
1. مقدمة
في هذا الدرس التطبيقي حول الترميز، ستتعلّم كيفية إنشاء وكلاء يمكنهم الإجابة عن أسئلة حول البيانات المخزّنة في BigQuery باستخدام حزمة تطوير الوكلاء (ADK). ستقيّم أيضًا هؤلاء الوكلاء باستخدام خدمة GenAI Evaluation من Vertex AI:
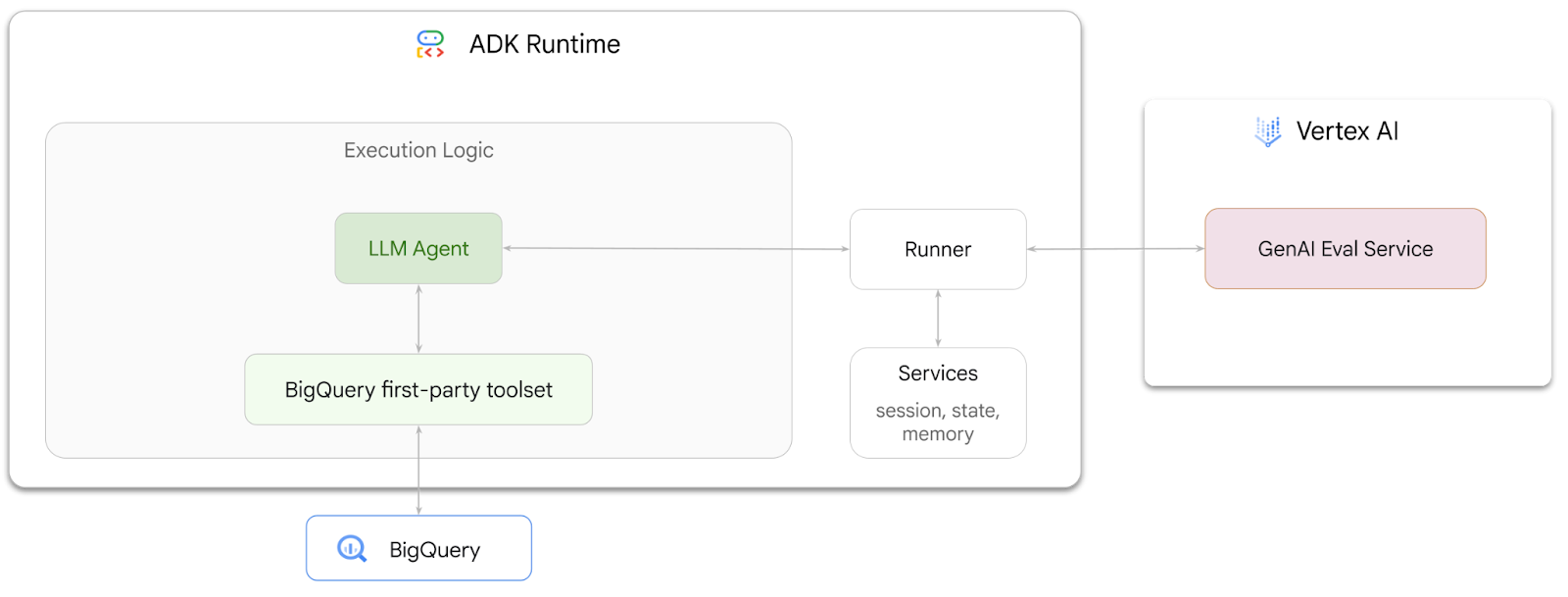
المهام التي ستنفِّذها
- إنشاء وكيل لتحليل المحادثات في ADK
- زوِّد هذا الوكيل بمجموعة أدوات الطرف الأول في ADK لـ BigQuery حتى يتمكّن من التفاعل مع البيانات المخزّنة في BigQuery
- إنشاء إطار عمل للتقييم للوكيل باستخدام خدمة Vertex AI GenAI Evaluation
- إجراء تقييمات على هذا الوكيل استنادًا إلى مجموعة من الردود النموذجية
المتطلبات
- متصفّح ويب، مثل Chrome
- مشروع على السحابة الإلكترونية من Google Cloud تم تفعيل الفوترة فيه
- حساب Gmail سيوضّح لك القسم التالي كيفية الاستفادة من رصيد مجاني بقيمة 5 دولار أمريكي لهذا الدرس التطبيقي حول الترميز وإعداد مشروع جديد.
