
1. บทนำ
ใน Codelab นี้ คุณจะได้เรียนรู้วิธีสร้าง Agent ที่ตอบคำถามเกี่ยวกับข้อมูลที่เก็บไว้ใน BigQuery โดยใช้ Agent Development Kit (ADK) นอกจากนี้ คุณยังประเมิน Agent เหล่านี้ได้โดยใช้บริการ GenAI Evaluation ของ Vertex AI ดังนี้
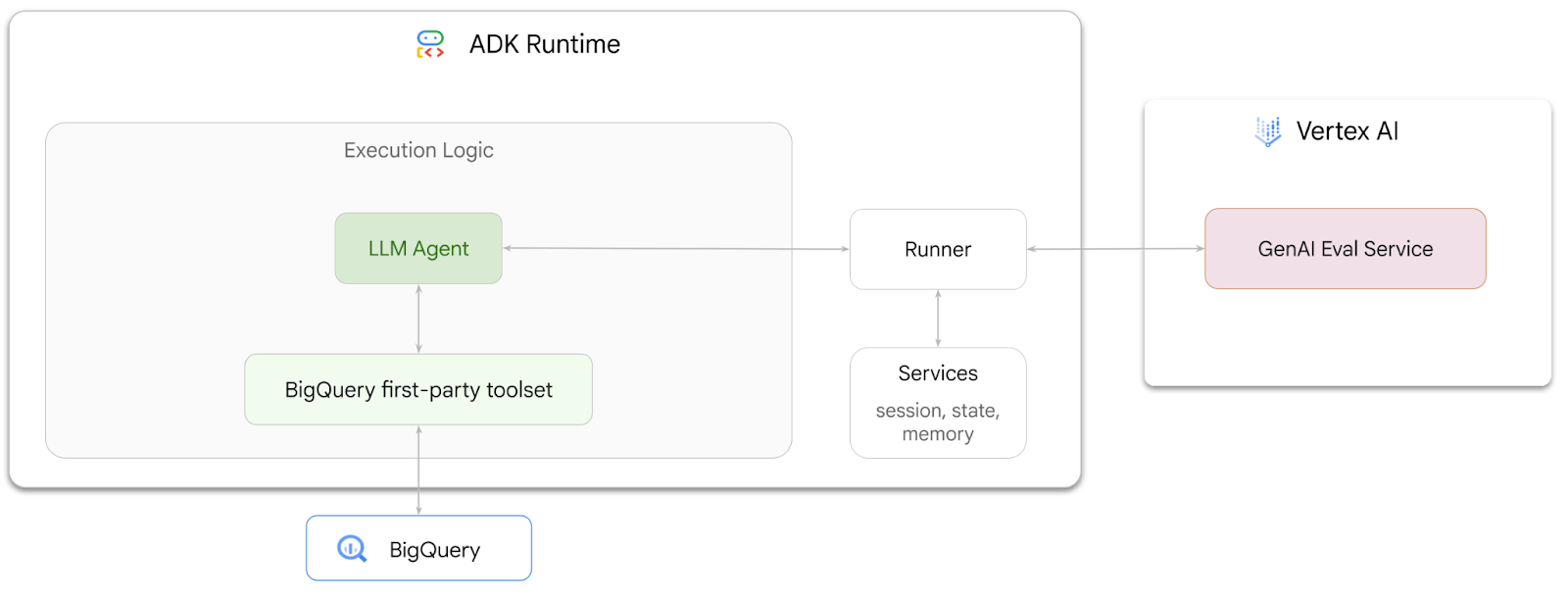
สิ่งที่คุณต้องทำ
- สร้าง Agent ข้อมูลวิเคราะห์แบบบทสนทนาใน ADK
- ติดตั้งชุดเครื่องมือของบุคคลที่หนึ่งสำหรับ BigQuery ให้กับ Agent นี้ เพื่อให้ Agent สามารถโต้ตอบกับข้อมูลที่จัดเก็บไว้ใน BigQuery ได้
- สร้างกรอบการประเมินสำหรับ Agent โดยใช้บริการ GenAI Evaluation ของ Vertex AI
- เรียกใช้การประเมินใน Agent นี้เทียบกับชุดคำตอบที่สมบูรณ์
สิ่งที่คุณต้องมี
- เว็บเบราว์เซอร์ เช่น Chrome
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน หรือ
- บัญชี Gmail ส่วนถัดไปจะแสดงวิธีแลกสิทธิ์เครดิต $5 ฟรีสำหรับ Codelab นี้และตั้งค่าโปรเจ็กต์ใหม่
Codelab นี้มีไว้สำหรับนักพัฒนาซอฟต์แวร์ทุกระดับ รวมถึงผู้เริ่มต้น คุณจะใช้อินเทอร์เฟซบรรทัดคำสั่งใน Google Cloud Shell และโค้ด Python สำหรับการพัฒนา ADK คุณไม่จำเป็นต้องเป็นผู้เชี่ยวชาญด้าน Python แต่ความเข้าใจพื้นฐานเกี่ยวกับวิธีอ่านโค้ดจะช่วยให้คุณเข้าใจแนวคิดต่างๆ ได้
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
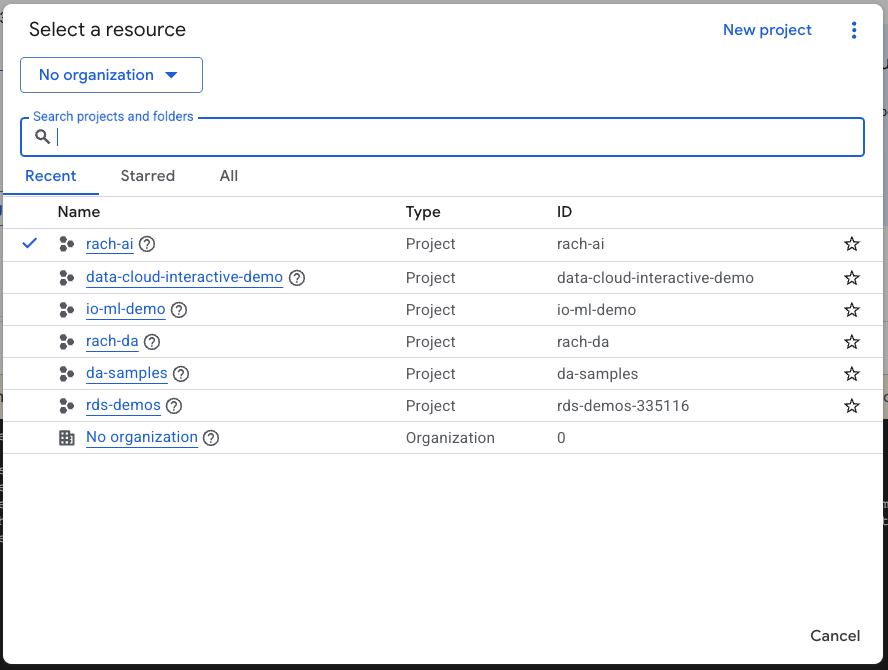
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
เริ่มต้น Cloud Shell
Cloud Shell คือสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud ซึ่งโหลดเครื่องมือที่จำเป็นไว้ล่วงหน้า
- คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้เรียกใช้คำสั่งต่อไปนี้เพื่อยืนยันการตรวจสอบสิทธิ์ใน Cloud Shell
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้เพื่อยืนยันว่าโปรเจ็กต์ได้รับการกำหนดค่าให้ใช้กับ gcloud แล้ว
gcloud config list project
- ใช้คำสั่งต่อไปนี้เพื่อตั้งค่าโปรเจ็กต์
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
เปิดใช้ API
- เรียกใช้คำสั่งนี้เพื่อเปิดใช้ API และบริการที่จำเป็นทั้งหมด
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- เมื่อดำเนินการคำสั่งสำเร็จแล้ว คุณควรเห็นข้อความที่คล้ายกับข้อความที่แสดงด้านล่าง
Operation "operations/..." finished successfully.
3. สร้างชุดข้อมูล BigQuery
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อสร้างชุดข้อมูลใหม่ชื่อ ecommerce ใน BigQuery
bq mk --dataset --location=US ecommerce
ระบบจะบันทึกชุดข้อมูลย่อยแบบคงที่ของชุดข้อมูลสาธารณะ BigQuery thelook_ecommerce เป็นไฟล์ AVRO ใน Bucket ของ Google Cloud Storage สาธารณะ
- เรียกใช้คำสั่งนี้ใน Cloud Shell เพื่อโหลดไฟล์ Avro เหล่านี้ลงใน BigQuery เป็นตาราง (events, order_items, products, users, orders)
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
กระบวนการนี้อาจใช้เวลาสักครู่
- ยืนยันว่าระบบได้สร้างชุดข้อมูลและตารางแล้วโดยไปที่คอนโซล BigQuery ในโปรเจ็กต์ Google Cloud
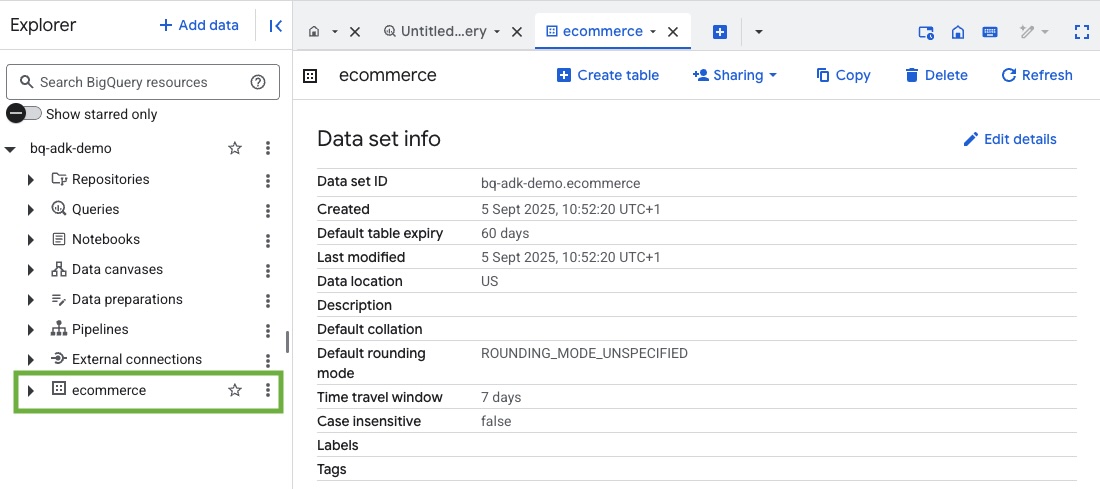
4. เตรียมสภาพแวดล้อมสำหรับ Agent ของ ADK
กลับไปที่ Cloud Shell และตรวจสอบว่าคุณอยู่ในไดเรกทอรีหลัก เราจะสร้างสภาพแวดล้อมเสมือนของ Python และติดตั้งแพ็กเกจที่จำเป็น
