
1. はじめに
この Codelab では、Agent Development Kit(ADK)を使用して、BigQuery に保存されているデータに関する質問に回答できるエージェントを構築する方法を学びます。また、Vertex AI の Gen AI Evaluation Service を使用して、これらのエージェントを評価します。
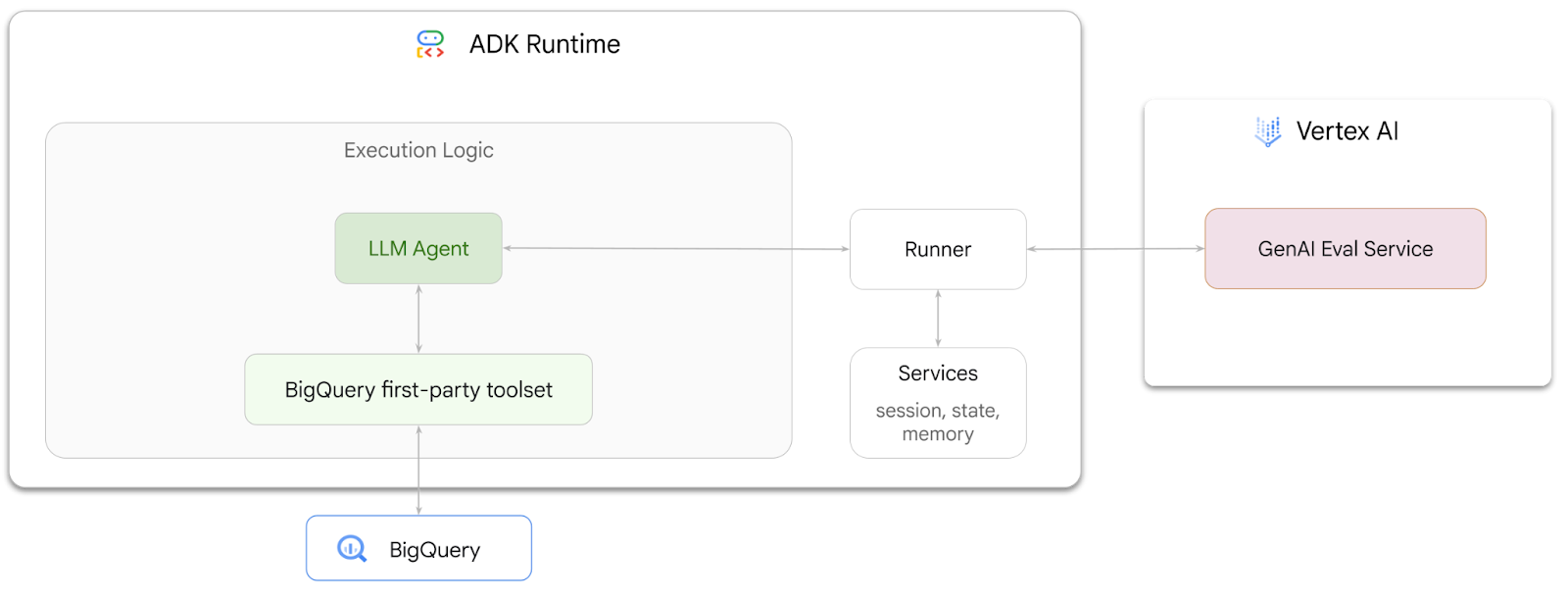
演習内容
- ADK で会話型分析エージェントを構築する
- このエージェントに ADK の BigQuery 用ファーストパーティ ツールセットを装備して、BigQuery に保存されているデータを操作できるようにします。
- Vertex AI GenAI Evaluation Service を使用して、エージェントの評価フレームワークを作成する
- 一連の正解レスポンスに対してこのエージェントの評価を実行する
必要なもの
- ウェブブラウザ(Chrome など)
- 課金が有効になっている Google Cloud プロジェクト
- Gmail アカウント。次のセクションでは、この Codelab で使用できる 5 ドルの無料クレジットを利用して、新しいプロジェクトを設定する方法について説明します。
この Codelab は、初心者を含むあらゆるレベルのデベロッパーを対象としています。ADK 開発には、Google Cloud Shell のコマンドライン インターフェースと Python コードを使用します。Python の専門家である必要はありませんが、コードの読み取り方法に関する基本的な知識があると、コンセプトを理解するのに役立ちます。
2. 始める前に
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト選択ページで、クラウド プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Cloud Shell は、必要なツールがプリロードされた Google Cloud で動作するコマンドライン環境です。
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。

- Cloud Shell に接続したら、次のコマンドを実行して Cloud Shell で認証を確認します。
gcloud auth list
- 次のコマンドを実行して、プロジェクトが gcloud で使用するように構成されていることを確認します。
gcloud config list project
- 次のコマンドを使用して、プロジェクトを設定します。
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
API を有効にする
- 次のコマンドを実行して、必要なすべての API とサービスを有効にします。
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- コマンドが正常に実行されると、次のようなメッセージが表示されます。
Operation "operations/..." finished successfully.
