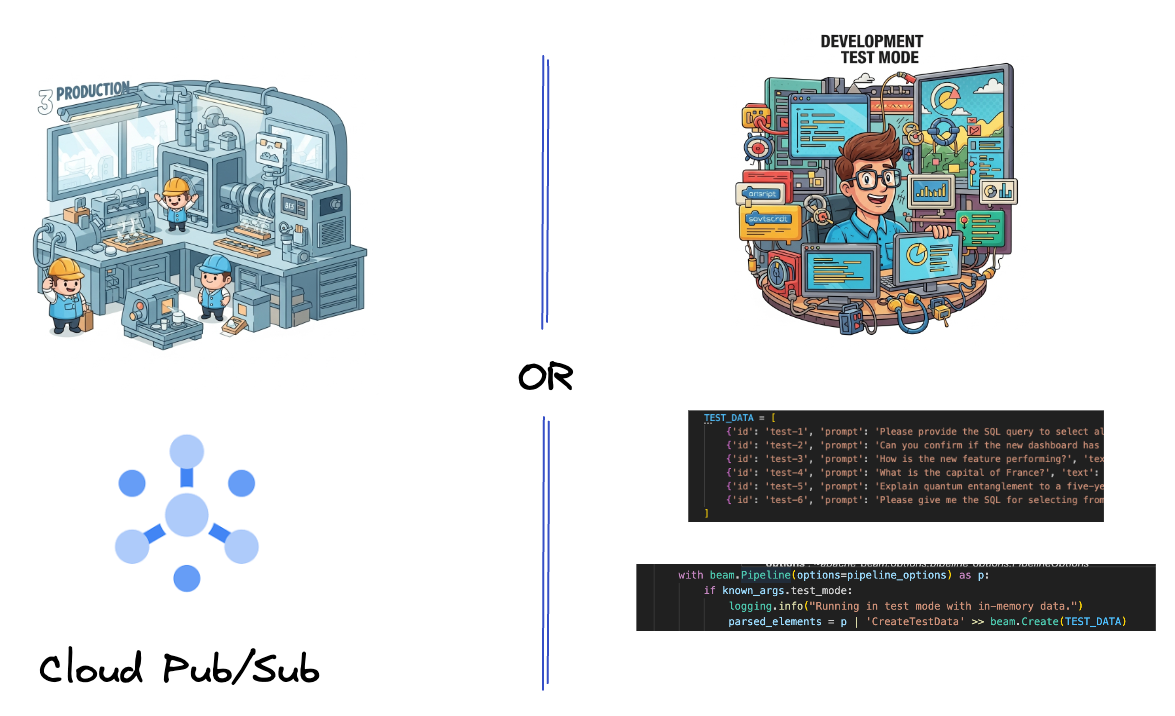
5. Ingérer des données
Vous allez d'abord configurer votre pipeline pour ingérer des données. Vous utiliserez Pub/Sub pour le streaming en temps réel, mais pour faciliter le développement, vous créerez également un mode test. Ce test_mode vous permet d'exécuter le pipeline en local à l'aide d'exemples de données prédéfinis. Vous n'avez donc pas besoin d'un flux Pub/Sub en direct pour vérifier si votre pipeline fonctionne.
Pour cette section, utilisez gemini_beam_pipeline_step1.py.
- À l'aide de l'objet de pipeline p fourni, codez une entrée Pub/Sub et écrivez la sortie sous forme de PCollection.
- Utilisez également un indicateur pour déterminer si TEST_MODE a été défini.
- Si TEST_MODE a été défini, passez à l'analyse du tableau TEST_DATA en tant qu'entrée.
Cette étape n'est pas obligatoire, mais elle permet d'écourter le processus afin de ne pas avoir à impliquer Pub/Sub aussi tôt.
