
1. Введение
В современном быстро меняющемся мире данных получение информации в режиме реального времени имеет решающее значение для принятия обоснованных решений. Этот практический урок поможет вам создать конвейер обработки данных в режиме реального времени. Мы начнем с использования фреймворка Apache Beam , который предлагает единую модель программирования как для пакетной, так и для потоковой обработки данных. Это значительно упрощает разработку конвейера, абстрагируя сложную логику распределенных вычислений, которую в противном случае пришлось бы создавать с нуля. После того, как ваш конвейер будет определен с помощью Beam, вы сможете легко запустить его в Google Cloud Dataflow — полностью управляемом сервисе, обеспечивающем беспрецедентную масштабируемость и производительность для ваших потребностей в обработке данных.
В этом практическом занятии вы научитесь проектировать масштабируемый конвейер Apache Beam для вывода результатов машинного обучения, разрабатывать пользовательский ModelHandler для интеграции модели Gemini от Vertex AI, использовать алгоритмы обработки подсказок для интеллектуальной классификации текста в потоках данных, а также развертывать и запускать этот потоковый конвейер вывода результатов машинного обучения в Google Cloud Dataflow. В конце вы получите ценные знания о применении машинного обучения для анализа данных в реальном времени и непрерывной оценки в рабочих процессах разработки, особенно для поддержания надежного и ориентированного на пользователя разговорного ИИ.
Сценарий
Ваша компания разработала агента данных. Этот агент, созданный с помощью комплекта разработки агентов (ADK), оснащен различными специализированными возможностями для решения задач, связанных с данными. Представьте его как универсального помощника по работе с данными, готового обрабатывать самые разные запросы: от работы в качестве аналитика бизнес-аналитики для создания информативных отчетов до инженера данных, помогающего вам создавать надежные конвейеры обработки данных, или генератора SQL-запросов, создающего точные SQL-запросы, и многого другого. Каждое взаимодействие этого агента, каждый сгенерированный им ответ автоматически сохраняются в Firestore. Но зачем здесь нужен конвейер обработки данных?
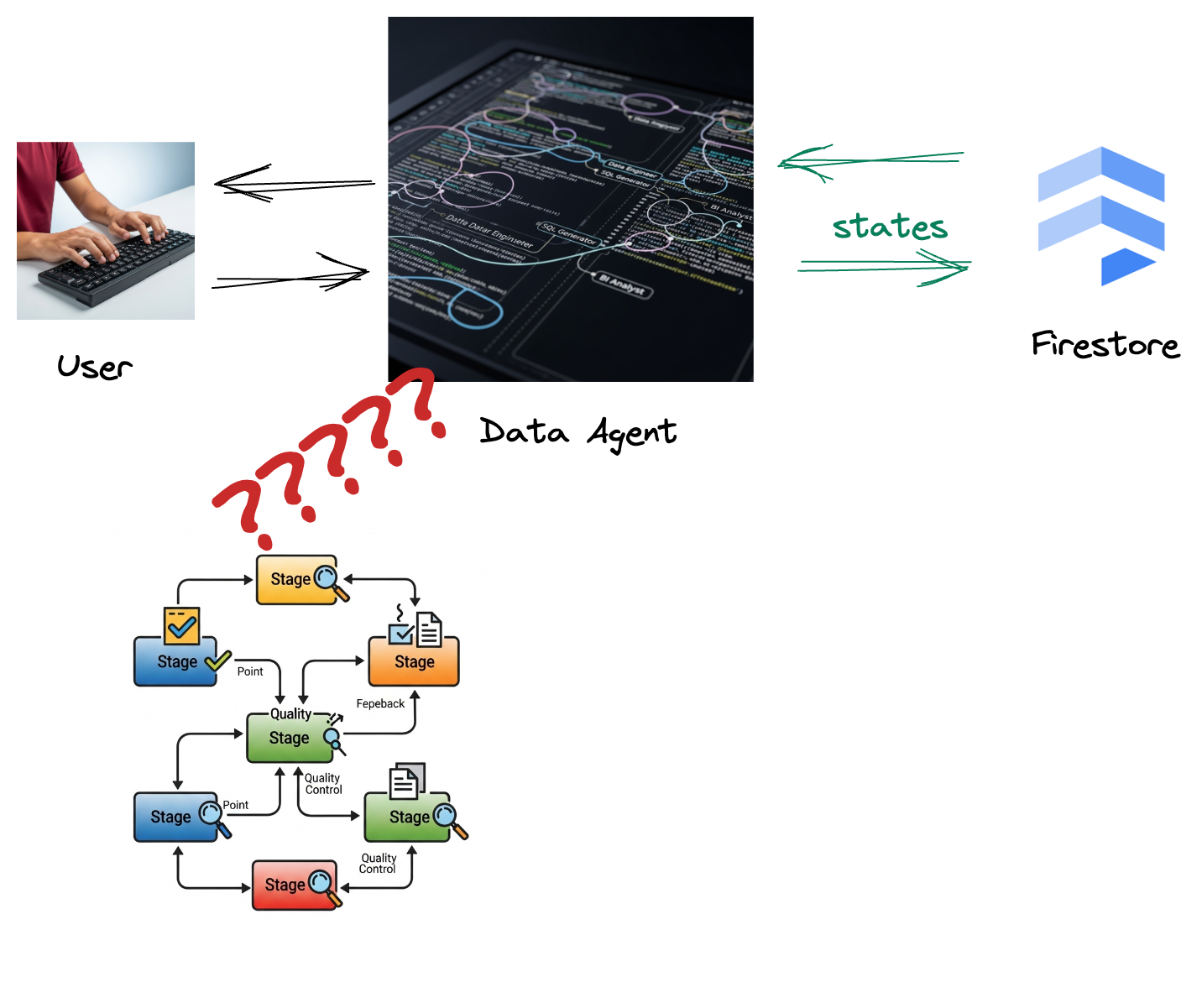
Благодаря тому, что из Firestore триггер беспрепятственно отправляет данные о взаимодействии в Pub/Sub, обеспечивая возможность немедленной обработки и анализа этих важных диалогов в режиме реального времени.