3. BigQuery データセットを作成する
- Cloud Shell で次のコマンドを実行して、BigQuery に ecommerce という新しいデータセットを作成します。
bq mk --dataset --location=US ecommerce
BigQuery 一般公開データセット thelook_ecommerce の静的サブセットは、一般公開の Google Cloud Storage バケットに AVRO ファイルとして保存されます。
- Cloud Shell で次のコマンドを実行して、これらの Avro ファイルを BigQuery にテーブル(events、order_items、products、users、orders)として読み込みます。
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
この処理には数分かかる場合があります。
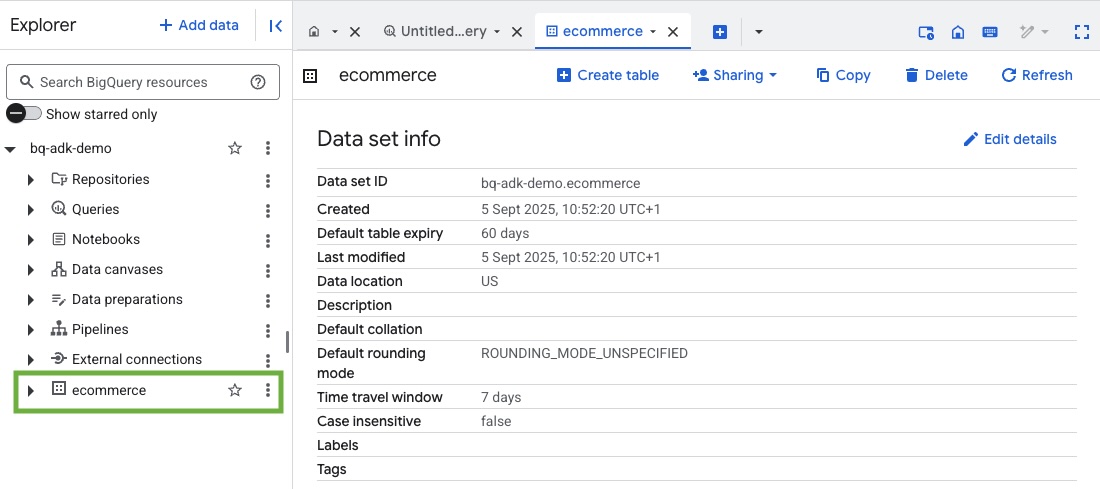
- Google Cloud プロジェクトの BigQuery コンソールにアクセスして、データセットとテーブルが作成されていることを確認します。
4. ADK エージェントの環境を準備する
Cloud Shell に戻り、ホーム ディレクトリにいることを確認します。仮想 Python 環境を作成し、必要なパッケージをインストールします。
- Cloud Shell で新しいターミナルタブを開き、次のコマンドを実行して bigquery-adk-codelab という名前のフォルダを作成して移動します。
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- 仮想 Python 環境を作成します。
python -m venv .venv
- 仮想環境をアクティブにします。
source .venv/bin/activate
- Google の ADK と AI-Platform Python パッケージをインストールします。bigquery エージェントを評価するには、AI プラットフォームと pandas パッケージが必要です。
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. ADK アプリケーションを作成する
