
1. Introduzione
Nel panorama dei dati odierno in rapido cambiamento, gli insight in tempo reale sono fondamentali per prendere decisioni consapevoli. Questo codelab ti guiderà nella creazione di una pipeline di valutazione in tempo reale. Inizieremo utilizzando il framework Apache Beam, che offre un modello di programmazione unificato sia per i dati in batch che per quelli in streaming. Ciò semplifica notevolmente lo sviluppo della pipeline, in quanto astrae la complessa logica di calcolo distribuito che altrimenti dovresti creare da zero. Una volta definita la pipeline utilizzando Beam, potrai eseguirla senza problemi su Google Cloud Dataflow, un servizio completamente gestito che offre scalabilità e prestazioni senza pari per le tue esigenze di elaborazione dei dati.
In questo codelab imparerai a progettare una pipeline Apache Beam scalabile per l'inferenza di machine learning, a sviluppare un ModelHandler personalizzato per integrare il modello Gemini di Vertex AI, a sfruttare l'ingegneria dei prompt per la classificazione intelligente del testo nei flussi di dati e a eseguire il deployment e il funzionamento di questa pipeline di inferenza ML di streaming su Google Cloud Dataflow. Alla fine, otterrai informazioni preziose sull'applicazione del machine learning per la comprensione dei dati in tempo reale e la valutazione continua nei flussi di lavoro di ingegneria, in particolare per mantenere un'AI conversazionale solida e incentrata sull'utente.
Scenario
La tua azienda ha creato un agente di dati. L'agente di dati, creato con Agent Development Kit (ADK), è dotato di varie funzionalità specializzate per assistere nelle attività relative ai dati. Immagina che sia un assistente dati versatile, pronto a gestire diverse richieste, dall'agire come analista BI per generare report approfonditi a un data engineer che ti aiuta a creare pipeline di dati robuste o a un generatore SQL che crea istruzioni SQL precise e molto altro ancora. Ogni interazione di questo agente, ogni risposta che genera, viene archiviata automaticamente in Firestore. Perché abbiamo bisogno di una pipeline qui?
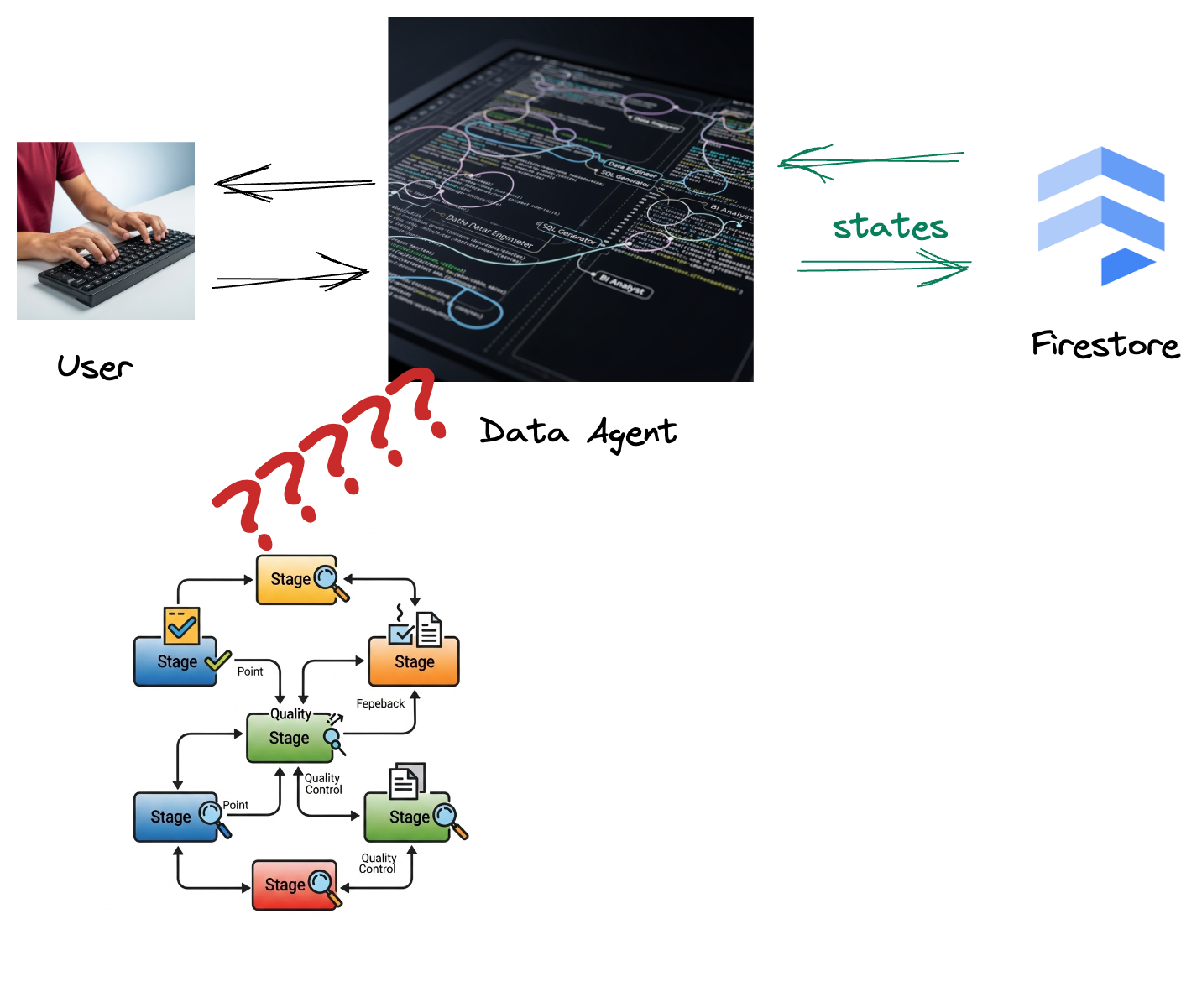
Da Firestore, un trigger invia senza problemi questi dati di interazione a Pub/Sub, garantendo che possiamo elaborare e analizzare immediatamente queste conversazioni critiche in tempo reale.
