
1. מבוא
בסביבת הנתונים המשתנה במהירות של ימינו, תובנות בזמן אמת הן חיוניות לקבלת החלטות מושכלות. בשיעור הזה תלמדו איך לפתח צינור עיבוד נתונים להערכה בזמן אמת. נתחיל בהיכרות עם Apache Beam framework, שמציעה מודל תכנות מאוחד לנתונים באצווה ולנתוני סטרימינג. המודל הזה מאפשר לפתח צינורות עיבוד נתונים בצורה פשוטה יותר, כי הוא מפשט את הלוגיקה המורכבת של מחשוב מבוזר שבדרך כלל צריך לבנות מאפס. אחרי שמגדירים את צינור הנתונים באמצעות Beam, אפשר להריץ אותו בצורה חלקה ב-Google Cloud Dataflow – שירות שמנוהל במלואו ומספק יכולות התאמה ייחודיות לעומס וביצועים לצורכי עיבוד נתונים.
ב-Codelab הזה תלמדו איך לתכנן צינור עיבוד נתונים ניתן להתאמה ב-Apache Beam שמיועד להסקת מסקנות של למידת מכונה, לפתח ModelHandler מותאם אישית כדי לשלב את מודל Gemini של Vertex AI, להשתמש בהנדסת הנחיות כדי לסווג טקסט חכם במקורות נתונים ולפרוס ולהפעיל את צינור עיבוד הנתונים הזה ב-Google Cloud Dataflow. בסיום הקורס תקבלו תובנות שיעזרו לכם ליישם למידת מכונה כדי להבין נתונים בזמן אמת ולבצע הערכה מתמשכת בתהליכי עבודה הנדסיים, ובמיוחד – כדי לתחזק AI איכותי בממשק שיחה שמתמקד במשתמש.
תרחיש
החברה שלכם יצרה סוכן נתונים. הסוכן, שנבנה באמצעות ערכה לפיתוח סוכנים (ADK), מצויד ביכולות ייחודיות שונות שיעזרו במשימות שקשורות לנתונים. אפשר לחשוב עליו כעוזר נתונים רב-תכליתי, שמוכן לטפל במגוון רחב של בקשות, החל מניתוח נתונים עסקיים כדי ליצור דוחות