
1. Giriş
Günümüzün hızlı tempolu veri ortamında, bilinçli kararlar vermek için anlık analizler çok önemlidir. Bu codelab, gerçek zamanlı değerlendirme işlem hattı oluşturma konusunda size yol gösterecektir. Hem toplu hem de akış verileri için birleştirilmiş bir programlama modeli sunan Apache Beam çerçevesinden yararlanarak başlayacağız. Bu, aksi takdirde sıfırdan oluşturmanız gereken karmaşık dağıtılmış bilgi işlem mantığını soyutlayarak kanal geliştirme sürecini önemli ölçüde basitleştirir. Ardışık düzeniniz Beam kullanılarak tanımlandıktan sonra, veri işleme ihtiyaçlarınız için benzersiz ölçek ve performans sağlayan, tümüyle yönetilen bir hizmet olan Google Cloud Dataflow'da sorunsuz bir şekilde çalıştırılır.
Bu codelab'de, makine öğrenimi çıkarımı için ölçeklenebilir bir Apache Beam ardışık düzeni tasarlamayı, Vertex AI'ın Gemini modelini entegre etmek için özel bir ModelHandler geliştirmeyi, veri akışlarında akıllı metin sınıflandırması için istem mühendisliğinden yararlanmayı ve bu akışlı makine öğrenimi çıkarımı ardışık düzenini Google Cloud Dataflow'da dağıtıp çalıştırmayı öğreneceksiniz. Eğitimin sonunda, özellikle sağlam ve kullanıcı odaklı bir etkileşimli yapay zeka oluşturmak için mühendislik iş akışlarında makine öğrenimini gerçek zamanlı veri anlayışı ve sürekli değerlendirme amacıyla uygulama konusunda değerli bilgiler edineceksiniz.
Senaryo
Şirketiniz bir veri aracısı oluşturduysa. Agent Development Kit (ADK) ile oluşturulan veri aracınız, veriyle ilgili görevlerde yardımcı olmak için çeşitli uzmanlık özellikleriyle donatılmıştır. Bu aracı, BI analisti olarak içgörülü raporlar oluşturmaktan veri mühendisi olarak sağlam veri ardışık düzenleri oluşturmanıza yardımcı olmaya veya SQL oluşturucu olarak hassas SQL ifadeleri oluşturmaya kadar çeşitli istekleri işlemeye hazır, çok yönlü bir veri asistanı olarak düşünebilirsiniz. Bu aracının her etkileşimi ve oluşturduğu her yanıt otomatik olarak Firestore'da saklanır. Peki burada neden bir işlem hattına ihtiyacımız var?
