
1. Introducción
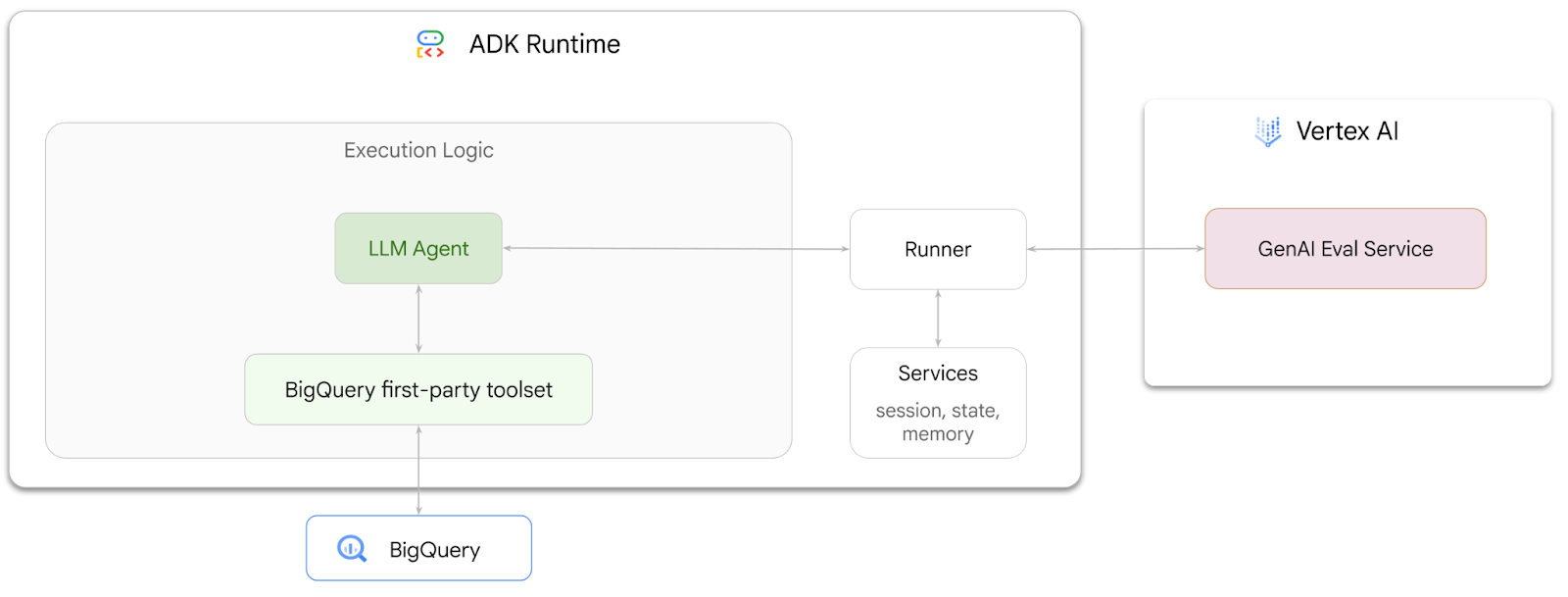
En este codelab, aprenderás a crear agentes que puedan responder preguntas sobre datos almacenados en BigQuery con el Kit de desarrollo de agentes (ADK). También evaluarás estos agentes con Gen AI Evaluation Service de Vertex AI:
Actividades
- Crea un agente de Conversational Analytics en el ADK
- Equipa a este agente con el conjunto de herramientas de origen de BigQuery del ADK para que pueda interactuar con los datos almacenados en BigQuery.
- Crea un marco de evaluación para tu agente con Gen AI Evaluation Service de Vertex AI
- Ejecuta evaluaciones en este agente en función de un conjunto de respuestas ideales.
Requisitos
- Un navegador web, como Chrome
- Un proyecto de Google Cloud con la facturación habilitada
- Una cuenta de Gmail En la siguiente sección, se mostrará cómo canjear un crédito gratuito de USD 5 para este codelab y configurar un proyecto nuevo.
Este codelab es para desarrolladores de todos los niveles, incluidos los principiantes. Usarás la interfaz de línea de comandos en Google Cloud Shell y código de Python para el desarrollo del ADK. No es necesario que seas un experto en Python, pero tener conocimientos básicos para leer código te ayudará a comprender los conceptos.