では、BigQuery エージェントを作成しましょう。このエージェントは、BigQuery に保存されているデータに関する自然言語の質問に回答するように設計されます。
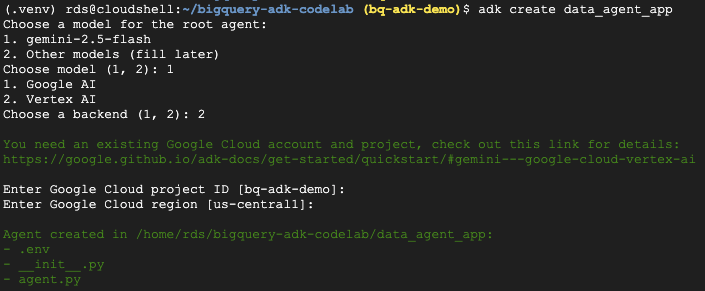
- ADK 作成ユーティリティ コマンドを実行して、必要なフォルダとファイルを含む新しいエージェント アプリケーションをスキャフォールディングします。
adk create data_agent_app
画面上の指示に沿って操作します。
- モデルとして gemini-2.5-flash を選択します。
- バックエンドに Vertex AI を選択します。
- デフォルトの Google Cloud プロジェクト ID とリージョンを確認します。
以下にやり取りの例を示します。
- Cloud Shell で [エディタを開く] ボタンをクリックして Cloud Shell エディタを開き、新しく作成したフォルダとファイルを表示します。

生成されたファイルを確認します。
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: フォルダを Python モジュールとしてマークします。
- agent.py: 初期エージェントの定義が含まれています。
- .env: プロジェクトの環境変数を含みます(このファイルを表示するには、[View] > [Toggle Hidden Files] をクリックする必要がある場合があります)。
プロンプトで正しく設定されなかった変数を更新します。
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. エージェントを定義し、BigQuery ツールセットを割り当てる
BigQuery ツールセットを使用して BigQuery とやり取りする ADK エージェントを定義するには、agent.py ファイルの既存のコンテンツを次のコードに置き換えます。
エージェントの手順でプロジェクト ID を実際のプロジェクト ID に更新する必要があります。
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
