
1. 简介
在此 Codelab 中,您将学习如何使用智能体开发套件 (ADK) 构建智能体,解答有关存储在 BigQuery 中的数据的问题。您还将使用 Vertex AI 的 GenAI Evaluation Service 评估这些代理:
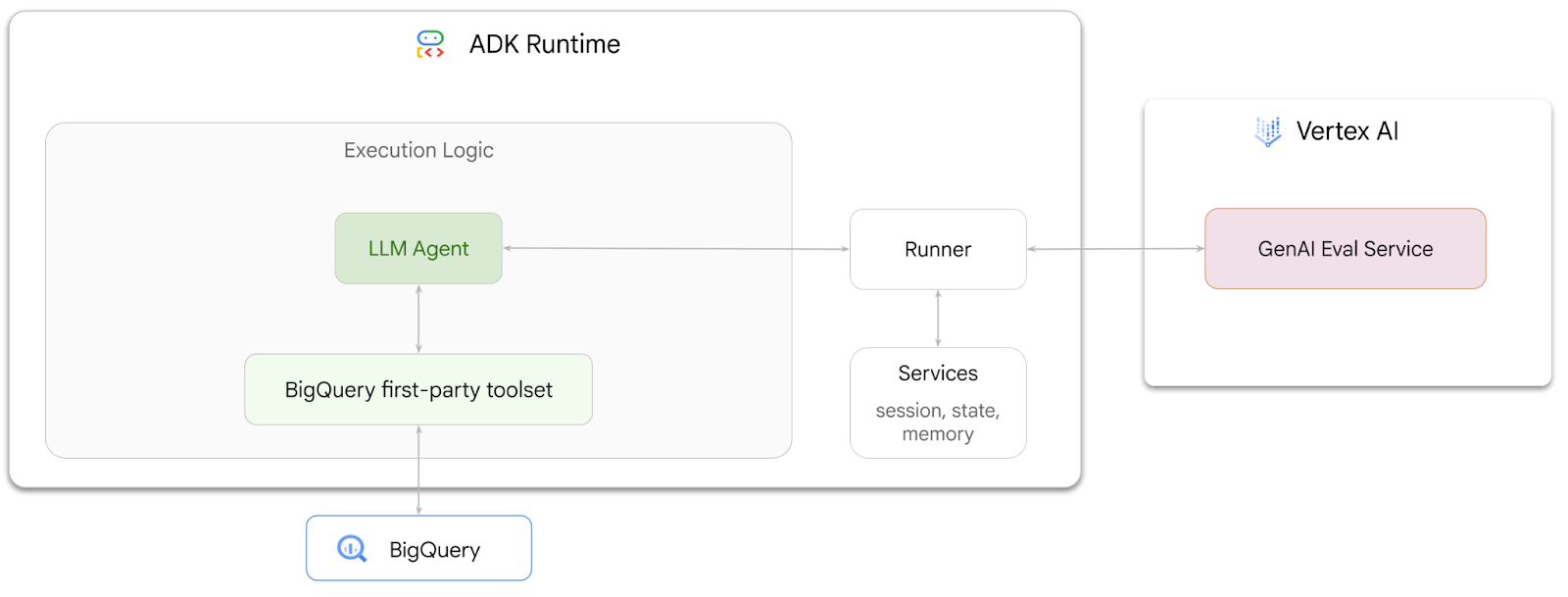
实践内容
- 在 ADK 中构建对话式分析智能体
- 为该代理配备 ADK 的BigQuery 第一方工具集,以便其与存储在 BigQuery 中的数据进行交互
- 使用 Vertex AI GenAI Evaluation Service 为智能体创建评估框架
- 针对一组标准回答对此代理运行评估
所需条件
- 网络浏览器,例如 Chrome
- 启用了结算功能的 Google Cloud 项目,或
- Gmail 账号。下一部分将介绍如何兑换此 Codelab 的 5 美元免费赠金并设置新项目
本 Codelab 适合各种水平的开发者,包括新手。您将使用 Google Cloud Shell 中的命令行界面和 Python 代码进行 ADK 开发。您无需成为 Python 专家,但对如何读取代码有基本的了解有助于您理解这些概念。
2. 准备工作
创建 Google Cloud 项目
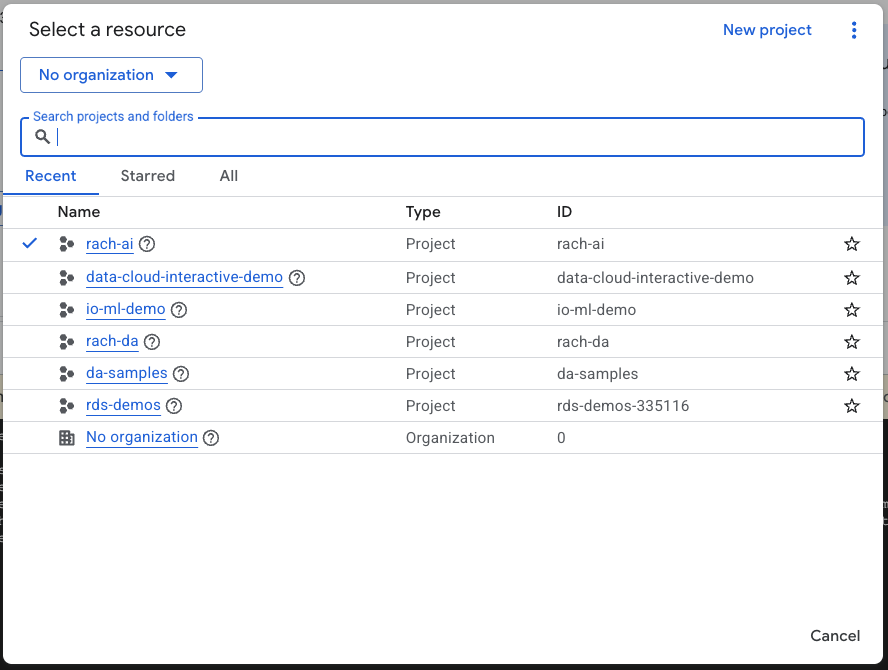
- 在 Google Cloud 控制台的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
启动 Cloud Shell
Cloud Shell 是在 Google Cloud 中运行的命令行环境,预加载了必要的工具。
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell:

- 连接到 Cloud Shell 后,运行以下命令以验证您在 Cloud Shell 中的身份验证:
gcloud auth list
- 运行以下命令,确认您的项目已配置为可与 gcloud 搭配使用:
gcloud config list project
- 使用以下命令设置项目:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
启用 API
- 运行以下命令以启用所有必需的 API 和服务:
gcloud services enable bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
- 成功执行该命令后,您应该会看到类似如下所示的消息:
Operation "operations/..." finished successfully.
