
1. Introduction
Dans cet atelier de programmation, vous allez apprendre à créer des agents capables de répondre à des questions sur les données stockées dans BigQuery à l'aide d'Agent Development Kit (ADK). Vous évaluerez également ces agents à l'aide de Gen AI Evaluation Service de Vertex AI :
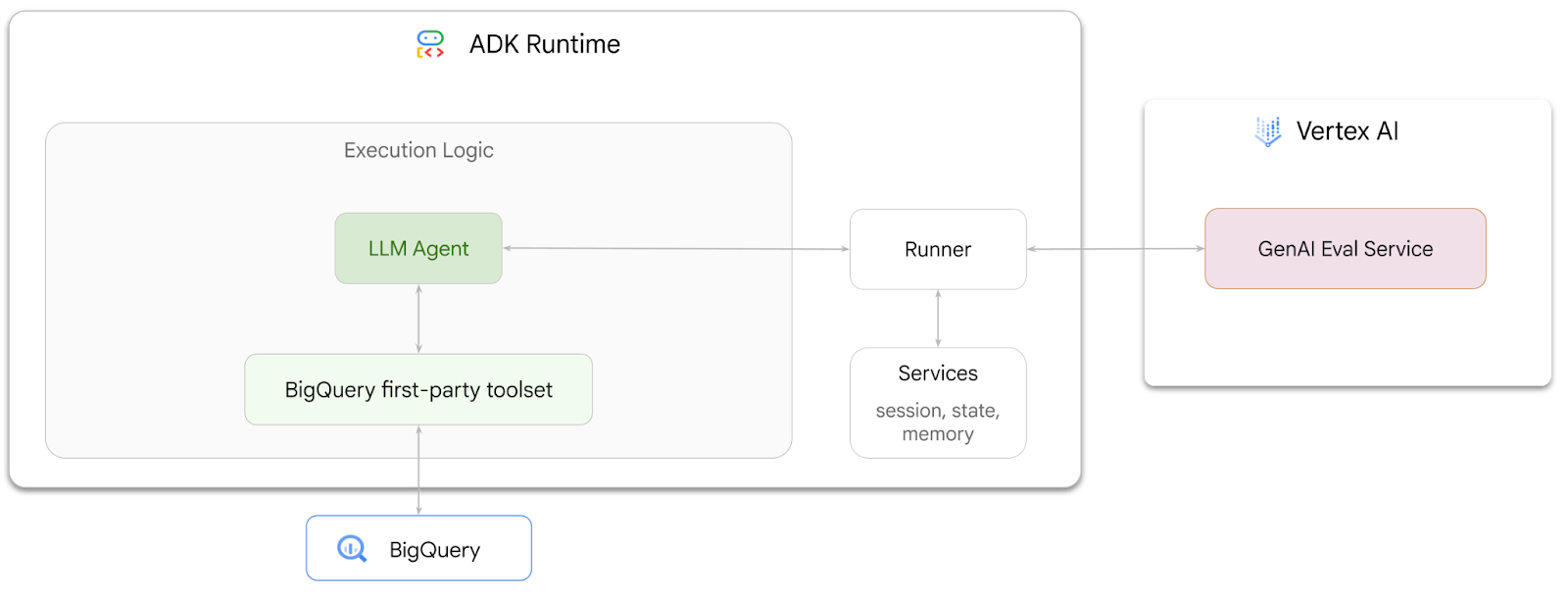
Objectifs de l'atelier
- Créer un agent d'analyse conversationnelle dans ADK
- Équipez cet agent de l'ensemble d'outils first party pour BigQuery de l'ADK afin qu'il puisse interagir avec les données stockées dans BigQuery.
- Créez un cadre d'évaluation pour votre agent à l'aide de Gen AI Evaluation Service de Vertex AI.