2. Antes de comenzar
Crea un proyecto de Google Cloud
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información sobre cómo verificar si la facturación está habilitada en un proyecto.
Inicia Cloud Shell
Cloud Shell es un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con las herramientas necesarias.
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud:

- Una vez que te conectes a Cloud Shell, ejecuta este comando para verificar tu autenticación en Cloud Shell:
gcloud auth list
- Ejecuta el siguiente comando para confirmar que tu proyecto esté configurado para usar gcloud:
gcloud config list project
- Usa el siguiente comando para configurar tu proyecto:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Habilitar APIs
- Ejecuta este comando para habilitar todas las APIs y los servicios requeridos:
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- Cuando el comando se ejecute correctamente, deberías ver un mensaje similar al que se muestra a continuación:
Operation "operations/..." finished successfully.
3. Crea un conjunto de datos de BigQuery
- Ejecuta el siguiente comando en Cloud Shell para crear un nuevo conjunto de datos llamado ecommerce en BigQuery:
bq mk --dataset --location=US ecommerce
Se guarda un subconjunto estático del conjunto de datos públicos de BigQuery thelook_ecommerce como archivos AVRO en un bucket público de Google Cloud Storage.
- Ejecuta este comando en Cloud Shell para cargar estos archivos Avro en BigQuery como tablas (events, order_items, products, users, orders):
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
Este proceso puede tardar unos minutos.
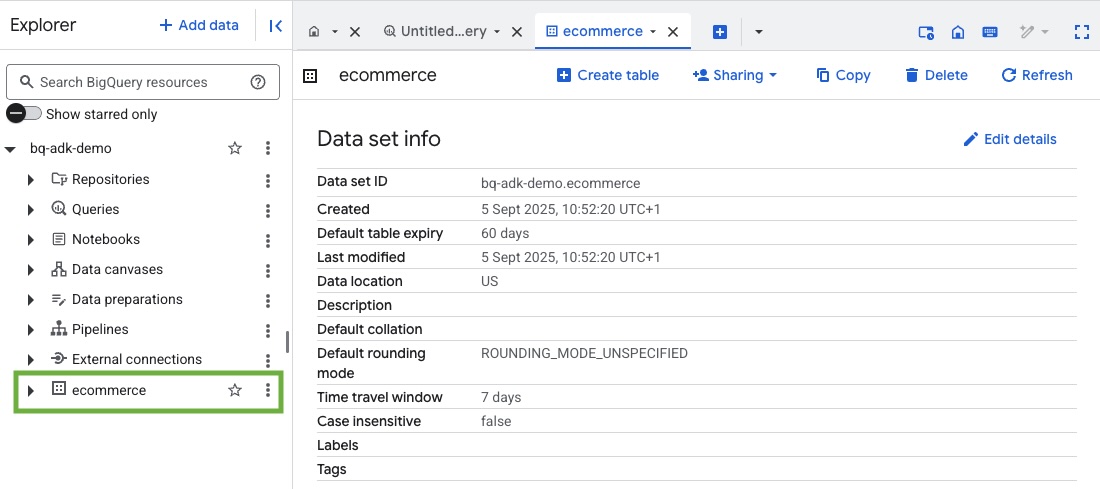
- Para verificar que se hayan creado el conjunto de datos y las tablas, visita la consola de BigQuery en tu proyecto de Google Cloud:
4. Prepara el entorno para los agentes del ADK
Regresa a Cloud Shell y asegúrate de estar en tu directorio principal. Crearemos un entorno virtual de Python y, luego, instalaremos los paquetes necesarios.
- Abre una nueva pestaña de la terminal en Cloud Shell y ejecuta este comando para crear una carpeta llamada bigquery-adk-codelab y navegar a ella:
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- Crea un entorno virtual de Python:
python -m venv .venv
- Activa el entorno virtual:
source .venv/bin/activate
- Instala los paquetes de Python del ADK y de AI Platform de Google. Se requiere la plataforma de IA y el paquete de pandas para evaluar el agente de BigQuery:
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. Crea una aplicación del ADK
Ahora, creemos nuestro agente de BigQuery. Este agente se diseñará para responder preguntas en lenguaje natural sobre los datos almacenados en BigQuery.
