
1. Pengantar
Dalam codelab ini, Anda akan mempelajari cara membangun agen yang dapat menjawab pertanyaan tentang data yang disimpan di BigQuery menggunakan Agent Development Kit (ADK). Anda juga akan mengevaluasi agen ini menggunakan layanan Evaluasi AI Generatif Vertex AI:
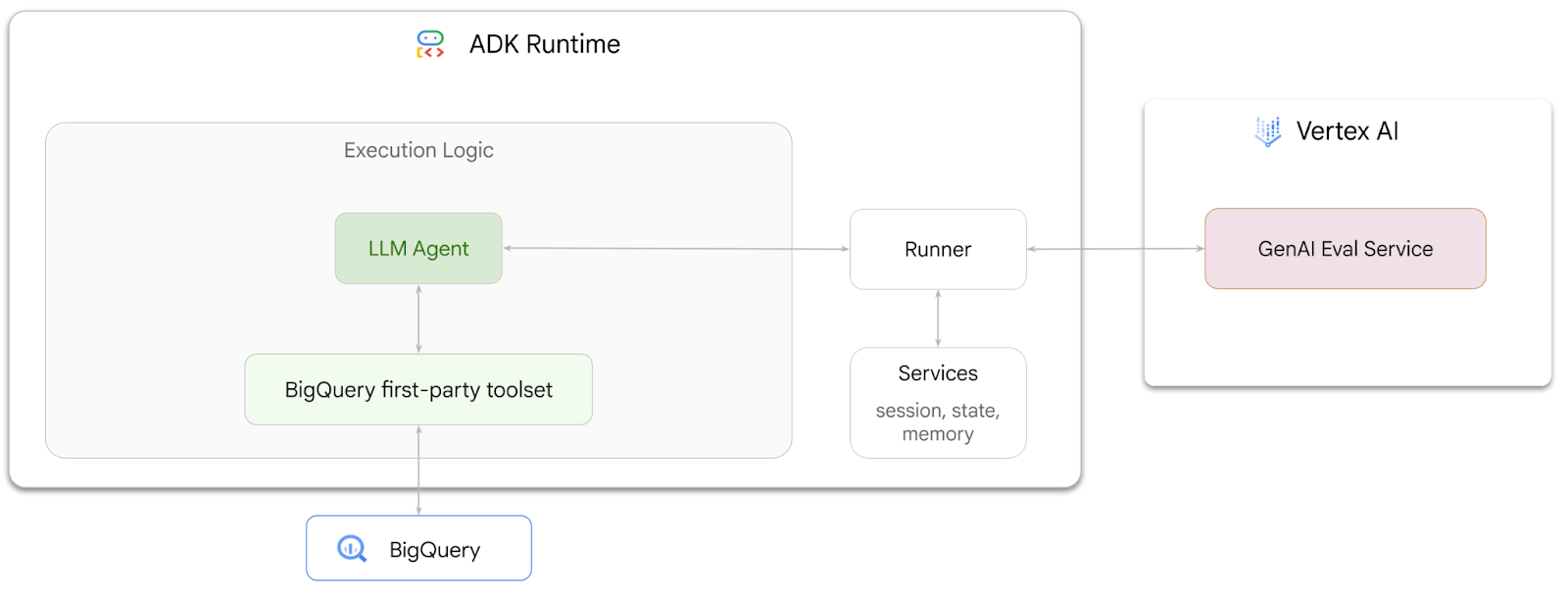
Yang akan Anda lakukan
- Membangun agen analisis percakapan di ADK
- Lengkapi agen ini dengan kumpulan alat pihak pertama ADK untuk BigQuery sehingga agen dapat berinteraksi dengan data yang disimpan di BigQuery
- Buat framework evaluasi untuk agen Anda menggunakan layanan Evaluasi AI Generatif Vertex AI
- Jalankan evaluasi pada agen ini terhadap serangkaian respons standar
Yang Anda butuhkan
- Browser web seperti Chrome
- Project Google Cloud dengan penagihan diaktifkan, atau
- Akun Gmail. Bagian berikutnya akan menunjukkan cara menukarkan kredit gratis senilai $5 untuk codelab ini dan menyiapkan project baru
Codelab ini ditujukan bagi developer dari semua level, termasuk pemula. Anda akan menggunakan antarmuka command line di Google Cloud Shell dan kode Python untuk pengembangan ADK. Anda tidak perlu menjadi pakar Python, tetapi pemahaman dasar tentang cara membaca kode akan membantu Anda memahami konsepnya.
