
1. Introdução
No cenário de dados acelerado de hoje, os insights em tempo real são cruciais para tomar decisões fundamentadas. Neste codelab, você vai aprender a criar um pipeline de avaliação em tempo real. Vamos começar usando o framework do Apache Beam, que oferece um modelo de programação unificado para dados em lote e de streaming. Isso simplifica significativamente o desenvolvimento de pipelines ao abstrair a lógica complexa de computação distribuída que você teria que criar do zero. Depois que o pipeline é definido usando o Beam, ele é executado sem problemas no Google Cloud Dataflow, um serviço totalmente gerenciado que oferece escalonamento e desempenho incomparáveis para suas necessidades de processamento de dados.
Neste codelab, você vai aprender a arquitetar um pipeline escalonável do Apache Beam para inferência de machine learning, desenvolver um ModelHandler personalizado para integrar o modelo Gemini da Vertex AI, aproveitar a engenharia de comandos para classificação inteligente de texto em fluxos de dados e implantar e operar esse pipeline de inferência de ML de streaming no Google Cloud Dataflow. Ao final, você vai receber insights valiosos sobre a aplicação do aprendizado de máquina para o entendimento de dados em tempo real e a avaliação contínua em fluxos de trabalho de engenharia, principalmente para manter uma IA de conversa robusta e focada no usuário.
Cenário
Sua empresa criou um agente de dados. Seu agente de dados, criado com o Kit de Desenvolvimento de Agente (ADK), está equipado com vários recursos especializados para ajudar em tarefas relacionadas a dados. Imagine como um assistente de dados versátil, pronto para lidar com diversas solicitações, desde atuar como um analista de BI para gerar relatórios úteis até um engenheiro de dados ajudando você a criar pipelines de dados robustos ou um gerador de SQL criando instruções SQL precisas e muito mais. Cada interação e resposta gerada pelo agente é armazenada automaticamente no Firestore. Mas por que precisamos de um pipeline aqui?
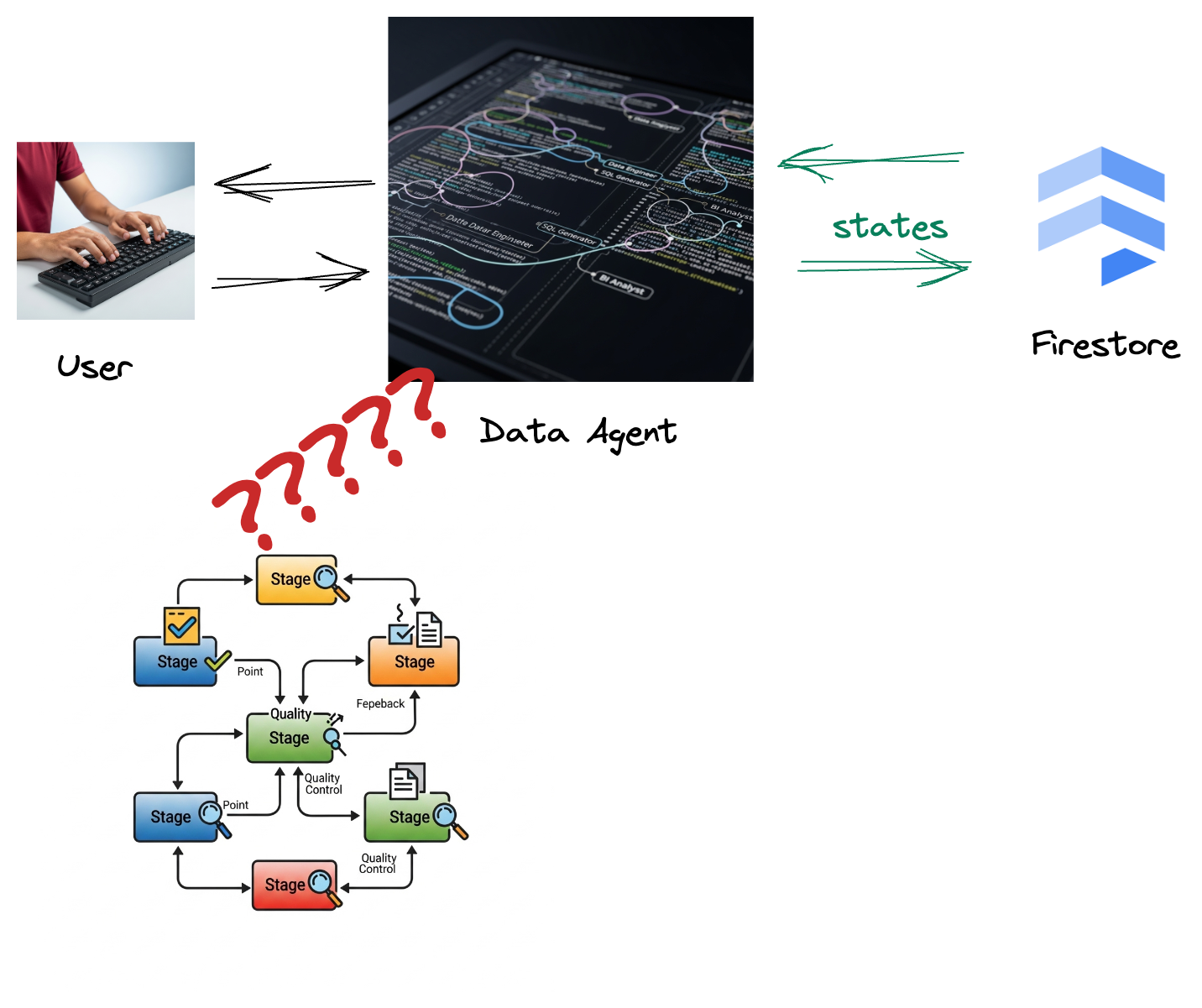
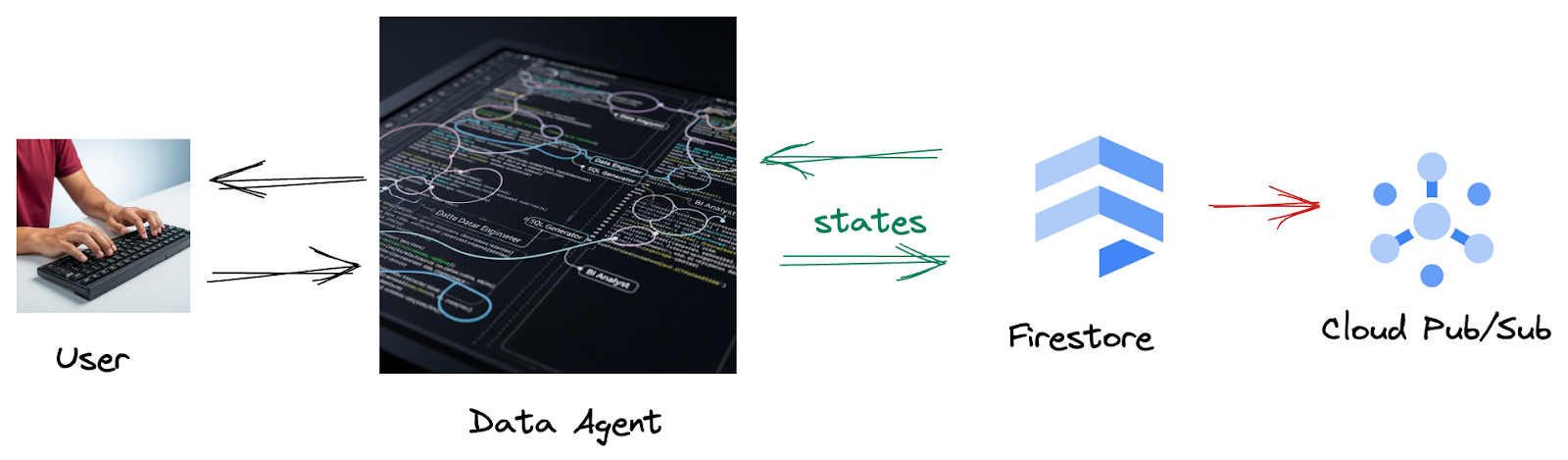