מעמיקים, דרך Data Engineer שיעזור לכם לפתח צינורות נתונים איכותיים, ועד למנוע ליצירת הצהרות SQL מדויקות ועוד הרבה יותר. כל אינטראקציה של הסוכן הזה, כל תגובה שהוא יוצר, מאוחסנת אוטומטית ב-Firestore. אבל למה אנחנו צריכים כאן צינור עיבוד נתונים?
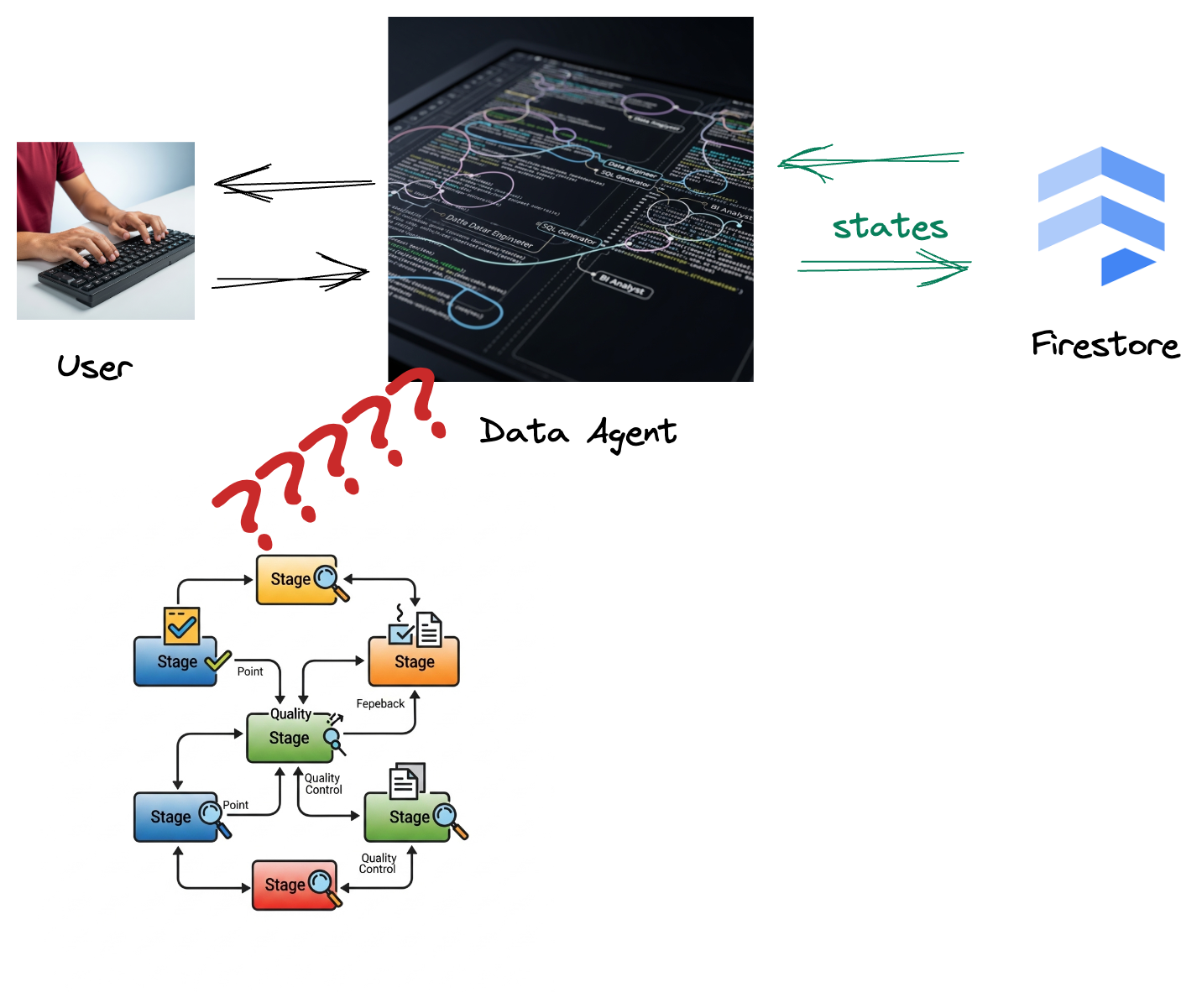
כי יש טריגר ב-Firestore ששולח בצורה חלקה את נתוני האינטראקציה האלה אל Pub/Sub, וכך אנחנו יכולים לעבד ולנתח באופן מיידי את השיחות החשובות האלה בזמן אמת.
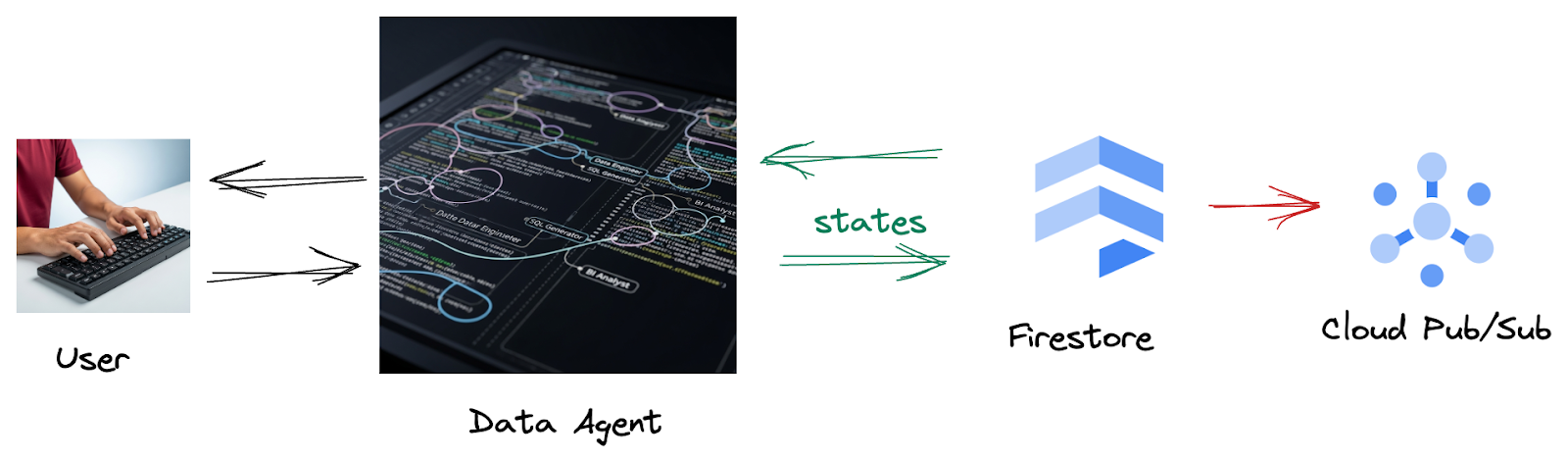
2. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
- לוחצים על הקישור כדי להפעיל את Cloud Shell. אפשר לעבור בין Cloud Shell Terminal (כדי להפעיל פקודות בענן) לבין Editor (כדי ליצור פרויקטים) בלחיצה על הכפתור המתאים ב-Cloud Shell.
- אחרי שמתחברים ל-Cloud Shell, בודקים שכבר בוצע אימות ושהפרויקט מוגדר למזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
- מפעילים את ממשקי ה-API הנדרשים באמצעות הפקודה שמוצגת למטה. זה יימשך כמה דקות, אז כדאי לחכות בסבלנות.
gcloud services enable \
dataflow.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- מוודאים שמותקנת גרסה Python 3.10 ומעלה
- מתקינים את Python Packages
בסביבת Cloud Shell, מתקינים את ספריות Python הנדרשות ל-Apache Beam, ל-Google Cloud Vertex AI ול-Google Generative AI.
pip install apache-beam[gcp] google-genai
- משכפלים את מאגר GitHub ועוברים לספריית ההדגמה.
