
1. はじめに
昨今の目まぐるしく変化するデータ環境において、情報に基づいた意思決定を行うには、リアルタイムの分析情報が不可欠です。この Codelab では、リアルタイム評価パイプラインの構築について説明します。まず、バッチデータとストリーミング データの両方に統合プログラミング モデルを提供する Apache Beam フレームワークを活用します。これにより、複雑な分散コンピューティング ロジックを抽象化して、パイプライン開発が大幅に簡素化されます。Beam を使用してパイプラインを定義すると、Google Cloud Dataflow でシームレスに実行できます。これは、データ処理のニーズに合わせて比類のないスケーラビリティとパフォーマンスを提供するフルマネージド サービスです。
この Codelab では、ML 推論用のスケーラブルな Apache Beam パイプラインを設計する方法、Vertex AI の Gemini モデルを統合するカスタム ModelHandler を開発する方法、データ ストリームでインテリジェントなテキスト分類を行うためにプロンプト エンジニアリングを活用する方法、このストリーミング ML 推論パイプラインを Google Cloud Dataflow にデプロイして運用する方法について学習します。このコースを修了すると、エンジニアリング ワークフローでリアルタイムのデータ理解と継続的な評価に ML を適用する方法、特に堅牢でユーザー中心の会話型 AI を維持する方法について、貴重な分析情報を得ることができます。
シナリオ
会社がデータ エージェントを構築している。Agent Development Kit(ADK)で構築されたデータ エージェントには、データ関連のタスクを支援するためのさまざまな専門機能が備わっています。BI アナリストとして有益なレポートを生成したり、データ エンジニアとして堅牢なデータ パイプラインの構築を支援したり、SQL ジェネレータとして正確な SQL ステートメントを作成したりするなど、さまざまなリクエストに対応できる多用途のデータ アシスタントとして考えてください。このエージェントが行ったすべてのやり取りと生成したすべてのレスポンスは、Firestore に自動的に保存されます。しかし、なぜここでパイプラインが必要なのでしょうか?
