
1. Введение
В этом практическом занятии вы научитесь создавать агентов, способных отвечать на вопросы о данных, хранящихся в BigQuery, используя Agent Development Kit (ADK ) . Вы также оцените этих агентов с помощью сервиса GenAI Evaluation от Vertex AI :
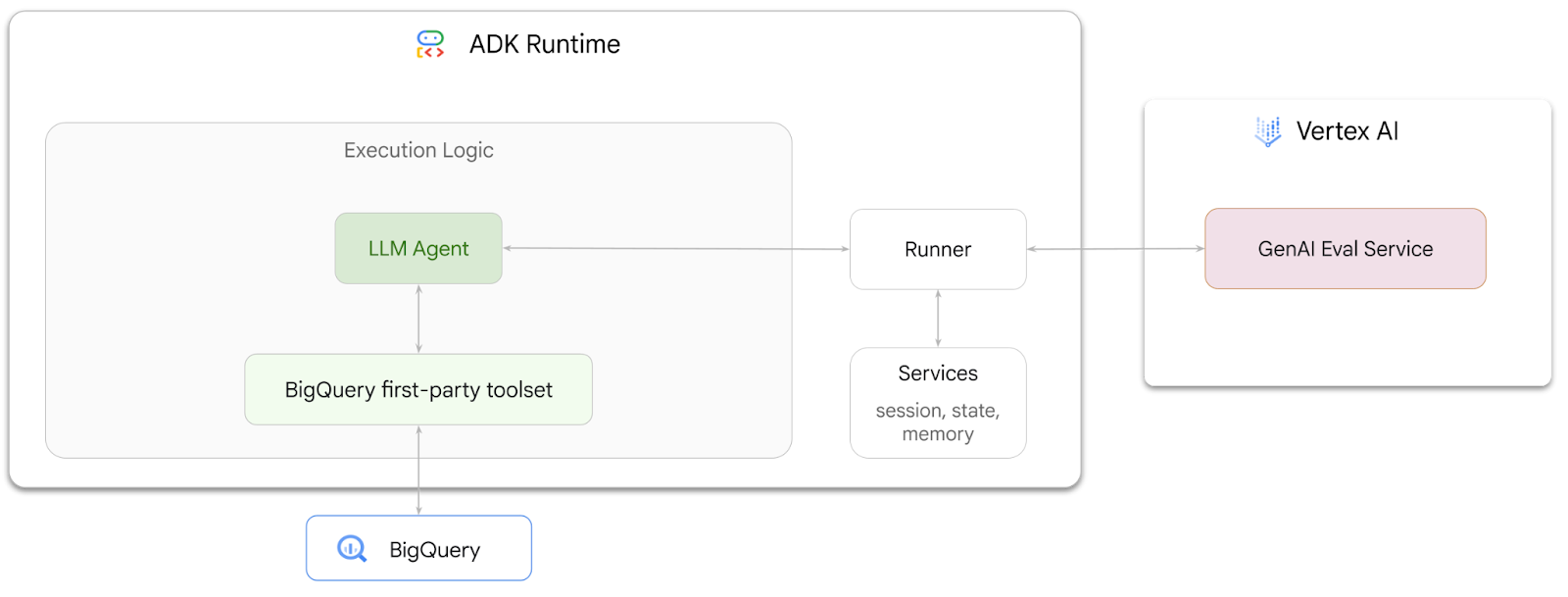
Что вы будете делать
- Создайте агента для анализа диалогов в ADK.
- Оснастите этого агента набором инструментов ADK для работы с BigQuery, чтобы он мог взаимодействовать с данными, хранящимися в BigQuery.
- Создайте систему оценки для вашего агента, используя сервис Vertex AI GenAI Evaluation.
- Проведите оценку этого агента на основе набора эталонных ответов.
Что вам понадобится
- Веб-браузер, например Chrome.
- Проект Google Cloud с включенной функцией выставления счетов, или
- Аккаунт Gmail. В следующем разделе вы узнаете, как получить бесплатный кредит в размере 5 долларов на этот практический курс и создать новый проект.
Этот практический семинар предназначен для разработчиков всех уровней, включая начинающих. Вы будете использовать интерфейс командной строки Google Cloud Shell и код Python для разработки ADK. Вам не обязательно быть экспертом в Python, но базовое понимание того, как читать код, поможет вам усвоить основные концепции.
