
1. Einführung
In diesem Codelab erfahren Sie, wie Sie mit dem Agent Development Kit (ADK) Agents erstellen, die Fragen zu in BigQuery gespeicherten Daten beantworten können. Außerdem bewerten Sie diese Agents mit dem GenAI Evaluation Service von Vertex AI:
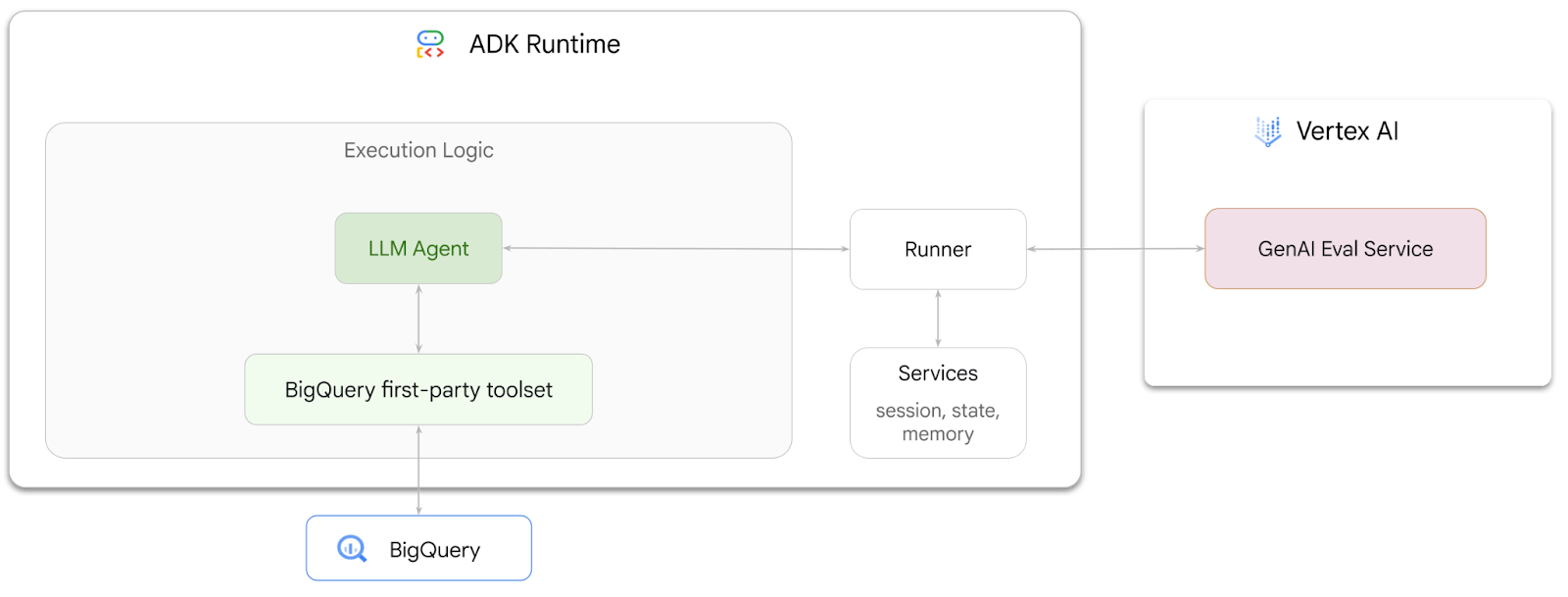
Aufgaben
- KI-Agent für konversationelle Analyse im ADK erstellen
- Stellen Sie diesem Agenten das ADK-Toolset für selbst erhobene Daten für BigQuery zur Verfügung, damit er mit in BigQuery gespeicherten Daten interagieren kann.
- Bewertungsframework für Ihren Agenten mit dem Vertex AI GenAI Evaluation Service erstellen
- Bewertungen für diesen KI-Agenten anhand einer Reihe von Referenzantworten ausführen
Voraussetzungen
- Ein Webbrowser wie Chrome
- Ein Google Cloud-Projekt mit aktivierter Abrechnung oder
- Ein Gmail-Konto. Im nächsten Abschnitt erfahren Sie, wie Sie ein kostenloses Guthaben in Höhe von 5 $ für dieses Codelab einlösen und ein neues Projekt einrichten.