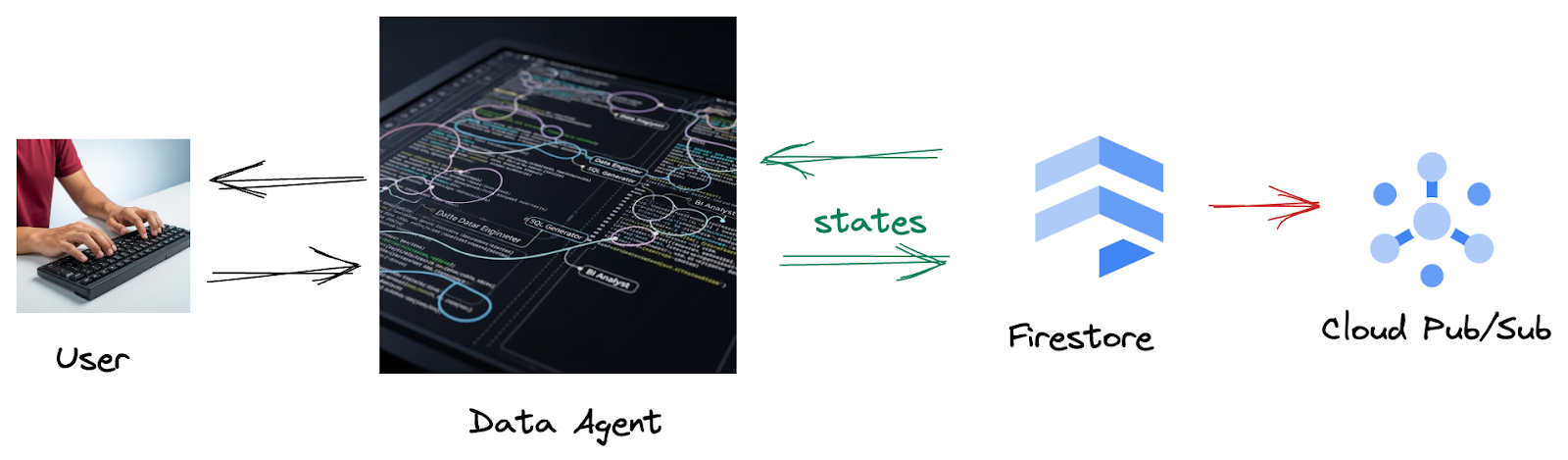
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Активируйте Cloud Shell, перейдя по этой ссылке . Вы можете переключаться между терминалом Cloud Shell (для выполнения облачных команд) и редактором (для сборки проектов), нажав соответствующую кнопку в Cloud Shell.
- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
- Включите необходимые API с помощью команды, указанной ниже. Это может занять несколько минут, поэтому, пожалуйста, наберитесь терпения.
gcloud services enable \
dataflow.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Убедитесь, что у вас установлен Python 3.10 или более поздней версии.
- Установите пакеты Python.
Установите необходимые библиотеки Python для Apache Beam, Google Cloud Vertex AI и Google Generative AI в вашей среде Cloud Shell.
pip install apache-beam[gcp] google-genai
- Клонируйте репозиторий GitHub и перейдите в каталог demo.
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/beam_as_eval
Для получения информации о командах gcloud и их использовании обратитесь к документации .
