
১. ভূমিকা
BigQuery-এর জেনারেটিভ এআই ফাংশনগুলো আপনাকে লার্জ ল্যাঙ্গুয়েজ মডেল (LLM) ব্যবহার করে SQL-এর মাধ্যমে আপনার ডেটার ওপর যুক্তি প্রয়োগ করতে দেয়। আপনি আপনার ডেটা স্থানান্তর না করেই লক্ষ লক্ষ সারির সেন্টিমেন্ট বিশ্লেষণ করতে, সারাংশ তৈরি করতে এবং ছবিতে ক্যাপশন যোগ করতে পারেন।
কিন্তু যদি সঠিক ও নির্ভরযোগ্য ফলাফল পেতে আপনার প্রম্পটের জন্য প্রচুর পরিমাণে প্রাসঙ্গিক তথ্যের (যেমন নীতিমালা, ম্যানুয়াল বা একটি ভিডিও) প্রয়োজন হয়, তাহলে কী হবে?
জেমিনি কনটেক্সট ক্যাশিং এই বিশাল কনটেক্সটকে একটি ক্যাশে সংরক্ষণ করার মাধ্যমে এই সমস্যার সমাধান করে। পরবর্তী প্রম্পটগুলো প্রতিবার সম্পূর্ণ কন্টেন্ট প্রসেস করার পরিবর্তে ক্যাশটিকে রেফারেন্স হিসেবে ব্যবহার করে, যার ফলে ল্যাটেন্সি কমে আসে এবং ইনপুট টোকেনের উপর ৯০% পর্যন্ত ছাড় পাওয়া যায় ।
এই কোডল্যাবে, আপনি একটি "ফাইন প্রিন্ট" রিটার্ন পলিসি চেকার তৈরি করবেন যা BigQuery-তে থাকা একটি বিশাল, স্ট্যাটিক রিটার্ন পলিসি ডকুমেন্টের বিপরীতে গ্রাহকের রিটার্নের অনুরোধগুলো বিশ্লেষণ করতে এক্সপ্লিসিট কনটেক্সট ক্যাশিং ব্যবহার করে।

আপনি যা করবেন
- একটি BigQuery ডেটাসেট তৈরি করুন এবং গ্রাহকের ফেরতের অনুরোধের নমুনা দিয়ে তা পূরণ করুন।
- জেমিনি এন্টারপ্রাইজ এজেন্ট প্ল্যাটফর্মে (পূর্বে ভার্টেক্স এআই নামে পরিচিত) একটি কনটেক্সট ক্যাশে তৈরি করুন, যা ক্লাউড স্টোরেজে সংরক্ষিত একটি রিটার্ন পলিসি ডকুমেন্টকে নির্দেশ করবে।
- অনুরোধগুলোকে দক্ষতার সাথে সারি-সারি ভিত্তিতে মূল্যায়ন করার জন্য,
AI.GENERATEব্যবহার করে এমন একটি কোয়েরি চালান যা ক্যাশকে রেফারেন্স করে।
আপনার যা যা লাগবে
- ক্রোমের মতো একটি ওয়েব ব্রাউজার
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট
- গুগল ক্লাউড শেলে অ্যাক্সেস
এই কোডল্যাবটি নতুনদের সহ সকল স্তরের ডেভেলপারদের জন্য।
এই কোডল্যাবে তৈরি রিসোর্সগুলোর খরচ ২ ডলারের কম হওয়া উচিত।
আনুমানিক সময়কাল: এই কোডল্যাবটি সম্পূর্ণ করতে প্রায় ৩০ মিনিট সময় লাগবে।
২. শুরু করার আগে
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন ।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
ক্লাউড শেল শুরু করুন
ক্লাউড শেল হলো গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ, যা প্রয়োজনীয় টুলস সহ আগে থেকেই লোড করা থাকে।
- Google Cloud কনসোলের শীর্ষে থাকা Activate Cloud Shell-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনার প্রমাণীকরণ যাচাই করুন:
gcloud auth list - আপনার প্রজেক্টটি কনফিগার করা হয়েছে কিনা তা নিশ্চিত করুন:
gcloud config get project - আপনার প্রজেক্টটি প্রত্যাশা অনুযায়ী সেট করা না থাকলে, এটি সেট করুন:
gcloud config set project <YOUR_PROJECT_ID>
আপনার প্রজেক্ট আইডি এবং অবস্থান সেট করুন