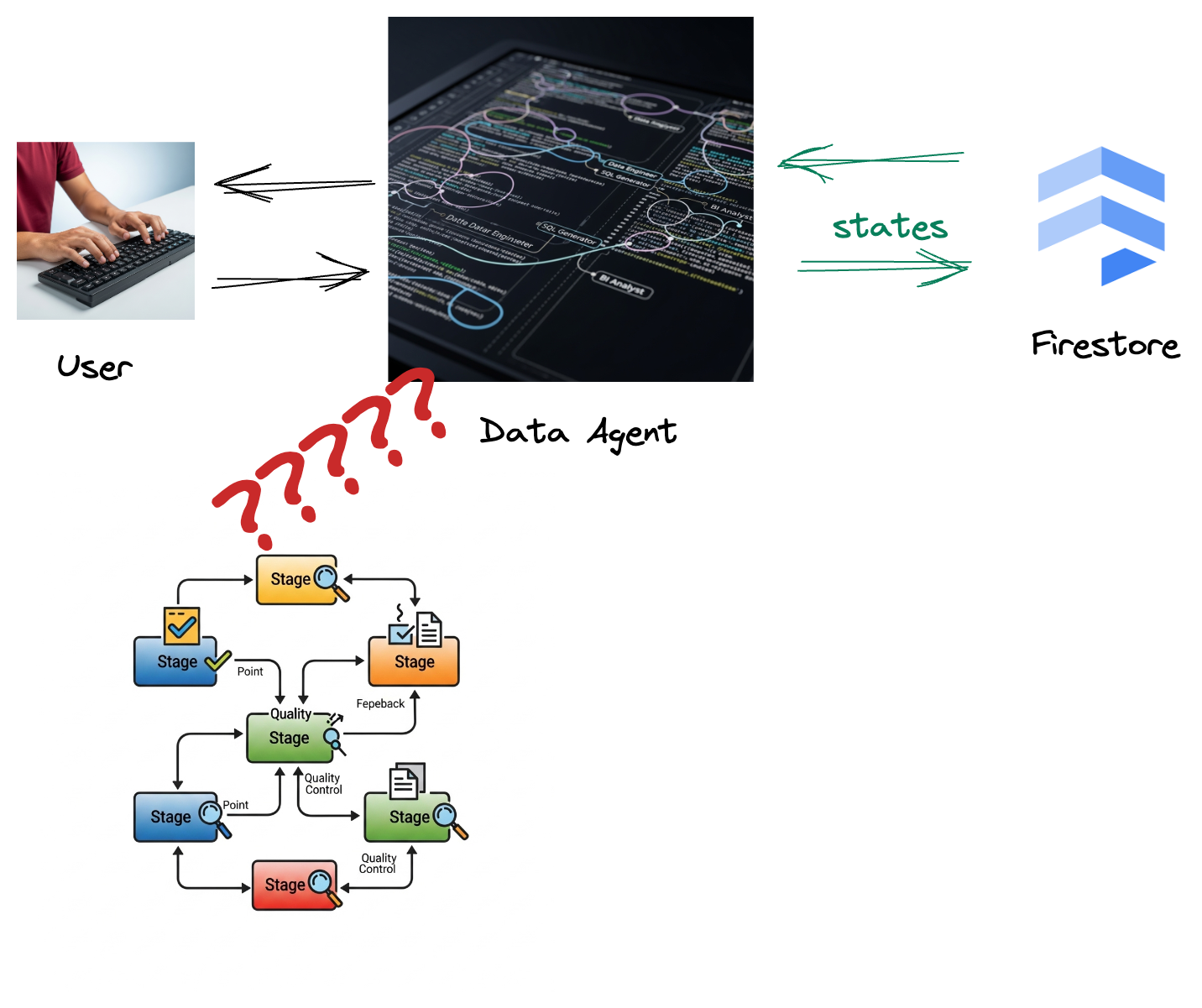
Çünkü Firestore'dan bir tetikleyici, bu etkileşim verilerini sorunsuz bir şekilde Pub/Sub'a göndererek bu önemli görüşmeleri anında işleyip gerçek zamanlı olarak analiz etmemizi sağlar.
2. Başlamadan önce
Proje oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
- Bu bağlantıyı tıklayarak Cloud Shell'i etkinleştirin. Cloud Shell'deki ilgili düğmeyi tıklayarak Cloud Shell Terminali (bulut komutlarını çalıştırmak için) ile Düzenleyici (projeleri oluşturmak için) arasında geçiş yapabilirsiniz.
- Cloud Shell'e bağlandıktan sonra aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını kontrol edin:
gcloud auth list
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın.
gcloud config list project
- Projeniz ayarlanmamışsa ayarlamak için aşağıdaki komutu kullanın:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
- Aşağıda gösterilen komutu kullanarak gerekli API'leri etkinleştirin. Bu işlem birkaç dakika sürebilir. Lütfen bekleyin.
gcloud services enable \
dataflow.googleapis.com \
pubsub.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
- Python 3.10 veya sonraki bir sürümün yüklü olduğundan emin olun.
- Python paketlerini yükleme
Cloud Shell kabuk ortamınızda Apache Beam, Google Cloud Vertex AI ve Google Üretken Yapay Zeka için gerekli Python kitaplıklarını yükleyin.
pip install apache-beam[gcp] google-genai
- GitHub deposunu klonlayın ve demo dizinine geçin.
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/beam_as_eval
gcloud komutları ve kullanımıyla ilgili belgelere bakın.
3. Sağlanan GitHub deposunu kullanma
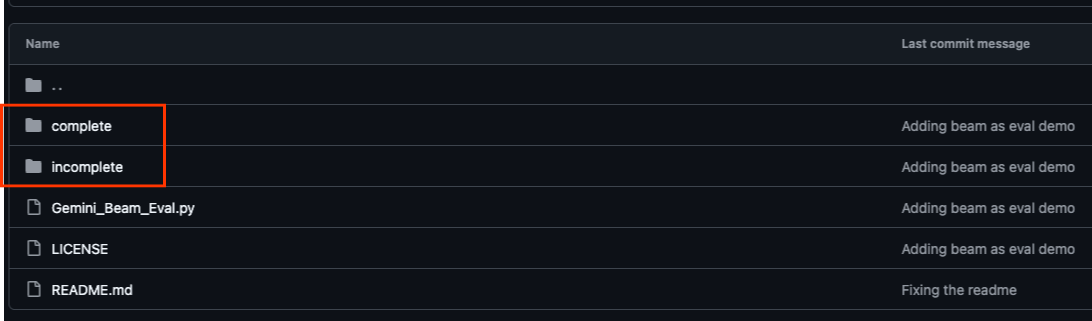
Bu codelab ile ilişkili GitHub deposu (https://github.com/GoogleCloudPlatform/devrel-demos/tree/main/data-analytics/beam_as_eval) rehberli bir öğrenme deneyimi sunmak için düzenlenmiştir. Codelab'in her bir bölümüyle uyumlu iskelet kodu içerir. Bu sayede, materyalde net bir ilerleme sağlanır.