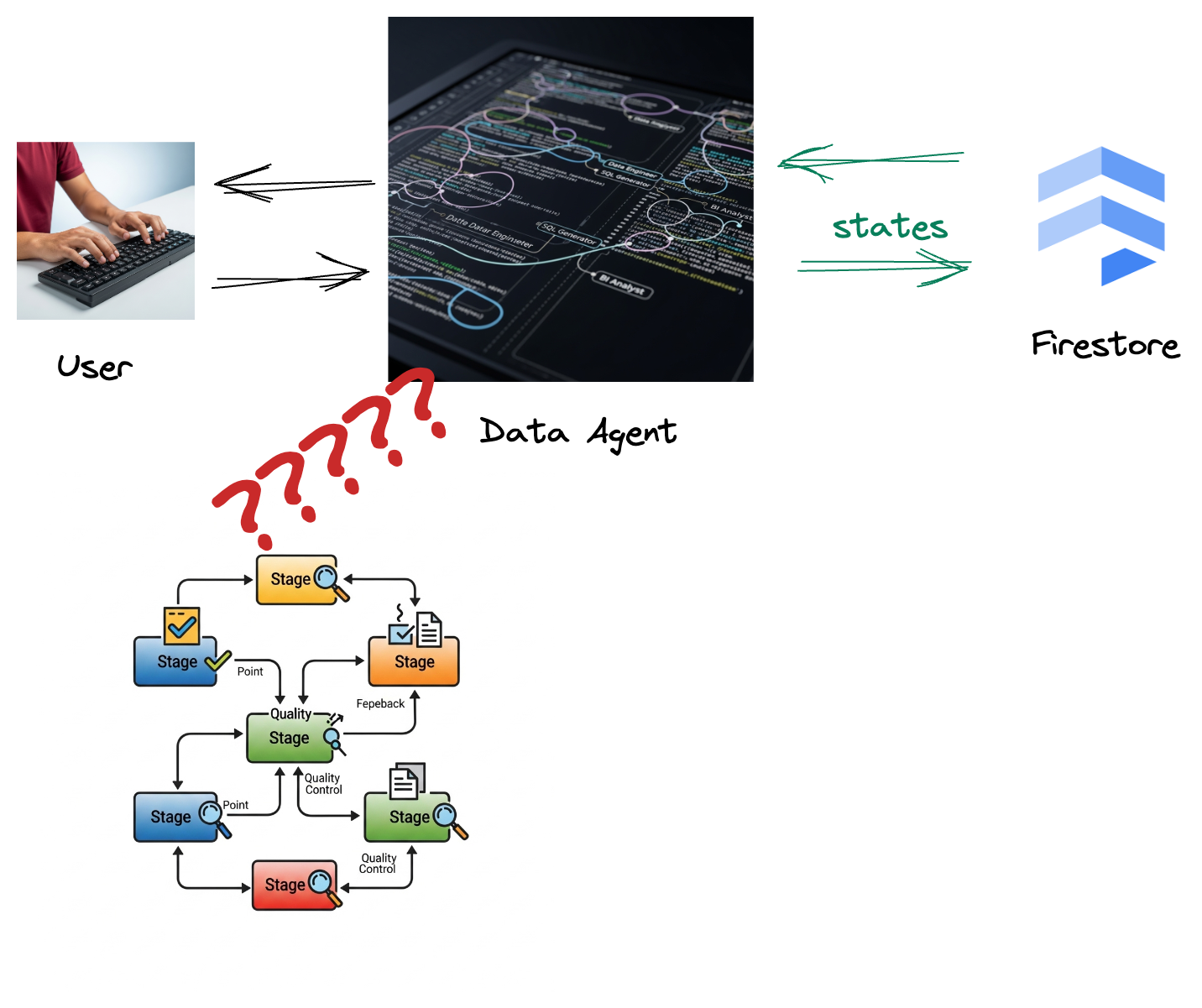
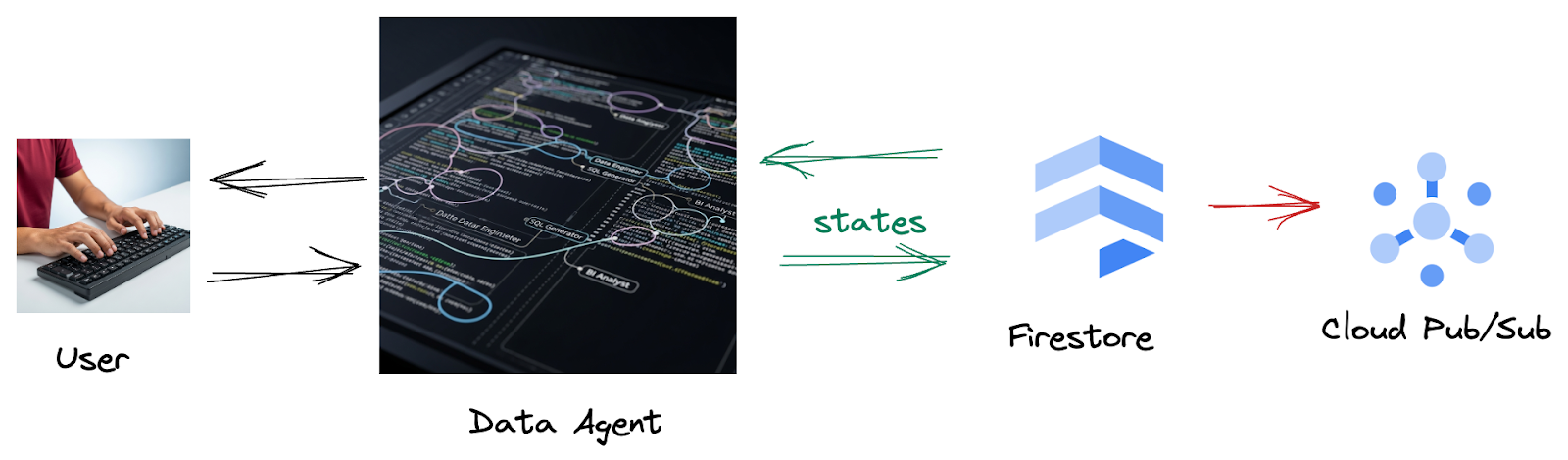
Firestore からトリガーによってこのインタラクション データが Pub/Sub にシームレスに送信されるため、これらの重要な会話をリアルタイムで直ちに処理して分析できます。
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- このリンクをクリックして、Cloud Shell をアクティブにします。Cloud Shell の対応するボタンをクリックすると、Cloud Shell ターミナル(クラウド コマンドの実行用)とエディタ(プロジェクトのビルド用)を切り替えることができます。
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
- 次のコマンドを使用して、必要な API を有効にします。これには数分かかることがあります。
gcloud services enable \
dataflow.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Python 3.10 以降がインストールされていることを確認する
- Python パッケージをインストールする
Cloud Shell 環境に、Apache Beam、Google Cloud Vertex AI、Google Generative AI に必要な Python ライブラリをインストールします。
pip install apache-beam[gcp] google-genai
- github リポジトリのクローンを作成し、デモ ディレクトリに切り替えます。
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/beam_as_eval
gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
3. 提供された GitHub リポジトリの使用方法
この Codelab に関連付けられている GitHub リポジトリ(https://github.com/GoogleCloudPlatform/devrel-demos/tree/main/data-analytics/beam_as_eval)は、ガイド付き学習を容易にするように構成されています。このファイルには、Codelab の各部分に対応するスケルトン コードが含まれており、教材を明確に進めることができます。
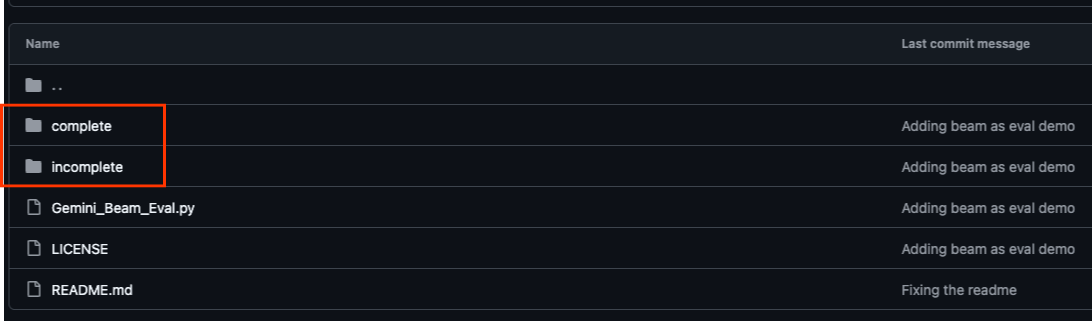
リポジトリ内には、「complete」と「incomplete」という 2 つのメイン フォルダがあります。「complete」フォルダには、各ステップの完全に機能するコードが格納されています。このコードを実行して、意図した出力を確認できます。一方、「incomplete」フォルダには、前の手順のコードが用意されています。##### START STEP <NUMBER> ##### と ##### END STEP <NUMBER> ##### の間にマークされた特定のセクションは、演習の一環として完了する必要があります。この構造により、コーディング チャレンジに積極的に参加しながら、以前の知識を基に構築できます。
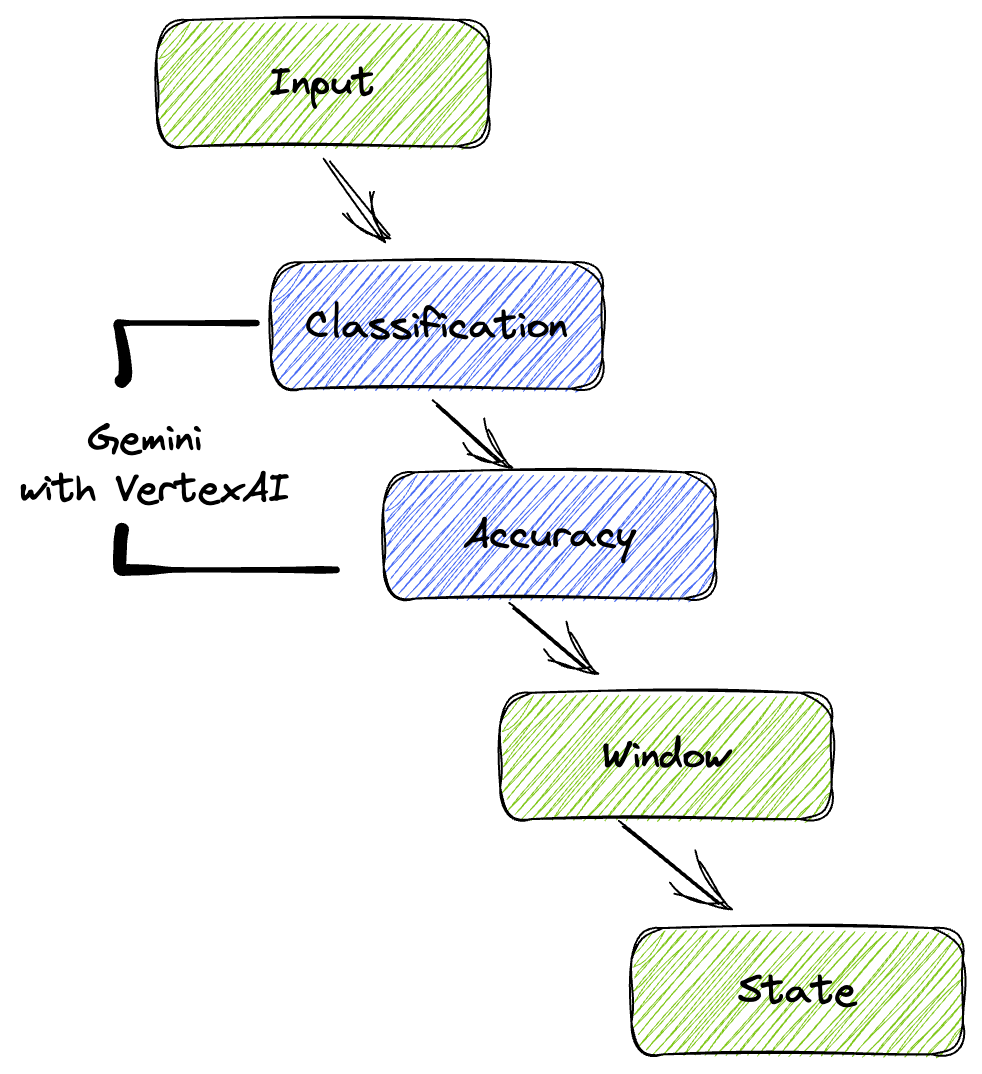
4. アーキテクチャの概要
このパイプラインは、ML 推論をデータ ストリームに統合するための強力でスケーラブルなパターンを提供します。各サービスはそれぞれ次のように分類されます。
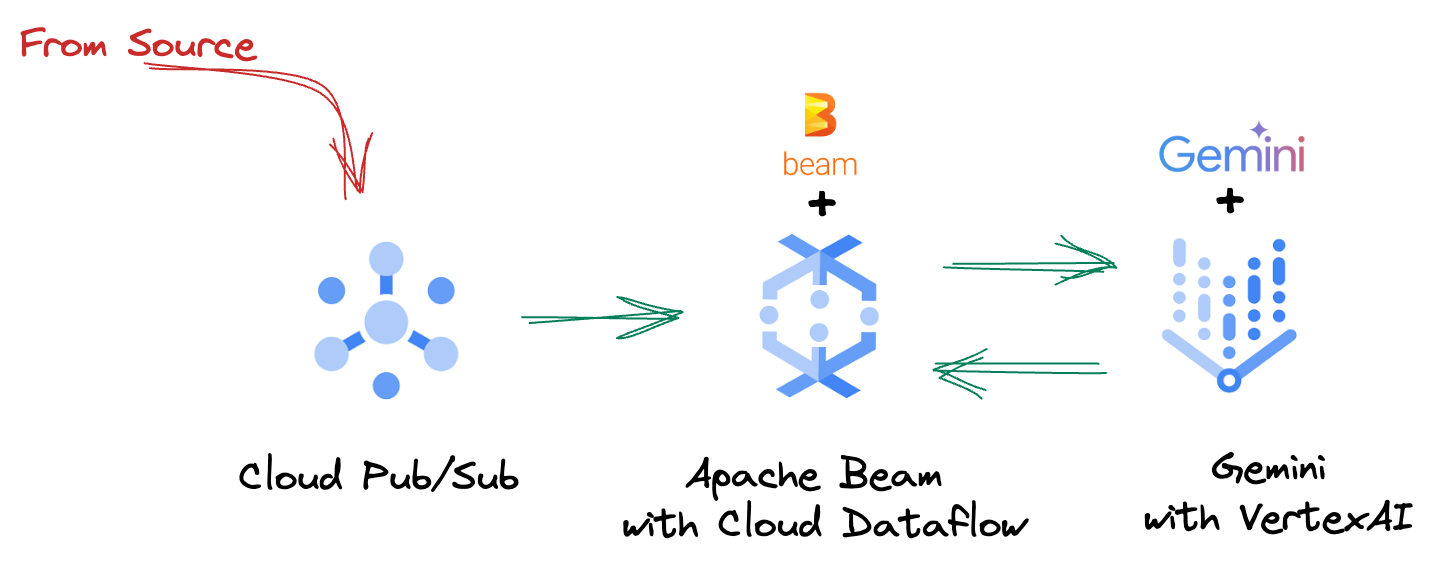