هذا الدرس التطبيقي حول الترميز مخصّص للمطوّرين من جميع المستويات، بما في ذلك المبتدئين. ستستخدم واجهة سطر الأوامر في Google Cloud Shell ورمز Python لتطوير حزمة تطوير الوكلاء (ADK). ليس عليك أن تكون خبيرًا في Python، ولكنّ فهمًا أساسيًا لكيفية قراءة الرموز البرمجية سيساعدك في فهم المفاهيم.
2. قبل البدء
إنشاء مشروع على Google Cloud
- في Google Cloud Console، في صفحة اختيار المشروع، اختَر مشروعًا على السحابة الإلكترونية أو أنشِئ مشروعًا على السحابة الإلكترونية.
- تأكَّد من تفعيل الفوترة لمشروعك على Cloud. كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع
بدء Cloud Shell
Cloud Shell هي بيئة سطر أوامر تعمل في Google Cloud ومحمّلة مسبقًا بالأدوات اللازمة.
- انقر على تفعيل Cloud Shell في أعلى "وحدة تحكّم Google Cloud":

- بعد الاتصال بـ Cloud Shell، نفِّذ الأمر التالي للتحقّق من مصادقتك في Cloud Shell:
gcloud auth list
- نفِّذ الأمر التالي للتأكّد من إعداد مشروعك لاستخدامه مع gcloud:
gcloud config list project
- استخدِم الأمر التالي لضبط مشروعك:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
تفعيل واجهات برمجة التطبيقات
- نفِّذ الأمر التالي لتفعيل جميع واجهات برمجة التطبيقات والخدمات المطلوبة:
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- عند تنفيذ الأمر بنجاح، من المفترض أن تظهر لك رسالة مشابهة للرسالة الموضّحة أدناه:
Operation "operations/..." finished successfully.
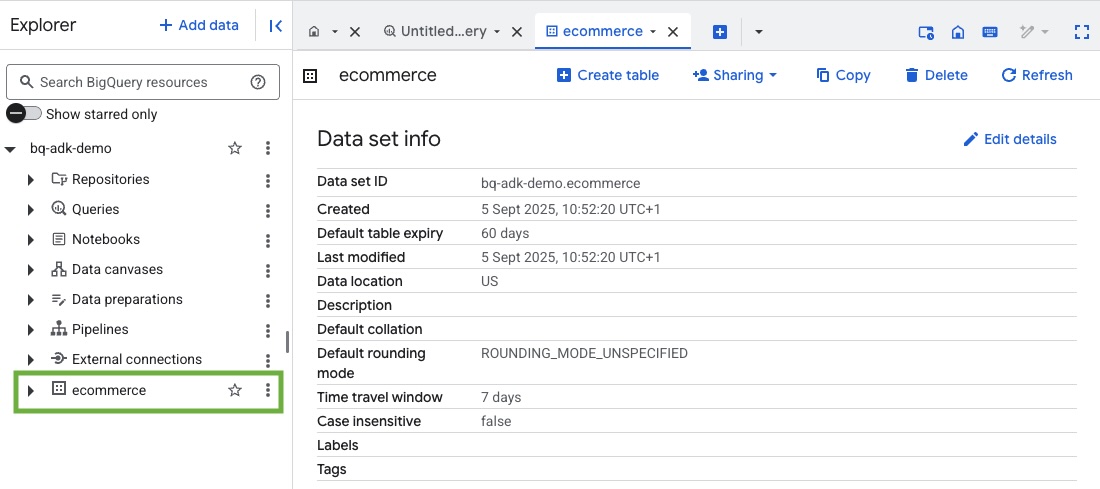
3- إنشاء مجموعة بيانات في BigQuery
- نفِّذ الأمر التالي في Cloud Shell لإنشاء مجموعة بيانات جديدة باسم ecommerce في BigQuery:
bq mk --dataset --location=US ecommerce
يتم حفظ مجموعة فرعية ثابتة من مجموعة البيانات العامة في BigQuery thelook_ecommerce كملفات AVRO في حزمة Google Cloud Storage متاحة للجميع.
