
1. Wprowadzenie
Z tego ćwiczenia dowiesz się, jak tworzyć agentów, którzy mogą odpowiadać na pytania dotyczące danych przechowywanych w BigQuery, za pomocą pakietu Agent Development Kit (ADK). Ocenisz też tych agentów za pomocą usługi oceny generatywnej AI w Vertex AI:
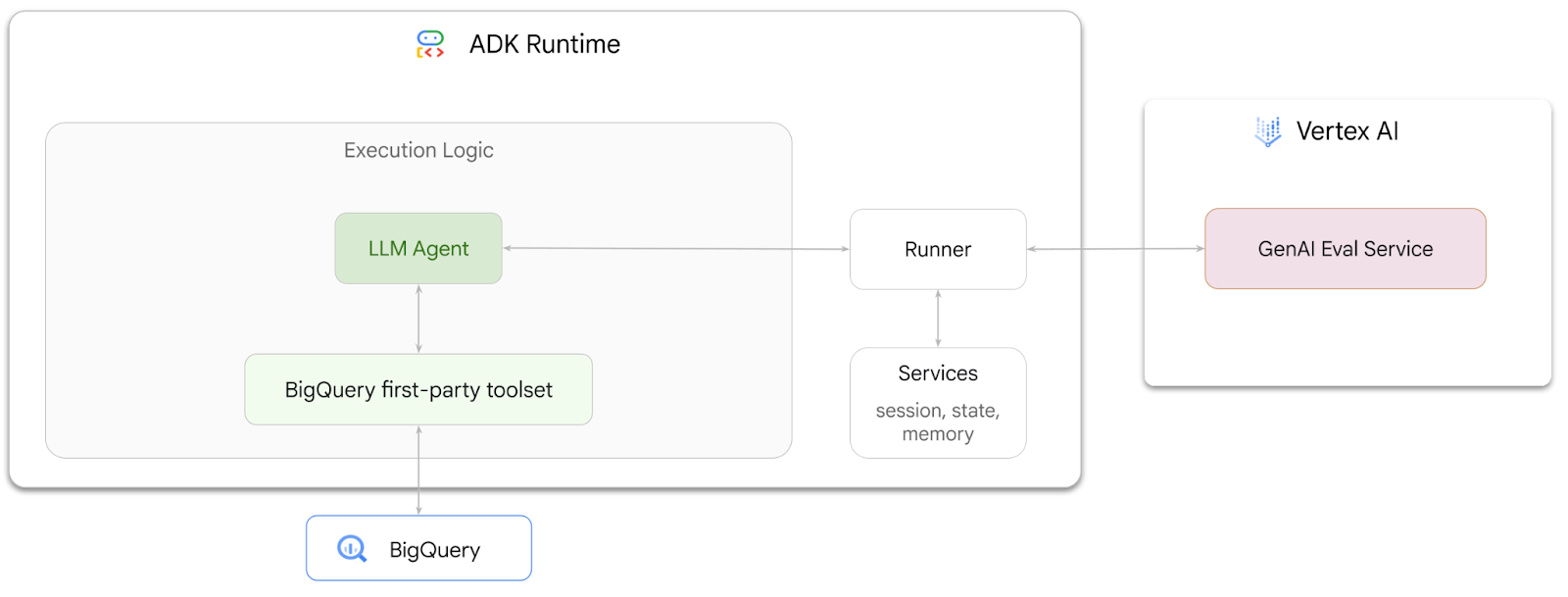
Co musisz zrobić
- Tworzenie agenta analityki konwersacyjnej w ADK
- Wyposaż tego agenta w zestaw narzędzi własnych ADK dla BigQuery, aby mógł wchodzić w interakcje z danymi przechowywanymi w BigQuery.
- Utwórz platformę oceny dla swojego agenta za pomocą usługi oceny generatywnej AI w Vertex AI.
- Przeprowadź ocenę tego agenta na podstawie zestawu wzorcowych odpowiedzi.
Czego potrzebujesz
- przeglądarka, np. Chrome;
- projekt Google Cloud z włączonymi płatnościami,
- konto Gmail, W następnej sekcji dowiesz się, jak wykorzystać bezpłatne środki w wysokości 5 USD na potrzeby tego laboratorium i skonfigurować nowy projekt.