- เปิดแท็บเทอร์มินัลใหม่ใน Cloud Shell แล้วเรียกใช้คำสั่งนี้เพื่อสร้างและไปยังโฟลเดอร์ชื่อ bigquery-adk-codelab
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- สร้างสภาพแวดล้อมเสมือนของ Python
python -m venv .venv
- เปิดใช้งานสภาพแวดล้อมเสมือนโดยใช้คำสั่งต่อไปนี้
source .venv/bin/activate
- ติดตั้งแพ็กเกจ Python ของ ADK และ AI Platform ของ Google คุณต้องมีแพลตฟอร์ม AI และแพ็กเกจ pandas เพื่อประเมิน BigQuery Agent
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. สร้างแอปพลิเคชัน ADK
ตอนนี้มาสร้าง BigQuery Agent กัน เราจะออกแบบ Agent นี้เพื่อตอบคำถามที่เป็นภาษาธรรมชาติเกี่ยวกับข้อมูลที่จัดเก็บไว้ใน BigQuery
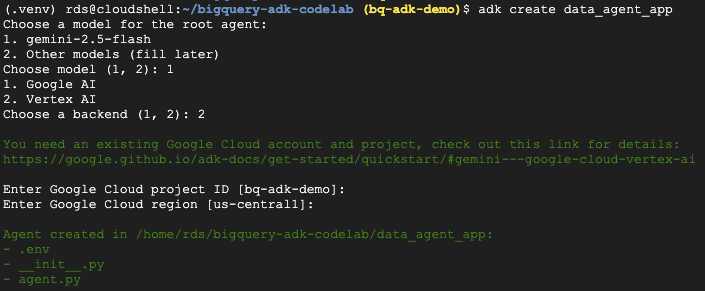
- เรียกใช้คำสั่งยูทิลิตี adk create เพื่อสร้างโครงร่างแอปพลิเคชันตัวแทนใหม่ที่มีโฟลเดอร์และไฟล์ที่จำเป็น
adk create data_agent_app
ทำตามข้อความแจ้ง
- เลือก gemini-2.5-flash สำหรับโมเดล
- เลือก Vertex AI สำหรับแบ็กเอนด์
- ยืนยันรหัสโปรเจ็กต์ Google Cloud และภูมิภาคเริ่มต้น
ตัวอย่างการโต้ตอบแสดงอยู่ด้านล่าง
- คลิกปุ่มเปิดตัวแก้ไขใน Cloud Shell เพื่อเปิด Cloud Shell Editor และดูโฟลเดอร์และไฟล์ที่สร้างขึ้นใหม่

โปรดทราบว่าไฟล์ที่สร้างขึ้นมีดังนี้
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py: ทำเครื่องหมายโฟลเดอร์เป็นโมดูล Python
- agent.py: มีคำจำกัดความเริ่มต้นของ Agent
- .env: มีตัวแปรสภาพแวดล้อมสำหรับโปรเจ็กต์ (คุณอาจต้องคลิกดู > สลับไฟล์ที่ซ่อนเพื่อดูไฟล์นี้)
อัปเดตตัวแปรที่ตั้งค่าไม่ถูกต้องจากพรอมต์