3. 创建 BigQuery 数据集
- 在 Cloud Shell 中运行以下命令,在 BigQuery 中创建一个名为 ecommerce 的新数据集:
bq mk --dataset --location=US ecommerce
BigQuery 公共数据集 thelook_ecommerce 的静态子集以 AVRO 文件的形式保存在公共 Google Cloud Storage 存储分区中。
- 在 Cloud Shell 中运行此命令,将这些 Avro 文件作为表(events、order_items、products、users、orders)加载到 BigQuery 中:
bq load --source_format=AVRO --autodetect \
ecommerce.events \
gs://sample-data-and-media/thelook_dataset_snapshot/events/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.order_items \
gs://sample-data-and-media/thelook_dataset_snapshot/order_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.products \
gs://sample-data-and-media/thelook_dataset_snapshot/products/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.users \
gs://sample-data-and-media/thelook_dataset_snapshot/users/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.orders \
gs://sample-data-and-media/thelook_dataset_snapshot/orders/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.inventory_items \
gs://sample-data-and-media/thelook_dataset_snapshot/inventory_items/*.avro.gz
bq load --source_format=AVRO --autodetect \
ecommerce.distribution_centers \
gs://sample-data-and-media/thelook_dataset_snapshot/distribution_centers/*.avro.gz
此过程可能需要几分钟时间。
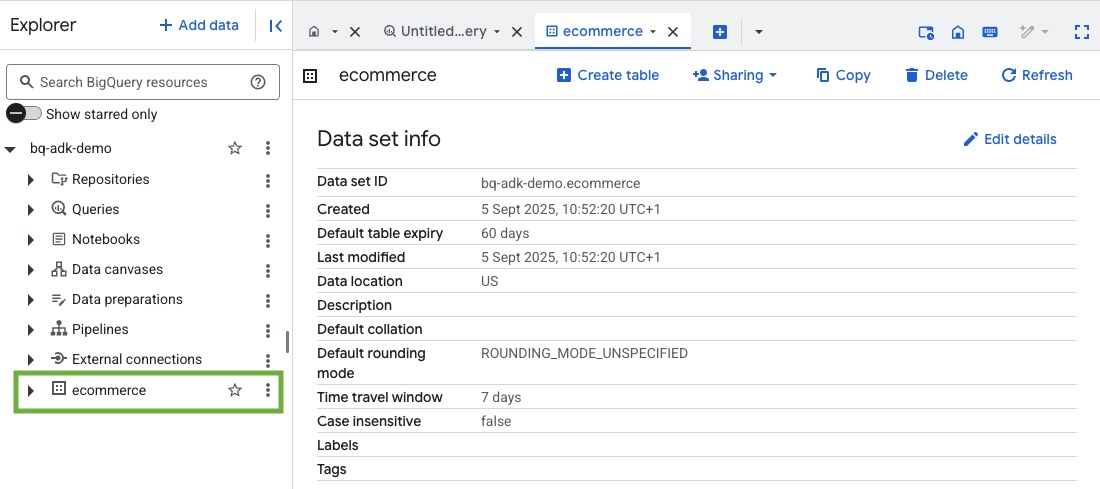
- 如需验证是否已创建数据集和表,请在您的 Google Cloud 项目中访问 BigQuery 控制台:
4. 为 ADK 智能体准备环境