Dieses Codelab richtet sich an Entwickler aller Erfahrungsstufen, auch an Anfänger. Sie verwenden die Befehlszeile in Google Cloud Shell und Python-Code für die ADK-Entwicklung. Sie müssen kein Python-Experte sein, aber ein grundlegendes Verständnis dafür, wie man Code liest, wird Ihnen helfen, die Konzepte zu verstehen.
2. Hinweis
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud Shell starten
Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und mit den erforderlichen Tools vorinstalliert ist.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren:

- Führen Sie nach der Verbindung mit Cloud Shell diesen Befehl aus, um Ihre Authentifizierung in Cloud Shell zu überprüfen:
gcloud auth list
- Führen Sie den folgenden Befehl aus, um zu bestätigen, dass Ihr Projekt für die Verwendung mit gcloud konfiguriert ist:
gcloud config list project
- Verwenden Sie den folgenden Befehl, um Ihr Projekt festzulegen:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
APIs aktivieren
- Führen Sie diesen Befehl aus, um alle erforderlichen APIs und Dienste zu aktivieren:
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- Bei erfolgreicher Ausführung des Befehls sollte eine Meldung wie die unten gezeigte angezeigt werden:
Operation "operations/..." finished successfully.
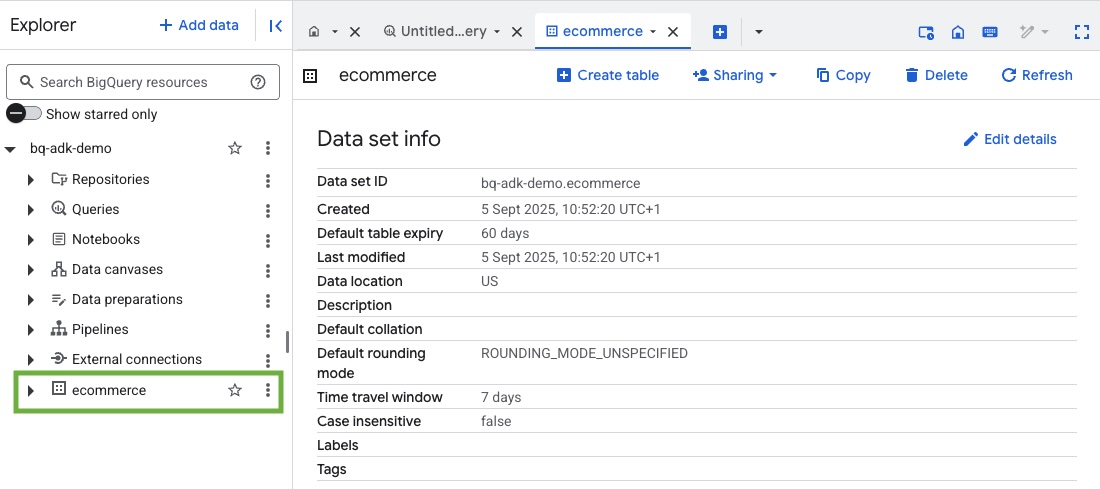
3. BigQuery-Dataset erstellen
- Führen Sie den folgenden Befehl in Cloud Shell aus, um ein neues Dataset mit dem Namen „ecommerce“ in BigQuery zu erstellen:
bq mk --dataset --location=US ecommerce
Eine statische Teilmenge des öffentlichen BigQuery-Datasets thelook_ecommerce wird als AVRO-Dateien in einem öffentlichen Google Cloud Storage-Bucket gespeichert.
- Führen Sie diesen Befehl in Cloud Shell aus, um diese Avro-Dateien als Tabellen (events, order_items, products, users, orders) in BigQuery zu laden:
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
Der Vorgang kann einige Minuten dauern.
- Prüfen Sie, ob das Dataset und die Tabellen erstellt wurden. Rufen Sie dazu in Ihrem Google Cloud-Projekt die BigQuery-Konsole auf:
4. Umgebung für ADK-KI-Agenten vorbereiten
Kehren Sie zu Cloud Shell zurück und vergewissern Sie sich, dass Sie sich in Ihrem Basisverzeichnis befinden. Wir erstellen eine virtuelle Python-Umgebung und installieren die erforderlichen Pakete.