To ćwiczenie jest przeznaczone dla deweloperów na wszystkich poziomach zaawansowania, w tym dla początkujących. Do tworzenia ADK będziesz używać interfejsu wiersza poleceń w Google Cloud Shell i kodu w języku Python. Nie musisz być ekspertem w Pythonie, ale podstawowa znajomość kodu pomoże Ci zrozumieć koncepcje.
2. Zanim zaczniesz
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt w chmurze Google Cloud.
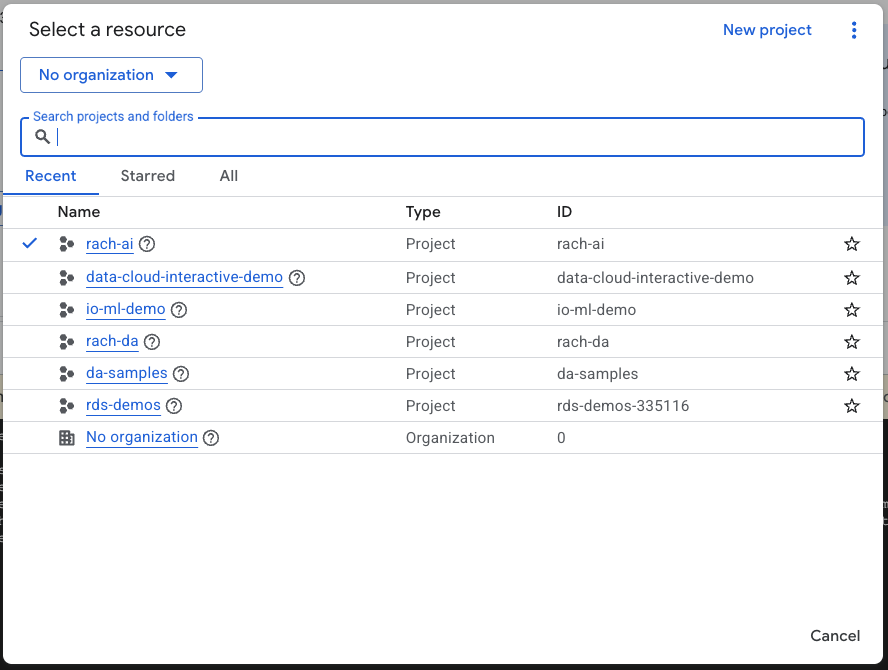
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Uruchamianie Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera niezbędne narzędzia.
- U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell:

- Po połączeniu z Cloud Shell uruchom to polecenie, aby sprawdzić uwierzytelnianie w Cloud Shell:
gcloud auth list
- Aby sprawdzić, czy projekt jest skonfigurowany do używania z gcloud, uruchom to polecenie:
gcloud config list project
- Aby ustawić projekt, użyj tego polecenia:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Włącz interfejsy API
- Aby włączyć wszystkie wymagane interfejsy API i usługi, uruchom to polecenie:
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- Po pomyślnym wykonaniu polecenia powinien wyświetlić się komunikat podobny do tego poniżej:
Operation "operations/..." finished successfully.
3. Tworzenie zbioru danych BigQuery
- Aby utworzyć w BigQuery nowy zbiór danych o nazwie ecommerce, uruchom w Cloud Shell to polecenie:
bq mk --dataset --location=US ecommerce
Statyczny podzbiór publicznego zbioru danych BigQuery thelook_ecommerce jest zapisywany jako pliki AVRO w publicznym zasobniku Google Cloud Storage.
- Aby wczytać te pliki Avro do BigQuery jako tabele (events, order_items, products, users, orders), uruchom to polecenie w Cloud Shell:
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
Może to potrwać kilka minut.