2. Прежде чем начать
Создайте проект в Google Cloud.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Запустить Cloud Shell
Cloud Shell — это среда командной строки, работающая в Google Cloud и поставляемая с предустановленными необходимыми инструментами.
- В верхней части консоли Google Cloud нажмите кнопку «Активировать Cloud Shell» :

- После подключения к Cloud Shell выполните следующую команду для проверки аутентификации в Cloud Shell:
gcloud auth list
- Выполните следующую команду, чтобы убедиться, что ваш проект настроен для использования с gcloud:
gcloud config list project
- Для настройки проекта используйте следующую команду:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Включить API
- Выполните эту команду, чтобы включить все необходимые API и сервисы:
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- После успешного выполнения команды вы должны увидеть сообщение, похожее на показанное ниже:
Operation "operations/..." finished successfully.
3. Создайте набор данных BigQuery.
- Выполните следующую команду в Cloud Shell, чтобы создать новый набор данных с именем ecommerce в BigQuery:
bq mk --dataset --location=US ecommerce
Статическое подмножество общедоступного набора данных BigQuery thelook_ecommerce сохраняется в виде файлов AVRO в общедоступном хранилище Google Cloud Storage.
- Выполните эту команду в Cloud Shell, чтобы загрузить эти файлы Avro в BigQuery в виде таблиц (events, order_items, products, users, orders):
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
Этот процесс может занять несколько минут.
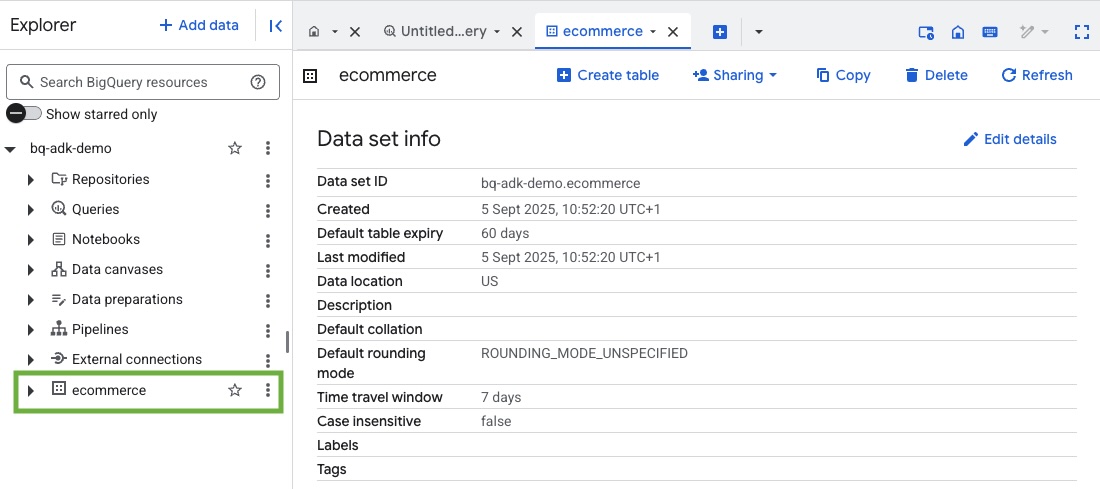
- Убедитесь, что набор данных и таблицы созданы, посетив консоль BigQuery в вашем проекте Google Cloud:
4. Подготовка среды для агентов ADK.
Вернитесь в Cloud Shell и убедитесь, что вы находитесь в своей домашней директории. Мы создадим виртуальную среду Python и установим необходимые пакеты.
- Откройте новую вкладку терминала в Cloud Shell и выполните эту команду, чтобы создать папку с именем bigquery-adk-codelab и перейти в неё:
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- Создайте виртуальную среду Python:
python -m venv .venv
- Активируйте виртуальную среду:
source .venv/bin/activate
- Установите пакеты Python ADK и AI-Platform от Google. Пакеты AI-Platform и pandas необходимы для работы с агентом BigQuery:
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. Создайте приложение ADK.
Теперь давайте создадим нашего агента BigQuery. Этот агент будет предназначен для ответа на вопросы на естественном языке о данных, хранящихся в BigQuery.
