
۱. مقدمه
در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه با استفاده از کیت توسعه عامل (ADK ) عاملهایی بسازید که میتوانند به سوالات مربوط به دادههای ذخیره شده در BigQuery پاسخ دهند. همچنین میتوانید این عاملها را با استفاده از سرویس ارزیابی GenAI شرکت Vertex AI ارزیابی کنید:
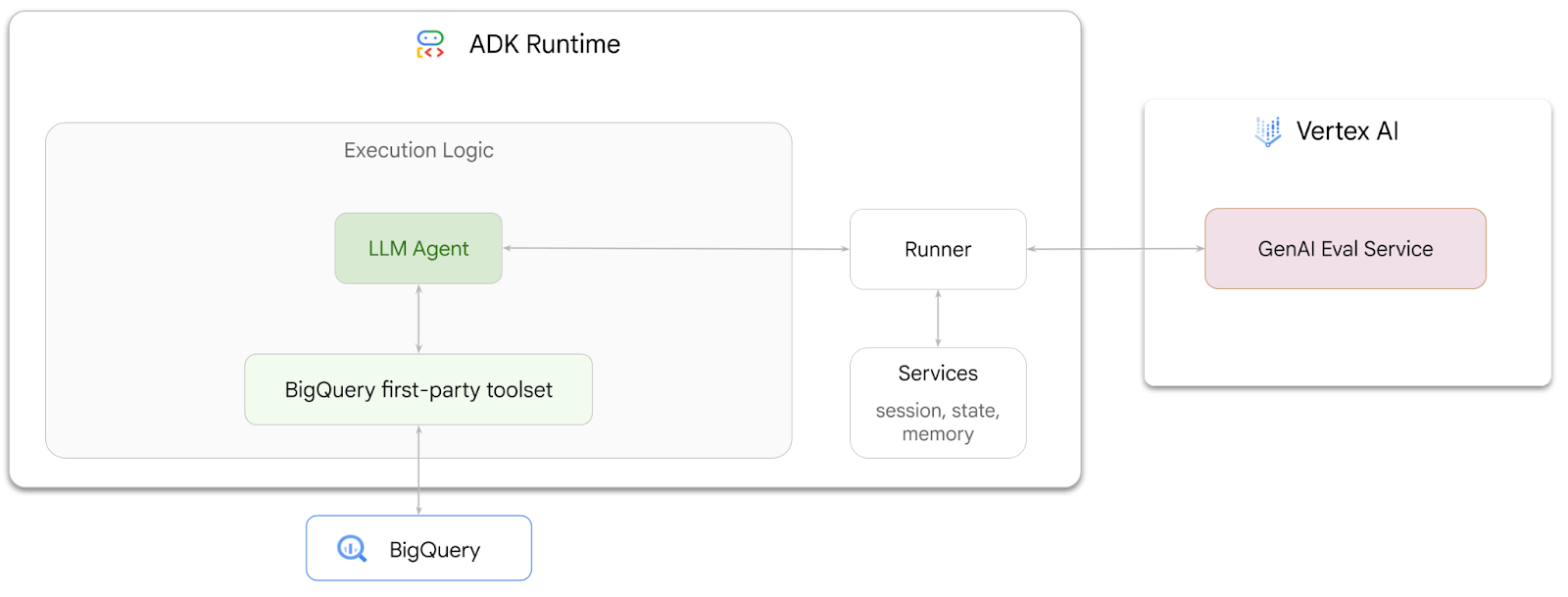
کاری که انجام خواهید داد
- ساخت یک عامل تجزیه و تحلیل مکالمه در ADK
- این عامل را به مجموعه ابزارهای شخص ثالث ADK برای BigQuery مجهز کنید تا بتواند با دادههای ذخیره شده در BigQuery تعامل داشته باشد.
- با استفاده از سرویس ارزیابی Vertex AI GenAI، یک چارچوب ارزیابی برای عامل خود ایجاد کنید
- ارزیابیهایی را روی این عامل در برابر مجموعهای از پاسخهای طلایی اجرا کنید
آنچه نیاز دارید
- یک مرورگر وب مانند کروم
- یک پروژه Google Cloud با قابلیت پرداخت، یا
- یک حساب جیمیل. بخش بعدی به شما نشان میدهد که چگونه میتوانید اعتبار رایگان ۵ دلاری را برای این codelab بازخرید کنید و یک پروژه جدید راهاندازی کنید.