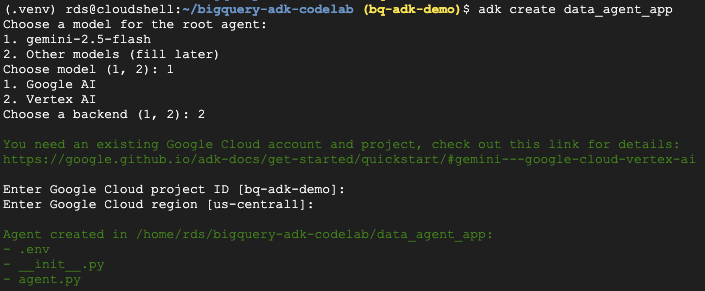
- Ejecuta el comando de utilidad adk create para crear una nueva aplicación de agente con las carpetas y los archivos necesarios:
adk create data_agent_app
Sigue las indicaciones:
- Elige gemini-2.5-flash para el modelo.
- Elige Vertex AI para el backend.
- Confirma tu ID del proyecto y región predeterminados de Google Cloud.
A continuación, se muestra una interacción de ejemplo:
- Haz clic en el botón Abrir editor en Cloud Shell para abrir el editor de Cloud Shell y ver las carpetas y los archivos recién creados:

Toma nota de los archivos generados:
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: Marca la carpeta como un módulo de Python.
- agent.py: Contiene la definición inicial del agente.
- .env: Contiene variables de entorno para tu proyecto (es posible que debas hacer clic en Ver > Activar o desactivar archivos ocultos para ver este archivo).
Actualiza las variables que no se configuraron correctamente a partir de las instrucciones:
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. Define tu agente y asígnale el conjunto de herramientas de BigQuery
Para definir un agente del ADK que interactúe con BigQuery usando el conjunto de herramientas de BigQuery, reemplaza el contenido existente del archivo agent.py por el siguiente código.
Debes actualizar el ID del proyecto en las instrucciones del agente con tu ID del proyecto real:
