
1. Wprowadzenie
W dzisiejszym dynamicznym świecie danych statystyki w czasie rzeczywistym mają kluczowe znaczenie dla podejmowania świadomych decyzji. W tym ćwiczeniu w Codelabs dowiesz się, jak utworzyć potok oceny w czasie rzeczywistym. Zaczniemy od wykorzystania platformy Apache Beam, która oferuje ujednolicony model programowania zarówno dla danych wsadowych, jak i strumieniowych. Znacznie upraszcza to tworzenie potoków, ponieważ eliminuje konieczność budowania od podstaw złożonej logiki obliczeń rozproszonych. Po zdefiniowaniu potoku za pomocą Beam możesz go bezproblemowo uruchomić w Google Cloud Dataflow, usłudze w pełni zarządzanej, która zapewnia niezrównaną skalę i wydajność w zakresie przetwarzania danych.
Z tego ćwiczenia w Codelabs dowiesz się, jak zaprojektować skalowalny potok Apache Beam do wnioskowania uczenia maszynowego, opracować niestandardowy element ModelHandler do integracji modelu Gemini w Vertex AI, wykorzystać inżynierię promptów do inteligentnej klasyfikacji tekstu w strumieniach danych oraz wdrożyć i obsługiwać ten potok wnioskowania uczenia maszynowego w Google Cloud Dataflow. Pod koniec tego szkolenia zdobędziesz cenne informacje o tym, jak stosować uczenie maszynowe do analizowania danych w czasie rzeczywistym i ciągłego oceniania w przepływach pracy inżynierskiej, zwłaszcza w celu utrzymania solidnej i skoncentrowanej na użytkownikach konwersacyjnej AI.
Scenariusz
Twoja firma utworzyła agenta danych. Agent danych utworzony za pomocą pakietu Agent Development Kit (ADK) ma różne specjalistyczne funkcje, które pomagają w wykonywaniu zadań związanych z danymi. Wyobraź sobie wszechstronnego asystenta danych, który jest gotowy do obsługi różnych żądań, od analityka BI generującego przydatne raporty po inżyniera danych pomagającego w budowaniu niezawodnych potoków danych czy generatora SQL tworzącego precyzyjne instrukcje SQL. Każda interakcja tego agenta i każda wygenerowana przez niego odpowiedź jest automatycznie zapisywana w Firestore. Ale po co nam tutaj potok?
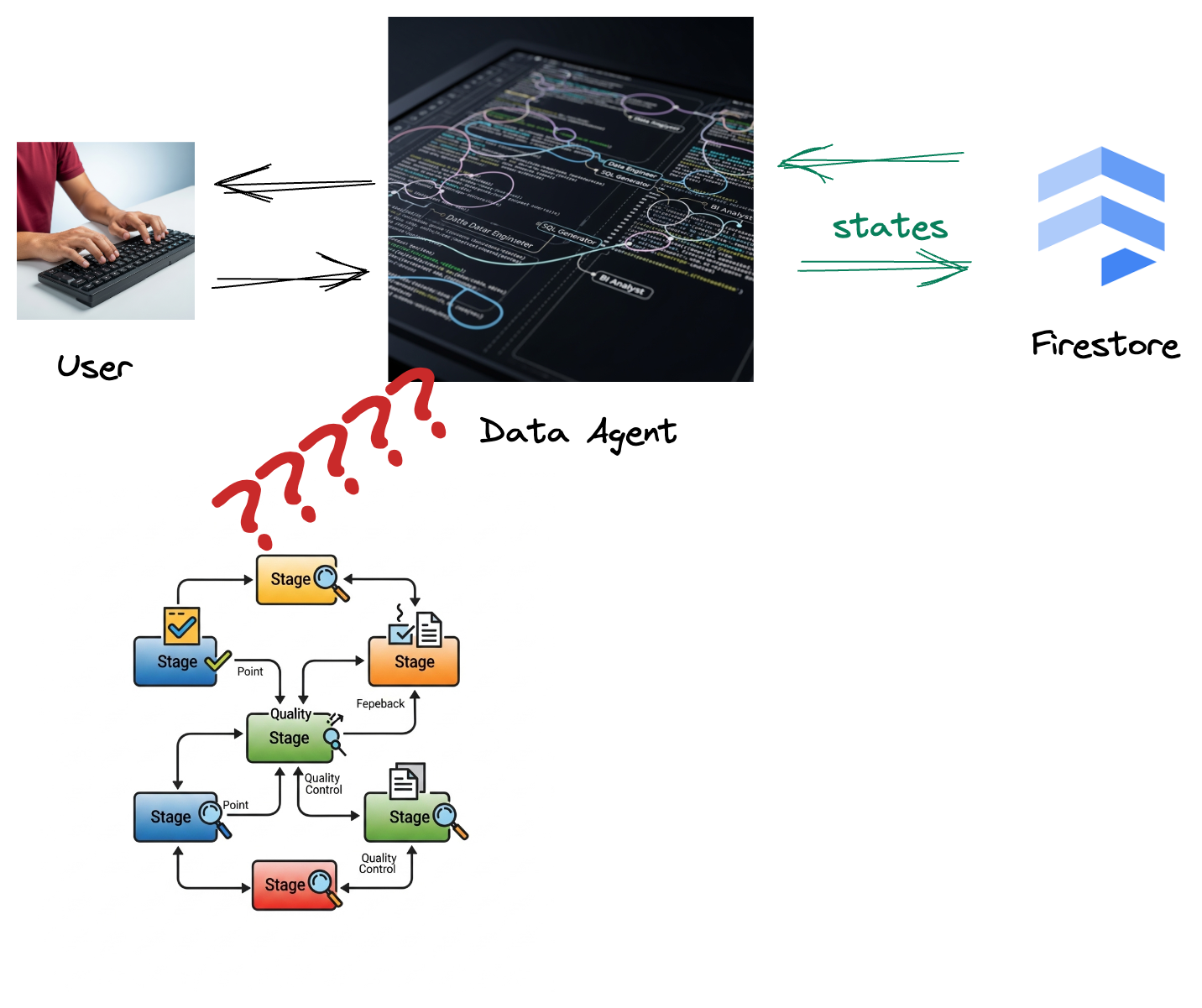
Dzieje się tak, ponieważ Firestore bezproblemowo wysyła dane o interakcjach do Pub/Sub, dzięki czemu możemy natychmiast przetwarzać i analizować te ważne rozmowy w czasie rzeczywistym.