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/beam_as_eval
אפשר לעיין במאמרי העזרה בנושא פקודות gcloud ושימוש בהן.
3. איך משתמשים במאגר GitHub שסופק
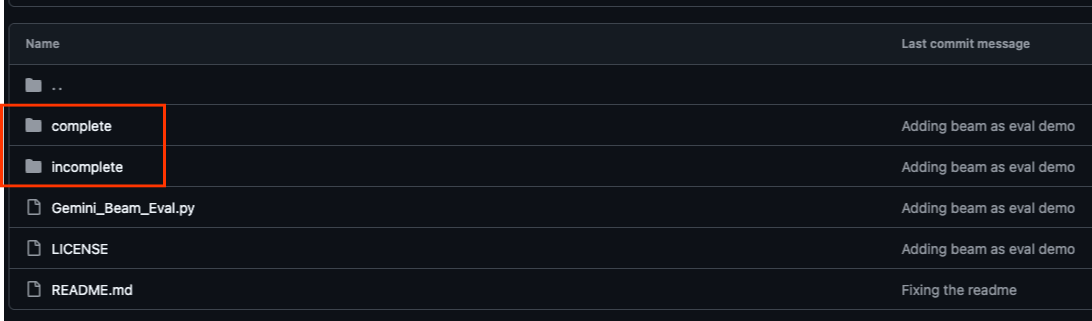
מאגר GitHub שמשויך ל-Codelab הזה נמצא בכתובת https://github.com/GoogleCloudPlatform/devrel-demos/tree/main/data-analytics/beam_as_eval ואמור לספק לכם חוויית למידה מודרכת. הוא מכיל שלד של קוד שתואם לכל חלק נפרד ב-Codelab, כדי להבטיח שתתקדמו בחומר בצורה הברורה ביותר.
במאגר יש שתי תיקיות ראשיות: complete ו-incomplete. בתיקייה complete תמצאו קוד שפועל במלואו לכל שלב, כך שתוכלו להריץ אותו ולראות את הפלט הרצוי. לעומת זאת, בתיקייה incomplete מופיע קוד מהשלבים הקודמים, וקטעים ספציפיים מסומנים בין ##### START STEP <NUMBER> ##### ל-##### END STEP <NUMBER> ##### כדי שתוכלו למלא אותם כחלק מהתרגילים. המבנה הזה מאפשר לכם להסתמך על ידע קודם וגם להשתתף באופן פעיל באתגרי התכנות.
4. סקירה כללית של הארכיטקטורה
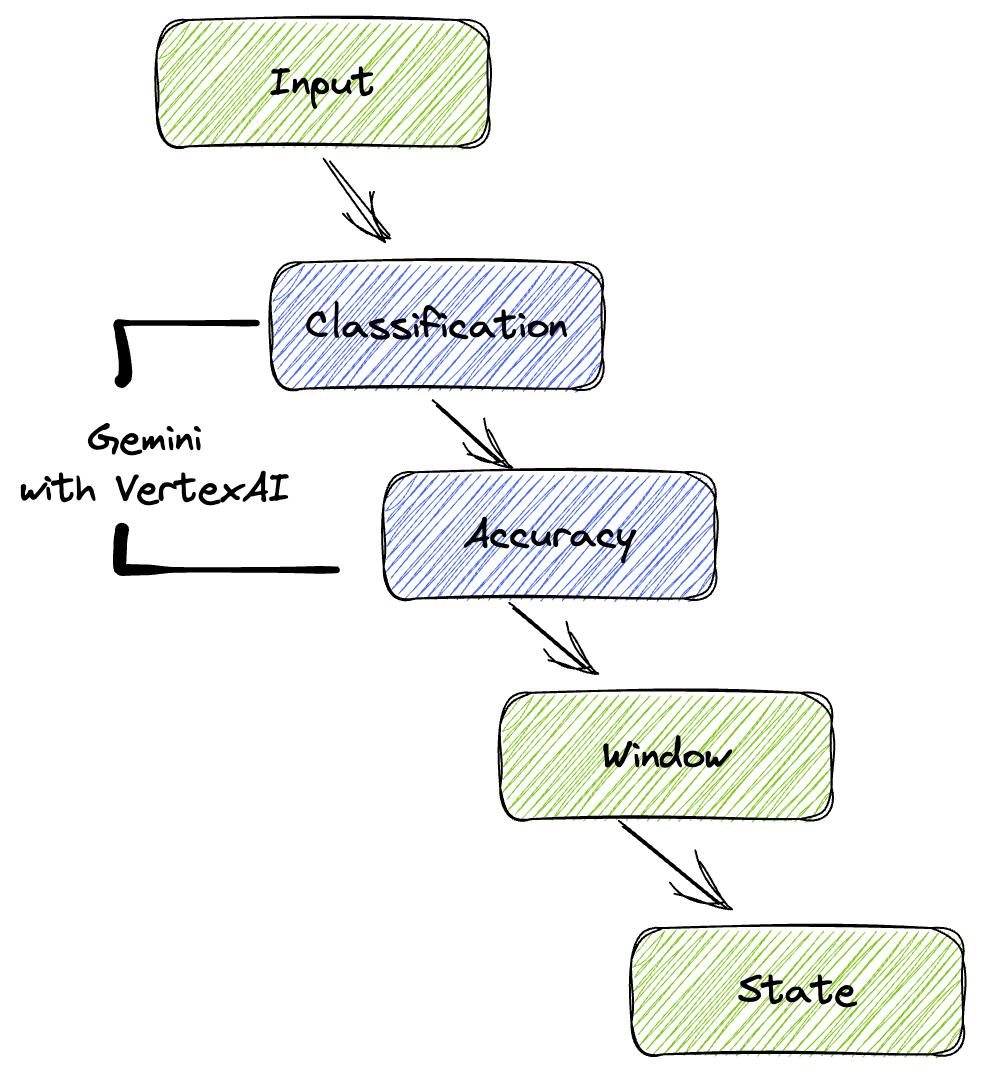
צינור עיבוד הנתונים שלנו מספק תבנית חזקה וניתנת להתאמה שמאפשרת לשלב יכולות הסקת מסקנות של למידת מכונה במקורות נתונים. ככה זה עובד:
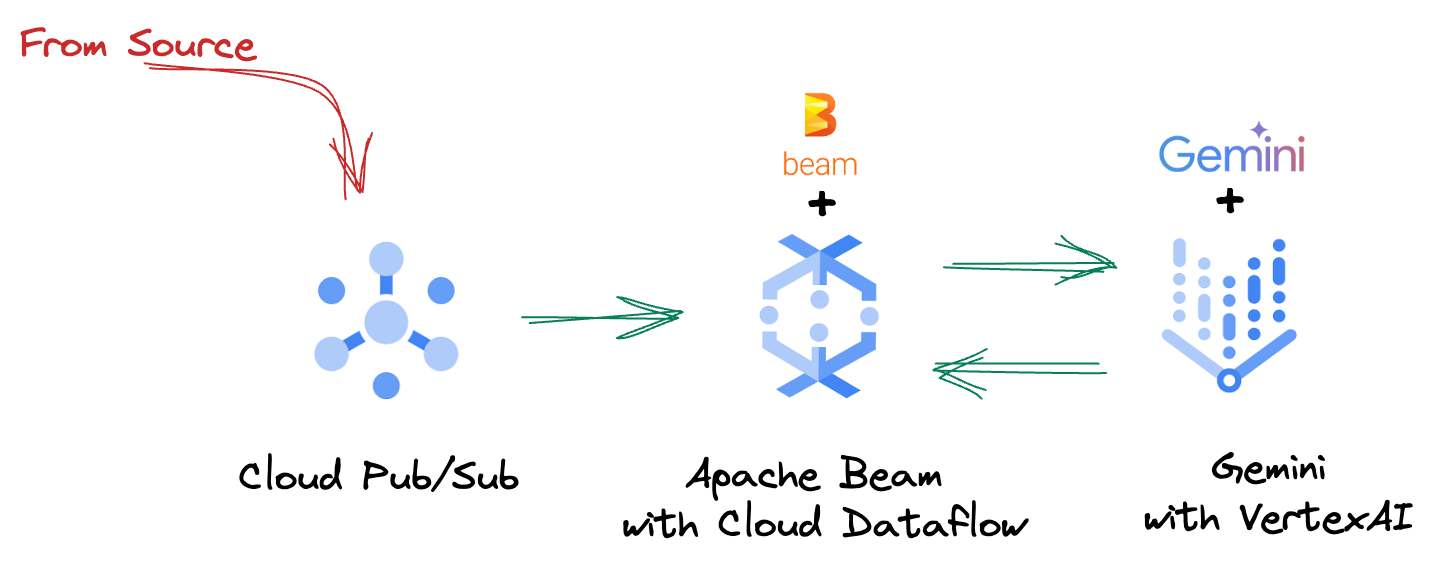
בצינור Beam כותבים קוד לכמה קלטים באופן מותנה, ואז טוענים מודלים בהתאמה אישית באמצעות טרנספורמציית RunInference מוכנה להפעלה. למרות שבדוגמה הזו משתמשים ב-Gemini עם VertexAI, היא ממחישה איך יוצרים כמה ModelHandler כדי להתאים למספר המודלים הרצוי. לבסוף, משתמשים ב-DoFn עם שמירת מצב כדי לעקוב אחרי אירועים ולשלוח אותם בצורה מבוקרת.