- Exécuter des évaluations sur cet agent par rapport à un ensemble de réponses de référence
Prérequis
- Un navigateur Web tel que Chrome
- Un projet Google Cloud avec la facturation activée
- Un compte Gmail La section suivante vous expliquera comment utiliser un crédit de 5 $ sans frais pour cet atelier de programmation et configurer un nouveau projet.
Cet atelier de programmation s'adresse aux développeurs de tous niveaux, y compris aux débutants. Vous utiliserez l'interface de ligne de commande dans Google Cloud Shell et le code Python pour le développement ADK. Vous n'avez pas besoin d'être un expert en Python, mais une compréhension de base de la lecture de code vous aidera à comprendre les concepts.
2. Avant de commencer
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Démarrer Cloud Shell
Cloud Shell est un environnement de ligne de commande exécuté dans Google Cloud et fourni avec les outils nécessaires.
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud :

- Une fois connecté à Cloud Shell, exécutez la commande suivante pour vérifier votre authentification dans Cloud Shell :
gcloud auth list
- Exécutez la commande suivante pour vérifier que votre projet est configuré pour être utilisé avec gcloud :
gcloud config list project
- Utilisez la commande suivante pour définir votre projet :
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Activer les API
- Exécutez cette commande pour activer toutes les API et tous les services requis :
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- Si la commande s'exécute correctement, un message semblable à celui ci-dessous s'affiche :
Operation "operations/..." finished successfully.
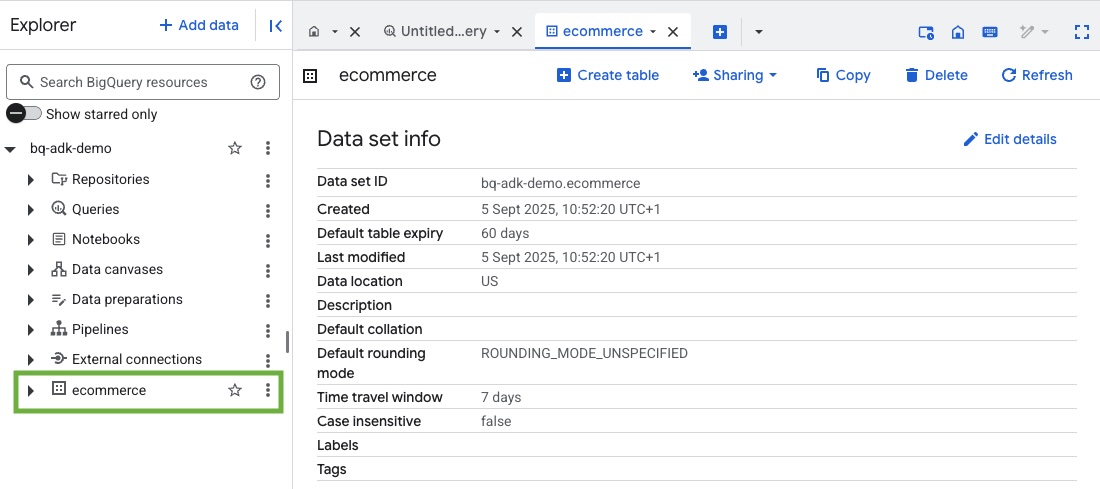
3. Créer un ensemble de données BigQuery
- Exécutez la commande suivante dans Cloud Shell pour créer un ensemble de données nommé "ecommerce" dans BigQuery :
bq mk --dataset --location=US ecommerce
Un sous-ensemble statique de l'ensemble de données public BigQuery thelook_ecommerce est enregistré sous forme de fichiers AVRO dans un bucket Google Cloud Storage public.
- Exécutez cette commande dans Cloud Shell pour charger ces fichiers Avro dans BigQuery en tant que tables (events, order_items, products, users, orders) :
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
Ce processus peut prendre quelques minutes.
- Vérifiez que l'ensemble de données et les tables ont été créés en accédant à la console BigQuery dans votre projet Google Cloud :
4. Préparer l'environnement pour les agents ADK
Revenez à Cloud Shell et assurez-vous d'être dans votre répertoire d'accueil. Nous allons créer un environnement Python virtuel et installer les packages requis.