返回到 Cloud Shell,并确保您位于主目录中。我们将创建一个虚拟 Python 环境并安装所需的软件包。
- 在 Cloud Shell 中打开新的终端标签页,然后运行以下命令来创建并进入名为 bigquery-adk-codelab 的文件夹:
mkdir bigquery-adk-codelab
cd bigquery-adk-codelab
- 创建虚拟 Python 环境:
python -m venv .venv
- 激活此虚拟环境:
source .venv/bin/activate
- 安装 Google 的 ADK 和 AI-Platform Python 软件包。需要 AI 平台和 pandas 软件包来评估 bigquery 代理:
pip install google-adk google-cloud-aiplatform[evaluation] pandas
5. 创建 ADK 应用
现在,我们来创建 BigQuery Agent。此智能体将设计为能够回答有关存储在 BigQuery 中的数据的自然语言问题。
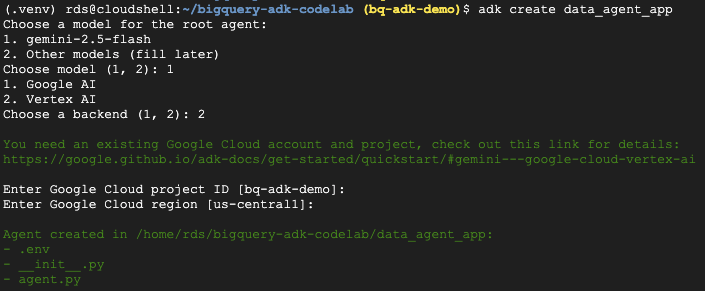
- 运行 ADK 创建实用程序命令,以搭建包含必要文件夹和文件的新代理应用:
adk create data_agent_app
按照提示操作:
- 选择 gemini-2.5-flash 作为模型。
- 选择 Vertex AI 作为后端。
- 确认您的默认 Google Cloud 项目 ID 和区域。
下面显示了一个互动示例:
- 点击 Cloud Shell 中的“打开编辑器”按钮,打开 Cloud Shell 编辑器并查看新创建的文件夹和文件:

请注意生成的文件:
bigquery-adk-codelab/
├── .venv/
└── data_agent_app/
├── __init__.py
├── agent.py
└── .env
- init.py::将相应文件夹标记为 Python 模块。
- agent.py::包含初始代理定义。
- .env:包含项目的环境变量(您可能需要依次点击“查看”>“显示/不显示隐藏文件”才能查看此文件)
根据提示更新未正确设置的任何变量:
GOOGLE_GENAI_USE_VERTEXAI=1 GOOGLE_CLOUD_PROJECT=<YOUR_GOOGLE_PROJECT_ID> GOOGLE_CLOUD_LOCATION=<YOUR_GOOGLE_CLOUD_REGION>
6. 定义智能体并为其分配 BigQuery 工具集
如需定义一个使用 BigQuery 工具集与 BigQuery 交互的 ADK 智能体,请将 agent.py 文件的现有内容替换为以下代码。
您必须将代理指令中的项目 ID 更新为您的实际项目 ID:
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
import google.auth
import dotenv
dotenv.load_dotenv()
credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(credentials=credentials)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config
)
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a BigQuery data analysis agent.
You are able to answer questions on data stored in project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
def get_bigquery_agent():
return root_agent
BigQuery 工具集为代理提供了以下功能:提取元数据和对 BigQuery 数据执行 SQL 查询。如需使用该工具集,您必须进行身份验证,最常见的选项包括:用于开发的“应用默认凭证”(ADC)、用于在代理需要代表特定用户执行操作时使用的“交互式 OAuth”,以及用于安全、生产级身份验证的“服务账号凭据”。
在此处,您可以返回到 Cloud Shell 并运行以下命令,与代理聊天:
adk web
您应该会看到一条通知,告知您 Web 服务器已启动:
... INFO: Started server process [2735] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000
点击提供的网址以启动 adk web - 您可以向智能体询问有关数据集的一些问题:
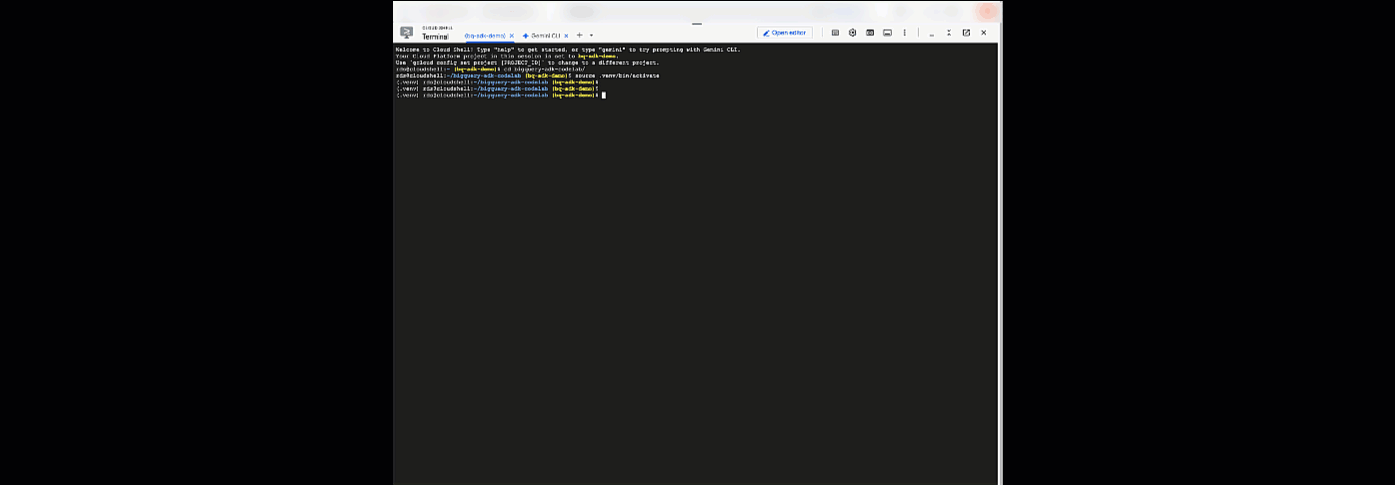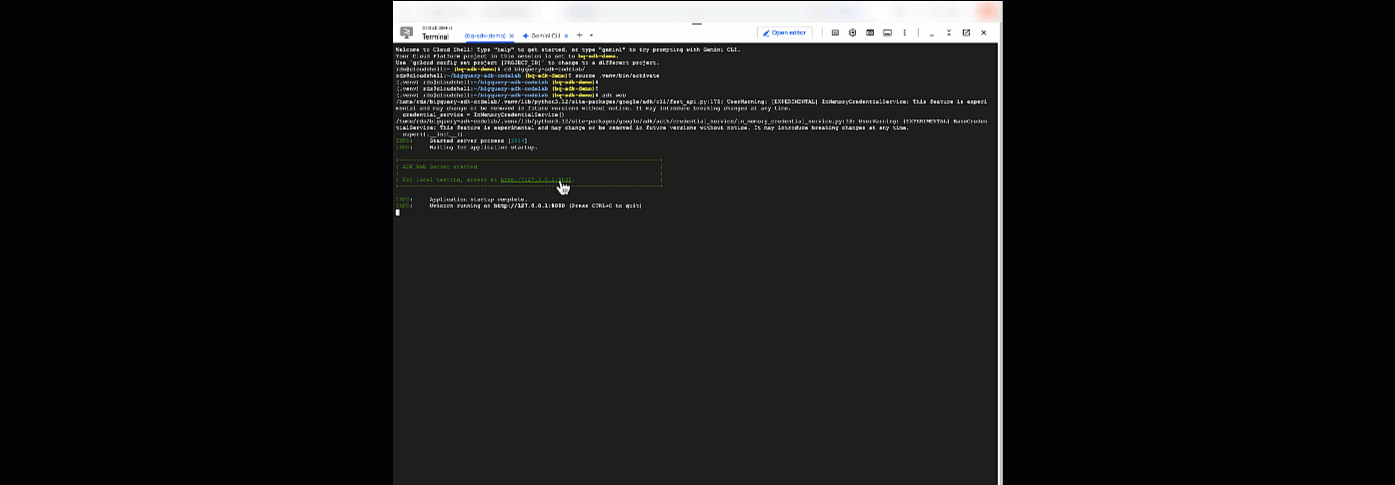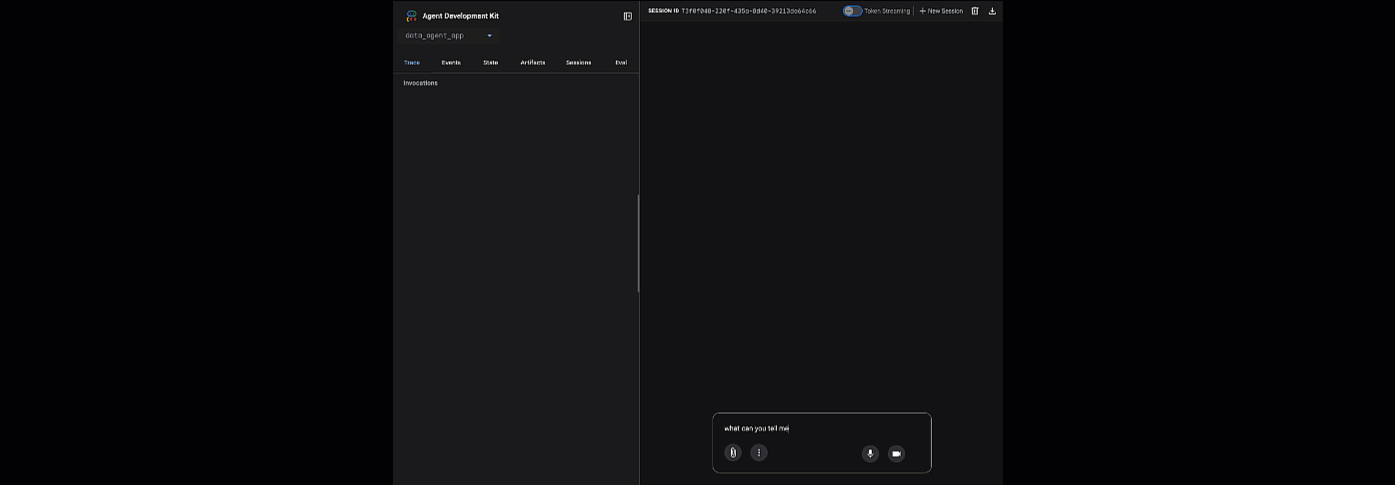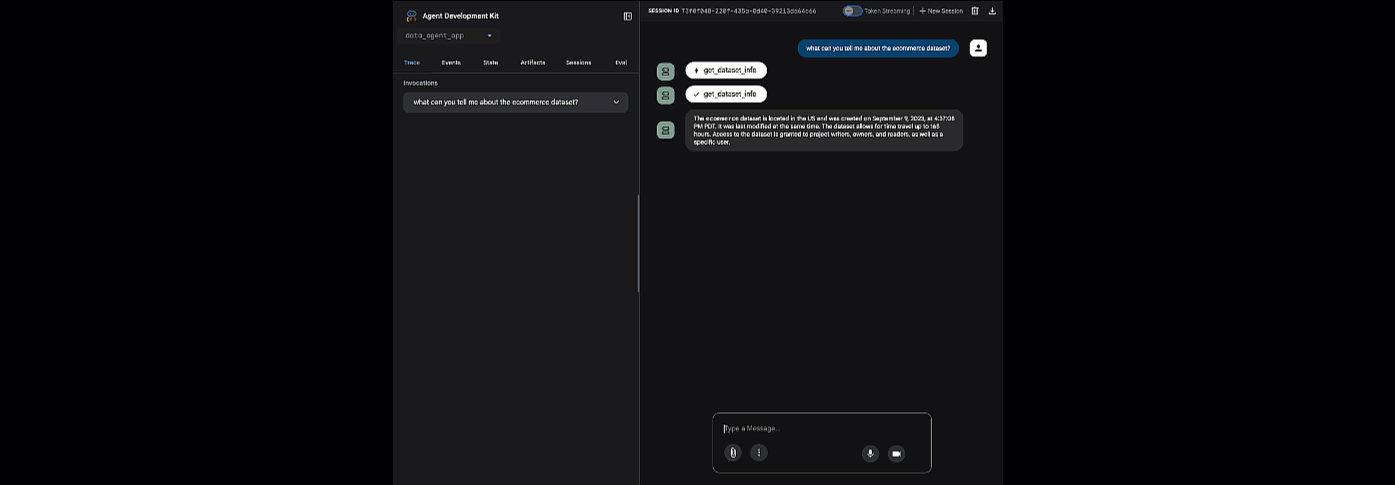
关闭 adk web,然后在终端中按 Ctrl + C 以关闭 Web 服务器。
7. 准备好要评估的代理
现在,您已定义 BigQuery 代理,接下来需要使其可运行以进行评估。
以下代码定义了一个函数 run_conversation,该函数通过创建代理、运行会话和处理事件来检索最终响应,从而处理对话流程。
- 返回 Cloud 编辑器,在 bigquery-adk-codelab 目录中创建一个名为
run_agent.py的新文件,然后复制/粘贴以下代码:
from data_agent_app.agent import get_bigquery_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
import uuid
APP_NAME = "data_agent_app"
USER_ID = "biquery_user_101"
async def run_conversation(prompt: str):
"""Runs a conversation with the BigQuery agent using the ADK Runner."""