2. Sebelum memulai
Buat Project Google Cloud
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
Mulai Cloud Shell
Cloud Shell adalah lingkungan command line yang berjalan di Google Cloud yang telah dilengkapi dengan alat yang diperlukan.
- Klik Activate Cloud Shell di bagian atas konsol Google Cloud:

- Setelah terhubung ke Cloud Shell, jalankan perintah ini untuk memverifikasi autentikasi Anda di Cloud Shell:
gcloud auth list
- Jalankan perintah berikut untuk mengonfirmasi bahwa project Anda dikonfigurasi untuk digunakan dengan gcloud:
gcloud config list project
- Gunakan perintah berikut untuk menyetel project Anda:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Mengaktifkan API
- Jalankan perintah ini untuk mengaktifkan semua API dan layanan yang diperlukan:
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- Setelah perintah berhasil dieksekusi, Anda akan melihat pesan yang mirip dengan yang ditampilkan di bawah:
Operation "operations/..." finished successfully.
3. Membuat set data BigQuery
- Jalankan perintah berikut di Cloud Shell untuk membuat set data baru bernama ecommerce di BigQuery:
bq mk --dataset --location=US ecommerce
Subkumpulan statis set data publik BigQuery thelook_ecommerce disimpan sebagai file AVRO di bucket Google Cloud Storage publik.
- Jalankan perintah ini di Cloud Shell untuk memuat file Avro ini ke BigQuery sebagai tabel (events, order_items, products, users, orders):
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
Proses ini mungkin membutuhkan waktu beberapa menit.
- Verifikasi bahwa set data dan tabel telah dibuat dengan membuka konsol BigQuery di Project Google Cloud Anda:
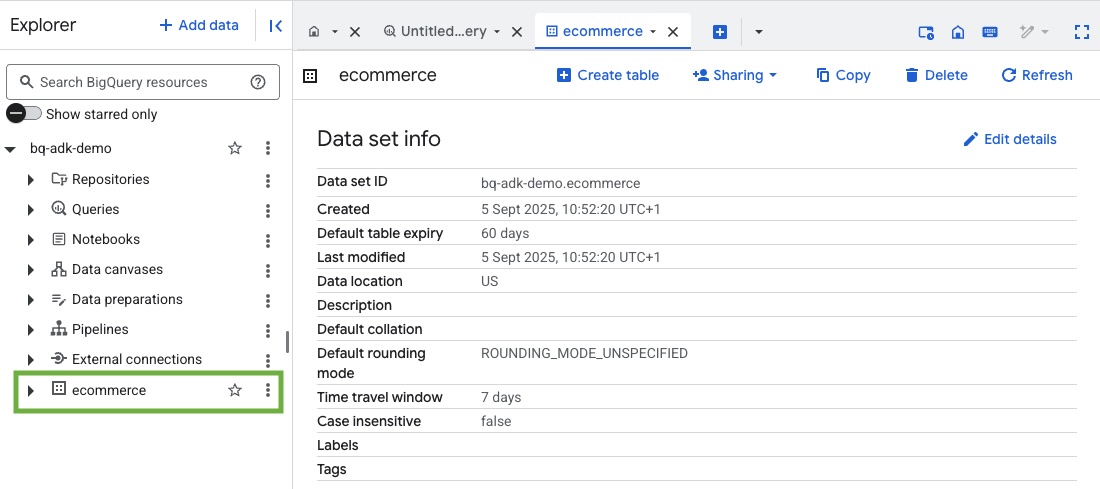
4. Menyiapkan lingkungan untuk agen ADK
Kembali ke Cloud Shell dan pastikan Anda berada di direktori utama Anda. Kita akan membuat lingkungan Python virtual dan menginstal paket yang diperlukan.