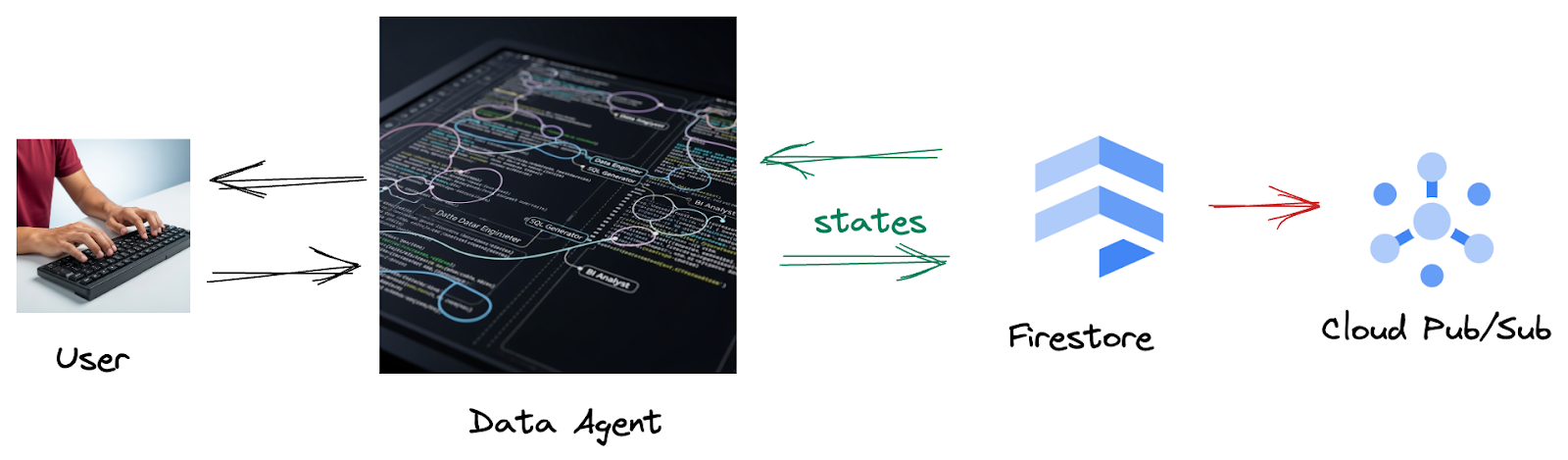
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
- Attiva Cloud Shell facendo clic su questo link. Puoi passare dal terminale Cloud Shell (per eseguire comandi cloud) all'editor (per creare progetti) facendo clic sul pulsante corrispondente in Cloud Shell.
- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
- Abilita le API richieste tramite il comando mostrato di seguito. L'operazione potrebbe richiedere alcuni minuti.
gcloud services enable \
dataflow.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Assicurati di avere Python 3.10 o versioni successive
- Installa pacchetti Python
Installa le librerie Python richieste per Apache Beam, Google Cloud Vertex AI e Google Generative AI nel tuo ambiente Cloud Shell.
pip install apache-beam[gcp] google-genai
- Clona il repository GitHub e passa alla directory demo.
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/beam_as_eval
Consulta la documentazione per i comandi e l'utilizzo di gcloud.