Isso porque, do Firestore, um gatilho envia esses dados de interação ao Pub/Sub, garantindo que possamos processar e analisar imediatamente essas conversas importantes em tempo real.
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Confira se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
- Clique neste link para ativar o Cloud Shell. É possível alternar entre o terminal do Cloud Shell (para executar comandos da nuvem) e o editor (para criar projetos) clicando no botão correspondente no Cloud Shell.
- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com o ID do seu projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
- Ative as APIs necessárias com o comando mostrado abaixo. Isso pode levar alguns minutos.
gcloud services enable \
dataflow.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Verifique se você tem o Python 3.10 ou uma versão mais recente.
- Instalar pacotes Python
Instale as bibliotecas Python necessárias para o Apache Beam, a Vertex AI do Google Cloud e a IA generativa do Google no seu ambiente do Cloud Shell.
pip install apache-beam[gcp] google-genai
- Clone o repositório do GitHub e mude para o diretório de demonstração.
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/beam_as_eval
Consulte a documentação para ver o uso e os comandos gcloud.
3. Como usar o repositório do GitHub fornecido
O repositório do GitHub associado a este codelab, encontrado em https://github.com/GoogleCloudPlatform/devrel-demos/tree/main/data-analytics/beam_as_eval , está organizado para facilitar uma experiência de aprendizado guiado. Ele contém um código de esqueleto que se alinha a cada parte distinta do codelab, garantindo uma progressão clara pelo material.
No repositório, você vai encontrar duas pastas principais: "complete" e "incomplete". A pasta "complete" contém código totalmente funcional para cada etapa, permitindo que você execute e observe a saída pretendida. Por outro lado, a pasta "incomplete" fornece código das etapas anteriores, deixando seções específicas marcadas entre ##### START STEP <NUMBER> ##### e ##### END STEP <NUMBER> ##### para você concluir como parte dos exercícios. Essa estrutura permite que você use o conhecimento prévio enquanto participa ativamente dos desafios de programação.