আপনার সক্রিয় গুগল ক্লাউড প্রজেক্ট আইডি পুনরুদ্ধার করতে এবং এই কোডল্যাব জুড়ে ব্যবহারের জন্য ডিফল্ট অবস্থানটিকে এনভায়রনমেন্ট ভেরিয়েবল হিসেবে সেট করতে নিম্নলিখিত কমান্ডটি চালান:
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export LOCATION="us-central1"
এপিআই সক্ষম করুন
প্রয়োজনীয় API-গুলো সক্রিয় করতে এই কমান্ডটি চালান:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com
৩. BigQuery ডেটা প্রস্তুত করুন
কনটেক্সট ক্যাশিং পরীক্ষা করার আগে, আমাদের একটি ডেটাসেট এবং একটি টেবিল প্রয়োজন, যেখানে গ্রাহকদের ফেরত পাঠানোর নমুনা অনুরোধগুলো থাকবে, যার উপর ভিত্তি করে আমরা আমাদের কোয়েরিগুলো চালাব।
১. একটি ডেটাসেট তৈরি করুন
caching_demo নামের একটি BigQuery ডেটাসেট তৈরি করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান:
bq mk --dataset $PROJECT_ID:caching_demo
২. টেবিলটি তৈরি করুন এবং এতে তথ্য যোগ করুন।
return_requests নামে একটি টেবিল তৈরি করতে এবং গ্রাহকের ফেরত অনুরোধের নমুনা সন্নিবেশ করতে নিম্নলিখিত কমান্ডটি চালান:
bq query \
--use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`caching_demo.return_requests\` AS
SELECT
10001 AS return_id,
'P-1001' AS purchase_id,
'I bought this jacket on Black Friday but it was too small.' AS return_comment,
DATE('2025-11-28') AS purchase_date,
DATE('2025-12-05') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier
UNION ALL
SELECT
10002 AS return_id,
'P-1002' AS purchase_id,
'The item arrived broken, I want a refund. I don\'t have photos because I threw it away.' AS return_comment,
DATE('2026-04-01') AS purchase_date,
DATE('2026-04-02') AS return_date,
'GenericBrand' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10003 AS return_id,
'P-1003' AS purchase_id,
'I bought this ApexWear jacket, took the tags off to wear it once, but it doesn\'t fit well.' AS return_comment,
DATE('2026-02-15') AS purchase_date,
DATE('2026-02-20') AS return_date,
'ApexWear' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10004 AS return_id,
'P-1004' AS purchase_id,
'This was a holiday gift but doesn\'t fit.' AS return_comment,
DATE('2025-12-20') AS purchase_date,
DATE('2026-01-28') AS return_date,
'StyleCorp' AS product_brand,
'Standard' AS customer_tier
UNION ALL
SELECT
10005 AS return_id,
'P-1005' AS purchase_id,
'I realized this doesn\'t fit' AS return_comment,
DATE('2026-02-01') AS purchase_date,
DATE('2026-03-15') AS return_date,
'ApexWear' AS product_brand,
'Gold' AS customer_tier;"
আপনি একটি সফলতার বার্তা দেখতে পাবেন:
Created your-project-id.caching_demo.return_requests
আমরা এখন আমাদের ক্যাশে তৈরি করার জন্য প্রস্তুত!