session_service = InMemorySessionService()
session_id = f"{APP_NAME}-{uuid.uuid4().hex[:8]}"
root_agent = get_bigquery_agent()
runner = Runner(
agent=root_agent, app_name=APP_NAME, session_service=session_service
)
session = await session_service.create_session(
app_name=APP_NAME, user_id=USER_ID, session_id=session_id
)
final_response_text = "Unable to retrieve final response."
tool_calls = []
try:
# Run the agent and process the events as they are generated
async for event in runner.run_async(
user_id=USER_ID,
session_id=session_id,
new_message=types.Content(role="user", parts=[types.Part(text=prompt)]),
):
if (
event.content
and event.content.parts
and event.content.parts[0].function_call
):
func_call = event.content.parts[0].function_call
tool_call = {
"tool_name": func_call.name,
"tool_input": dict(func_call.args),
}
tool_calls.append(tool_call)
if event.is_final_response():
if event.content and event.content.parts:
final_response_text = event.content.parts[0].text
break
except Exception as e:
print(f"Error in run_conversation: {e}")
final_response_text = f"An error occurred during the conversation: {e}"
return {
"response": final_response_text,
"predicted_trajectory": tool_calls
}
以下代码定义了用于调用此可运行函数并返回结果的实用函数。它还包含用于打印和保存评估结果的辅助函数:
- 在 bigquery-adk-codelab 目录中创建一个名为
utils.py的新文件,并将以下代码复制/粘贴到 utils.py 文件中:
import json
import os
import asyncio
import run_agent
import numbers
import math
def get_agent_response(prompt: str) -> dict:
"""Invokes the agent with a prompt and returns its response."""
try:
response = asyncio.run(run_agent.run_conversation(prompt)) # Invoke the agent
return response
except Exception as e:
return {"response": "Error: Agent failed to produce a response."}
def save_evaluation_results(eval_result, experiment_run):
"""Processes, saves, and prints the evaluation results for a single run."""
os.makedirs("eval_results", exist_ok=True)
output_file_path = os.path.join(
"eval_results", f"bq_agent_eval_results_{experiment_run}.json"
)
# Prepare data for JSON serialization
eval_result_dict = {
"summary_metrics": eval_result.summary_metrics,
"pointwise_metrics": eval_result.metrics_table.to_dict("records"),
}
# --- Save the results as a JSON file ---
with open(output_file_path, "w") as f:
json.dump(eval_result_dict, f, indent=4)
print(f"Results for run '{experiment_run}' saved to {output_file_path}")
def print_evaluation_summary(eval_result):
"""Prints a detailed summary of the evaluation results, including summary-level and aggregated pointwise metrics."""
pointwise_metrics = eval_result.metrics_table
# Print summary metrics for the current run
summary_metrics = eval_result.summary_metrics
if summary_metrics:
for key, value in summary_metrics.items():
if isinstance(value, numbers.Real) and not math.isnan(value):
value = f"{value:.2f}"
metric_name = key.replace("/mean", "").replace("_", " ").title()
print(f"- {metric_name}: {key}: {value}")
else:
print("No summary metrics found for this run.")
print("\n" + "=" * 50 + "\n")
if not pointwise_metrics.empty:
total_questions = len(pointwise_metrics)
avg_completeness_score = pointwise_metrics["completeness_metric/score"].mean()
avg_factual_accuracy_score = pointwise_metrics[
"factual_accuracy_metric/score"
].mean()
print("\n" + "=" * 50 + "\n")
print("--- Aggregated Evaluation Summary ---")
print(f"Total questions in evaluation dataset: {total_questions}")
print(f"Average Completeness Score: {avg_completeness_score:.2f}")
print(f"Average Factual Accuracy Score: {avg_factual_accuracy_score:.2f}")
print("\n" + "=" * 50 + "\n")
else:
print("\nNo successful evaluation runs were completed.")
8. 创建评估数据集
如需评估代理,您需要创建评估数据集、定义评估指标,以及运行评估任务。
评估数据集包含一系列问题(提示)及其对应的正确答案(参考答案)。评估服务将使用这些配对来比较代理的回答,并确定回答是否准确。
- 在 bigquery-adk-codelab 目录中创建一个名为 evaluation_dataset.json 的新文件,然后复制/粘贴以下评估数据集:
[
{
"prompt": "What tables are available in the dataset `ecommerce`?",
"reference": "The tables available in the dataset `ecommerce` are: `distribution_centers`, `events`, `inventory_items`, `order_items`, `orders`, `products`, and `users`."