Beam パイプラインで、複数の入力を条件付きでコーディングし、RunInference ターンキー変換を使用してカスタムモデルを読み込みます。この例では VertexAI で Gemini を使用していますが、実際には、複数の ModelHandler を作成して、モデルの数に合わせる方法を示しています。最後に、ステートフル DoFn を使用してイベントを追跡し、制御された方法でイベントを出力します。
5. データの取り込み
まず、データを取り込むようにパイプラインを設定します。リアルタイム ストリーミングには Pub/Sub を使用しますが、開発を容易にするためにテストモードも作成します。この test_mode を使用すると、事前定義されたサンプルデータを使用してパイプラインをローカルで実行できるため、パイプラインが機能するかどうかを確認するためにライブ Pub/Sub ストリームは必要ありません。
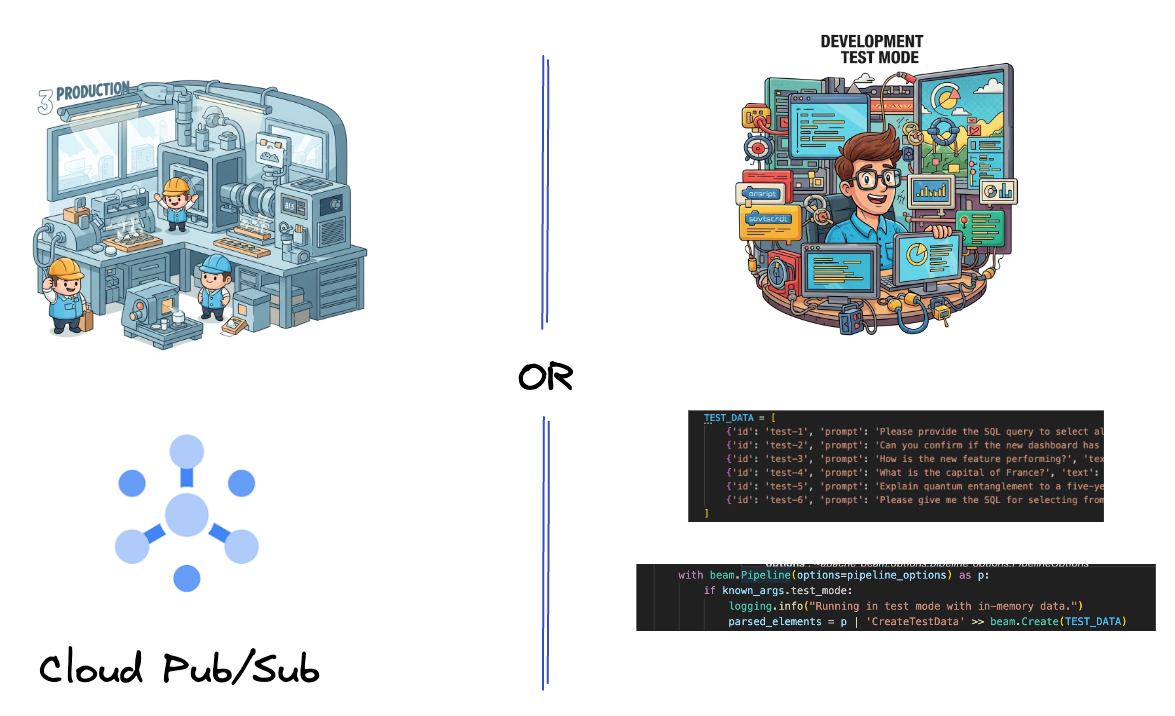
このセクションでは、gemini_beam_pipeline_step1.py を使用します。
- 提供されたパイプライン オブジェクト p を使用して、Pub/Sub 入力をコーディングし、出力を pCollection として書き出します。
- また、フラグを使用して TEST_MODE が設定されているかどうかを判断します。
- TEST_MODE が設定されている場合は、TEST_DATA 配列を入力として解析するように切り替えます。
これは必須ではありませんが、プロセスを短縮して、この段階で Pub/Sub を使用する必要がないようにするのに役立ちます。
以下に、コードの例を示します。
# Step 1
# Ingesting Data
# Write your data ingestion step here.
############## BEGIN STEP 1 ##############
if known_args.test_mode:
logging.info("Running in test mode with in-memory data.")
parsed_elements = p | 'CreateTestData' >> beam.Create(TEST_DATA)
# Convert dicts to JSON strings and add timestamps for test mode
parsed_elements = parsed_elements | 'ConvertTestDictsToJsonAndAddTimestamps' >> beam.Map(
lambda x: beam.window.TimestampedValue(json.dumps(x), x['timestamp'])
)
else:
logging.info(f"Reading from Pub/Sub topic: {known_args.input_topic}")
parsed_elements = (
p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(
topic=known_args.input_topic
).with_output_types(bytes)
| 'DecodeBytes' >> beam.Map(lambda b: b.decode('utf-8')) # Output is JSON string
# Extract timestamp from JSON string for Pub/Sub messages
| 'AddTimestampsFromParsedJson' >> beam.Map(lambda s: beam.window.TimestampedValue(s, json.loads(s)['timestamp']))
)
############## END STEP 1 ##############
次のコマンドを実行して、このコードをテストします。
python gemini_beam_pipeline_step1.py --project $PROJECT_ID --runner DirectRunner --test_mode
このステップでは、すべてのレコードが出力され、stdout にロギングされます。
次のような出力が想定されます。
INFO:root:Running in test mode with in-memory data.
