
1. מבוא
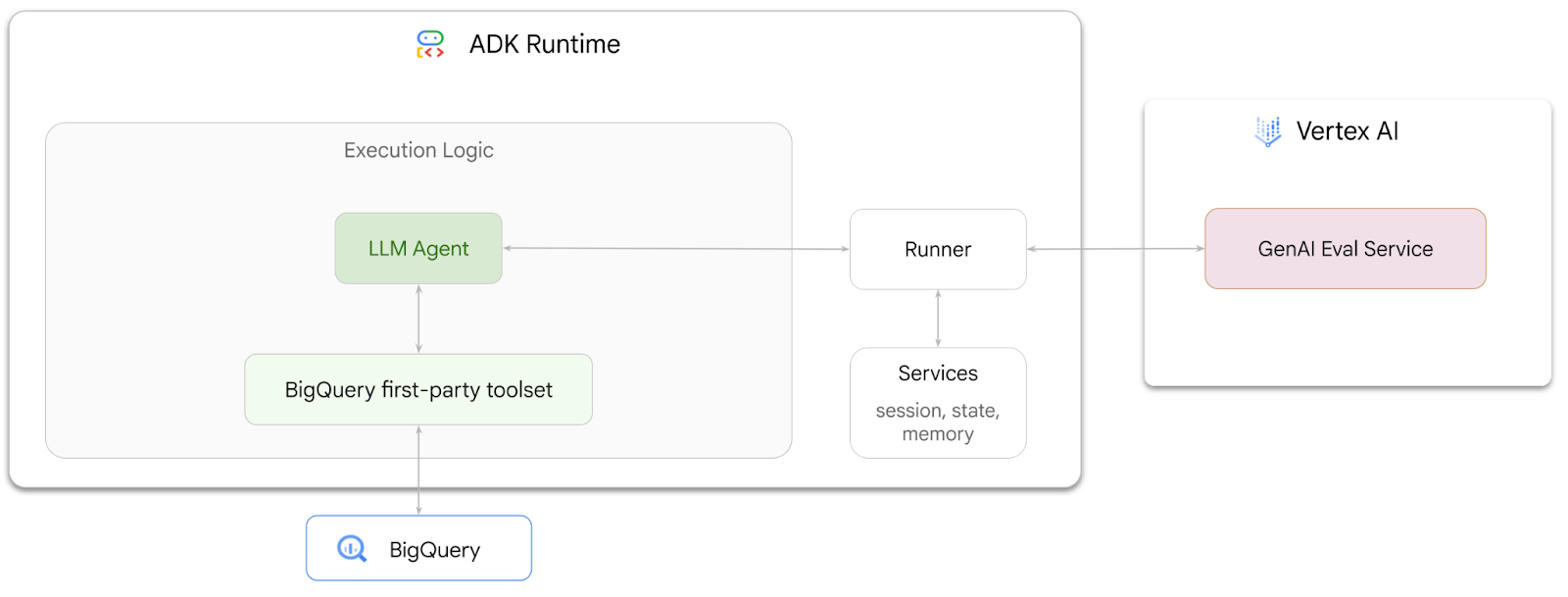
בשיעור Codelab הזה נסביר איך ליצור סוכנים שיכולים לענות על שאלות לגבי נתונים שמאוחסנים ב-BigQuery באמצעות הערכה לפיתוח סוכנים (ADK). בנוסף, תעריכו את הסוכנים האלה באמצעות שירות ההערכה של Vertex AI ל-AI גנרטיבי:
מה תעשו
- יצירת סוכן לניתוח נתוני שיחות ב-ADK
- מציידים את הסוכן הזה בערכת הכלים מאינטראקציה ישירה (First-Party) של ADK ל-BigQuery כדי שהוא יוכל לקיים אינטראקציה עם נתונים שמאוחסנים ב-BigQuery
- יצירת מסגרת להערכה של הסוכן באמצעות שירות ההערכה של Vertex AI ל-AI גנרטיבי
- הפעלת הערכות של הסוכן הזה בהשוואה לקבוצה של תשובות לדוגמה
מה תצטרכו
- דפדפן אינטרנט כמו Chrome
- פרויקט בענן של Google שהחיוב בו מופעל, או
- חשבון Gmail. בקטע הבא נסביר איך לממש קרדיט חינמי בסך 5 $לשימוש ב-codelab הזה, ואיך להגדיר פרויקט חדש.