- Ouvrez un nouvel onglet de terminal dans Cloud Shell et exécutez cette commande pour créer un dossier nommé bigquery-adk-codelab et y accéder :
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- Créez un environnement virtuel Python :
python -m venv .venv
- Activez l'environnement virtuel :
source .venv/bin/activate
- Installez les packages Python ADK et AI-Platform de Google. La plate-forme d'IA et le package pandas sont nécessaires pour évaluer l'agent BigQuery :
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. Créer une application ADK
Maintenant, créons notre agent BigQuery. Cet agent sera conçu pour répondre à des questions en langage naturel sur les données stockées dans BigQuery.
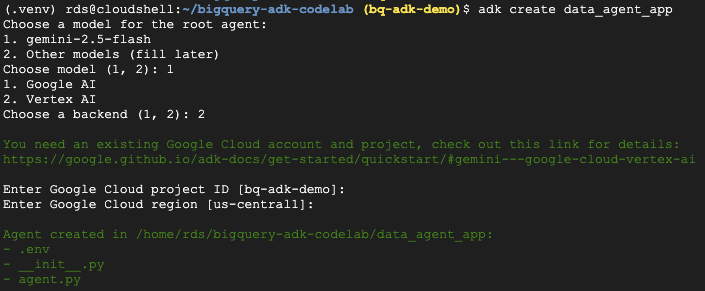
- Exécutez la commande utilitaire adk create pour créer une application d'agent avec les dossiers et fichiers nécessaires :
adk create data_agent_app
Suivez les instructions :
- Choisissez gemini-2.5-flash comme modèle.
- Choisissez Vertex AI comme backend.
- Vérifiez l'ID et la région de votre projet Google Cloud par défaut.
Voici un exemple d'interaction :
- Cliquez sur le bouton "Ouvrir l'éditeur" dans Cloud Shell pour ouvrir l'éditeur Cloud Shell et afficher les dossiers et fichiers nouvellement créés :

Notez les fichiers générés :
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: : marque le dossier comme module Python.
- agent.py: : contient la définition initiale de l'agent.
- .env : contient les variables d'environnement de votre projet (vous devrez peut-être cliquer sur Affichage > Activer/Désactiver les fichiers cachés pour afficher ce fichier).
Mettez à jour les variables qui n'ont pas été correctement définies à partir des invites :
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. Définissez votre agent et attribuez-lui l'ensemble d'outils BigQuery.
Pour définir un agent ADK qui interagit avec BigQuery à l'aide de l'ensemble d'outils BigQuery, remplacez le contenu existant du fichier agent.py par le code suivant.
Vous devez remplacer l'ID du projet dans les instructions de l'agent par l'ID de votre projet :
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
L'ensemble d'outils BigQuery fournit à l'agent les capacités nécessaires pour extraire des métadonnées et exécuter des requêtes SQL sur les données BigQuery. Pour utiliser l'ensemble d'outils, vous devez vous authentifier. Les options les plus courantes sont les identifiants par défaut de l'application (ADC) pour le développement, OAuth interactif lorsque l'agent doit agir au nom d'un utilisateur spécifique, ou les identifiants de compte de service pour une authentification sécurisée au niveau de la production.