این آزمایشگاه کد برای توسعهدهندگان در تمام سطوح، از جمله مبتدیان، مناسب است. شما از رابط خط فرمان در Google Cloud Shell و کد پایتون برای توسعه ADK استفاده خواهید کرد. نیازی نیست که متخصص پایتون باشید، اما درک اولیه از نحوه خواندن کد به شما در درک مفاهیم کمک میکند.
۲. قبل از شروع
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
شروع پوسته ابری
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و ابزارهای لازم از قبل روی آن بارگذاری شدهاند.
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید:

- پس از اتصال به Cloud Shell، این دستور را برای تأیید احراز هویت خود در Cloud Shell اجرا کنید:
gcloud auth list
- برای تأیید اینکه پروژه شما برای استفاده با gcloud پیکربندی شده است، دستور زیر را اجرا کنید:
gcloud config list project
- برای تنظیم پروژه خود از دستور زیر استفاده کنید:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
فعال کردن APIها
- برای فعال کردن تمام APIها و سرویسهای مورد نیاز، این دستور را اجرا کنید:
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- در صورت اجرای موفقیتآمیز دستور، باید پیامی مشابه آنچه در زیر نشان داده شده است را مشاهده کنید:
Operation "operations/..." finished successfully.
۳. ایجاد یک مجموعه داده BigQuery
- دستور زیر را در Cloud Shell اجرا کنید تا یک مجموعه داده جدید به نام ecommerce در BigQuery ایجاد شود:
bq mk --dataset --location=US ecommerce
یک زیرمجموعه استاتیک از مجموعه داده عمومی BigQuery به نام thelook_ecommerce به صورت فایلهای AVRO در یک مخزن ذخیرهسازی ابری عمومی گوگل ذخیره میشود.
- این دستور را در Cloud Shell اجرا کنید تا این فایلهای Avro به صورت جداول (events, order_items, products, users, orders) در BigQuery بارگذاری شوند:
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
این فرآیند ممکن است چند دقیقه طول بکشد.
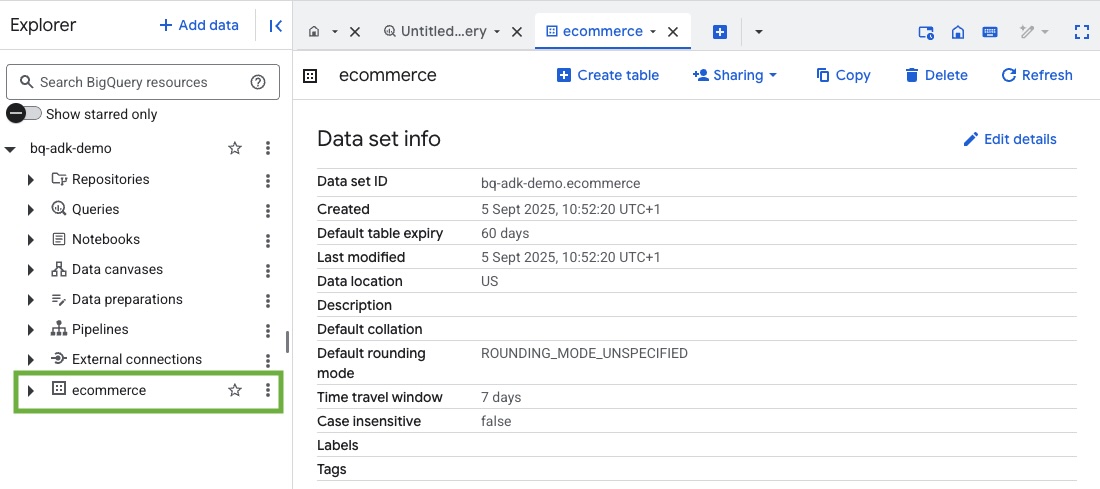
- با مراجعه به کنسول BigQuery در پروژه Google Cloud خود، از ایجاد مجموعه دادهها و جداول اطمینان حاصل کنید:
۴. آمادهسازی محیط برای عوامل ADK
به Cloud Shell برگردید و مطمئن شوید که در دایرکتوری خانگی خود هستید. ما یک محیط مجازی پایتون ایجاد خواهیم کرد و بستههای مورد نیاز را نصب خواهیم کرد.