שיעור ה-Codelab הזה מיועד למפתחים בכל הרמות, כולל מתחילים. תשתמשו בממשק שורת הפקודה ב-Google Cloud Shell ובקוד Python לפיתוח ADK. לא צריך להיות מומחה ל-Python, אבל הבנה בסיסית של קריאת קוד תעזור לכם להבין את המושגים.
2. לפני שמתחילים
יצירת פרויקט ב-Google Cloud
- ב-Google Cloud Console, בדף לבחירת הפרויקט, בוחרים פרויקט ב-Google Cloud או יוצרים פרויקט.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
מפעילים את Cloud Shell
Cloud Shell היא סביבת שורת פקודה שפועלת ב-Google Cloud וכוללת מראש את הכלים הנדרשים.
- לוחצים על Activate Cloud Shell (הפעלת Cloud Shell) בחלק העליון של מסוף Google Cloud:

- אחרי שמתחברים ל-Cloud Shell, מריצים את הפקודה הבאה כדי לאמת את האימות ב-Cloud Shell:
gcloud auth list
- מריצים את הפקודה הבאה כדי לוודא שהפרויקט מוגדר לשימוש ב-gcloud:
gcloud config list project
- משתמשים בפקודה הבאה כדי להגדיר את הפרויקט:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
הפעלת ממשקי ה-API
- מריצים את הפקודה הזו כדי להפעיל את כל ממשקי ה-API והשירותים הנדרשים:
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- אם הפקודה תפעל בהצלחה, תוצג הודעה דומה לזו שמופיעה בהמשך:
Operation "operations/..." finished successfully.
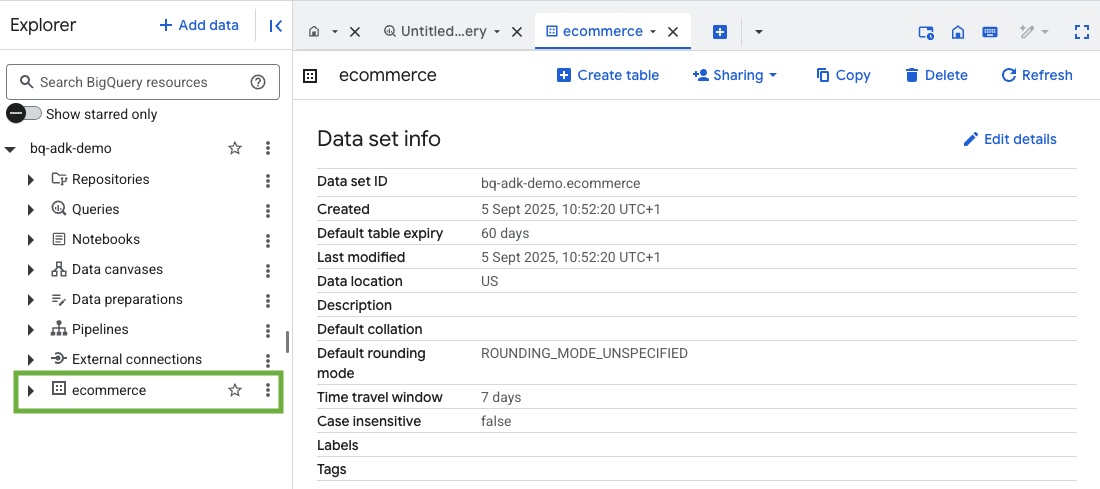
3. יצירת מערך נתונים ב-BigQuery
- מריצים את הפקודה הבאה ב-Cloud Shell כדי ליצור מערך נתונים חדש בשם ecommerce ב-BigQuery:
bq mk --dataset --location=US ecommerce
קבוצת משנה סטטית של קבוצת הנתונים הציבורית ב-BigQuery thelook_ecommerce נשמרת כקבצי AVRO בקטגוריה ציבורית של Google Cloud Storage.
- מריצים את הפקודה הזו ב-Cloud Shell כדי לטעון את קובצי ה-Avro האלה ל-BigQuery כטבלאות (events, order_items, products, users, orders):
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
התהליך הזה עשוי להימשך כמה דקות.