৪. কনটেক্সট ক্যাশে তৈরি করুন
আপনি curl ব্যবহার করে Gemini Enterprise Agent Platform (পূর্বে Vertex AI নামে পরিচিত) মডেল এন্ডপয়েন্টে একটি REST কলের মাধ্যমে ক্যাশে তৈরি করবেন।
একটি নতুন স্টোরেজ বাকেট তৈরি করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান। এটি সেই ফাইলগুলি সংরক্ষণ করতে ব্যবহৃত হবে যা আমরা ক্যাশে করতে চাই:
gcloud storage buckets create gs://${PROJECT_ID}-caching-demo --location=${LOCATION}
এরপর, নমুনা পলিসি ডকুমেন্টটি আপনার নতুন তৈরি করা বাকেটে কপি করুন :
gcloud storage cp gs://sample-data-and-media/context_caching_demo/return_policy.md gs://${PROJECT_ID}-caching-demo/
এখন, আপনার নতুন স্টেজ করা পলিসি ডকুমেন্টটি উল্লেখ করে ক্যাশে তৈরি করতে নিম্নলিখিত কমান্ডটি চালান (এটি সম্পন্ন হতে প্রায় এক মিনিট সময় লাগতে পারে):
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents" \
-d '{
"model": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/publishers/google/models/gemini-2.5-flash",
"contents": [
{
"role": "user",
"parts": [
{
"fileData": {
"mimeType": "text/markdown",
"fileUri": "gs://'"${PROJECT_ID}"'-caching-demo/return_policy.md"
}
}
]
}
],
"ttl": "3600s"
}'
রেসপন্স JSON-এ প্রাপ্ত name নোট করে নিন, যা দেখতে এইরকম হবে: projects/PROJECT_NUMBER/locations/LOCATION/cachedContents/CACHE_ID । পরবর্তী ধাপের জন্য আপনার এই CACHE_ID প্রয়োজন হবে।
{
"name": "projects/123456789012/locations/us-central1/cachedContents/123456789012345"
}
ক্লাউড শেলে CACHE_ID-কে একটি এনভায়রনমেন্ট ভেরিয়েবল হিসেবে সংরক্ষণ করুন :
export CACHE_ID="<YOUR_CACHE_ID>"