5. הטמעת נתונים
קודם כל, מגדירים את הצינור כך שיטמיע נתונים. משתמשים ב-Pub/Sub לסטרימינג בזמן אמת, אבל כדי להקל על הפיתוח, אפשר ליצור גם מצב בדיקה. עם מצב test_mode אפשר להריץ את צינור הנתונים באופן מקומי באמצעות נתונים לדוגמה שהוגדרו מראש, כך שלא צריך להשתמש בסטרים Pub/Sub בזמן אמת כדי לבדוק אם צינור עיבוד הנתונים פועל.
בקטע הזה נשתמש בקובץ gemini_beam_pipeline_step1.py.
- באמצעות אובייקט p בצינור עיבוד הנתונים שסופק, כותבים קוד לקלט Pub/Sub ומוציאים את הפלט כ-PCollection.
- אפשר גם להשתמש בסימון כדי לקבוע אם הוגדר מצב TEST_MODE.
- אם TEST_MODE הוגדר, מחליפים מצב כדי לנתח את המערך TEST_DATA כקלט.
זה לא הכרחי, אבל זה עוזר לקצר את התהליך כך שלא צריך לערב את Pub/Sub בשלב מוקדם כל כך.
הנה קוד לדוגמה:
# Step 1
# Ingesting Data
# Write your data ingestion step here.
############## BEGIN STEP 1 ##############
if known_args.test_mode:
logging.info("Running in test mode with in-memory data.")
parsed_elements = p | 'CreateTestData' >> beam.Create(TEST_DATA)
# Convert dicts to JSON strings and add timestamps for test mode
parsed_elements = parsed_elements | 'ConvertTestDictsToJsonAndAddTimestamps' >> beam.Map(
lambda x: beam.window.TimestampedValue(json.dumps(x), x['timestamp'])
)
else:
logging.info(f"Reading from Pub/Sub topic: {known_args.input_topic}")
parsed_elements = (
p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(
topic=known_args.input_topic
).with_output_types(bytes)
| 'DecodeBytes' >> beam.Map(lambda b: b.decode('utf-8')) # Output is JSON string
# Extract timestamp from JSON string for Pub/Sub messages
| 'AddTimestampsFromParsedJson' >> beam.Map(lambda s: beam.window.TimestampedValue(s, json.loads(s)['timestamp']))
)
############## END STEP 1 ##############
מריצים את הקוד הזה כדי לבדוק אותו:
python gemini_beam_pipeline_step1.py --project $PROJECT_ID --runner DirectRunner --test_mode
בשלב הזה, כל הרשומות אמורות להישלח ולהיכנס ליומן הרישום של stdout.
הפלט אמור להיראות כך:
INFO:root:Running in test mode with in-memory data.
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:root:{"id": "test-1", "prompt": "Please provide the SQL query to select all fields from the 'TEST_TABLE'.", "text": "Sure here is the SQL: SELECT * FROM TEST_TABLE;", "timestamp": 1751052405.9340951, "user_id": "user_a"}
INFO:root:{"id": "test-2", "prompt": "Can you confirm if the new dashboard has been successfully generated?", "text": "I have gone ahead and generated a new dashboard for you.", "timestamp": 1751052410.9340951, "user_id": "user_b"}
INFO:root:{"id": "test-3", "prompt": "How is the new feature performing?", "text": "It works as expected.", "timestamp": 1751052415.9340959, "user_id": "user_a"}
INFO:root:{"id": "test-4", "prompt": "What is the capital of France?", "text": "The square root of a banana is purple.", "timestamp": 1751052430.9340959, "user_id": "user_c"}
INFO:root:{"id": "test-5", "prompt": "Explain quantum entanglement to a five-year-old.", "text": "A flock of geese wearing tiny hats danced the tango on the moon.", "timestamp": 1751052435.9340959, "user_id": "user_b"}
INFO:root:{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here's a picture of a cat", "timestamp": 1751052440.9340959, "user_id": "user_c"}
6. פיתוח PTransform לסיווג הנחיות ל-LLM
בשלב הבא, בונים PTransform כדי לסווג הנחיות. לשם כך משתמשים במודל Gemini של Vertex AI כדי לסווג טקסט נכנס. מגדירים GeminiModelHandler מותאם אישית שטוען את מודל Gemini ואז נותן למודל הוראות לסיווג הטקסט לקטגוריות כמו "DATA ENGINEER", "BI ANALYST" או "SQL GENERATOR".
כדי להשתמש בסיווג הטקסט, צריך להשוות אותו לקריאות שהגיעו בפועל מהכלי ביומן. אנחנו לא נוגעים בנושא הזה ב-Codelab הנוכחי, אבל אתם יכולים לשלוח את הנתונים במורד הזרם ולהשוות אותם. יכול להיות שיהיו כמה סיווגים לא ברורים, והם ישמשו כנקודת נתונים נוספת שתעזור לכם לוודא שהסוכן שיצרתם קורא לכלים הנכונים.
בקטע הזה נשתמש בקובץ gemini_beam_pipeline_step2.py.