- כדי לוודא שמערך הנתונים והטבלאות נוצרו, נכנסים אל מסוף BigQuery בפרויקט Google Cloud:
4. הכנת סביבה לסוכני ADK
חוזרים ל-Cloud Shell ומוודאים שאתם בספריית הבית. ניצור סביבת Python וירטואלית ונתקין את החבילות הנדרשות.
- פותחים כרטיסייה חדשה בטרמינל ב-Cloud Shell ומריצים את הפקודה הבאה כדי ליצור תיקייה בשם bigquery-adk-codelab ולעבור אליה:
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- יוצרים סביבת Python וירטואלית:
python -m venv .venv
- מפעילים את הסביבה הווירטואלית:
source .venv/bin/activate
- מתקינים את חבילות ה-Python של ADK ו-AI-Platform מבית Google. כדי להעריך את סוכן BigQuery, צריך את פלטפורמת ה-AI ואת חבילת pandas:
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. יצירת אפליקציית ADK
עכשיו ניצור את סוכן BigQuery. הסוכן הזה מיועד לענות על שאלות בשפה טבעית לגבי נתונים שמאוחסנים ב-BigQuery.
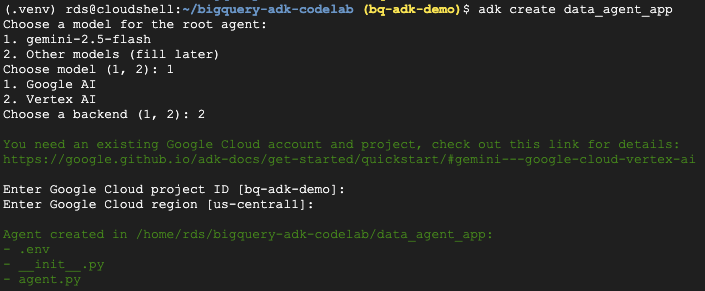
- מריצים את הפקודה adk create utility כדי ליצור סביבת עבודה לאפליקציית סוכן חדשה עם התיקיות והקבצים הנדרשים:
adk create data_agent_app
פועלים לפי ההנחיות:
- בוחרים במודל gemini-2.5-flash.
- בוחרים ב-Vertex AI עבור ה-Backend.
- מאשרים את מזהה הפרויקט ואת האזור שמוגדרים כברירת מחדל ב-Google Cloud.
דוגמה לאינטראקציה:
- לוחצים על הלחצן Open Editor ב-Cloud Shell כדי לפתוח את Cloud Shell Editor ולראות את התיקיות והקבצים החדשים שנוצרו:

שימו לב לקבצים שנוצרו:
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: מסמן את התיקייה כמודול Python.
- agent.py: מכיל את ההגדרה הראשונית של הסוכן.
- .env: מכיל משתני סביבה לפרויקט (יכול להיות שתצטרכו ללחוץ על View > Toggle Hidden Files (תצוגה > החלפת קבצים מוסתרים) כדי לראות את הקובץ הזה)
מעדכנים את המשתנים שלא הוגדרו בצורה נכונה בהנחיות:
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. הגדרת הסוכן והקצאת ערכת הכלים של BigQuery
כדי להגדיר סוכן ADK שמקיים אינטראקציה עם BigQuery באמצעות ערכת הכלים של BigQuery, מחליפים את התוכן הקיים בקובץ agent.py בקוד הבא.
צריך לעדכן את מזהה הפרויקט בהוראות של הסוכן למזהה הפרויקט בפועל:
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
ערכת הכלים של BigQuery מספקת לסוכן את היכולות לאחזר מטא-נתונים ולהריץ שאילתות SQL על נתונים ב-BigQuery. כדי להשתמש בערכת הכלים, צריך לבצע אימות. האפשרויות הנפוצות ביותר הן Application Default Credentials (ADC) לפיתוח, OAuth אינטראקטיבי כשהסוכן צריך לפעול בשם משתמש ספציפי, או Service Account Credentials לאימות מאובטח ברמת הייצור.