3. Как использовать предоставленный репозиторий Github
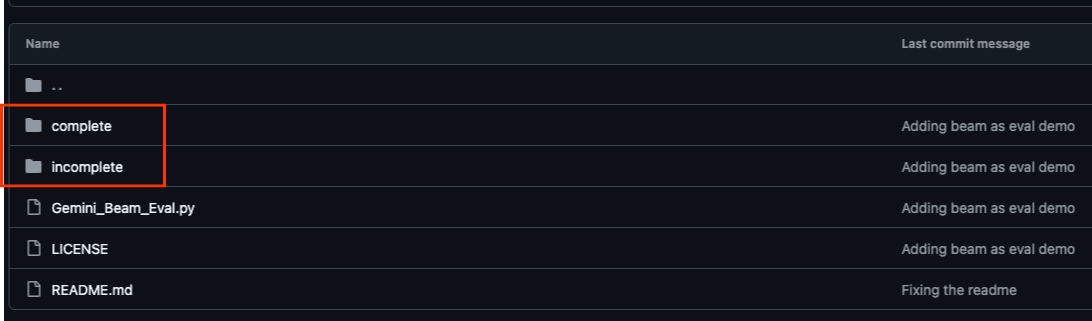
Репозиторий GitHub, связанный с этим практическим заданием, расположенный по адресу https://github.com/GoogleCloudPlatform/devrel-demos/tree/main/data-analytics/beam_as_eval , организован таким образом, чтобы облегчить обучение под руководством преподавателя. Он содержит базовый код, соответствующий каждой отдельной части практического задания, обеспечивая четкое последовательное освоение материала.
Внутри репозитория вы обнаружите две основные папки: «complete» и «incomplete». В папке «complete» находится полностью функциональный код для каждого шага, позволяющий запустить его и увидеть желаемый результат. В свою очередь, папка «incomplete» содержит код из предыдущих шагов, оставляя определенные разделы, отмеченные между ##### START STEP <NUMBER> ##### и ##### END STEP <NUMBER> ##### для выполнения в рамках упражнений. Такая структура позволяет вам опираться на имеющиеся знания, активно участвуя в решении задач по программированию.
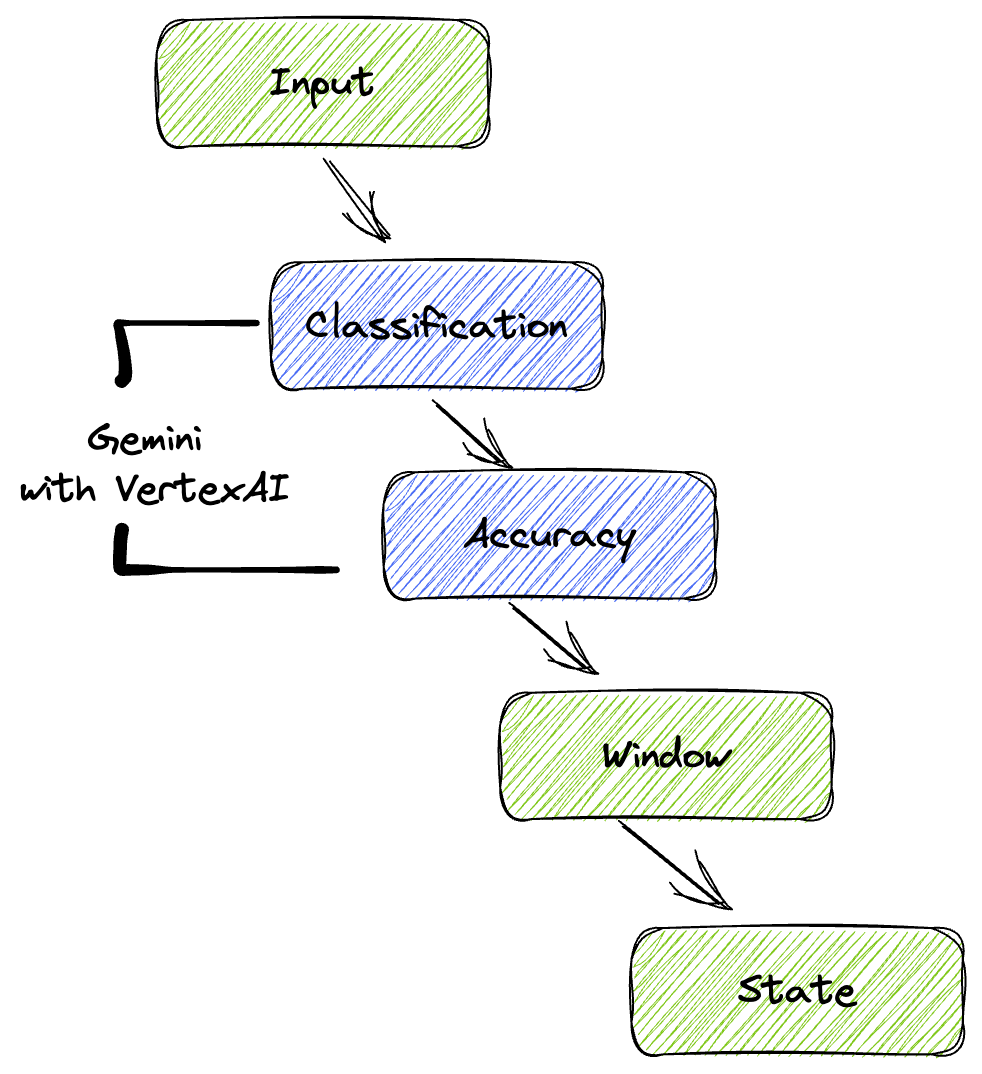
4. Архитектурный обзор