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. กำหนด Agent และมอบหมายชุดเครื่องมือ BigQuery ให้กับ Agent
หากต้องการกำหนด Agent ของ ADK ที่โต้ตอบกับ BigQuery โดยใช้ชุดเครื่องมือ BigQuery ให้แทนที่เนื้อหาที่มีอยู่ของไฟล์ agent.py ด้วยโค้ดต่อไปนี้
คุณต้องอัปเดตรหัสโปรเจ็กต์ในวิธีการของเอเจนต์เป็นรหัสโปรเจ็กต์จริง
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
ชุดเครื่องมือ BigQuery ช่วยให้ตัวแทนมีความสามารถในการดึงข้อมูลเมตาและเรียกใช้การค้นหา SQL ในข้อมูล BigQuery หากต้องการใช้ชุดเครื่องมือ คุณต้องตรวจสอบสิทธิ์ โดยตัวเลือกที่พบบ่อยที่สุดคือข้อมูลรับรองเริ่มต้นของแอปพลิเคชัน (ADC) สำหรับการพัฒนา, OAuth แบบอินเทอร์แอกทีฟสำหรับกรณีที่ตัวแทนต้องดำเนินการในนามของผู้ใช้ที่เฉพาะเจาะจง หรือข้อมูลเข้าสู่ระบบของบัญชีบริการสำหรับการตรวจสอบสิทธิ์ระดับเวอร์ชันที่ใช้งานจริงที่ปลอดภัย
จากตรงนี้ คุณสามารถแชทกับตัวแทนได้โดยกลับไปที่ Cloud Shell แล้วเรียกใช้คำสั่งนี้
adk web
คุณควรเห็นการแจ้งเตือนที่ระบุว่าเว็บเซิร์ฟเวอร์เริ่มทำงานแล้ว
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
คลิก URL ที่ระบุเพื่อเปิดใช้ adk web - คุณสามารถถามคำถามเกี่ยวกับชุดข้อมูลกับตัวแทนได้
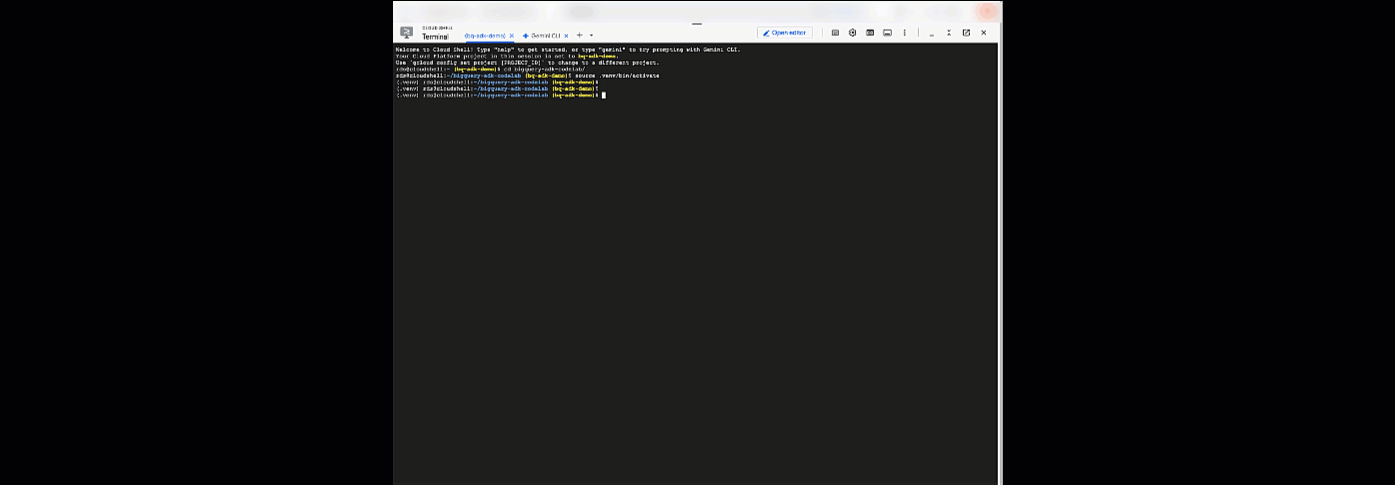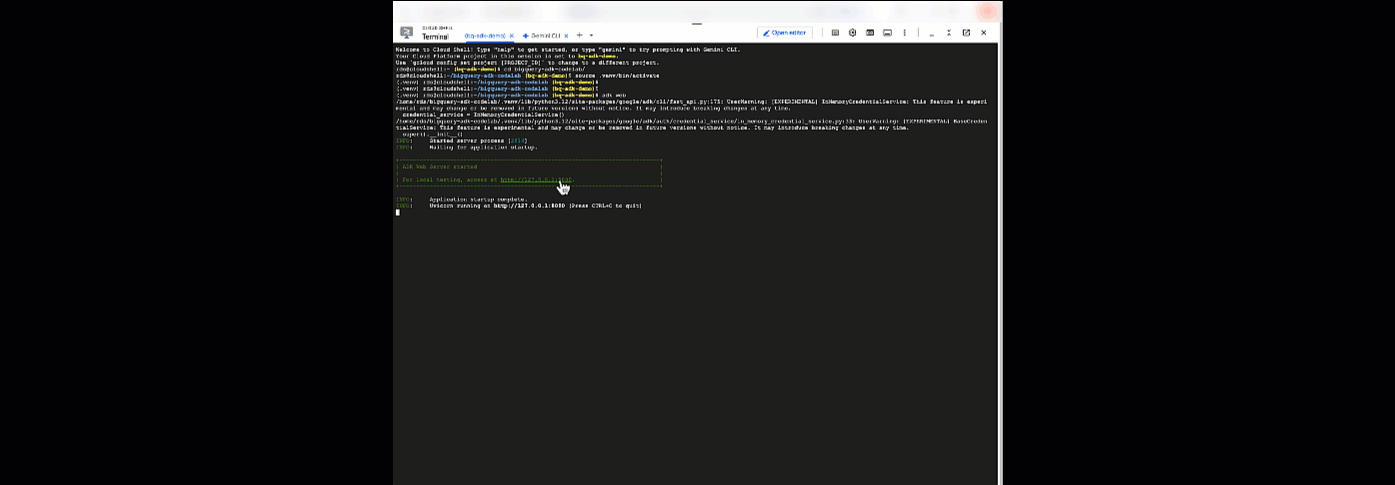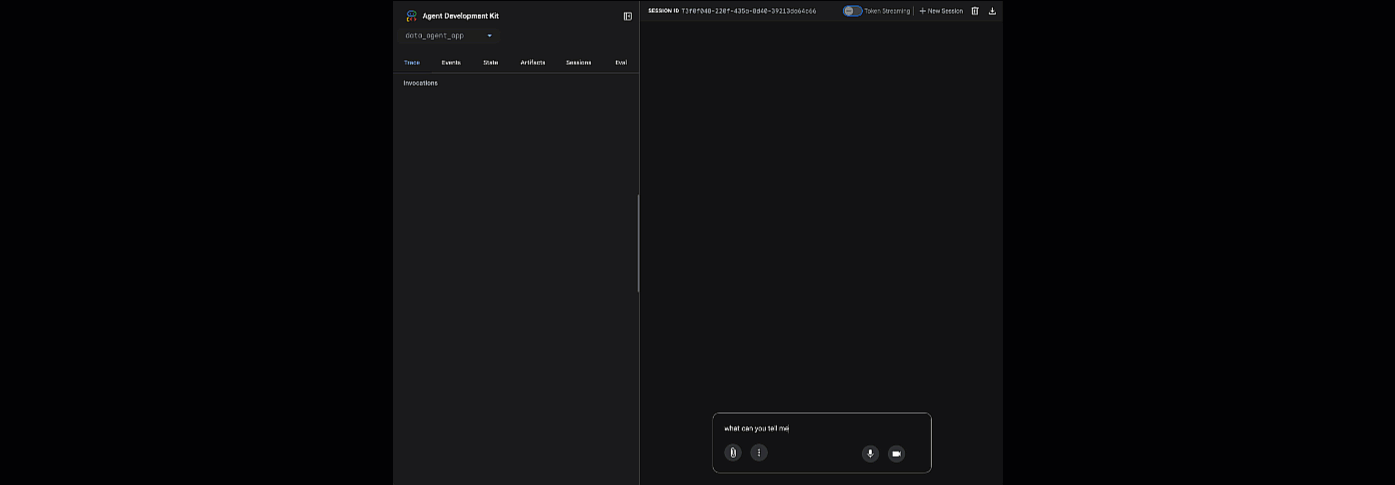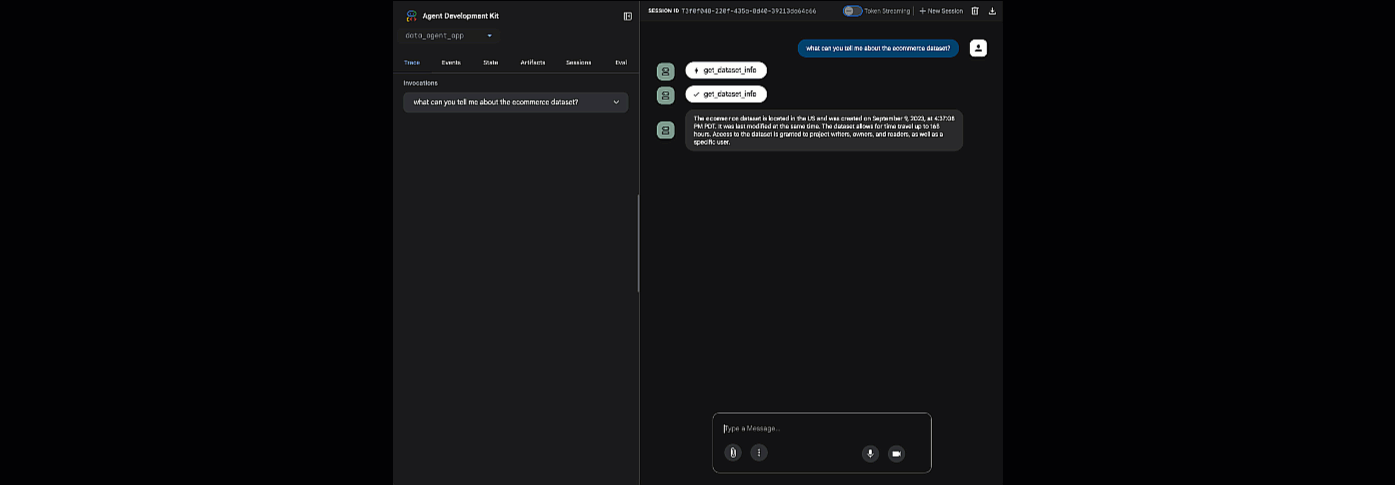
ปิดเว็บ adk แล้วกด Ctrl + C ในเทอร์มินัลเพื่อปิดเว็บเซิร์ฟเวอร์
7. เตรียมตัวแทนให้พร้อมสำหรับการประเมิน