3. Come utilizzare il repository GitHub fornito
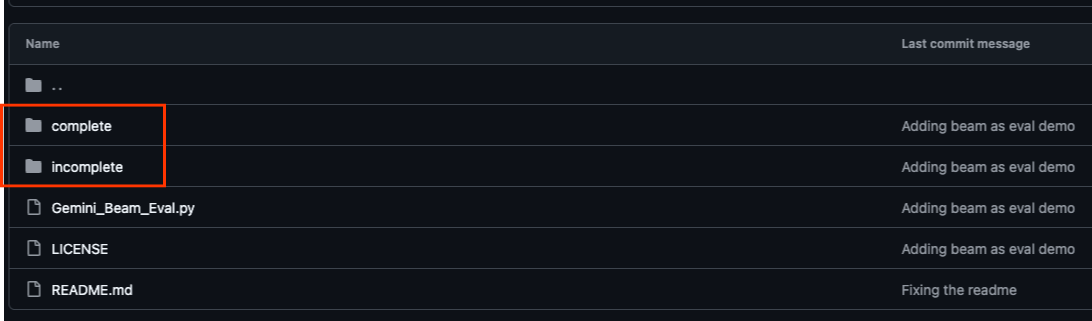
Il repository GitHub associato a questo codelab, disponibile all'indirizzo https://github.com/GoogleCloudPlatform/devrel-demos/tree/main/data-analytics/beam_as_eval , è organizzato per facilitare un'esperienza di apprendimento guidata. Contiene il codice di base che corrisponde a ogni parte distinta del codelab, garantendo una progressione chiara attraverso il materiale.
All'interno del repository, troverai due cartelle principali: "complete" e "incomplete". La cartella "complete" contiene il codice completamente funzionante per ogni passaggio, consentendoti di eseguire e osservare l'output previsto. Al contrario, la cartella "incomplete" fornisce il codice dei passaggi precedenti, lasciando sezioni specifiche contrassegnate tra ##### START STEP <NUMBER> ##### e ##### END STEP <NUMBER> ##### da completare nell'ambito degli esercizi. Questa struttura ti consente di basarti sulle conoscenze precedenti mentre partecipi attivamente alle sfide di programmazione.
4. Panoramica dell'architettura
La nostra pipeline fornisce un pattern potente e scalabile per l'integrazione dell'inferenza ML nei flussi di dati. Ecco come si combinano i vari elementi:
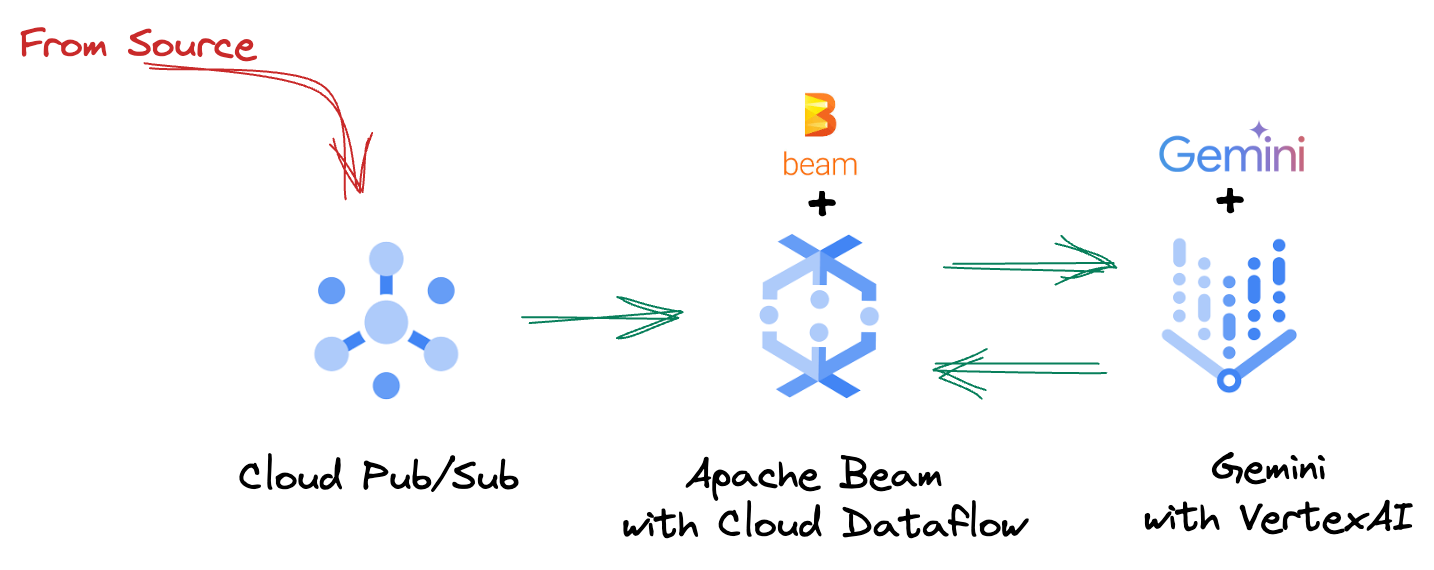
Nella pipeline Beam, codificherai più input in modo condizionale, quindi caricherai i modelli personalizzati con la trasformazione chiavi in mano RunInference. Anche se nell'esempio utilizzi Gemini con Vertex AI, viene mostrato come creare più ModelHandler per adattarsi al numero di modelli che hai. Infine, utilizzerai una DoFn stateful per tenere traccia degli eventi ed emetterli in modo controllato.