- Buka tab terminal baru di Cloud Shell dan jalankan perintah ini untuk membuat dan membuka folder bernama bigquery-adk-codelab:
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- Buat lingkungan Python virtual:
python -m venv .venv
- Aktifkan lingkungan virtual:
source .venv/bin/activate
- Instal paket python ADK dan AI-Platform Google. Platform AI dan paket pandas diperlukan untuk mengevaluasi agen bigquery:
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. Membuat aplikasi ADK
Sekarang, mari kita buat Agen BigQuery. Agen ini akan dirancang untuk menjawab pertanyaan dalam bahasa alami tentang data yang disimpan di BigQuery.
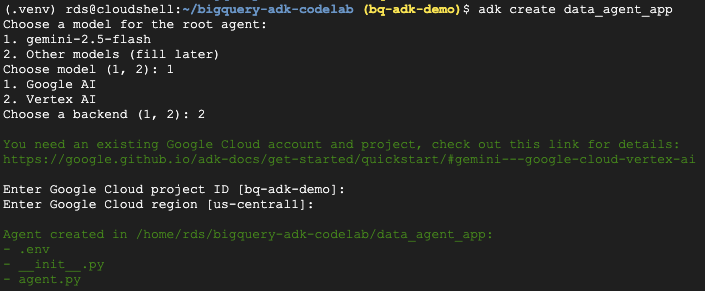
- Jalankan perintah utilitas adk create untuk membuat struktur aplikasi agen baru dengan folder dan file yang diperlukan:
adk create data_agent_app
Ikuti perintahnya:
- Pilih gemini-2.5-flash untuk model.
- Pilih Vertex AI untuk backend.
- Konfirmasi ID Project Google Cloud dan region default Anda.
Contoh interaksi ditampilkan di bawah:
- Klik tombol Open Editor di Cloud Shell untuk membuka Cloud Shell Editor dan melihat folder serta file yang baru dibuat:

Perhatikan file yang dihasilkan:
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: Menandai folder sebagai modul Python.
- agent.py: Berisi definisi agen awal.
- .env: Berisi variabel lingkungan untuk project Anda (Anda mungkin perlu mengklik View > Toggle Hidden Files untuk melihat file ini)
Perbarui variabel yang tidak disetel dengan benar dari perintah:
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. Tentukan agen Anda dan tetapkan set alat BigQuery ke agen tersebut
Untuk menentukan Agen ADK yang berinteraksi dengan BigQuery menggunakan toolset BigQuery, ganti konten yang ada di file agent.py dengan kode berikut.
Anda harus memperbarui project ID dalam petunjuk agen ke project ID Anda yang sebenarnya:
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
Toolset BigQuery menyediakan agen dengan kemampuan untuk mengambil metadata dan menjalankan kueri SQL pada data BigQuery. Untuk menggunakan toolset, Anda harus melakukan autentikasi, dengan opsi yang paling umum adalah Kredensial Default Aplikasi (ADC) untuk pengembangan, OAuth Interaktif saat agen perlu bertindak atas nama pengguna tertentu, atau Kredensial Akun Layanan untuk autentikasi tingkat produksi yang aman.