৫. ক্যাশ করা কন্টেন্ট দিয়ে AI.GENERATE চালান।
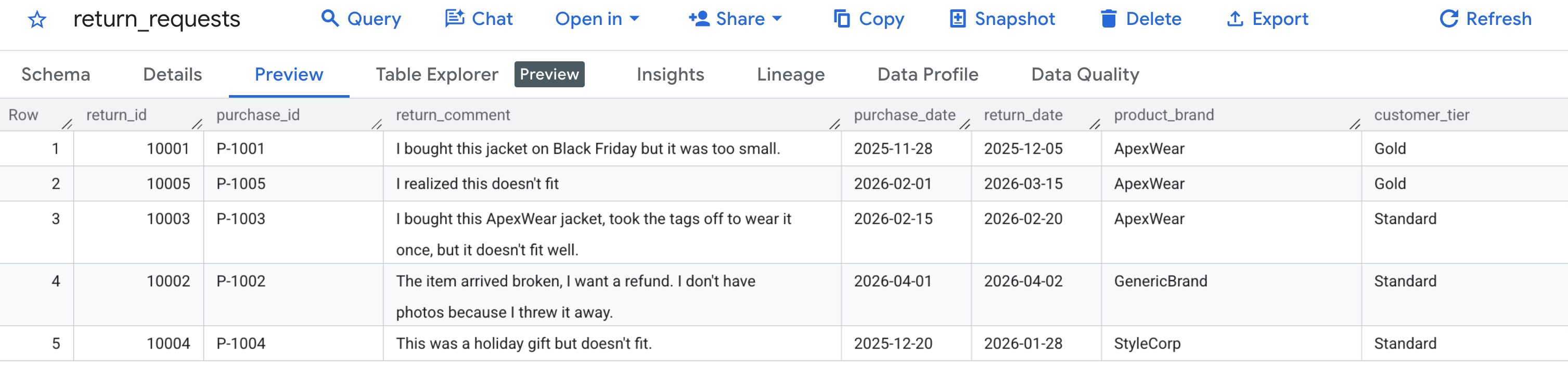
প্রথমে, চলুন যাচাই করে নিই যে আমাদের স্যাম্পল ডেটা সঠিকভাবে তৈরি হয়েছে কিনা । BigQuery কনসোলে যান, caching_demo ডেটাসেটটি খুঁজুন এবং return_requests টেবিলটিতে ক্লিক করুন।
প্রিভিউ ট্যাবের অধীনে, আপনি আমাদের পূর্বে তৈরি করা গ্রাহক ফেরতের অনুরোধগুলি দেখতে পাবেন:
এখন যেহেতু ক্যাশে তৈরি এবং ডেটা দিয়ে পূর্ণ করা হয়েছে, আপনি শুধুমাত্র সেই ক্যাশে আইডিটি উল্লেখ করে AI.GENERATE ব্যবহার করে রিফান্ড অনুরোধটি মূল্যায়ন করার জন্য কোয়েরি করতে পারেন।
ম্যানুয়ালি ভেরিয়েবল খুঁজে প্রতিস্থাপন করার ঝামেলা এড়াতে, ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান । এটি আপনার বিদ্যমান এনভায়রনমেন্ট ভেরিয়েবল ব্যবহার করে ডায়নামিকভাবে SQL কোয়েরি তৈরি করবে এবং স্ক্রিনে প্রিন্ট করে দেবে, যাতে আপনি সহজেই এটি কপি করতে পারেন।
cat << EOF > query.sql
WITH generated_returns AS (
SELECT
*,
-- Call AI.GENERATE with the prompt, schema, and cache ID
AI.GENERATE(
-- Construct the prompt referencing the cached policy
prompt => CONCAT(
'Analyze this return request using the cached Return Policy. ',
'Return Comment: "', return_comment, '". ',
'Purchase Date: ', purchase_date, '. ',
'Brand: ', product_brand, '. ',
'Customer Tier: ', customer_tier, '. '
),
-- Define the structured output schema
output_schema => """
eligible_for_refund STRING OPTIONS(description = 'True/False whether the request is eligible for a refund based on the policy'),
refund_type STRING OPTIONS(description = 'Classify as Full, Store Credit, or None'),