- Öffnen Sie einen neuen Terminaltab in Cloud Shell und führen Sie den folgenden Befehl aus, um einen Ordner mit dem Namen bigquery-adk-codelab zu erstellen und zu öffnen:
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- Erstellen Sie eine virtuelle Python-Umgebung:
python -m venv .venv
- Aktivieren Sie die virtuelle Umgebung:
source .venv/bin/activate
- Installieren Sie das ADK und die AI Platform-Python-Pakete von Google. Für die Bewertung des BigQuery-Agents sind die KI-Plattform und das Pandas-Paket erforderlich:
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. ADK-Anwendung erstellen
Jetzt erstellen wir unseren BigQuery-Agenten. Dieser Agent soll Fragen in natürlicher Sprache zu in BigQuery gespeicherten Daten beantworten.
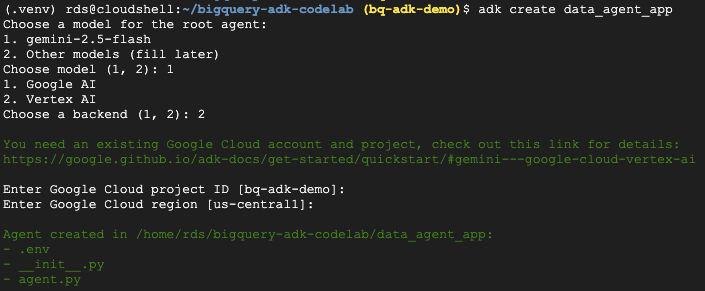
- Führen Sie den Befehl zum Erstellen des ADK-Dienstprogramms aus, um eine neue Agent-Anwendung mit den erforderlichen Ordnern und Dateien zu erstellen:
adk create data_agent_app
Folgen Sie der Anleitung:
- Wählen Sie „gemini-2.5-flash“ als Modell aus.
- Wählen Sie Vertex AI als Backend aus.
- Bestätigen Sie Ihre Standard-Google Cloud-Projekt-ID und -Region.
Unten sehen Sie eine Beispielinteraktion:
- Klicken Sie in Cloud Shell auf die Schaltfläche „Editor öffnen“, um den Cloud Shell-Editor zu öffnen und die neu erstellten Ordner und Dateien anzusehen:

Sehen Sie sich die generierten Dateien an:
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py::Kennzeichnet den Ordner als Python-Modul.
- agent.py::Enthält die ursprüngliche Definition des KI-Agenten.
- .env:Enthält Umgebungsvariablen für Ihr Projekt. Möglicherweise müssen Sie auf „Ansicht“ > „Versteckte Dateien einblenden“ klicken, um diese Datei zu sehen.
Aktualisieren Sie alle Variablen, die nicht korrekt über die Prompts festgelegt wurden:
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. KI‑Agenten definieren und ihm das BigQuery-Toolset zuweisen
Wenn Sie einen ADK-Agenten definieren möchten, der mit BigQuery interagiert und das BigQuery-Toolset verwendet, ersetzen Sie den vorhandenen Inhalt der Datei agent.py durch den folgenden Code.
Sie müssen die Projekt-ID in der Anleitung des Agents durch Ihre tatsächliche Projekt-ID ersetzen:
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
Das BigQuery-Toolset bietet einem Agenten die Möglichkeit, Metadaten abzurufen und SQL-Abfragen für BigQuery-Daten auszuführen. Um das Toolset zu verwenden, müssen Sie sich authentifizieren. Die gängigsten Optionen sind Standardanmeldedaten für Anwendungen (Application Default Credentials, ADC) für die Entwicklung, interaktives OAuth, wenn der Agent im Namen eines bestimmten Nutzers agieren muss, oder Dienstkonto-Anmeldedaten für die sichere Authentifizierung auf Produktionsebene.