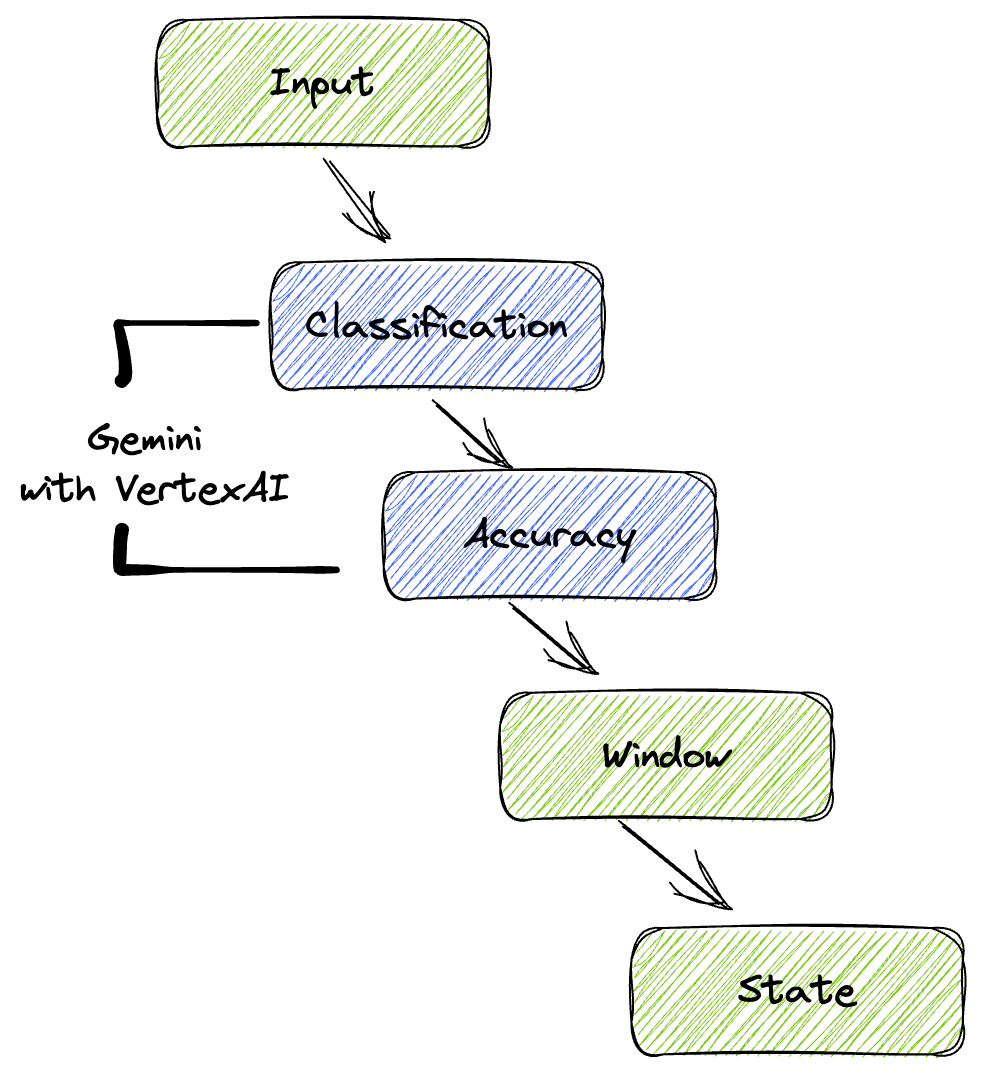
5. Importazione dei dati
Innanzitutto, configurerai la pipeline per l'importazione dei dati. Utilizzerai Pub/Sub per lo streaming in tempo reale, ma per semplificare lo sviluppo creerai anche una modalità di test. Questo test_mode ti consente di eseguire la pipeline localmente utilizzando dati di esempio predefiniti, in modo da non aver bisogno di un flusso Pub/Sub attivo per verificare se la pipeline funziona.