- نفِّذ هذا الأمر في Cloud Shell لتحميل ملفات Avro هذه إلى BigQuery كجداول (الأحداث، وعناصر الطلبات، والمنتجات، والمستخدمون، والطلبات):
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
قد تستغرق هذه العملية بضع دقائق.
- تأكَّد من إنشاء مجموعة البيانات والجداول من خلال الانتقال إلى وحدة تحكّم BigQuery في مشروعك على Google Cloud:
4. إعداد البيئة لوكلاء ADK
ارجع إلى Cloud Shell وتأكَّد من أنّك في دليل المنزل. سننشئ بيئة Python افتراضية ونثبّت الحِزم المطلوبة.
- افتح علامة تبويب وحدة طرفية جديدة في Cloud Shell ونفِّذ هذا الأمر لإنشاء مجلد باسم bigquery-adk-codelab والانتقال إليه:
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- أنشئ بيئة Python افتراضية:
python -m venv .venv
- فعِّل البيئة الافتراضية:
source .venv/bin/activate
- ثبِّت حِزم Python الخاصة بأدوات تطوير التطبيقات (ADK) وAI Platform من Google. يجب توفّر منصة الذكاء الاصطناعي وحزمة pandas لتقييم وكيل BigQuery:
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5- إنشاء تطبيق ADK
لننشئ الآن وكيل BigQuery. سيتم تصميم هذا الوكيل للإجابة عن الأسئلة المُدخَلة باللغة العادية حول البيانات المخزَّنة في BigQuery.
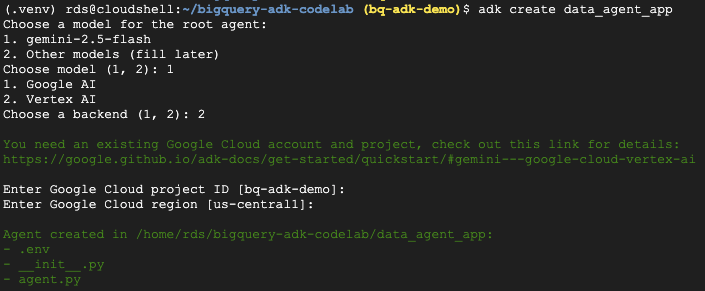
- نفِّذ أمر أداة إنشاء حزمة تطوير التطبيقات لإنشاء بنية تطبيق وكيل جديد تتضمّن المجلدات والملفات اللازمة:
adk create data_agent_app
اتّبِع التعليمات:
- اختَر gemini-2.5-flash للنموذج.
- اختَر Vertex AI للخادم الخلفي.
- أكِّد رقم تعريف مشروع Google Cloud التلقائي والمنطقة.
في ما يلي نموذج للتفاعل:
- انقر على الزر "فتح المحرّر" في Cloud Shell لفتح "محرّر Cloud Shell" وعرض المجلدات والملفات التي تم إنشاؤها حديثًا:

دوِّن الملفات التي تم إنشاؤها:
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: يضع علامة على المجلد باعتباره وحدة Python.
- agent.py: يحتوي على تعريف الوكيل الأولي.
- .env: يحتوي على متغيرات البيئة لمشروعك (قد تحتاج إلى النقر على "عرض" > "تبديل الملفات المخفية" لعرض هذا الملف)
عدِّل أي متغيرات لم يتم ضبطها بشكل صحيح من الطلبات:
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. تحديد الوكيل وتعيين مجموعة أدوات BigQuery له
لتحديد وكيل ADK يتفاعل مع BigQuery باستخدام مجموعة أدوات BigQuery، استبدِل المحتوى الحالي لملف agent.py بالرمز التالي.
يجب تعديل رقم تعريف المشروع في تعليمات الوكيل إلى رقم تعريف مشروعك الفعلي:
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
توفّر مجموعة أدوات BigQuery برنامجًا مزوّدًا بإمكانات استرداد البيانات الوصفية وتنفيذ طلبات بحث SQL على بيانات BigQuery. لاستخدام مجموعة الأدوات، يجب المصادقة باستخدام الخيارات الأكثر شيوعًا، مثل "بيانات الاعتماد التلقائية للتطبيق" (ADC) لأغراض التطوير، أو بروتوكول OAuth التفاعلي عندما يحتاج الوكيل إلى اتّخاذ إجراء نيابةً عن مستخدم معيّن، أو بيانات اعتماد حساب الخدمة للمصادقة الآمنة على مستوى الإنتاج.
