
1. 소개
이 Codelab에서는 에이전트 개발 키트 (ADK)를 사용하여 BigQuery에 저장된 데이터에 대한 질문에 답할 수 있는 에이전트를 빌드하는 방법을 알아봅니다. 또한 Vertex AI의 Gen AI Evaluation Service를 사용하여 이러한 에이전트를 평가합니다.
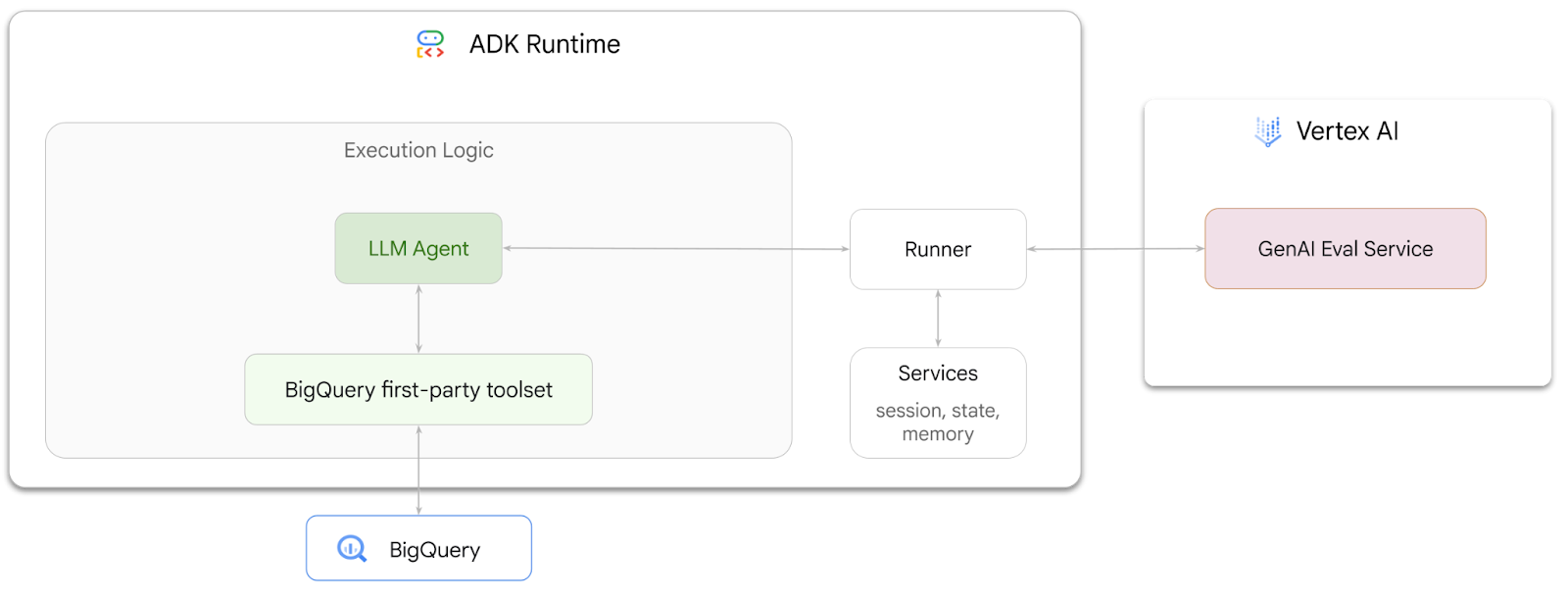
실행할 작업
- ADK에서 대화형 분석 에이전트 빌드
- 이 에이전트가 BigQuery에 저장된 데이터와 상호작용할 수 있도록 ADK의 BigQuery용 퍼스트 파티 도구 세트를 장착합니다.
- Vertex AI GenAI Evaluation Service를 사용하여 에이전트의 평가 프레임워크 만들기
- 이 에이전트에 대해 골든 응답 세트를 기준으로 평가를 실행합니다.