BigQuery ツールセットは、BigQuery データでメタデータを取得し、SQL クエリを実行する機能をエージェントに提供します。ツールセットを使用するには、認証を行う必要があります。最も一般的なオプションは、開発用のアプリケーションのデフォルト認証情報(ADC)、エージェントが特定のユーザーの代わりに行動する必要がある場合のインタラクティブ OAuth、安全な本番環境レベルの認証用のサービス アカウント認証情報です。
ここから、Cloud Shell に戻って次のコマンドを実行すると、エージェントとチャットできます。
adk web
ウェブサーバーが起動したことを示す通知が表示されます。
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
提供された URL をクリックして adk web を起動します。データセットについてエージェントに質問できます。
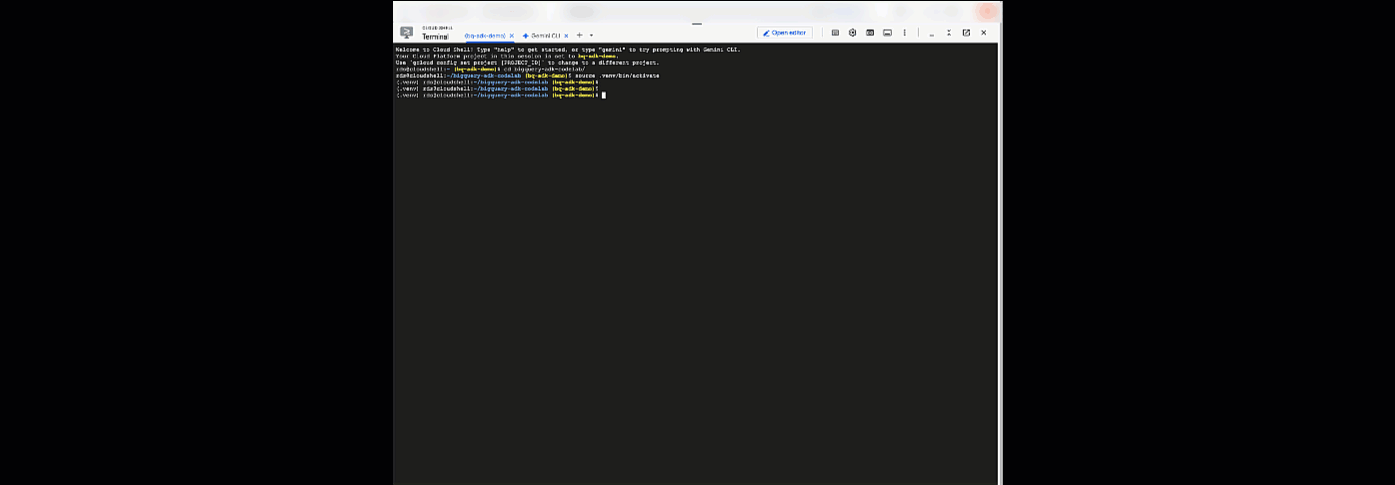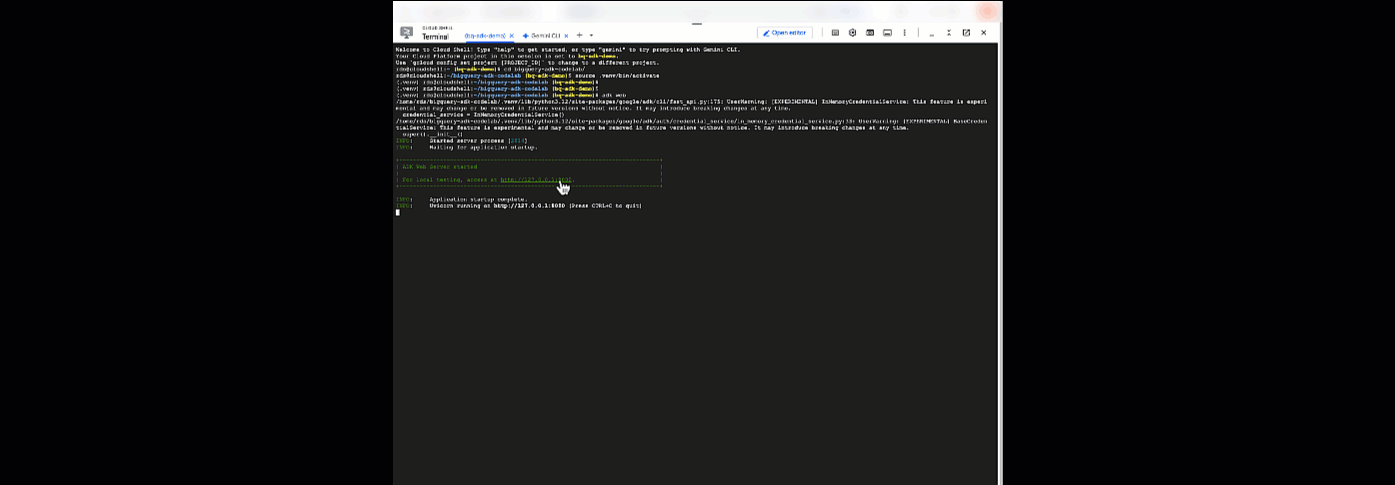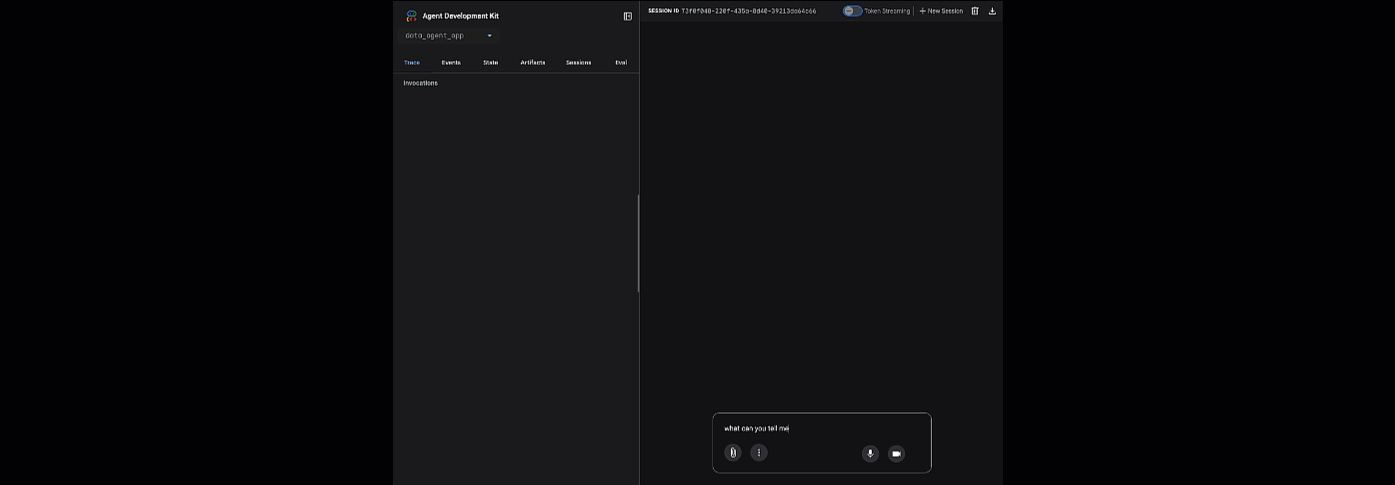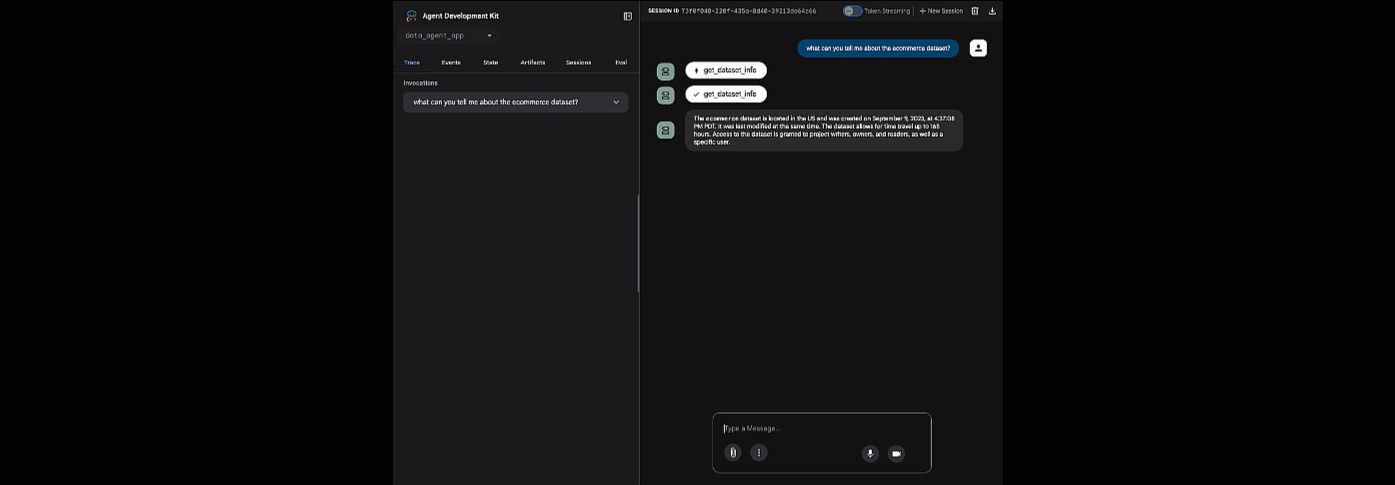
adk web を閉じ、ターミナルで Ctrl+C キーを押してウェブサーバーをシャットダウンします。
7. 評価用にエージェントを準備する
BigQuery エージェントを定義したら、評価用に実行可能にする必要があります。
次のコードは、エージェントの作成、セッションの実行、イベントの処理を行って最終的なレスポンスを取得することで、会話フローを処理する関数 run_conversation を定義します。
- Cloud エディタに戻り、bigquery-adk-codelab ディレクトリに
run_agent.pyという名前の新しいファイルを作成して、次のコードをコピーして貼り付けます。
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
次のコードは、この実行可能関数を呼び出して結果を返すユーティリティ関数を定義します。また、評価結果を出力して保存するヘルパー関数も含まれています。
- bigquery-adk-codelab ディレクトリに
utils.pyという名前の新しいファイルを作成し、次のコードを utils.py ファイルにコピーして貼り付けます。