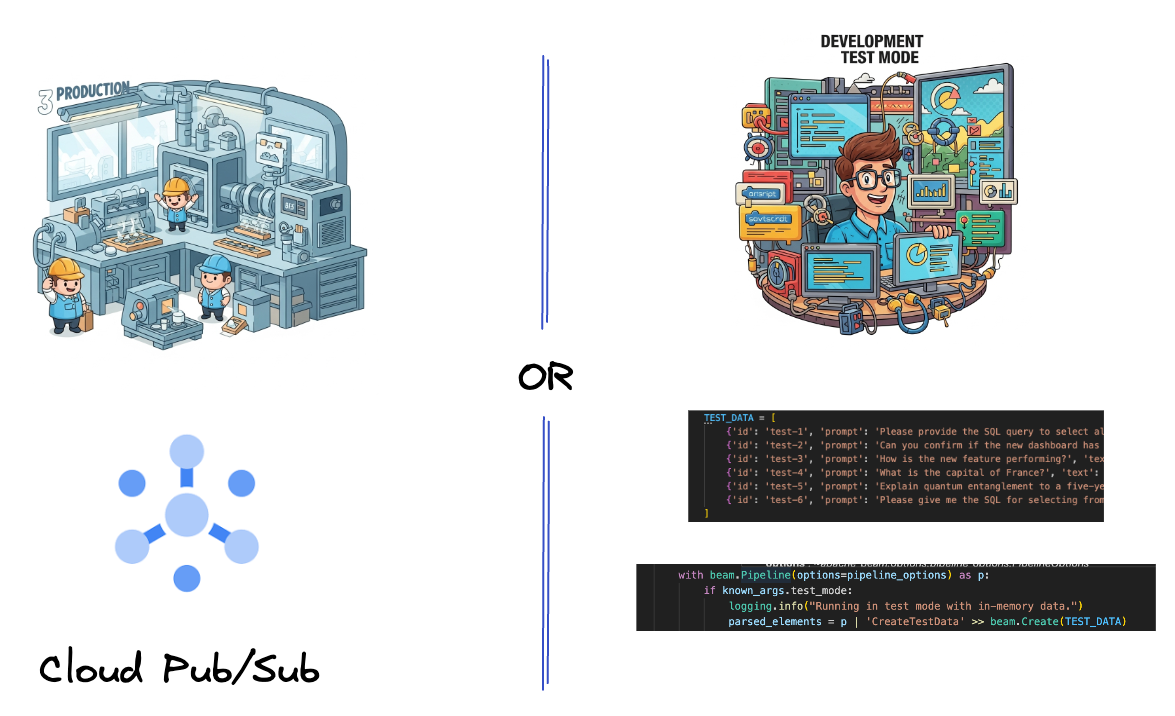
Per questa sezione, utilizza gemini_beam_pipeline_step1.py.
- Utilizzando l'oggetto pipeline fornito p, codifica un input Pub/Sub e scrivi l'output come PCollection.
- Inoltre, utilizza un flag per determinare se è stata impostata la modalità TEST_MODE.
- Se è stato impostato TEST_MODE, passa all'analisi dell'array TEST_DATA come input.
Non è necessario, ma aiuta ad abbreviare la procedura, in modo da non dover coinvolgere Pub/Sub in questa fase iniziale.
Ecco un esempio del codice riportato di seguito:
# Step 1
# Ingesting Data
# Write your data ingestion step here.
############## BEGIN STEP 1 ##############
if known_args.test_mode:
logging.info("Running in test mode with in-memory data.")
parsed_elements = p | 'CreateTestData' >> beam.Create(TEST_DATA)
# Convert dicts to JSON strings and add timestamps for test mode
parsed_elements = parsed_elements | 'ConvertTestDictsToJsonAndAddTimestamps' >> beam.Map(
lambda x: beam.window.TimestampedValue(json.dumps(x), x['timestamp'])
)
else:
logging.info(f"Reading from Pub/Sub topic: {known_args.input_topic}")
parsed_elements = (
p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(
topic=known_args.input_topic
).with_output_types(bytes)
| 'DecodeBytes' >> beam.Map(lambda b: b.decode('utf-8')) # Output is JSON string
# Extract timestamp from JSON string for Pub/Sub messages
| 'AddTimestampsFromParsedJson' >> beam.Map(lambda s: beam.window.TimestampedValue(s, json.loads(s)['timestamp']))
)
############## END STEP 1 ##############
Prova questo codice eseguendo:
python gemini_beam_pipeline_step1.py --project $PROJECT_ID --runner DirectRunner --test_mode
Questo passaggio deve emettere tutti i record, registrandoli in stdout.
Dovresti aspettarti un output simile al seguente.
INFO:root:Running in test mode with in-memory data.
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:root:{"id": "test-1", "prompt": "Please provide the SQL query to select all fields from the 'TEST_TABLE'.", "text": "Sure here is the SQL: SELECT * FROM TEST_TABLE;", "timestamp": 1751052405.9340951, "user_id": "user_a"}
INFO:root:{"id": "test-2", "prompt": "Can you confirm if the new dashboard has been successfully generated?", "text": "I have gone ahead and generated a new dashboard for you.", "timestamp": 1751052410.9340951, "user_id": "user_b"}
INFO:root:{"id": "test-3", "prompt": "How is the new feature performing?", "text": "It works as expected.", "timestamp": 1751052415.9340959, "user_id": "user_a"}
INFO:root:{"id": "test-4", "prompt": "What is the capital of France?", "text": "The square root of a banana is purple.", "timestamp": 1751052430.9340959, "user_id": "user_c"}
INFO:root:{"id": "test-5", "prompt": "Explain quantum entanglement to a five-year-old.", "text": "A flock of geese wearing tiny hats danced the tango on the moon.", "timestamp": 1751052435.9340959, "user_id": "user_b"}
INFO:root:{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here's a picture of a cat", "timestamp": 1751052440.9340959, "user_id": "user_c"}
6. Creazione di una PTransform per la classificazione dei prompt LLM
Successivamente, creerai una PTransform per classificare i prompt. Ciò comporta l'utilizzo del modello Gemini di Vertex AI per classificare il testo in entrata. Definirai un GeminiModelHandler personalizzato che carica il modello Gemini e poi gli indica come classificare il testo in categorie come "DATA ENGINEER", "BI ANALYST" o "SQL GENERATOR".