Dari sini, Anda dapat melakukan chat dengan agen Anda dengan kembali ke Cloud Shell dan menjalankan perintah ini:
adk web
Anda akan melihat notifikasi yang menyatakan bahwa server web telah dimulai:
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
Klik URL yang diberikan untuk meluncurkan web adk. Anda dapat mengajukan beberapa pertanyaan kepada agen tentang set data:
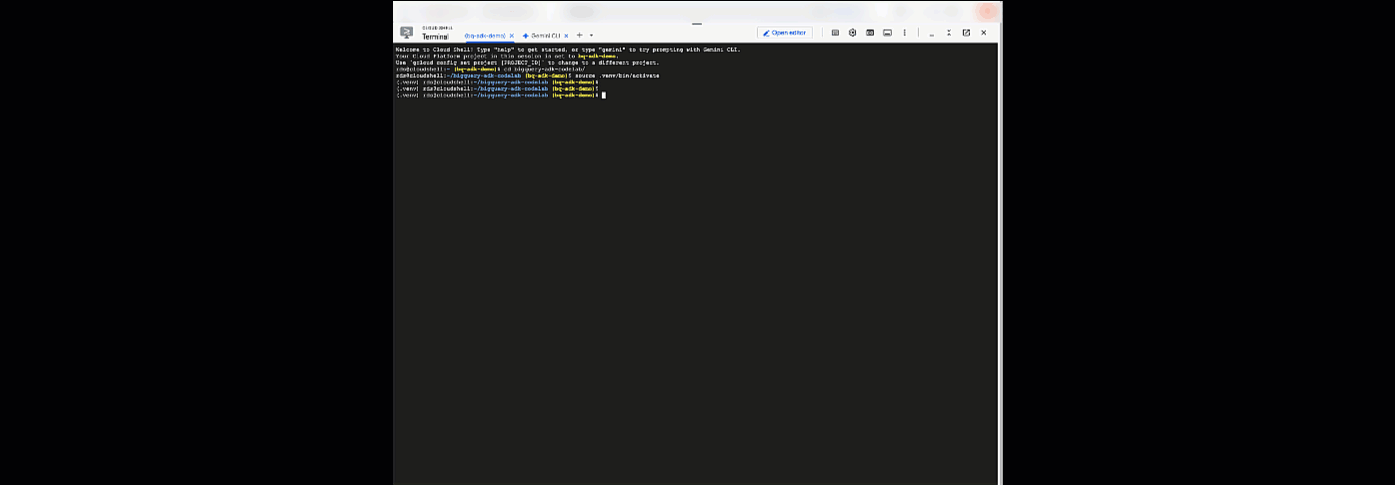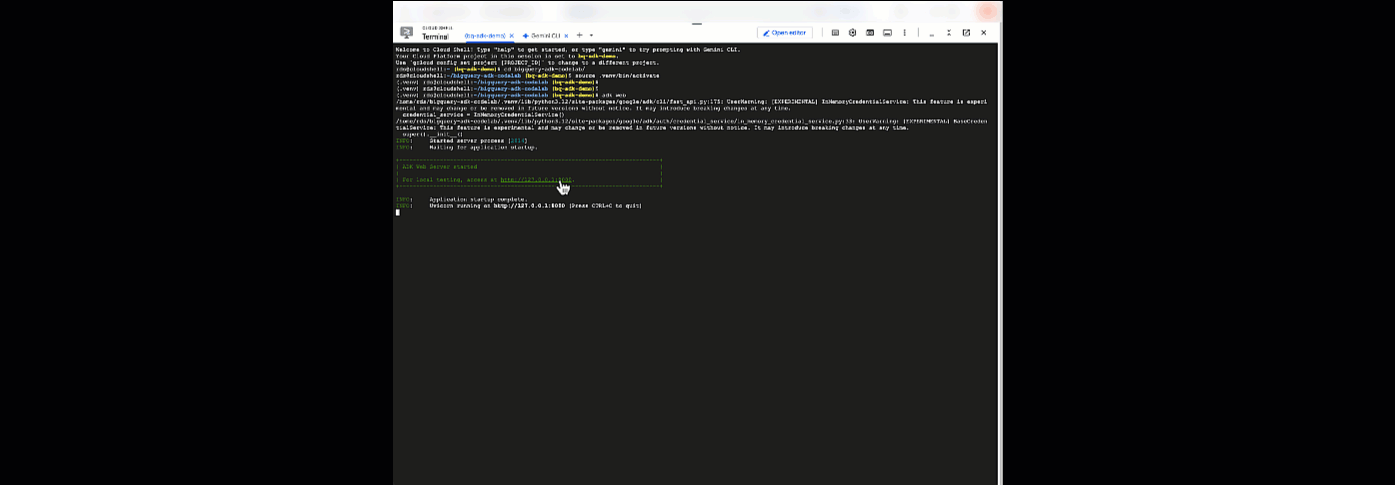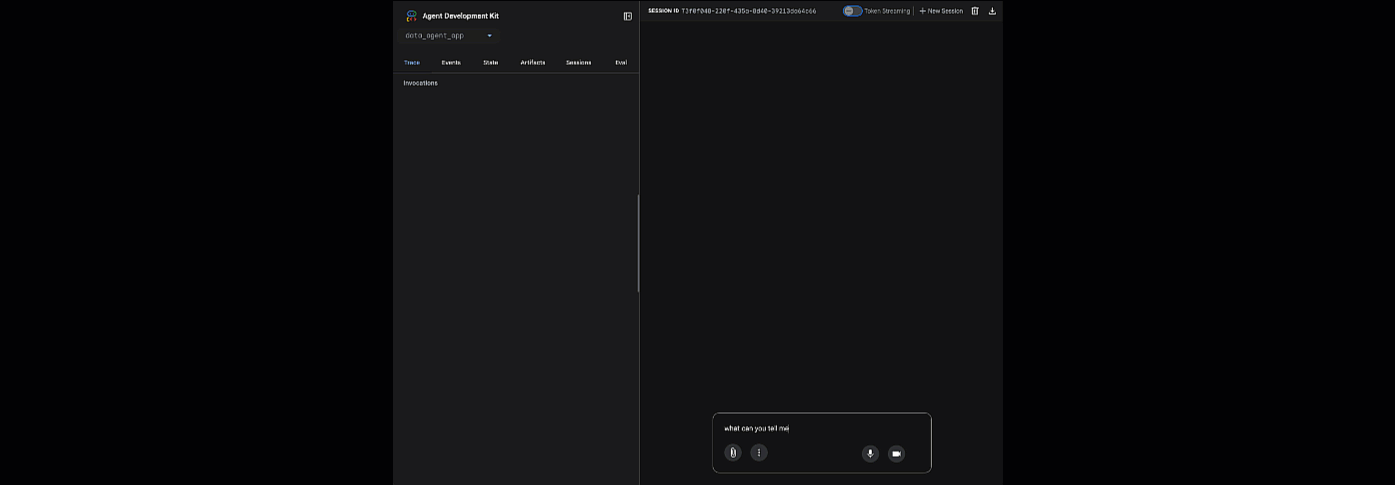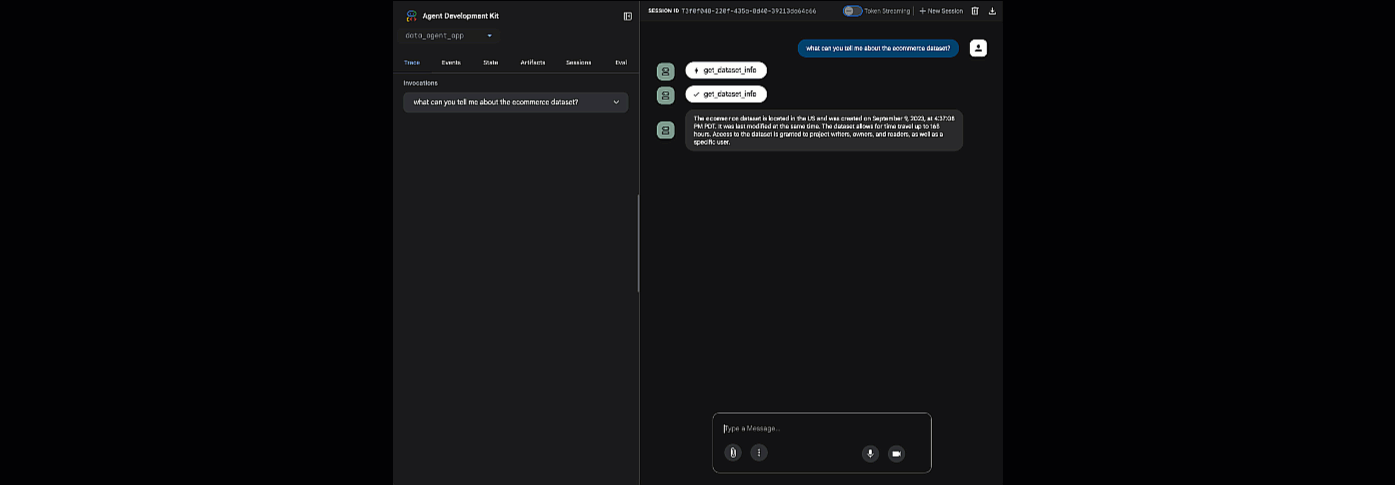
Tutup adk web dan tekan Ctrl + C di terminal untuk mematikan server web.