מכאן אפשר לשוחח בצ'אט עם הסוכן. כדי לעשות את זה, צריך לחזור ל-Cloud Shell ולהריץ את הפקודה הבאה:
adk web
אמורה להופיע התראה שהשרת האינטרנטי התחיל לפעול:
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
לוחצים על כתובת ה-URL שסופקה כדי להפעיל את adk web – אפשר לשאול את הנציג שאלות לגבי מערך הנתונים:
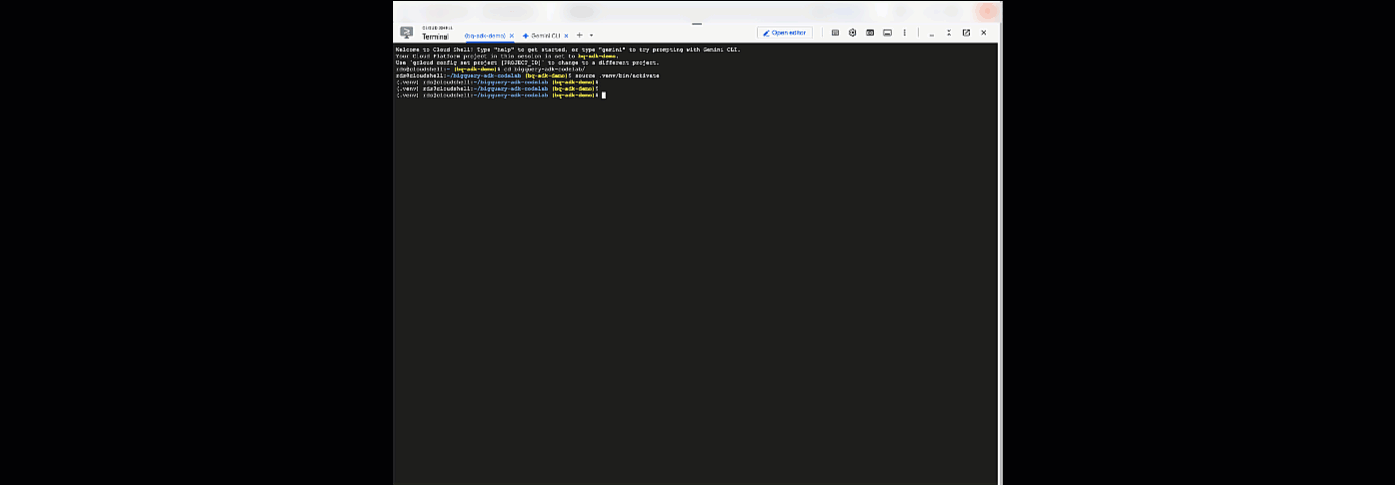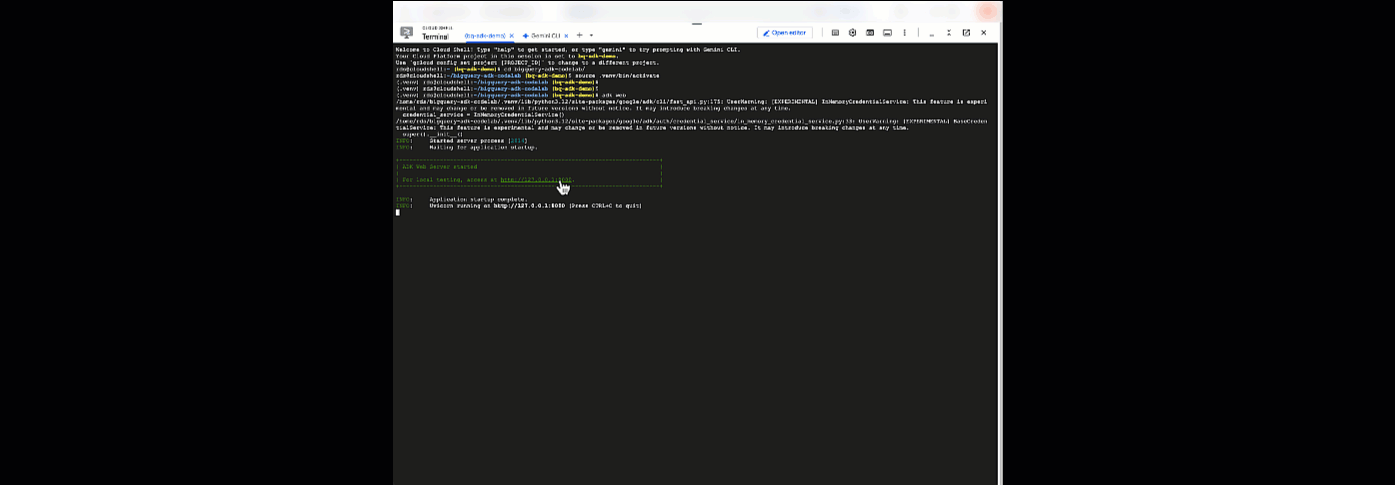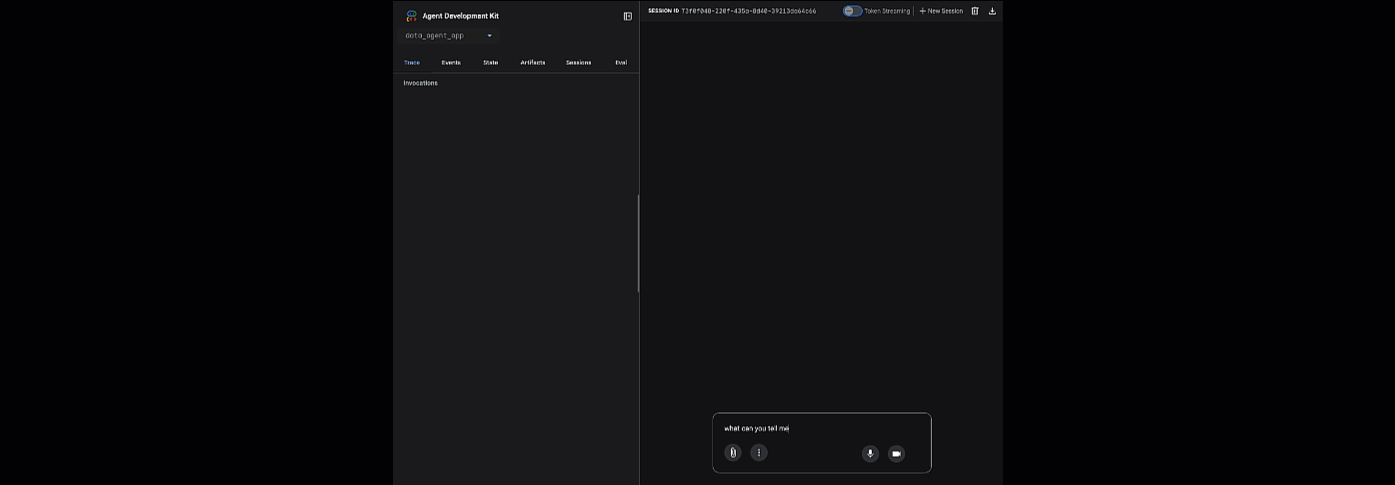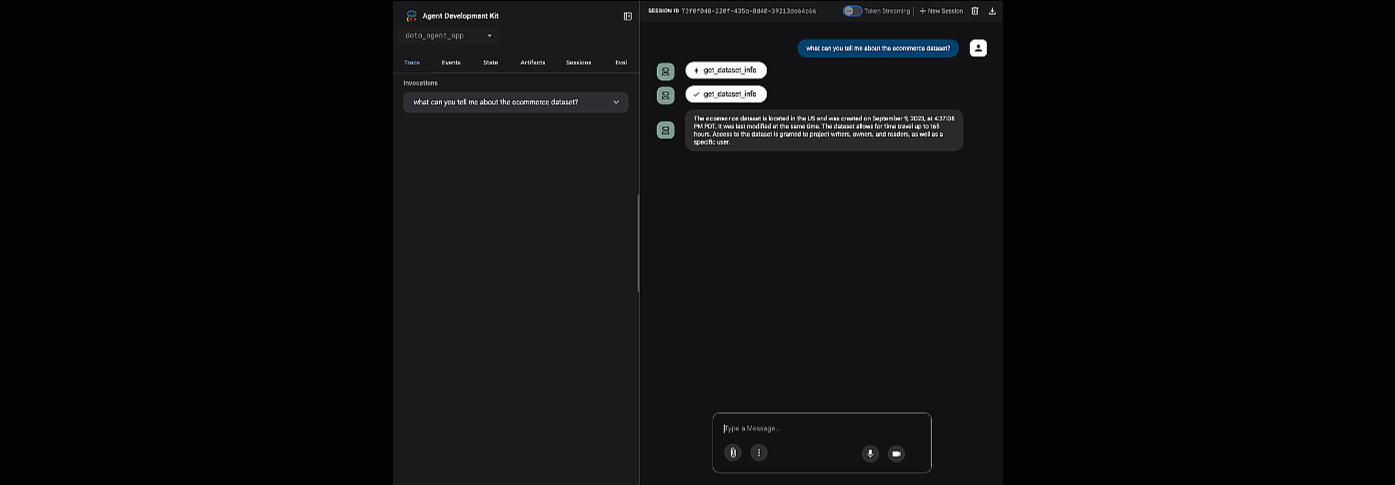
סוגרים את ADK Web ומקישים על Ctrl + C בטרמינל כדי לכבות את שרת האינטרנט.