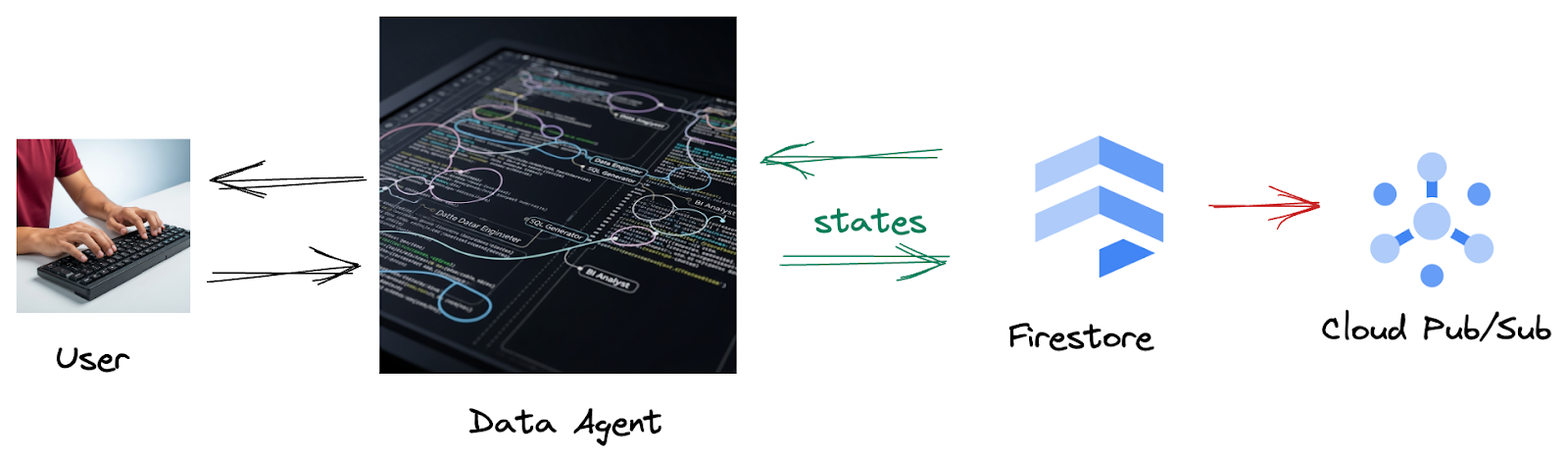
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
- Aktywuj Cloud Shell, klikając ten link. Możesz przełączać się między terminalem Cloud Shell (do uruchamiania poleceń w chmurze) a edytorem (do tworzenia projektów), klikając odpowiedni przycisk w Cloud Shell.
- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
- Włącz wymagane interfejsy API za pomocą polecenia pokazanego poniżej. Może to potrwać kilka minut, więc zachowaj cierpliwość.
gcloud services enable \
dataflow.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Upewnij się, że masz Pythona w wersji 3.10 lub nowszej.
- Instalowanie pakietów Pythona
Zainstaluj w środowisku powłoki Cloud Shell wymagane biblioteki Pythona dla Apache Beam, Google Cloud Vertex AI i Google Generative AI.
pip install apache-beam[gcp] google-genai
- Sklonuj repozytorium GitHub i przejdź do katalogu demonstracyjnego.