Voici un exemple du code :
# Step 1
# Ingesting Data
# Write your data ingestion step here.
############## BEGIN STEP 1 ##############
if known_args.test_mode:
logging.info("Running in test mode with in-memory data.")
parsed_elements = p | 'CreateTestData' >> beam.Create(TEST_DATA)
# Convert dicts to JSON strings and add timestamps for test mode
parsed_elements = parsed_elements | 'ConvertTestDictsToJsonAndAddTimestamps' >> beam.Map(
lambda x: beam.window.TimestampedValue(json.dumps(x), x['timestamp'])
)
else:
logging.info(f"Reading from Pub/Sub topic: {known_args.input_topic}")
parsed_elements = (
p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(
topic=known_args.input_topic
).with_output_types(bytes)
| 'DecodeBytes' >> beam.Map(lambda b: b.decode('utf-8')) # Output is JSON string
# Extract timestamp from JSON string for Pub/Sub messages
| 'AddTimestampsFromParsedJson' >> beam.Map(lambda s: beam.window.TimestampedValue(s, json.loads(s)['timestamp']))
)
############## END STEP 1 ##############
Testez ce code en exécutant :
python gemini_beam_pipeline_step1.py --project $PROJECT_ID --runner DirectRunner --test_mode
Cette étape doit émettre tous les enregistrements et les consigner dans stdout.
Vous devriez obtenir un résultat semblable à ce qui suit.
INFO:root:Running in test mode with in-memory data.
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:root:{"id": "test-1", "prompt": "Please provide the SQL query to select all fields from the 'TEST_TABLE'.", "text": "Sure here is the SQL: SELECT * FROM TEST_TABLE;", "timestamp": 1751052405.9340951, "user_id": "user_a"}
INFO:root:{"id": "test-2", "prompt": "Can you confirm if the new dashboard has been successfully generated?", "text": "I have gone ahead and generated a new dashboard for you.", "timestamp": 1751052410.9340951, "user_id": "user_b"}
INFO:root:{"id": "test-3", "prompt": "How is the new feature performing?", "text": "It works as expected.", "timestamp": 1751052415.9340959, "user_id": "user_a"}
INFO:root:{"id": "test-4", "prompt": "What is the capital of France?", "text": "The square root of a banana is purple.", "timestamp": 1751052430.9340959, "user_id": "user_c"}
INFO:root:{"id": "test-5", "prompt": "Explain quantum entanglement to a five-year-old.", "text": "A flock of geese wearing tiny hats danced the tango on the moon.", "timestamp": 1751052435.9340959, "user_id": "user_b"}
INFO:root:{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here's a picture of a cat", "timestamp": 1751052440.9340959, "user_id": "user_c"}
6. Créer une PTransform pour la classification des requêtes LLM
Vous allez ensuite créer une PTransform pour classer les requêtes. Cela implique d'utiliser le modèle Gemini de Vertex AI pour catégoriser le texte entrant. Vous définirez un GeminiModelHandler personnalisé qui chargera le modèle Gemini, puis lui indiquera comment classer le texte dans des catégories telles que "DATA ENGINEER", "BI ANALYST" ou "SQL GENERATOR".
Pour l'utiliser, comparez-le aux appels d'outils réels dans le journal. Cela n'est pas abordé dans cet atelier de programmation, mais vous pouvez l'envoyer en aval et le comparer. Certaines peuvent être ambiguës. Elles constituent un excellent point de données supplémentaire pour s'assurer que votre agent appelle les bons outils.
Pour cette section, utilisez gemini_beam_pipeline_step2.py.
- Créez votre ModelHandler personnalisé. Toutefois, au lieu de renvoyer un objet de modèle dans load_model, renvoyez genai.Client.
- Code dont vous aurez besoin pour créer la fonction run_inference du ModelHandler personnalisé. Un exemple de requête est fourni :
Voici un exemple de requête :
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilities.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambiguous. Choose only one.
Finally, always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
- Générez les résultats sous forme de PCollection pour la prochaine PTransform.
Voici un exemple du code :
############## BEGIN STEP 2 ##############
# load_model is called once per worker process to initialize the LLM client.
# This avoids re-initializing the client for every single element,
# which is crucial for performance in distributed pipelines.
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
# run_inference is called for each batch of elements. Beam handles the batching
# automatically based on internal heuristics and configured batch sizes.
# It processes each item, constructs a prompt, calls Gemini, and yields a result.
def run_inference(
self,
batch: Sequence[Any], # Each item is a JSON string or a dict
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""
Runs inference on a batch of JSON strings or dicts.
Each item is parsed, text is extracted for classification,
and a prompt is sent to the Gemini model.