reason_citation STRING OPTIONS(description = 'Quote the specific rule from the policy applied to this decision')
""",
-- Construct the endpoint string dynamically using variables
endpoint => 'gemini-2.5-flash',
-- Pass the cached content ID using bash interpolation for the literal
model_params => JSON '{"cachedContent": "projects/$PROJECT_NUMBER/locations/$LOCATION/cachedContents/$CACHE_ID"}'
) AS results
FROM \`caching_demo.return_requests\`
)
SELECT
*,
-- Extract token usage metrics from the raw JSON response
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.prompt_token_count') AS INT64) AS prompt_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.cached_content_token_count') AS INT64) AS cached_content_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.candidates_token_count') AS INT64) AS output_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.total_token_count') AS INT64) AS total_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.thoughts_token_count') AS INT64) AS thoughts_token_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_prompt_usage.text_count') AS INT64) AS billable_prompt_text_count,
CAST(JSON_EXTRACT_SCALAR(results.full_response, '$.usage_metadata.billable_cached_content_usage.text_count') AS INT64) AS billable_cached_text_count
FROM generated_returns;
EOF
cat query.sql
এখন, টার্মিনালে থাকা sql-টি কপি করুন , আপনার ব্রাউজারে BigQuery কনসোলে যান এবং কোয়েরি এডিটর ট্যাবে কোয়েরিটি এক্সিকিউট করুন ।
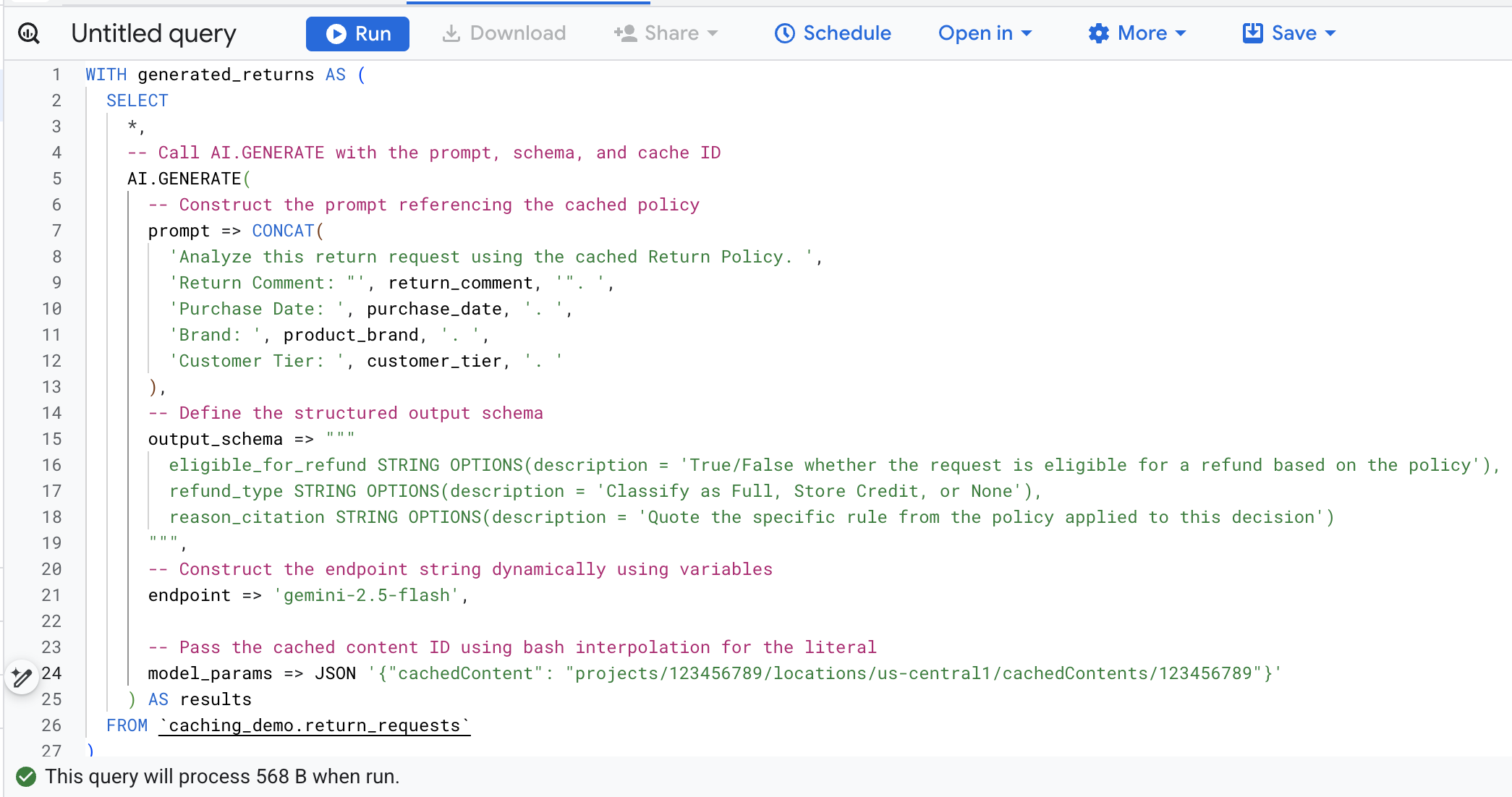