- Sprawdź, czy zbiór danych i tabele zostały utworzone. W tym celu otwórz konsolę BigQuery w projekcie Google Cloud:
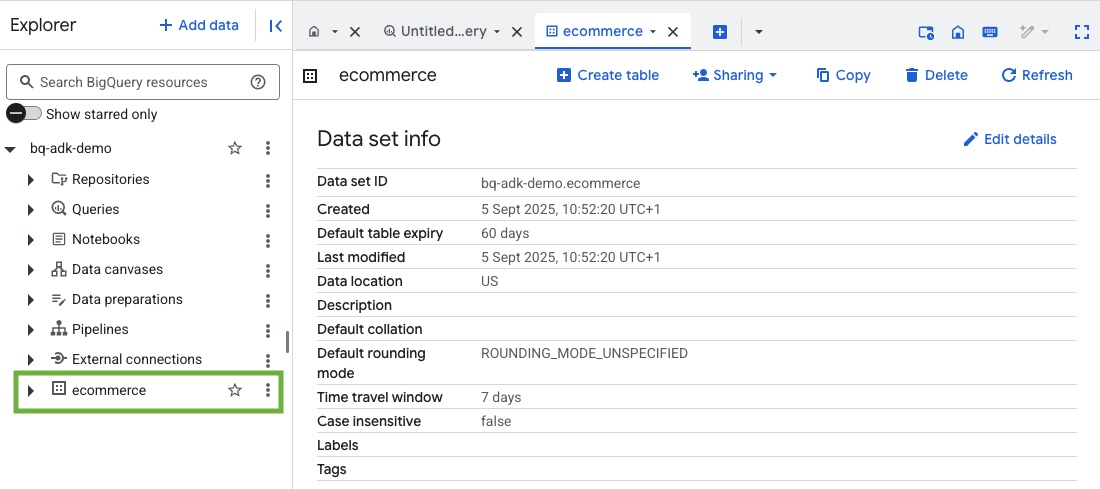
4. Przygotowywanie środowiska dla agentów ADK
Wróć do Cloud Shell i upewnij się, że jesteś w katalogu domowym. Utworzymy wirtualne środowisko Pythona i zainstalujemy wymagane pakiety.
- Otwórz nową kartę terminala w Cloud Shell i uruchom to polecenie, aby utworzyć folder o nazwie bigquery-adk-codelab i przejść do niego:
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- Utwórz wirtualne środowisko Pythona:
python -m venv .venv
- Aktywuj środowisko wirtualne:
source .venv/bin/activate
- Zainstaluj pakiety ADK i AI Platform w Pythonie od Google. Do oceny agenta bigquery wymagana jest platforma AI i pakiet pandas:
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. Tworzenie aplikacji ADK
Teraz utworzymy agenta BigQuery. Ten agent będzie odpowiadać na pytania w języku naturalnym dotyczące danych przechowywanych w BigQuery.
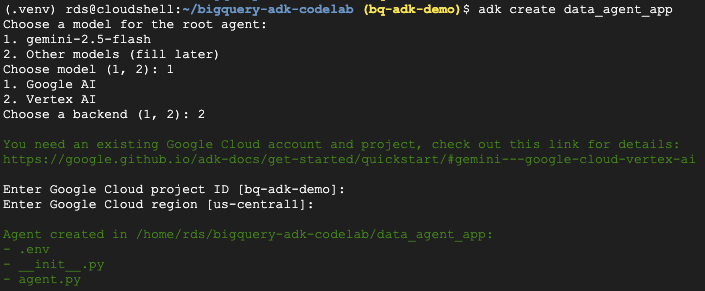
- Uruchom polecenie narzędzia adk create, aby utworzyć szkielet nowej aplikacji agenta z niezbędnymi folderami i plikami:
adk create data_agent_app
Postępuj zgodnie z wyświetlanymi instrukcjami:
- Wybierz model gemini-2.5-flash.
- Wybierz Vertex AI jako backend.
- Potwierdź domyślny identyfikator projektu Google Cloud i region.
Przykładowa interakcja jest pokazana poniżej:
- Kliknij przycisk Otwórz edytor w Cloud Shell, aby otworzyć edytor Cloud Shell i wyświetlić nowo utworzone foldery i pliki:

Zwróć uwagę na wygenerowane pliki:
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: oznacza folder jako moduł Pythona.
- agent.py: zawiera początkową definicję agenta.
- .env: zawiera zmienne środowiskowe projektu (aby wyświetlić ten plik, może być konieczne kliknięcie kolejno View > Toggle Hidden Files).