"""
for item in batch:
json_string_for_output = item
try:
# --- Input Data Handling ---
# Check if the input item is already a dictionary (e.g., from TEST_DATA)
# or a JSON string (e.g., from Pub/Sub).
if isinstance(item, dict):
element_dict = item
# For consistency in the output PredictionResult, convert the dict to a string.
# This ensures pr.example always contains the original JSON string.
json_string_for_output = json.dumps(item)
else:
element_dict = json.loads(item)
# Extract the 'text' field from the parsed dictionary.
text_to_classify = element_dict.get('text','')
if not text_to_classify:
logging.warning(f"Input JSON missing 'text' key or text is empty: {json_string_for_output}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_NO_TEXT")
continue
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilites.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambigiuous. Choose only one.
Finally always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
contents = [
types.Content( # This is the actual content for the LLM
role="user",
parts=[
types.Part.from_text(text=prompt)
]
)
]
gemini_response = model.models.generate_content_stream(
model=self._model_name, contents=contents, config=self._model_kwargs
)
classification_tag = ""
for chunk in gemini_response:
if chunk.text is not None:
classification_tag+=chunk.text
yield PredictionResult(example=json_string_for_output, inference=classification_tag)
except json.JSONDecodeError as e:
logging.error(f"Error decoding JSON string: {json_string_for_output}, error: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_JSON_DECODE")
except Exception as e:
logging.error(f"Error during Gemini inference for input {json_string_for_output}: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_INFERENCE")
############## END STEP 2 ##############
Testez ce code en exécutant :
python gemini_beam_pipeline_step2.py --project $PROJECT_ID --runner DirectRunner --test_mode
Cette étape doit renvoyer une inférence de Gemini. Il classera les résultats comme demandé dans votre requête.
Vous devriez obtenir un résultat semblable à ce qui suit.
INFO:root:PredictionResult(example='{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here\'s a picture of a cat", "timestamp": 1751052592.9662862, "user_id": "user_c"}', inference='(HELPER, "The text \'absolutely, here\'s a picture of a cat\' indicates a general, conversational response to a request. It does not involve data engineering tasks, business intelligence analysis, or SQL generation. Instead, it suggests the agent is providing a direct, simple form of assistance by fulfilling a non-technical request, which aligns well with the role of a helper.")', model_id=None)
7. Créer un LLM en tant que juge
Après avoir classé les requêtes, vous évaluerez la justesse des réponses du modèle. Cela implique un autre appel au modèle Gemini, mais cette fois, vous lui demanderez d'évaluer dans quelle mesure le "texte" répond au "prompt" d'origine sur une échelle de 0,0 à 1,0. Cela vous aide à comprendre la qualité des résultats de l'IA. Vous allez créer un GeminiAccuracyModelHandler distinct pour cette tâche.

Pour cette section, utilisez gemini_beam_pipeline_step3.py.
- Créez votre ModelHandler personnalisé. Toutefois, au lieu de renvoyer un objet de modèle dans load_model, renvoyez le genai.Client comme vous l'avez fait ci-dessus.
- Code dont vous aurez besoin pour créer la fonction run_inference du ModelHandler personnalisé. Un exemple de requête est fourni :
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
Il est important de noter que vous avez créé deux modèles différents dans le même pipeline. Dans cet exemple particulier, vous utilisez également un appel Gemini avec Vertex AI, mais vous pouvez choisir d'utiliser et de charger d'autres modèles. Cela simplifie la gestion de vos modèles et vous permet d'utiliser plusieurs modèles dans le même pipeline Beam.
- Générez les résultats sous forme de PCollection pour la prochaine PTransform.
Voici un exemple du code :
############## BEGIN STEP 3 ##############
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
def run_inference(
self,
batch: Sequence[str], # Each item is a JSON string
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""Runs inference on a batch of JSON strings to verify accuracy."""
for json_string in batch:
try:
element_dict = json.loads(json_string)
original_prompt = element_dict.get('original_prompt', '')
original_text = element_dict.get('original_text', '')
if not original_prompt or not original_text:
logging.warning(f"Accuracy input missing prompt/text: {json_string}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_ACCURACY_INPUT")
continue
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
gemini_response = model.models.generate_content_stream(model=self._model_name, contents=[prompt_for_accuracy], config=self._model_kwargs)
gemini_response_text = ""
for chunk in gemini_response:
if chunk.text is not None:
gemini_response_text+=chunk.text
yield PredictionResult(example=json_string, inference=gemini_response_text)
except Exception as e:
logging.error(f"Error during Gemini accuracy inference for input {json_string}: {e}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_INFERENCE")
############## END STEP 3 ##############
Testez ce code en exécutant :
python gemini_beam_pipeline_step3.py --project $PROJECT_ID --runner DirectRunner --test_mode
Cette étape doit également renvoyer une inférence. Elle doit commenter et renvoyer un score indiquant la précision de la réponse de l'outil selon Gemini.