Depoda "complete" (tamamlanmış) ve "incomplete" (tamamlanmamış) olmak üzere iki ana klasör bulunur. "Complete" (Tam) klasöründe, her adım için tamamen işlevsel kod bulunur. Bu kodları çalıştırıp amaçlanan çıkışı gözlemleyebilirsiniz. Buna karşılık, "incomplete" klasöründe önceki adımlardan kod sağlanır. Bu kodda, alıştırmalar kapsamında tamamlamanız için belirli bölümler ##### START STEP <NUMBER> ##### ve ##### END STEP <NUMBER> ##### arasında işaretlenmiştir. Bu yapı, kodlama yarışmalarına aktif olarak katılırken önceki bilgilerinizden yararlanmanızı sağlar.
4. Mimari Genel Bakış
Ardışık düzenimiz, makine öğrenimi çıkarımını veri akışlarına entegre etmek için güçlü ve ölçeklenebilir bir yöntem sunar. Parçaların bir araya gelme şekli:
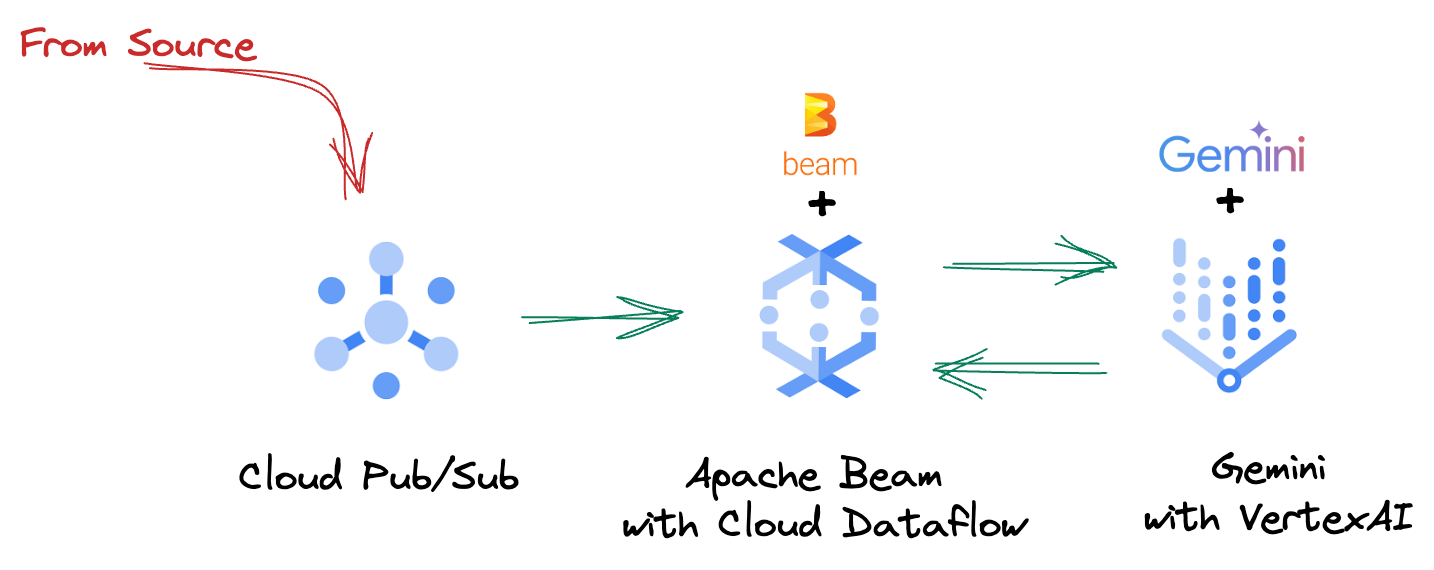
Beam işlem hattınızda, birden fazla girişi koşullu olarak kodlayacak ve ardından RunInference hazır dönüşümüyle özel modeller yükleyeceksiniz. Örnekte Gemini with VertexAI kullanılıyor olsa da bu, sahip olduğunuz model sayısına uyacak şekilde birden fazla ModelHandler'ı nasıl oluşturacağınızı gösterir. Son olarak, etkinlikleri takip etmek ve kontrollü bir şekilde yayınlamak için durum bilgisi olan bir DoFn kullanacaksınız.