يمكنك من هنا الدردشة مع وكيلك من خلال الرجوع إلى Cloud Shell وتشغيل الأمر التالي:
adk web
من المفترض أن يظهر لك إشعار يفيد بأنّ خادم الويب قد بدأ:
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
انقر على عنوان URL المقدَّم لتشغيل adk web، ويمكنك طرح بعض الأسئلة على الوكيل بشأن مجموعة البيانات:
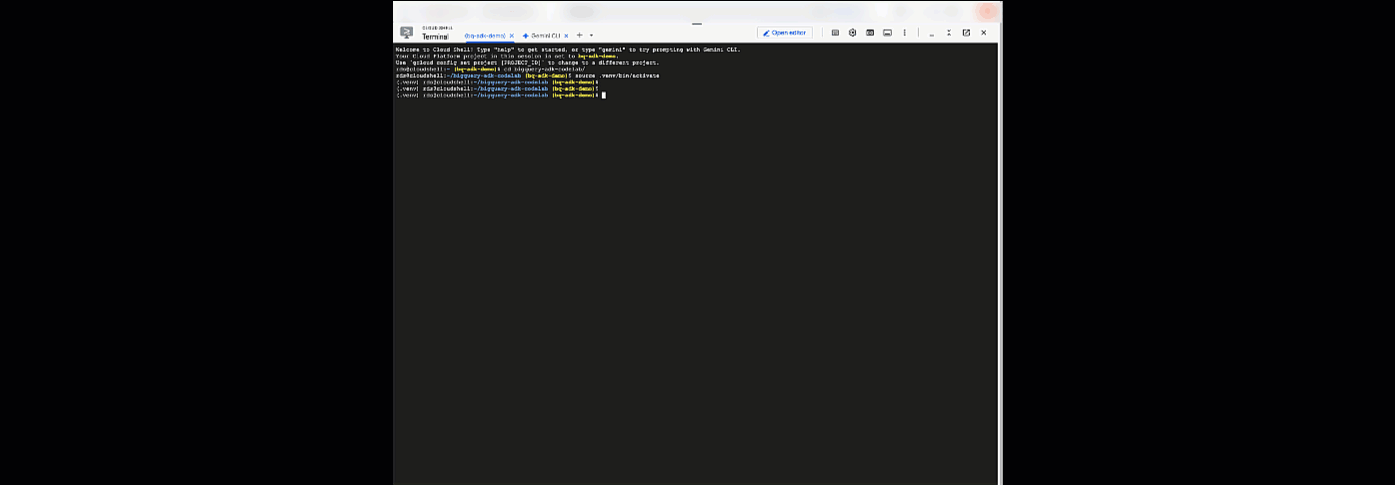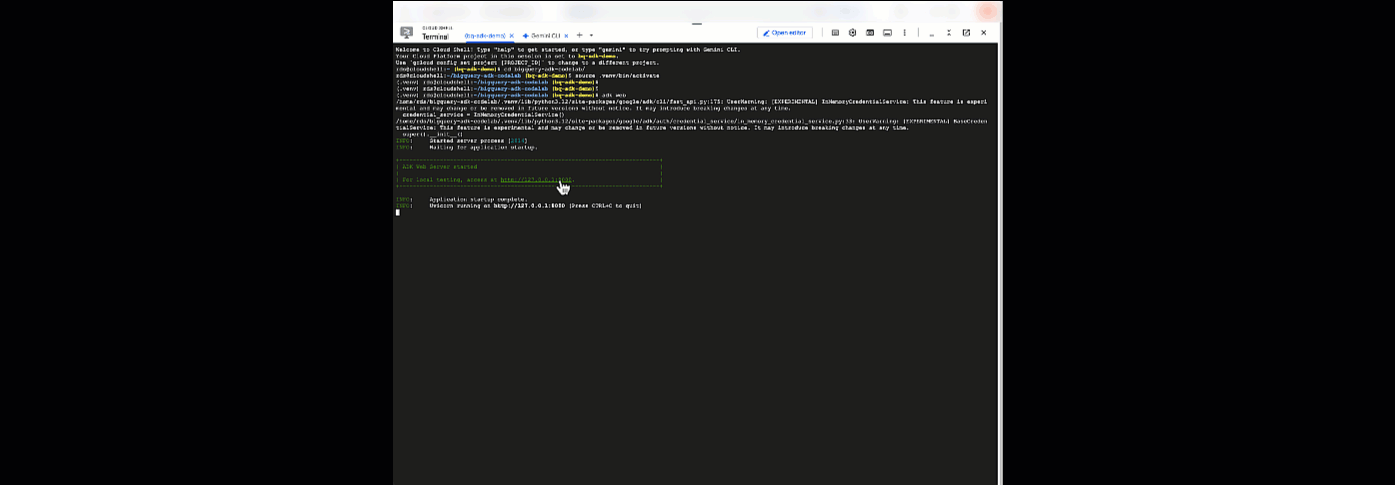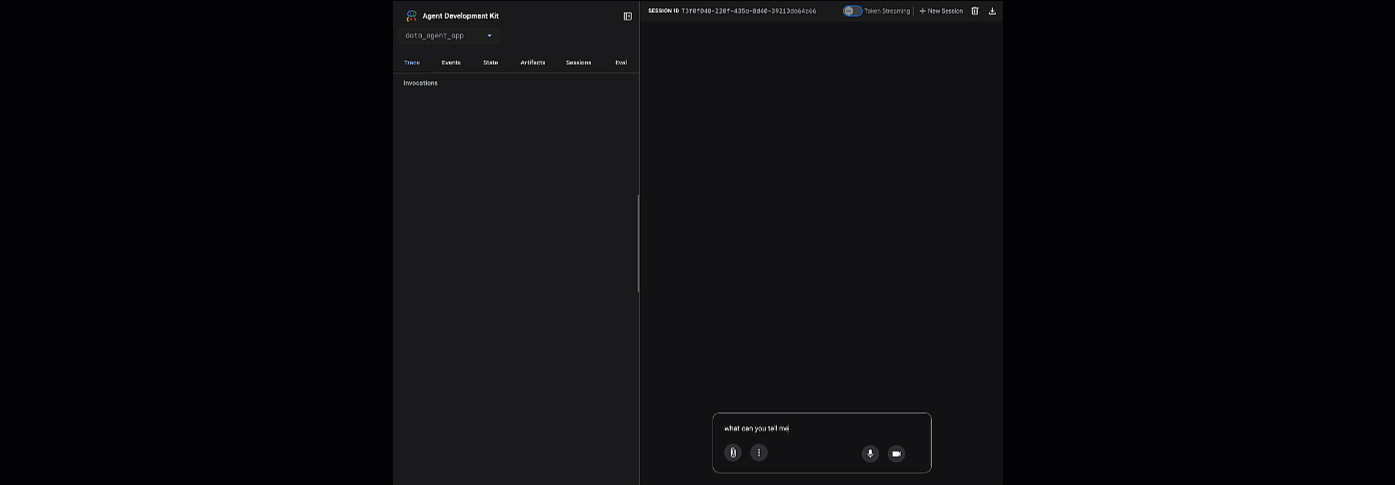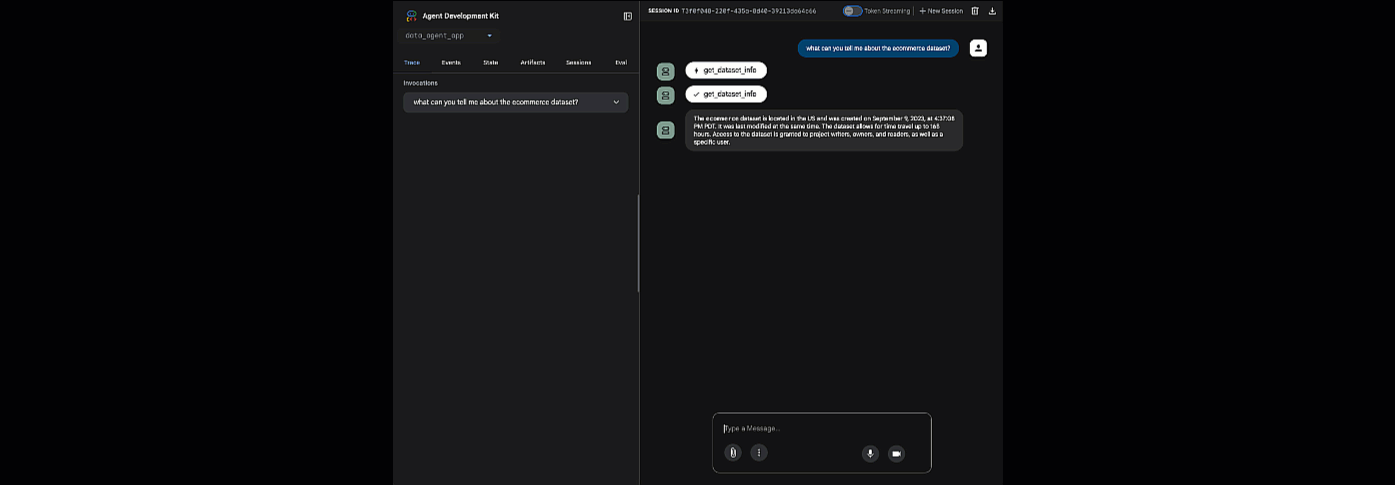
أغلِق adk web واضغط على Ctrl + C في الوحدة الطرفية لإيقاف خادم الويب.