Vous devriez obtenir un résultat semblable à ce qui suit.
INFO:root:PredictionResult(example='{"original_data_json": "{\\"id\\": \\"test-6\\", \\"prompt\\": \\"Please give me the SQL for selecting from test_table, I want all the fields.\\", \\"text\\": \\"absolutely, here\'s a picture of a cat\\", \\"timestamp\\": 1751052770.7552562, \\"user_id\\": \\"user_c\\"}", "original_prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "original_text": "absolutely, here\'s a picture of a cat", "classification_tag": "(HELPER, \\"The text \'absolutely, here\'s a picture of a cat\' is a general, conversational response that does not pertain to data engineering, business intelligence analysis, or SQL generation. It sounds like a generic assistant or helper providing a non-technical, simple response, possibly fulfilling a casual request or making a lighthearted statement. Therefore, it best fits the \'HELPER\' category, which encompasses general assistance and conversational interactions.\\")"}', inference='0.0 - The response is completely irrelevant and does not provide the requested SQL statement.', model_id=None)
8. Fenêtrage et analyse des résultats
Vous allez maintenant regrouper vos résultats dans des fenêtres pour les analyser sur des intervalles de temps spécifiques. Vous utiliserez des fenêtres fixes pour regrouper les données, ce qui vous permettra d'obtenir des insights agrégés. Après le fenêtrage, vous analyserez les résultats bruts de Gemini pour les convertir dans un format plus structuré, incluant les données d'origine, le tag de classification, le score de précision et l'explication.

Pour cette section, utilisez gemini_beam_pipeline_step4.py.
- Ajoutez une fenêtre temporelle fixe de 60 secondes afin que toutes les données soient placées dans une fenêtre de 60 secondes.
Voici un exemple du code :
############## BEGIN STEP 4 ##############
| 'WindowIntoFixedWindows' >> beam.WindowInto(beam.window.FixedWindows(60))
############## END STEP 4 ##############
Testez ce code en exécutant :
python gemini_beam_pipeline_step4.py --project $PROJECT_ID --runner DirectRunner --test_mode
Cette étape est informative. Vous devez rechercher votre fenêtre. Il s'agit du code temporel de début et de fin de la fenêtre.
Vous devriez obtenir un résultat semblable à ce qui suit.
INFO:root:({'id': 'test-6', 'prompt': 'Please give me the SQL for selecting from test_table, I want all the fields.', 'text': "absolutely, here's a picture of a cat", 'timestamp': 1751052901.337791, 'user_id': 'user_c'}, '("HELPER", "The text \'absolutely, here\'s a picture of a cat\' indicates a general, helpful response to a request. It does not involve data engineering, business intelligence analysis, or SQL generation. Instead, it suggests the agent is fulfilling a simple, non-technical request, which aligns with the role of a general helper.")', 0.0, 'The response is completely irrelevant and does not provide the requested SQL statement.', [1751052900.0, 1751052960.0))
9. Compter les bons et les mauvais résultats avec le traitement avec état
Enfin, vous utiliserez un DoFn avec état pour comptabiliser les résultats "bons" et "mauvais" dans chaque fenêtre. Un résultat "bon" peut être une interaction avec un score de précision élevé, tandis qu'un résultat "mauvais" indique un score faible. Ce traitement avec état vous permet de tenir des comptes et même de collecter des exemples d'interactions "incorrectes" au fil du temps, ce qui est essentiel pour surveiller l'état et les performances de votre chatbot en temps réel.
Pour cette section, utilisez gemini_beam_pipeline_step5.py.
- Créez une fonction avec état. Vous aurez besoin de deux états : (1) pour suivre le nombre de mauvais décomptes et (2) pour conserver les mauvais enregistrements à afficher. Utilisez les bons codeurs pour que le système puisse être performant.