À partir de là, vous pouvez discuter avec votre agent en revenant à Cloud Shell et en exécutant cette commande :
adk web
Une notification indiquant que le serveur Web a démarré devrait s'afficher :
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
Cliquez sur l'URL fournie pour lancer ADK Web. Vous pouvez poser des questions à votre agent sur l'ensemble de données :
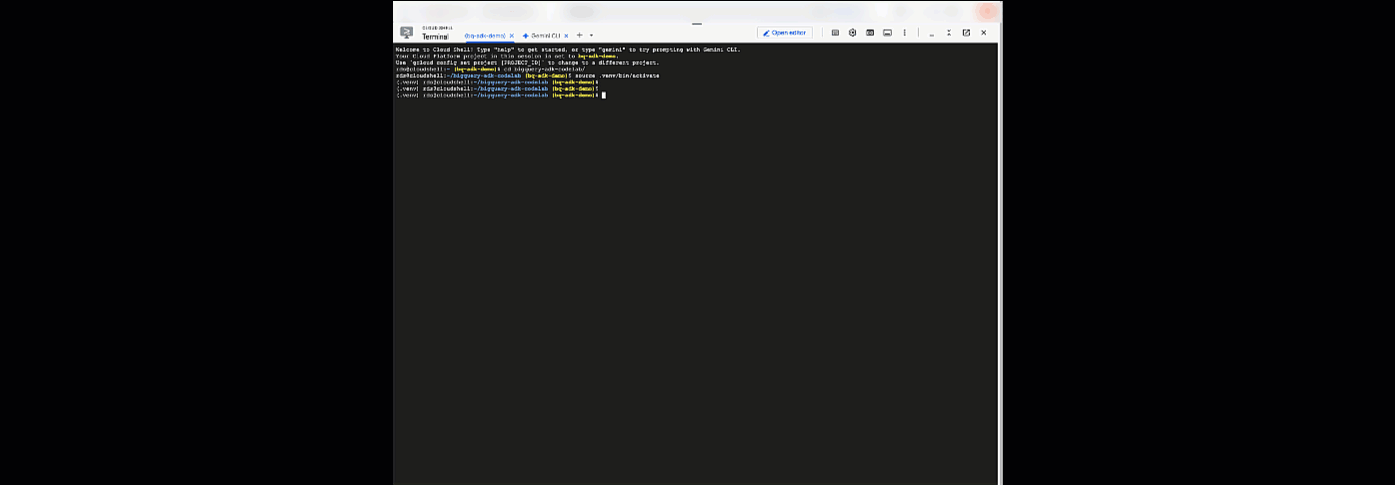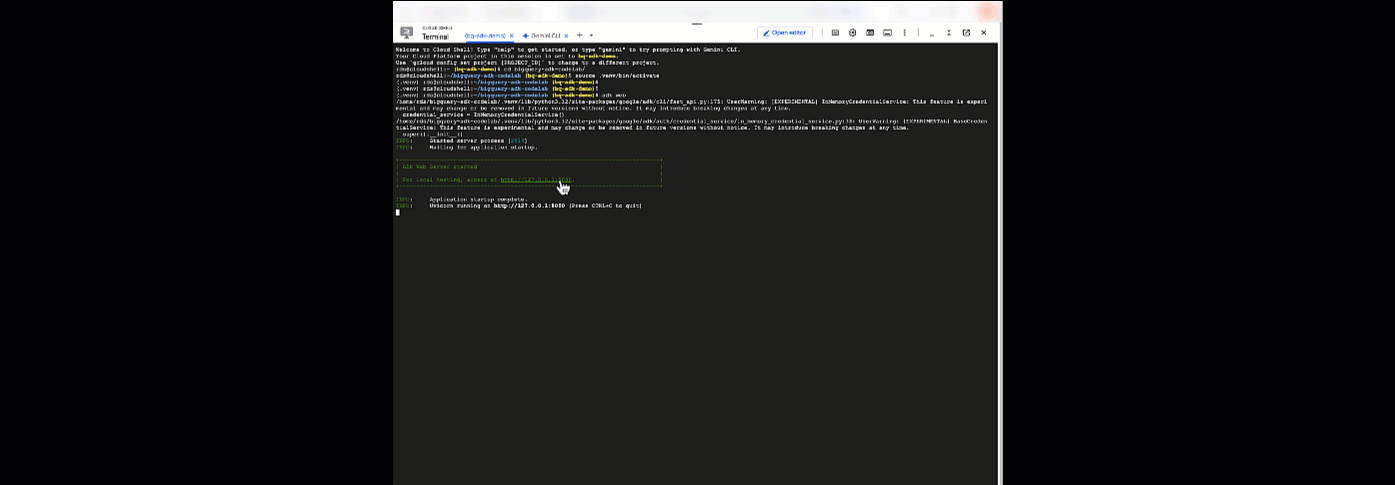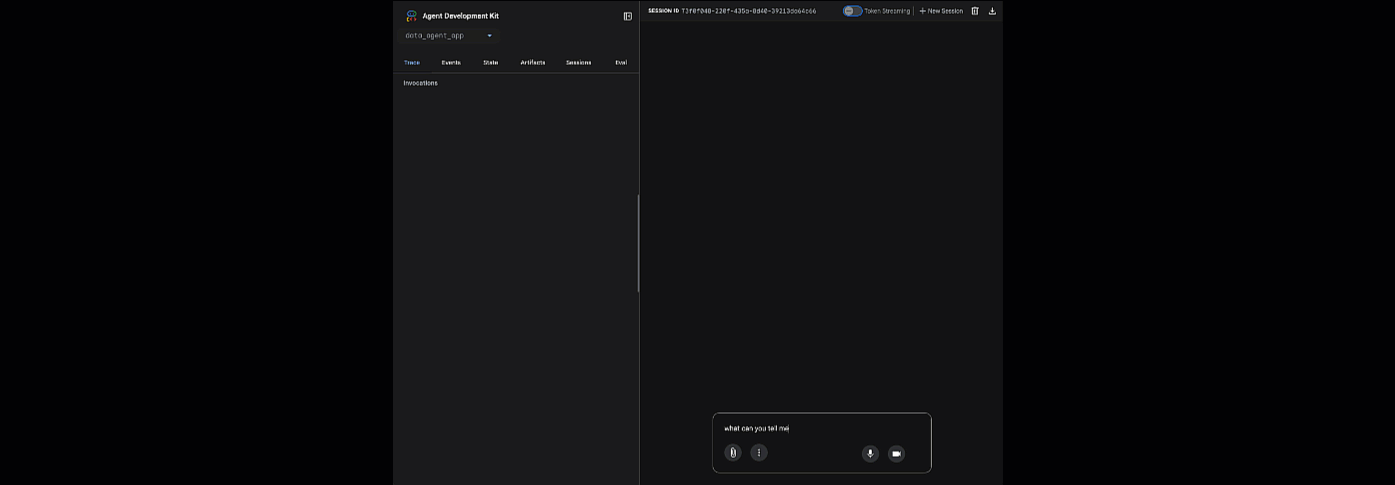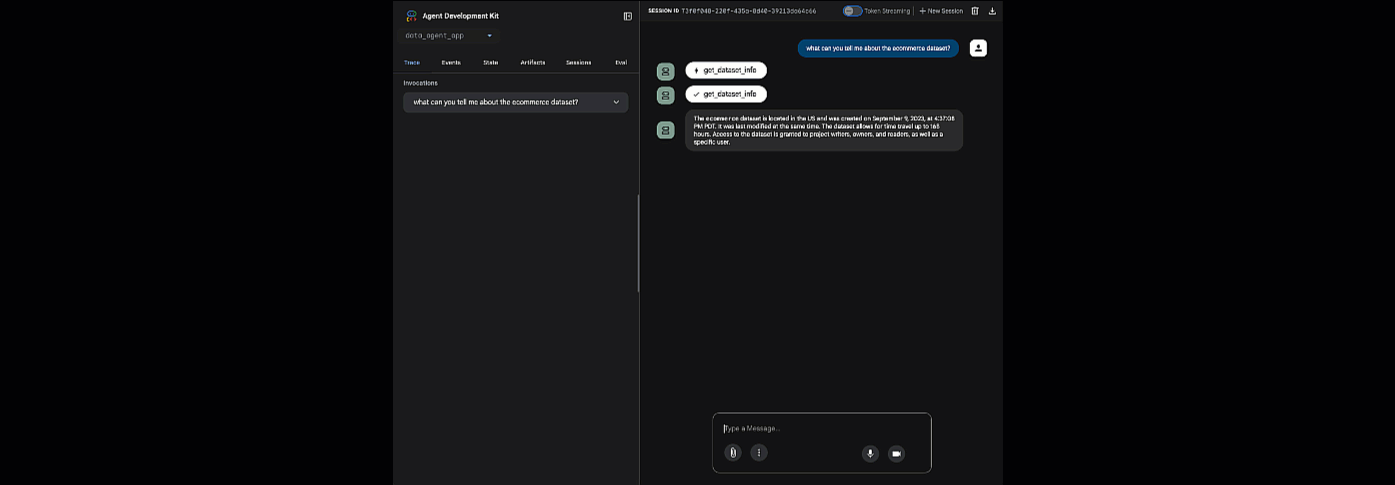
Fermez le serveur Web ADK et appuyez sur Ctrl+C dans le terminal pour l'arrêter.