7. Menyiapkan agen untuk evaluasi
Setelah menentukan agen BigQuery, Anda harus membuatnya dapat dijalankan untuk evaluasi.
Kode di bawah menentukan fungsi, run_conversation, yang menangani alur percakapan dengan membuat agen, menjalankan sesi, dan memproses peristiwa untuk mengambil respons akhir.
- Kembali ke Cloud Editor dan buat file baru bernama
run_agent.pydi direktori bigquery-adk-codelab, lalu salin/tempel kode di bawah:
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
Kode di bawah menentukan fungsi utilitas untuk memanggil fungsi yang dapat dijalankan ini dan menampilkan hasilnya. Tautan ini juga mencakup fungsi bantuan yang mencetak dan menyimpan hasil evaluasi:
- Buat file baru bernama
utils.pydi direktori bigquery-adk-codelab dan Salin/tempel kode ini ke file utils.py:
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. Membuat set data evaluasi
Untuk mengevaluasi agen, Anda perlu membuat set data evaluasi, menentukan metrik evaluasi, dan menjalankan tugas evaluasi.
Set data evaluasi berisi daftar pertanyaan (perintah) dan jawaban benar yang sesuai (referensi). Layanan evaluasi akan menggunakan pasangan ini untuk membandingkan respons agen Anda dan menentukan apakah respons tersebut akurat.
- Buat file baru bernama evaluation_dataset.json di direktori bigquery-adk-codelab, lalu salin/tempel set data evaluasi di bawah:
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. Tentukan metrik evaluasi Anda
Sekarang kita akan menggunakan dua metrik kustom untuk menilai kemampuan agen dalam menjawab pertanyaan terkait data BigQuery Anda, yang masing-masing memberikan skor dari 1 hingga 5:
- Metrik Akurasi Faktual: Metrik ini menilai apakah semua data dan fakta yang disajikan dalam respons akurat dan benar jika dibandingkan dengan kebenaran dasar.
- Metrik Kelengkapan: Metrik ini mengukur apakah respons menyertakan semua informasi penting yang diminta oleh pengguna dan ada dalam jawaban yang benar, tanpa ada kelalaian penting.
- Terakhir, buat file baru bernama
evaluate_agent.pydi direktori bigquery-adk-codelab dan salin/tempel kode definisi metrik ke dalam file evaluate_agent.py:
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
Saya juga menyertakan metrik TrajectorySingleToolUse untuk evaluasi lintasan. Jika metrik ini ada, panggilan alat agen (termasuk SQL mentah yang dibuat dan dijalankan terhadap BigQuery) akan disertakan dalam respons evaluasi, sehingga memungkinkan pemeriksaan mendetail.
Metrik TrajectorySingleToolUse menentukan apakah agen telah menggunakan alat tertentu. Dalam hal ini, saya memilih list_table_ids, karena kita berharap alat ini dipanggil untuk setiap pertanyaan dalam set data evaluasi. Tidak seperti metrik lintasan lainnya, metrik ini tidak mengharuskan Anda menentukan semua panggilan alat dan argumen yang diharapkan untuk setiap pertanyaan dalam set data evaluasi.