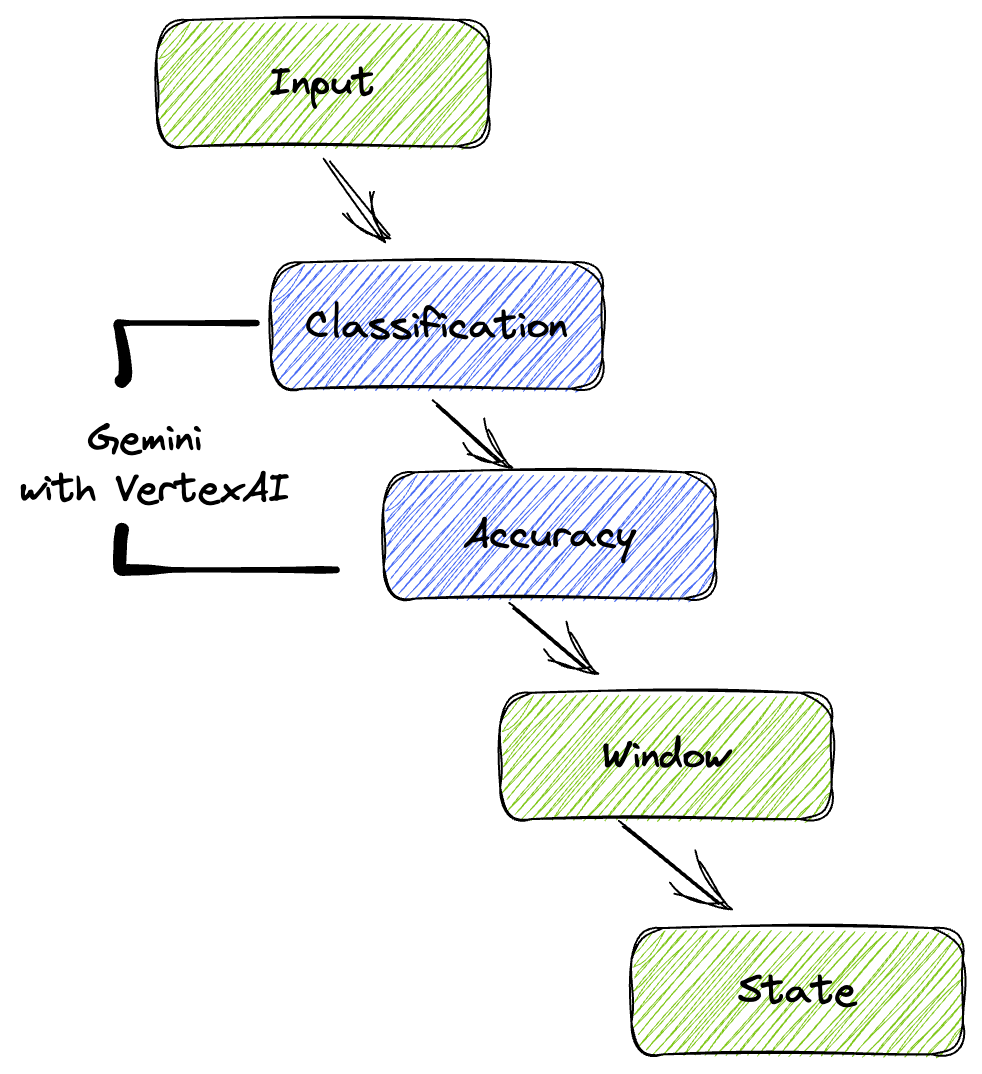
4. Visão geral da arquitetura
Nosso pipeline oferece um padrão avançado e escalonável para integrar a inferência de ML aos fluxos de dados. Confira como as peças se encaixam:
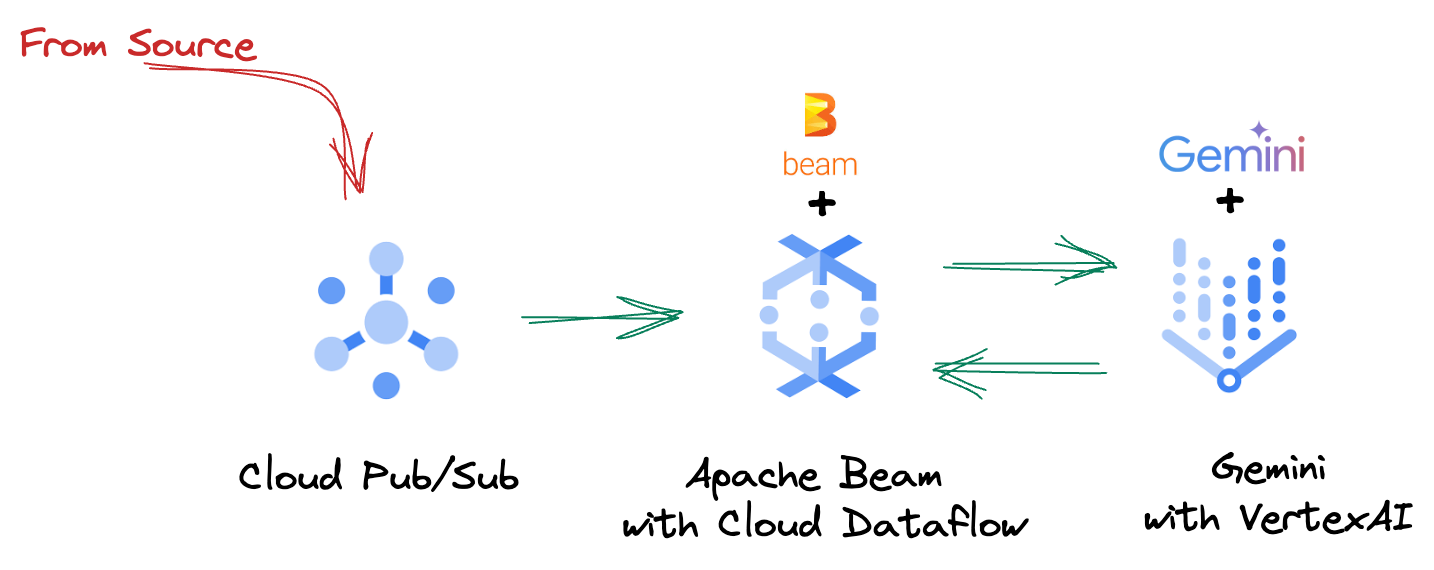
No pipeline do Beam, você vai programar várias entradas de forma condicional e carregar modelos personalizados com a transformação pronta para uso RunInference. Embora você use o Gemini com a Vertex AI no exemplo, ele demonstra como você essencialmente criaria vários ModelHandlers para se adequar ao número de modelos que você tem. Por fim, você vai usar uma DoFn com estado para acompanhar e emitir eventos de maneira controlada.