필요한 항목
- 웹브라우저(예: Chrome)
- 결제가 사용 설정된 Google Cloud 프로젝트
- Gmail 계정 다음 섹션에서는 이 Codelab에서 사용할 수 있는 무료 $5 크레딧을 사용하고 새 프로젝트를 설정하는 방법을 보여줍니다.
이 Codelab은 초보자를 포함한 모든 수준의 개발자를 대상으로 합니다. Google Cloud Shell의 명령줄 인터페이스와 ADK 개발용 Python 코드를 사용합니다. Python 전문가가 아니어도 되지만 코드를 읽는 방법을 기본적으로 이해하면 개념을 이해하는 데 도움이 됩니다.
2. 시작하기 전에
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell 시작
Cloud Shell은 Google Cloud에서 실행되는 명령줄 환경으로, 필요한 도구가 미리 로드되어 제공됩니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 실행하여 Cloud Shell에서 인증을 확인합니다.
gcloud auth list
- 다음 명령어를 실행하여 프로젝트가 gcloud와 함께 사용하도록 구성되어 있는지 확인합니다.
gcloud config list project
- 다음 명령어를 사용하여 프로젝트를 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
API 사용 설정
- 다음 명령어를 실행하여 필요한 모든 API와 서비스를 사용 설정합니다.
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- 명령어가 성공적으로 실행되면 아래와 유사한 메시지가 표시됩니다.
Operation "operations/..." finished successfully.
3. BigQuery 데이터 세트 만들기
- Cloud Shell에서 다음 명령어를 실행하여 BigQuery에 ecommerce라는 새 데이터 세트를 만듭니다.
bq mk --dataset --location=US ecommerce
BigQuery 공개 데이터 세트 thelook_ecommerce의 정적 하위 집합이 공개 Google Cloud Storage 버킷에 AVRO 파일로 저장됩니다.
- Cloud Shell에서 다음 명령어를 실행하여 이러한 Avro 파일을 BigQuery에 테이블 (events, order_items, products, users, orders)로 로드합니다.
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
이 과정은 몇 분 정도 걸릴 수 있습니다.
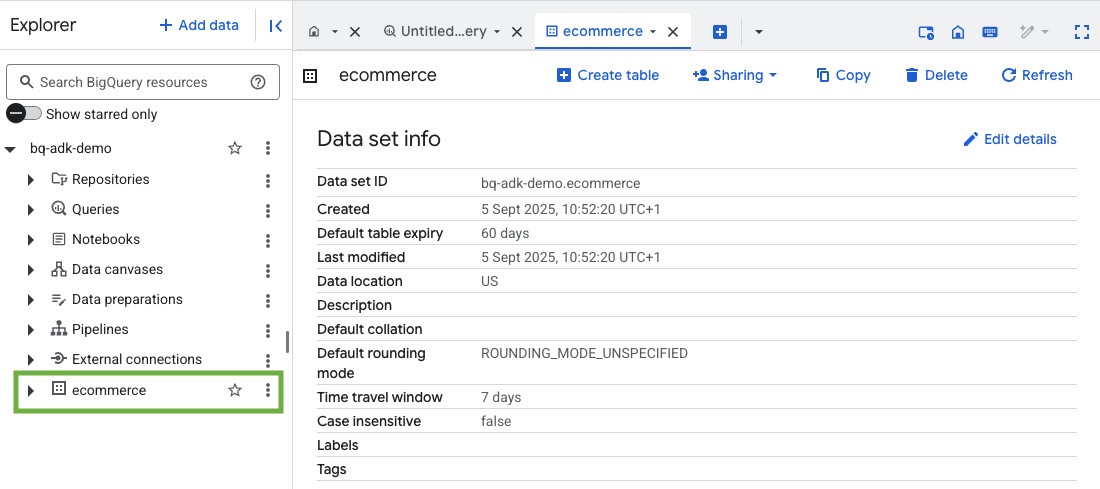
- Google Cloud 프로젝트에서 BigQuery 콘솔을 방문하여 데이터 세트와 테이블이 생성되었는지 확인합니다.