7. إعداد الوكيل للتقييم
بعد تحديد وكيل BigQuery، عليك إعداده ليكون قابلاً للتنفيذ من أجل التقييم.
يحدّد الرمز البرمجي أدناه دالة، run_conversation، تعالج مسار المحادثة من خلال إنشاء وكيل وتشغيل جلسة ومعالجة الأحداث لاسترداد الرد النهائي.
- ارجع إلى Cloud Editor وأنشئ ملفًا جديدًا باسم
run_agent.pyفي دليل bigquery-adk-codelab وانسخ الرمز أدناه وألصِقه:
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
يحدّد الرمز البرمجي أدناه دوال مساعدة لاستدعاء هذه الدالة القابلة للتنفيذ وعرض النتيجة. يتضمّن أيضًا دوال مساعِدة تطبع نتائج التقييم وتحفظها:
- أنشئ ملفًا جديدًا باسم
utils.pyفي دليل bigquery-adk-codelab وانسخ هذا الرمز والصقه في ملف utils.py:
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. إنشاء مجموعة بيانات تقييم
لتقييم الوكيل، عليك إنشاء مجموعة بيانات التقييم وتحديد مقاييس التقييم وتنفيذ مهمة التقييم.
تحتوي مجموعة بيانات التقييم على قائمة بأسئلة (طلبات) وإجاباتها الصحيحة (مراجع). ستستخدم خدمة التقييم هذه الأزواج لمقارنة ردود برنامجك الحواري وتحديد ما إذا كانت دقيقة.
- أنشئ ملفًا جديدًا باسم evaluation_dataset.json في الدليل bigquery-adk-codelab وانسخ مجموعة بيانات التقييم أدناه والصقها:
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. تحديد مقاييس التقييم
سنستخدم الآن مقياسَين مخصّصَين لتقييم قدرة الوكيل على الإجابة عن الأسئلة المتعلّقة ببياناتك في BigQuery، وسيقدم كلّ منهما نتيجة تتراوح بين 1 و5:
- مقياس الدقة الواقعية: يقيس هذا المقياس ما إذا كانت جميع البيانات والحقائق المقدَّمة في الرد دقيقة وصحيحة عند مقارنتها بالبيانات الأساسية.
- مقياس الاكتمال: يقيس هذا المقياس ما إذا كان الرد يتضمّن جميع المعلومات الأساسية التي طلبها المستخدم والموجودة في الإجابة الصحيحة، بدون أي إغفال مهم.
- أخيرًا، أنشئ ملفًا جديدًا باسم
evaluate_agent.pyفي دليل bigquery-adk-codelab وانسخ/الصق رمز تعريف المقياس في ملف evaluate_agent.py:
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
لقد أدرجتُ أيضًا مقياس TrajectorySingleToolUse من أجل تقييم المسار. عند توفّر هذه المقاييس، سيتم تضمين طلبات أداة الوكيل (بما في ذلك SQL الأولي الذي يتم إنشاؤه وتنفيذه في BigQuery) في ردّ التقييم، ما يتيح إجراء فحص تفصيلي.
يقيس مقياس TrajectorySingleToolUse ما إذا كان أحد العملاء قد استخدم أداة معيّنة. في هذه الحالة، اخترت list_table_ids، لأنّنا نتوقّع أن يتم استدعاء هذه الأداة لكل سؤال في مجموعة بيانات التقييم. على عكس مقاييس المسار الأخرى، لا يتطلّب هذا المقياس تحديد جميع استدعاءات الأدوات والحجج المتوقّعة لكل سؤال في مجموعة بيانات التقييم.