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. 評価データセットを作成する
エージェントを評価するには、評価データセットを作成し、評価指標を定義し、評価タスクを実行する必要があります。
評価データセットには、質問(プロンプト)とその正解(リファレンス)のリストが含まれています。評価サービスは、これらのペアを使用してエージェントのレスポンスを比較し、正確かどうかを判断します。
- bigquery-adk-codelab ディレクトリに evaluation_dataset.json という名前の新しいファイルを作成し、次の評価データセットをコピーして貼り付けます。
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. 評価指標を定義する
次に、2 つのカスタム指標を使用して、BigQuery データに関連する質問に回答するエージェントの能力を評価します。どちらの指標も 1 ~ 5 のスコアを提供します。
- 事実の正確性指標: 回答で提示されたすべてのデータと事実が、グラウンド トゥルースと比較して正確かつ正しいかどうかを評価します。
- 完全性指標: 回答に、ユーザーがリクエストした重要な情報がすべて含まれており、正解に存在する情報がすべて含まれているかどうかを測定します。重要な情報が欠落していないかどうかも測定します。
- 最後に、bigquery-adk-codelab ディレクトリに
evaluate_agent.pyという名前の新しいファイルを作成し、指標定義コードを evaluate_agent.py ファイルにコピーして貼り付けます。
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
また、軌跡の評価のために TrajectorySingleToolUse 指標も追加しました。これらの指標が存在する場合、エージェント ツールの呼び出し(BigQuery に対して生成して実行する未加工の SQL を含む)が評価レスポンスに含まれ、詳細な検査が可能になります。
TrajectorySingleToolUse 指標は、エージェントが特定のツールを使用したかどうかを判断します。この場合、このツールは評価データセットのすべての質問に対して呼び出されることが想定されるため、list_table_ids を選択しました。他の軌跡指標とは異なり、この指標では、評価データセットの各質問に対して、想定されるすべてのツール呼び出しと引数を指定する必要はありません。