5. Ingestão de dados
Primeiro, você vai configurar o pipeline para ingerir dados. Você vai usar o Pub/Sub para streaming em tempo real, mas, para facilitar o desenvolvimento, também vai criar um modo de teste. Esse test_mode permite executar o pipeline localmente usando dados de amostra predefinidos. Assim, você não precisa de um fluxo do Pub/Sub ativo para verificar se o pipeline funciona.
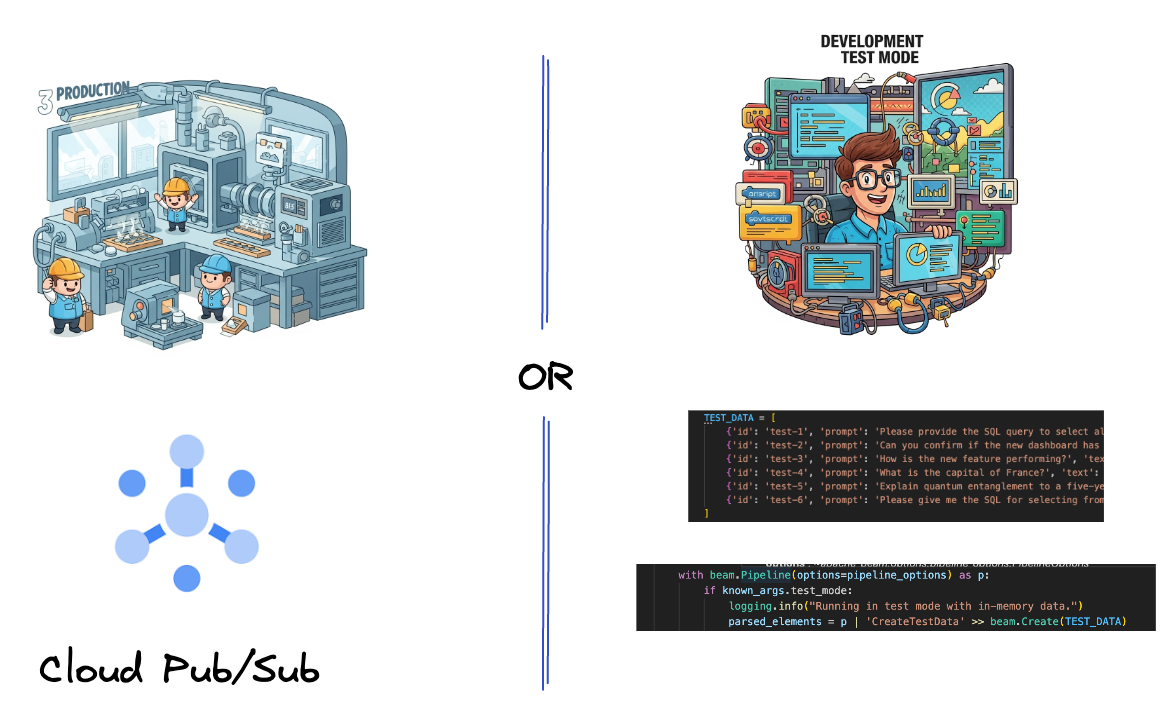
Para esta seção, use gemini_beam_pipeline_step1.py.
- Usando o objeto de pipeline fornecido p, codifique uma entrada do Pub/Sub e grave a saída como uma pCollection.
- Além disso, use uma flag para determinar se TEST_MODE foi definido.
- Se TEST_MODE estiver definido, mude para analisar a matriz TEST_DATA como uma entrada.
Isso não é necessário, mas ajuda a encurtar o processo para que você não precise envolver o Pub/Sub tão cedo.