10. إنشاء مهمة التقييم
تأخذ مهمة EvalTask مجموعة بيانات التقييم والمقاييس المخصّصة وتُعدّ تجربة تقييم جديدة.
هذه الدالة، run_eval، هي المحرك الرئيسي للتقييم. تتكرّر هذه العملية من خلال EvalTask، ما يؤدي إلى تشغيل الوكيل على كل سؤال في مجموعة البيانات. بالنسبة إلى كل سؤال، يسجّل الردّ الذي قدّمه الموظف ثم يستخدم المقاييس التي حدّدتها سابقًا لتقييمه.
انسخ الرمز التالي وألصِقه في أسفل ملف evaluate_agent.py:
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
يتم تلخيص النتائج وحفظها في ملف JSON.
11. إجراء التقييم
بعد أن أصبحت لديك الآن مجموعة بيانات التقييم ومقاييس التقييم والوكيل، يمكنك إجراء التقييم.
ارجع إلى Cloud Shell، وتأكَّد من أنّك في دليل bigquery-adk-codelab، ونفِّذ نص التقييم البرمجي باستخدام الأمر التالي:
python evaluate_agent.py
ستظهر لك نتيجة مشابهة لما يلي أثناء تقدُّم عملية التقييم:
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
إذا واجهت أي أخطاء مثل الأخطاء أدناه، يعني ذلك ببساطة أنّ البرنامج لم يستدعِ أي أدوات لتنفيذ عملية معيّنة. يمكنك فحص سلوك البرنامج بشكل أكبر في الخطوة التالية.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
تفسير النتائج:
انتقِل إلى المجلد eval_results في دليل data_agent_app وافتح ملف نتيجة التقييم باسم bq_agent_eval_results_*.json:
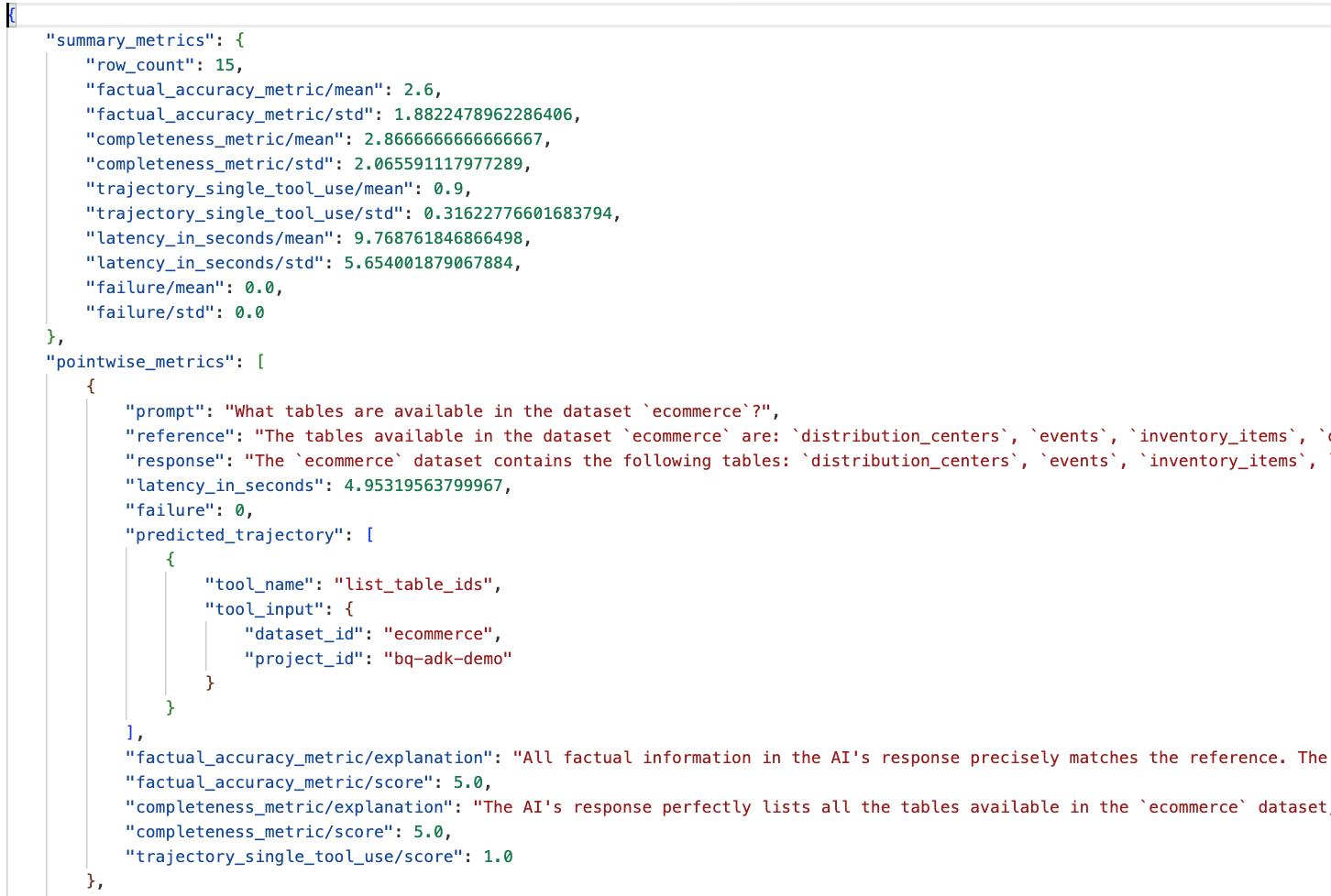
- مقاييس الملخّص: تقدّم هذه المقاييس عرضًا مجمّعًا لأداء الموظف في مجموعة البيانات.
- مقاييس دقة الحقائق واكتمالها على مستوى كل نقطة: تشير النتيجة الأقرب إلى 5 إلى دقة واكتمال أعلى. سيتم عرض درجة لكل سؤال، بالإضافة إلى شرح مكتوب لسبب حصوله على هذه الدرجة.