Per utilizzarlo, confrontalo con le chiamate effettive agli strumenti nel log. Questo aspetto non è trattato in questo codelab, ma potresti inviarlo a valle e confrontarlo. Alcuni potrebbero essere ambigui e questo serve come ottimo punto dati aggiuntivo per garantire che l'agente chiami gli strumenti giusti.
Per questa sezione, utilizza gemini_beam_pipeline_step2.py.
- Crea il tuo ModelHandler personalizzato, ma anziché restituire un oggetto modello in load_model, restituisci genai.Client.
- Codice necessario per creare la funzione run_inference del ModelHandler personalizzato. È stato fornito un prompt di esempio:
Il prompt può essere il seguente:
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilities.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambiguous. Choose only one.
Finally, always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
- Restituisci i risultati come PCollection per la successiva pTransform.
Ecco un esempio del codice riportato di seguito:
############## BEGIN STEP 2 ##############
# load_model is called once per worker process to initialize the LLM client.
# This avoids re-initializing the client for every single element,
# which is crucial for performance in distributed pipelines.
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
# run_inference is called for each batch of elements. Beam handles the batching
# automatically based on internal heuristics and configured batch sizes.
# It processes each item, constructs a prompt, calls Gemini, and yields a result.
def run_inference(
self,
batch: Sequence[Any], # Each item is a JSON string or a dict
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""
Runs inference on a batch of JSON strings or dicts.
Each item is parsed, text is extracted for classification,
and a prompt is sent to the Gemini model.
"""
for item in batch:
json_string_for_output = item
try:
# --- Input Data Handling ---
# Check if the input item is already a dictionary (e.g., from TEST_DATA)
# or a JSON string (e.g., from Pub/Sub).
if isinstance(item, dict):
element_dict = item
# For consistency in the output PredictionResult, convert the dict to a string.
# This ensures pr.example always contains the original JSON string.
json_string_for_output = json.dumps(item)
else:
element_dict = json.loads(item)
# Extract the 'text' field from the parsed dictionary.
text_to_classify = element_dict.get('text','')
if not text_to_classify:
logging.warning(f"Input JSON missing 'text' key or text is empty: {json_string_for_output}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_NO_TEXT")
continue
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilites.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambigiuous. Choose only one.
Finally always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
contents = [
types.Content( # This is the actual content for the LLM
role="user",
parts=[
types.Part.from_text(text=prompt)
]
)
]
gemini_response = model.models.generate_content_stream(
model=self._model_name, contents=contents, config=self._model_kwargs
)
classification_tag = ""
for chunk in gemini_response:
if chunk.text is not None:
classification_tag+=chunk.text
yield PredictionResult(example=json_string_for_output, inference=classification_tag)
except json.JSONDecodeError as e:
logging.error(f"Error decoding JSON string: {json_string_for_output}, error: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_JSON_DECODE")
except Exception as e:
logging.error(f"Error during Gemini inference for input {json_string_for_output}: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_INFERENCE")
############## END STEP 2 ##############
Prova questo codice eseguendo:
python gemini_beam_pipeline_step2.py --project $PROJECT_ID --runner DirectRunner --test_mode
Questo passaggio dovrebbe restituire un'inferenza da Gemini. Classificherà i risultati come richiesto dal prompt.
Dovresti aspettarti un output simile al seguente.
INFO:root:PredictionResult(example='{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here\'s a picture of a cat", "timestamp": 1751052592.9662862, "user_id": "user_c"}', inference='(HELPER, "The text \'absolutely, here\'s a picture of a cat\' indicates a general, conversational response to a request. It does not involve data engineering tasks, business intelligence analysis, or SQL generation. Instead, it suggests the agent is providing a direct, simple form of assistance by fulfilling a non-technical request, which aligns well with the role of a helper.")', model_id=None)
7. Creazione di un LLM come giudice
Dopo aver classificato i prompt, valuterai l'accuratezza delle risposte del modello. Ciò comporta un'altra chiamata al modello Gemini, ma questa volta gli chiederai di valutare in che misura il "testo" soddisfa il "prompt" originale su una scala da 0,0 a 1,0. In questo modo puoi comprendere la qualità dell'output dell'AI. Per questa attività creerai un GeminiAccuracyModelHandler separato.

Per questa sezione, utilizza gemini_beam_pipeline_step3.py.
- Crea il tuo ModelHandler personalizzato, ma anziché restituire un oggetto modello in load_model, restituisci genai.Client come hai fatto in precedenza.