- یک تب ترمینال جدید در Cloud Shell باز کنید و این دستور را اجرا کنید تا پوشهای به نام bigquery-adk-codelab ایجاد و به آن بروید:
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- ایجاد یک محیط مجازی پایتون:
python -m venv .venv
- فعال کردن محیط مجازی:
source .venv/bin/activate
- بستههای پایتون ADK و AI-Platform گوگل را نصب کنید. برای ارزیابی عامل bigquery، بستههای AI platform و pandas مورد نیاز است:
pip install google-adk google-cloud-aiplatform[evaluation] pandas
۵. یک برنامه ADK ایجاد کنید
حالا، بیایید عامل BigQuery خود را ایجاد کنیم. این عامل برای پاسخ به سوالات زبان طبیعی در مورد دادههای ذخیره شده در BigQuery طراحی خواهد شد.
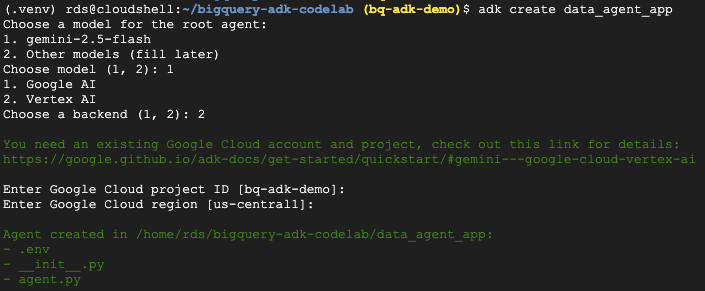
- دستور adk create utility را اجرا کنید تا یک برنامه عامل جدید با پوشهها و فایلهای لازم ایجاد شود:
adk create data_agent_app
دستورالعملها را دنبال کنید:
- برای مدل، gemini-2.5-flash را انتخاب کنید.
- برای بکاند، Vertex AI را انتخاب کنید.
- شناسه و منطقه پیشفرض پروژه گوگل کلود خود را تأیید کنید.
یک نمونه تعامل در زیر نشان داده شده است:
- برای باز کردن ویرایشگر Cloud Shell و مشاهده پوشهها و فایلهای تازه ایجاد شده، روی دکمه Open Editor در Cloud Shell کلیک کنید :

به فایلهای تولید شده توجه کنید:
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: پوشه را به عنوان یک ماژول پایتون علامتگذاری میکند.
- agent.py: شامل تعریف اولیه عامل است.
- .env: شامل متغیرهای محیطی برای پروژه شما است (برای مشاهده این فایل، ممکن است لازم باشد روی View > Toggle Hidden Files کلیک کنید)
هر متغیری را که به درستی از طریق اعلانها تنظیم نشده است، بهروزرسانی کنید:
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
۶. عامل خود را تعریف کنید و مجموعه ابزار BigQuery را به آن اختصاص دهید
برای تعریف یک ADK Agent که با استفاده از مجموعه ابزار BigQuery با BigQuery تعامل دارد، محتوای موجود فایل agent.py را با کد زیر جایگزین کنید.
شما باید شناسه پروژه را در دستورالعملهای نماینده به شناسه پروژه واقعی خود بهروزرسانی کنید:
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
مجموعه ابزارهای BigQuery به یک عامل (agent) قابلیتهایی برای واکشی فرادادهها (metadata) و اجرای کوئریهای SQL روی دادههای BigQuery ارائه میدهد. برای استفاده از این مجموعه ابزارها، باید احراز هویت کنید که رایجترین گزینهها عبارتند از Application Default Credentials (ADC) برای توسعه، Interactive OAuth برای زمانی که عامل باید از طرف یک کاربر خاص عمل کند، یا Service Account Credentials برای احراز هویت امن و در سطح تولید.