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
El conjunto de herramientas de BigQuery proporciona un agente con las capacidades para recuperar metadatos y ejecutar consultas en SQL sobre los datos de BigQuery. Para usar el conjunto de herramientas, debes autenticarte. Las opciones más comunes son las credenciales predeterminadas de la aplicación (ADC) para el desarrollo, OAuth interactivo cuando el agente necesita actuar en nombre de un usuario específico o credenciales de cuenta de servicio para la autenticación segura a nivel de producción.
Desde aquí, puedes chatear con tu agente. Para ello, vuelve a Cloud Shell y ejecuta este comando:
adk web
Deberías ver una notificación que indica que se inició el servidor web:
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
Haz clic en la URL proporcionada para iniciar la Web del ADK. Puedes hacerle algunas preguntas a tu agente sobre el conjunto de datos:
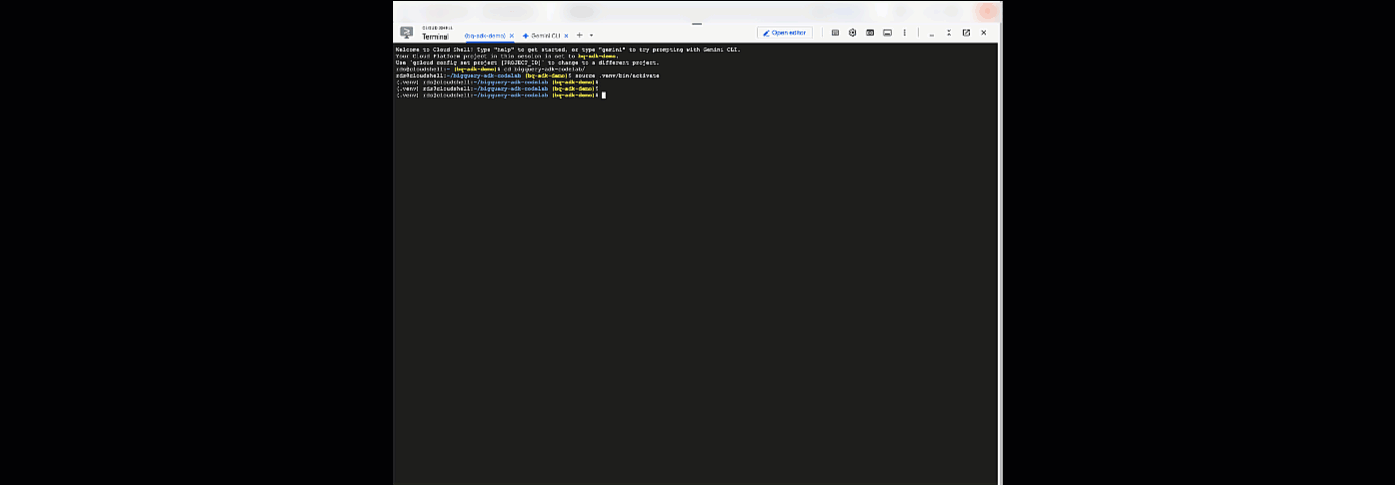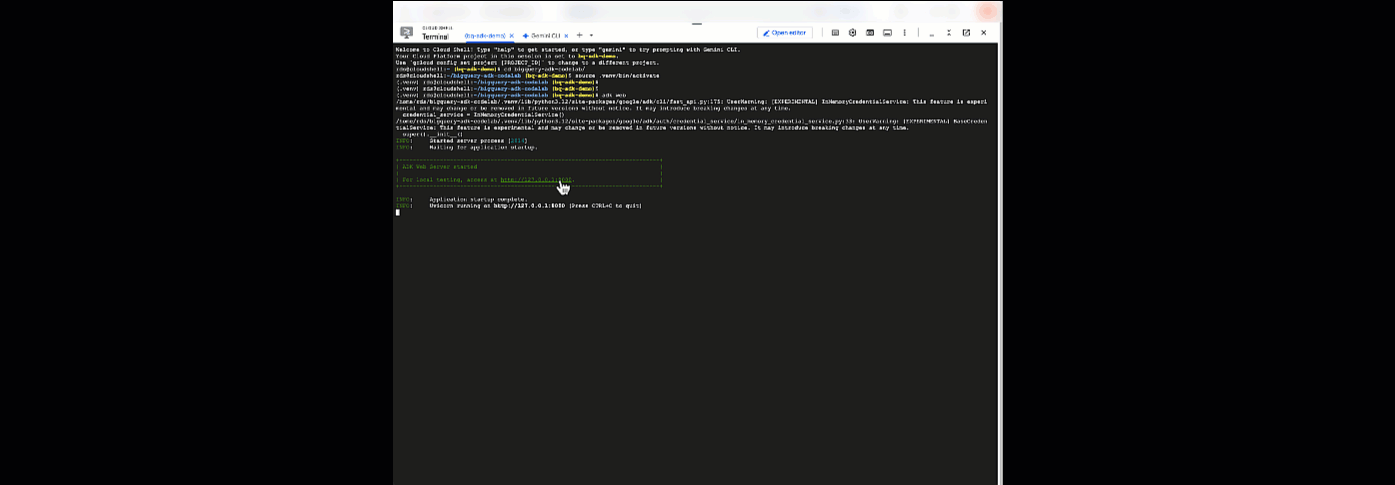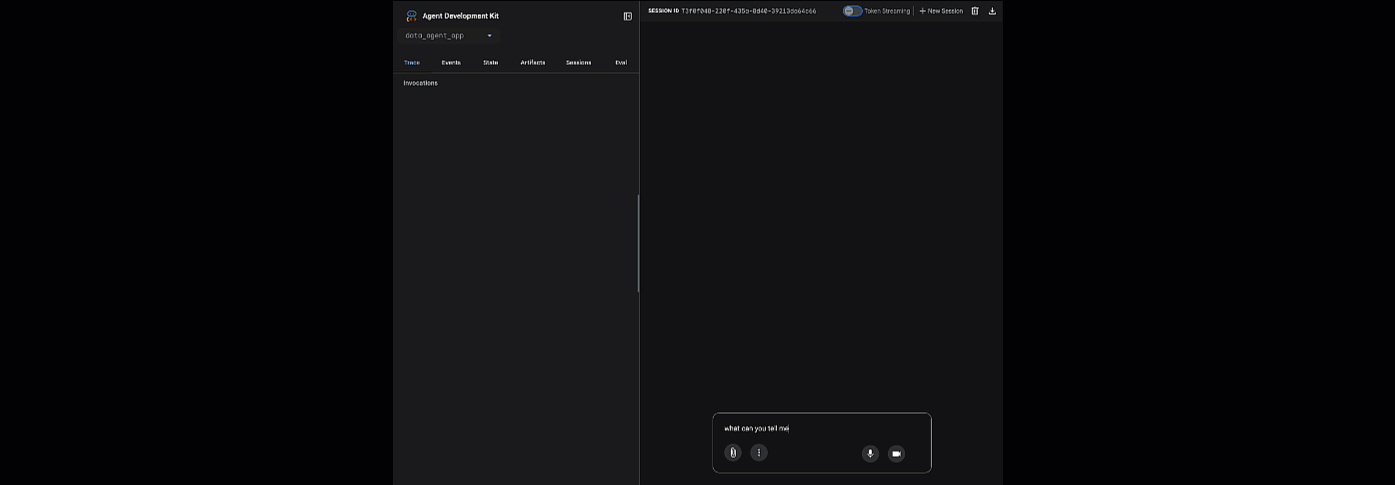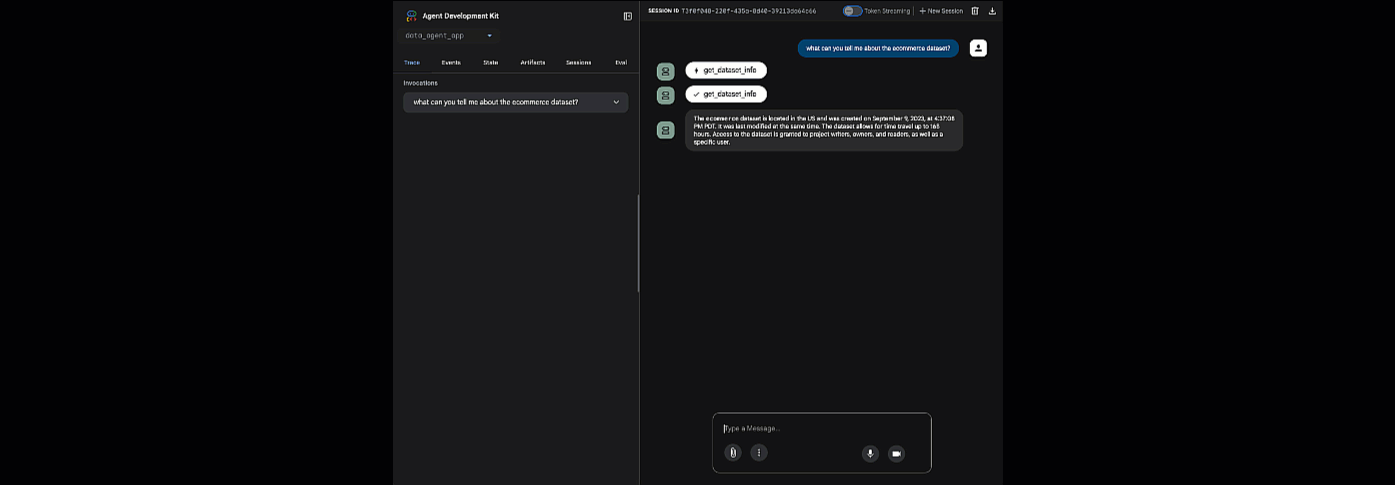
Cierra adk web y presiona Ctrl + C en la terminal para apagar el servidor web.
7. Prepara tu agente para la evaluación
Ahora que definiste tu agente de BigQuery, debes hacer que se pueda ejecutar para la evaluación.