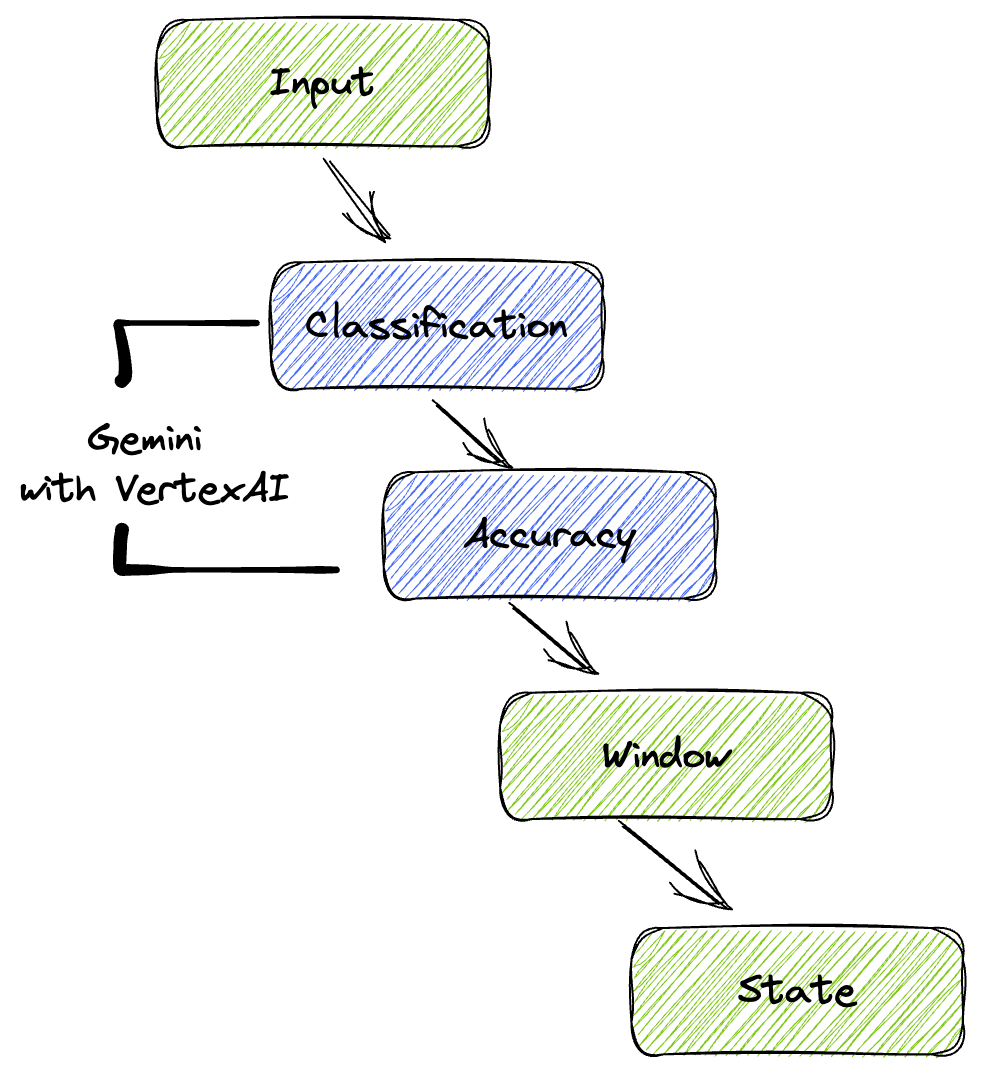
5. Veri Kullanımı
İlk olarak, verileri almak için ardışık düzeninizi oluşturursunuz. Gerçek zamanlı yayın için Pub/Sub'ı kullanacaksınız ancak geliştirmeyi kolaylaştırmak için bir test modu da oluşturacaksınız. Bu test_mode, ardışık düzeninizin çalışıp çalışmadığını görmek için canlı bir Pub/Sub akışına ihtiyacınız olmaması adına, önceden tanımlanmış örnek verileri kullanarak ardışık düzeni yerel olarak çalıştırmanıza olanak tanır.
Bu bölüm için gemini_beam_pipeline_step1.py dosyasını kullanın.
- Sağlanan işlem hattı nesnesi p'yi kullanarak bir Pub/Sub girişi kodlayın ve çıkışı pCollection olarak yazın.
- Ayrıca, TEST_MODE'un ayarlanıp ayarlanmadığını belirlemek için bir işaret kullanın.
- TEST_MODE ayarlandıysa TEST_DATA dizisini giriş olarak ayrıştırmaya geçin.
Bu gerekli olmasa da süreci kısaltmaya yardımcı olur. Böylece Pub/Sub'ı bu kadar erken dahil etmeniz gerekmez.
Aşağıdaki kodun bir örneğini burada bulabilirsiniz:
# Step 1
# Ingesting Data
# Write your data ingestion step here.
############## BEGIN STEP 1 ##############
if known_args.test_mode:
logging.info("Running in test mode with in-memory data.")
parsed_elements = p | 'CreateTestData' >> beam.Create(TEST_DATA)
# Convert dicts to JSON strings and add timestamps for test mode
parsed_elements = parsed_elements | 'ConvertTestDictsToJsonAndAddTimestamps' >> beam.Map(
lambda x: beam.window.TimestampedValue(json.dumps(x), x['timestamp'])
)
else:
logging.info(f"Reading from Pub/Sub topic: {known_args.input_topic}")
parsed_elements = (
p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(
topic=known_args.input_topic
).with_output_types(bytes)
| 'DecodeBytes' >> beam.Map(lambda b: b.decode('utf-8')) # Output is JSON string
# Extract timestamp from JSON string for Pub/Sub messages
| 'AddTimestampsFromParsedJson' >> beam.Map(lambda s: beam.window.TimestampedValue(s, json.loads(s)['timestamp']))
)
############## END STEP 1 ##############
Bu kodu çalıştırarak test edin:
python gemini_beam_pipeline_step1.py --project $PROJECT_ID --runner DirectRunner --test_mode
Bu adım, tüm kayıtları stdout'a günlük kaydı yaparak yayınlamalıdır.