เมื่อกำหนด Agent BigQuery แล้ว คุณต้องทำให้ Agent เรียกใช้ได้เพื่อการประเมิน
โค้ดด้านล่างกำหนดฟังก์ชัน run_conversation ซึ่งจัดการโฟลว์การสนทนาโดยการสร้าง Agent เรียกใช้เซสชัน และประมวลผลเหตุการณ์เพื่อดึงข้อมูลคำตอบสุดท้าย
- กลับไปที่ Cloud Editor แล้วสร้างไฟล์ใหม่ชื่อ
run_agent.pyในไดเรกทอรี bigquery-adk-codelab แล้วคัดลอก/วางโค้ดด้านล่าง
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
โค้ดด้านล่างกำหนดฟังก์ชันยูทิลิตีเพื่อเรียกใช้ฟังก์ชันที่เรียกใช้ได้นี้และแสดงผลลัพธ์ นอกจากนี้ ยังมีฟังก์ชันตัวช่วยที่พิมพ์และบันทึกผลการประเมินด้วย
- สร้างไฟล์ใหม่ชื่อ
utils.pyในไดเรกทอรี bigquery-adk-codelab แล้วคัดลอก/วางโค้ดนี้ลงในไฟล์ utils.py
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. สร้างชุดข้อมูลการประเมิน
หากต้องการประเมินเอเจนต์ คุณจะต้องสร้างชุดข้อมูลการประเมิน กำหนดเมตริกการประเมิน และเรียกใช้ชิ้นงานการประเมิน
ชุดข้อมูลการประเมินมีรายการคำถาม (พรอมต์) และคำตอบที่ถูกต้องที่เกี่ยวข้อง (ข้อมูลอ้างอิง) บริการประเมินจะใช้คู่ข้อความเหล่านี้เพื่อเปรียบเทียบคำตอบของเอเจนต์และพิจารณาว่าคำตอบนั้นถูกต้องหรือไม่
- สร้างไฟล์ใหม่ชื่อ evaluation_dataset.json ในไดเรกทอรี bigquery-adk-codelab แล้วคัดลอก/วางชุดข้อมูลการประเมินด้านล่าง
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. กำหนดเมตริกการประเมิน
ตอนนี้เราจะใช้เมตริกที่กำหนดเอง 2 รายการเพื่อประเมินความสามารถของเอเจนต์ในการตอบคำถามที่เกี่ยวข้องกับข้อมูล BigQuery ของคุณ โดยทั้ง 2 รายการจะให้คะแนนตั้งแต่ 1 ถึง 5 ดังนี้