El siguiente código define una función, run_conversation, que controla el flujo de la conversación creando un agente, ejecutando una sesión y procesando los eventos para recuperar la respuesta final.
- Vuelve a Cloud Editor y crea un archivo nuevo llamado
run_agent.pyen el directorio bigquery-adk-codelab. Luego, copia y pega el siguiente código:
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
El siguiente código define funciones de utilidad para llamar a esta función ejecutable y devolver el resultado. También incluye funciones auxiliares que imprimen y guardan los resultados de la evaluación:
- Crea un archivo nuevo llamado
utils.pyen el directorio bigquery-adk-codelab y copia y pega este código en el archivo utils.py:
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. Crea un conjunto de datos de evaluación
Para evaluar tu agente, deberás crear un conjunto de datos de evaluación, definir tus métricas de evaluación y ejecutar la tarea de evaluación.
El conjunto de datos de evaluación contiene una lista de preguntas (instrucciones) y sus respuestas correctas correspondientes (referencias). El servicio de evaluación usará estos pares para comparar las respuestas de tu agente y determinar si son precisas.
- Crea un archivo nuevo llamado evaluation_dataset.json en el directorio bigquery-adk-codelab y copia y pega el siguiente conjunto de datos de evaluación:
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. Define tus métricas de evaluación.
