
1. Introdução
Neste codelab, você vai aprender a criar agentes que podem responder a perguntas sobre dados armazenados no BigQuery usando o Kit de Desenvolvimento de Agente (ADK). Você também vai avaliar esses agentes usando o serviço de avaliação de IA generativa da Vertex AI:
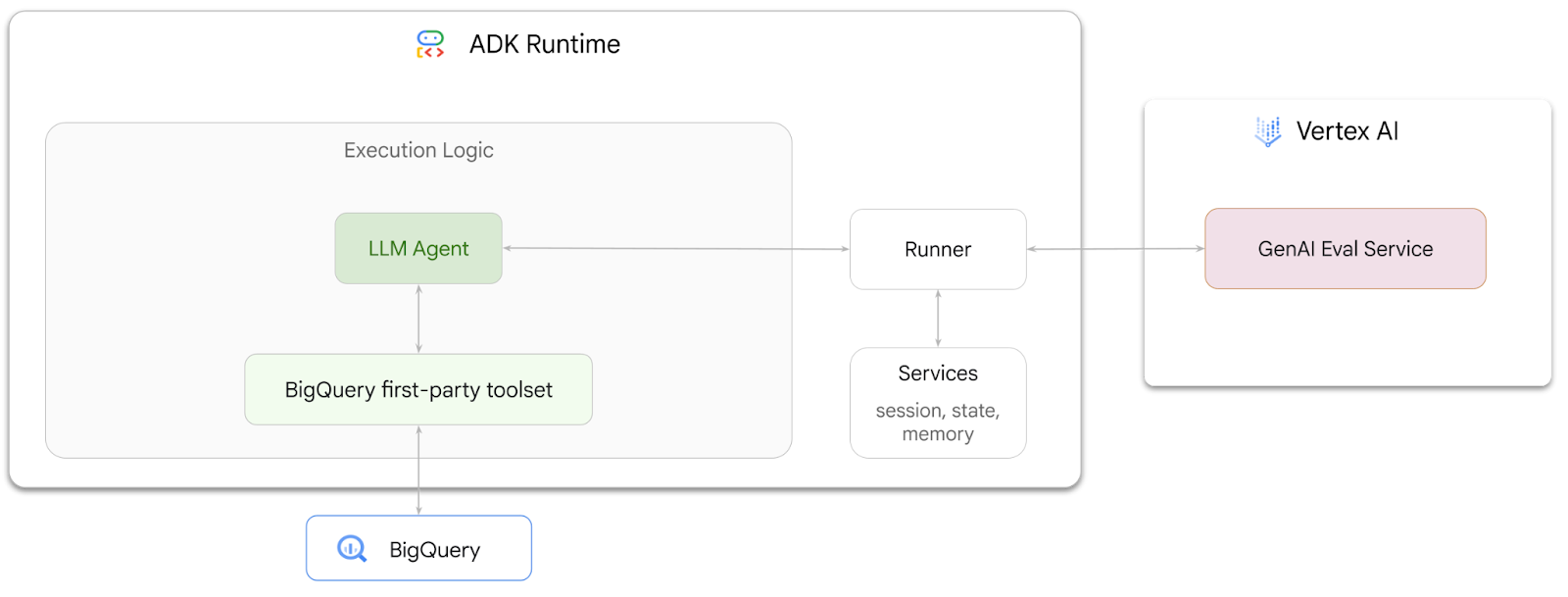
O que você aprenderá
- Criar um agente de análise conversacional no ADK
- Equipe esse agente com o conjunto de ferramentas próprias do ADK para BigQuery para que ele possa interagir com os dados armazenados no BigQuery.
- Crie uma estrutura de avaliação para seu agente usando o serviço de avaliação de IA generativa da Vertex AI
- Executar avaliações nesse agente com base em um conjunto de respostas de ouro
O que é necessário
- Um navegador da Web, como o Chrome
- Um projeto na nuvem do Google com o faturamento ativado ou
- Uma conta do Gmail. Na próxima seção, você vai aprender a resgatar um crédito sem custo financeiro de US $5 para este codelab e configurar um novo projeto.
Este codelab é destinado a desenvolvedores de todos os níveis, inclusive iniciantes. Você vai usar a interface de linha de comando no Google Cloud Shell e o código Python para desenvolvimento do ADK. Não é preciso ser especialista em Python, mas um entendimento básico de como ler código vai ajudar você a entender os conceitos.