10. 評価タスクを作成する
EvalTask は、評価データセットとカスタム指標を取得し、新しい評価テストを設定します。
この関数 run_eval は、評価のメインエンジンです。EvalTask をループ処理し、データセット内の各質問に対してエージェントを実行します。質問ごとに、エージェントの回答を記録し、事前に定義した指標を使用して採点します。
次のコードをコピーして evaluate_agent.py ファイルの末尾に貼り付けます。
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
結果は要約され、JSON ファイルに保存されます。
11. 評価を実行する
エージェント、評価指標、評価データセットの準備が整ったら、評価を実行できます。
Cloud Shell に戻り、bigquery-adk-codelab ディレクトリに移動して、次のコマンドで評価スクリプトを実行します。
python evaluate_agent.py
評価の進行状況に応じて、次のような出力が表示されます。
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
次のようなエラーが発生した場合は、特定実行でエージェントがツールを呼び出さなかったことを意味します。次のステップでエージェントの動作をさらに詳しく調べることができます。
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
結果の解釈:
data_agent_app ディレクトリの eval_results フォルダに移動し、bq_agent_eval_results_*.json という名前の評価結果ファイルを開きます。
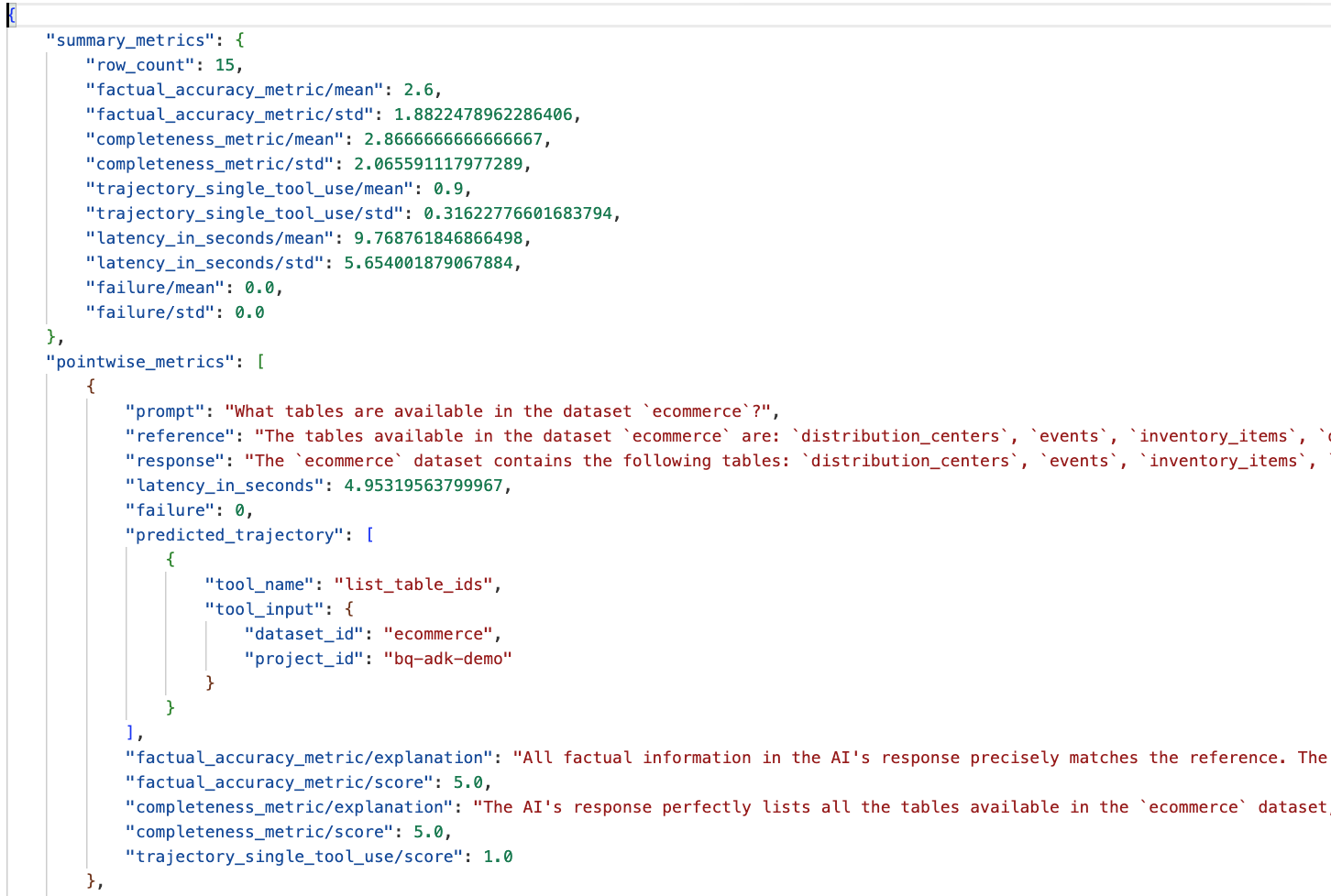
- 概要指標: データセット全体でのエージェントのパフォーマンスの集計ビューを提供します。
- 事実の正確性と完全性に関するポイントワイズ指標: スコアが 5 に近いほど、正確性と完全性が高いことを示します。各質問にはスコアが表示され、そのスコアが付いた理由が説明として記載されます。