Von hier aus können Sie mit Ihrem Agent chatten, indem Sie zu Cloud Shell zurückkehren und diesen Befehl ausführen:
adk web
Sie sollten eine Benachrichtigung sehen, dass der Webserver gestartet wurde:
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
Klicken Sie auf die angegebene URL, um ADK Web zu starten. Sie können Ihrem Agenten einige Fragen zum Dataset stellen:
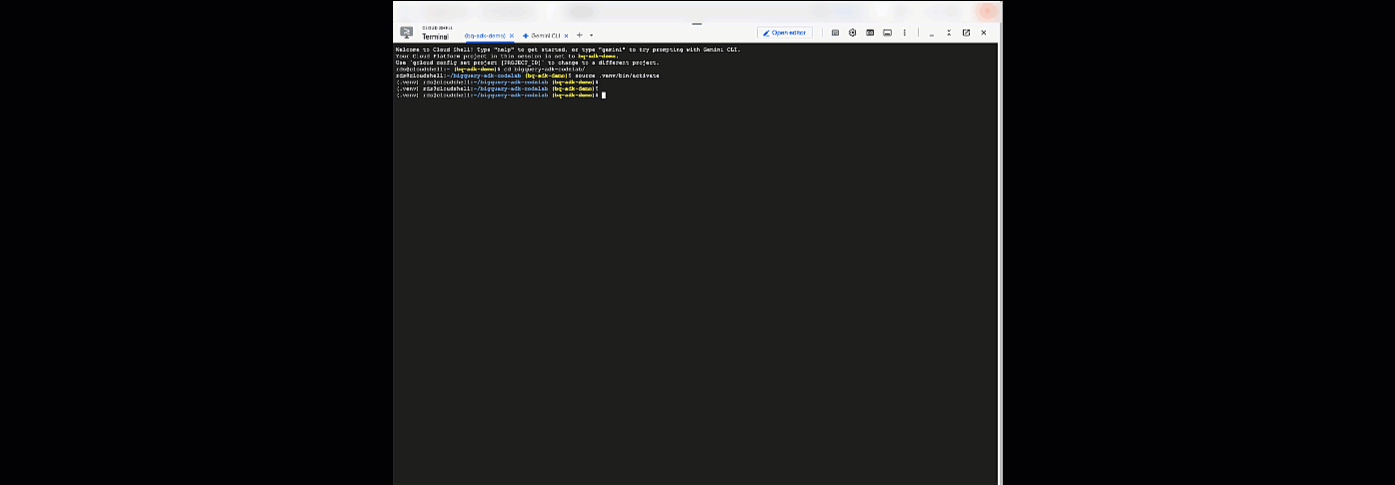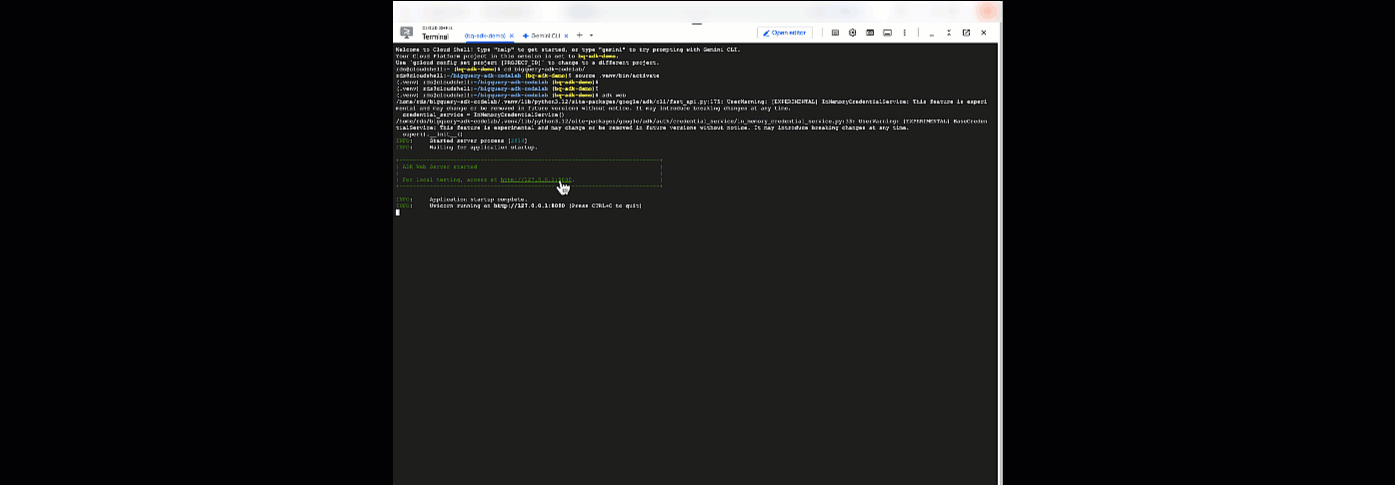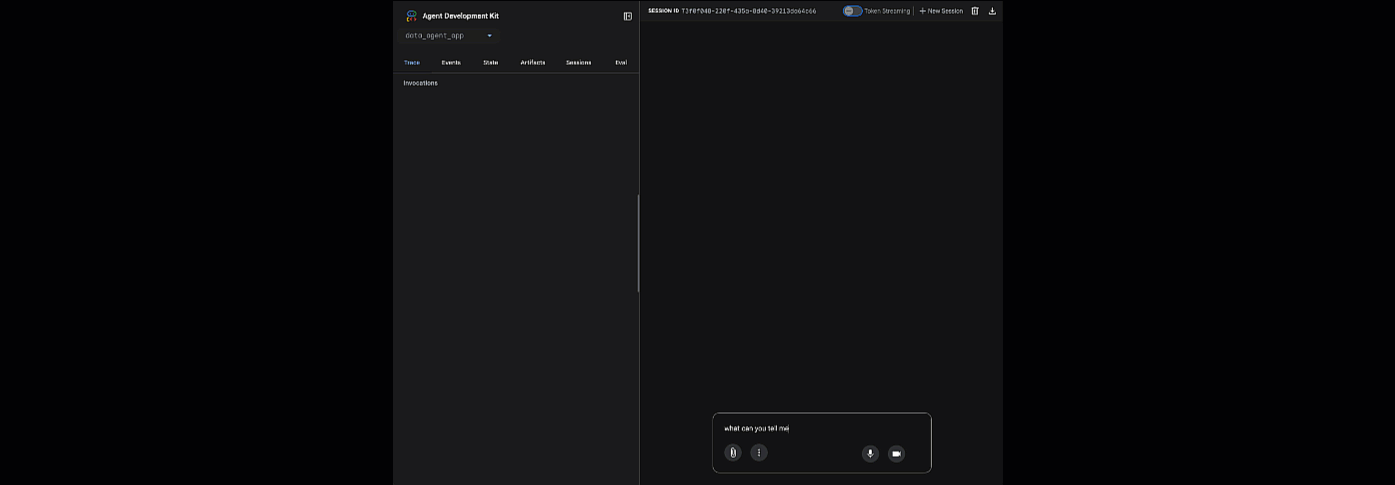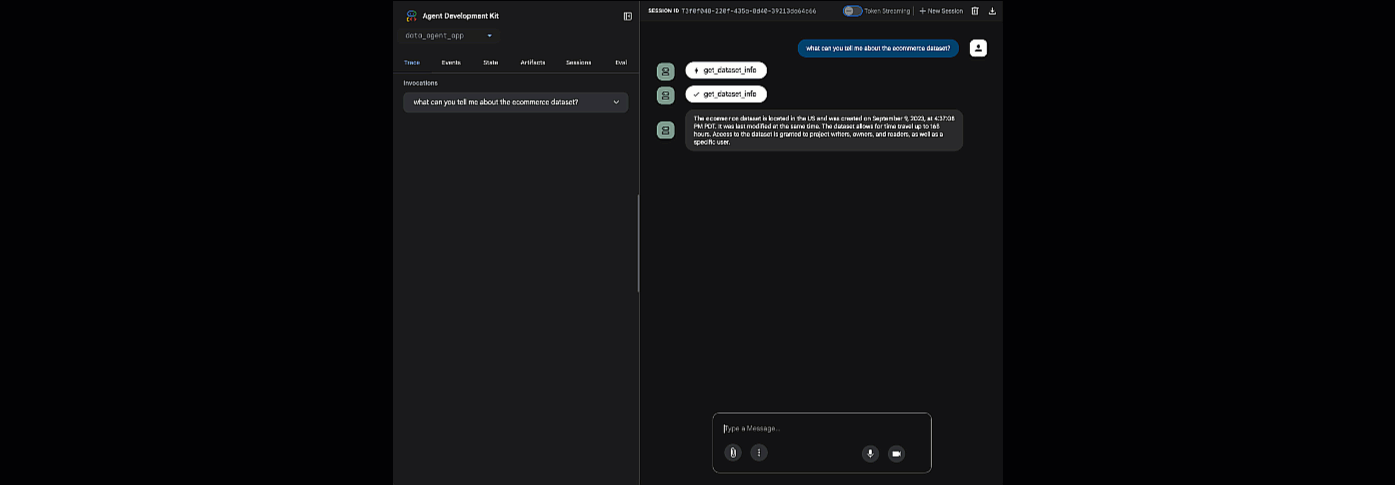
Schließen Sie „adk web“ und drücken Sie im Terminal Strg + C, um den Webserver zu beenden.