4. ADK 에이전트 환경 준비
Cloud Shell로 돌아가 홈 디렉터리에 있는지 확인합니다. 가상 Python 환경을 만들고 필요한 패키지를 설치합니다.
- Cloud Shell에서 새 터미널 탭을 열고 다음 명령어를 실행하여 bigquery-adk-codelab이라는 폴더를 만들고 해당 폴더로 이동합니다.
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- 가상 Python 환경을 만듭니다.
python -m venv .venv
- 가상 환경을 활성화합니다.
source .venv/bin/activate
- Google의 ADK 및 AI-Platform Python 패키지를 설치합니다. BigQuery 에이전트를 평가하려면 AI 플랫폼과 pandas 패키지가 필요합니다.
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. ADK 애플리케이션 만들기
이제 BigQuery 에이전트를 만들어 보겠습니다. 이 에이전트는 BigQuery에 저장된 데이터에 대한 자연어 질문에 답변하도록 설계됩니다.
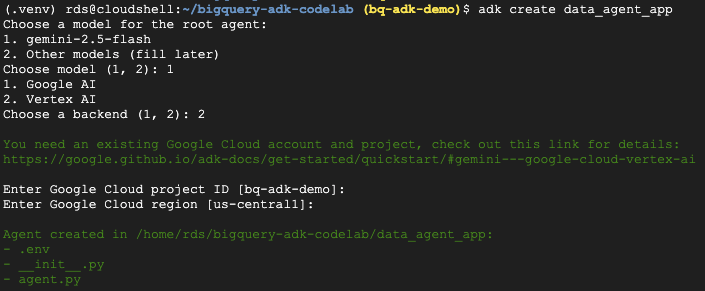
- adk create 유틸리티 명령어를 실행하여 필요한 폴더와 파일이 포함된 새 에이전트 애플리케이션을 스캐폴딩합니다.
adk create data_agent_app
표시되는 메시지에 따라 다음 작업을 진행합니다.
- 모델로 gemini-2.5-flash를 선택합니다.
- 백엔드로 Vertex AI를 선택합니다.
- 기본 Google Cloud 프로젝트 ID와 리전을 확인합니다.
샘플 상호작용은 아래와 같습니다.
- Cloud Shell에서 편집기 열기 버튼을 클릭하여 Cloud Shell 편집기를 열고 새로 만든 폴더와 파일을 확인합니다.

생성된 파일을 확인합니다.
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: 폴더를 Python 모듈로 표시합니다.
- agent.py: 초기 에이전트 정의가 포함되어 있습니다.
- .env: 프로젝트의 환경 변수를 포함합니다. 이 파일을 보려면 보기 > 숨은 파일 전환을 클릭해야 할 수도 있습니다.
프롬프트에서 올바르게 설정되지 않은 변수를 업데이트합니다.
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. 에이전트를 정의하고 BigQuery 도구 세트를 할당합니다.
BigQuery 도구 모음을 사용하여 BigQuery와 상호작용하는 ADK 에이전트를 정의하려면 agent.py 파일의 기존 콘텐츠를 다음 코드로 바꿉니다.
에이전트의 안내에 있는 프로젝트 ID를 실제 프로젝트 ID로 업데이트해야 합니다.
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
BigQuery 도구 모음은 에이전트에게 메타데이터를 가져오고 BigQuery 데이터에 대해 SQL 쿼리를 실행하는 기능을 제공합니다. 툴셋을 사용하려면 인증해야 하며, 가장 일반적인 옵션은 개발용 애플리케이션 기본 사용자 인증 정보 (ADC), 에이전트가 특정 사용자를 대신하여 작업을 실행해야 하는 경우의 대화형 OAuth, 안전한 프로덕션 수준 인증을 위한 서비스 계정 사용자 인증 정보입니다.
여기에서 Cloud Shell로 돌아가 다음 명령어를 실행하여 상담사와 채팅할 수 있습니다.
adk web
웹 서버가 시작되었다는 알림이 표시됩니다.
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
제공된 URL을 클릭하여 adk 웹을 실행합니다. 에이전트에게 데이터 세트에 관한 질문을 할 수 있습니다.