- 予測軌跡: エージェントが最終回答に到達するために使用したツール呼び出しのリストです。これにより、エージェントによって生成された SQL クエリを確認できます。
平均的な完全性と事実の正確さの平均スコアは、それぞれ 2.87 と 2.6 です。
結果はあまり良くありません。エージェントが質問に答えられるように改善してみましょう。
12. エージェントの評価結果を改善する
bigquery-adk-codelab ディレクトリの agent.py に移動し、エージェントのモデルとシステム指示を更新します。<YOUR_PROJECT_ID> は実際のプロジェクト ID に置き換えてください。
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
ターミナルに戻り、評価を再実行します。
python evaluate_agent.py
結果が大幅に改善されていることがわかります。
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
エージェントの評価は反復的なプロセスです。評価結果をさらに改善するには、システム指示、モデル パラメータ、さらには BigQuery のメタデータを調整できます。ヒントとコツで、その他のアイデアをご確認ください。
13. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、このワークショップで作成したリソースを削除することが重要です。
この Codelab 用に特定の BigQuery データセットまたはテーブル(e コマース データセットなど)を作成した場合は、それらを削除することをおすすめします。
bq rm -r $PROJECT_ID:ecommerce
bigquery-adk-codelab ディレクトリとその内容を削除するには:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. 完了
おめでとうございます!Agent Development Kit(ADK)を使用して BigQuery エージェントを正常に構築し、評価しました。これで、BigQuery ツールを使用して ADK エージェントを設定し、カスタム評価指標を使用してパフォーマンスを測定する方法を理解できました。