7. KI-Agenten für die Bewertung vorbereiten
Nachdem Sie Ihren BigQuery-Agenten definiert haben, müssen Sie ihn für die Auswertung ausführbar machen.
Im folgenden Code wird eine Funktion, run_conversation, definiert, die den Unterhaltungsablauf verarbeitet, indem sie einen Agenten erstellt, eine Sitzung ausführt und die Ereignisse verarbeitet, um die endgültige Antwort abzurufen.
- Wechseln Sie zurück zum Cloud Editor und erstellen Sie im Verzeichnis „bigquery-adk-codelab“ eine neue Datei mit dem Namen
run_agent.py. Kopieren Sie den folgenden Code und fügen Sie ihn ein:
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
Im folgenden Code werden Hilfsfunktionen definiert, mit denen diese ausführbare Funktion aufgerufen und das Ergebnis zurückgegeben wird. Es enthält auch Hilfsfunktionen zum Drucken und Speichern der Bewertungsergebnisse:
- Erstellen Sie im Verzeichnis „bigquery-adk-codelab“ eine neue Datei mit dem Namen
utils.pyund kopieren Sie diesen Code in die Datei „utils.py“:
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. Bewertungs-Dataset erstellen
Um Ihren Agenten zu bewerten, müssen Sie ein Bewertungs-Dataset erstellen, Bewertungsmesswerte definieren und die Bewertungsaufgabe ausführen.
Das Bewertungs-Dataset enthält eine Liste mit Fragen (Prompts) und den entsprechenden richtigen Antworten (Referenzen). Der Evaluierungsdienst verwendet diese Paare, um die Antworten Ihres Agents zu vergleichen und festzustellen, ob sie korrekt sind.
- Erstellen Sie im Verzeichnis „bigquery-adk-codelab“ eine neue Datei mit dem Namen „evaluation_dataset.json“ und kopieren Sie das Evaluierungs-Dataset unten hinein:
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. Bewertungsmesswerte definieren
Wir verwenden jetzt zwei benutzerdefinierte Messwerte, um die Fähigkeit des Agents zu bewerten, Fragen zu Ihren BigQuery-Daten zu beantworten. Beide Messwerte liefern einen Wert zwischen 1 und 5:
- Messwert für sachliche Richtigkeit:Hier wird bewertet, ob alle in der Antwort präsentierten Daten und Fakten im Vergleich zum Ground Truth präzise und korrekt sind.
- Messwert für Vollständigkeit:Dieser Messwert gibt an, ob die Antwort alle wichtigen Informationen enthält, die vom Nutzer angefordert wurden und in der richtigen Antwort enthalten sind, ohne dass kritische Auslassungen vorliegen.
- Erstellen Sie schließlich im Verzeichnis „bigquery-adk-codelab“ eine neue Datei mit dem Namen
evaluate_agent.pyund kopieren Sie den Code für die Messwertdefinition in die Datei „evaluate_agent.py“:
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
Außerdem habe ich den Messwert „TrajectorySingleToolUse“ für die Bewertung von Vorgehensweisen eingefügt. Wenn diese Messwerte vorhanden sind, werden die Tool-Aufrufe des Agents (einschließlich des von ihm generierten und in BigQuery ausgeführten Roh-SQL-Codes) in die Antwort der Auswertung aufgenommen, was eine detaillierte Prüfung ermöglicht.
Mit der Messwert „TrajectorySingleToolUse“ wird ermittelt, ob ein Agent ein bestimmtes Tool verwendet hat. In diesem Fall habe ich „list_table_ids“ ausgewählt, da wir davon ausgehen, dass dieses Tool für jede Frage im Bewertungs-Dataset aufgerufen wird. Im Gegensatz zu anderen Trajektorienmesswerten müssen Sie für diesen Messwert nicht alle erwarteten Tool-Aufrufe und Argumente für jede Frage im Bewertungs-Dataset angeben.