- Codice necessario per creare la funzione run_inference del ModelHandler personalizzato. È stato fornito un prompt di esempio:
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
Una cosa da notare qui è che hai creato essenzialmente due modelli diversi nella stessa pipeline. In questo esempio specifico, utilizzi anche una chiamata Gemini con Vertex AI, ma nello stesso concetto puoi scegliere di utilizzare e caricare altri modelli. In questo modo, la gestione dei modelli viene semplificata e puoi utilizzare più modelli all'interno della stessa pipeline Beam.
- Restituisci i risultati come PCollection per la successiva pTransform.
Ecco un esempio del codice riportato di seguito:
############## BEGIN STEP 3 ##############
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
def run_inference(
self,
batch: Sequence[str], # Each item is a JSON string
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""Runs inference on a batch of JSON strings to verify accuracy."""
for json_string in batch:
try:
element_dict = json.loads(json_string)
original_prompt = element_dict.get('original_prompt', '')
original_text = element_dict.get('original_text', '')
if not original_prompt or not original_text:
logging.warning(f"Accuracy input missing prompt/text: {json_string}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_ACCURACY_INPUT")
continue
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
gemini_response = model.models.generate_content_stream(model=self._model_name, contents=[prompt_for_accuracy], config=self._model_kwargs)
gemini_response_text = ""
for chunk in gemini_response:
if chunk.text is not None:
gemini_response_text+=chunk.text
yield PredictionResult(example=json_string, inference=gemini_response_text)
except Exception as e:
logging.error(f"Error during Gemini accuracy inference for input {json_string}: {e}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_INFERENCE")
############## END STEP 3 ##############
Prova questo codice eseguendo:
python gemini_beam_pipeline_step3.py --project $PROJECT_ID --runner DirectRunner --test_mode
Questo passaggio dovrebbe anche restituire un'inferenza, commentare e restituire un punteggio sull'accuratezza della risposta dello strumento secondo Gemini.
Dovresti aspettarti un output simile al seguente.
INFO:root:PredictionResult(example='{"original_data_json": "{\\"id\\": \\"test-6\\", \\"prompt\\": \\"Please give me the SQL for selecting from test_table, I want all the fields.\\", \\"text\\": \\"absolutely, here\'s a picture of a cat\\", \\"timestamp\\": 1751052770.7552562, \\"user_id\\": \\"user_c\\"}", "original_prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "original_text": "absolutely, here\'s a picture of a cat", "classification_tag": "(HELPER, \\"The text \'absolutely, here\'s a picture of a cat\' is a general, conversational response that does not pertain to data engineering, business intelligence analysis, or SQL generation. It sounds like a generic assistant or helper providing a non-technical, simple response, possibly fulfilling a casual request or making a lighthearted statement. Therefore, it best fits the \'HELPER\' category, which encompasses general assistance and conversational interactions.\\")"}', inference='0.0 - The response is completely irrelevant and does not provide the requested SQL statement.', model_id=None)
8. Finestre e analisi dei risultati
Ora puoi visualizzare i risultati in intervalli di tempo specifici per analizzarli. Utilizzerai finestre fisse per raggruppare i dati, in modo da ottenere insight aggregati. Dopo la suddivisione in finestre, analizzerai gli output non elaborati di Gemini in un formato più strutturato, inclusi i dati originali, il tag di classificazione, il punteggio di accuratezza e la spiegazione.

Per questa sezione, utilizza gemini_beam_pipeline_step4.py.
- Aggiungi una finestra temporale fissa di 60 secondi in modo che tutti i dati vengano inseriti in una finestra di 60 secondi.
Ecco un esempio del codice riportato di seguito:
############## BEGIN STEP 4 ##############
| 'WindowIntoFixedWindows' >> beam.WindowInto(beam.window.FixedWindows(60))
############## END STEP 4 ##############
Prova questo codice eseguendo:
python gemini_beam_pipeline_step4.py --project $PROJECT_ID --runner DirectRunner --test_mode
Questo passaggio è informativo, stai cercando la tua finestra. Verrà visualizzato come timestamp di interruzione/avvio della finestra.
Dovresti aspettarti un output simile al seguente.
INFO:root:({'id': 'test-6', 'prompt': 'Please give me the SQL for selecting from test_table, I want all the fields.', 'text': "absolutely, here's a picture of a cat", 'timestamp': 1751052901.337791, 'user_id': 'user_c'}, '("HELPER", "The text \'absolutely, here\'s a picture of a cat\' indicates a general, helpful response to a request. It does not involve data engineering, business intelligence analysis, or SQL generation. Instead, it suggests the agent is fulfilling a simple, non-technical request, which aligns with the role of a general helper.")', 0.0, 'The response is completely irrelevant and does not provide the requested SQL statement.', [1751052900.0, 1751052960.0))
9. Conteggio dei risultati positivi e negativi con l'elaborazione stateful
Infine, utilizzerai una DoFn stateful per conteggiare i risultati "buoni " e"cattivi " all'interno di ogni finestra. Un risultato "buono" potrebbe essere un'interazione con un punteggio di precisione elevato, mentre un risultato "scarso" indica un punteggio basso. Questo elaborazione stateful ti consente di mantenere i conteggi e persino raccogliere esempi di interazioni "errate" nel tempo, il che è fondamentale per monitorare l'integrità e il rendimento del tuo chatbot in tempo reale.