- المسار المتوقّع: هذه هي قائمة طلبات الأدوات التي تستخدمها البرامج للوصول إلى الردّ النهائي. سيسمح لنا ذلك بالاطّلاع على أي طلبات SQL أنشأها الوكيل.
يمكننا أن نرى أنّ متوسط درجة الاكتمال والدقة الواقعية هو 2.87 و2.6 على التوالي.
النتائج ليست جيدة جدًا. لنجرّب تحسين قدرة الوكيل على الإجابة عن الأسئلة.
12. تحسين نتائج تقييم الوكيل
انتقِل إلى الملف agent.py في الدليل bigquery-adk-codelab وعدِّل نموذج الوكيل وتعليمات النظام. تذكَّر استبدال <YOUR_PROJECT_ID> برقم تعريف مشروعك:
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
الآن، ارجع إلى الوحدة الطرفية وأعِد تنفيذ التقييم:
python evaluate_agent.py
من المفترض أن تلاحظ تحسّنًا كبيرًا في النتائج:
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
تقييم الوكيل هو عملية تكرارية. لتحسين نتائج التقييم بشكل أكبر، يمكنك تعديل تعليمات النظام أو مَعلمات النموذج أو حتى البيانات الوصفية في BigQuery. يمكنك الاطّلاع على هذه النصائح والحيل للحصول على المزيد من الأفكار.
13. تنظيف
لتجنُّب تحصيل رسوم مستمرة من حسابك على Google Cloud، من المهم حذف الموارد التي أنشأناها خلال ورشة العمل هذه.
إذا أنشأت أي مجموعات بيانات أو جداول محدّدة في BigQuery لهذا الدرس التطبيقي حول الترميز (مثل مجموعة بيانات التجارة الإلكترونية)، يمكنك حذفها باتّباع الخطوات التالية:
bq rm -r $PROJECT_ID:ecommerce
لإزالة الدليل bigquery-adk-codelab ومحتواه، اتّبِع الخطوات التالية:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. تهانينا
تهانينا! لقد أنشأت وكيل BigQuery وقمت بتقييمه بنجاح باستخدام "حزمة تطوير الوكلاء" (ADK). أصبحت الآن على دراية بكيفية إعداد وكيل ADK باستخدام أدوات BigQuery وقياس أدائه باستخدام مقاييس التقييم المخصّصة.