Confira um exemplo do código abaixo:
# Step 1
# Ingesting Data
# Write your data ingestion step here.
############## BEGIN STEP 1 ##############
if known_args.test_mode:
logging.info("Running in test mode with in-memory data.")
parsed_elements = p | 'CreateTestData' >> beam.Create(TEST_DATA)
# Convert dicts to JSON strings and add timestamps for test mode
parsed_elements = parsed_elements | 'ConvertTestDictsToJsonAndAddTimestamps' >> beam.Map(
lambda x: beam.window.TimestampedValue(json.dumps(x), x['timestamp'])
)
else:
logging.info(f"Reading from Pub/Sub topic: {known_args.input_topic}")
parsed_elements = (
p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(
topic=known_args.input_topic
).with_output_types(bytes)
| 'DecodeBytes' >> beam.Map(lambda b: b.decode('utf-8')) # Output is JSON string
# Extract timestamp from JSON string for Pub/Sub messages
| 'AddTimestampsFromParsedJson' >> beam.Map(lambda s: beam.window.TimestampedValue(s, json.loads(s)['timestamp']))
)
############## END STEP 1 ##############
Teste este código executando:
python gemini_beam_pipeline_step1.py --project $PROJECT_ID --runner DirectRunner --test_mode
Essa etapa precisa emitir todos os registros, fazendo o registro em stdout.
A saída será semelhante a esta:
INFO:root:Running in test mode with in-memory data.
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:root:{"id": "test-1", "prompt": "Please provide the SQL query to select all fields from the 'TEST_TABLE'.", "text": "Sure here is the SQL: SELECT * FROM TEST_TABLE;", "timestamp": 1751052405.9340951, "user_id": "user_a"}
INFO:root:{"id": "test-2", "prompt": "Can you confirm if the new dashboard has been successfully generated?", "text": "I have gone ahead and generated a new dashboard for you.", "timestamp": 1751052410.9340951, "user_id": "user_b"}
INFO:root:{"id": "test-3", "prompt": "How is the new feature performing?", "text": "It works as expected.", "timestamp": 1751052415.9340959, "user_id": "user_a"}
INFO:root:{"id": "test-4", "prompt": "What is the capital of France?", "text": "The square root of a banana is purple.", "timestamp": 1751052430.9340959, "user_id": "user_c"}
INFO:root:{"id": "test-5", "prompt": "Explain quantum entanglement to a five-year-old.", "text": "A flock of geese wearing tiny hats danced the tango on the moon.", "timestamp": 1751052435.9340959, "user_id": "user_b"}
INFO:root:{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here's a picture of a cat", "timestamp": 1751052440.9340959, "user_id": "user_c"}
6. Como criar uma PTransform para classificação de comandos de LLM
Em seguida, você vai criar uma PTransform para classificar comandos. Isso envolve o uso do modelo Gemini da Vertex AI para categorizar o texto recebido. Você vai definir um GeminiModelHandler personalizado que carrega o modelo do Gemini e o instrui a classificar o texto em categorias como "ENGENHEIRO DE DADOS", "ANALISTA DE BI" ou "GERADOR DE SQL".
Para usar isso, compare com as chamadas de função reais no registro. Isso não é abordado neste codelab, mas você pode enviar para baixo e comparar. Alguns podem ser ambíguos, e isso serve como um ótimo ponto de dados adicional para garantir que o agente esteja chamando as ferramentas certas.
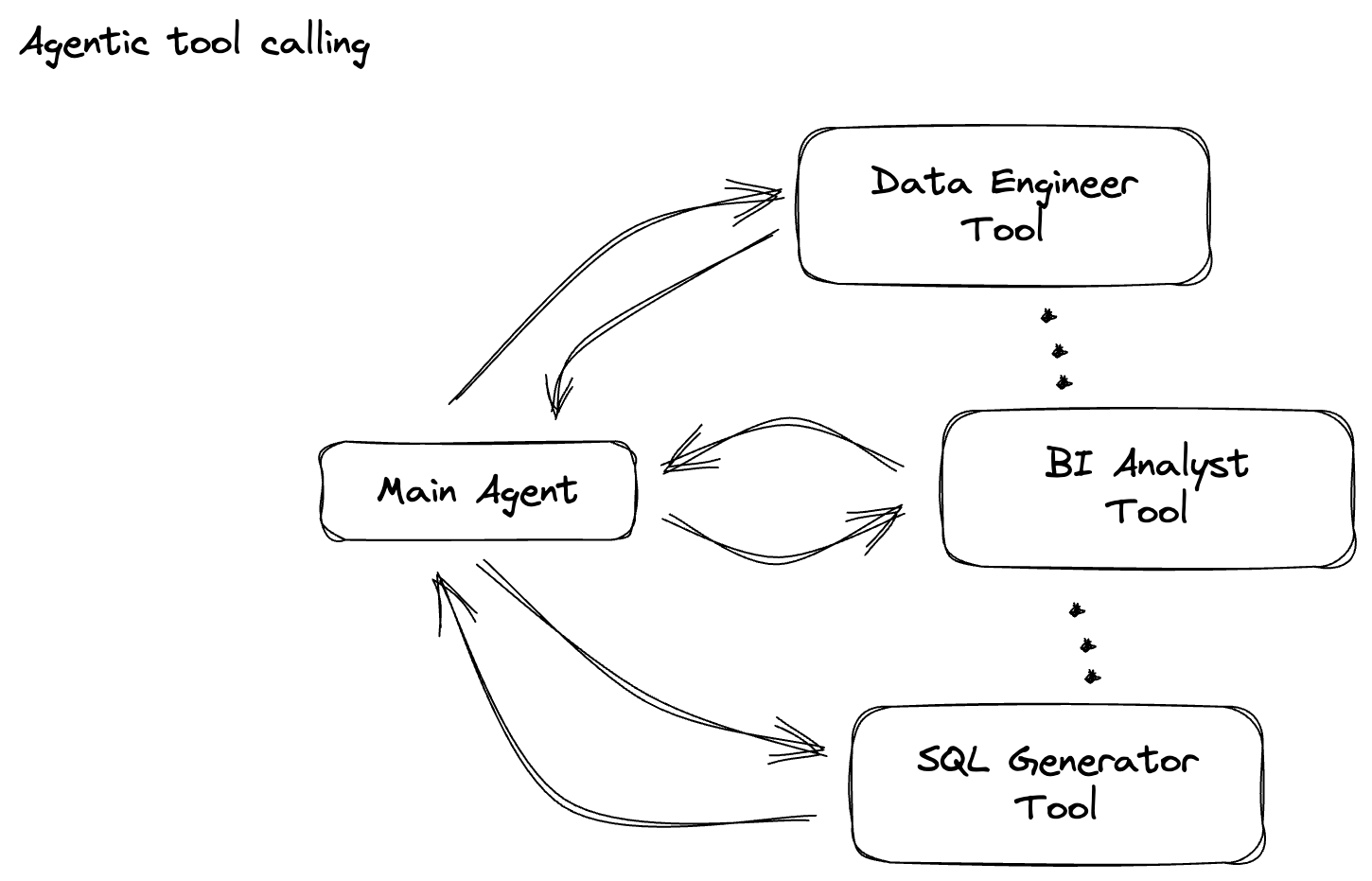
Para esta seção, use gemini_beam_pipeline_step2.py.
- Crie seu ModelHandler personalizado. No entanto, em vez de retornar um objeto de modelo em load_model, retorne o genai.Client.