- เมตริกความถูกต้องตามข้อเท็จจริง: เมตริกนี้จะประเมินว่าข้อมูลและข้อเท็จจริงทั้งหมดที่นำเสนอในคำตอบนั้นแม่นยำและถูกต้องเมื่อเทียบกับข้อมูลจากการสังเกตการณ์โดยตรงหรือไม่
- เมตริกความสมบูรณ์: เมตริกนี้จะวัดว่าคำตอบมีข้อมูลสำคัญทั้งหมดที่ผู้ใช้ขอและอยู่ในคำตอบที่ถูกต้องหรือไม่ โดยไม่มีการละเว้นข้อมูลสำคัญ
- สุดท้าย ให้สร้างไฟล์ใหม่ชื่อ
evaluate_agent.pyในไดเรกทอรี bigquery-adk-codelab แล้วคัดลอก/วางโค้ดคำจำกัดความเมตริกลงในไฟล์ evaluate_agent.py
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
นอกจากนี้ ฉันยังรวมเมตริก TrajectorySingleToolUse สำหรับการประเมินวิถีด้วย เมื่อมีเมตริกเหล่านี้ การเรียกใช้เครื่องมือของ Agent (รวมถึง SQL ดิบที่สร้างและเรียกใช้กับ BigQuery) จะรวมอยู่ในคำตอบการประเมิน ซึ่งจะช่วยให้ตรวจสอบได้อย่างละเอียด
เมตริก TrajectorySingleToolUse จะพิจารณาว่าเอเจนต์ใช้เครื่องมือใดเครื่องมือหนึ่งหรือไม่ ในกรณีนี้ ฉันเลือก list_table_ids เนื่องจากเราคาดหวังว่าจะมีการเรียกใช้เครื่องมือนี้สำหรับทุกคำถามในชุดข้อมูลการประเมิน เมตริกนี้ไม่เหมือนกับเมตริกวิถีอื่นๆ ตรงที่คุณไม่จำเป็นต้องระบุการเรียกเครื่องมือและอาร์กิวเมนต์ที่คาดไว้ทั้งหมดสำหรับคำถามแต่ละข้อในชุดข้อมูลการประเมิน
10. สร้างงานการประเมิน
EvalTask จะใช้ชุดข้อมูลการประเมินและเมตริกที่กำหนดเองเพื่อตั้งค่าการทดลองการประเมินใหม่
ฟังก์ชัน run_eval เป็นเครื่องมือหลักสำหรับการประเมิน โดยจะวนซ้ำ EvalTask เพื่อเรียกใช้เอเจนต์กับคำถามแต่ละข้อในชุดข้อมูล สำหรับคำถามแต่ละข้อ ระบบจะบันทึกคำตอบของตัวแทน แล้วใช้เมตริกที่คุณกำหนดไว้ก่อนหน้านี้เพื่อให้คะแนน