از اینجا، میتوانید با بازگشت به Cloud Shell و اجرای این دستور با نماینده خود چت کنید :
adk web
شما باید اعلانی مبنی بر شروع به کار وب سرور مشاهده کنید:
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
برای اجرای adk web روی آدرس اینترنتی ارائه شده کلیک کنید - میتوانید از نماینده خود در مورد مجموعه دادهها سؤال بپرسید:
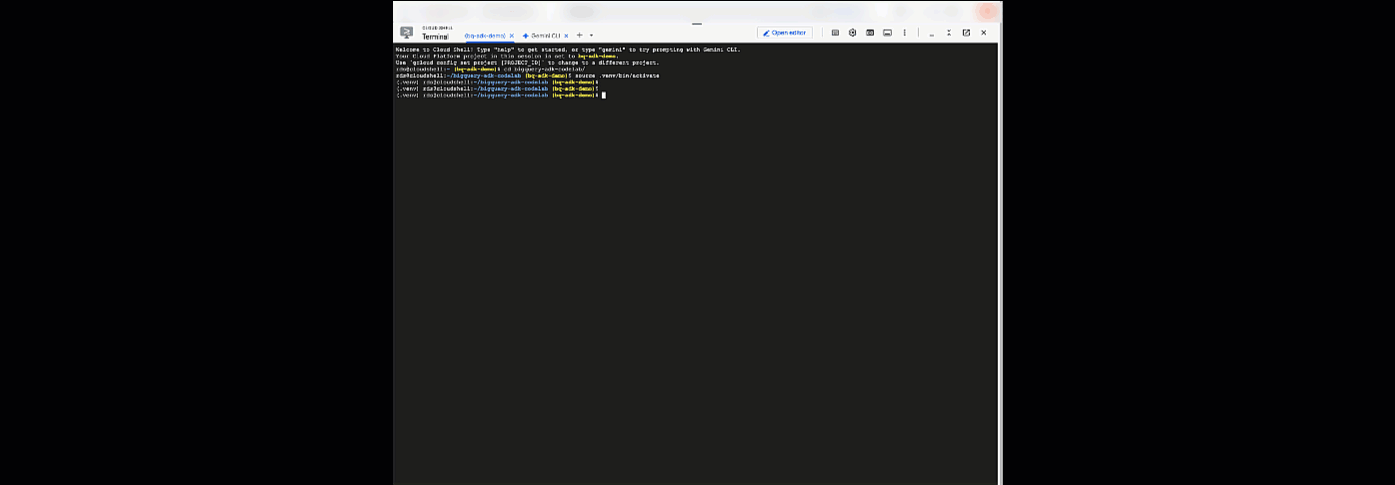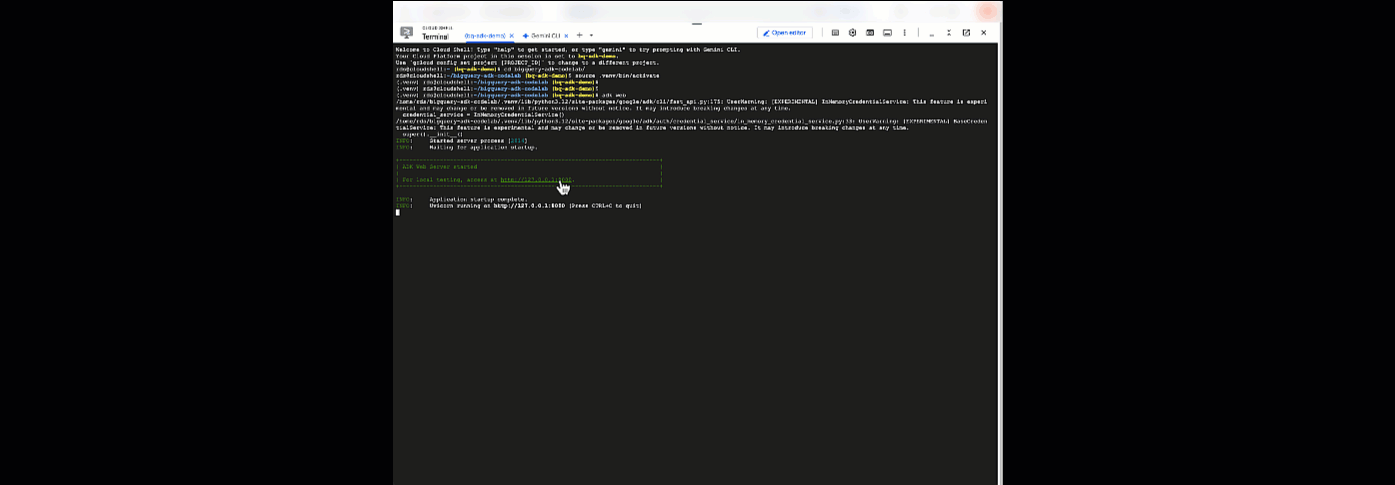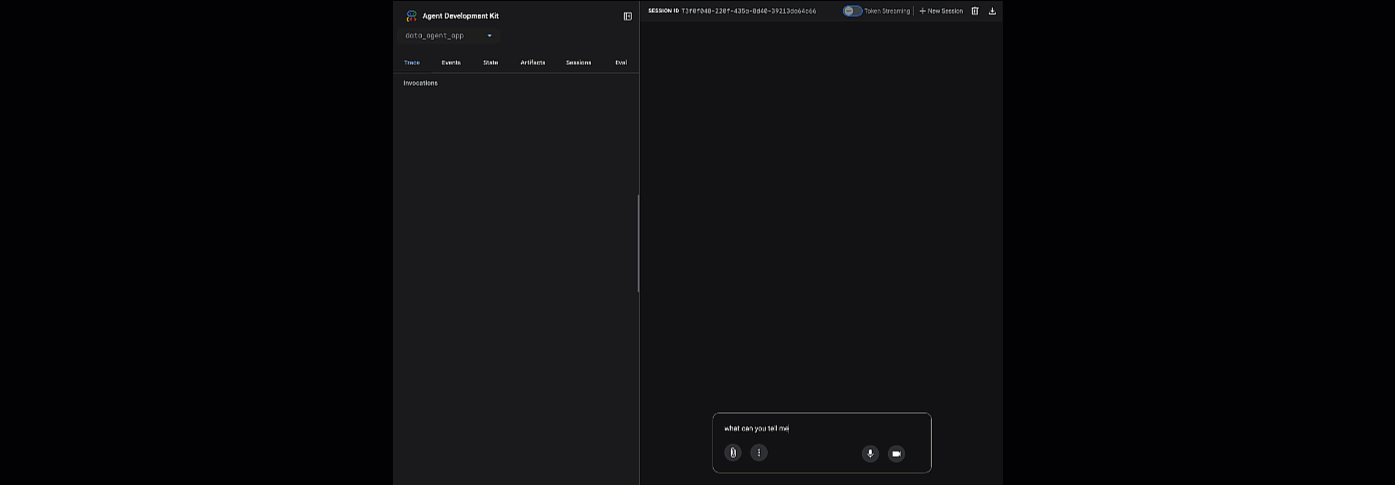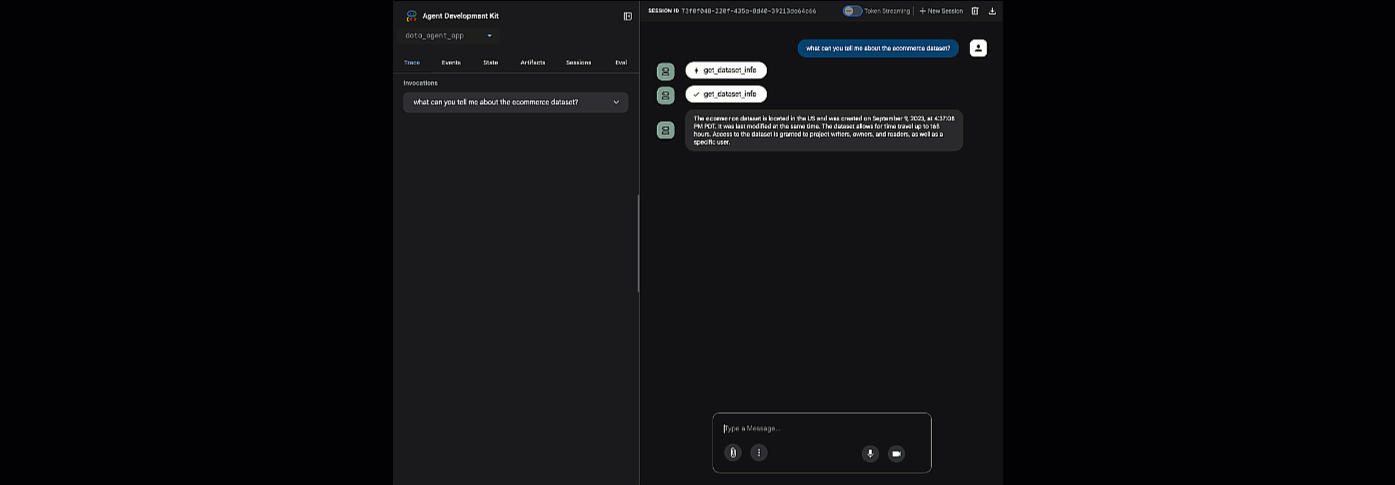
adk web را ببندید و در ترمینال Ctrl + C را فشار دهید تا سرور وب خاموش شود.