- יוצרים את ModelHandler המותאם אישית, אבל במקום להחזיר אובייקט של מודל ב-load_model, מחזירים את genai.Client.
- כותבים קוד שייצור את הפונקציה run_inference ל-ModelHandler מותאם אישית. הנה דוגמה להנחיה:
ההנחיה יכולה להיות משהו כזה:
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilities.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambiguous. Choose only one.
Finally, always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
- התוצאות מוחזרות כ-PCollection ל-PTransform הבא.
הנה קוד לדוגמה:
############## BEGIN STEP 2 ##############
# load_model is called once per worker process to initialize the LLM client.
# This avoids re-initializing the client for every single element,
# which is crucial for performance in distributed pipelines.
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
# run_inference is called for each batch of elements. Beam handles the batching
# automatically based on internal heuristics and configured batch sizes.
# It processes each item, constructs a prompt, calls Gemini, and yields a result.
def run_inference(
self,
batch: Sequence[Any], # Each item is a JSON string or a dict
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""
Runs inference on a batch of JSON strings or dicts.
Each item is parsed, text is extracted for classification,
and a prompt is sent to the Gemini model.
"""
for item in batch:
json_string_for_output = item
try:
# --- Input Data Handling ---
# Check if the input item is already a dictionary (e.g., from TEST_DATA)
# or a JSON string (e.g., from Pub/Sub).
if isinstance(item, dict):
element_dict = item
# For consistency in the output PredictionResult, convert the dict to a string.
# This ensures pr.example always contains the original JSON string.
json_string_for_output = json.dumps(item)
else:
element_dict = json.loads(item)
# Extract the 'text' field from the parsed dictionary.
text_to_classify = element_dict.get('text','')
if not text_to_classify:
logging.warning(f"Input JSON missing 'text' key or text is empty: {json_string_for_output}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_NO_TEXT")
continue
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilites.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambigiuous. Choose only one.
Finally always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
contents = [
types.Content( # This is the actual content for the LLM
role="user",
parts=[
types.Part.from_text(text=prompt)
]
)
]
gemini_response = model.models.generate_content_stream(
model=self._model_name, contents=contents, config=self._model_kwargs
)
classification_tag = ""
for chunk in gemini_response:
if chunk.text is not None:
classification_tag+=chunk.text
yield PredictionResult(example=json_string_for_output, inference=classification_tag)
except json.JSONDecodeError as e:
logging.error(f"Error decoding JSON string: {json_string_for_output}, error: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_JSON_DECODE")
except Exception as e:
logging.error(f"Error during Gemini inference for input {json_string_for_output}: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_INFERENCE")
############## END STEP 2 ##############
מריצים את הקוד הזה כדי לבדוק אותו:
python gemini_beam_pipeline_step2.py --project $PROJECT_ID --runner DirectRunner --test_mode
בשלב הזה Gemini אמור להחזיר לכם היקש ולסווג את התוצאות לפי ההנחיה שנתתם.
הפלט אמור להיראות כך:
INFO:root:PredictionResult(example='{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here\'s a picture of a cat", "timestamp": 1751052592.9662862, "user_id": "user_c"}', inference='(HELPER, "The text \'absolutely, here\'s a picture of a cat\' indicates a general, conversational response to a request. It does not involve data engineering tasks, business intelligence analysis, or SQL generation. Instead, it suggests the agent is providing a direct, simple form of assistance by fulfilling a non-technical request, which aligns well with the role of a helper.")', model_id=None)
7. פיתוח LLM-as-a-Judge
מסווגים את ההנחיות ואז מעריכים את רמת הדיוק של התשובות של המודל. במסגרת התהליך הזה נשלחת קריאה נוספת למודל Gemini, אבל הפעם מבקשים ממנו לתת ציון למידת ההתאמה של ה"טקסט" ל"הנחיה" המקורית, בסולם של 0.0 עד 1.0. זה מאפשר לכם להבין את איכות הפלט של ה-AI. תצטרכו ליצור GeminiAccuracyModelHandler נפרד למשימה הזו.

בקטע הזה נשתמש בקובץ gemini_beam_pipeline_step3.py.
- יוצרים את ModelHandler בהתאמה אישית, אבל במקום להחזיר אובייקט של מודל ב-load_model, מחזירים את genai.Client כמו בדוגמה שלמעלה.
- כותבים קוד שייצור את הפונקציה run_inference ל-ModelHandler מותאם אישית. הנה דוגמה להנחיה:
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
שימו לב שבדוגמה הזו יצרתם למעשה שני מודלים שונים באותו צינור. בדוגמה הזו נשתמש גם בקריאה ל-Gemini עם VertexAI, אבל באותו אופן אפשר לבחור ולטעון מודלים אחרים. זה מפשט את ניהול המודלים ומאפשר לכם להשתמש בכמה מודלים באותו צינור Beam.
- התוצאות מוחזרות כ-PCollection ל-PTransform הבא.