},
{
"prompt": "How many users are there in total?",
"reference": "There are 100,000 users in total."
},
{
"prompt": "Find the email and age of the user with id 72685.",
"reference": "The email address of user 72685 is lindseybrennan@example.org and their age is 59."
},
{
"prompt": "How many orders have a status of Complete?",
"reference": "There are 31,077 orders with a status of 'complete'."
},
{
"prompt": "Which distribution center has the highest latitude, and what is it's latitude?",
"reference": "Chicago IL is the distribution center with the highest latitude, with a latitude of 41.84."
},
{
"prompt": "Retrieve the order id for all orders with a status of cancelled placed on the 1st June 2023 before 6am.",
"reference": "The order IDs for all orders with a status of 'cancelled' placed on the 1st June 2023 before 6am are: 26622, 49223"
},
{
"prompt": "What id the full name and user ids of the top 5 users with the most orders.",
"reference": "The top 5 users with the most orders are: Kristine Pennington (user ID 77359), Anthony Bright (user ID 4137), David Bean (user ID 30740), Michelle Wright (user ID 54563), and Matthew Reynolds (user ID 41136), each with 4 total orders."
},
{
"prompt": "Which distribution center is associated with the highest average retail price of its products, and what is the average retail price?",
"reference": "The distribution center associated with the highest average retail price of its products is Houston TX, with an average retail price of $69.74."
},
{
"prompt": "How many events were of type 'purchase' in Seoul during May 2024?",
"reference": "In May 2024, there were 57 'purchase' events recorded in Seoul."
},
{
"prompt": "For orders placed in June 2023, how many took three days or longer to be delivered after they were shipped?",
"reference": "In June 2023, there were 318 orders with a time difference of of 3 days or more between when they were shipped and delivered."
},
{
"prompt": "What are the names of the products and their respective retail price that have never been sold, but have a retail price greater than $210?",
"reference": "The products that have never been sold but have a retail price greater than $210 are:\n- Tommy Hilfiger Men's 2 Button Side Vent Windowpane Trim Fit Sport Coat, with a retail price of $249.9\n- MICHAEL Michael Kors Women's Hooded Leather Jacket: $211.11"
},
{
"prompt": "List the id and first name of users between the ages of 70 and 75 who have Facebook were sourced from Facebook and are located in California.",
"reference": "The users between the ages of 70 and 75 from California with 'Facebook' as their traffic source are:\n- Julie (ID: 25379)\n- Sherry (ID: 85196)\n- Kenneth (ID: 82238)\n- Lindsay (ID: 64079)\n- Matthew (ID: 99612)"
},
{
"prompt": "Identify the full name and user id of users over the age of 67 who live within 3.5 kilometers of any distribution_center.",
"reference": "The users over the age of 67 who live within 3.5 kilometers of any distribution center are:\n- William Campbell (user ID: 26082)\n- Becky Cantrell (user ID: 39008)"
},
{
"prompt": "What is the median age of users for each gender?",
"reference": "The median age for female users is 41, and the median age for male users is 41."
},
{
"prompt": "What is the average sale price of complete orders compared to returned orders, and what is the percentage difference (to two decimal places) between them?",
"reference": "The average sale price for 'Complete' orders was $59.56, while for 'Returned' orders it was $59.76. This represents a percentage difference of 0.34%."
}
]
9. 定义评估指标
现在,我们将使用两个自定义指标来评估智能体回答与 BigQuery 数据相关问题的能力,这两个指标都提供 1 到 5 的分数:
- 事实准确性指标:此指标用于评估与标准答案相比,回答中呈现的所有数据和事实是否准确无误。
- 完整性指标:此指标用于衡量回答是否包含用户请求的所有关键信息,以及是否包含正确答案中的所有关键信息,而不会遗漏任何重要信息。
- 最后,在 bigquery-adk-codelab 目录中创建一个名为
evaluate_agent.py的新文件,并将指标定义代码复制/粘贴到 evaluate_agent.py 文件中:
import uuid
import pandas as pd
from datetime import datetime
from vertexai.preview.evaluation import EvalTask
from vertexai.preview.evaluation.metrics import (
PointwiseMetricPromptTemplate,
PointwiseMetric,
TrajectorySingleToolUse,
)
from utils import save_evaluation_results, print_evaluation_summary, get_agent_response
factual_accuracy_metric = PointwiseMetric(
metric="factual_accuracy_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the factual accuracy of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if all factual information in the AI's answer is precise and correct when compared to the reference.""",
criteria={
"Accuracy": """The AI's answer must present factual information (numerical values, names, dates, specific values) that are **identical** to or an exact logical derivation from the reference.
- **Wording may vary, but the core factual information must be the same.**
- No numerical discrepancies.
- No incorrect names or identifiers.
- No fabricated or misleading details.
- Note: Minor rounding of numerical values that doesn't alter the core meaning or lead to significant misrepresentation is generally acceptable, assuming the prompt doesn't ask for exact precision."""
},
rating_rubric={
"5": "Excellent: The response is entirely factually correct. **All factual information precisely matches the reference.** There are absolutely no inaccuracies or misleading details.",
"3": "Good: The response is generally accurate, but contains minor, non-critical factual inaccuracies (e.g., a negligible rounding difference or slightly wrong detail) that do not impact the core understanding.",
"1": "Poor: The response contains significant factual errors, major numerical discrepancies, or fabricated information that makes the answer incorrect or unreliable."