Aşağıdakine benzer bir çıkış alırsınız.
INFO:root:Running in test mode with in-memory data.
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:root:{"id": "test-1", "prompt": "Please provide the SQL query to select all fields from the 'TEST_TABLE'.", "text": "Sure here is the SQL: SELECT * FROM TEST_TABLE;", "timestamp": 1751052405.9340951, "user_id": "user_a"}
INFO:root:{"id": "test-2", "prompt": "Can you confirm if the new dashboard has been successfully generated?", "text": "I have gone ahead and generated a new dashboard for you.", "timestamp": 1751052410.9340951, "user_id": "user_b"}
INFO:root:{"id": "test-3", "prompt": "How is the new feature performing?", "text": "It works as expected.", "timestamp": 1751052415.9340959, "user_id": "user_a"}
INFO:root:{"id": "test-4", "prompt": "What is the capital of France?", "text": "The square root of a banana is purple.", "timestamp": 1751052430.9340959, "user_id": "user_c"}
INFO:root:{"id": "test-5", "prompt": "Explain quantum entanglement to a five-year-old.", "text": "A flock of geese wearing tiny hats danced the tango on the moon.", "timestamp": 1751052435.9340959, "user_id": "user_b"}
INFO:root:{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here's a picture of a cat", "timestamp": 1751052440.9340959, "user_id": "user_c"}
6. LLM istem sınıflandırması için PTransform oluşturma
Ardından, istemleri sınıflandırmak için bir PTransform oluşturacaksınız. Bu işlemde, gelen metni kategorize etmek için Vertex AI'ın Gemini modeli kullanılır. Gemini modelini yükleyen ve ardından metni "VERİ MÜHENDİSİ", "İŞ ZEKASI ANALİSTİ" veya "SQL OLUŞTURUCU" gibi kategorilere nasıl sınıflandıracağı konusunda modele talimat veren özel bir GeminiModelHandler tanımlayacaksınız.
Bunu, günlüğündeki gerçek araç çağrılarıyla karşılaştırarak kullanabilirsiniz. Bu codelab'de bu konu ele alınmamıştır ancak bunu aşağı akışa gönderebilir ve karşılaştırabilirsiniz. Belirsiz olanlar olabilir. Bu, temsilcinizin doğru araçları çağırdığından emin olmak için harika bir ek veri noktasıdır.
Bu bölüm için gemini_beam_pipeline_step2.py dosyasını kullanın.
- Özel ModelHandler'ınızı oluşturun. Ancak load_model'da model nesnesi döndürmek yerine genai.Client'ı döndürün.
- Özel ModelHandler'ın run_inference işlevini oluşturmak için gereken kod. Örnek bir istem sağlanmıştır:
İstem şu şekilde olabilir:
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilities.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambiguous. Choose only one.
Finally, always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
- Sonuçları bir sonraki pTransform için pCollection olarak verin.
Aşağıdaki kodun bir örneğini burada bulabilirsiniz:
############## BEGIN STEP 2 ##############
# load_model is called once per worker process to initialize the LLM client.
# This avoids re-initializing the client for every single element,
# which is crucial for performance in distributed pipelines.
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
# run_inference is called for each batch of elements. Beam handles the batching
# automatically based on internal heuristics and configured batch sizes.
# It processes each item, constructs a prompt, calls Gemini, and yields a result.
def run_inference(
self,
batch: Sequence[Any], # Each item is a JSON string or a dict
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""
Runs inference on a batch of JSON strings or dicts.
Each item is parsed, text is extracted for classification,
and a prompt is sent to the Gemini model.
"""
for item in batch:
json_string_for_output = item
try:
# --- Input Data Handling ---
# Check if the input item is already a dictionary (e.g., from TEST_DATA)
# or a JSON string (e.g., from Pub/Sub).
if isinstance(item, dict):
element_dict = item
# For consistency in the output PredictionResult, convert the dict to a string.
# This ensures pr.example always contains the original JSON string.
json_string_for_output = json.dumps(item)
else:
element_dict = json.loads(item)
# Extract the 'text' field from the parsed dictionary.
text_to_classify = element_dict.get('text','')
if not text_to_classify:
logging.warning(f"Input JSON missing 'text' key or text is empty: {json_string_for_output}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_NO_TEXT")
continue
prompt =f"""
The input is a response from another agent.
The agent has multiple tools, each having their own responsibilites.
You are to analyze the input and then classify it into one and only one.
Use the best one if it seems like it is ambigiuous. Choose only one.
Finally always provide a paragraph on why you think it is in one of the categories.