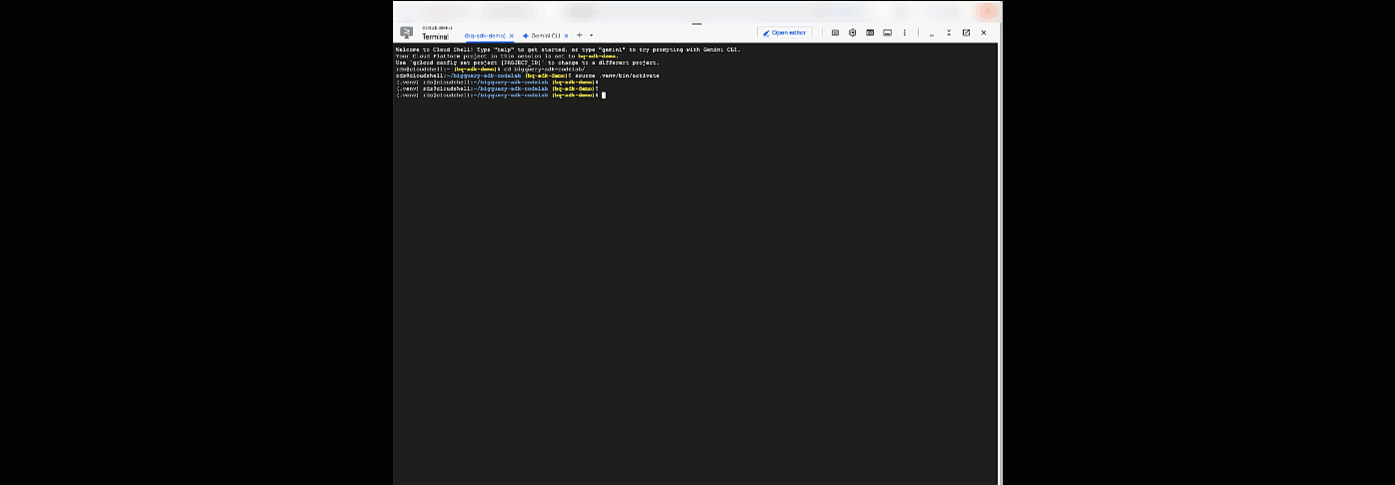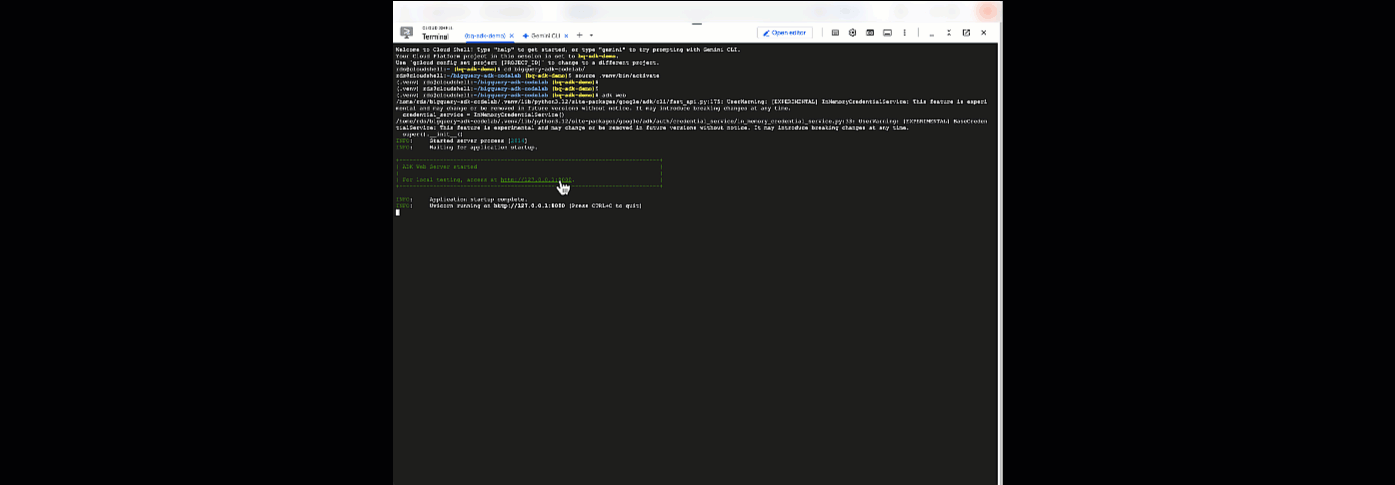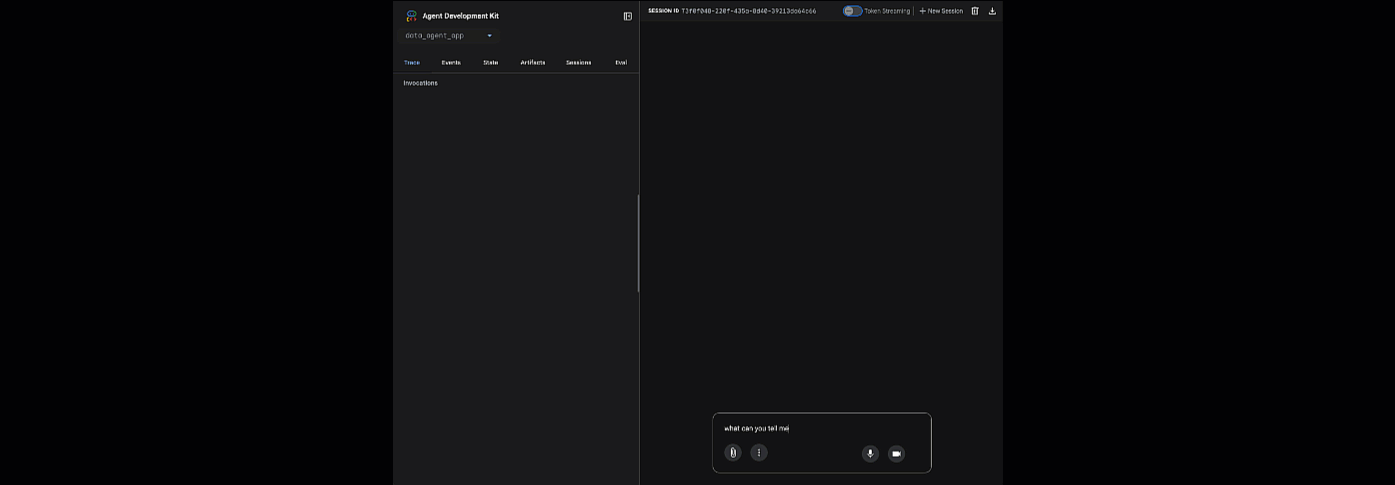