7. הכנת הסוכן להערכה
אחרי שמגדירים את סוכן BigQuery, צריך להגדיר אותו כך שאפשר יהיה להריץ אותו לצורך הערכה.
הקוד שלמטה מגדיר פונקציה, run_conversation, שמטפלת בזרימת השיחה על ידי יצירת סוכן, הפעלת סשן ועיבוד האירועים כדי לאחזר את התגובה הסופית.
- חוזרים ל-Cloud Editor ויוצרים קובץ חדש בשם
run_agent.pyבספרייה bigquery-adk-codelab ומעתיקים/מדביקים את הקוד הבא:
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
הקוד שבהמשך מגדיר פונקציות עזר להפעלת הפונקציה הזו ולהחזרת התוצאה. היא כוללת גם פונקציות עזר שמדפיסות ושומרות את תוצאות ההערכה:
- יוצרים קובץ חדש בשם
utils.pyבספרייה bigquery-adk-codelab ומעתיקים את הקוד הזה לקובץ utils.py:
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. יצירת מערך נתונים להערכה
כדי להעריך את הסוכן, צריך ליצור מערך נתונים להערכה, להגדיר את מדדי ההערכה ולהריץ את משימת ההערכה.
מערך נתוני ההערכה מכיל רשימה של שאלות (פרומפטים) והתשובות הנכונות המתאימות להן (הפניות). שירות ההערכה ישתמש בצמדים האלה כדי להשוות את התשובות של הסוכן ולקבוע אם הן מדויקות.
- יוצרים קובץ חדש בשם evaluation_dataset.json בספרייה bigquery-adk-codelab ומעתיקים/מדביקים את מערך הנתונים של ההערכה שמופיע בהמשך:
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. הגדרת מדדי ההערכה
עכשיו נשתמש בשני מדדים מותאמים אישית כדי להעריך את היכולת של הסוכן לענות על שאלות שקשורות לנתוני BigQuery שלכם. כל מדד יספק ציון מ-1 עד 5:
- מדד הדיוק העובדתי: המדד הזה בודק אם כל הנתונים והעובדות שמוצגים בתשובה מדויקים ונכונים בהשוואה לאמת הבסיסית.
- מדד השלמות: המדד הזה בודק אם התשובה כוללת את כל חלקי המידע העיקריים שהמשתמש ביקש ושמופיעים בתשובה הנכונה, בלי השמטות קריטיות.
- לבסוף, יוצרים קובץ חדש בשם
evaluate_agent.pyבספרייה bigquery-adk-codelab ומעתיקים את קוד ההגדרה של המדד לקובץ evaluate_agent.py:
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
הוספתי גם את המדד TrajectorySingleToolUse להערכת מסלול. אם המדדים האלה קיימים, קריאות הכלים של הסוכן (כולל ה-SQL הגולמי שהוא יוצר ומריץ ב-BigQuery) ייכללו בתשובת ההערכה, וכך תוכלו לבדוק אותן בפירוט.