},
input_variables=["prompt", "reference", "response"],
),
)
completeness_metric = PointwiseMetric(
metric="completeness_metric",
metric_prompt_template=PointwiseMetricPromptTemplate(
instruction="""You are an expert evaluator assessing the completeness of an AI's answer to a user's question, given a natural language prompt and a 'reference' (ground truth) answer. Your task is to determine if the AI's answer provides all the essential information requested by the user and present in the reference.""",
criteria={
"Completeness": """The AI's answer must include **all** key pieces of information explicitly or implicitly requested by the prompt and present in the reference.
- No omissions of critical facts.
- All requested attributes (e.g., age AND email, not just one) must be present.
- If the reference provides a multi-part answer, all parts must be covered."""
},
rating_rubric={
"5": "Excellent: The response is perfectly complete. **All key information requested by the prompt and present in the reference is included.** There are absolutely no omissions.",
"3": "Good: The response is mostly complete. It has only a slight, non-critical omission that does not impact the core understanding or utility of the answer.",
"1": "Poor: The response is critically incomplete. Essential parts of the requested information are missing, making the answer less useful or unusable for the user's purpose."
},
input_variables=["prompt", "reference", "response"],
),
)
tool_use_metric = TrajectorySingleToolUse(tool_name="list_table_ids")
我还添加了 TrajectorySingleToolUse 指标,用于轨迹评估。如果存在这些指标,评估响应中将包含代理工具调用(包括其生成并针对 BigQuery 执行的原始 SQL),以便进行详细检查。
TrajectorySingleToolUse 指标用于确定智能体是否使用了特定工具。在这种情况下,我选择了 list_table_ids,因为我们希望针对评估数据集中的每个问题调用此工具。与其他轨迹指标不同,此指标不需要您为评估数据集中的每个问题指定所有预期工具调用和实参。
10. 创建评估任务
EvalTask 接受评估数据集和自定义指标,并设置新的评估实验。
此函数 run_eval 是评估的主要引擎。它会循环遍历 EvalTask,针对数据集中的每个问题运行智能体。对于每个问题,它都会记录代理的回答,然后使用您之前定义的指标对其进行评分。
将以下代码复制/粘贴到 evaluate_agent.py 文件的底部:
def run_eval():
eval_dataset = pd.read_json("evaluation_dataset.json")
# Generate a unique run name
current_time = datetime.now().strftime("%Y%m%d-%H%M%S")
experiment_run_id = f"{current_time}-{uuid.uuid4().hex[:8]}"
print(f"--- Starting evaluation: ({experiment_run_id}) ---")
# Define the evaluation task with your dataset and metrics
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
factual_accuracy_metric,
completeness_metric,
tool_use_metric,
],
experiment="evaluate-bq-data-agent"
)
try:
eval_result = eval_task.evaluate(
runnable=get_agent_response, experiment_run_name=experiment_run_id
)
save_evaluation_results(eval_result, experiment_run_id)
print_evaluation_summary(eval_result)
except Exception as e:
print(f"An error occurred during evaluation run: {e}")
if __name__ == "__main__":
run_eval()
结果会进行总结并保存到 JSON 文件中。
11. 运行评估
现在,您已准备好智能体、评估指标和评估数据集,可以运行评估了。
返回 Cloud Shell,确保您位于 bigquery-adk-codelab 目录中,然后使用以下命令运行评估脚本:
python evaluate_agent.py
随着评估的进行,您将看到类似于以下内容的输出:
Evaluation Took:11.410560518999773 seconds Results for run '20250922-130011-300ea89b' saved to eval_results/bq_agent_eval_results_20250922-130011-300ea89b.json - Row Count: row_count: 15.00 - Factual Accuracy Metric: factual_accuracy_metric/mean: 2.60 - Factual Accuracy Metric/Std: factual_accuracy_metric/std: 1.88 - Completeness Metric: completeness_metric/mean: 2.87 - Completeness Metric/Std: completeness_metric/std: 2.07 - Trajectory Single Tool Use: trajectory_single_tool_use/mean: 0.90 - Trajectory Single Tool Use/Std: trajectory_single_tool_use/std: 0.32 - Latency In Seconds: latency_in_seconds/mean: 9.77 - Latency In Seconds/Std: latency_in_seconds/std: 5.65 - Failure: failure/mean: 0.00 - Failure/Std: failure/std: 0.00
如果您遇到任何类似以下的错误,这仅表示代理在特定运行中未调用任何工具;您可以在下一步中进一步检查代理行为。
Error encountered for metric trajectory_single_tool_use at dataset index 1: Error: 400 List of Field: trajectory_single_tool_use_input.instances[0].predicted_trajectory; Message: Required field is not set.