Per questa sezione, utilizza gemini_beam_pipeline_step5.py.
- Creare una funzione stateful. Avrai bisogno di due stati: (1) per tenere traccia del numero di conteggi errati e (2) per conservare i record errati da visualizzare. Utilizza i codificatori corretti per garantire le prestazioni del sistema.
- Ogni volta che vedi i valori per un'inferenza errata, devi tenere traccia di entrambi ed emetterli alla fine della finestra. Ricorda di reimpostare gli stati dopo l'emissione. Quest'ultimo è solo a scopo illustrativo, non cercare di memorizzarli tutti in un ambiente reale.
Ecco un esempio del codice riportato di seguito:
############## BEGIN STEP 5 ##############
# Define a state specification for a combining value.
# This will store the running sum for each key.
# The coder is specified for efficiency.
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(), # Used VarIntCoder directly
beam.transforms.combiners.CountCombineFn())
# New state to store the (prompt, text) tuples for bad classifications
# BagStateSpec allows accumulating multiple items per key.
BAD_PROMPTS_STATE = beam.transforms.userstate.BagStateSpec(
'bad_prompts', coder=beam.coders.TupleCoder([beam.coders.StrUtf8Coder(), beam.coders.StrUtf8Coder()])
)
# Define a timer to fire at the end of the window, using WATERMARK as per blog example.
WINDOW_TIMER = TimerSpec('window_timer', TimeDomain.WATERMARK)
def process(
self,
element: Tuple[str, Tuple[int, Tuple[str, str]]], # (key, (count_val, (prompt, text)))
key=beam.DoFn.KeyParam,
count_state=beam.DoFn.StateParam(COUNT_STATE),
bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE), # New state param
window_timer=beam.DoFn.TimerParam(WINDOW_TIMER),
window=beam.DoFn.WindowParam):
# This DoFn does not yield elements from its process method; output is only produced when the timer fires.
if key == 'bad': # Only count 'bad' elements
count_state.add(element[1][0]) # Add the count (which is 1)
bad_prompts_state.add(element[1][1]) # Add the (prompt, text) tuple
window_timer.set(window.end) # Set timer to fire at window end
@on_timer(WINDOW_TIMER)
def on_window_timer(self, key=beam.DoFn.KeyParam, count_state=beam.DoFn.StateParam(COUNT_STATE), bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE)):
final_count = count_state.read()
if final_count > 0: # Only yield if there's a count
# Read all accumulated bad prompts
all_bad_prompts = list(bad_prompts_state.read())
# Clear the state for the next window to avoid carrying over data.
count_state.clear()
bad_prompts_state.clear()
yield (key, final_count, all_bad_prompts) # Yield count and list of prompts
############## END STEP 5 ##############
Prova questo codice eseguendo:
python gemini_beam_pipeline_step5.py --project $PROJECT_ID --runner DirectRunner --test_mode
Questo passaggio dovrebbe restituire tutti i conteggi. Se modifichi le dimensioni della finestra, vedrai che i batch saranno diversi. La finestra predefinita rientra in un minuto, quindi prova a utilizzare 30 secondi o un altro intervallo di tempo e dovresti notare una differenza tra i batch e i conteggi.
Dovresti aspettarti un output simile al seguente.
INFO:root:Window: [1751052960.0, 1751053020.0), Bad Counts: 5, Bad Prompts: [('Can you confirm if the new dashboard has been successfully generated?', 'I have gone ahead and generated a new dashboard for you.'), ('How is the new feature performing?', 'It works as expected.'), ('What is the capital of France?', 'The square root of a banana is purple.'), ('Explain quantum entanglement to a five-year-old.', 'A flock of geese wearing tiny hats danced the tango on the moon.'), ('Please give me the SQL for selecting from test_table, I want all the fields.', "absolutely, here's a picture of a cat")]
10. Pulizia
- (Facoltativo, ma consigliato per i codelab) Elimina il progetto Google Cloud: se questo progetto è stato creato esclusivamente per questo codelab e non ti serve più, l'eliminazione dell'intero progetto è il modo più completo per assicurarti che tutte le risorse vengano rimosse.
- Vai alla pagina Gestisci risorse nella console Google Cloud.
- Seleziona il progetto.
- Fai clic su Elimina progetto e segui le istruzioni sullo schermo.
11. Complimenti!
Congratulazioni per aver completato il codelab. Hai creato correttamente una pipeline di inferenza ML in tempo reale utilizzando Apache Beam e Gemini su Dataflow. Hai imparato a sfruttare la potenza dell'AI generativa nei tuoi flussi di dati, estraendo informazioni preziose per un'ingegneria dei dati più intelligente e automatizzata.