2. Antes de começar
Criar um projeto do Google Cloud
- No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Inicie o Cloud Shell
O Cloud Shell é um ambiente de linha de comando executado no Google Cloud que vem pré-carregado com as ferramentas necessárias.
- Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud:

- Depois de se conectar ao Cloud Shell, execute este comando para verificar sua autenticação no Cloud Shell:
gcloud auth list
- Execute o comando a seguir para confirmar se o projeto está configurado para uso com a gcloud:
gcloud config list project
- Use o comando a seguir para definir seu projeto:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Ativar APIs
- Execute este comando para ativar todas as APIs e serviços necessários:
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- Após a execução do comando, você vai ver uma mensagem semelhante à mostrada abaixo:
Operation "operations/..." finished successfully.
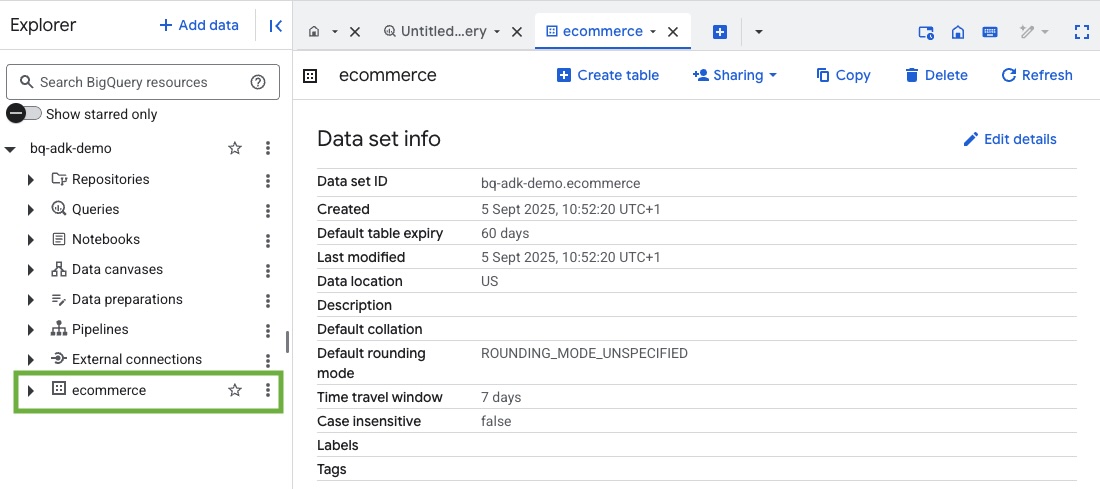
3. Criar um conjunto de dados do BigQuery
- Execute o comando a seguir no Cloud Shell para criar um conjunto de dados chamado "ecommerce" no BigQuery:
bq mk --dataset --location=US ecommerce
Um subconjunto estático do conjunto de dados público do BigQuery thelook_ecommerce é salvo como arquivos AVRO em um bucket público do Google Cloud Storage.
- Execute este comando no Cloud Shell para carregar esses arquivos Avro no BigQuery como tabelas (events, order_items, products, users, orders):
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
Esse processo pode levar alguns minutos.
- Para verificar se o conjunto de dados e as tabelas foram criados, acesse o console do BigQuery no seu projeto do Google Cloud:
4. Preparar o ambiente para agentes do ADK
Volte ao Cloud Shell e verifique se você está no diretório inicial. Vamos criar um ambiente virtual do Python e instalar os pacotes necessários.
- Abra uma nova guia do terminal no Cloud Shell e execute este comando para criar e acessar uma pasta chamada bigquery-adk-codelab:
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- Crie um ambiente virtual Python:
python -m venv .venv
- Ative o ambiente virtual:
source .venv/bin/activate
- Instale os pacotes do ADK e da AI Platform em Python do Google. A plataforma de IA e o pacote pandas são necessários para avaliar o agente do BigQuery:
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. Criar um aplicativo ADK
Agora vamos criar nosso agente do BigQuery. Ele foi projetado para responder a perguntas em linguagem natural sobre os dados armazenados no BigQuery.