10. Buat tugas evaluasi Anda
EvalTask menggunakan set data evaluasi dan metrik kustom, lalu menyiapkan eksperimen evaluasi baru.
Fungsi ini, run_eval, adalah mesin utama untuk evaluasi. Proses ini melakukan iterasi melalui EvalTask, menjalankan agen Anda pada setiap pertanyaan dalam set data. Untuk setiap pertanyaan, agen akan merekam responsnya, lalu menggunakan metrik yang Anda tentukan sebelumnya untuk menilai respons tersebut.
Salin/tempel kode berikut di bagian bawah file evaluate_agent.py:
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
Hasilnya diringkas dan disimpan ke file JSON.
11. Jalankan evaluasi Anda
Setelah agen, metrik evaluasi, dan set data evaluasi siap, Anda dapat menjalankan evaluasi.
Kembali ke Cloud Shell, pastikan Anda berada di direktori bigquery-adk-codelab dan jalankan skrip evaluasi menggunakan perintah berikut:
python evaluate_agent.py
Anda akan melihat output yang mirip dengan ini saat evaluasi berlangsung:
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
Jika Anda mengalami error seperti di bawah, artinya agen tidak memanggil alat apa pun untuk menjalankan tertentu; Anda dapat memeriksa perilaku agen lebih lanjut pada langkah berikutnya.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
Menafsirkan Hasil:
Buka folder eval_results di direktori data_agent_app, lalu buka file hasil evaluasi bernama bq_agent_eval_results_*.json:
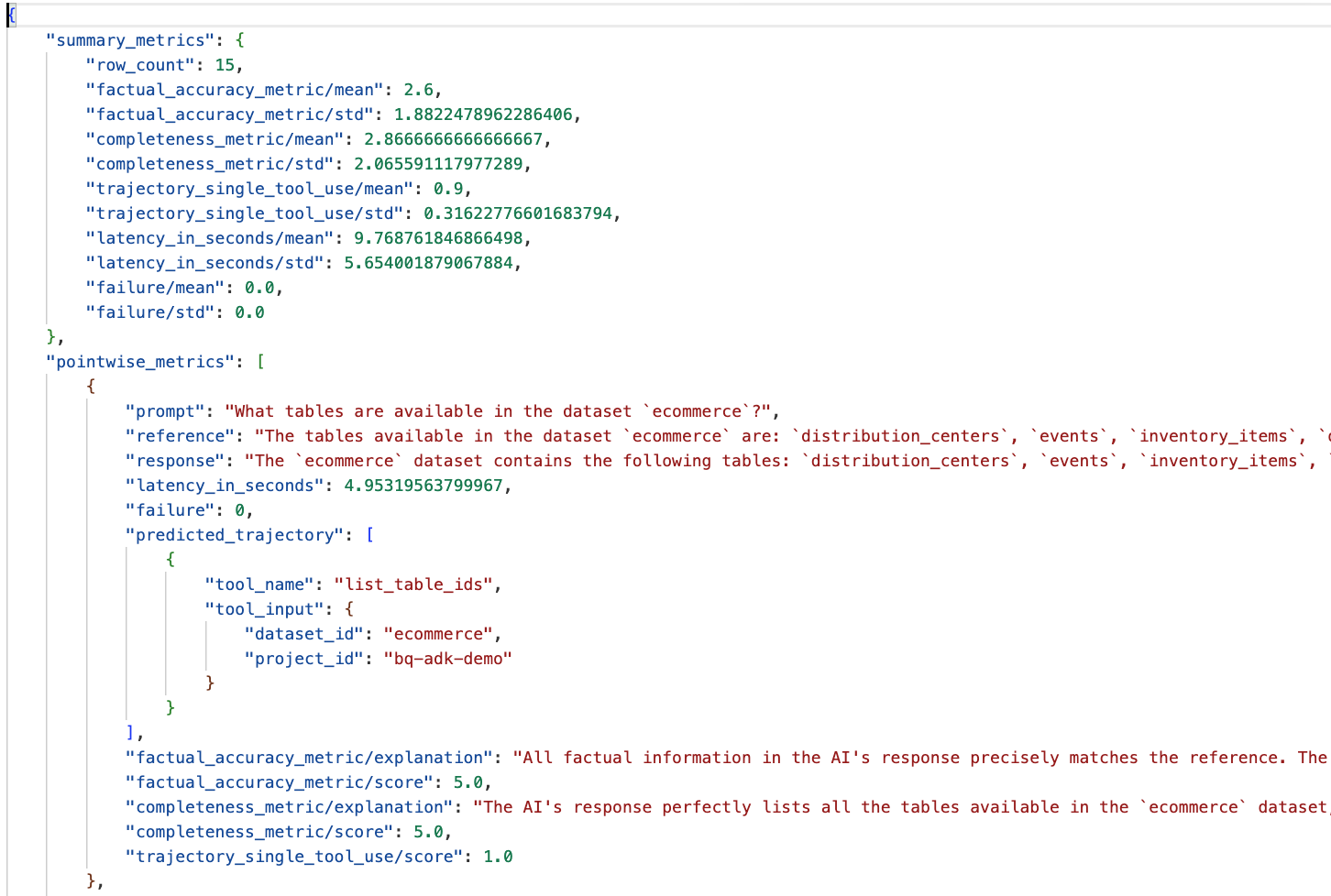
- Metrik Ringkasan: Memberikan tampilan gabungan performa agen Anda di seluruh set data.
- Metrik Per Titik Akurasi dan Kelengkapan Fakta: Skor yang lebih mendekati 5 menunjukkan akurasi dan kelengkapan yang lebih tinggi. Akan ada skor untuk setiap pertanyaan, beserta penjelasan tertulis tentang alasan pertanyaan tersebut mendapatkan skor tersebut.