۷. مشاور خود را برای ارزیابی آماده کنید
حالا که عامل BigQuery خود را تعریف کردهاید، باید آن را برای ارزیابی قابل اجرا کنید.
کد زیر تابعی به نام run_conversation را تعریف میکند که جریان مکالمه را با ایجاد یک عامل، اجرای یک جلسه و پردازش رویدادها برای بازیابی پاسخ نهایی، مدیریت میکند.
- به ویرایشگر ابری برگردید و یک فایل جدید با نام
run_agent.pyدر پوشه bigquery-adk-codelab ایجاد کنید و کد زیر را کپی/پیست کنید:
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
کد زیر توابع کاربردی را برای فراخوانی این تابع قابل اجرا و بازگرداندن نتیجه تعریف میکند. همچنین شامل توابع کمکی است که نتایج ارزیابی را چاپ و ذخیره میکنند:
- یک فایل جدید با نام
utils.pyدر دایرکتوری bigquery-adk-codelab ایجاد کنید و این کد را در فایل utils.py کپی/پیست کنید:
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
۸. ایجاد یک مجموعه داده ارزیابی
برای ارزیابی عامل خود، باید یک مجموعه داده ارزیابی ایجاد کنید ، معیارهای ارزیابی خود را تعریف کنید و وظیفه ارزیابی را اجرا کنید .
مجموعه دادههای ارزیابی شامل فهرستی از سوالات ( سوالات ) و پاسخهای صحیح مربوط به آنها ( منابع ) است. سرویس ارزیابی از این جفتها برای مقایسه پاسخهای عامل شما و تعیین صحت آنها استفاده خواهد کرد.
- یک فایل جدید با نام evaluation_dataset.json در دایرکتوری bigquery-adk-codelab ایجاد کنید و مجموعه دادههای ارزیابی زیر را کپی/پیست کنید:
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
۹. معیارهای ارزیابی خود را تعریف کنید
اکنون از دو معیار سفارشی برای ارزیابی توانایی عامل در پاسخ به سوالات مربوط به دادههای BigQuery شما استفاده خواهیم کرد که هر دو امتیازی از ۱ تا ۵ ارائه میدهند:
- معیار دقت واقعی: این معیار ارزیابی میکند که آیا تمام دادهها و حقایق ارائه شده در پاسخ، در مقایسه با واقعیت، دقیق و صحیح هستند یا خیر.
- معیار کامل بودن: این معیار نشان میدهد که آیا پاسخ شامل تمام اطلاعات کلیدی درخواست شده توسط کاربر است و در پاسخ صحیح و بدون هیچ گونه حذف مهمی ارائه شده است یا خیر.
- در نهایت، یک فایل جدید با نام
evaluate_agent.pyدر دایرکتوری bigquery-adk-codelab ایجاد کنید و کد تعریف معیار را در فایل evaluate_agent.py کپی/پیست کنید:
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
من همچنین معیار TrajectorySingleToolUse را برای ارزیابی مسیر اضافه کردهام. وقتی این معیارها وجود داشته باشند، فراخوانیهای ابزار عامل (از جمله SQL خامی که تولید و در BigQuery اجرا میکند) در پاسخ ارزیابی گنجانده میشوند و امکان بررسی دقیق را فراهم میکنند.
معیار TrajectorySingleToolUse تعیین میکند که آیا یک عامل از ابزار خاصی استفاده کرده است یا خیر. در این مورد، من list_table_ids را انتخاب کردم، زیرا انتظار داریم این ابزار برای هر سوال در مجموعه داده ارزیابی فراخوانی شود. برخلاف سایر معیارهای مسیر، این معیار نیازی به مشخص کردن تمام فراخوانیها و آرگومانهای ابزار مورد انتظار برای هر سوال در مجموعه داده ارزیابی ندارد.