7. Préparer votre agent pour l'évaluation
Maintenant que vous avez défini votre agent BigQuery, vous devez le rendre exécutable pour l'évaluation.
Le code ci-dessous définit une fonction, run_conversation, qui gère le flux de conversation en créant un agent, en exécutant une session et en traitant les événements pour récupérer la réponse finale.
- Revenez à l'éditeur de code et créez un fichier nommé
run_agent.pydans le répertoire bigquery-adk-codelab, puis copiez-collez le code ci-dessous :
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
Le code ci-dessous définit des fonctions utilitaires pour appeler cette fonction exécutable et renvoyer le résultat. Il inclut également des fonctions d'assistance qui impriment et enregistrent les résultats de l'évaluation :
- Créez un fichier nommé
utils.pydans le répertoire bigquery-adk-codelab, puis copiez et collez le code suivant dans le fichier utils.py :
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. Créer un ensemble de données d'évaluation
Pour évaluer votre agent, vous devez créer un ensemble de données d'évaluation, définir vos métriques d'évaluation et exécuter la tâche d'évaluation.
L'ensemble de données d'évaluation contient une liste de questions (requêtes) et les bonnes réponses correspondantes (références). Le service d'évaluation utilisera ces paires pour comparer les réponses de votre agent et déterminer si elles sont exactes.
- Créez un fichier nommé evaluation_dataset.json dans le répertoire bigquery-adk-codelab, puis copiez-collez l'ensemble de données d'évaluation ci-dessous :
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. Définir vos métriques d'évaluation
Nous allons maintenant utiliser deux métriques personnalisées pour évaluer la capacité de l'agent à répondre aux questions liées à vos données BigQuery. Chacune d'elles fournit un score de 1 à 5 :
- Métrique de précision factuelle : elle évalue si toutes les données et tous les faits présentés dans la réponse sont précis et corrects par rapport à la vérité terrain.
- Métrique d'exhaustivité : elle mesure si la réponse inclut toutes les informations clés demandées par l'utilisateur et présentes dans la bonne réponse, sans aucune omission critique.
- Enfin, créez un fichier nommé
evaluate_agent.pydans le répertoire bigquery-adk-codelab et copiez/collez le code de définition de métrique dans le fichier evaluate_agent.py :
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
J'ai également inclus la métrique TrajectorySingleToolUse pour l'évaluation de la trajectoire. Lorsque ces métriques sont présentes, les appels d'outils d'agent (y compris le code SQL brut qu'il génère et exécute sur BigQuery) sont inclus dans la réponse d'évaluation, ce qui permet une inspection détaillée.
La métrique TrajectorySingleToolUse détermine si un agent a utilisé un outil spécifique. Dans ce cas, j'ai choisi list_table_ids, car nous nous attendons à ce que cet outil soit appelé pour chaque question de l'ensemble de données d'évaluation. Contrairement aux autres métriques de trajectoire, celle-ci ne vous oblige pas à spécifier tous les appels d'outils et arguments attendus pour chaque question de l'ensemble de données d'évaluation.