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:root:{"id": "test-1", "prompt": "Please provide the SQL query to select all fields from the 'TEST_TABLE'.", "text": "Sure here is the SQL: SELECT * FROM TEST_TABLE;", "timestamp": 1751052405.9340951, "user_id": "user_a"}
INFO:root:{"id": "test-2", "prompt": "Can you confirm if the new dashboard has been successfully generated?", "text": "I have gone ahead and generated a new dashboard for you.", "timestamp": 1751052410.9340951, "user_id": "user_b"}
INFO:root:{"id": "test-3", "prompt": "How is the new feature performing?", "text": "It works as expected.", "timestamp": 1751052415.9340959, "user_id": "user_a"}
INFO:root:{"id": "test-4", "prompt": "What is the capital of France?", "text": "The square root of a banana is purple.", "timestamp": 1751052430.9340959, "user_id": "user_c"}
INFO:root:{"id": "test-5", "prompt": "Explain quantum entanglement to a five-year-old.", "text": "A flock of geese wearing tiny hats danced the tango on the moon.", "timestamp": 1751052435.9340959, "user_id": "user_b"}
INFO:root:{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here's a picture of a cat", "timestamp": 1751052440.9340959, "user_id": "user_c"}
6. LLM プロンプト分類用の PTransform の構築
次に、プロンプトを分類する PTransform を構築します。これには、Vertex AI の Gemini モデルを使用して受信テキストを分類することが含まれます。Gemini モデルを読み込み、テキストを「データ エンジニア」、「BI アナリスト」、「SQL ジェネレータ」などのカテゴリに分類する方法をモデルに指示するカスタム GeminiModelHandler を定義します。
これを使用するには、ログ内の実際のツール呼び出しと比較します。この Codelab では説明しませんが、ダウンストリームに送信して比較できます。曖昧なものもあるかもしれませんが、これはエージェントが適切なツールを呼び出していることを確認するための重要な追加データポイントとなります。
このセクションでは、gemini_beam_pipeline_step2.py を使用します。
- カスタム ModelHandler を構築します。ただし、load_model でモデル オブジェクトを返す代わりに、genai.Client を返します。
- カスタム ModelHandler の run_inference 関数を作成するために必要なコード。プロンプトの例を以下に示します。
プロンプトは次のようになります。
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilities.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambiguous. Choose only one.
Finally, always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
- 結果を次の pTransform の pCollection として生成します。
以下に、コードの例を示します。
############## BEGIN STEP 2 ##############
# load_model is called once per worker process to initialize the LLM client.
# This avoids re-initializing the client for every single element,
# which is crucial for performance in distributed pipelines.
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
# run_inference is called for each batch of elements. Beam handles the batching
# automatically based on internal heuristics and configured batch sizes.
# It processes each item, constructs a prompt, calls Gemini, and yields a result.
def run_inference(
self,
batch: Sequence[Any], # Each item is a JSON string or a dict
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""
Runs inference on a batch of JSON strings or dicts.
Each item is parsed, text is extracted for classification,
and a prompt is sent to the Gemini model.
"""
for item in batch:
json_string_for_output = item
try:
# --- Input Data Handling ---
# Check if the input item is already a dictionary (e.g., from TEST_DATA)
# or a JSON string (e.g., from Pub/Sub).
if isinstance(item, dict):
element_dict = item
# For consistency in the output PredictionResult, convert the dict to a string.
# This ensures pr.example always contains the original JSON string.
json_string_for_output = json.dumps(item)
else:
element_dict = json.loads(item)
# Extract the 'text' field from the parsed dictionary.
text_to_classify = element_dict.get('text','')
if not text_to_classify:
logging.warning(f"Input JSON missing 'text' key or text is empty: {json_string_for_output}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_NO_TEXT")
continue
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilites.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambigiuous. Choose only one.
Finally always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
contents = [
types.Content( # This is the actual content for the LLM
role="user",
parts=[
types.Part.from_text(text=prompt)
]
)
]
gemini_response = model.models.generate_content_stream(
model=self._model_name, contents=contents, config=self._model_kwargs
)
classification_tag = ""
for chunk in gemini_response:
if chunk.text is not None:
classification_tag+=chunk.text
yield PredictionResult(example=json_string_for_output, inference=classification_tag)
except json.JSONDecodeError as e:
logging.error(f"Error decoding JSON string: {json_string_for_output}, error: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_JSON_DECODE")
except Exception as e:
logging.error(f"Error during Gemini inference for input {json_string_for_output}: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_INFERENCE")
############## END STEP 2 ##############
次のコマンドを実行して、このコードをテストします。
python gemini_beam_pipeline_step2.py --project $PROJECT_ID --runner DirectRunner --test_mode
このステップでは、Gemini から推論が返されます。プロンプトでリクエストされたとおりに結果が分類されます。
次のような出力が想定されます。
INFO:root:PredictionResult(example='{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here\'s a picture of a cat", "timestamp": 1751052592.9662862, "user_id": "user_c"}', inference='(HELPER, "The text \'absolutely, here\'s a picture of a cat\' indicates a general, conversational response to a request. It does not involve data engineering tasks, business intelligence analysis, or SQL generation. Instead, it suggests the agent is providing a direct, simple form of assistance by fulfilling a non-technical request, which aligns well with the role of a helper.")', model_id=None)
7. LLM-as-a-Judge の構築
プロンプトを分類したら、モデルの回答の精度を評価します。これには Gemini モデルへの別の呼び出しが含まれますが、今回は「テキスト」が元の「プロンプト」をどの程度満たしているかを 0.0 ~ 1.0 のスケールで評価するようにプロンプトします。これにより、AI の出力の品質を把握できます。このタスク用に別の GeminiAccuracyModelHandler を作成します。

このセクションでは、gemini_beam_pipeline_step3.py を使用します。
- カスタム ModelHandler を構築します。ただし、load_model でモデル オブジェクトを返す代わりに、上記のように genai.Client を返します。
- カスタム ModelHandler の run_inference 関数を作成するために必要なコード。プロンプトの例を以下に示します。
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
ここで注意すべき点は、同じパイプラインで 2 つの異なるモデルを作成したことです。この例では、VertexAI で Gemini 呼び出しも使用していますが、同じコンセプトで他のモデルを使用および読み込むこともできます。これにより、モデル管理が簡素化され、同じ Beam パイプライン内で複数のモデルを使用できます。
- 結果を次の pTransform の pCollection として生成します。
以下に、コードの例を示します。
############## BEGIN STEP 3 ##############
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
def run_inference(
self,
batch: Sequence[str], # Each item is a JSON string
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""Runs inference on a batch of JSON strings to verify accuracy."""