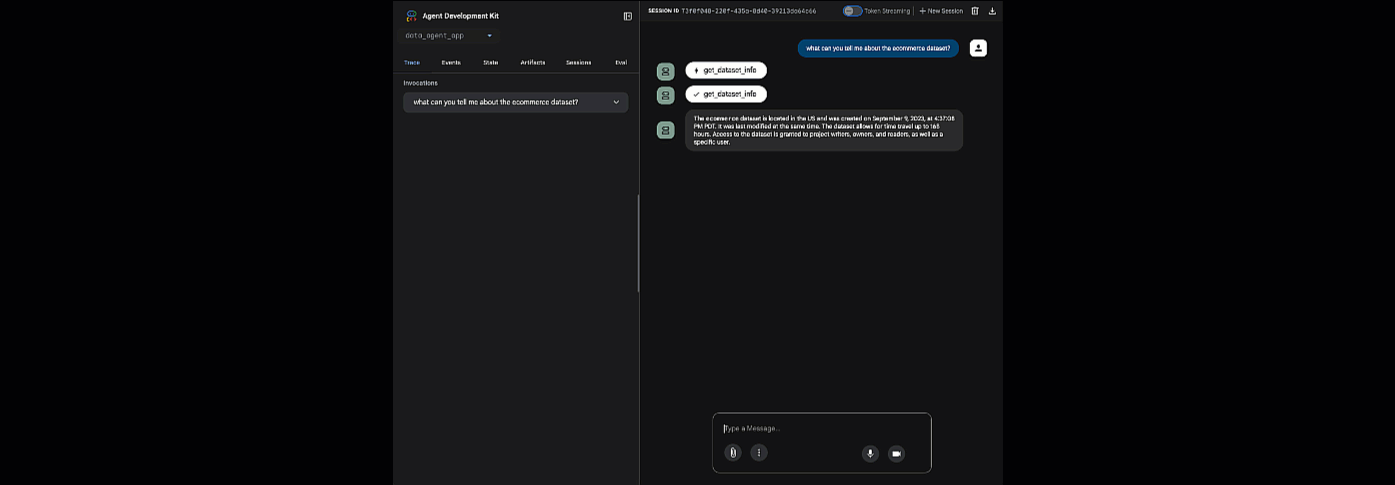
adk 웹을 닫고 터미널에서 Ctrl + C를 눌러 웹 서버를 종료합니다.