Наш конвейер предоставляет мощную и масштабируемую модель для интеграции результатов машинного обучения в потоки данных. Вот как все компоненты взаимодействуют друг с другом:
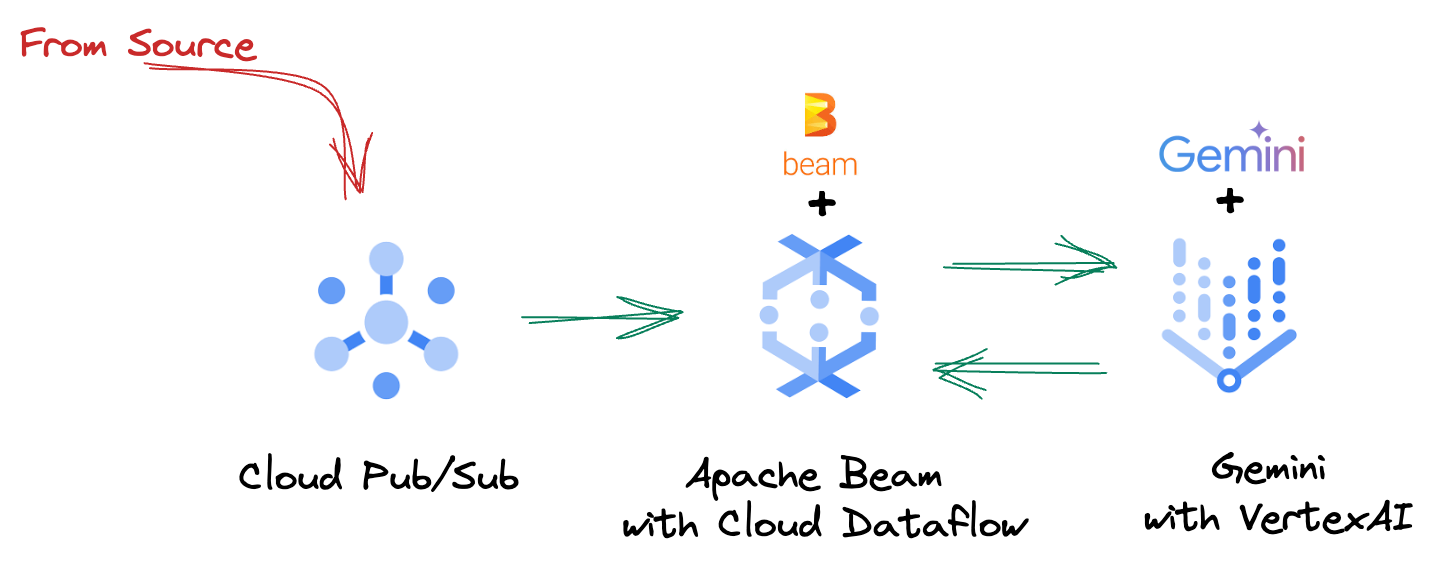
В вашем конвейере Beam вы будете задавать несколько входных данных в зависимости от условий, а затем загружать пользовательские модели с помощью готового преобразования RunInference . Хотя в примере используется Gemini с VertexAI, это демонстрирует, как по сути создается несколько обработчиков моделей (ModelHandlers) в соответствии с количеством имеющихся моделей. Наконец, вы будете использовать состояние DoFn для отслеживания событий и их контролируемой генерации.
5. Ввод данных
Сначала вы настроите свой конвейер для приема данных. Для потоковой передачи в реальном времени вы будете использовать Pub/Sub, но для упрощения разработки вы также создадите тестовый режим. Этот test_mode позволяет запускать конвейер локально, используя предопределенные примеры данных, поэтому вам не потребуется поток Pub/Sub в реальном времени, чтобы проверить работоспособность вашего конвейера.