คัดลอก/วางโค้ดต่อไปนี้ที่ด้านล่างของไฟล์ evaluate_agent.py
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
ระบบจะสรุปผลลัพธ์และบันทึกลงในไฟล์ JSON
11. ทำการประเมิน
ตอนนี้คุณมีเอเจนต์ เมตริกการประเมิน และชุดข้อมูลการประเมินพร้อมแล้ว คุณก็เรียกใช้การประเมินได้
กลับไปที่ Cloud Shell ตรวจสอบว่าคุณอยู่ในไดเรกทอรี bigquery-adk-codelab แล้วเรียกใช้สคริปต์การประเมินโดยใช้คำสั่งต่อไปนี้
python evaluate_agent.py
คุณจะเห็นเอาต์พุตที่คล้ายกับเอาต์พุตนี้เมื่อการประเมินคืบหน้า
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
หากพบข้อผิดพลาดเช่นที่แสดงด้านล่าง แสดงว่าเอเจนต์ไม่ได้เรียกใช้เครื่องมือใดๆ สำหรับการเรียกใช้หนึ่งๆ คุณสามารถตรวจสอบลักษณะการทำงานของเอเจนต์เพิ่มเติมได้ในขั้นตอนถัดไป
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
การตีความผลลัพธ์:
ไปที่โฟลเดอร์ eval_results ในไดเรกทอรี data_agent_app แล้วเปิดไฟล์ผลการประเมินที่ชื่อ bq_agent_eval_results_*.json:
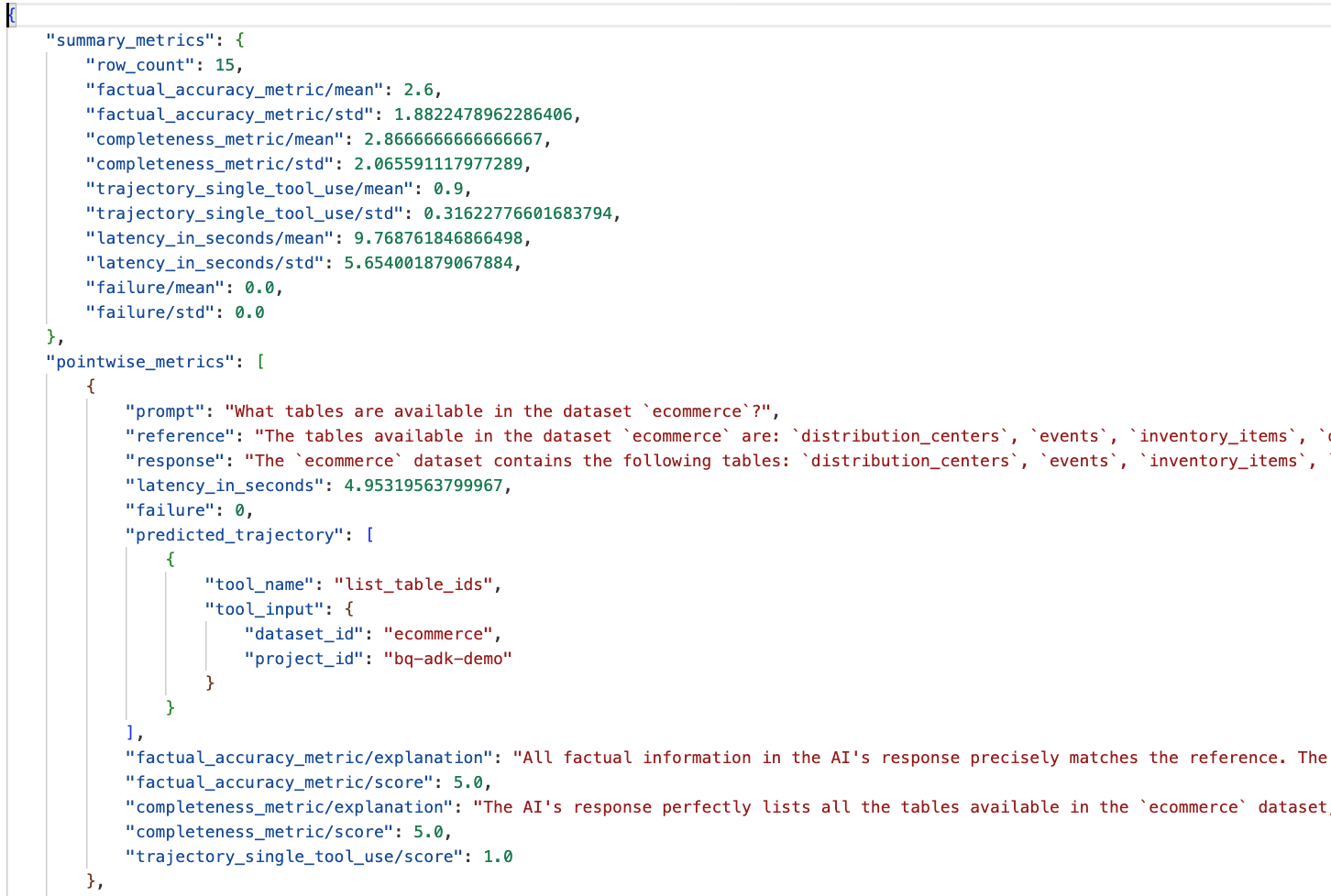
- เมตริกสรุป: แสดงมุมมองแบบรวมของประสิทธิภาพของเอเจนต์ในชุดข้อมูล
- เมตริกแบบจุดต่อจุดสำหรับความถูกต้องและความสมบูรณ์ของข้อเท็จจริง: คะแนนที่ใกล้เคียง 5 แสดงถึงความถูกต้องและความสมบูรณ์ที่สูงกว่า คำถามแต่ละข้อจะมีคะแนนพร้อมคำอธิบายเป็นลายลักษณ์อักษรว่าเหตุใดจึงได้คะแนนดังกล่าว
- วิถีที่คาดการณ์: นี่คือรายการการเรียกใช้เครื่องมือที่เอเจนต์ใช้เพื่อให้ได้คำตอบสุดท้าย ซึ่งจะช่วยให้เราเห็นคำค้นหา SQL ที่ตัวแทนสร้างขึ้น