- Código necessário para criar a função run_inference do ModelHandler personalizado. Um exemplo de comando foi fornecido:
O comando pode ser algo como:
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilities.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambiguous. Choose only one.
Finally, always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
- Gere os resultados como uma PCollection para a próxima PTransform.
Confira um exemplo do código abaixo:
############## BEGIN STEP 2 ##############
# load_model is called once per worker process to initialize the LLM client.
# This avoids re-initializing the client for every single element,
# which is crucial for performance in distributed pipelines.
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
# run_inference is called for each batch of elements. Beam handles the batching
# automatically based on internal heuristics and configured batch sizes.
# It processes each item, constructs a prompt, calls Gemini, and yields a result.
def run_inference(
self,
batch: Sequence[Any], # Each item is a JSON string or a dict
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""
Runs inference on a batch of JSON strings or dicts.
Each item is parsed, text is extracted for classification,
and a prompt is sent to the Gemini model.
"""
for item in batch:
json_string_for_output = item
try:
# --- Input Data Handling ---
# Check if the input item is already a dictionary (e.g., from TEST_DATA)
# or a JSON string (e.g., from Pub/Sub).
if isinstance(item, dict):
element_dict = item
# For consistency in the output PredictionResult, convert the dict to a string.
# This ensures pr.example always contains the original JSON string.
json_string_for_output = json.dumps(item)
else:
element_dict = json.loads(item)
# Extract the 'text' field from the parsed dictionary.
text_to_classify = element_dict.get('text','')
if not text_to_classify:
logging.warning(f"Input JSON missing 'text' key or text is empty: {json_string_for_output}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_NO_TEXT")
continue
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilites.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambigiuous. Choose only one.
Finally always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
contents = [
types.Content( # This is the actual content for the LLM
role="user",
parts=[
types.Part.from_text(text=prompt)
]
)
]
gemini_response = model.models.generate_content_stream(
model=self._model_name, contents=contents, config=self._model_kwargs
)
classification_tag = ""
for chunk in gemini_response:
if chunk.text is not None:
classification_tag+=chunk.text
yield PredictionResult(example=json_string_for_output, inference=classification_tag)
except json.JSONDecodeError as e:
logging.error(f"Error decoding JSON string: {json_string_for_output}, error: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_JSON_DECODE")
except Exception as e:
logging.error(f"Error during Gemini inference for input {json_string_for_output}: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_INFERENCE")
############## END STEP 2 ##############
Teste este código executando:
python gemini_beam_pipeline_step2.py --project $PROJECT_ID --runner DirectRunner --test_mode
Essa etapa vai retornar uma inferência do Gemini. Ele vai classificar os resultados conforme solicitado no comando.