- Lintasan yang Diprediksi: Ini adalah daftar panggilan alat yang digunakan oleh agen untuk mencapai respons akhir. Dengan begitu, kita dapat melihat kueri SQL yang dihasilkan oleh agen.
Kita dapat melihat bahwa skor rata-rata untuk kelengkapan dan akurasi faktual adalah 2,87 dan 2,6.
Hasilnya tidak terlalu bagus. Mari kita coba meningkatkan kemampuan agen kita dalam menjawab pertanyaan.
12. Meningkatkan hasil evaluasi agen Anda
Buka agent.py di direktori bigquery-adk-codelab, lalu perbarui model dan petunjuk sistem agen. Jangan lupa untuk mengganti <YOUR_PROJECT_ID> dengan project ID Anda:
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
Sekarang kembali ke terminal dan jalankan kembali evaluasi:
python evaluate_agent.py
Anda akan melihat bahwa hasilnya kini jauh lebih baik:
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
Mengevaluasi agen Anda adalah proses iteratif. Untuk lebih meningkatkan hasil evaluasi, Anda dapat menyesuaikan petunjuk sistem, parameter model, atau bahkan metadata di BigQuery. Lihat tips dan trik ini untuk mendapatkan ide lainnya.
13. Pembersihan
Agar tidak menimbulkan biaya berkelanjutan pada akun Google Cloud Anda, penting untuk menghapus resource yang kita buat selama workshop ini.
Jika Anda membuat set data atau tabel BigQuery tertentu untuk codelab ini (misalnya, set data e-commerce), Anda mungkin ingin menghapusnya:
bq rm -r $PROJECT_ID:ecommerce
Untuk menghapus direktori bigquery-adk-codelab dan isinya:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. Selamat
Selamat! Anda telah berhasil membangun dan mengevaluasi agen BigQuery menggunakan Agent Development Kit (ADK). Sekarang Anda memahami cara menyiapkan agen ADK dengan alat BigQuery dan mengukur performanya menggunakan metrik evaluasi kustom.