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/beam_as_eval
Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
3. Jak korzystać z udostępnionego repozytorium GitHub
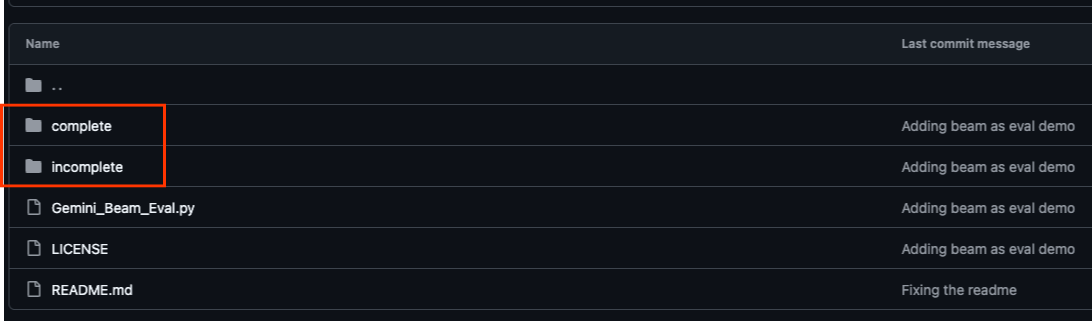
Repozytorium GitHub powiązane z tym ćwiczeniem, które znajdziesz pod adresem https://github.com/GoogleCloudPlatform/devrel-demos/tree/main/data-analytics/beam_as_eval, zostało zorganizowane tak, aby ułatwić naukę. Zawiera on kod szkieletowy, który jest zgodny z każdą częścią ćwiczenia, co zapewnia przejrzystość materiału.
W repozytorium znajdziesz 2 główne foldery: „complete” (ukończone) i „incomplete” (nieukończone). Folder „complete” zawiera w pełni funkcjonalny kod dla każdego kroku, dzięki czemu możesz uruchomić kod i obserwować zamierzone dane wyjściowe. Z kolei folder „incomplete” zawiera kod z poprzednich kroków, a określone sekcje są oznaczone między znakami ##### START STEP <NUMBER> ##### i ##### END STEP <NUMBER> #####, aby można było je uzupełnić w ramach ćwiczeń. Taka struktura pozwala wykorzystywać zdobytą wcześniej wiedzę podczas aktywnego uczestnictwa w wyzwaniach związanych z kodowaniem.
4. Omówienie architektury
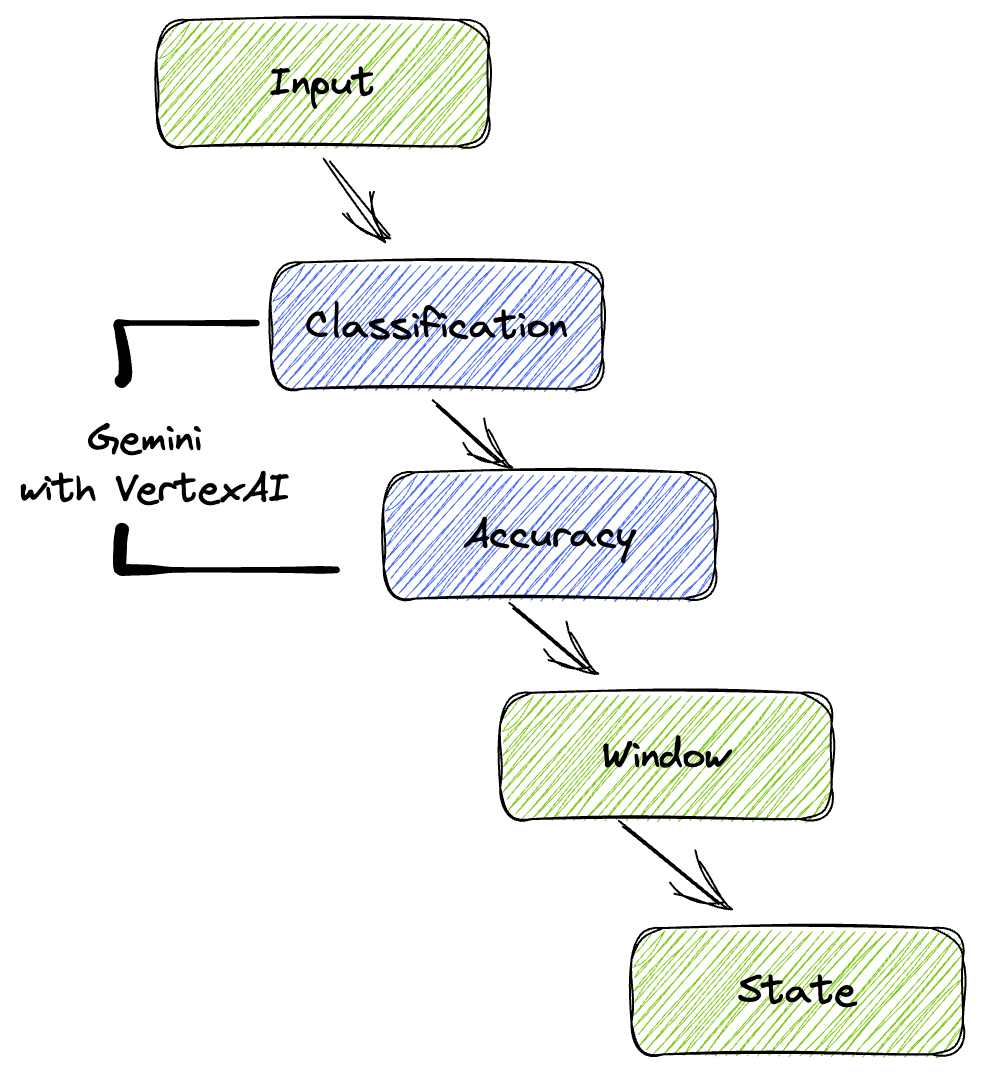
Nasz potok zapewnia zaawansowany i skalowalny wzorzec integracji wnioskowania ML ze strumieniami danych. Oto jak te elementy łączą się ze sobą:
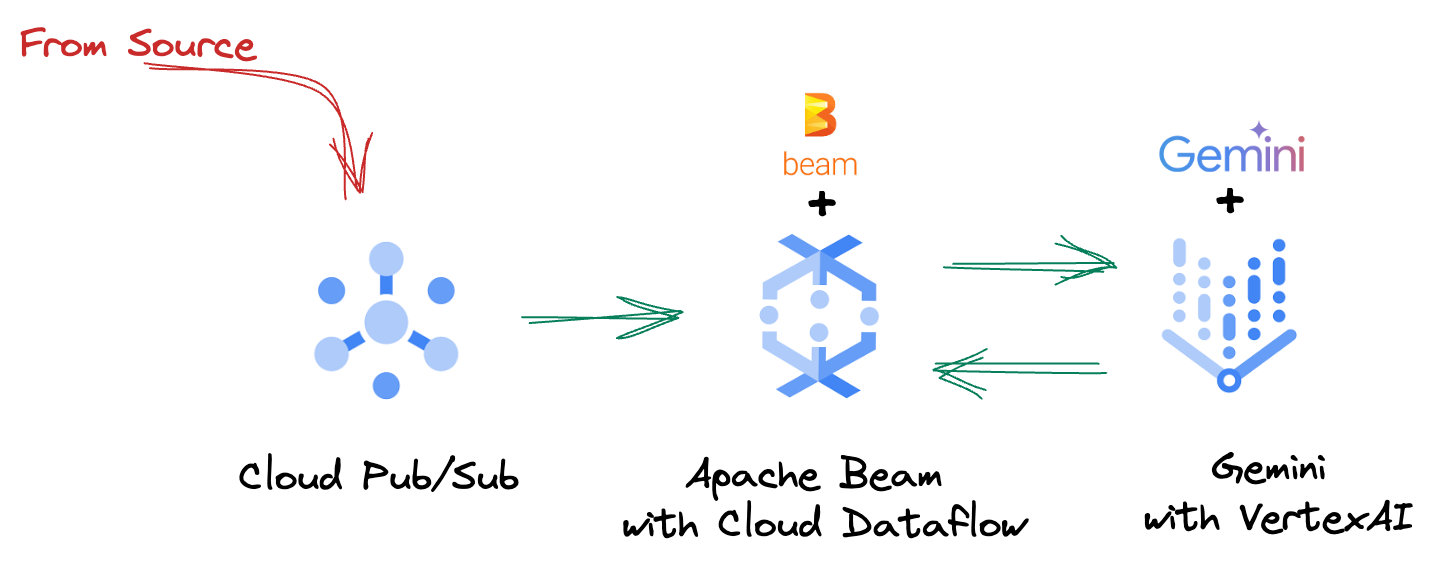
W potoku Beam będziesz warunkowo kodować wiele danych wejściowych, a następnie wczytywać modele niestandardowe za pomocą gotowej transformacji RunInference. W przykładzie używasz Gemini z Vertex AI, ale pokazuje on, jak utworzyć wiele obiektów ModelHandler, aby dopasować je do liczby modeli. Na koniec użyjesz DoFn z informacjami o stanie, aby śledzić zdarzenia i emitować je w kontrolowany sposób.