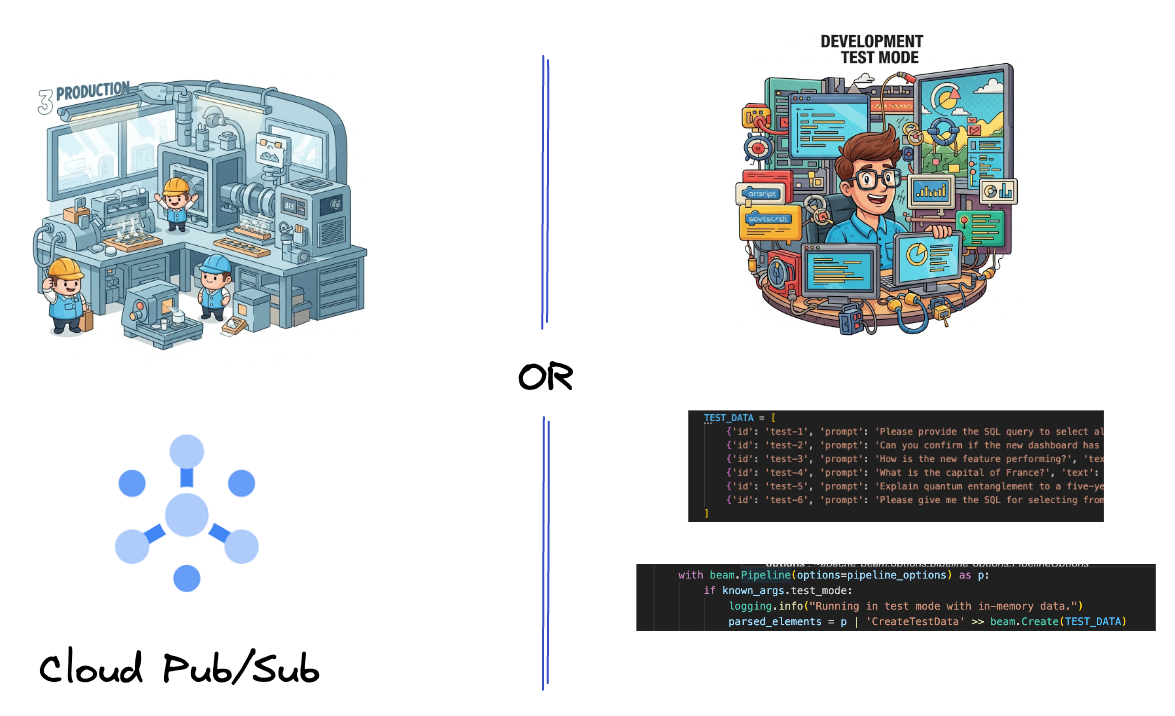
Для этого раздела используйте файл gemini_beam_pipeline_step1.py .
- Используя предоставленный объект конвейера p, запрограммируйте ввод данных по схеме Pub/Sub и выведите результат в виде коллекции pCollection.
- Кроме того, используйте флаг, чтобы определить, установлен ли параметр TEST_MODE.
- Если установлен параметр TEST_MODE, то переключитесь на обработку массива TEST_DATA в качестве входных данных.
Это необязательно, но помогает сократить процесс, так что вам не нужно привлекать Pub/Sub на этом этапе.
Ниже приведён пример кода:
# Step 1
# Ingesting Data
# Write your data ingestion step here.
############## BEGIN STEP 1 ##############
if known_args.test_mode:
logging.info("Running in test mode with in-memory data.")
parsed_elements = p | 'CreateTestData' >> beam.Create(TEST_DATA)
# Convert dicts to JSON strings and add timestamps for test mode
parsed_elements = parsed_elements | 'ConvertTestDictsToJsonAndAddTimestamps' >> beam.Map(
lambda x: beam.window.TimestampedValue(json.dumps(x), x['timestamp'])
)
else:
logging.info(f"Reading from Pub/Sub topic: {known_args.input_topic}")
parsed_elements = (
p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(
topic=known_args.input_topic
).with_output_types(bytes)
| 'DecodeBytes' >> beam.Map(lambda b: b.decode('utf-8')) # Output is JSON string
# Extract timestamp from JSON string for Pub/Sub messages
| 'AddTimestampsFromParsedJson' >> beam.Map(lambda s: beam.window.TimestampedValue(s, json.loads(s)['timestamp']))
)
############## END STEP 1 ##############
Проверьте этот код, выполнив:
python gemini_beam_pipeline_step1.py --project $PROJECT_ID --runner DirectRunner --test_mode
На этом этапе необходимо вывести все записи, записав их в стандартный вывод.
В результате вы должны получить примерно следующий результат.
INFO:root:Running in test mode with in-memory data.
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:root:{"id": "test-1", "prompt": "Please provide the SQL query to select all fields from the 'TEST_TABLE'.", "text": "Sure here is the SQL: SELECT * FROM TEST_TABLE;", "timestamp": 1751052405.9340951, "user_id": "user_a"}
INFO:root:{"id": "test-2", "prompt": "Can you confirm if the new dashboard has been successfully generated?", "text": "I have gone ahead and generated a new dashboard for you.", "timestamp": 1751052410.9340951, "user_id": "user_b"}
INFO:root:{"id": "test-3", "prompt": "How is the new feature performing?", "text": "It works as expected.", "timestamp": 1751052415.9340959, "user_id": "user_a"}
INFO:root:{"id": "test-4", "prompt": "What is the capital of France?", "text": "The square root of a banana is purple.", "timestamp": 1751052430.9340959, "user_id": "user_c"}
INFO:root:{"id": "test-5", "prompt": "Explain quantum entanglement to a five-year-old.", "text": "A flock of geese wearing tiny hats danced the tango on the moon.", "timestamp": 1751052435.9340959, "user_id": "user_b"}
INFO:root:{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here's a picture of a cat", "timestamp": 1751052440.9340959, "user_id": "user_c"}
6. Создание PTransform для классификации подсказок LLM.