הנה קוד לדוגמה:
############## BEGIN STEP 3 ##############
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
def run_inference(
self,
batch: Sequence[str], # Each item is a JSON string
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""Runs inference on a batch of JSON strings to verify accuracy."""
for json_string in batch:
try:
element_dict = json.loads(json_string)
original_prompt = element_dict.get('original_prompt', '')
original_text = element_dict.get('original_text', '')
if not original_prompt or not original_text:
logging.warning(f"Accuracy input missing prompt/text: {json_string}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_ACCURACY_INPUT")
continue
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
gemini_response = model.models.generate_content_stream(model=self._model_name, contents=[prompt_for_accuracy], config=self._model_kwargs)
gemini_response_text = ""
for chunk in gemini_response:
if chunk.text is not None:
gemini_response_text+=chunk.text
yield PredictionResult(example=json_string, inference=gemini_response_text)
except Exception as e:
logging.error(f"Error during Gemini accuracy inference for input {json_string}: {e}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_INFERENCE")
############## END STEP 3 ##############
מריצים את הקוד הזה כדי לבדוק אותו:
python gemini_beam_pipeline_step3.py --project $PROJECT_ID --runner DirectRunner --test_mode
בשלב הזה אמורים להתקבל גם היקש, הערה וציון לגבי רמת הדיוק של התשובה ש-Gemini חושב שהכלי סיפק.
הפלט אמור להיראות כך:
INFO:root:PredictionResult(example='{"original_data_json": "{\\"id\\": \\"test-6\\", \\"prompt\\": \\"Please give me the SQL for selecting from test_table, I want all the fields.\\", \\"text\\": \\"absolutely, here\'s a picture of a cat\\", \\"timestamp\\": 1751052770.7552562, \\"user_id\\": \\"user_c\\"}", "original_prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "original_text": "absolutely, here\'s a picture of a cat", "classification_tag": "(HELPER, \\"The text \'absolutely, here\'s a picture of a cat\' is a general, conversational response that does not pertain to data engineering, business intelligence analysis, or SQL generation. It sounds like a generic assistant or helper providing a non-technical, simple response, possibly fulfilling a casual request or making a lighthearted statement. Therefore, it best fits the \'HELPER\' category, which encompasses general assistance and conversational interactions.\\")"}', inference='0.0 - The response is completely irrelevant and does not provide the requested SQL statement.', model_id=None)
8. הצגה וניתוח של התוצאות בחלונות
מציגים את התוצאות בחלונות כדי לנתח אותן במרווחי זמן ספציפיים. השתמשו בחלונות קבועים כדי לקבץ נתונים ולקבל תובנות מצטברות. אחרי ההצגה בחלונות, מחלקים את התוצאות הגולמיות מ-Gemini לפורמט מובנה יותר, כולל הנתונים המקוריים, תג הסיווג, ציון מידת הדיוק וההסבר.

בקטע הזה נשתמש בקובץ gemini_beam_pipeline_step4.py.
- מוסיפים חלון זמן קבוע של 60 שניות כדי שכל הנתונים ימוקמו בתוכו.
הנה קוד לדוגמה:
############## BEGIN STEP 4 ##############
| 'WindowIntoFixedWindows' >> beam.WindowInto(beam.window.FixedWindows(60))
############## END STEP 4 ##############
מריצים את הקוד הזה כדי לבדוק אותו:
python gemini_beam_pipeline_step4.py --project $PROJECT_ID --runner DirectRunner --test_mode
השלב הזה הוא אינפורמטיבי בלבד. אתם צריכים למצוא את החלון שלכם. הוא יופיע בתור חלון עם חותמת זמן של עצירה או התחלה.
הפלט אמור להיראות כך:
INFO:root:({'id': 'test-6', 'prompt': 'Please give me the SQL for selecting from test_table, I want all the fields.', 'text': "absolutely, here's a picture of a cat", 'timestamp': 1751052901.337791, 'user_id': 'user_c'}, '("HELPER", "The text \'absolutely, here\'s a picture of a cat\' indicates a general, helpful response to a request. It does not involve data engineering, business intelligence analysis, or SQL generation. Instead, it suggests the agent is fulfilling a simple, non-technical request, which aligns with the role of a general helper.")', 0.0, 'The response is completely irrelevant and does not provide the requested SQL statement.', [1751052900.0, 1751052960.0))
9. ספירת תוצאות טובות וגרועות בעיבוד עם שמירת מצב
לבסוף, משתמשים ב-DoFn עם שמירת מצב כדי לספור את התוצאות ה"טובות" וה"גרועות" בכל חלון. תוצאה "טובה" יכולה להיות אינטראקציה עם ציון דיוק גבוה, ואילו תוצאה "גרועה" מצביעה על ציון נמוך. עיבוד עם שמירת מצב מאפשר לכם לתעד את המספרים ואפילו לאסוף דוגמאות של אינטראקציות "גרועות" לאורך זמן – דבר חיוני למעקב אחרי תקינות הצ'אטבוט והביצועים שלו בזמן אמת.
בקטע הזה נשתמש בקובץ gemini_beam_pipeline_step5.py.