7. 평가를 위해 상담사 준비
이제 BigQuery 에이전트를 정의했으므로 평가를 위해 실행 가능하도록 만들어야 합니다.
아래 코드는 에이전트를 만들고, 세션을 실행하고, 이벤트를 처리하여 최종 응답을 가져옴으로써 대화 흐름을 처리하는 함수 run_conversation를 정의합니다.
- Cloud Editor로 다시 이동하여 bigquery-adk-codelab 디렉터리에
run_agent.py이라는 새 파일을 만들고 아래 코드를 복사하여 붙여넣습니다.
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
아래 코드는 이 실행 가능한 함수를 호출하고 결과를 반환하는 유틸리티 함수를 정의합니다. 또한 평가 결과를 출력하고 저장하는 도우미 함수도 포함되어 있습니다.
- bigquery-adk-codelab 디렉터리에
utils.py라는 새 파일을 만들고 이 코드를 utils.py 파일에 복사하여 붙여넣습니다.
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. 평가 데이터 세트 만들기
에이전트를 평가하려면 평가 데이터 세트를 만들고, 평가 측정항목을 정의하고, 평가 작업을 실행해야 합니다.
평가 데이터 세트에는 질문 (프롬프트)과 이에 상응하는 정답 (참조) 목록이 포함됩니다. 평가 서비스는 이러한 쌍을 사용하여 에이전트의 대답을 비교하고 정확한지 확인합니다.
- bigquery-adk-codelab 디렉터리에 evaluation_dataset.json이라는 새 파일을 만들고 아래 평가 데이터 세트를 복사하여 붙여넣습니다.
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. 평가 측정항목 정의
이제 두 가지 맞춤 측정항목을 사용하여 에이전트가 BigQuery 데이터와 관련된 질문에 답변하는 능력을 평가합니다. 두 측정항목 모두 1~5점의 점수를 제공합니다.
- 사실성 정확도 측정항목: 대답에 제시된 모든 데이터와 사실이 정답과 비교했을 때 정확하고 올바른지 평가합니다.
- 완전성 측정항목: 대답에 사용자가 요청하고 정답에 있는 모든 주요 정보가 중요한 누락 없이 포함되어 있는지 측정합니다.
- 마지막으로 bigquery-adk-codelab 디렉터리에
evaluate_agent.py라는 새 파일을 만들고 측정항목 정의 코드를 evaluate_agent.py 파일에 복사하여 붙여넣습니다.
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
실행 궤적 평가를 위한 TrajectorySingleToolUse 측정항목도 포함했습니다. 이러한 측정항목이 있으면 상담사 도구 호출 (BigQuery에 대해 생성되고 실행되는 원시 SQL 포함)이 평가 응답에 포함되어 자세히 검사할 수 있습니다.