Classify the text into one of these categories:
DATA ENGINEER
BI ANALYST
SQL GENERATOR
HELPER
OTHER
Respond with only the one single classification tag.
Your response should be in a tuple (classification_tag, reason)
Text: "{text_to_classify}"
"""
contents = [
types.Content( # This is the actual content for the LLM
role="user",
parts=[
types.Part.from_text(text=prompt)
]
)
]
gemini_response = model.models.generate_content_stream(
model=self._model_name, contents=contents, config=self._model_kwargs
)
classification_tag = ""
for chunk in gemini_response:
if chunk.text is not None:
classification_tag+=chunk.text
yield PredictionResult(example=json_string_for_output, inference=classification_tag)
except json.JSONDecodeError as e:
logging.error(f"Error decoding JSON string: {json_string_for_output}, error: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_JSON_DECODE")
except Exception as e:
logging.error(f"Error during Gemini inference for input {json_string_for_output}: {e}")
yield PredictionResult(example=json_string_for_output, inference="ERROR_INFERENCE")
############## END STEP 2 ##############
Bu kodu çalıştırarak test edin:
python gemini_beam_pipeline_step2.py --project $PROJECT_ID --runner DirectRunner --test_mode
Bu adımda Gemini'dan bir çıkarım döndürülmelidir. Sonuçları isteminizde belirtildiği şekilde sınıflandırır.
Aşağıdakine benzer bir çıkış alırsınız.
INFO:root:PredictionResult(example='{"id": "test-6", "prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "text": "absolutely, here\'s a picture of a cat", "timestamp": 1751052592.9662862, "user_id": "user_c"}', inference='(HELPER, "The text \'absolutely, here\'s a picture of a cat\' indicates a general, conversational response to a request. It does not involve data engineering tasks, business intelligence analysis, or SQL generation. Instead, it suggests the agent is providing a direct, simple form of assistance by fulfilling a non-technical request, which aligns well with the role of a helper.")', model_id=None)
7. LLM-as-a-Judge oluşturma
İstemleri sınıflandırdıktan sonra modelin yanıtlarının doğruluğunu değerlendirirsiniz. Bu işlemde Gemini modeline başka bir çağrı yapılır ancak bu kez, "metnin" orijinal "istem"i ne kadar iyi karşıladığını 0,0 ile 1,0 arasında bir ölçekte puanlaması istenir. Bu, yapay zekanın çıktısının kalitesini anlamanıza yardımcı olur. Bu görev için ayrı bir GeminiAccuracyModelHandler oluşturursunuz.

Bu bölüm için gemini_beam_pipeline_step3.py dosyasını kullanın.
- Özel ModelHandler'ınızı oluşturun. Ancak load_model'da bir model nesnesi döndürmek yerine, yukarıda yaptığınız gibi genai.Client'ı döndürün.
- Özel ModelHandler'ın run_inference işlevini oluşturmak için gereken kod. Örnek bir istem sağlanmıştır:
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
Burada dikkat edilmesi gereken bir nokta, aynı işlem hattında temelde iki farklı model oluşturmuş olmanızdır. Bu örnekte, Vertex AI ile bir Gemini çağrısı da kullanıyorsunuz ancak aynı konseptte diğer modelleri kullanmayı ve yüklemeyi de seçebilirsiniz. Bu sayede model yönetimi basitleştirilir ve aynı Beam ardışık düzeninde birden fazla model kullanabilirsiniz.
- Sonuçları bir sonraki pTransform için pCollection olarak verin.
Aşağıdaki kodun bir örneğini burada bulabilirsiniz:
############## BEGIN STEP 3 ##############
def load_model(self) -> genai.Client:
"""Loads and initializes a model for processing."""
client = genai.Client(
vertexai=True,
project=self._project,
location=self._location,
)
return client
def run_inference(
self,
batch: Sequence[str], # Each item is a JSON string
model: genai.Client,
inference_args: Optional[Dict[str, Any]] = None
) -> Iterable[PredictionResult]:
"""Runs inference on a batch of JSON strings to verify accuracy."""
for json_string in batch:
try:
element_dict = json.loads(json_string)
original_prompt = element_dict.get('original_prompt', '')
original_text = element_dict.get('original_text', '')
if not original_prompt or not original_text:
logging.warning(f"Accuracy input missing prompt/text: {json_string}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_ACCURACY_INPUT")
continue
prompt_for_accuracy = f"""
You are an AI assistant evaluating the accuracy of another AI agent's response to a given prompt.
Score the accuracy of the 'text' in fulfilling the 'prompt' from 0.0 to 1.0 (float).
0.0 is very bad, 1.0 is excellent.
Example of very bad, score of 0:
prompt: Give me the SQL for test_Table
text: SUre, here's a picture of a dog
Example of very good score of 1:
prompt: generate a sql statement to select all fields from test_table
text: SELECT * from test_table;
Your response should be ONLY the float score, followed by a brief explanation of why.
For example: "0.8 - The response was mostly accurate but missed a minor detail."