เราจะเห็นว่าคะแนนเฉลี่ยของความสมบูรณ์และความถูกต้องตามข้อเท็จจริงโดยเฉลี่ยอยู่ที่ 2.87 และ 2.6 ตามลำดับ
ผลลัพธ์ไม่ค่อยดีนัก มาลองปรับปรุงความสามารถของเอเจนต์ในการตอบคำถามกัน
12. ปรับปรุงผลการประเมินของ Agent
ไปที่ agent.py ในไดเรกทอรี bigquery-adk-codelab แล้วอัปเดตโมเดลและคำสั่งของระบบของเอเจนต์ อย่าลืมแทนที่ <YOUR_PROJECT_ID> ด้วยรหัสโปรเจ็กต์ของคุณ
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
ตอนนี้กลับไปที่เทอร์มินัลแล้วเรียกใช้การประเมินอีกครั้ง
python evaluate_agent.py
คุณจะเห็นว่าผลลัพธ์ดีขึ้นมาก
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
การประเมินเอเจนต์เป็นกระบวนการที่ต้องทำซ้ำๆ หากต้องการปรับปรุงผลการประเมินเพิ่มเติม คุณสามารถปรับแต่งวิธีการของระบบ พารามิเตอร์ของโมเดล หรือแม้แต่ข้อมูลเมตาใน BigQuery ได้ โปรดดูเคล็ดลับและเทคนิคเหล่านี้เพื่อดูแนวคิดเพิ่มเติม
13. ล้าง
คุณควรลบทรัพยากรที่เราสร้างขึ้นในเวิร์กช็อปนี้เพื่อหลีกเลี่ยงการเรียกเก็บเงินอย่างต่อเนื่องในบัญชี Google Cloud
หากสร้างชุดข้อมูลหรือตาราง BigQuery เฉพาะสำหรับ Codelab นี้ (เช่น ชุดข้อมูลอีคอมเมิร์ซ) คุณอาจต้องการลบชุดข้อมูลหรือตารางดังกล่าวโดยทำดังนี้
bq rm -r $PROJECT_ID:ecommerce
วิธีนำไดเรกทอรี bigquery-adk-codelab และเนื้อหาในไดเรกทอรีออก
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. ขอแสดงความยินดี
ยินดีด้วย คุณสร้างและประเมิน BigQuery Agent โดยใช้ Agent Development Kit (ADK) เรียบร้อยแล้ว ตอนนี้คุณทราบวิธีตั้งค่า ADK Agent ด้วยเครื่องมือ BigQuery และวัดประสิทธิภาพโดยใช้เมตริกการประเมินที่กำหนดเองแล้ว