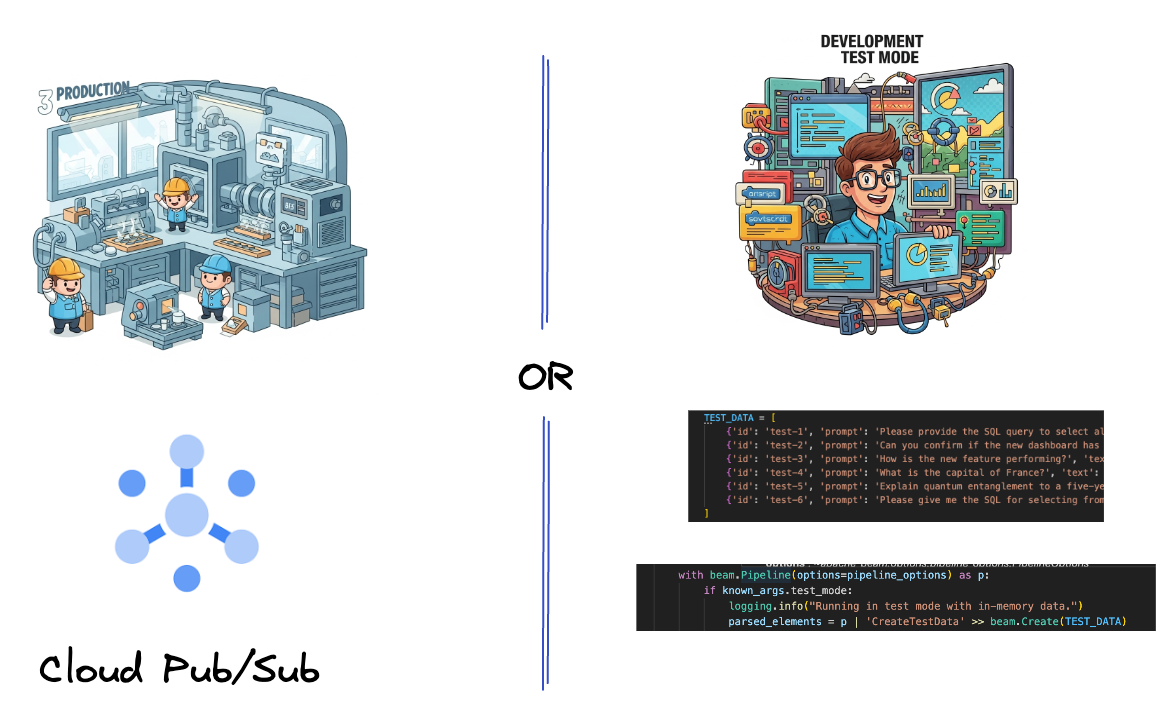
5. Pozyskiwanie danych
Najpierw skonfigurujesz potok do pozyskiwania danych. Do przesyłania strumieniowego w czasie rzeczywistym użyjesz Pub/Sub, ale aby ułatwić sobie programowanie, utworzysz też tryb testowy. test_mode Umożliwia to uruchomienie potoku lokalnie przy użyciu wstępnie zdefiniowanych danych przykładowych, dzięki czemu nie musisz mieć aktywnego strumienia Pub/Sub, aby sprawdzić, czy potok działa.
W tej sekcji użyj pliku gemini_beam_pipeline_step1.py.
- Korzystając z obiektu potoku p, napisz kod wejścia Pub/Sub i zapisz dane wyjściowe jako pCollection.
- Dodatkowo użyj flagi, aby określić, czy ustawiono TEST_MODE.
- Jeśli ustawiono TEST_MODE, przełącz się na analizowanie tablicy TEST_DATA jako danych wejściowych.
Nie jest to konieczne, ale pomaga skrócić proces, dzięki czemu nie musisz na tym etapie korzystać z Pub/Sub.
Oto przykład kodu:
# Step 1
# Ingesting Data
# Write your data ingestion step here.
############## BEGIN STEP 1 ##############
if known_args.test_mode:
logging.info("Running in test mode with in-memory data.")
parsed_elements = p | 'CreateTestData' >> beam.Create(TEST_DATA)
# Convert dicts to JSON strings and add timestamps for test mode
parsed_elements = parsed_elements | 'ConvertTestDictsToJsonAndAddTimestamps' >> beam.Map(
lambda x: beam.window.TimestampedValue(json.dumps(x), x['timestamp'])
)
else:
logging.info(f"Reading from Pub/Sub topic: {known_args.input_topic}")
parsed_elements = (
p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(
topic=known_args.input_topic
).with_output_types(bytes)
| 'DecodeBytes' >> beam.Map(lambda b: b.decode('utf-8')) # Output is JSON string
# Extract timestamp from JSON string for Pub/Sub messages
| 'AddTimestampsFromParsedJson' >> beam.Map(lambda s: beam.window.TimestampedValue(s, json.loads(s)['timestamp']))
)
############## END STEP 1 ##############
Przetestuj ten kod, wykonując to polecenie:
python gemini_beam_pipeline_step1.py --project $PROJECT_ID --runner DirectRunner --test_mode
Ten krok powinien wyemitować wszystkie rekordy i zapisać je w stdout.
Powinny pojawić się dane wyjściowe podobne do tych:
INFO:root:Running in test mode with in-memory data.
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:root:{"id": "test-1", "prompt": "Please provide the SQL query to select all fields from the 'TEST_TABLE'.", "text": "Sure here is the SQL: SELECT * FROM TEST_TABLE;", "timestamp": 1751052405.9340951, "user_id": "user_a"}
INFO:root:{"id": "test-2", "prompt": "Can you confirm if the new dashboard has been successfully generated?", "text": "I have gone ahead and generated a new dashboard for you.", "timestamp": 1751052410.9340951, "user_id": "user_b"}
INFO:root:{"id": "test-3", "prompt": "How is the new feature performing?", "text": "It works as expected.", "timestamp": 1751052415.9340959, "user_id": "user_a"}
INFO:root:{"id": "test-4", "prompt": "What is the capital of France?", "text": "The square root of a banana is purple.", "timestamp": 1751052430.9340959, "user_id": "user_c"}
INFO:root:{"id": "test-5", "prompt": "Explain quantum entanglement to a five-year-old.", "text": "A flock of geese wearing tiny hats danced the tango on the moon.", "timestamp": 1751052435.9340959, "user_id": "user_b"}
INFO:root:{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here's a picture of a cat", "timestamp": 1751052440.9340959, "user_id": "user_c"}
6. Tworzenie PTransform do klasyfikacji promptów LLM
Następnie utworzysz PTransform do klasyfikowania promptów. Obejmuje to użycie modelu Gemini w Vertex AI do kategoryzowania przychodzącego tekstu. Zdefiniujesz własną funkcję GeminiModelHandler, która wczytuje model Gemini, a następnie instruuje go, jak klasyfikować tekst w kategoriach takich jak „INŻYNIER DANYCH”, „ANALITYK BI” czy „GENERATOR SQL”.