Ahora usaremos dos métricas personalizadas para evaluar la capacidad del agente de responder preguntas relacionadas con tus datos de BigQuery, y ambas proporcionarán una puntuación del 1 al 5:
- Métrica de exactitud fáctica: Evalúa si todos los datos y hechos presentados en la respuesta son precisos y correctos en comparación con la verdad fundamental.
- Métrica de exhaustividad: Mide si la respuesta incluye todas las partes clave de la información que solicitó el usuario y que están presentes en la respuesta correcta, sin omisiones críticas.
- Por último, crea un archivo nuevo llamado
evaluate_agent.pyen el directorio bigquery-adk-codelab y copia y pega el código de definición de métricas en el archivo evaluate_agent.py:
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
También incluí la métrica TrajectorySingleToolUse para la evaluación de la trayectoria. Cuando estas métricas están presentes, las llamadas a herramientas del agente (incluido el SQL sin procesar que genera y ejecuta en BigQuery) se incluirán en la respuesta de evaluación, lo que permitirá una inspección detallada.
La métrica TrajectorySingleToolUse determina si un agente usó una herramienta en particular. En este caso, elegí list_table_ids, ya que esperamos que se llame a esta herramienta para cada pregunta del conjunto de datos de evaluación. A diferencia de otras métricas de trayectoria, esta no requiere que especifiques todos los argumentos y las llamadas a herramientas esperados para cada pregunta del conjunto de datos de evaluación.
10. Crea tu tarea de evaluación
La EvalTask toma el conjunto de datos de evaluación y las métricas personalizadas, y configura un nuevo experimento de evaluación.
Esta función, run_eval, es el motor principal de la evaluación. Itera a través de un EvalTask y ejecuta tu agente en cada pregunta del conjunto de datos. Para cada pregunta, se registra la respuesta del agente y, luego, se usan las métricas que definiste antes para calificarla.
Copia y pega el siguiente código en la parte inferior del archivo evaluate_agent.py:
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
Los resultados se resumen y se guardan en un archivo JSON.
11. Ejecuta tu evaluación
Ahora que tienes listos tu agente, las métricas de evaluación y el conjunto de datos de evaluación, puedes ejecutar la evaluación.
Regresa a Cloud Shell, asegúrate de estar en el directorio bigquery-adk-codelab y ejecuta la secuencia de comandos de evaluación con el siguiente comando:
python evaluate_agent.py
A medida que avance la evaluación, verás un resultado similar a este:
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