এই ফাংশন কলটির মূল আর্গুমেন্টগুলোর বিবরণ নিচে দেওয়া হলো:
-
prompt: প্রতিটি গ্রাহক সারির জন্য নির্দিষ্ট তথ্য ধারণ করে। এই লেখাটি কার্যকরভাবে ক্যাশে আগে থেকেই থাকা বৃহৎ রিটার্ন পলিসি ডকুমেন্টের সাথে যুক্ত করা হয়। -
output_schema: মডেলের প্রতিক্রিয়ার প্রত্যাশিত JSON কাঠামো নির্ধারণ করে। -
endpoint: জেনারেশনের জন্য ব্যবহৃত এজেন্ট প্ল্যাটফর্ম এআই মডেলের এন্ডপয়েন্ট নির্দিষ্ট করে (আমাদের ক্ষেত্রে জেমিনি ২.৫ ফ্ল্যাশ)। -
model_params: এটি একটি গুরুত্বপূর্ণ প্যারামিটার যাcachedContentফিল্ড ব্যবহার করে তৈরি করা ক্যাশ আইডি প্রেরণ করে।
সংরক্ষিত নীতি অনুসারে প্রতিটি ফেরত অনুরোধ বিশ্লেষণ করে তৈরি হওয়া ফলাফলগুলো আপনি দেখতে পাবেন। নিষ্কাশিত টোকেন মেট্রিকগুলো দেখতে ডানদিকে স্ক্রোল করুন।
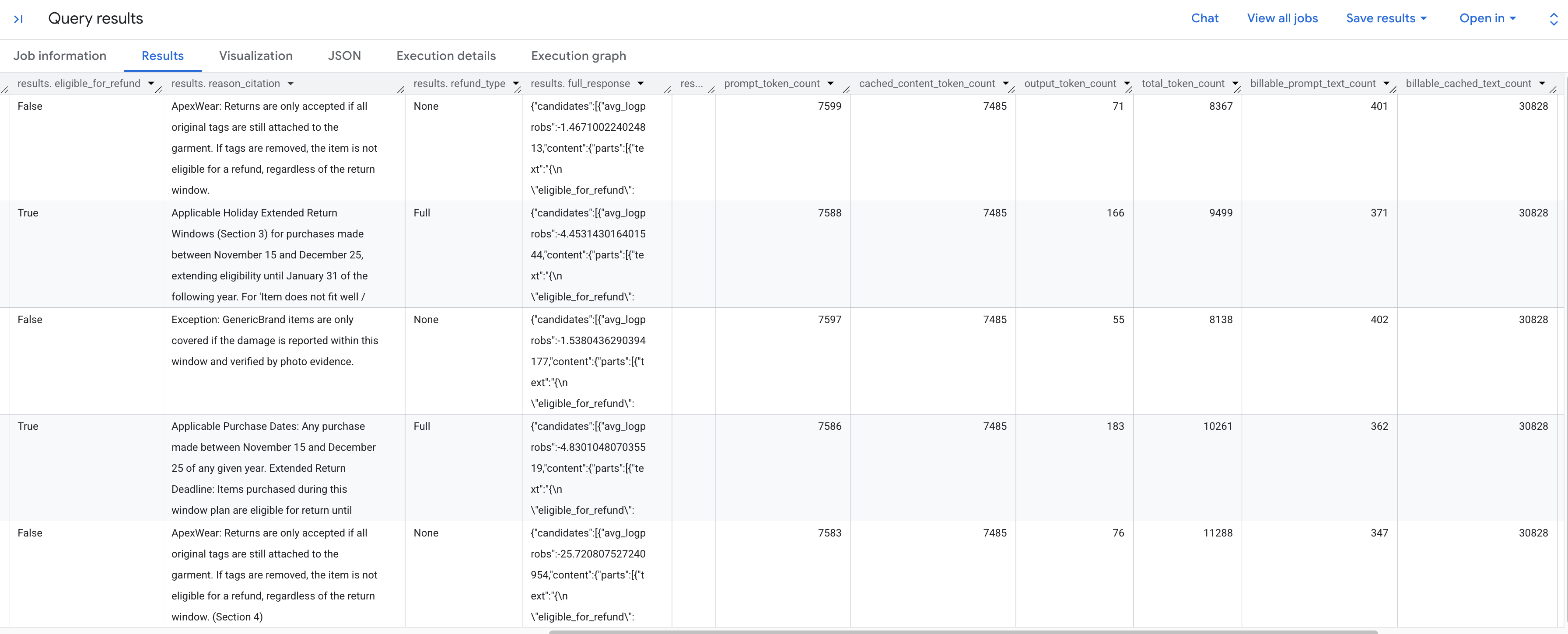
আপনি যে টোকেন মেট্রিকগুলো দেখতে পাচ্ছেন, তার বিস্তারিত বিবরণ নিচে দেওয়া হলো:
-
prompt_token_count: ইনপুট প্রম্পটে প্রক্রিয়াকৃত মোট টোকেনের সংখ্যা (ক্যাশে করা বিষয়বস্তু সহ)। -
cached_content_token_count: ক্যাশে থেকে পরিবেশিত টোকেনের সংখ্যা (যা স্ট্যাটিক রিটার্ন পলিসি ডকুমেন্টকে প্রতিনিধিত্ব করে)। -
output_token_count: রেসপন্সে মডেল দ্বারা তৈরি টোকেনের সংখ্যা। -
total_token_count: প্রম্পট এবং আউটপুট টোকেনগুলির যোগফল। -
billable_prompt_text_count: প্রম্পটের নন-ক্যাশড অংশে থাকা বিলযোগ্য অক্ষরের সংখ্যা। -
billable_cached_text_count: ক্যাশ করা কন্টেন্টে থাকা বিলযোগ্য অক্ষরের সংখ্যা।