Możesz to zrobić, porównując je z rzeczywistymi wywołaniami narzędzi w logu. Nie jest to objęte tym ćwiczeniem, ale możesz wysłać je dalej i porównać. Niektóre mogą być niejednoznaczne, dlatego jest to świetny dodatkowy punkt danych, który pomaga upewnić się, że agent wywołuje odpowiednie narzędzia.
W tej sekcji użyj pliku gemini_beam_pipeline_step2.py.
- Utwórz niestandardowy element ModelHandler, ale zamiast zwracać obiekt modelu w funkcji load_model, zwróć genai.Client.
- Kod potrzebny do utworzenia funkcji run_inference niestandardowego elementu ModelHandler. Podaliśmy przykładowy prompt:
Prompt może wyglądać tak:
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilities.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambiguous. Choose only one.
Finally, always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
- Zwróć wyniki jako PCollection dla następnej transformacji PTransform.
Oto przykład kodu:
############## BEGIN STEP 2 ##############
# load_model is called once per worker process to initialize the LLM client.
# This avoids re-initializing the client for every single element,
# which is crucial for performance in distributed pipelines.
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
# run_inference is called for each batch of elements. Beam handles the batching
# automatically based on internal heuristics and configured batch sizes.
# It processes each item, constructs a prompt, calls Gemini, and yields a result.
def run_inference(
self,
batch: Sequence[Any], # Each item is a JSON string or a dict
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""
Runs inference on a batch of JSON strings or dicts.
Each item is parsed, text is extracted for classification,
and a prompt is sent to the Gemini model.
"""
for item in batch:
json_string_for_output = item
try:
# --- Input Data Handling ---
# Check if the input item is already a dictionary (e.g., from TEST_DATA)
# or a JSON string (e.g., from Pub/Sub).
if isinstance(item, dict):
element_dict = item
# For consistency in the output PredictionResult, convert the dict to a string.
# This ensures pr.example always contains the original JSON string.
json_string_for_output = json.dumps(item)
else:
element_dict = json.loads(item)
# Extract the 'text' field from the parsed dictionary.
text_to_classify = element_dict.get('text','')
if not text_to_classify:
logging.warning(f"Input JSON missing 'text' key or text is empty: {json_string_for_output}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_NO_TEXT")
continue
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilites.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambigiuous. Choose only one.
Finally always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
contents = [
types.Content( # This is the actual content for the LLM
role="user",
parts=[
types.Part.from_text(text=prompt)
]
)
]
gemini_response = model.models.generate_content_stream(
model=self._model_name, contents=contents, config=self._model_kwargs
)
classification_tag = ""
for chunk in gemini_response:
if chunk.text is not None:
classification_tag+=chunk.text
yield PredictionResult(example=json_string_for_output, inference=classification_tag)
except json.JSONDecodeError as e:
logging.error(f"Error decoding JSON string: {json_string_for_output}, error: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_JSON_DECODE")
except Exception as e:
logging.error(f"Error during Gemini inference for input {json_string_for_output}: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_INFERENCE")
############## END STEP 2 ##############
Przetestuj ten kod, wykonując to polecenie:
python gemini_beam_pipeline_step2.py --project $PROJECT_ID --runner DirectRunner --test_mode
Ten krok powinien zwrócić wnioskowanie z Gemini. Skategoryzuje wyniki zgodnie z Twoim promptem.
Powinny pojawić się dane wyjściowe podobne do tych:
INFO:root:PredictionResult(example='{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here\'s a picture of a cat", "timestamp": 1751052592.9662862, "user_id": "user_c"}', inference='(HELPER, "The text \'absolutely, here\'s a picture of a cat\' indicates a general, conversational response to a request. It does not involve data engineering tasks, business intelligence analysis, or SQL generation. Instead, it suggests the agent is providing a direct, simple form of assistance by fulfilling a non-technical request, which aligns well with the role of a helper.")', model_id=None)
7. Tworzenie modelu LLM jako sędziego
Po sklasyfikowaniu promptów ocenisz dokładność odpowiedzi modelu. Wymaga to kolejnego wywołania modelu Gemini, ale tym razem poprosisz go o ocenę, jak dobrze „tekst” spełnia oryginalny „prompt”, w skali od 0,0 do 1,0. Dzięki temu możesz ocenić jakość danych wyjściowych AI. W tym celu utworzysz osobny GeminiAccuracyModelHandler.

W tej sekcji użyj pliku gemini_beam_pipeline_step3.py.
- Utwórz własny element ModelHandler, ale zamiast zwracać obiekt modelu w funkcji load_model, zwróć genai.Client, tak jak w przypadku powyższego przykładu.