Prompt: "{original_prompt}"
Text: "{original_text}"
Score and Explanation:
"""
gemini_response = model.models.generate_content_stream(model=self._model_name, contents=[prompt_for_accuracy], config=self._model_kwargs)
gemini_response_text = ""
for chunk in gemini_response:
if chunk.text is not None:
gemini_response_text+=chunk.text
yield PredictionResult(example=json_string, inference=gemini_response_text)
except Exception as e:
logging.error(f"Error during Gemini accuracy inference for input {json_string}: {e}")
yield PredictionResult(example=json_string, inference="0.0 - ERROR_INFERENCE")
############## END STEP 3 ##############
Bu kodu çalıştırarak test edin:
python gemini_beam_pipeline_step3.py --project $PROJECT_ID --runner DirectRunner --test_mode
Bu adımda da bir çıkarım döndürülmeli, Gemini'ın aracın ne kadar doğru yanıt verdiğini düşündüğü yorumlanmalı ve puanlandırılmalıdır.
Aşağıdakine benzer bir çıkış alırsınız.
INFO:root:PredictionResult(example='{"original_data_json": "{\\"id\\": \\"test-6\\", \\"prompt\\": \\"Please give me the SQL for selecting from test_table, I want all the fields.\\", \\"text\\": \\"absolutely, here\'s a picture of a cat\\", \\"timestamp\\": 1751052770.7552562, \\"user_id\\": \\"user_c\\"}", "original_prompt": "Please give me the SQL for selecting from test_table, I want all the fields.", "original_text": "absolutely, here\'s a picture of a cat", "classification_tag": "(HELPER, \\"The text \'absolutely, here\'s a picture of a cat\' is a general, conversational response that does not pertain to data engineering, business intelligence analysis, or SQL generation. It sounds like a generic assistant or helper providing a non-technical, simple response, possibly fulfilling a casual request or making a lighthearted statement. Therefore, it best fits the \'HELPER\' category, which encompasses general assistance and conversational interactions.\\")"}', inference='0.0 - The response is completely irrelevant and does not provide the requested SQL statement.', model_id=None)
8. Sonuçları Pencereleme ve Analiz Etme
Artık sonuçlarınızı belirli zaman aralıklarında analiz etmek için pencereleyebilirsiniz. Verileri gruplandırmak için sabit aralıklar kullanırsınız. Bu sayede, toplu analizler elde edebilirsiniz. Pencereleme işleminden sonra, Gemini'dan gelen ham çıkışları orijinal veriler, sınıflandırma etiketi, doğruluk puanı ve açıklama gibi daha yapılandırılmış bir biçimde ayrıştıracaksınız.

Bu bölüm için gemini_beam_pipeline_step4.py dosyasını kullanın.
- Tüm verilerin 60 saniyelik bir pencereye yerleştirilmesi için 60 saniyelik sabit bir zaman aralığı ekleyin.
Aşağıdaki kodun bir örneğini burada bulabilirsiniz:
############## BEGIN STEP 4 ##############
| 'WindowIntoFixedWindows' >> beam.WindowInto(beam.window.FixedWindows(60))
############## END STEP 4 ##############
Bu kodu çalıştırarak test edin:
python gemini_beam_pipeline_step4.py --project $PROJECT_ID --runner DirectRunner --test_mode
Bu adım bilgilendirme amaçlıdır. Pencerenizi arıyorsunuz. Bu, pencere durdurma/başlatma zaman damgası olarak gösterilir.
Aşağıdakine benzer bir çıkış alırsınız.
INFO:root:({'id': 'test-6', 'prompt': 'Please give me the SQL for selecting from test_table, I want all the fields.', 'text': "absolutely, here's a picture of a cat", 'timestamp': 1751052901.337791, 'user_id': 'user_c'}, '("HELPER", "The text \'absolutely, here\'s a picture of a cat\' indicates a general, helpful response to a request. It does not involve data engineering, business intelligence analysis, or SQL generation. Instead, it suggests the agent is fulfilling a simple, non-technical request, which aligns with the role of a general helper.")', 0.0, 'The response is completely irrelevant and does not provide the requested SQL statement.', [1751052900.0, 1751052960.0))
9. Durum Bilgili İşleme ile İyi ve Kötü Sonuçları Sayma
Son olarak, her penceredeki "iyi" ve "kötü" sonuçları saymak için durum bilgisi olan bir DoFn kullanacaksınız. "İyi" bir sonuç, yüksek doğruluk puanına sahip bir etkileşim olabilirken "kötü" bir sonuç, düşük puanı gösterir. Durum bilgili işleme sayesinde, zaman içinde "kötü" etkileşim örnekleri toplayabilir ve sayıları koruyabilirsiniz. Bu, chatbot'unuzun sağlığını ve performansını gerçek zamanlı olarak izlemek için çok önemlidir.
Bu bölüm için gemini_beam_pipeline_step5.py dosyasını kullanın.