המדד TrajectorySingleToolUse קובע אם סוכן השתמש בכלי מסוים. במקרה הזה, בחרתי את list_table_ids, כי אנחנו מצפים שהכלי הזה יופעל לכל שאלה במערך הנתונים של ההערכה. בניגוד למדדים אחרים של מסלול, המדד הזה לא מחייב לציין את כל הקריאות הצפויות לכלים ואת הארגומנטים לכל שאלה במערך נתוני ההערכה.
10. יצירת משימת הערכה
ה-EvalTask לוקח את מערך הנתונים של ההערכה ואת המדדים המותאמים אישית ומגדיר ניסוי הערכה חדש.
הפונקציה run_eval היא המנוע הראשי להערכה. הוא מבצע לולאה דרך EvalTask, ומריץ את הסוכן שלכם על כל שאלה במערך הנתונים. לכל שאלה, המערכת מתעדת את התשובה של הנציג ואז משתמשת במדדים שהגדרתם קודם כדי לתת לה ציון.
מעתיקים את הקוד הבא ומדביקים אותו בחלק התחתון של קובץ evaluate_agent.py:
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
התוצאות מסוכמות ונשמרות בקובץ JSON.
11. הרצת ההערכה
אחרי שהסוכן, מדדי ההערכה וערכת נתוני ההערכה מוכנים, אפשר להריץ את ההערכה.
חוזרים ל-Cloud Shell, מוודאים שאתם בספרייה bigquery-adk-codelab ומריצים את סקריפט ההערכה באמצעות הפקודה הבאה:
python evaluate_agent.py
במהלך ההערכה יוצג פלט שדומה לזה:
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
אם נתקלתם בשגיאות כמו אלה שבהמשך, זה רק אומר שהסוכן לא הפעיל אף כלי במהלך ריצה מסוימת. בשלב הבא תוכלו לבדוק את התנהגות הסוכן.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
פירוש התוצאות:
עוברים לתיקייה eval_results בספרייה data_agent_app ופותחים את קובץ תוצאות ההערכה שנקרא bq_agent_eval_results_*.json:
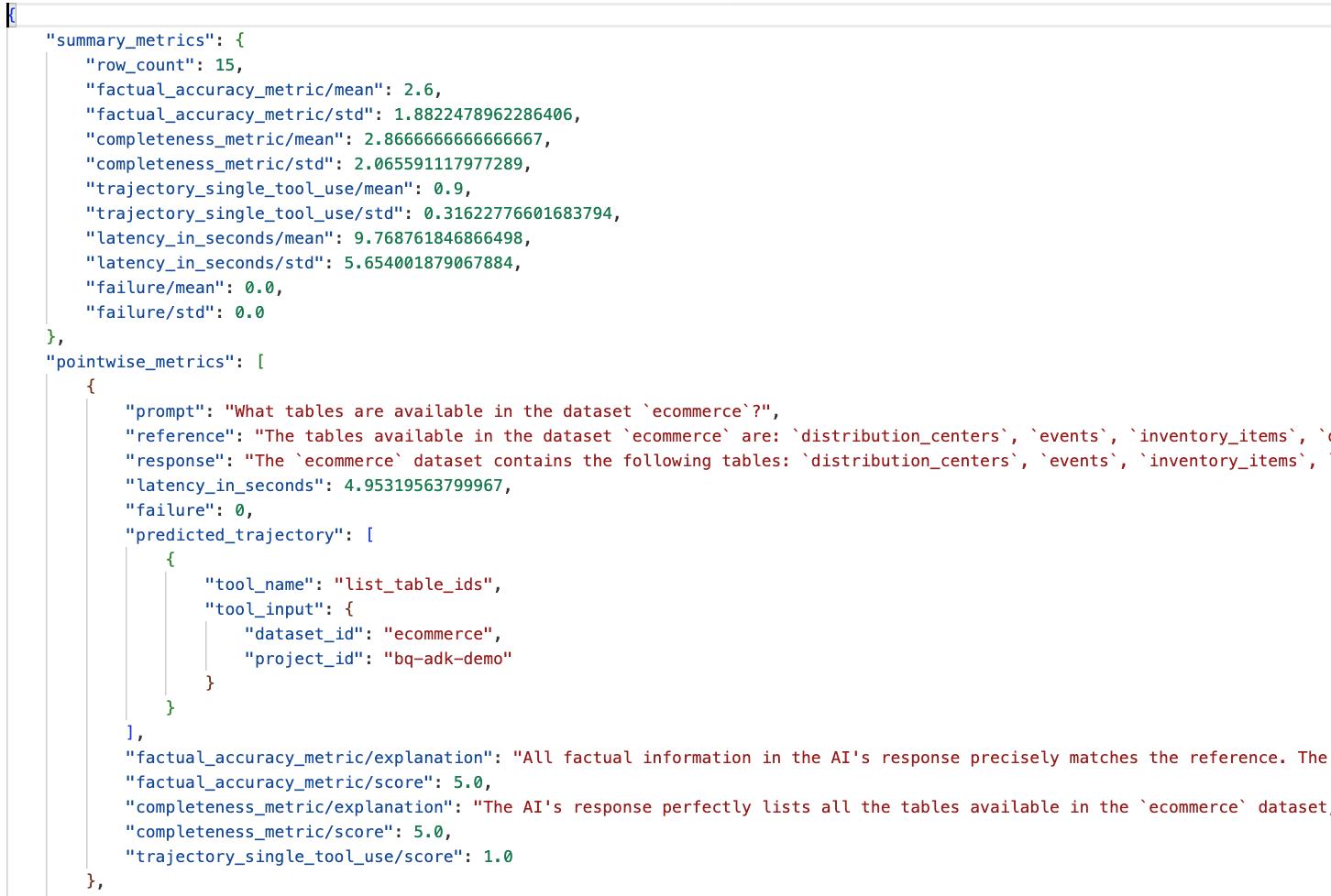
- מדדי סיכום: מספקים תצוגה מצטברת של ביצועי הסוכן במערך הנתונים.