billable_prompt_text_count কলামটি দেখুন—এটি প্রতি সারিতে মাত্র কয়েকশ অক্ষর দেখায়, যা কেবল গ্রাহকের নির্দিষ্ট অনুরোধ। এর বিপরীতে, সম্পূর্ণ রিটার্ন পলিসির জন্য billable_cached_text_count এ ৩০,০০০-এরও বেশি অক্ষর থাকে। কনটেক্সট ক্যাশিং ছাড়া, আপনাকে প্রতিটি সারির জন্য সম্পূর্ণ পলিসি ডকুমেন্টটি প্রসেস করতে অর্থ প্রদান করতে হতো। এটি ক্যাশ করার মাধ্যমে, আপনি বড় ডকুমেন্টটির জন্য একবার অর্থ প্রদান করেন এবং পরবর্তী সারিগুলোর জন্য আপনাকে কেবল ছোট, পরিবর্তনশীল প্রম্পট টেক্সটের জন্য চার্জ করা হয়।
এর ফলে ব্যাচ জবগুলোর ক্ষেত্রে বিপুল সাশ্রয় হয়!
৬. পরিষ্কার করুন
আপনার গুগল ক্লাউড অ্যাকাউন্টে চলমান চার্জ এড়াতে, এই কোডল্যাব চলাকালীন তৈরি করা রিসোর্সগুলো মুছে ফেলুন।
BigQuery ডেটাসেট এবং এর টেবিলগুলো ডিলিট করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান :
bq rm -r -f -d caching_demo
পলিসি ডকুমেন্টের জন্য তৈরি করা স্টেজিং বাকেটটি মুছে ফেলুন :
gcloud storage rm --recursive gs://${PROJECT_ID}-caching-demo
অবশেষে, আপনার পূর্বে সংরক্ষণ করা ভেরিয়েবলগুলো ব্যবহার করে কনটেক্সট ক্যাশে মুছে ফেলুন , যাতে চলমান স্টোরেজ চার্জ এড়ানো যায়:
curl -X DELETE \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/cachedContents/${CACHE_ID}"
৭. অভিনন্দন
অভিনন্দন! আপনি এজেন্ট প্ল্যাটফর্মে সফলভাবে একটি কনটেক্সট ক্যাশে তৈরি করেছেন এবং ইনপুট টোকেন প্রক্রিয়াকরণের খরচ কমানোর পাশাপাশি বিশ্লেষণের গতি বাড়াতে একটি BigQuery AI ফাংশনে এটিকে রেফারেন্স করেছেন।
আপনি যা শিখেছেন
- রিটার্ন রিকোয়েস্ট অ্যানালিটিক্সের জন্য এনভায়রনমেন্ট টেবিল কীভাবে সেট আপ করবেন।
- স্পষ্টভাবে একটি স্ট্যাটিক ডকুমেন্ট কনটেক্সট ক্যাশে তৈরি করার জন্য
curlব্যবহার করে এজেন্ট প্ল্যাটফর্ম (Vertex AI) API-কে কীভাবে কল করতে হয়। - সক্রিয় প্রম্পটগুলো থেকে অপ্রয়োজনীয় ইনপুট টোকেন বাদ দিতে
AI.GENERATESQL কোয়েরিতে তৈরি করা ক্যাশ আইডি কীভাবে ব্যবহার করবেন।