TrajectorySingleToolUse 측정항목은 에이전트가 특정 도구를 사용했는지 여부를 확인합니다. 이 경우 평가 데이터 세트의 모든 질문에 대해 이 도구가 호출될 것으로 예상되므로 list_table_ids를 선택했습니다. 다른 궤적 측정항목과 달리 이 측정항목은 평가 데이터 세트의 각 질문에 대해 예상되는 모든 도구 호출과 인수를 지정하지 않아도 됩니다.
10. 평가 작업 만들기
EvalTask는 평가 데이터 세트와 맞춤 측정항목을 가져와 새 평가 실험을 설정합니다.
run_eval 함수는 평가의 기본 엔진입니다. EvalTask를 통해 루프를 실행하여 데이터 세트의 각 질문에 대해 에이전트를 실행합니다. 각 질문에 대해 상담사의 응답을 기록한 다음 이전에 정의한 측정항목을 사용하여 평가합니다.
evaluate_agent.py 파일 하단에 다음 코드를 복사하여 붙여넣습니다.
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
결과가 요약되어 JSON 파일에 저장됩니다.
11. 평가 실행
이제 에이전트, 평가 측정항목, 평가 데이터 세트가 준비되었으므로 평가를 실행할 수 있습니다.
Cloud Shell로 돌아가 bigquery-adk-codelab 디렉터리에 있는지 확인하고 다음 명령어를 사용하여 평가 스크립트를 실행합니다.
python evaluate_agent.py
평가가 진행되면 다음과 비슷한 출력이 표시됩니다.
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
아래와 같은 오류가 발생하면 특정 실행에서 에이전트가 도구를 호출하지 않은 것입니다. 다음 단계에서 에이전트 동작을 자세히 검사할 수 있습니다.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
결과 해석:
data_agent_app 디렉터리의 eval_results 폴더로 이동하여 bq_agent_eval_results_*.json라는 평가 결과 파일을 엽니다.
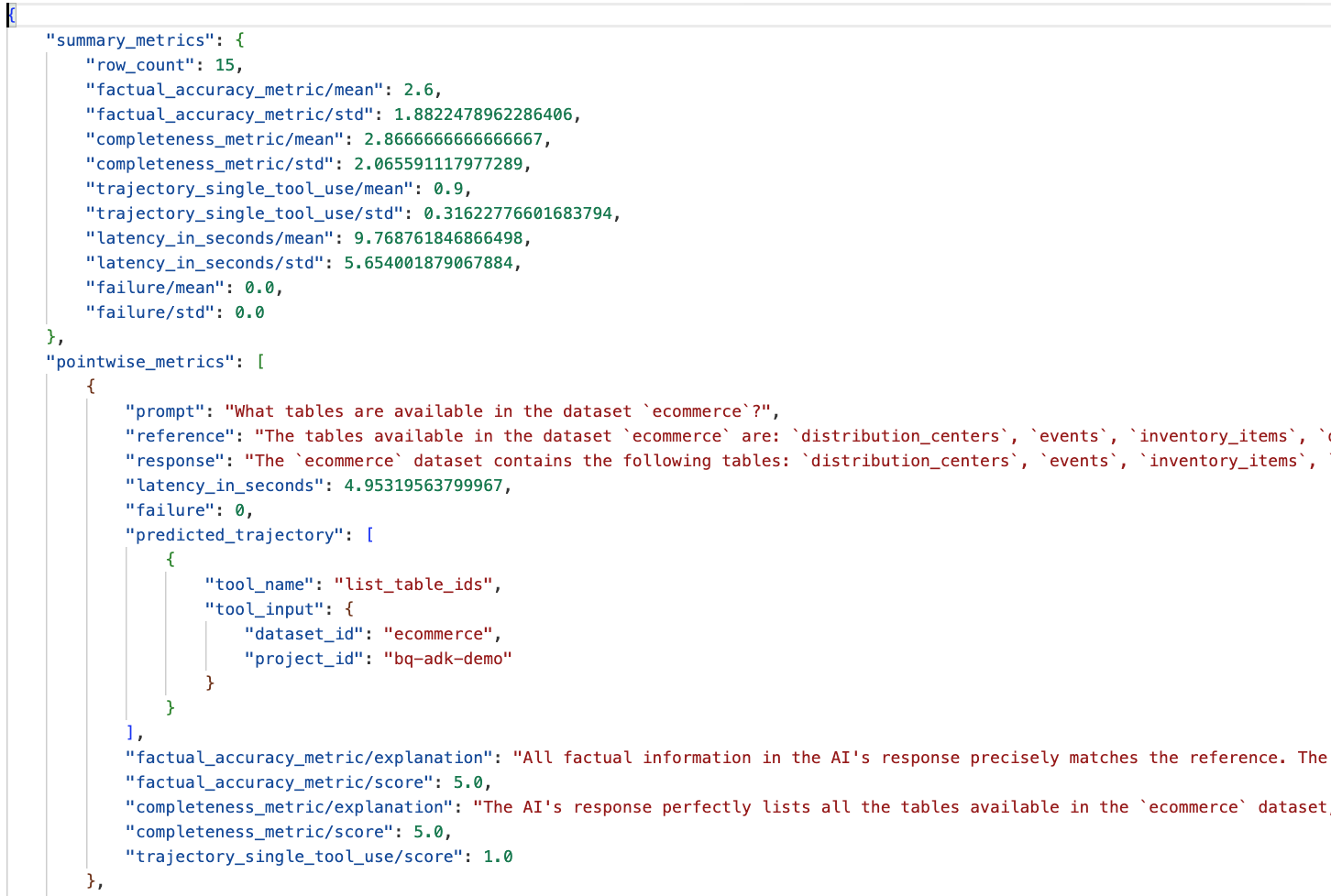
- 요약 측정항목: 데이터 세트 전반에서 에이전트의 실적을 집계하여 보여줍니다.