Zaktualizuj wszystkie zmienne, które nie zostały poprawnie ustawione na podstawie promptów:
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. Zdefiniuj agenta i przypisz mu zestaw narzędzi BigQuery
Aby zdefiniować agenta ADK, który wchodzi w interakcje z BigQuery za pomocą zestawu narzędzi BigQuery, zastąp dotychczasową zawartość pliku agent.py tym kodem:
W instrukcjach agenta musisz zaktualizować identyfikator projektu, aby był zgodny z Twoim identyfikatorem:
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
Zestaw narzędzi BigQuery zapewnia agentowi możliwość pobierania metadanych i wykonywania zapytań SQL dotyczących danych BigQuery. Aby korzystać z zestawu narzędzi, musisz się uwierzytelnić. Najczęstsze opcje to domyślne uwierzytelnianie aplikacji (ADC) na potrzeby programowania, interaktywne OAuth, gdy agent musi działać w imieniu konkretnego użytkownika, lub dane logowania konta usługi na potrzeby bezpiecznego uwierzytelniania na poziomie produkcyjnym.
W tym celu możesz porozmawiać na czacie z pracownikiem obsługi klienta, wracając do Cloud Shell i wykonując to polecenie:
adk web
Powinno się wyświetlić powiadomienie o uruchomieniu serwera internetowego:
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
Kliknij podany adres URL, aby uruchomić ADK Web. Możesz zadać agentowi pytania dotyczące zbioru danych:
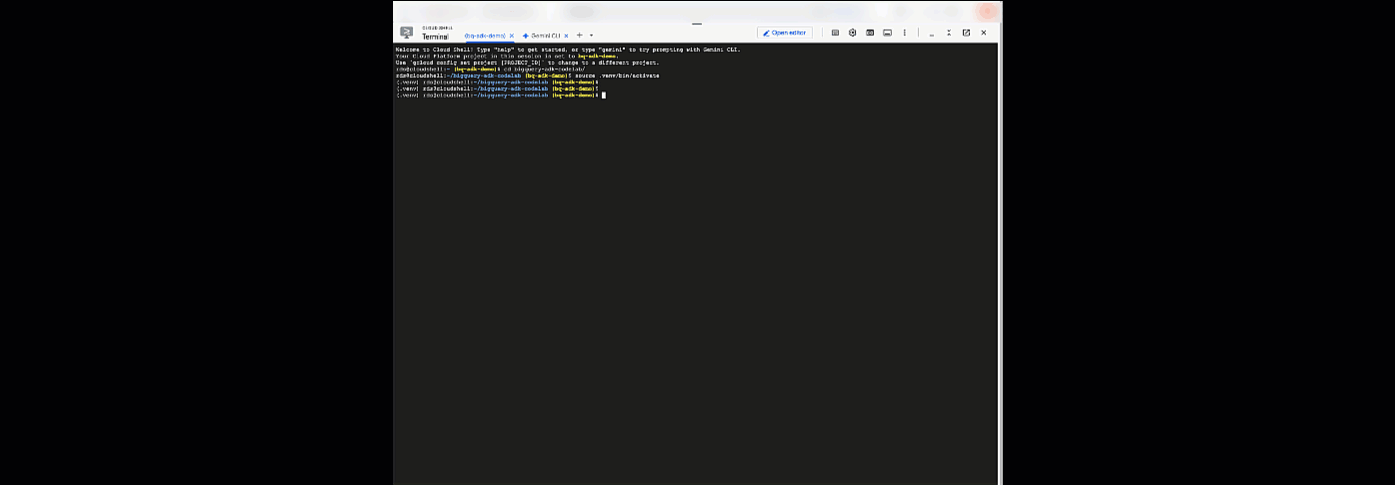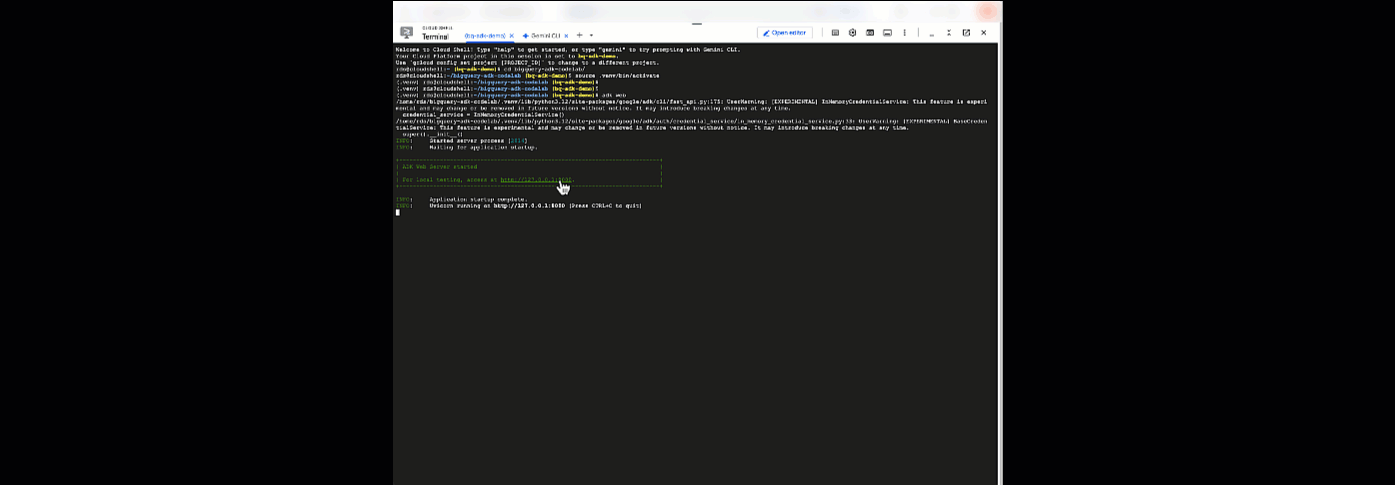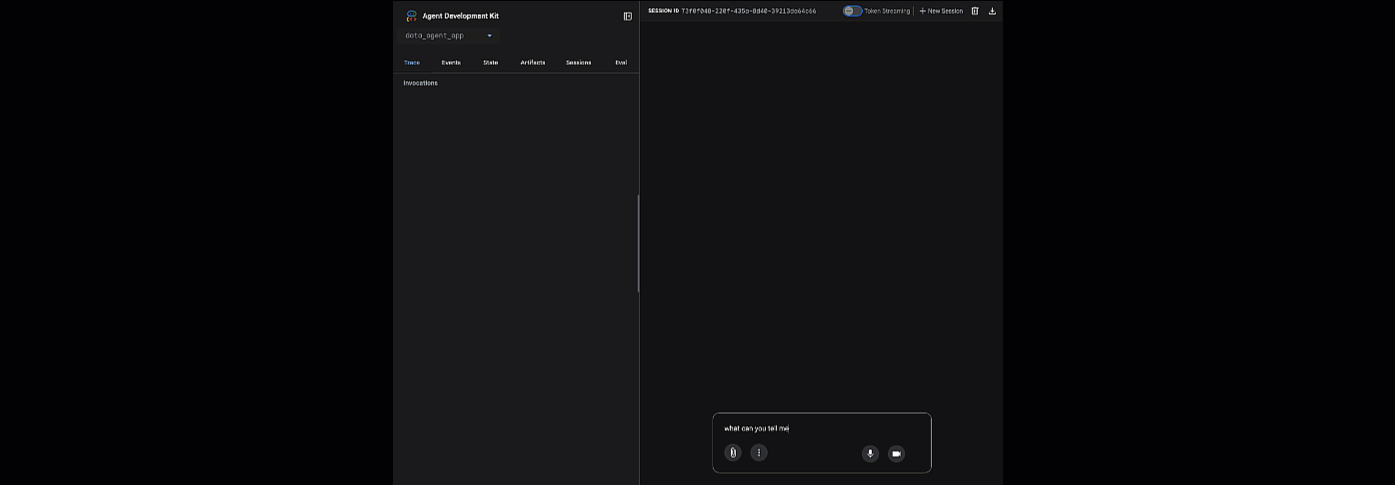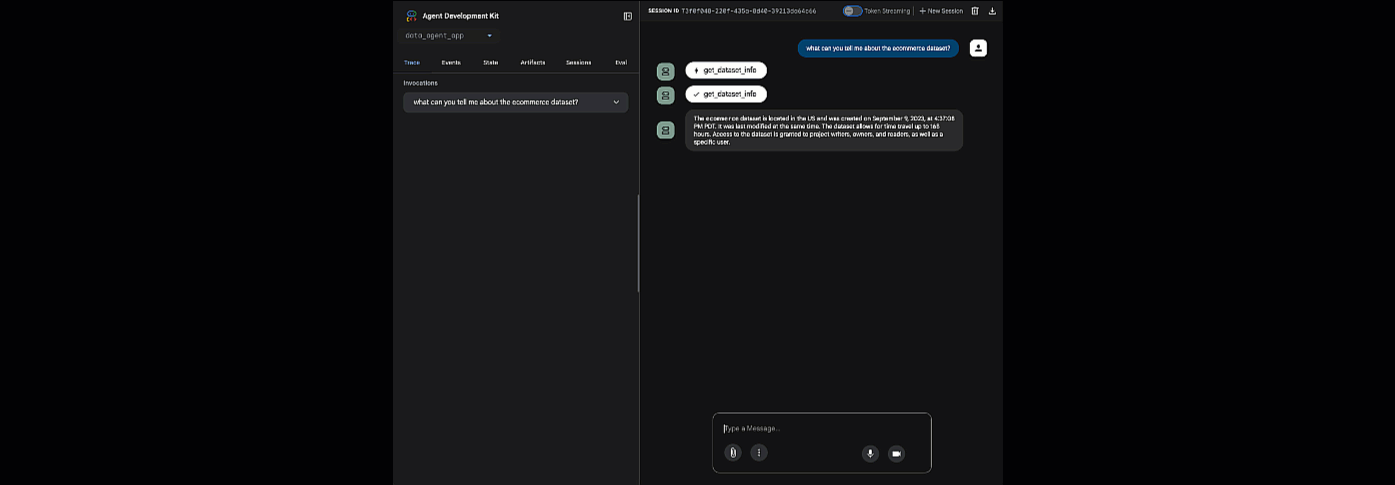
Zamknij adk web i naciśnij Ctrl + C w terminalu, aby wyłączyć serwer WWW.
7. Przygotowanie agenta do oceny
Po zdefiniowaniu agenta BigQuery musisz umożliwić jego uruchomienie na potrzeby oceny.
Poniższy kod definiuje funkcję run_conversation, która obsługuje przebieg rozmowy, tworząc agenta, uruchamiając sesję i przetwarzając zdarzenia w celu uzyskania ostatecznej odpowiedzi.
- Wróć do edytora Cloud i utwórz nowy plik o nazwie
run_agent.pyw katalogu bigquery-adk-codelab. Następnie skopiuj i wklej poniższy kod:
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
Poniższy kod definiuje funkcje narzędziowe do wywoływania tej funkcji wykonywalnej i zwracania wyniku. Zawiera też funkcje pomocnicze, które drukują i zapisują wyniki oceny:
- Utwórz nowy plik o nazwie
utils.pyw katalogu bigquery-adk-codelab i skopiuj/wklej do niego ten kod:
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. Tworzenie zbioru danych do oceny
Aby ocenić agenta, musisz utworzyć zbiór danych do oceny, zdefiniować wskaźniki oceny i uruchomić zadanie oceny.
Zbiór danych oceny zawiera listę pytań (promptów) i odpowiadających im prawidłowych odpowiedzi (odniesień). Usługa oceny będzie używać tych par do porównywania odpowiedzi agenta i określania, czy są one dokładne.
- Utwórz nowy plik o nazwie evaluation_dataset.json w katalogu bigquery-adk-codelab i skopiuj/wklej poniższy zbiór danych do oceny:
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. Określanie wskaźników oceny
Będziemy teraz używać 2 niestandardowych rodzajów pomiarów, aby ocenić zdolność agenta do odpowiadania na pytania dotyczące danych BigQuery. Oba rodzaje pomiarów będą podawać wynik w skali od 1 do 5:
- Wskaźnik dokładności faktów: ocenia, czy wszystkie dane i fakty przedstawione w odpowiedzi są precyzyjne i prawidłowe w porównaniu z danymi podstawowymi.
- Wskaźnik kompletności: mierzy, czy odpowiedź zawiera wszystkie kluczowe informacje, o które prosił użytkownik, i czy są one obecne w prawidłowej odpowiedzi bez istotnych pominięć.