Далее вам предстоит создать PTransform для классификации запросов. Это включает в себя использование модели Gemini от Vertex AI для категоризации входящего текста. Вы определите пользовательский GeminiModelHandler , который загружает модель Gemini, а затем инструктирует модель, как классифицировать текст по категориям, таким как «инженер данных», «аналитик бизнес-аналитики» или «генератор SQL».
Для этого нужно сравнить данные с фактическими вызовами инструментов в журнале. В данном практическом задании это не рассматривается, но вы можете отправить данные дальше по потоку и сравнить их. Могут быть неоднозначные вызовы, и это послужит отличным дополнительным источником данных, чтобы убедиться, что ваш агент вызывает правильные инструменты.
Для этого раздела используйте файл gemini_beam_pipeline_step2.py .
- Создайте собственный ModelHandler; однако вместо возврата объекта модели в функции load_model, верните genai.Client.
- Вам потребуется написать код для создания функции run_inference пользовательского ModelHandler. Пример командной строки приведён ниже:
В качестве подсказки может использоваться следующий текст:
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilities.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambiguous. Choose only one.
Finally, always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
- Выведите результаты в виде pCollection для следующего pTransform.
Ниже приведён пример кода:
############## BEGIN STEP 2 ##############
# load_model is called once per worker process to initialize the LLM client.
# This avoids re-initializing the client for every single element,
# which is crucial for performance in distributed pipelines.
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
# run_inference is called for each batch of elements. Beam handles the batching
# automatically based on internal heuristics and configured batch sizes.
# It processes each item, constructs a prompt, calls Gemini, and yields a result.
def run_inference(
self,
batch: Sequence[Any], # Each item is a JSON string or a dict
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""
Runs inference on a batch of JSON strings or dicts.
Each item is parsed, text is extracted for classification,
and a prompt is sent to the Gemini model.
"""
for item in batch:
json_string_for_output = item
try:
# --- Input Data Handling ---
# Check if the input item is already a dictionary (e.g., from TEST_DATA)
# or a JSON string (e.g., from Pub/Sub).
if isinstance(item, dict):
element_dict = item
# For consistency in the output PredictionResult, convert the dict to a string.
# This ensures pr.example always contains the original JSON string.
json_string_for_output = json.dumps(item)
else:
element_dict = json.loads(item)
# Extract the 'text' field from the parsed dictionary.
text_to_classify = element_dict.get('text','')
if not text_to_classify:
logging.warning(f"Input JSON missing 'text' key or text is empty: {json_string_for_output}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_NO_TEXT")
continue
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilites.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambigiuous. Choose only one.
Finally always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
contents = [
types.Content( # This is the actual content for the LLM
role="user",
parts=[
types.Part.from_text(text=prompt)
]
)
]
gemini_response = model.models.generate_content_stream(
model=self._model_name, contents=contents, config=self._model_kwargs
)
classification_tag = ""
for chunk in gemini_response:
if chunk.text is not None:
classification_tag+=chunk.text
yield PredictionResult(example=json_string_for_output, inference=classification_tag)
except json.JSONDecodeError as e:
logging.error(f"Error decoding JSON string: {json_string_for_output}, error: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_JSON_DECODE")
except Exception as e:
logging.error(f"Error during Gemini inference for input {json_string_for_output}: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_INFERENCE")
############## END STEP 2 ##############
Проверьте этот код, выполнив:
python gemini_beam_pipeline_step2.py --project $PROJECT_ID --runner DirectRunner --test_mode
На этом этапе Gemini должен вывести результат. Он классифицирует результаты в соответствии с вашим запросом.
В результате вы должны получить примерно следующий результат.
INFO:root:PredictionResult(example='{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here\'s a picture of a cat", "timestamp": 1751052592.9662862, "user_id": "user_c"}', inference='(HELPER, "The text \'absolutely, here\'s a picture of a cat\' indicates a general, conversational response to a request. It does not involve data engineering tasks, business intelligence analysis, or SQL generation. Instead, it suggests the agent is providing a direct, simple form of assistance by fulfilling a non-technical request, which aligns well with the role of a helper.")', model_id=None)
7. Подготовка магистра права к работе судьей.
После классификации запросов вы оцените точность ответов модели. Для этого потребуется еще один вызов модели Gemini, но на этот раз вы попросите ее оценить, насколько хорошо «текст» соответствует исходному «запросу», по шкале от 0,0 до 1,0. Это поможет вам понять качество выходных данных ИИ. Для этой задачи вы создадите отдельный обработчик GeminiAccuracyModelHandler .

Для этого раздела используйте файл gemini_beam_pipeline_step3.py .