10. Bewertungsaufgabe erstellen
Die EvalTask verwendet das Bewertungs-Dataset und die benutzerdefinierten Messwerte und richtet einen neuen Bewertungsversuch ein.
Diese Funktion, run_eval, ist die Hauptkomponente für die Auswertung. Es durchläuft eine EvalTask und führt Ihren Agent für jede Frage im Dataset aus. Für jede Frage wird die Antwort des Agents aufgezeichnet und dann anhand der zuvor definierten Messwerte bewertet.
Kopieren Sie den folgenden Code und fügen Sie ihn unten in die Datei evaluate_agent.py ein:
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
Die Ergebnisse werden zusammengefasst und in einer JSON-Datei gespeichert.
11. Bewertung ausführen
Nachdem Sie Ihren Agent, die Bewertungsmesswerte und das Bewertungs-Dataset vorbereitet haben, können Sie die Bewertung ausführen.
Kehren Sie zu Cloud Shell zurück, achten Sie darauf, dass Sie sich im Verzeichnis „bigquery-adk-codelab“ befinden, und führen Sie das Auswertungsskript mit dem folgenden Befehl aus:
python evaluate_agent.py
Während der Auswertung wird eine Ausgabe wie diese angezeigt:
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
Wenn Fehler wie die unten aufgeführten auftreten, bedeutet das nur, dass der Agent bei einem bestimmten Lauf keine Tools aufgerufen hat. Sie können das Verhalten des Agents im nächsten Schritt genauer untersuchen.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
Ergebnisse interpretieren:
Rufen Sie den Ordner „eval_results“ im Verzeichnis „data_agent_app“ auf und öffnen Sie die Datei mit den Bewertungsergebnissen mit dem Namen bq_agent_eval_results_*.json:
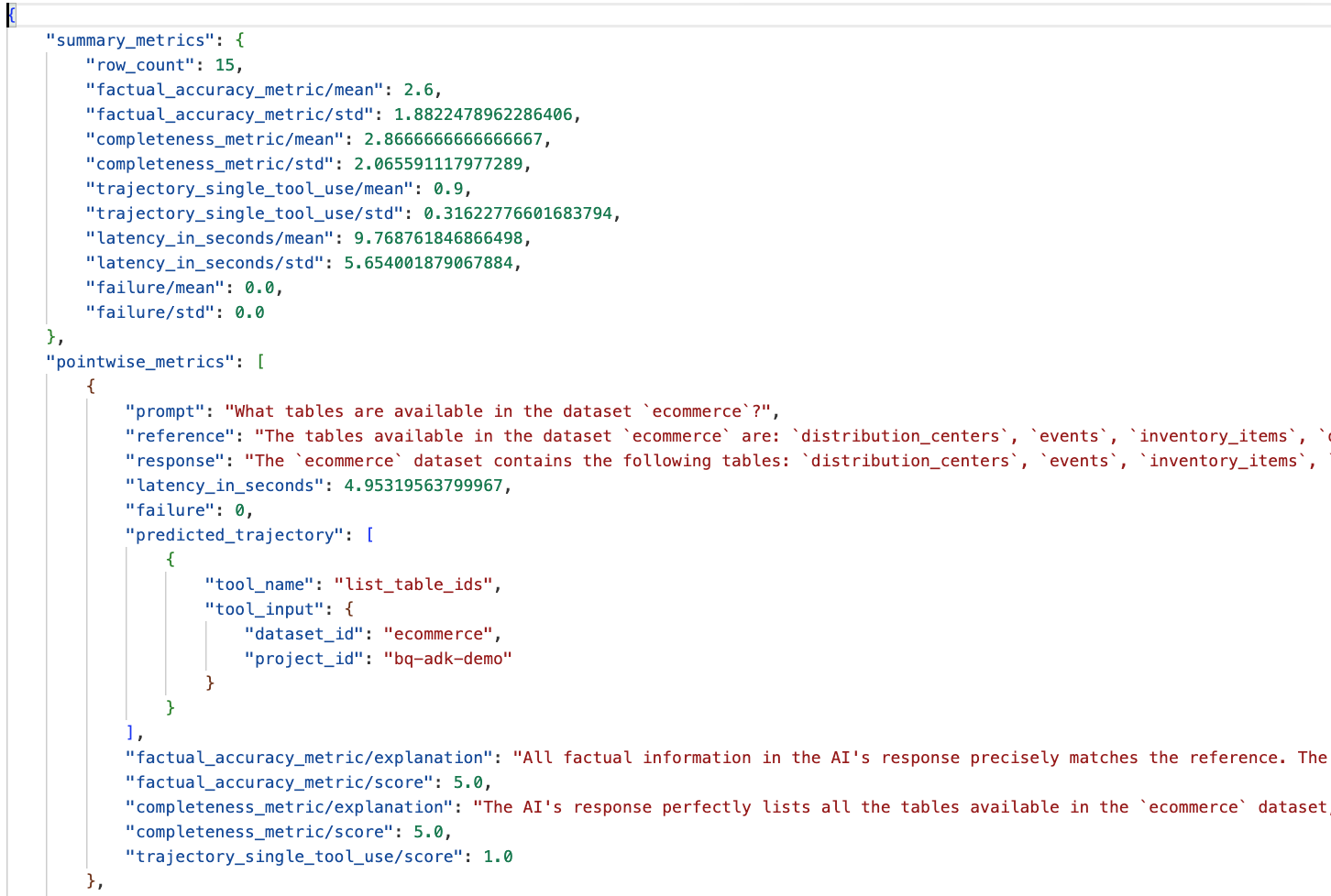
- Zusammenfassungsmesswerte:Bieten eine aggregierte Ansicht der Leistung Ihres Agents im gesamten Dataset.
- Messwerte für die punktweise faktische Richtigkeit und Vollständigkeit:Ein Wert näher an 5 weist auf eine höhere Richtigkeit und Vollständigkeit hin. Für jede Frage wird eine Punktzahl angegeben, zusammen mit einer Erklärung, warum sie diese Punktzahl erhalten hat.