解读结果:
前往 data_agent_app 目录中的 eval_results 文件夹,然后打开名为 bq_agent_eval_results_*.json 的评估结果文件:
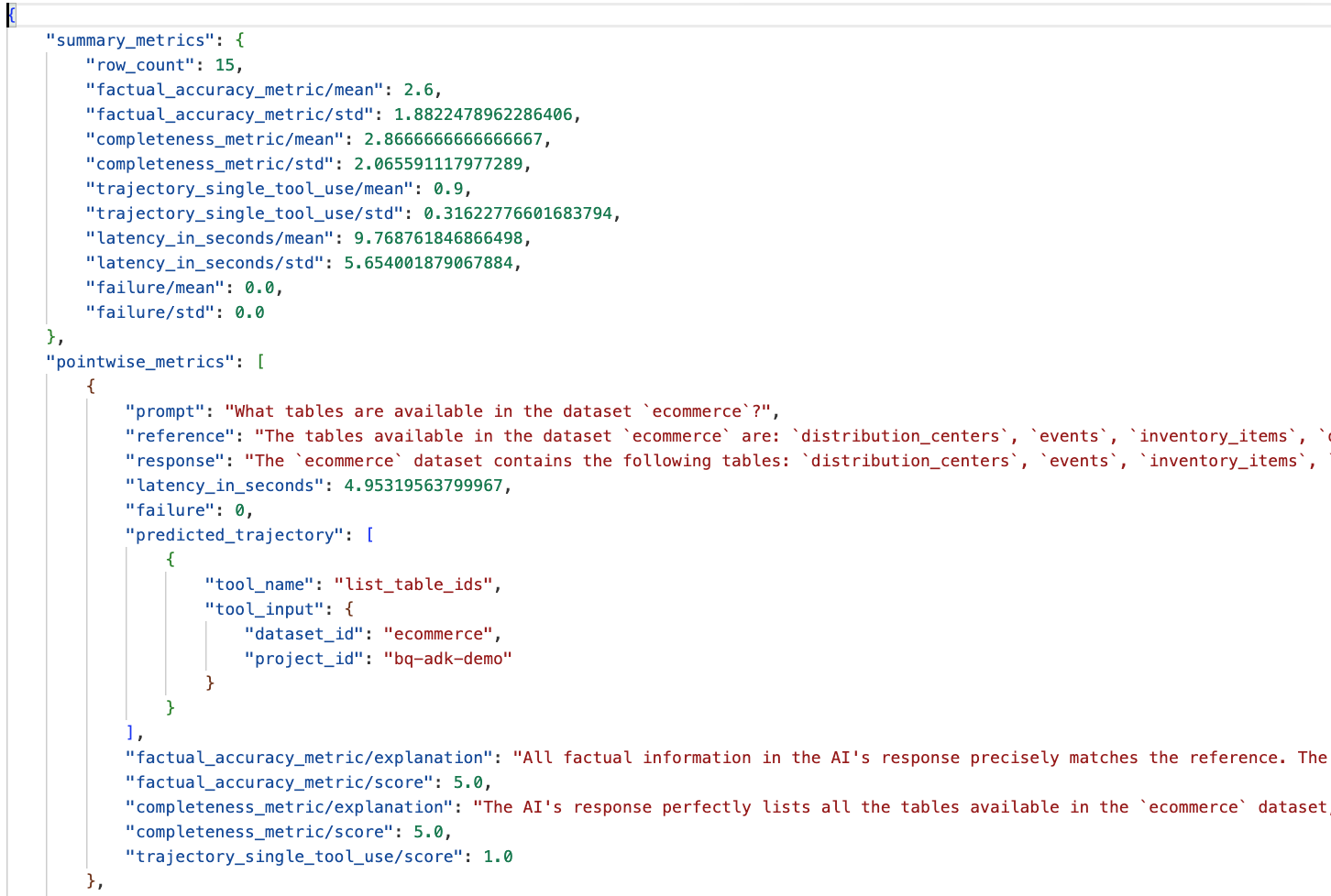
- 摘要指标:提供代理在整个数据集中的效果汇总视图。
- 事实准确性和完整性逐点指标:分数越接近 5,表示准确性和完整性越高。每道题都会有一个分数,并附有说明,解释该题获得相应分数的原因。
- 预测轨迹:这是智能体为生成最终回答而调用的工具的列表。这样,我们就可以看到代理生成的任何 SQL 查询。
我们可以看到,平均完整性和事实准确性的平均得分分别为 2.87 和 2.6。
结果不太理想!让我们尝试提高代理回答问题的能力。
12. 提升智能体的评估结果
前往 bigquery-adk-codelab 目录中的 agent.py,然后更新代理的模型和系统指令。请记得将 <YOUR_PROJECT_ID> 替换为您的项目 ID:
root_agent = Agent(
model="gemini-2.5-flash",
name="bigquery_agent",
description="Agent that answers questions about BigQuery data by executing SQL queries.",
instruction=(
"""
You are a data analysis agent with access to several BigQuery tools.
Use the appropriate tools to fetch relevant BigQuery metadata and execute SQL queries.
You must use these tools to answer the user's questions.
Run these queries in the project-id: '<YOUR_PROJECT_ID>' on the `ecommerce` dataset.
"""
),
tools=[bigquery_toolset]
)
现在返回到终端并重新运行评估:
python evaluate_agent.py
您应该会看到结果现在好多了:
================================================== --- Aggregated Evaluation Summary --- Total questions in evaluation dataset: 15 Average Completeness Score: 4.73 Average Factual Accuracy Score: 4.20 ==================================================
评估智能体是一个迭代过程。如需进一步改进评估结果,您可以调整系统指令、模型参数,甚至 BigQuery 中的元数据 - 请查看这些提示和技巧,了解更多想法。
13. 清理
为避免系统向您的 Google Cloud 账号持续收取费用,请务必删除我们在本次研讨会期间创建的资源。
如果您为此 Codelab 创建了任何特定的 BigQuery 数据集或表(例如电子商务数据集),不妨将其删除:
bq rm -r $PROJECT_ID:ecommerce
如需移除 bigquery-adk-codelab 目录及其内容,请执行以下操作:
cd .. # Go back to your home directory if you are still in bigquery-adk-codelab
rm -rf bigquery-adk-codelab
14. 恭喜
恭喜!您已成功使用智能体开发套件 (ADK) 构建并评估了 BigQuery 智能体。现在,您已了解如何使用 BigQuery 工具设置 ADK 智能体,以及如何使用自定义评估指标衡量其性能。