- 사실에 기반한 정확성 및 완전성 포인트별 측정항목: 5에 가까운 점수는 정확성과 완전성이 높다는 것을 나타냅니다. 각 질문에 대한 점수와 함께 해당 점수를 받은 이유에 대한 설명이 표시됩니다.
- 예측된 진행 경로: 에이전트가 최종 응답에 도달하는 데 사용하는 도구 호출 목록입니다. 이렇게 하면 에이전트에서 생성된 SQL 쿼리를 확인할 수 있습니다.
평균 완전성과 사실 정확성의 평균 점수는 각각 2.87과 2.6입니다.
결과가 좋지 않습니다. 상담사의 질문 응답 능력을 개선해 보겠습니다.
12. 에이전트 평가 결과 개선
bigquery-adk-codelab 디렉터리에서 agent.py로 이동하여 에이전트의 모델과 시스템 지침을 업데이트합니다. <YOUR_PROJECT_ID>를 프로젝트 ID로 바꿔야 합니다.
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
이제 터미널로 돌아가서 평가를 다시 실행합니다.
python evaluate_agent.py
이제 결과가 훨씬 개선되었습니다.
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
에이전트 평가는 반복적인 프로세스입니다. 평가 결과를 더욱 개선하려면 시스템 안내, 모델 매개변수 또는 BigQuery의 메타데이터를 조정하면 됩니다. 팁과 요령에서 아이디어를 얻어 보세요.
13. 삭제
Google Cloud 계정에 지속적으로 요금이 청구되지 않도록 하려면 이 워크숍에서 만든 리소스를 삭제해야 합니다.
이 Codelab을 위해 특정 BigQuery 데이터 세트 또는 테이블 (예: 이커머스 데이터 세트)을 만든 경우 이를 삭제하는 것이 좋습니다.
bq rm -r $PROJECT_ID:ecommerce
bigquery-adk-codelab 디렉터리와 그 콘텐츠를 삭제하려면 다음을 실행하세요.
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. 축하합니다
수고하셨습니다 에이전트 개발 키트 (ADK)를 사용하여 BigQuery 에이전트를 성공적으로 빌드하고 평가했습니다. 이제 BigQuery 도구로 ADK 에이전트를 설정하고 맞춤 평가 측정항목을 사용하여 성능을 측정하는 방법을 이해했습니다.