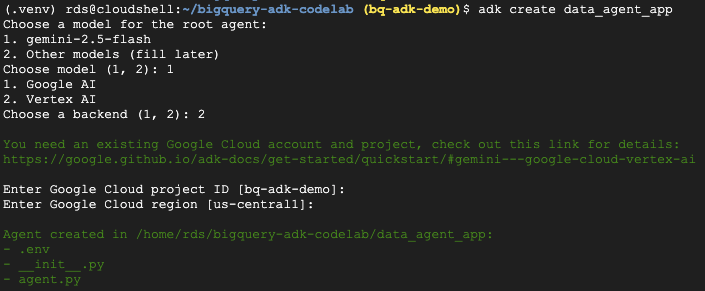
- Выполните команду утилиты adk create , чтобы создать новое приложение-агент с необходимыми папками и файлами:
adk create data_agent_app
Следуйте инструкциям:
- Выберите модель gemini-2.5-flash.
- Выберите Vertex AI для бэкэнда.
- Подтвердите свой идентификатор проекта Google Cloud по умолчанию и регион.
Пример взаимодействия показан ниже:
- Нажмите кнопку «Открыть редактор» в Cloud Shell, чтобы открыть редактор Cloud Shell и просмотреть созданные папки и файлы:

Обратите внимание на сгенерированные файлы:
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: Помечает папку как модуль Python.
- agent.py: Содержит исходное определение агента.
- .env: Содержит переменные окружения для вашего проекта (возможно, вам потребуется нажать «Вид» > «Открыть скрытые файлы», чтобы просмотреть этот файл).
Обновите все переменные, которые были неправильно установлены в ответ на запросы:
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. Определите своего агента и назначьте ему набор инструментов BigQuery.
Чтобы определить агент ADK, взаимодействующий с BigQuery с помощью набора инструментов BigQuery, замените существующее содержимое файла agent.py следующим кодом.
Необходимо обновить идентификатор проекта в инструкциях агента, указав фактический идентификатор вашего проекта:
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
Набор инструментов BigQuery предоставляет агенту возможности для получения метаданных и выполнения SQL-запросов к данным BigQuery. Для использования набора инструментов необходима аутентификация, наиболее распространенными вариантами которой являются учетные данные приложения по умолчанию (ADC) для разработки, интерактивная аутентификация OAuth, когда агенту необходимо действовать от имени конкретного пользователя, или учетные данные сервисной учетной записи для безопасной аутентификации на уровне производственной среды.
Отсюда вы можете пообщаться со своим агентом , вернувшись в Cloud Shell и выполнив следующую команду:
adk web
Вы должны увидеть уведомление о том, что веб-сервер запущен:
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
Нажмите на указанную ссылку, чтобы открыть веб-версию ADK — вы сможете задать своему агенту несколько вопросов о наборе данных:
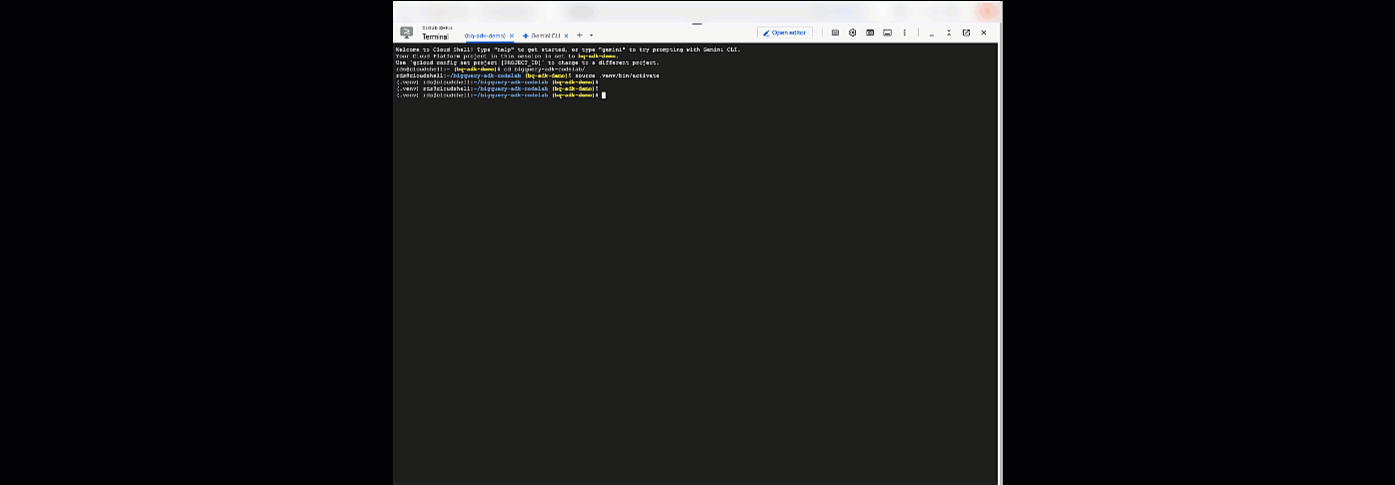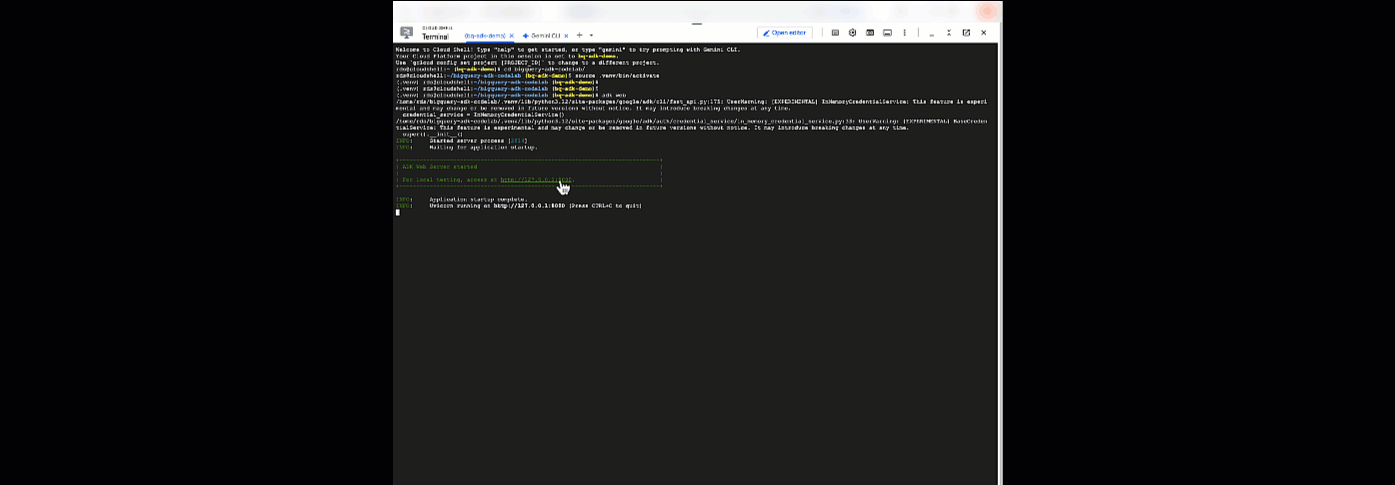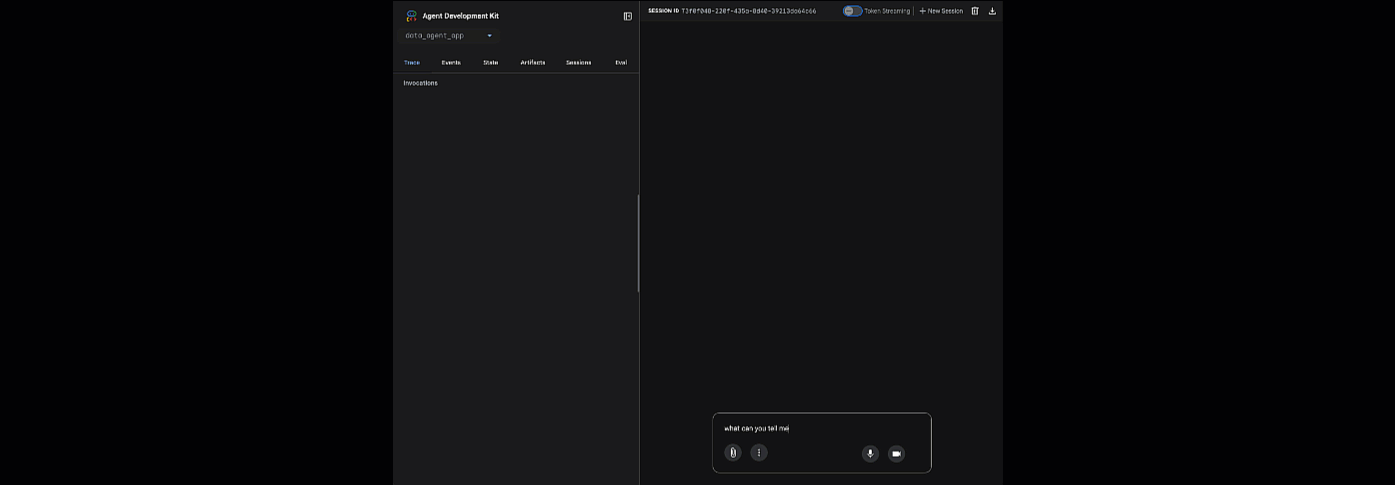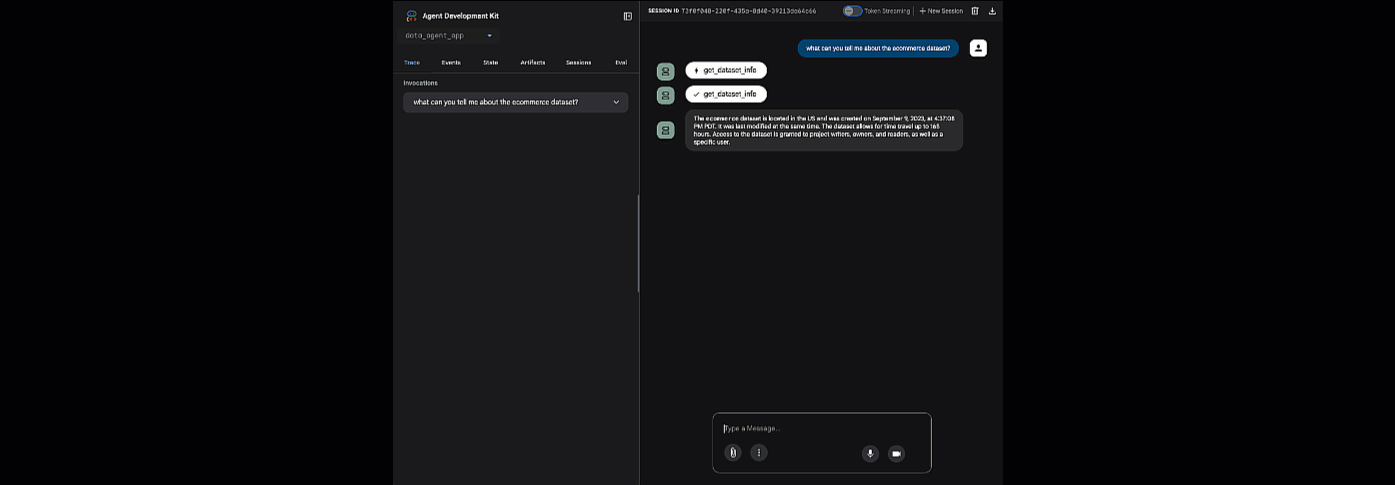
Закройте веб-интерфейс ADK и нажмите Ctrl + C в терминале, чтобы остановить веб-сервер.
7. Подготовьте своего агента к оценке.
Теперь, когда вы определили свой агент BigQuery, вам нужно сделать его работоспособным для оценки.
Приведённый ниже код определяет функцию run_conversation , которая обрабатывает ход диалога, создавая агента, запуская сессию и обрабатывая события для получения окончательного ответа.
- Вернитесь в Cloud Editor и создайте новый файл с именем
run_agent.pyв каталоге bigquery-adk-codelab, затем скопируйте и вставьте приведенный ниже код:
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
Приведённый ниже код определяет вспомогательные функции для вызова этой исполняемой функции и возврата результата. Он также включает вспомогательные функции, которые выводят и сохраняют результаты вычисления:
- Создайте новый файл с именем
utils.pyв каталоге bigquery-adk-codelab и скопируйте/вставьте следующий код в файл utils.py:
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. Создайте набор данных для оценки.
Для оценки вашего агента вам потребуется создать набор данных для оценки , определить метрики оценки и запустить задачу оценки .
Набор данных для оценки содержит список вопросов ( подсказок ) и соответствующих им правильных ответов ( ссылок ). Сервис оценки будет использовать эти пары для сравнения ответов вашего агента и определения их точности.
- Создайте новый файл с именем evaluation_dataset.json в каталоге bigquery-adk-codelab и скопируйте/вставьте приведенный ниже набор данных для оценки:
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. Определите критерии оценки.