Si te encuentras con algún error como el que se muestra a continuación, significa que el agente no llamó a ninguna herramienta para una ejecución en particular. Puedes inspeccionar el comportamiento del agente con más detalle en el siguiente paso.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
Cómo interpretar los resultados:
Navega a la carpeta eval_results en el directorio data_agent_app y abre el archivo de resultados de la evaluación llamado bq_agent_eval_results_*.json:
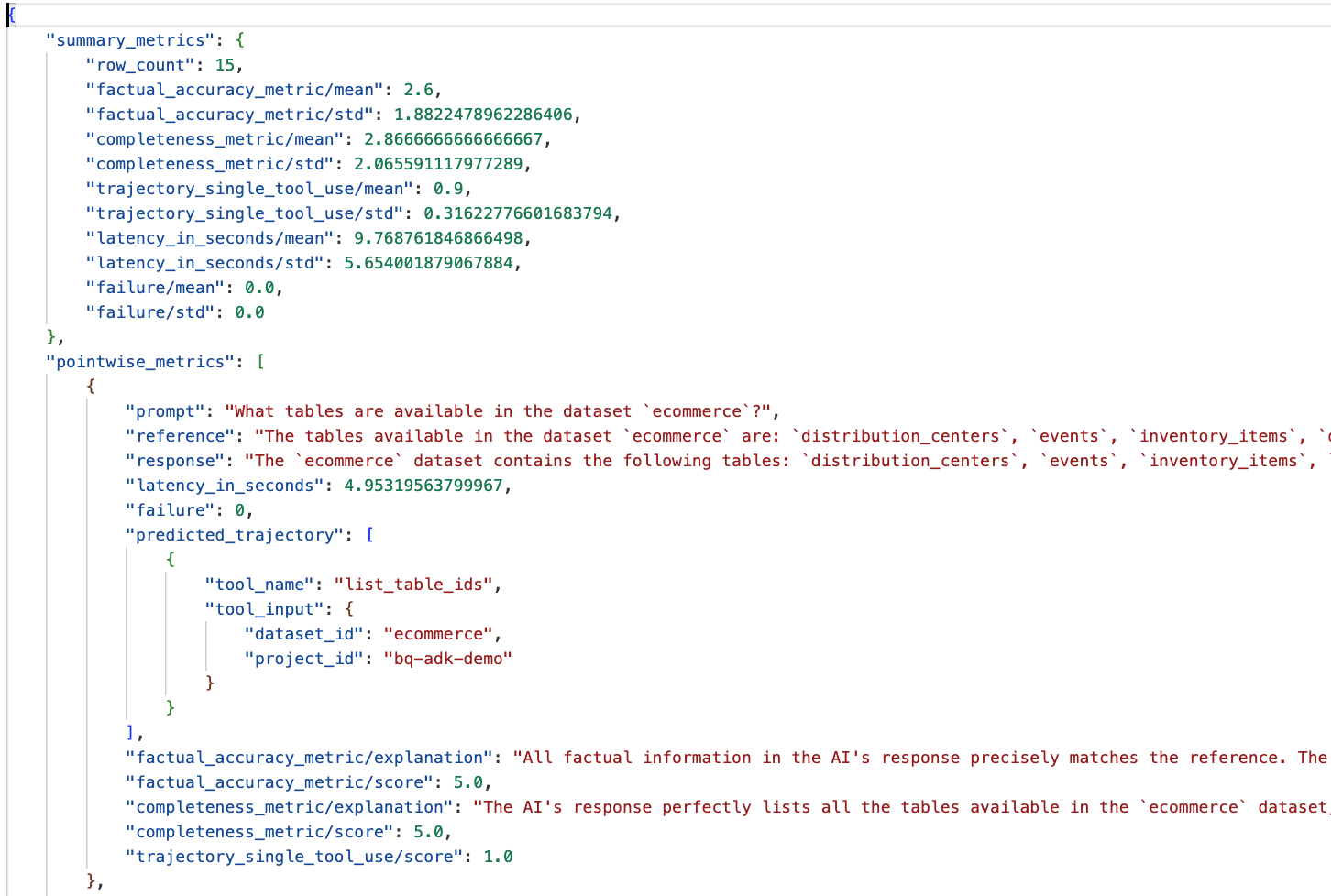
- Métricas de resumen: Proporcionan una vista agregada del rendimiento de tu agente en todo el conjunto de datos.
- Métricas puntuales de precisión y completitud fácticas: Una puntuación más cercana a 5 indica una mayor precisión y completitud. Habrá una puntuación para cada pregunta, junto con una explicación escrita de por qué recibió esa puntuación.
- Trayectoria prevista: Es la lista de llamadas a herramientas que usan los agentes para llegar a la respuesta final. Esto nos permitirá ver las consultas en SQL que genere el agente.
Podemos ver que la puntuación media de la integridad promedio y la precisión fáctica es de 2.87 y 2.6, respectivamente.
Los resultados no son muy buenos. Intentemos mejorar la capacidad de nuestro agente para responder preguntas.
12. Mejora los resultados de la evaluación de tu agente
Navega a agent.py en el directorio bigquery-adk-codelab y actualiza el modelo y las instrucciones del sistema del agente. Recuerda reemplazar <YOUR_PROJECT_ID> por el ID de tu proyecto:
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
Ahora, regresa a la terminal y vuelve a ejecutar la evaluación:
python evaluate_agent.py
Ahora deberías ver que los resultados son mucho mejores:
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
Evaluar tu agente es un proceso iterativo. Para mejorar aún más los resultados de la evaluación, puedes modificar las instrucciones del sistema, los parámetros del modelo o incluso los metadatos en BigQuery. Consulta estos consejos y trucos para obtener más ideas.
13. Limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud, es importante que borres los recursos que creamos durante este taller.
Si creaste conjuntos de datos o tablas específicos de BigQuery para este codelab (p.ej., el conjunto de datos de comercio electrónico), es posible que desees borrarlos:
bq rm -r $PROJECT_ID:ecommerce
Para quitar el directorio bigquery-adk-codelab y su contenido, haz lo siguiente:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. Felicitaciones
¡Felicitaciones! Creaste y evaluaste correctamente un agente de BigQuery con el Kit de desarrollo de agentes (ADK). Ahora sabes cómo configurar un agente del ADK con herramientas de BigQuery y medir su rendimiento con métricas de evaluación personalizadas.