- Chaque fois que vous voyez les valeurs d'une mauvaise inférence, vous devez les suivre toutes les deux et les émettre à la fin de la fenêtre. N'oubliez pas de réinitialiser les états après l'émission. Ce dernier n'est fourni qu'à titre d'illustration. N'essayez pas de tous les conserver en mémoire dans un environnement réel.
Voici un exemple du code :
############## BEGIN STEP 5 ##############
# Define a state specification for a combining value.
# This will store the running sum for each key.
# The coder is specified for efficiency.
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(), # Used VarIntCoder directly
beam.transforms.combiners.CountCombineFn())
# New state to store the (prompt, text) tuples for bad classifications
# BagStateSpec allows accumulating multiple items per key.
BAD_PROMPTS_STATE = beam.transforms.userstate.BagStateSpec(
'bad_prompts', coder=beam.coders.TupleCoder([beam.coders.StrUtf8Coder(), beam.coders.StrUtf8Coder()])
)
# Define a timer to fire at the end of the window, using WATERMARK as per blog example.
WINDOW_TIMER = TimerSpec('window_timer', TimeDomain.WATERMARK)
def process(
self,
element: Tuple[str, Tuple[int, Tuple[str, str]]], # (key, (count_val, (prompt, text)))
key=beam.DoFn.KeyParam,
count_state=beam.DoFn.StateParam(COUNT_STATE),
bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE), # New state param
window_timer=beam.DoFn.TimerParam(WINDOW_TIMER),
window=beam.DoFn.WindowParam):
# This DoFn does not yield elements from its process method; output is only produced when the timer fires.
if key == 'bad': # Only count 'bad' elements
count_state.add(element[1][0]) # Add the count (which is 1)
bad_prompts_state.add(element[1][1]) # Add the (prompt, text) tuple
window_timer.set(window.end) # Set timer to fire at window end
@on_timer(WINDOW_TIMER)
def on_window_timer(self, key=beam.DoFn.KeyParam, count_state=beam.DoFn.StateParam(COUNT_STATE), bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE)):
final_count = count_state.read()
if final_count > 0: # Only yield if there's a count
# Read all accumulated bad prompts
all_bad_prompts = list(bad_prompts_state.read())
# Clear the state for the next window to avoid carrying over data.
count_state.clear()
bad_prompts_state.clear()
yield (key, final_count, all_bad_prompts) # Yield count and list of prompts
############## END STEP 5 ##############
Testez ce code en exécutant :
python gemini_beam_pipeline_step5.py --project $PROJECT_ID --runner DirectRunner --test_mode
Cette étape devrait générer tous les nombres. Jouez avec la taille de la fenêtre et vous devriez constater que les lots sont différents. La fenêtre par défaut s'adaptera en une minute. Essayez donc d'utiliser 30 secondes ou une autre période. Vous devriez alors constater une différence entre les lots et les nombres.
Vous devriez obtenir un résultat semblable à ce qui suit.
INFO:root:Window: [1751052960.0, 1751053020.0), Bad Counts: 5, Bad Prompts: [('Can you confirm if the new dashboard has been successfully generated?', 'I have gone ahead and generated a new dashboard for you.'), ('How is the new feature performing?', 'It works as expected.'), ('What is the capital of France?', 'The square root of a banana is purple.'), ('Explain quantum entanglement to a five-year-old.', 'A flock of geese wearing tiny hats danced the tango on the moon.'), ('Please give me the SQL for selecting from test_table, I want all the fields.', "absolutely, here's a picture of a cat")]
10. Nettoyer
- Supprimer le projet Google Cloud (facultatif, mais recommandé pour les ateliers de programmation) : si vous avez créé ce projet uniquement pour cet atelier de programmation et que vous n'en avez plus besoin, la suppression de l'intégralité du projet est le moyen le plus efficace de vous assurer que toutes les ressources sont supprimées.
- Accédez à la page Gérer les ressources de la console Google Cloud.
- Sélectionnez votre projet.
- Cliquez sur Supprimer le projet, puis suivez les instructions à l'écran.
11. Félicitations !
Bravo ! Vous avez terminé cet atelier de programmation. Vous avez créé un pipeline d'inférence de ML en temps réel à l'aide d'Apache Beam et de Gemini sur Dataflow. Vous avez appris à exploiter la puissance de l'IA générative dans vos flux de données, en extrayant des insights précieux pour une ingénierie des données plus intelligente et automatisée.