10. Créer votre tâche d'évaluation
La EvalTask prend l'ensemble de données d'évaluation et les métriques personnalisées, et configure un nouvel test d'évaluation.
Cette fonction, run_eval, est le moteur principal de l'évaluation. Il parcourt une EvalTask, en exécutant votre agent sur chaque question de l'ensemble de données. Pour chaque question, il enregistre la réponse de l'agent, puis l'évalue à l'aide des métriques que vous avez définies précédemment.
Copiez et collez le code suivant en bas du fichier evaluate_agent.py :
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
Les résultats sont résumés et enregistrés dans un fichier JSON.
11. Exécuter votre évaluation
Maintenant que vous avez préparé votre agent, vos métriques d'évaluation et votre ensemble de données d'évaluation, vous pouvez exécuter l'évaluation.
Revenez à Cloud Shell, assurez-vous d'être dans le répertoire bigquery-adk-codelab et exécutez le script d'évaluation à l'aide de la commande suivante :
python evaluate_agent.py
Au fur et à mesure de l'évaluation, vous verrez un résultat semblable à celui-ci :
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
Si vous rencontrez des erreurs comme celles ci-dessous, cela signifie simplement que l'agent n'a appelé aucun outil pour une exécution particulière. Vous pouvez inspecter plus en détail le comportement de l'agent à l'étape suivante.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
Interpréter les résultats :
Accédez au dossier eval_results dans le répertoire data_agent_app et ouvrez le fichier de résultats d'évaluation nommé bq_agent_eval_results_*.json :
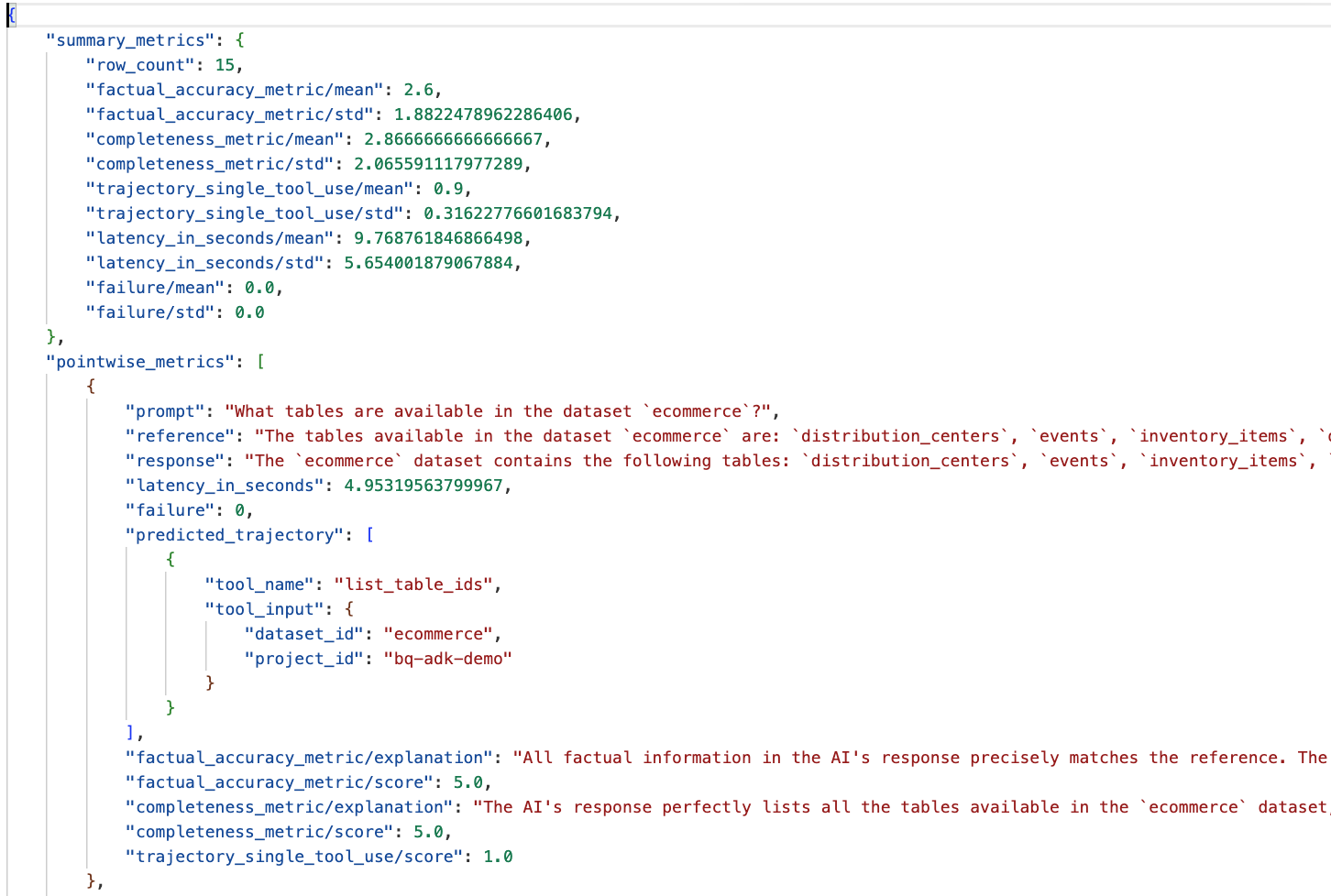
- Métriques récapitulatives : elles offrent une vue globale des performances de votre agent dans l'ensemble de données.
- Métriques ponctuelles sur l'exactitude et l'exhaustivité des faits : un score proche de 5 indique une exactitude et une exhaustivité plus élevées. Une note sera attribuée à chaque question, accompagnée d'une explication écrite du motif de cette note.