- Vorhersage der Vorgehensweise:Dies ist die Liste der Tool-Aufrufe, die von den KI-Agenten verwendet werden, um die endgültige Antwort zu erhalten. So können wir alle vom Agenten generierten SQL-Abfragen sehen.
Der durchschnittliche Wert für die durchschnittliche Vollständigkeit und die sachliche Richtigkeit liegt bei 2,87 bzw. 2,6.
Die Ergebnisse sind nicht sehr gut. Wir versuchen, die Fähigkeit unseres Kundenservicemitarbeiters, Fragen zu beantworten, zu verbessern.
12. Bewertungsergebnisse Ihres KI-Agenten verbessern
Rufen Sie die Datei agent.py im Verzeichnis „bigquery-adk-codelab“ auf und aktualisieren Sie das Modell und die Systemanweisungen des Agents. Denken Sie daran, <YOUR_PROJECT_ID> durch Ihre Projekt-ID zu ersetzen:
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
Kehren Sie nun zum Terminal zurück und führen Sie die Auswertung noch einmal aus:
python evaluate_agent.py
Die Ergebnisse sollten jetzt viel besser sein:
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
Die Bewertung Ihres Agenten ist ein iterativer Prozess. Um die Bewertungsergebnisse weiter zu verbessern, können Sie die Systemanweisungen, die Modellparameter oder sogar die Metadaten in BigQuery anpassen. Hier finden Sie weitere Tipps und Tricks.
13. Bereinigen
Damit Ihrem Google Cloud-Konto keine laufenden Gebühren in Rechnung gestellt werden, ist es wichtig, die Ressourcen zu löschen, die wir während dieses Workshops erstellt haben.
Wenn Sie für dieses Codelab bestimmte BigQuery-Datasets oder -Tabellen erstellt haben (z.B. das E-Commerce-Dataset), sollten Sie sie löschen:
bq rm -r $PROJECT_ID:ecommerce
So entfernen Sie das Verzeichnis „bigquery-adk-codelab“ und dessen Inhalt:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. Glückwunsch
Das wars! Sie haben das Lab erfolgreich abgeschlossen. Sie haben erfolgreich einen BigQuery-Agenten mit dem Agent Development Kit (ADK) erstellt und bewertet. Sie wissen jetzt, wie Sie einen ADK-Agenten mit BigQuery-Tools einrichten und seine Leistung mit benutzerdefinierten Evaluierungsmesswerten messen.