Теперь мы воспользуемся двумя пользовательскими метриками для оценки способности агента отвечать на вопросы, связанные с вашими данными BigQuery, каждая из которых выставляет оценку от 1 до 5:
- Показатель фактической точности: Этот показатель оценивает, насколько все данные и факты, представленные в ответе, являются точными и корректными по сравнению с истинной реальностью.
- Показатель полноты: Этот показатель измеряет, включает ли ответ всю ключевую информацию, запрошенную пользователем и присутствующую в правильном ответе, без каких-либо существенных упущений.
- Наконец, создайте новый файл с именем
evaluate_agent.pyв каталоге bigquery-adk-codelab и скопируйте/вставьте код определения метрик в файл evaluate_agent.py:
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
Я также добавил метрику TrajectorySingleToolUse для оценки траектории . При наличии этих метрик вызовы агента (включая генерируемый и выполняемый им необработанный SQL-код для BigQuery) будут включены в ответ на оценку, что позволит провести детальный анализ.
Метрика TrajectorySingleToolUse определяет, использовал ли агент тот или иной инструмент. В данном случае я выбрал list_table_ids, поскольку мы ожидаем, что этот инструмент будет вызываться для каждого вопроса в оценочном наборе данных. В отличие от других метрик траектории, эта метрика не требует указания всех ожидаемых вызовов инструментов и аргументов для каждого вопроса в оценочном наборе данных.
10. Создайте задание для оценки.
Функция EvalTask принимает набор данных для оценки и пользовательские метрики и настраивает новый эксперимент по оценке.
Функция run_eval является основным механизмом оценки. Она выполняет цикл по задаче EvalTask, запуская вашего агента для каждого вопроса в наборе данных. Для каждого вопроса она записывает ответ агента, а затем использует определенные вами ранее метрики для его оценки.
Скопируйте и вставьте следующий код в конец файла evaluate_agent.py :
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
Результаты суммируются и сохраняются в JSON-файл.
11. Проведите оценку.
Теперь, когда у вас есть агент, метрики оценки и набор данных для оценки, вы можете запустить оценку.
Вернитесь в Cloud Shell, убедитесь, что вы находитесь в каталоге bigquery-adk-codelab, и запустите скрипт оценки, используя следующую команду:
python evaluate_agent.py
В процессе оценки вы будете видеть результаты, похожие на эти:
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
Если вы столкнетесь с ошибками, подобными приведенным ниже, это просто означает, что агент не запустил ни одного инструмента для конкретного запуска; вы можете подробнее изучить поведение агента на следующем шаге.