- מדדים נקודתיים של דיוק עובדתי ושלמות: ציון שקרוב יותר ל-5 מצביע על דיוק ושלמות גבוהים יותר. לכל שאלה יוצג ציון, והסבר כתוב לציון שניתן.
- מסלול צפוי: זו רשימת הקריאות לכלי שבהן הסוכנים השתמשו כדי להגיע לתגובה הסופית. כך נוכל לראות את כל שאילתות ה-SQL שנוצרו על ידי הסוכן.
אפשר לראות שהציון הממוצע של השלמות והדיוק העובדתי הוא 2.87 ו-2.6 בהתאמה.
התוצאות לא טובות במיוחד. אנסה לשפר את היכולת של הסוכן לענות על שאלות.
12. שיפור תוצאות ההערכה של הסוכן
עוברים אל agent.py בספרייה bigquery-adk-codelab ומעדכנים את המודל של הסוכן ואת הוראות המערכת. חשוב להחליף את <YOUR_PROJECT_ID> במזהה הפרויקט:
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
עכשיו חוזרים לטרמינל ומריצים מחדש את ההערכה:
python evaluate_agent.py
אמורות להתקבל תוצאות טובות יותר:
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
הערכת הסוכן היא תהליך איטרטיבי. כדי לשפר עוד יותר את תוצאות ההערכה, אפשר לשנות את הוראות המערכת, את פרמטרים המודל או אפילו את המטא-נתונים ב-BigQuery. כדאי לעיין בטיפים וטריקים כדי לקבל עוד רעיונות.
13. מחיקה
כדי להימנע מחיובים שוטפים בחשבון Google Cloud, חשוב למחוק את המשאבים שיצרנו במהלך הסדנה הזו.
אם יצרתם מערכי נתונים או טבלאות ספציפיים ב-BigQuery בשביל ה-Codelab הזה (למשל, מערך הנתונים של המסחר האלקטרוני), כדאי למחוק אותם:
bq rm -r $PROJECT_ID:ecommerce
כדי להסיר את הספרייה bigquery-adk-codelab ואת התוכן שלה:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. מזל טוב
מעולה! יצרתם והערכתם בהצלחה סוכן BigQuery באמצעות Agent Development Kit (ADK). עכשיו אתם יודעים איך להגדיר סוכן ADK באמצעות כלים של BigQuery ולמדוד את הביצועים שלו באמצעות מדדי הערכה בהתאמה אישית.