۱۰. وظیفه ارزیابی خود را ایجاد کنید
EvalTask مجموعه دادههای ارزیابی و معیارهای سفارشی را دریافت کرده و یک آزمایش ارزیابی جدید راهاندازی میکند.
این تابع، run_eval، موتور اصلی ارزیابی است. این تابع در یک EvalTask حلقه میزند و عامل شما را روی هر سوال در مجموعه داده اجرا میکند. برای هر سوال، پاسخ عامل را ثبت میکند و سپس از معیارهایی که قبلاً تعریف کردهاید برای رتبهبندی آن استفاده میکند.
کد زیر را در انتهای فایل evaluate_agent.py کپی/پیست کنید:
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
نتایج خلاصه شده و در یک فایل JSON ذخیره میشوند.
۱۱. ارزیابی خود را اجرا کنید
اکنون که عامل، معیارهای ارزیابی و مجموعه دادههای ارزیابی خود را آماده دارید، میتوانید ارزیابی را اجرا کنید.
به Cloud Shell برگردید، مطمئن شوید که در دایرکتوری bigquery-adk-codelab هستید و اسکریپت ارزیابی را با استفاده از دستور زیر اجرا کنید:
python evaluate_agent.py
با پیشرفت ارزیابی، خروجی مشابه این را خواهید دید:
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
اگر با خطاهایی مانند زیر مواجه شدید، فقط به این معنی است که عامل هیچ ابزاری را برای یک اجرای خاص فراخوانی نکرده است؛ میتوانید در مرحله بعدی رفتار عامل را بیشتر بررسی کنید.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
تفسیر نتایج:
به پوشه eval_results در دایرکتوری data_agent_app بروید و فایل نتیجه ارزیابی با نام bq_agent_eval_results_*.json را باز کنید:
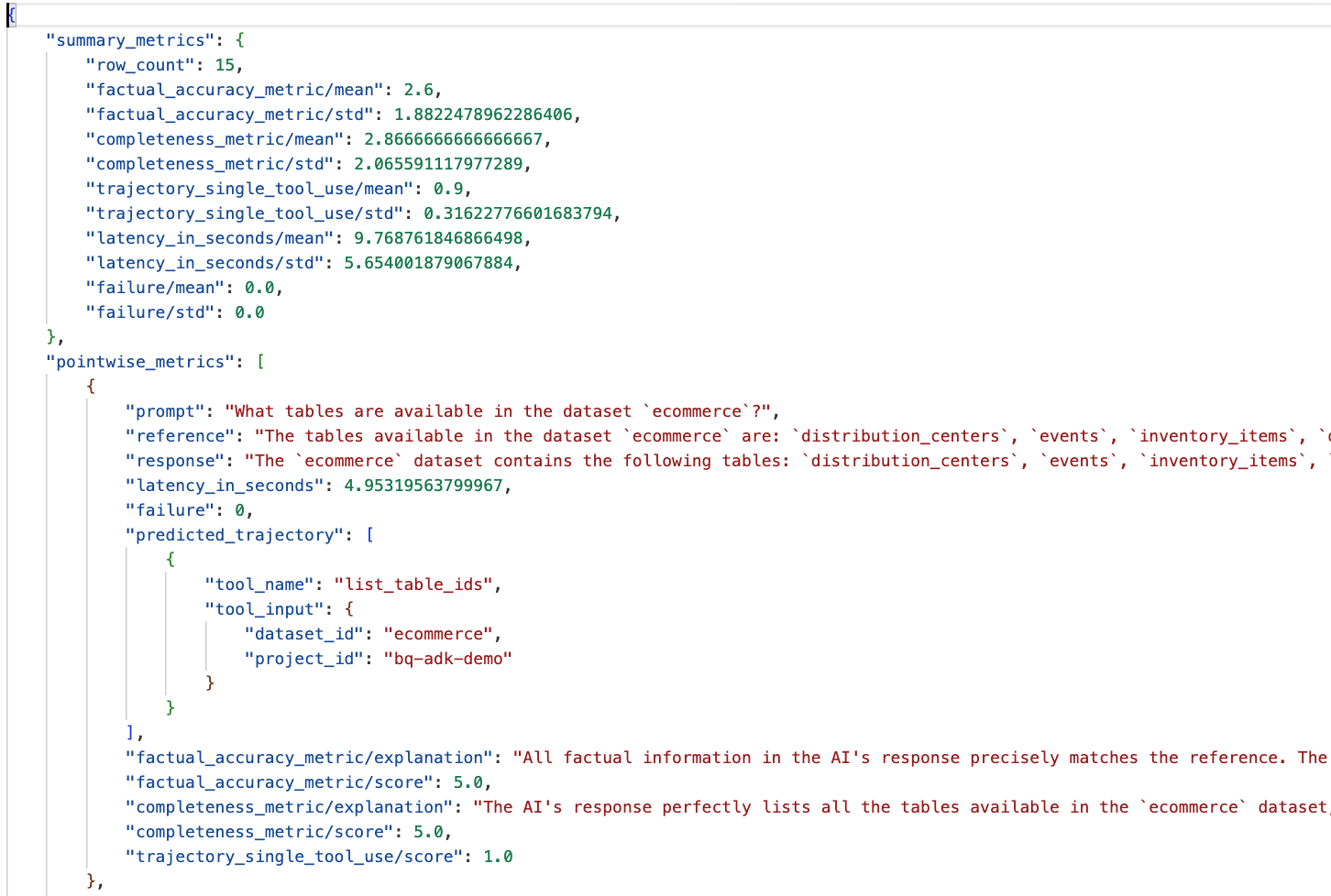
- معیارهای خلاصه: یک نمای کلی از عملکرد نماینده شما در مجموعه دادهها ارائه میدهد.
- معیارهای نقطهای دقت و کامل بودن بر اساس واقعیت: امتیاز نزدیکتر به ۵ نشاندهنده دقت و کامل بودن بالاتر است. برای هر سوال یک امتیاز به همراه توضیح کتبی در مورد دلیل دریافت آن امتیاز وجود خواهد داشت.