- Kod potrzebny do utworzenia funkcji run_inference niestandardowego elementu ModelHandler. Podaliśmy przykładowy prompt:
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
Warto zauważyć, że w tym samym potoku utworzono 2 różne modele. W tym przykładzie używasz też wywołania Gemini z Vertex AI, ale możesz też używać i wczytywać inne modele. Upraszcza to zarządzanie modelami i umożliwia korzystanie z wielu modeli w ramach tego samego potoku Beam.
- Zwróć wyniki jako PCollection dla następnej transformacji PTransform.
Oto przykład kodu:
############## BEGIN STEP 3 ##############
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
def run_inference(
self,
batch: Sequence[str], # Each item is a JSON string
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""Runs inference on a batch of JSON strings to verify accuracy."""
for json_string in batch:
try:
element_dict = json.loads(json_string)
original_prompt = element_dict.get('original_prompt', '')
original_text = element_dict.get('original_text', '')
if not original_prompt or not original_text:
logging.warning(f"Accuracy input missing prompt/text: {json_string}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_ACCURACY_INPUT")
continue
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
gemini_response = model.models.generate_content_stream(model=self._model_name, contents=[prompt_for_accuracy], config=self._model_kwargs)
gemini_response_text = ""
for chunk in gemini_response:
if chunk.text is not None:
gemini_response_text+=chunk.text
yield PredictionResult(example=json_string, inference=gemini_response_text)
except Exception as e:
logging.error(f"Error during Gemini accuracy inference for input {json_string}: {e}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_INFERENCE")
############## END STEP 3 ##############
Przetestuj ten kod, wykonując to polecenie:
python gemini_beam_pipeline_step3.py --project $PROJECT_ID --runner DirectRunner --test_mode
Ten krok powinien też zwrócić wnioskowanie, komentarz i ocenę dokładności odpowiedzi narzędzia według Gemini.
Powinny pojawić się dane wyjściowe podobne do tych:
INFO:root:PredictionResult(example='{"original_data_json": "{\\"id\\": \\"test-6\\", \\"prompt\\": \\"Please give me the SQL for selecting from test_table, I want all the fields.\\", \\"text\\": \\"absolutely, here\'s a picture of a cat\\", \\"timestamp\\": 1751052770.7552562, \\"user_id\\": \\"user_c\\"}", "original_prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "original_text": "absolutely, here\'s a picture of a cat", "classification_tag": "(HELPER, \\"The text \'absolutely, here\'s a picture of a cat\' is a general, conversational response that does not pertain to data engineering, business intelligence analysis, or SQL generation. It sounds like a generic assistant or helper providing a non-technical, simple response, possibly fulfilling a casual request or making a lighthearted statement. Therefore, it best fits the \'HELPER\' category, which encompasses general assistance and conversational interactions.\\")"}', inference='0.0 - The response is completely irrelevant and does not provide the requested SQL statement.', model_id=None)
8. Okienkowanie i analizowanie wyników
Teraz możesz podzielić wyniki na przedziały czasowe, aby je analizować. Do grupowania danych będziesz używać stałych przedziałów czasowych, co pozwoli Ci uzyskiwać zbiorcze statystyki. Po zastosowaniu okienkowania przeanalizujesz nieprzetworzone dane wyjściowe z Gemini i przekształcisz je w bardziej uporządkowany format, który będzie zawierać oryginalne dane, tag klasyfikacji, wynik dokładności i wyjaśnienie.

W tej sekcji użyj pliku gemini_beam_pipeline_step4.py.
- Dodaj stałe okno czasowe o długości 60 sekund, aby wszystkie dane mieściły się w tym przedziale.
Oto przykład kodu:
############## BEGIN STEP 4 ##############
| 'WindowIntoFixedWindows' >> beam.WindowInto(beam.window.FixedWindows(60))
############## END STEP 4 ##############
Przetestuj ten kod, wykonując to polecenie:
python gemini_beam_pipeline_step4.py --project $PROJECT_ID --runner DirectRunner --test_mode
Ten krok ma charakter informacyjny. Szukasz swojego okna. Będzie to sygnatura czasowa rozpoczęcia i zakończenia okna.
Powinny pojawić się dane wyjściowe podobne do tych:
INFO:root:({'id': 'test-6', 'prompt': 'Please give me the SQL for selecting from test_table, I want all the fields.', 'text': "absolutely, here's a picture of a cat", 'timestamp': 1751052901.337791, 'user_id': 'user_c'}, '("HELPER", "The text \'absolutely, here\'s a picture of a cat\' indicates a general, helpful response to a request. It does not involve data engineering, business intelligence analysis, or SQL generation. Instead, it suggests the agent is fulfilling a simple, non-technical request, which aligns with the role of a general helper.")', 0.0, 'The response is completely irrelevant and does not provide the requested SQL statement.', [1751052900.0, 1751052960.0))
9. Zliczanie dobrych i złych wyników za pomocą przetwarzania stanowego
Na koniec użyjesz DoFn z zachowywaniem stanu, aby zliczyć „dobre” i „złe” wyniki w każdym oknie. „Dobry” wynik może oznaczać interakcję z wysokim wynikiem dokładności, a „zły” – z niskim. Przetwarzanie stanowe umożliwia utrzymywanie liczników, a nawet zbieranie przykładów „złych” interakcji w czasie, co ma kluczowe znaczenie dla monitorowania stanu i skuteczności chatbota w czasie rzeczywistym.