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
Интерпретация результатов:
Перейдите в папку eval_results в каталоге data_agent_app и откройте файл с результатами оценки, названный bq_agent_eval_results_*.json :
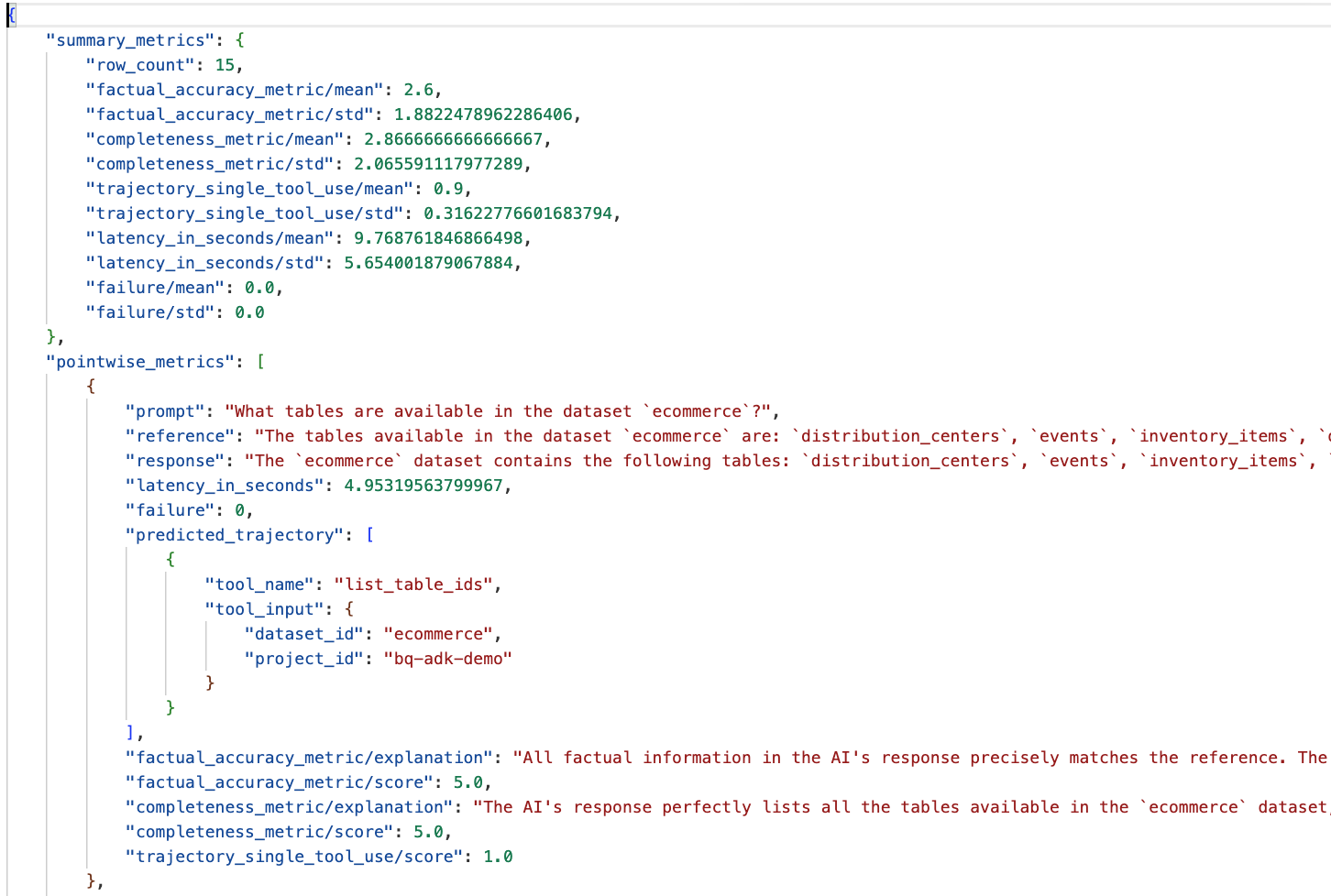
- Сводные показатели: Предоставляют агрегированное представление о производительности вашего агента по всему набору данных.
- Точность и полнота фактов: оценка, близкая к 5, указывает на более высокую точность и полноту. Каждому вопросу будет присвоена оценка, а также письменное объяснение причин присвоения этой оценки.
- Прогнозируемая траектория: это список вызовов инструментов, использованных агентами для получения конечного ответа. Это позволит нам увидеть все SQL-запросы, сгенерированные агентом.
Мы видим, что средний балл по полноте и фактической точности составляет 2,87 и 2,6 соответственно.
Результаты не очень хорошие! Давайте попробуем улучшить способность нашего агента отвечать на вопросы.
12. Улучшите результаты оценки работы вашего агента.
Перейдите к файлу agent.py в каталоге bigquery-adk-codelab и обновите модель агента и системные инструкции. Не забудьте заменить <YOUR_PROJECT_ID> на идентификатор вашего проекта:
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
Теперь вернитесь в терминал и повторно запустите оценку:
python evaluate_agent.py
Вы должны увидеть, что результаты теперь намного лучше:
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
Оценка вашего агента — это итеративный процесс. Для дальнейшего улучшения результатов оценки вы можете изменить системные инструкции, параметры модели или даже метаданные в BigQuery — ознакомьтесь с этими советами и рекомендациями, чтобы получить дополнительные идеи.
13. Уборка
Чтобы избежать дальнейших списаний средств с вашего аккаунта Google Cloud, важно удалить ресурсы, созданные нами в ходе этого семинара.
Если вы создавали какие-либо конкретные наборы данных или таблицы BigQuery для этого практического занятия (например, набор данных по электронной коммерции), возможно, вам стоит их удалить:
bq rm -r $PROJECT_ID:ecommerce
Чтобы удалить каталог bigquery-adk-codelab и его содержимое:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. Поздравляем!
Поздравляем! Вы успешно создали и оценили агент BigQuery с помощью комплекта разработки агентов (ADK). Теперь вы понимаете, как настроить агент ADK с инструментами BigQuery и измерить его производительность, используя пользовательские метрики оценки.