- مسیر پیشبینیشده: این فهرستی از فراخوانیهای ابزار است که توسط عاملها برای رسیدن به پاسخ نهایی استفاده میشود. این به ما امکان میدهد هرگونه پرسوجوی SQL تولید شده توسط عامل را مشاهده کنیم.
میتوانیم ببینیم که میانگین امتیاز برای میانگین کامل بودن و دقت واقعی به ترتیب ۲.۸۷ و ۲.۶ است.
نتایج خیلی خوب نیستند! بیایید سعی کنیم توانایی عامل خود را در پاسخ به سوالات بهبود بخشیم.
۱۲. نتایج ارزیابی نماینده خود را بهبود بخشید
به فایل agent.py در دایرکتوری bigquery-adk-codelab بروید و مدل و دستورالعملهای سیستم عامل را بهروزرسانی کنید. به یاد داشته باشید که <YOUR_PROJECT_ID> را با شناسه پروژه خود جایگزین کنید:
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
حالا به ترمینال برگردید و ارزیابی را دوباره اجرا کنید:
python evaluate_agent.py
باید ببینید که نتایج اکنون بسیار بهتر شدهاند:
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
ارزیابی عامل شما یک فرآیند تکراری است. برای بهبود بیشتر نتایج ارزیابی، میتوانید دستورالعملهای سیستم، پارامترهای مدل یا حتی فرادادهها را در BigQuery تغییر دهید - برای ایدههای بیشتر، این نکات و ترفندها را بررسی کنید.
۱۳. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود، مهم است که منابعی را که در طول این کارگاه ایجاد کردهایم، حذف کنید.
اگر مجموعه داده یا جدول خاصی از BigQuery را برای این codelab ایجاد کردهاید (مثلاً مجموعه داده ecommerce)، شاید بخواهید آنها را حذف کنید:
bq rm -r $PROJECT_ID:ecommerce
برای حذف دایرکتوری bigquery-adk-codelab و محتویات آن:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
۱۴. تبریک
تبریک! شما با موفقیت یک عامل BigQuery را با استفاده از کیت توسعه عامل (ADK) ساختید و ارزیابی کردید. اکنون میدانید که چگونه یک عامل ADK را با ابزارهای BigQuery راهاندازی کنید و عملکرد آن را با استفاده از معیارهای ارزیابی سفارشی اندازهگیری کنید.