A saída será semelhante a esta:
INFO:root:PredictionResult(example='{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here\'s a picture of a cat", "timestamp": 1751052592.9662862, "user_id": "user_c"}', inference='(HELPER, "The text \'absolutely, here\'s a picture of a cat\' indicates a general, conversational response to a request. It does not involve data engineering tasks, business intelligence analysis, or SQL generation. Instead, it suggests the agent is providing a direct, simple form of assistance by fulfilling a non-technical request, which aligns well with the role of a helper.")', model_id=None)
7. Como criar um LLM como juiz
Depois de classificar os comandos, você vai avaliar a acurácia das respostas do modelo. Isso envolve outra chamada ao modelo do Gemini, mas desta vez, você vai pedir que ele avalie o quanto o "texto" atende ao "comando" original em uma escala de 0,0 a 1,0. Isso ajuda você a entender a qualidade da saída da IA. Você vai criar um GeminiAccuracyModelHandler separado para essa tarefa.

Para esta seção, use gemini_beam_pipeline_step3.py.
- Crie seu ModelHandler personalizado. No entanto, em vez de retornar um objeto de modelo em load_model, retorne o genai.Client como fez acima.
- Código necessário para criar a função run_inference do ModelHandler personalizado. Um exemplo de comando foi fornecido:
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
Uma coisa importante a observar é que você criou dois modelos diferentes no mesmo pipeline. Neste exemplo específico, você também está usando uma chamada do Gemini com a Vertex AI, mas, no mesmo conceito, é possível usar e carregar outros modelos. Isso simplifica o gerenciamento de modelos e permite usar vários modelos no mesmo pipeline do Beam.
- Gere os resultados como uma PCollection para a próxima PTransform.
Confira um exemplo do código abaixo:
############## BEGIN STEP 3 ##############
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
def run_inference(
self,
batch: Sequence[str], # Each item is a JSON string
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""Runs inference on a batch of JSON strings to verify accuracy."""
for json_string in batch:
try:
element_dict = json.loads(json_string)
original_prompt = element_dict.get('original_prompt', '')
original_text = element_dict.get('original_text', '')
if not original_prompt or not original_text:
logging.warning(f"Accuracy input missing prompt/text: {json_string}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_ACCURACY_INPUT")
continue
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
gemini_response = model.models.generate_content_stream(model=self._model_name, contents=[prompt_for_accuracy], config=self._model_kwargs)
gemini_response_text = ""
for chunk in gemini_response:
if chunk.text is not None:
gemini_response_text+=chunk.text
yield PredictionResult(example=json_string, inference=gemini_response_text)
except Exception as e:
logging.error(f"Error during Gemini accuracy inference for input {json_string}: {e}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_INFERENCE")
############## END STEP 3 ##############
Teste este código executando:
python gemini_beam_pipeline_step3.py --project $PROJECT_ID --runner DirectRunner --test_mode
Essa etapa também precisa retornar uma inferência, um comentário e uma pontuação sobre a acurácia da resposta da ferramenta na opinião do Gemini.
A saída será semelhante a esta:
INFO:root:PredictionResult(example='{"original_data_json": "{\\"id\\": \\"test-6\\", \\"prompt\\": \\"Please give me the SQL for selecting from test_table, I want all the fields.\\", \\"text\\": \\"absolutely, here\'s a picture of a cat\\", \\"timestamp\\": 1751052770.7552562, \\"user_id\\": \\"user_c\\"}", "original_prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "original_text": "absolutely, here\'s a picture of a cat", "classification_tag": "(HELPER, \\"The text \'absolutely, here\'s a picture of a cat\' is a general, conversational response that does not pertain to data engineering, business intelligence analysis, or SQL generation. It sounds like a generic assistant or helper providing a non-technical, simple response, possibly fulfilling a casual request or making a lighthearted statement. Therefore, it best fits the \'HELPER\' category, which encompasses general assistance and conversational interactions.\\")"}', inference='0.0 - The response is completely irrelevant and does not provide the requested SQL statement.', model_id=None)
8. Janelamento e análise de resultados
Agora, você vai criar janelas de resultados para analisá-los em intervalos de tempo específicos. Você vai usar janelas fixas para agrupar dados e receber insights agregados. Depois do janelamento, você vai analisar as saídas brutas do Gemini em um formato mais estruturado, incluindo os dados originais, a tag de classificação, a pontuação de acurácia e a explicação.

Para esta seção, use gemini_beam_pipeline_step4.py.
- Adicione uma janela de tempo fixa de 60 segundos para que todos os dados sejam colocados em uma janela de 60 segundos.
Confira um exemplo do código abaixo:
############## BEGIN STEP 4 ##############
| 'WindowIntoFixedWindows' >> beam.WindowInto(beam.window.FixedWindows(60))
############## END STEP 4 ##############
Teste este código executando:
python gemini_beam_pipeline_step4.py --project $PROJECT_ID --runner DirectRunner --test_mode
Esta etapa é informativa. Você está procurando sua janela. Isso vai aparecer como um carimbo de data/hora de parada/início da janela.