- Na koniec utwórz w katalogu bigquery-adk-codelab nowy plik o nazwie
evaluate_agent.pyi skopiuj do niego kod definicji wskaźnika:
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
Uwzględniłem też wskaźnik TrajectorySingleToolUse na potrzeby oceny trajektorii. Jeśli te dane są dostępne, wywołania narzędzi agenta (w tym wygenerowany i wykonany w BigQuery surowy kod SQL) zostaną uwzględnione w odpowiedzi na ocenę, co umożliwi szczegółowe sprawdzenie.
Metryka TrajectorySingleToolUse określa, czy agent użył danego narzędzia. W tym przypadku wybrałem list_table_ids, ponieważ oczekujemy, że to narzędzie będzie wywoływane w przypadku każdego pytania w zbiorze danych do oceny. W odróżnieniu od innych danych dotyczących trajektorii nie wymaga ona podania wszystkich oczekiwanych wywołań narzędzi i argumentów dla każdego pytania w zbiorze danych oceny.
10. Tworzenie zadania oceny
EvalTask pobiera zbiór danych do oceny i niestandardowe dane, a następnie konfiguruje nowy eksperyment oceny.
Funkcja run_eval to główny mechanizm oceny. Wykonuje pętlę EvalTask, uruchamiając agenta dla każdego pytania w zbiorze danych. W przypadku każdego pytania rejestruje odpowiedź agenta, a następnie ocenia ją na podstawie zdefiniowanych wcześniej danych.
Skopiuj i wklej ten kod na końcu pliku evaluate_agent.py:
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
Wyniki są podsumowywane i zapisywane w pliku JSON.
11. Przeprowadź ocenę
Gdy masz już gotowego agenta, wskaźniki oceny i zbiór danych do oceny, możesz przeprowadzić ocenę.
Wróć do Cloud Shell, upewnij się, że jesteś w katalogu bigquery-adk-codelab, i uruchom skrypt oceny za pomocą tego polecenia:
python evaluate_agent.py
W trakcie oceny zobaczysz dane wyjściowe podobne do tych:
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
Jeśli napotkasz błędy podobne do tych poniżej, oznacza to, że w danym przebiegu agent nie wywołał żadnych narzędzi. W następnym kroku możesz dokładniej sprawdzić jego działanie.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
Interpretowanie wyników:
Przejdź do folderu eval_results w katalogu data_agent_app i otwórz plik wyników oceny o nazwie bq_agent_eval_results_*.json:
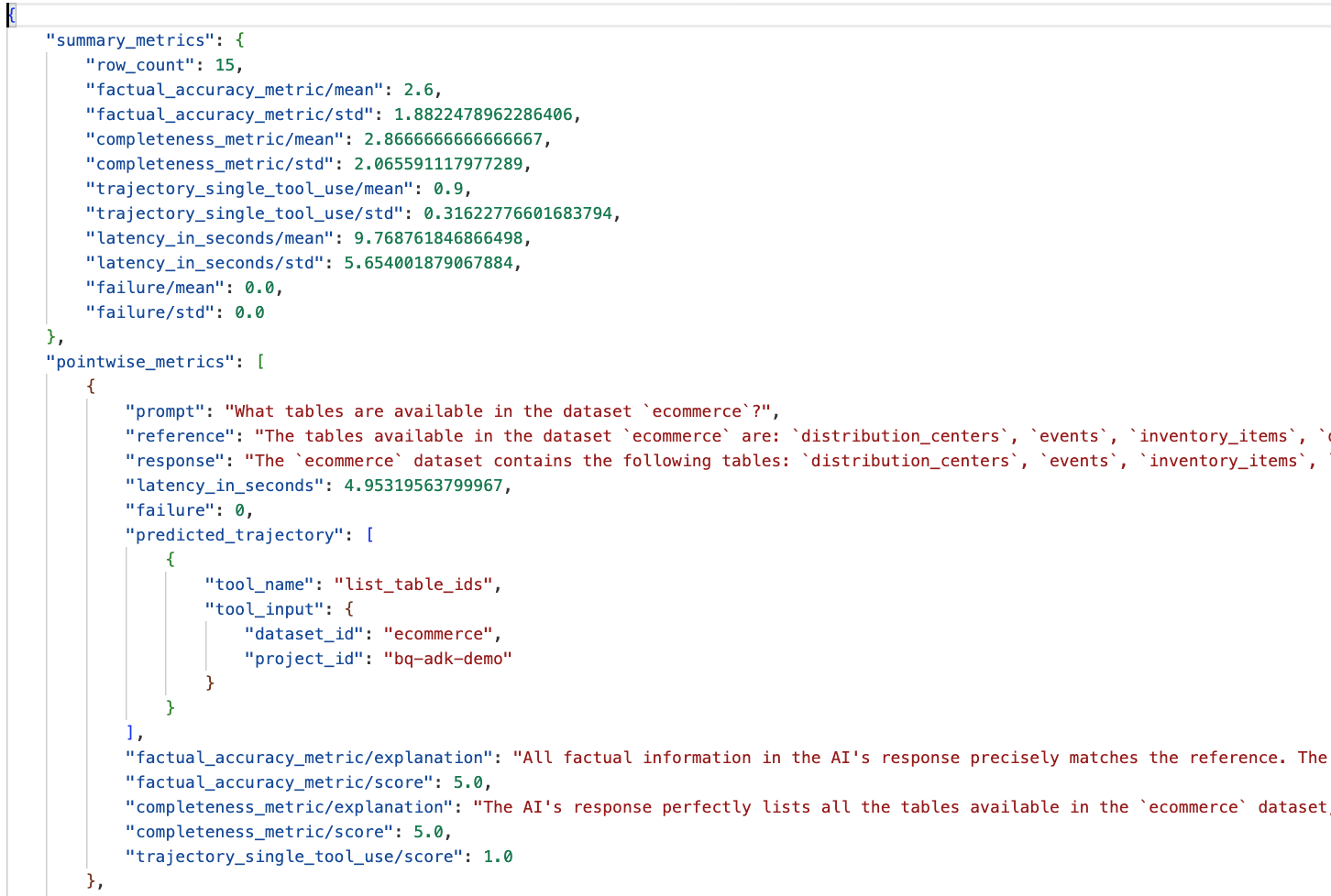
- Podsumowanie danych: zawiera zbiorcze dane o skuteczności agenta w całym zbiorze danych.
- Wskaźniki punktowe dokładności i kompletności informacji: wynik bliższy 5 oznacza większą dokładność i kompletność. Przy każdym pytaniu będzie podana ocena wraz z pisemnym wyjaśnieniem, dlaczego została przyznana.
- Przewidywana trajektoria: lista wywołań narzędzi używanych przez agentów do uzyskania ostatecznej odpowiedzi. Dzięki temu będziemy mogli zobaczyć wszystkie zapytania SQL wygenerowane przez agenta.
Średnia ocena średniej kompletności i rzetelności wynosi odpowiednio 2,87 i 2,6.
Wyniki nie są zbyt dobre. Spróbujmy poprawić umiejętność odpowiadania na pytania przez naszego agenta.
12. Poprawianie wyników oceny agenta
Otwórz plik agent.py w katalogu bigquery-adk-codelab i zaktualizuj model agenta oraz instrukcje systemowe. Pamiętaj, aby zastąpić <YOUR_PROJECT_ID> identyfikatorem projektu:
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
Wróć teraz do terminala i ponownie uruchom ocenę:
python evaluate_agent.py
Powinny się wyświetlić znacznie lepsze wyniki:
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
Ocena agenta to proces iteracyjny. Aby jeszcze bardziej poprawić wyniki oceny, możesz dostosować instrukcje systemowe, parametry modelu lub nawet metadane w BigQuery. Więcej pomysłów znajdziesz w tych wskazówkach.
13. Czyszczenie
Aby uniknąć obciążania konta Google Cloud bieżącymi opłatami, usuń zasoby utworzone podczas tych warsztatów.
Jeśli w ramach tego samouczka zostały przez Ciebie utworzone jakieś zbiory danych lub tabele BigQuery (np. zbiór danych e-commerce), możesz je usunąć:
bq rm -r $PROJECT_ID:ecommerce
Aby usunąć katalog bigquery-adk-codelab i jego zawartość:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. Gratulacje
Gratulacje! Udało Ci się utworzyć i ocenić agenta BigQuery za pomocą pakietu Agent Development Kit (ADK). Wiesz już, jak skonfigurować agenta ADK za pomocą narzędzi BigQuery i mierzyć jego skuteczność za pomocą niestandardowych wskaźników oceny.