- Создайте собственный ModelHandler; однако вместо возврата объекта модели в функции load_model, верните genai.Client, как вы это делали выше.
- Вам потребуется написать код для создания функции run_inference пользовательского ModelHandler. Пример командной строки приведён ниже:
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
Здесь важно отметить, что вы, по сути, создали две разные модели в одном и том же конвейере. В этом конкретном примере вы также используете вызов Gemini с VertexAI, но, следуя той же концепции, вы можете выбирать и загружать другие модели. Это упрощает управление моделями и позволяет использовать несколько моделей в одном конвейере Beam.
- Выведите результаты в виде pCollection для следующего pTransform.
Ниже приведён пример кода:
############## BEGIN STEP 3 ##############
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
def run_inference(
self,
batch: Sequence[str], # Each item is a JSON string
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""Runs inference on a batch of JSON strings to verify accuracy."""
for json_string in batch:
try:
element_dict = json.loads(json_string)
original_prompt = element_dict.get('original_prompt', '')
original_text = element_dict.get('original_text', '')
if not original_prompt or not original_text:
logging.warning(f"Accuracy input missing prompt/text: {json_string}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_ACCURACY_INPUT")
continue
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
gemini_response = model.models.generate_content_stream(model=self._model_name, contents=[prompt_for_accuracy], config=self._model_kwargs)
gemini_response_text = ""
for chunk in gemini_response:
if chunk.text is not None:
gemini_response_text+=chunk.text
yield PredictionResult(example=json_string, inference=gemini_response_text)
except Exception as e:
logging.error(f"Error during Gemini accuracy inference for input {json_string}: {e}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_INFERENCE")
############## END STEP 3 ##############
Проверьте этот код, выполнив:
python gemini_beam_pipeline_step3.py --project $PROJECT_ID --runner DirectRunner --test_mode
На этом этапе также должен быть получен результат, включающий комментарий и оценку того, насколько точным, по мнению Gemini, показал ответ инструмента.
В результате вы должны получить примерно следующий результат.
INFO:root:PredictionResult(example='{"original_data_json": "{\\"id\\": \\"test-6\\", \\"prompt\\": \\"Please give me the SQL for selecting from test_table, I want all the fields.\\", \\"text\\": \\"absolutely, here\'s a picture of a cat\\", \\"timestamp\\": 1751052770.7552562, \\"user_id\\": \\"user_c\\"}", "original_prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "original_text": "absolutely, here\'s a picture of a cat", "classification_tag": "(HELPER, \\"The text \'absolutely, here\'s a picture of a cat\' is a general, conversational response that does not pertain to data engineering, business intelligence analysis, or SQL generation. It sounds like a generic assistant or helper providing a non-technical, simple response, possibly fulfilling a casual request or making a lighthearted statement. Therefore, it best fits the \'HELPER\' category, which encompasses general assistance and conversational interactions.\\")"}', inference='0.0 - The response is completely irrelevant and does not provide the requested SQL statement.', model_id=None)
8. Оконная обработка и анализ результатов
Теперь вы будете анализировать результаты за определенные временные интервалы, используя фиксированные окна для группировки данных, что позволит получить сводные данные. После обработки данных с помощью окон вы преобразуете исходные данные из Gemini в более структурированный формат, включающий исходные данные, тег классификации, показатель точности и пояснение.

Для этого раздела используйте файл gemini_beam_pipeline_step4.py .
- Добавьте фиксированный временной интервал в 60 секунд, чтобы все данные уложились в этот 60-секундный промежуток.
Ниже приведён пример кода:
############## BEGIN STEP 4 ##############
| 'WindowIntoFixedWindows' >> beam.WindowInto(beam.window.FixedWindows(60))
############## END STEP 4 ##############
Проверьте этот код, выполнив:
python gemini_beam_pipeline_step4.py --project $PROJECT_ID --runner DirectRunner --test_mode
Этот шаг носит информативный характер: вы ищете нужное вам окно. Оно будет отображаться в виде временной метки остановки/запуска окна.
В результате вы должны получить примерно следующий результат.
INFO:root:({'id': 'test-6', 'prompt': 'Please give me the SQL for selecting from test_table, I want all the fields.', 'text': "absolutely, here's a picture of a cat", 'timestamp': 1751052901.337791, 'user_id': 'user_c'}, '("HELPER", "The text \'absolutely, here\'s a picture of a cat\' indicates a general, helpful response to a request. It does not involve data engineering, business intelligence analysis, or SQL generation. Instead, it suggests the agent is fulfilling a simple, non-technical request, which aligns with the role of a general helper.")', 0.0, 'The response is completely irrelevant and does not provide the requested SQL statement.', [1751052900.0, 1751052960.0))
9. Подсчет положительных и отрицательных результатов с использованием обработки состояний.