A saída será semelhante a esta:
INFO:root:({'id': 'test-6', 'prompt': 'Please give me the SQL for selecting from test_table, I want all the fields.', 'text': "absolutely, here's a picture of a cat", 'timestamp': 1751052901.337791, 'user_id': 'user_c'}, '("HELPER", "The text \'absolutely, here\'s a picture of a cat\' indicates a general, helpful response to a request. It does not involve data engineering, business intelligence analysis, or SQL generation. Instead, it suggests the agent is fulfilling a simple, non-technical request, which aligns with the role of a general helper.")', 0.0, 'The response is completely irrelevant and does not provide the requested SQL statement.', [1751052900.0, 1751052960.0))
9. Contagem de resultados bons e ruins com processamento com estado
Por fim, você vai usar uma DoFn com estado para contar os resultados "bons" e "ruins" em cada janela. Um resultado "bom" pode ser uma interação com uma pontuação de alta precisão, enquanto um resultado "ruim" indica uma pontuação baixa. Esse processamento com estado permite manter contagens e até mesmo coletar exemplos de interações "ruins" ao longo do tempo, o que é crucial para monitorar a integridade e o desempenho do chatbot em tempo real.
Para esta seção, use gemini_beam_pipeline_step5.py.
- Crie uma função com estado. Você vai precisar de dois estados: (1) para acompanhar o número de contagens incorretas e (2) para manter os registros incorretos a serem mostrados. Use os codificadores adequados para garantir que o sistema tenha um bom desempenho.
- Cada vez que você vê os valores de uma inferência ruim, é importante acompanhar os dois e emiti-los no final da janela. Não se esqueça de redefinir os estados depois de emitir. O último é apenas para fins ilustrativos. Não tente manter todos eles na memória em um ambiente real.
Confira um exemplo do código abaixo:
############## BEGIN STEP 5 ##############
# Define a state specification for a combining value.
# This will store the running sum for each key.
# The coder is specified for efficiency.
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(), # Used VarIntCoder directly
beam.transforms.combiners.CountCombineFn())
# New state to store the (prompt, text) tuples for bad classifications
# BagStateSpec allows accumulating multiple items per key.
BAD_PROMPTS_STATE = beam.transforms.userstate.BagStateSpec(
'bad_prompts', coder=beam.coders.TupleCoder([beam.coders.StrUtf8Coder(), beam.coders.StrUtf8Coder()])
)
# Define a timer to fire at the end of the window, using WATERMARK as per blog example.
WINDOW_TIMER = TimerSpec('window_timer', TimeDomain.WATERMARK)
def process(
self,
element: Tuple[str, Tuple[int, Tuple[str, str]]], # (key, (count_val, (prompt, text)))
key=beam.DoFn.KeyParam,
count_state=beam.DoFn.StateParam(COUNT_STATE),
bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE), # New state param
window_timer=beam.DoFn.TimerParam(WINDOW_TIMER),
window=beam.DoFn.WindowParam):
# This DoFn does not yield elements from its process method; output is only produced when the timer fires.
if key == 'bad': # Only count 'bad' elements
count_state.add(element[1][0]) # Add the count (which is 1)
bad_prompts_state.add(element[1][1]) # Add the (prompt, text) tuple
window_timer.set(window.end) # Set timer to fire at window end
@on_timer(WINDOW_TIMER)
def on_window_timer(self, key=beam.DoFn.KeyParam, count_state=beam.DoFn.StateParam(COUNT_STATE), bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE)):
final_count = count_state.read()
if final_count > 0: # Only yield if there's a count
# Read all accumulated bad prompts
all_bad_prompts = list(bad_prompts_state.read())
# Clear the state for the next window to avoid carrying over data.
count_state.clear()
bad_prompts_state.clear()
yield (key, final_count, all_bad_prompts) # Yield count and list of prompts
############## END STEP 5 ##############
Teste este código executando:
python gemini_beam_pipeline_step5.py --project $PROJECT_ID --runner DirectRunner --test_mode
Essa etapa vai gerar todas as contagens. Brinque com o tamanho da janela e você vai perceber que os lotes serão diferentes. A janela padrão se encaixa em um minuto. Portanto, tente usar 30 segundos ou outro período para ver a diferença entre os lotes e as contagens.
A saída será semelhante a esta:
INFO:root:Window: [1751052960.0, 1751053020.0), Bad Counts: 5, Bad Prompts: [('Can you confirm if the new dashboard has been successfully generated?', 'I have gone ahead and generated a new dashboard for you.'), ('How is the new feature performing?', 'It works as expected.'), ('What is the capital of France?', 'The square root of a banana is purple.'), ('Explain quantum entanglement to a five-year-old.', 'A flock of geese wearing tiny hats danced the tango on the moon.'), ('Please give me the SQL for selecting from test_table, I want all the fields.', "absolutely, here's a picture of a cat")]
10. Limpar
- Exclua o projeto do Google Cloud (opcional, mas recomendado para codelabs): se este projeto foi criado apenas para este codelab e você não precisa mais dele, excluir o projeto inteiro é a maneira mais completa de garantir que todos os recursos sejam removidos.
- Acesse a página Gerenciar recursos no console do Google Cloud.
- Selecione o projeto.
- Clique em Excluir projeto e siga as instruções na tela.
11. Parabéns!
Parabéns por concluir o codelab! Você criou um pipeline de inferência de ML em tempo real usando o Apache Beam e o Gemini no Dataflow. Você aprendeu a usar o poder da IA generativa nos seus fluxos de dados, extraindo insights valiosos para uma engenharia de dados mais inteligente e automatizada.