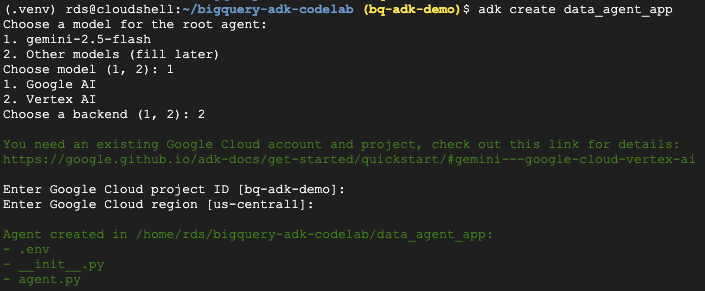
- Execute o comando adk create utility para criar um novo aplicativo de agente com as pastas e os arquivos necessários:
adk create data_agent_app
Siga as instruções:
- Escolha gemini-2.5-flash para o modelo.
- Escolha a Vertex AI para o back-end.
- Confirme o ID do projeto e a região padrão do Google Cloud.
Confira um exemplo de interação:
- Clique no botão "Abrir editor" no Cloud Shell para abrir o editor do Cloud Shell e conferir as pastas e os arquivos recém-criados:

Observe os arquivos gerados:
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py::marca a pasta como um módulo do Python.
- agent.py::contém a definição inicial do agente.
- .env:contém variáveis de ambiente para seu projeto. Talvez seja necessário clicar em "Visualizar" > "Ativar/desativar arquivos ocultos" para ver esse arquivo.
Atualize as variáveis que não foram definidas corretamente nos comandos:
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. Definir seu agente e atribuir a ele o conjunto de ferramentas do BigQuery
Para definir um agente do ADK que interaja com o BigQuery usando o conjunto de ferramentas do BigQuery, substitua o conteúdo atual do arquivo agent.py pelo código a seguir.