Наконец, вы будете использовать механизм DoFn с сохранением состояния для подсчета «хороших» и «плохих» результатов в каждом окне. «Хороший» результат может представлять собой взаимодействие с высокой точностью, а «плохой» — с низкой. Такая обработка с сохранением состояния позволяет поддерживать подсчеты и даже собирать примеры «плохих» взаимодействий с течением времени, что крайне важно для мониторинга состояния и производительности вашего чат-бота в режиме реального времени.
Для этого раздела используйте файл gemini_beam_pipeline_step5.py .
- Создайте функцию с состоянием. Вам понадобятся два состояния: (1) для отслеживания количества некорректных записей и (2) для хранения некорректных записей для отображения. Используйте квалифицированных программистов, чтобы обеспечить высокую производительность системы.
- Каждый раз, когда вы видите значения, указывающие на неудачный вывод, вам нужно отслеживать оба значения и передавать их в конце окна. Не забудьте сбросить состояния после передачи. Последнее приведено только для иллюстрации, не пытайтесь хранить все эти данные в памяти в реальной среде.
Ниже приведён пример кода:
############## BEGIN STEP 5 ##############
# Define a state specification for a combining value.
# This will store the running sum for each key.
# The coder is specified for efficiency.
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(), # Used VarIntCoder directly
beam.transforms.combiners.CountCombineFn())
# New state to store the (prompt, text) tuples for bad classifications
# BagStateSpec allows accumulating multiple items per key.
BAD_PROMPTS_STATE = beam.transforms.userstate.BagStateSpec(
'bad_prompts', coder=beam.coders.TupleCoder([beam.coders.StrUtf8Coder(), beam.coders.StrUtf8Coder()])
)
# Define a timer to fire at the end of the window, using WATERMARK as per blog example.
WINDOW_TIMER = TimerSpec('window_timer', TimeDomain.WATERMARK)
def process(
self,
element: Tuple[str, Tuple[int, Tuple[str, str]]], # (key, (count_val, (prompt, text)))
key=beam.DoFn.KeyParam,
count_state=beam.DoFn.StateParam(COUNT_STATE),
bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE), # New state param
window_timer=beam.DoFn.TimerParam(WINDOW_TIMER),
window=beam.DoFn.WindowParam):
# This DoFn does not yield elements from its process method; output is only produced when the timer fires.
if key == 'bad': # Only count 'bad' elements
count_state.add(element[1][0]) # Add the count (which is 1)
bad_prompts_state.add(element[1][1]) # Add the (prompt, text) tuple
window_timer.set(window.end) # Set timer to fire at window end
@on_timer(WINDOW_TIMER)
def on_window_timer(self, key=beam.DoFn.KeyParam, count_state=beam.DoFn.StateParam(COUNT_STATE), bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE)):
final_count = count_state.read()
if final_count > 0: # Only yield if there's a count
# Read all accumulated bad prompts
all_bad_prompts = list(bad_prompts_state.read())
# Clear the state for the next window to avoid carrying over data.
count_state.clear()
bad_prompts_state.clear()
yield (key, final_count, all_bad_prompts) # Yield count and list of prompts
############## END STEP 5 ##############
Проверьте этот код, выполнив:
python gemini_beam_pipeline_step5.py --project $PROJECT_ID --runner DirectRunner --test_mode
На этом этапе должны отобразиться все значения счетчиков. Поэкспериментируйте с размером окна, и вы увидите, что значения для разных партий будут отличаться. Окно по умолчанию помещается в пределах одной минуты, поэтому попробуйте использовать 30 секунд или другой временной интервал, и вы увидите, что значения для разных партий и счетчиков различаются.
В результате вы должны получить примерно следующий результат.
INFO:root:Window: [1751052960.0, 1751053020.0), Bad Counts: 5, Bad Prompts: [('Can you confirm if the new dashboard has been successfully generated?', 'I have gone ahead and generated a new dashboard for you.'), ('How is the new feature performing?', 'It works as expected.'), ('What is the capital of France?', 'The square root of a banana is purple.'), ('Explain quantum entanglement to a five-year-old.', 'A flock of geese wearing tiny hats danced the tango on the moon.'), ('Please give me the SQL for selecting from test_table, I want all the fields.', "absolutely, here's a picture of a cat")]
10. Уборка
- Удаление проекта Google Cloud (необязательно, но рекомендуется для практических занятий): Если этот проект был создан исключительно для данного практического занятия и он вам больше не нужен, удаление всего проекта — наиболее надежный способ гарантировать удаление всех ресурсов.
- Перейдите на страницу «Управление ресурсами» в консоли Google Cloud.
- Выберите свой проект.
- Нажмите «Удалить проект» и следуйте инструкциям на экране.
11. Поздравляем!
Поздравляем с завершением практического занятия! Вы успешно создали конвейер машинного обучения в реальном времени, используя Apache Beam и Gemini на Dataflow. Вы научились применять возможности генеративного ИИ к вашим потокам данных, извлекая ценные аналитические данные для более интеллектуальной и автоматизированной обработки данных.