- Trajectoire prédite : il s'agit de la liste des appels d'outils utilisés par les agents pour obtenir la réponse finale. Cela nous permettra de voir les requêtes SQL générées par l'agent.
Nous pouvons constater que le score moyen pour l'exhaustivité et l'exactitude factuelle est respectivement de 2,87 et 2,6.
Les résultats ne sont pas très bons. Essayons d'améliorer la capacité de notre agent à répondre aux questions.
12. Améliorer les résultats de l'évaluation de votre agent
Accédez à agent.py dans le répertoire bigquery-adk-codelab et mettez à jour les instructions système et le modèle de l'agent. N'oubliez pas de remplacer <YOUR_PROJECT_ID> par l'ID de votre projet :
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
Revenez maintenant au terminal et réexécutez l'évaluation :
python evaluate_agent.py
Vous devriez constater que les résultats sont désormais bien meilleurs :
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
L'évaluation de votre agent est un processus itératif. Pour améliorer encore les résultats de l'évaluation, vous pouvez ajuster les instructions système, les paramètres du modèle ou même les métadonnées dans BigQuery. Consultez ces conseils et astuces pour obtenir d'autres idées.
13. Effectuer un nettoyage
Pour éviter que des frais ne soient facturés en permanence sur votre compte Google Cloud, il est important de supprimer les ressources que nous avons créées lors de cet atelier.
Si vous avez créé des ensembles de données ou des tables BigQuery spécifiques pour cet atelier de programmation (par exemple, l'ensemble de données sur l'e-commerce), vous pouvez les supprimer :
bq rm -r $PROJECT_ID:ecommerce
Pour supprimer le répertoire bigquery-adk-codelab et son contenu :
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. Félicitations
Félicitations ! Vous avez réussi à créer et à évaluer un agent BigQuery à l'aide d'Agent Development Kit (ADK). Vous savez désormais comment configurer un agent ADK avec les outils BigQuery et mesurer ses performances à l'aide de métriques d'évaluation personnalisées.