- יוצרים פונקציה עם שמירת מצב. צריך לשמור שני מצבים: (1) כדי לעקוב אחרי מספר התוצאות הגרועות ו-(2) כדי לשמור את הרשומות הגרועות שהוצגו. כדי לוודא שהמערכת תפעל בצורה יעילה, צריך להשתמש במקודדים מתאימים.
- בכל פעם שרואים את הערכים של היקש גרוע, כדאי לעקוב אחרי שתי הפונקציות ולשלוח אותן בסוף חלון הזמן. חשוב לזכור לאפס את המצבים אחרי השליחה. האפשרות השנייה נועדה להמחשה בלבד. אל תנסו לשמור את כל הנתונים האלה בזיכרון בסביבה אמיתית.
הנה קוד לדוגמה:
############## BEGIN STEP 5 ##############
# Define a state specification for a combining value.
# This will store the running sum for each key.
# The coder is specified for efficiency.
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(), # Used VarIntCoder directly
beam.transforms.combiners.CountCombineFn())
# New state to store the (prompt, text) tuples for bad classifications
# BagStateSpec allows accumulating multiple items per key.
BAD_PROMPTS_STATE = beam.transforms.userstate.BagStateSpec(
'bad_prompts', coder=beam.coders.TupleCoder([beam.coders.StrUtf8Coder(), beam.coders.StrUtf8Coder()])
)
# Define a timer to fire at the end of the window, using WATERMARK as per blog example.
WINDOW_TIMER = TimerSpec('window_timer', TimeDomain.WATERMARK)
def process(
self,
element: Tuple[str, Tuple[int, Tuple[str, str]]], # (key, (count_val, (prompt, text)))
key=beam.DoFn.KeyParam,
count_state=beam.DoFn.StateParam(COUNT_STATE),
bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE), # New state param
window_timer=beam.DoFn.TimerParam(WINDOW_TIMER),
window=beam.DoFn.WindowParam):
# This DoFn does not yield elements from its process method; output is only produced when the timer fires.
if key == 'bad': # Only count 'bad' elements
count_state.add(element[1][0]) # Add the count (which is 1)
bad_prompts_state.add(element[1][1]) # Add the (prompt, text) tuple
window_timer.set(window.end) # Set timer to fire at window end
@on_timer(WINDOW_TIMER)
def on_window_timer(self, key=beam.DoFn.KeyParam, count_state=beam.DoFn.StateParam(COUNT_STATE), bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE)):
final_count = count_state.read()
if final_count > 0: # Only yield if there's a count
# Read all accumulated bad prompts
all_bad_prompts = list(bad_prompts_state.read())
# Clear the state for the next window to avoid carrying over data.
count_state.clear()
bad_prompts_state.clear()
yield (key, final_count, all_bad_prompts) # Yield count and list of prompts
############## END STEP 5 ##############
מריצים את הקוד הזה כדי לבדוק אותו:
python gemini_beam_pipeline_step5.py --project $PROJECT_ID --runner DirectRunner --test_mode
בשלב הזה אמורים להתקבל כל המספרים. חלון ברירת המחדל מוגדר לדקה אחת. אתם יכולים לשחק עם גודל החלון – להגדיר אותו ל-30 שניות או פרק זמן אחר – ולראות שהקבוצות והספירות שונות.
הפלט אמור להיראות כך:
INFO:root:Window: [1751052960.0, 1751053020.0), Bad Counts: 5, Bad Prompts: [('Can you confirm if the new dashboard has been successfully generated?', 'I have gone ahead and generated a new dashboard for you.'), ('How is the new feature performing?', 'It works as expected.'), ('What is the capital of France?', 'The square root of a banana is purple.'), ('Explain quantum entanglement to a five-year-old.', 'A flock of geese wearing tiny hats danced the tango on the moon.'), ('Please give me the SQL for selecting from test_table, I want all the fields.', "absolutely, here's a picture of a cat")]
10. סידור וארגון
- מוחקים את הפרויקט ב-Google Cloud (אופציונלי, אבל מומלץ ל-Codelabs): אם הפרויקט הזה נוצר רק בשביל ה-Codelab הזה ואתם לא צריכים אותו יותר, מחיקת הפרויקט כולו היא הדרך היסודית ביותר לוודא שכל המשאבים יוסרו.
- נכנסים אל הדף Manage Resources במסוף Google Cloud.
- בוחרים את הפרויקט הרצוי.
- לוחצים על Delete Project ופועלים לפי ההוראות במסך.
11. מזל טוב!
כל הכבוד, סיימתם את ה-Codelab! יצרתם בהצלחה צינור עיבוד נתונים של למידת מכונה בזמן אמת באמצעות Apache Beam ו-Gemini ב-Dataflow. למדתם איך להשתמש ב-AI גנרטיבי כדי להפיק תובנות חשובות ממקורות הנתונים, וכך להפוך את הנדסת הנתונים לחכמה יותר ולאוטומטית יותר.