for json_string in batch:
try:
element_dict = json.loads(json_string)
original_prompt = element_dict.get('original_prompt', '')
original_text = element_dict.get('original_text', '')
if not original_prompt or not original_text:
logging.warning(f"Accuracy input missing prompt/text: {json_string}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_ACCURACY_INPUT")
continue
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
gemini_response = model.models.generate_content_stream(model=self._model_name, contents=[prompt_for_accuracy], config=self._model_kwargs)
gemini_response_text = ""
for chunk in gemini_response:
if chunk.text is not None:
gemini_response_text+=chunk.text
yield PredictionResult(example=json_string, inference=gemini_response_text)
except Exception as e:
logging.error(f"Error during Gemini accuracy inference for input {json_string}: {e}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_INFERENCE")
############## END STEP 3 ##############
次のコマンドを実行して、このコードをテストします。
python gemini_beam_pipeline_step3.py --project $PROJECT_ID --runner DirectRunner --test_mode
このステップでは推論も返される必要があります。Gemini がツールによる回答の精度をどのように評価したかを示すスコアをコメントして返す必要があります。
次のような出力が想定されます。
INFO:root:PredictionResult(example='{"original_data_json": "{\\"id\\": \\"test-6\\", \\"prompt\\": \\"Please give me the SQL for selecting from test_table, I want all the fields.\\", \\"text\\": \\"absolutely, here\'s a picture of a cat\\", \\"timestamp\\": 1751052770.7552562, \\"user_id\\": \\"user_c\\"}", "original_prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "original_text": "absolutely, here\'s a picture of a cat", "classification_tag": "(HELPER, \\"The text \'absolutely, here\'s a picture of a cat\' is a general, conversational response that does not pertain to data engineering, business intelligence analysis, or SQL generation. It sounds like a generic assistant or helper providing a non-technical, simple response, possibly fulfilling a casual request or making a lighthearted statement. Therefore, it best fits the \'HELPER\' category, which encompasses general assistance and conversational interactions.\\")"}', inference='0.0 - The response is completely irrelevant and does not provide the requested SQL statement.', model_id=None)
8. 結果のウィンドウ表示と分析
次に、結果をウィンドウ化して、特定の時間間隔で分析します。固定ウィンドウを使用してデータをグループ化し、集計された分析情報を取得します。ウィンドウ処理後、Gemini からの未加工の出力を、元のデータ、分類タグ、精度スコア、説明などを含む、より構造化された形式に解析します。

このセクションでは、gemini_beam_pipeline_step4.py を使用します。
- 60 秒の固定時間枠を追加して、すべてのデータが 60 秒の枠内に配置されるようにします。
以下に、コードの例を示します。
############## BEGIN STEP 4 ##############
| 'WindowIntoFixedWindows' >> beam.WindowInto(beam.window.FixedWindows(60))
############## END STEP 4 ##############
次のコマンドを実行して、このコードをテストします。
python gemini_beam_pipeline_step4.py --project $PROJECT_ID --runner DirectRunner --test_mode
この手順は情報提供を目的としています。ウィンドウを探してください。これは、ウィンドウの停止/開始のタイムスタンプとして表示されます。
次のような出力が想定されます。
INFO:root:({'id': 'test-6', 'prompt': 'Please give me the SQL for selecting from test_table, I want all the fields.', 'text': "absolutely, here's a picture of a cat", 'timestamp': 1751052901.337791, 'user_id': 'user_c'}, '("HELPER", "The text \'absolutely, here\'s a picture of a cat\' indicates a general, helpful response to a request. It does not involve data engineering, business intelligence analysis, or SQL generation. Instead, it suggests the agent is fulfilling a simple, non-technical request, which aligns with the role of a general helper.")', 0.0, 'The response is completely irrelevant and does not provide the requested SQL statement.', [1751052900.0, 1751052960.0))
9. ステートフル処理による良い結果と悪い結果のカウント
最後に、ステートフル DoFn を使用して、各ウィンドウ内の「良い」結果と「悪い」結果をカウントします。「良い」結果は精度スコアの高いインタラクション、「悪い」結果はスコアの低いインタラクションを示します。このステートフル処理により、カウントを維持し、時間の経過とともに「悪い」インタラクションの例を収集できます。これは、chatbot の健全性とパフォーマンスをリアルタイムでモニタリングするうえで重要です。
このセクションでは、gemini_beam_pipeline_step5.py を使用します。
- ステートフル関数を作成します。(1)無効なカウント数を追跡し、(2)無効なレコードを表示するために、2 つの状態が必要です。適切なコーダーを使用して、システムがパフォーマンスを発揮できるようにします。
- 誤った推論の値が表示されるたびに、両方を追跡し、ウィンドウの最後にそれらを出力します。状態を送信したら、必ずリセットしてください。後者は説明のみを目的としたものです。実際の環境でこれらすべてをメモリに保持しようとしないでください。