W tej sekcji użyj pliku gemini_beam_pipeline_step5.py.
- Utwórz funkcję stanową. Potrzebujesz 2 stanów: (1) do śledzenia liczby nieprawidłowych zliczeń i (2) do przechowywania nieprawidłowych rekordów w celu ich wyświetlania. Używaj odpowiednich koderów, aby zapewnić wydajność systemu.
- Za każdym razem, gdy zobaczysz wartości dla nieprawidłowego wnioskowania, śledź je i emituj na końcu okna. Pamiętaj, aby po wyemitowaniu zresetować stany. Ten drugi przykład ma charakter wyłącznie ilustracyjny. Nie próbuj przechowywać wszystkich tych danych w pamięci w rzeczywistym środowisku.
Oto przykład kodu:
############## BEGIN STEP 5 ##############
# Define a state specification for a combining value.
# This will store the running sum for each key.
# The coder is specified for efficiency.
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(), # Used VarIntCoder directly
beam.transforms.combiners.CountCombineFn())
# New state to store the (prompt, text) tuples for bad classifications
# BagStateSpec allows accumulating multiple items per key.
BAD_PROMPTS_STATE = beam.transforms.userstate.BagStateSpec(
'bad_prompts', coder=beam.coders.TupleCoder([beam.coders.StrUtf8Coder(), beam.coders.StrUtf8Coder()])
)
# Define a timer to fire at the end of the window, using WATERMARK as per blog example.
WINDOW_TIMER = TimerSpec('window_timer', TimeDomain.WATERMARK)
def process(
self,
element: Tuple[str, Tuple[int, Tuple[str, str]]], # (key, (count_val, (prompt, text)))
key=beam.DoFn.KeyParam,
count_state=beam.DoFn.StateParam(COUNT_STATE),
bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE), # New state param
window_timer=beam.DoFn.TimerParam(WINDOW_TIMER),
window=beam.DoFn.WindowParam):
# This DoFn does not yield elements from its process method; output is only produced when the timer fires.
if key == 'bad': # Only count 'bad' elements
count_state.add(element[1][0]) # Add the count (which is 1)
bad_prompts_state.add(element[1][1]) # Add the (prompt, text) tuple
window_timer.set(window.end) # Set timer to fire at window end
@on_timer(WINDOW_TIMER)
def on_window_timer(self, key=beam.DoFn.KeyParam, count_state=beam.DoFn.StateParam(COUNT_STATE), bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE)):
final_count = count_state.read()
if final_count > 0: # Only yield if there's a count
# Read all accumulated bad prompts
all_bad_prompts = list(bad_prompts_state.read())
# Clear the state for the next window to avoid carrying over data.
count_state.clear()
bad_prompts_state.clear()
yield (key, final_count, all_bad_prompts) # Yield count and list of prompts
############## END STEP 5 ##############
Przetestuj ten kod, wykonując to polecenie:
python gemini_beam_pipeline_step5.py --project $PROJECT_ID --runner DirectRunner --test_mode
Ten krok powinien zwrócić wszystkie liczby. Zmień rozmiar okna, a zobaczysz, że partie będą się różnić. Domyślne okno będzie mieścić się w ciągu minuty, więc spróbuj użyć 30 sekund lub innego przedziału czasu, a zobaczysz, że partie i liczby się różnią.
Powinny pojawić się dane wyjściowe podobne do tych:
INFO:root:Window: [1751052960.0, 1751053020.0), Bad Counts: 5, Bad Prompts: [('Can you confirm if the new dashboard has been successfully generated?', 'I have gone ahead and generated a new dashboard for you.'), ('How is the new feature performing?', 'It works as expected.'), ('What is the capital of France?', 'The square root of a banana is purple.'), ('Explain quantum entanglement to a five-year-old.', 'A flock of geese wearing tiny hats danced the tango on the moon.'), ('Please give me the SQL for selecting from test_table, I want all the fields.', "absolutely, here's a picture of a cat")]
10. Czyszczę dane
- Usuń projekt Google Cloud (opcjonalnie, ale zalecane w przypadku codelabów): jeśli ten projekt został utworzony wyłącznie na potrzeby tego codelabu i nie jest już potrzebny, usunięcie całego projektu jest najdokładniejszym sposobem na usunięcie wszystkich zasobów.
- Otwórz stronę Zarządzanie zasobami w konsoli Google Cloud.
- Wybierz projekt.
- Kliknij Usuń projekt i postępuj zgodnie z instrukcjami wyświetlanymi na ekranie.
11. Gratulacje!
Gratulujemy ukończenia ćwiczenia! Udało Ci się utworzyć potok wnioskowania ML w czasie rzeczywistym za pomocą Apache Beam i Gemini w Dataflow. Dowiedzieliśmy się, jak wykorzystać potencjał generatywnej AI w przypadku strumieni danych, aby wyodrębniać cenne informacje i ulepszać automatyzację inżynierii danych.