- Durum bilgili işlev oluşturma İki duruma ihtiyacınız vardır: (1) Hatalı sayıların sayısını takip etmek ve (2) gösterilecek hatalı kayıtları tutmak. Sistemin iyi performans gösterebilmesi için uygun kodlayıcıları kullanın.
- Kötü çıkarımla ilgili değerleri her gördüğünüzde her ikisini de takip etmek ve pencerenin sonunda yayınlamak istersiniz. Yayınladıktan sonra durumları sıfırlamayı unutmayın. İkincisi yalnızca örnek amaçlıdır. Gerçek bir ortamda bunların hepsini bellekte tutmaya çalışmayın.
Aşağıdaki kodun bir örneğini burada bulabilirsiniz:
############## BEGIN STEP 5 ##############
# Define a state specification for a combining value.
# This will store the running sum for each key.
# The coder is specified for efficiency.
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(), # Used VarIntCoder directly
beam.transforms.combiners.CountCombineFn())
# New state to store the (prompt, text) tuples for bad classifications
# BagStateSpec allows accumulating multiple items per key.
BAD_PROMPTS_STATE = beam.transforms.userstate.BagStateSpec(
'bad_prompts', coder=beam.coders.TupleCoder([beam.coders.StrUtf8Coder(), beam.coders.StrUtf8Coder()])
)
# Define a timer to fire at the end of the window, using WATERMARK as per blog example.
WINDOW_TIMER = TimerSpec('window_timer', TimeDomain.WATERMARK)
def process(
self,
element: Tuple[str, Tuple[int, Tuple[str, str]]], # (key, (count_val, (prompt, text)))
key=beam.DoFn.KeyParam,
count_state=beam.DoFn.StateParam(COUNT_STATE),
bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE), # New state param
window_timer=beam.DoFn.TimerParam(WINDOW_TIMER),
window=beam.DoFn.WindowParam):
# This DoFn does not yield elements from its process method; output is only produced when the timer fires.
if key == 'bad': # Only count 'bad' elements
count_state.add(element[1][0]) # Add the count (which is 1)
bad_prompts_state.add(element[1][1]) # Add the (prompt, text) tuple
window_timer.set(window.end) # Set timer to fire at window end
@on_timer(WINDOW_TIMER)
def on_window_timer(self, key=beam.DoFn.KeyParam, count_state=beam.DoFn.StateParam(COUNT_STATE), bad_prompts_state=beam.DoFn.StateParam(BAD_PROMPTS_STATE)):
final_count = count_state.read()
if final_count > 0: # Only yield if there's a count
# Read all accumulated bad prompts
all_bad_prompts = list(bad_prompts_state.read())
# Clear the state for the next window to avoid carrying over data.
count_state.clear()
bad_prompts_state.clear()
yield (key, final_count, all_bad_prompts) # Yield count and list of prompts
############## END STEP 5 ##############
Bu kodu çalıştırarak test edin:
python gemini_beam_pipeline_step5.py --project $PROJECT_ID --runner DirectRunner --test_mode
Bu adımda tüm sayımlar çıkış olarak verilmelidir. Pencerenin boyutuyla oynadığınızda grupların farklı olduğunu görürsünüz. Varsayılan pencere bir dakika içinde tamamlanır. Bu nedenle, 30 saniye veya başka bir zaman aralığı kullanmayı deneyin. Grupların ve sayıların farklı olduğunu göreceksiniz.
Aşağıdakine benzer bir çıkış alırsınız.
INFO:root:Window: [1751052960.0, 1751053020.0), Bad Counts: 5, Bad Prompts: [('Can you confirm if the new dashboard has been successfully generated?', 'I have gone ahead and generated a new dashboard for you.'), ('How is the new feature performing?', 'It works as expected.'), ('What is the capital of France?', 'The square root of a banana is purple.'), ('Explain quantum entanglement to a five-year-old.', 'A flock of geese wearing tiny hats danced the tango on the moon.'), ('Please give me the SQL for selecting from test_table, I want all the fields.', "absolutely, here's a picture of a cat")]
10. Temizleme
- Google Cloud projesini silin (isteğe bağlıdır ancak codelab'ler için önerilir): Bu proje yalnızca bu codelab için oluşturulduysa ve artık ihtiyacınız yoksa tüm kaynakların kaldırıldığından emin olmanın en kapsamlı yolu projenin tamamını silmektir.
- Google Cloud Console'da Kaynakları yönetin sayfasına gidin.
- Projenizi seçin.
- Projeyi Sil'i tıklayın ve ekrandaki talimatları uygulayın.
11. Tebrikler!
Tebrikler, codelab'i tamamladınız. Dataflow'da Apache Beam ve Gemini'ı kullanarak gerçek zamanlı bir makine öğrenimi çıkarımı ardışık düzeni başarıyla oluşturdunuz. Üretken yapay zekanın gücünü veri akışlarınıza taşıyarak daha akıllı ve otomatik veri mühendisliği için değerli analizler elde etmeyi öğrendiniz.