Atualize o ID do projeto nas instruções do agente com o ID do seu projeto real:
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
O conjunto de ferramentas do BigQuery oferece a um agente os recursos para buscar metadados e executar consultas SQL em dados do BigQuery. Para usar o conjunto de ferramentas, é preciso fazer a autenticação. As opções mais comuns são as Application Default Credentials (ADC) para desenvolvimento, o OAuth interativo para quando o agente precisa agir em nome de um usuário específico ou as credenciais da conta de serviço para autenticação segura em nível de produção.
Agora, você pode conversar com seu agente. Para isso, volte ao Cloud Shell e execute este comando:
adk web
Você vai receber uma notificação informando que o servidor da Web foi iniciado:
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
Clique no URL fornecido para iniciar o ADK Web. Você pode fazer algumas perguntas ao agente sobre o conjunto de dados:
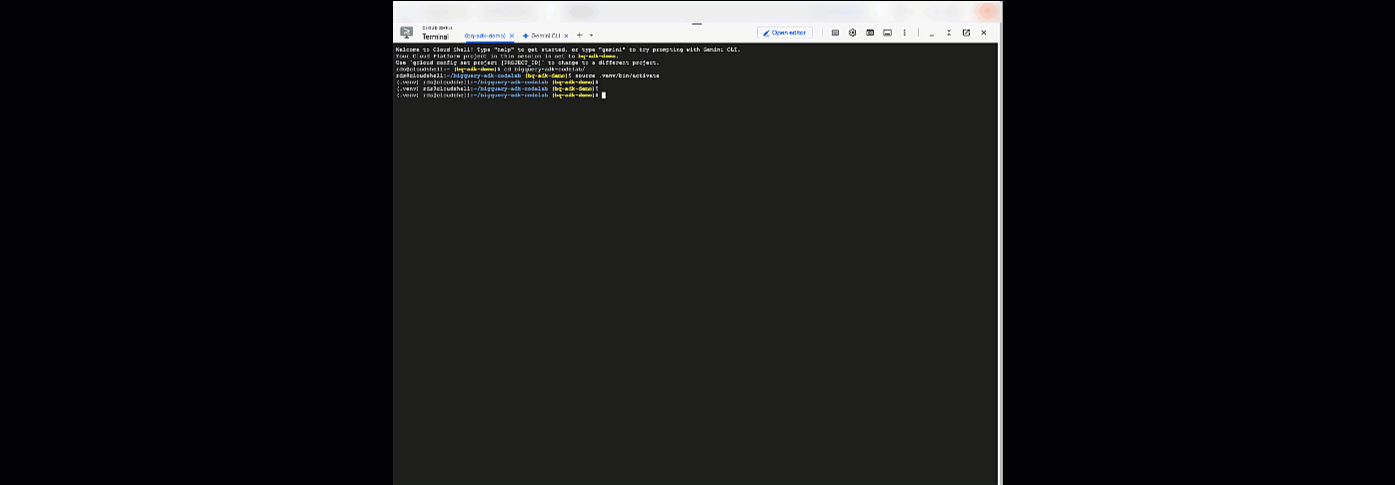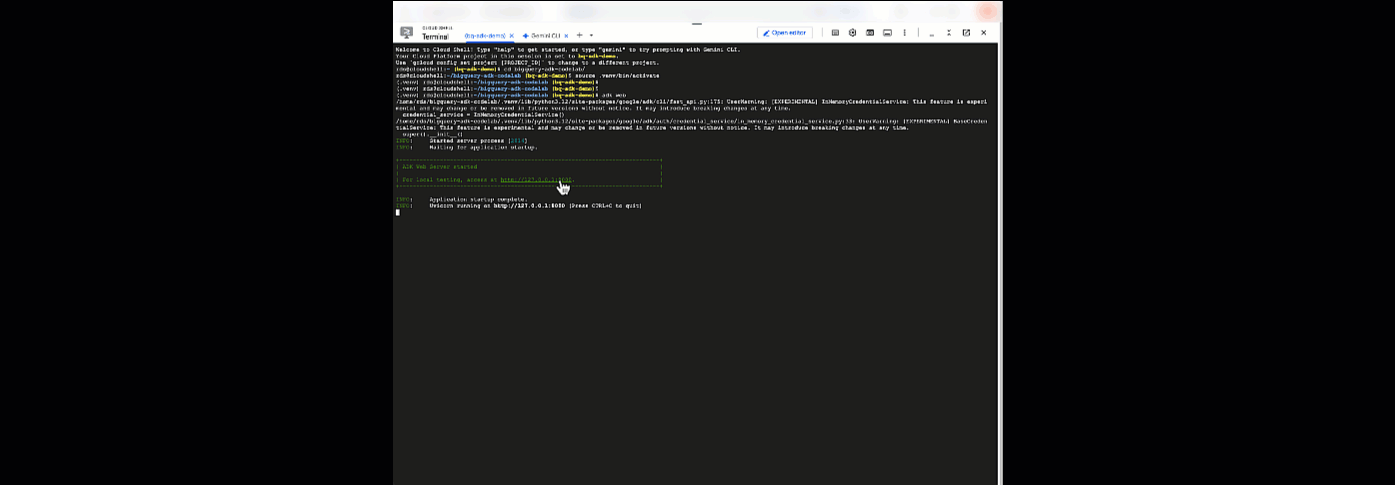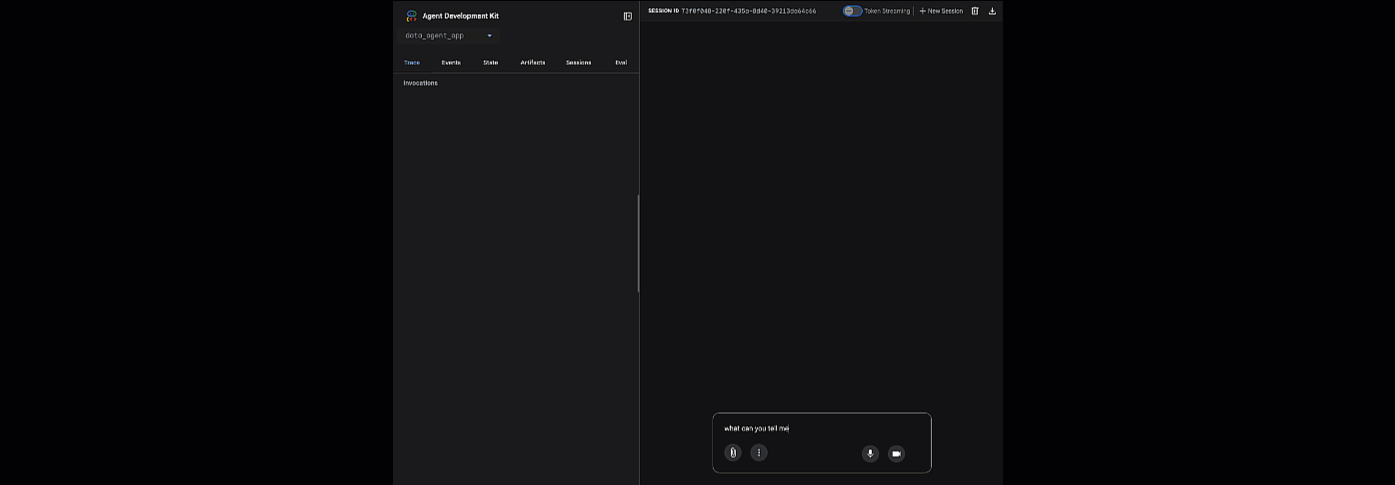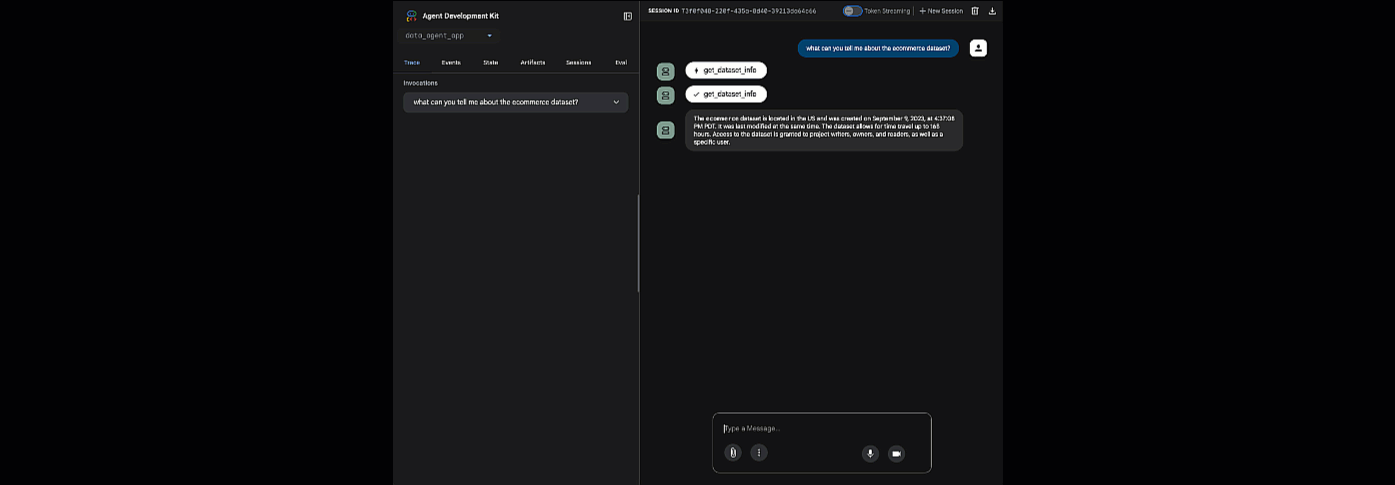
Feche o adk web e pressione Ctrl + C no terminal para desligar o servidor da web.
7. Preparar seu agente para avaliação
Agora que você definiu seu agente do BigQuery, é preciso torná-lo executável para avaliação.
O código abaixo define uma função, run_conversation, que processa o fluxo da conversa criando um agente, executando uma sessão e processando os eventos para recuperar a resposta final.
- Volte ao Cloud Editor e crie um arquivo chamado
run_agent.pyno diretório bigquery-adk-codelab e copie/cole o código abaixo:
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
O código abaixo define funções utilitárias para chamar essa função executável e retornar o resultado. Ele também inclui funções auxiliares que imprimem e salvam os resultados da avaliação:
- Crie um arquivo chamado
utils.pyno diretório bigquery-adk-codelab e copie/cole este código no arquivo utils.py:
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. Criar um conjunto de dados de avaliação
Para avaliar seu agente, você precisa criar um conjunto de dados de avaliação, definir as métricas de avaliação e executar a tarefa de avaliação.
O conjunto de dados de avaliação contém uma lista de perguntas (comandos) e as respostas corretas correspondentes (referências). O serviço de avaliação vai usar esses pares para comparar as respostas do seu agente e determinar se elas são precisas.