以下に、コードの例を示します。
############## BEGIN STEP 5 ##############
# Define a state specification for a combining value.
# This will store the running sum for each key.
# The coder is specified for efficiency.
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(), # Used VarIntCoder directly
beam.transforms.combiners.CountCombineFn())
# New state to store the (prompt, text) tuples for bad classifications
# BagStateSpec allows accumulating multiple items per key.
BAD_PROMPTS_STATE = beam.transforms.userstate.BagStateSpec(
'bad_prompts', coder=beam.coders.TupleCoder([beam.coders.StrUtf8Coder(), beam.coders.StrUtf8Coder()])
)
# Define a timer to fire at the end of the window, using WATERMARK as per blog example.
WINDOW_TIMER = TimerSpec('window_timer', TimeDomain.WATERMARK)
def process(
self,
element: Tuple[str, Tuple[int, Tuple[str, str]]], # (key, (count_val, (prompt, text)))
key=beam.DoFn.KeyParam,
count_state=beam.DoFn.StateParam(COUNT_STATE),
bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE), # New state param
window_timer=beam.DoFn.TimerParam(WINDOW_TIMER),
window=beam.DoFn.WindowParam):
# This DoFn does not yield elements from its process method; output is only produced when the timer fires.
if key == 'bad': # Only count 'bad' elements
count_state.add(element[1][0]) # Add the count (which is 1)
bad_prompts_state.add(element[1][1]) # Add the (prompt, text) tuple
window_timer.set(window.end) # Set timer to fire at window end
@on_timer(WINDOW_TIMER)
def on_window_timer(self, key=beam.DoFn.KeyParam, count_state=beam.DoFn.StateParam(COUNT_STATE), bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE)):
final_count = count_state.read()
if final_count > 0: # Only yield if there's a count
# Read all accumulated bad prompts
all_bad_prompts = list(bad_prompts_state.read())
# Clear the state for the next window to avoid carrying over data.
count_state.clear()
bad_prompts_state.clear()
yield (key, final_count, all_bad_prompts) # Yield count and list of prompts
############## END STEP 5 ##############
次のコマンドを実行して、このコードをテストします。
python gemini_beam_pipeline_step5.py --project $PROJECT_ID --runner DirectRunner --test_mode
このステップでは、すべてのカウントが出力されます。ウィンドウのサイズを変更すると、バッチが異なることがわかります。デフォルトのウィンドウは 1 分以内に収まるため、30 秒などの別の期間を使用すると、バッチとカウントの違いを確認できます。
次のような出力が想定されます。
INFO:root:Window: [1751052960.0, 1751053020.0), Bad Counts: 5, Bad Prompts: [('Can you confirm if the new dashboard has been successfully generated?', 'I have gone ahead and generated a new dashboard for you.'), ('How is the new feature performing?', 'It works as expected.'), ('What is the capital of France?', 'The square root of a banana is purple.'), ('Explain quantum entanglement to a five-year-old.', 'A flock of geese wearing tiny hats danced the tango on the moon.'), ('Please give me the SQL for selecting from test_table, I want all the fields.', "absolutely, here's a picture of a cat")]
10. クリーンアップ
- Google Cloud プロジェクトを削除する(省略可、ただし Codelab では推奨): このプロジェクトがこの Codelab 専用に作成されたもので、不要になった場合は、プロジェクト全体を削除すると、すべてのリソースが確実に削除されます。
- Google Cloud コンソールの [ リソースの管理] ページに移動します。
- プロジェクトを選択します。
- [プロジェクトを削除] をクリックし、画面の指示に沿って操作します。
11. 完了
以上で、この Codelab は完了です。Apache Beam と Gemini on Dataflow を使用して、リアルタイム ML 推論パイプラインを正常に構築しました。生成 AI の力をデータ ストリームに取り込み、よりインテリジェントで自動化されたデータ エンジニアリングに役立つ分析情報を抽出する方法を学習しました。