- Crie um arquivo chamado "evaluation_dataset.json" no diretório "bigquery-adk-codelab" e copie/cole o conjunto de dados de avaliação abaixo:
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. Definir as métricas de avaliação
Agora vamos usar duas métricas personalizadas para avaliar a capacidade do agente de responder a perguntas relacionadas aos seus dados do BigQuery, ambas fornecendo uma pontuação de 1 a 5:
- Métrica de acurácia factual:avalia se todos os dados e fatos apresentados na resposta são precisos e corretos quando comparados às informações empíricas.
- Métrica de integridade:mede se a resposta inclui todas as informações principais solicitadas pelo usuário e presentes na resposta correta, sem omissões críticas.
- Por fim, crie um arquivo chamado
evaluate_agent.pyno diretório bigquery-adk-codelab e copie/cole o código de definição de métricas no arquivo evaluate_agent.py:
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
Também incluí a métrica TrajectorySingleToolUse para avaliação de trajetória. Quando essas métricas estão presentes, as chamadas de ferramentas do agente (incluindo o SQL bruto que ele gera e executa no BigQuery) são incluídas na resposta da avaliação, permitindo uma inspeção detalhada.
A métrica TrajectorySingleToolUse determina se um agente usou uma ferramenta específica. Nesse caso, escolhi "list_table_ids", já que esperamos que essa ferramenta seja chamada para todas as perguntas no conjunto de dados de avaliação. Ao contrário de outras métricas de trajetória, essa não exige que você especifique todas as chamadas de função e argumentos esperados para cada pergunta no conjunto de dados de avaliação.
10. Criar sua tarefa de avaliação
A EvalTask usa o conjunto de dados de avaliação e as métricas personalizadas e configura um novo experimento de avaliação.
Essa função, run_eval, é o principal mecanismo da avaliação. Ele faz um loop em uma EvalTask, executando seu agente em cada pergunta do conjunto de dados. Para cada pergunta, ele registra a resposta do agente e usa as métricas definidas anteriormente para classificar.
Copie e cole o código a seguir na parte de baixo do arquivo evaluate_agent.py:
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
Os resultados são resumidos e salvos em um arquivo JSON.
11. Executar a avaliação
Agora que você tem o agente, as métricas e o conjunto de dados de avaliação prontos, é possível executar a avaliação.
Volte ao Cloud Shell, verifique se você está no diretório bigquery-adk-codelab e execute o script de avaliação usando o seguinte comando:
python evaluate_agent.py
Você verá uma saída semelhante a esta à medida que a avaliação avança:
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
Se você encontrar erros como os abaixo, isso significa apenas que o agente não chamou nenhuma ferramenta para uma execução específica. Você pode inspecionar melhor o comportamento do agente na próxima etapa.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
Interpretação dos resultados:
Acesse a pasta "eval_results" no diretório "data_agent_app" e abra o arquivo de resultado da avaliação chamado bq_agent_eval_results_*.json:
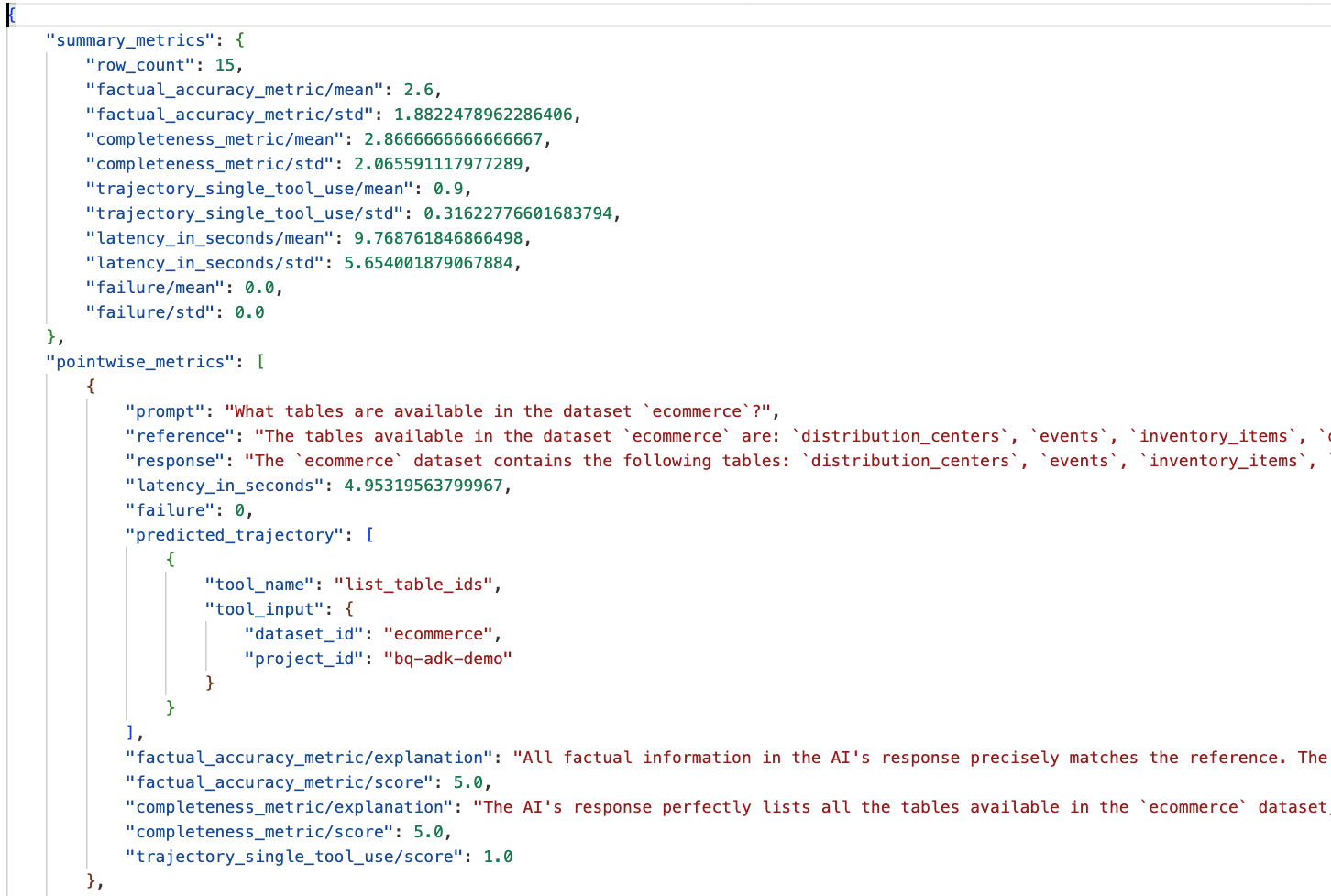
- Métricas de resumo:oferecem uma visão agregada da performance do seu agente no conjunto de dados.
- Métricas pontuais de acurácia e integridade factual:uma pontuação mais próxima de 5 indica maior acurácia e integridade. Cada pergunta vai receber uma pontuação e uma explicação por escrito do motivo dessa pontuação.
- Trajetória prevista:é a lista de chamadas de ferramentas usadas pelos agentes para chegar à resposta final. Assim, podemos conferir as consultas SQL geradas pelo agente.
A pontuação média para integridade e acurácia factual é de 2,87 e 2,6, respectivamente.
Os resultados não são muito bons. Vamos tentar melhorar a capacidade do nosso agente de responder a perguntas.
12. Melhorar os resultados da avaliação do seu agente
Navegue até agent.py no diretório bigquery-adk-codelab e atualize o modelo e as instruções do sistema do agente. Substitua <YOUR_PROJECT_ID> pelo ID do seu projeto:
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
Volte ao terminal e execute a avaliação novamente:
python evaluate_agent.py
Os resultados vão estar muito melhores:
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
A avaliação do agente é um processo iterativo. Para melhorar ainda mais os resultados da avaliação, ajuste as instruções do sistema, os parâmetros do modelo ou até mesmo os metadados no BigQuery. Confira estas dicas e truques para mais ideias.
13. Limpeza
Para evitar cobranças contínuas na sua conta do Google Cloud, exclua os recursos criados durante este workshop.
Se você criou conjuntos de dados ou tabelas específicos do BigQuery para este codelab (por exemplo, o conjunto de dados de e-commerce), talvez queira excluí-los:
bq rm -r $PROJECT_ID:ecommerce
Para remover o diretório bigquery-adk-codelab e o conteúdo dele:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. Parabéns
Parabéns! Você criou e avaliou um agente do BigQuery usando o Kit de Desenvolvimento de Agente (ADK). Agora você sabe como configurar um agente do ADK com ferramentas do BigQuery e medir a performance dele usando métricas de avaliação personalizadas.